单链表:数据结构中的高效指针艺术
今天我们给大家带来的是数据结构中的单链表的知识点。
一、数据结构是什么
1.定义:
数据结构(Data Structure)是计算机中组织、存储和管理数据的特定方式,它通过定义数据之间的逻辑关系、操作规则以及物理存储形式,旨在高效地实现数据的访问、插入、删除、修改等操作,是计算机科学与编程的核心基础之一。
2.作用:
数据结构的本质是为了平衡时间复杂度和空间复杂度,让程序在不同场景下更高效。举例说明:
- 若需要频繁 “按索引查数据”(如查学生学号对应的信息):选数组(随机访问 O (1)),而非链表(遍历 O (n))。
- 若需要频繁 “插入 / 删除数据”(如实时日志记录):选链表(修改指针 O (1)),而非数组(移动元素 O (n))。
- 若需要 “优先处理高优先级任务”(如操作系统任务调度):选堆(优先队列),而非普通队列(仅按顺序处理)。
二、单链表
1.定义:
单链表(Singly Linked List)是一种线性数据结构,由一系列节点(Node)通过指针连接而成,其定义包含以下核心要素:
节点结构:每个节点包含两部分
- 数据域:存储具体的数据值(如整数、字符串、对象等)
- 指针域:仅存储下一个节点的地址(或引用),用于指向后继节点
连接方式:节点之间通过指针单向串联,形成链式结构
- 第一个节点称为头节点(Head),是访问整个链表的起点
- 最后一个节点的指针域为
null(或None),表示链表的结束 - 只能从当前节点访问其后继节点,无法直接访问前驱节点
逻辑结构:呈现为线性序列,例如:plaintext
头节点 → 节点A → 节点B → 节点C → null图示:
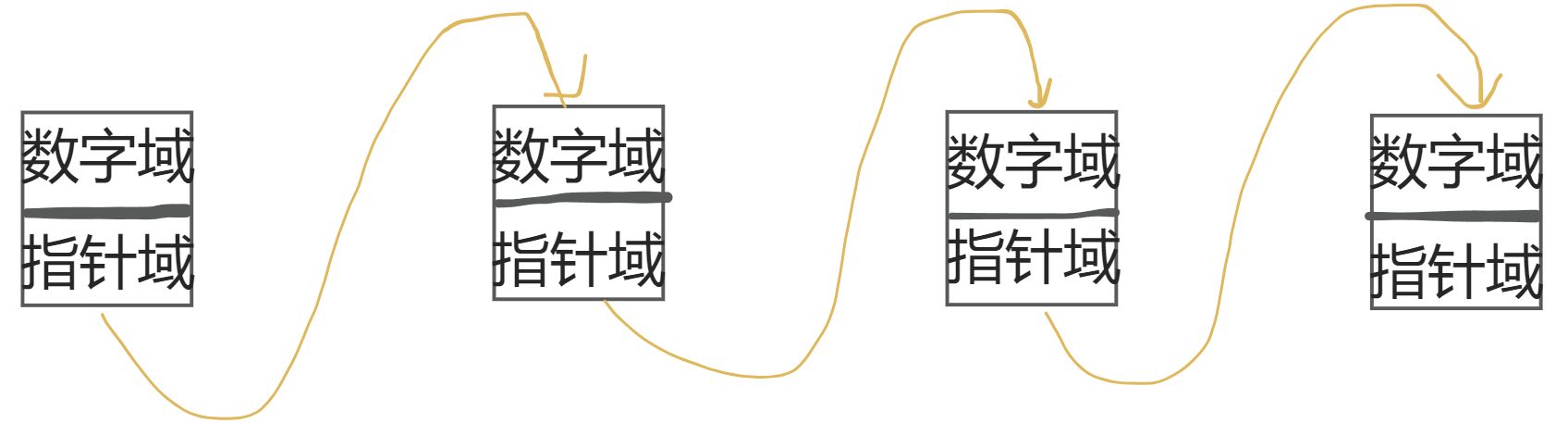
2.单链表跟数组的对比
2.1访问效率差异的根源:
数组的连续存储使其能通过下标进行随机访问(eg.a[0],a[10]);而链表的分散存储无固定地址规律,只能通过指针逐个跳转,必须顺序遍历。
2.2插入 / 删除效率差异的根源:
数组的中间操作需要 “移动元素” 以维持连续存储的特性(例如在数组 [1,2,3] 的索引 1 插入 4,需将 2、3 后移为 [1,4,2,3]);而链表的插入 / 删除仅需修改指针指向(例如在节点 A 和 B 之间插入节点 C,只需将 A.next 指向 C,C.next 指向 B),无需移动其他节点。
2.3内存灵活性差异的根源:
数组的大小依赖 “连续内存块”,初始化时需确保内存中有足够大的连续空间;而链表的节点分散存储,只需内存中有零散的小空间即可,新增节点时动态申请,灵活性更高。
3.单链表的实现
说明:这里我们是通过数据进行模拟的单链表。
代码中的一些参数说明:
e[]:表示节点的值
ne[]:表示节点的next指针是多少
idx:表示存储当前已经用到了哪个点
head:表示头节点的下标
-1表示最后一个节点的地址
图示说明:
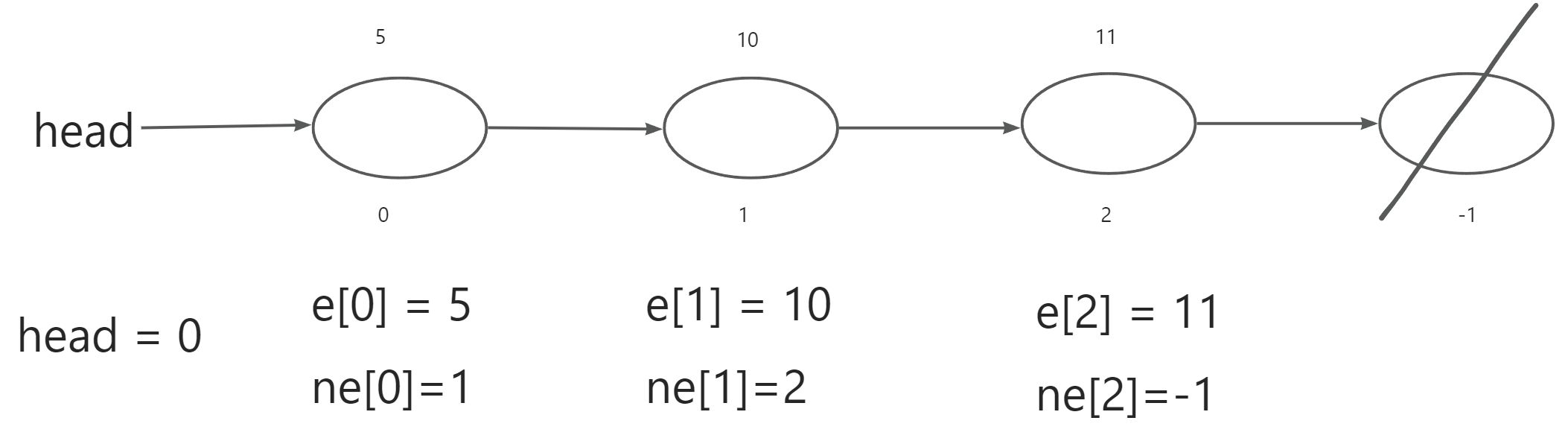
3.1初始化链表:
一开始 head = -1,idx = 0,因为还没有加入节点。
void init()
{head = -1;idx = 0;
}
3.2将x插到头节点(头插法)
图示:
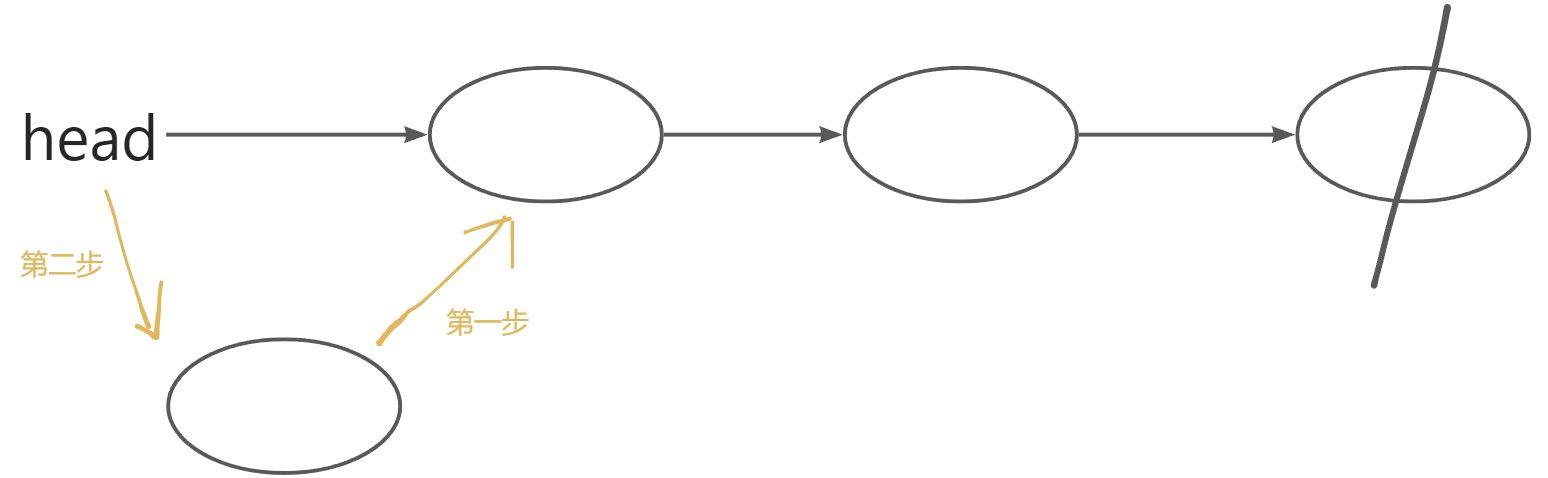
void add_to_head(int x)
{// 1. 将新元素x存入当前空闲位置idx的数据域// (把值存一下)e[idx] = x;// 2. 新节点的指针域指向原头节点(head)ne[idx] = head;// 3. 更新头节点指针,使其指向新节点(idx)head = idx;// 4. 移动空闲位置指针idx,为下一次插入新节点做准备idx++;
}3.3将x插入到小标是k的点的后面
图示:
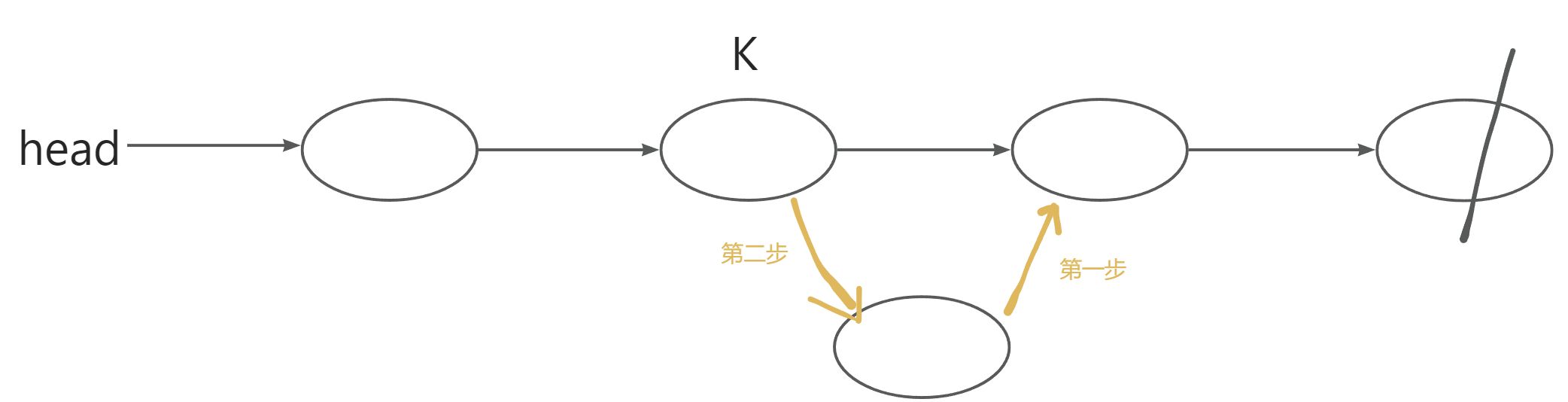
void add(int k, int x)
{// 1. 将新元素x存入当前空闲位置idx的数据域e[idx] = x;// 2. 新节点的指针域指向k节点原本指向的下一个节点ne[idx] = ne[k];// 3. 更新k节点的指针域,使其指向新节点idxne[k] = idx;// 4. 移动空闲位置指针,为下一次插入做准备idx++;
}3.4将下标是k的点后面的点删除
图示:
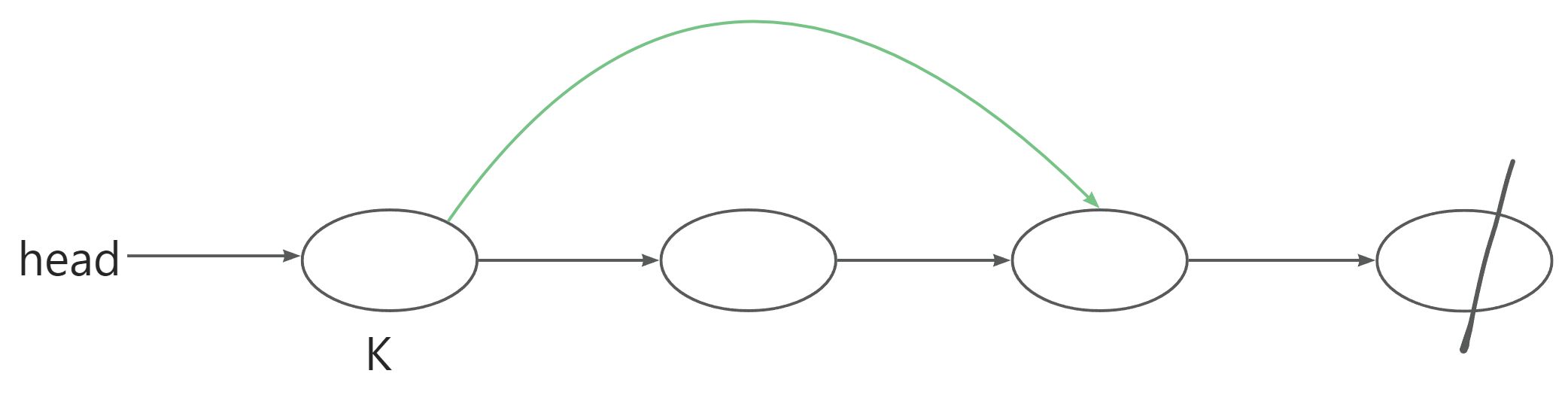
void remove(int k)
{ne[k] = ne[ne[k]];
}3.5遍历链表
for(int i = head;i != -1;i = ne[i])三、总结
学习单链表的核心是 “建立指针思维”—— 不纠结于节点的物理位置,而是关注指针的指向关系;同时重视边界条件(空链表、尾节点、单节点)和内存管理(动态链表)。通过 “概念理解→画图分析→代码实现→调试验证” 的流程,可逐步掌握单链表的本质。在学习链表的时候可以多画图,去理解它们的关系。
在你想要放弃的那一刻,想想为什么当初坚持走到了这里,大家共勉!!!