大模型如何一招打通,零标注也能SOTA
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
当大模型成为跨模态知识的统一接口,从图-文对齐到知识图谱补全、从网页截图到多轮搜索,顶会顶刊正把“零样本跨模态迁移”推向下一个爆点
我拆了该领域三大新作,带你秒懂它们如何用同一套大模型范式打通推荐、图表示与搜索,附论文直达链接,助你快速锁定下一篇高分 idea。
Comprehending Knowledge Graphs with Large Language Models for Recommender Systems
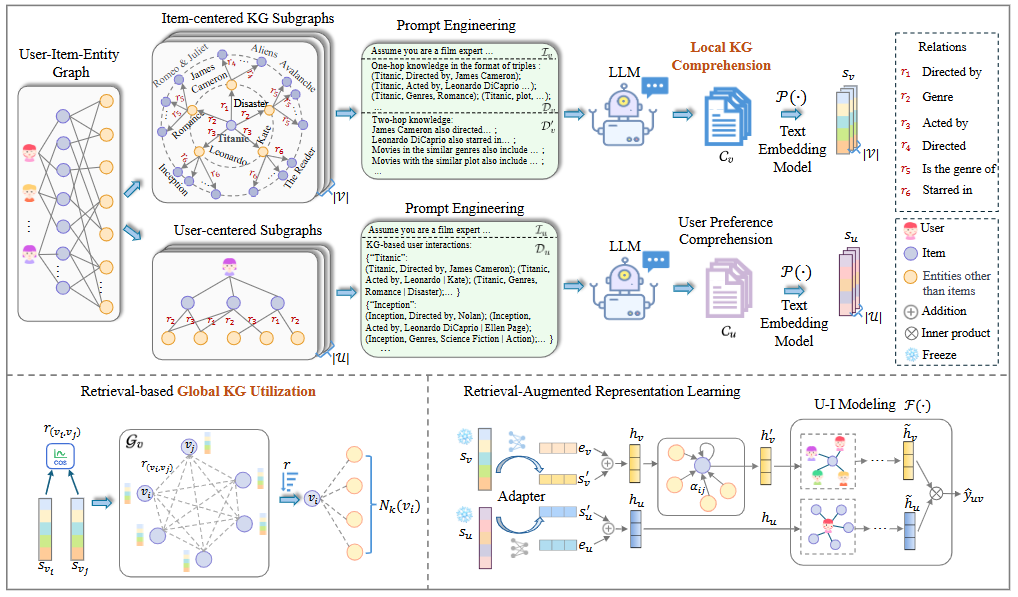
方法:这篇文章提出CoLaKG框架,用大型语言模型先对以物品为中心的局部知识子图进行补全与理解并生成语义嵌入,再通过全局语义检索构建物品-物品图,最后用适配器将语义嵌入与传统ID嵌入对齐融合,并以注意力机制聚合高阶邻居,整体在推荐阶段完全脱离LLM推理以保证工业效率。
创新点:
首次将LLM用于同时补全缺失知识图谱事实并深度理解其语义结构,突破传统方法只能依赖结构化ID的局限。
设计检索式全局KG利用模块,直接把高阶跨图谱语义关联转化为物品-物品图的显式边,避免多层GNN传播带来的过平滑与噪声。
提出解耦的两阶段训练范式,第一阶段仅用LLM离线生成语义嵌入,第二阶段用轻量适配器与注意力机制把语义信息无缝注入任意传统推荐模型,实现高效果与高效率兼得。

总结:文章先让LLM阅读并补全每个物品的两跳知识子图,输出文本理解后再转成语义向量;接着用这些向量计算物品间的全局语义相似度,为每个物品召回最相关的k个邻居以增强表示;最后把融合后的用户与物品表征送入LightGCN等任意推荐模型进行训练,整个过程在推理阶段无需再次调用LLM。
GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
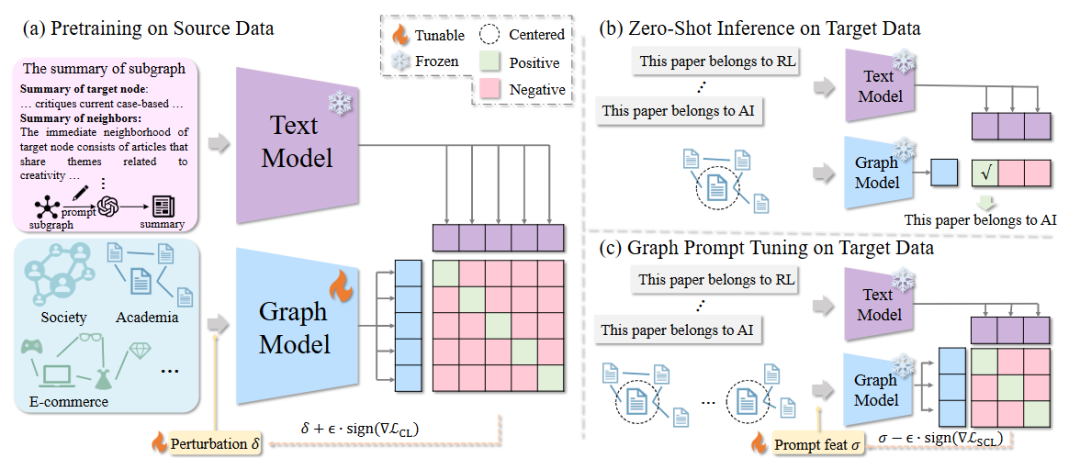
方法:这篇文章提出GraphCLIP框架,通过让大模型为无标签子图生成高质量摘要并构建2亿词规模的图-摘要对,采用图Transformer与冻结文本编码器进行自监督对比预训练,同时引入对抗扰动的最大差异损失提取跨域不变特征,实现零样本直接推理,并在少样本场景下用与预训练目标对齐的图提示微调仅更新少量参数以避免灾难遗忘。
创新点:
首次利用大语言模型在无标签图上批量生成富含结构语义的子图摘要,构建超大规模图-摘要对训练语料,摆脱对人工标签的依赖。
提出结合对抗扰动的最大差异不变对齐损失,使图编码器在自监督对比学习中捕获跨域因果特征,显著提升跨数据集零样本迁移能力。
设计任务一致的图提示微调策略,在少样本阶段仅优化与预训练扰动形式相同的少量提示参数,兼顾低学习成本与灾难遗忘抑制。
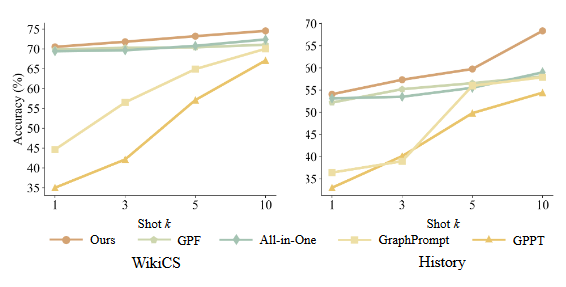
总结:GraphCLIP先用随机游走采样大规模子图,调用冻结的Qwen2-72B按XML模板为每个子图生成500词以内的结构-语义摘要,形成大规模图-摘要对;随后用12层GraphGPS编码图、冻结的MiniLM编码摘要,在对比损失中加入对抗扰动寻找最坏增强差异以强化跨域不变性。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
MMSEARCH:UNVEILING THE POTENTIAL OF LARGE MOD-ELS AS MULTI-MODAL SEARCH ENGINES
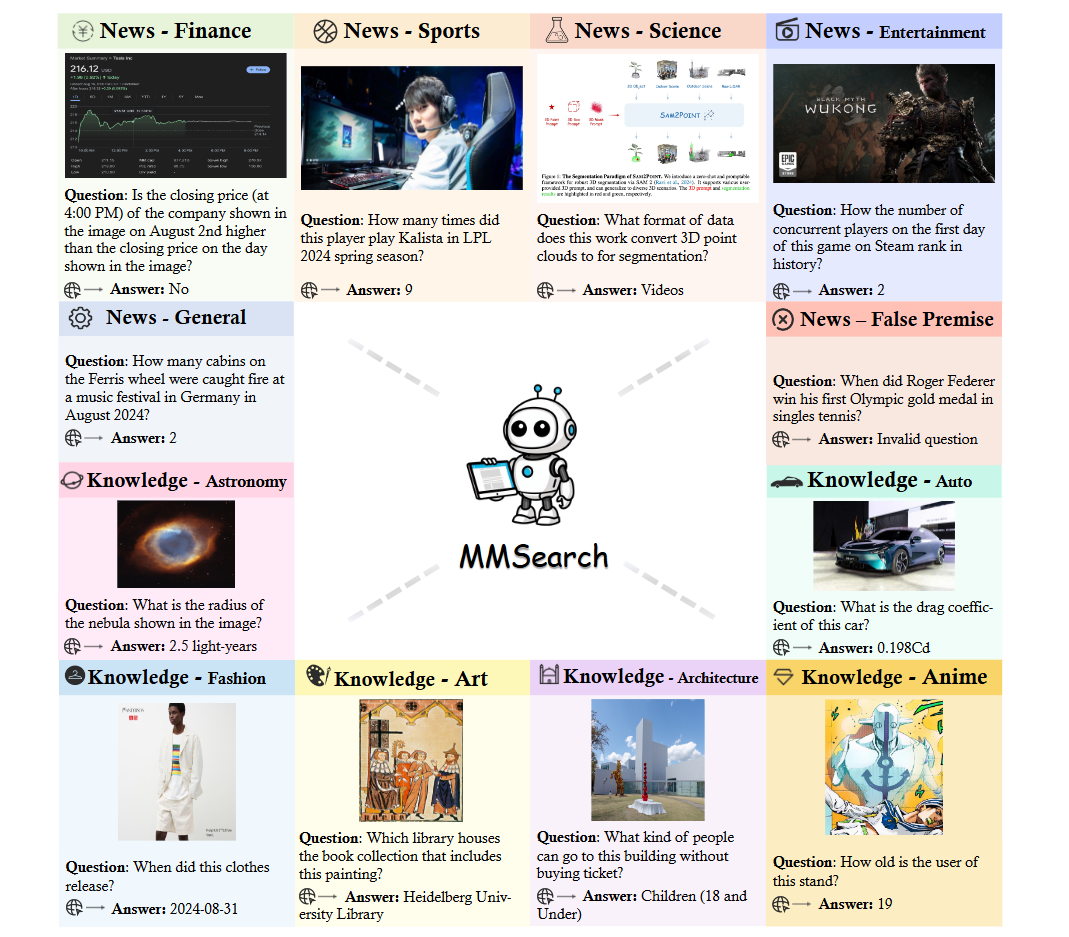
方法:这篇文章首次构建了端到端多模态AI搜索引擎,通过MMSEARCH-ENGINE让任何LMM都能零样本完成“重查询-重排序-摘要”三阶段搜索,并用300条与训练数据无重叠的人工问题全面衡量其能力,从而突破现有文本搜索局限、揭示LMM在真实网络场景中的真实水平。
创新点:
首创MMSEARCH-ENGINE零样本管道,将Google Lens视觉搜索与网页截图结合,使LMM无需微调即可在图文交错网页中完成端到端多模态检索。
构建MMSEARCH基准,首次以“最新新闻+罕见知识”双域300题确保答案只能由搜索获得,并设计分步评估体系量化重查询、重排序、摘要三大环节。
系统实验发现:GPT-4o+MMSEARCH-ENGINE在端到端任务上超越商业产品Perplexity Pro,且通过测试时计算缩放可让小模型反超大模型,为未来搜索系统指明方向。
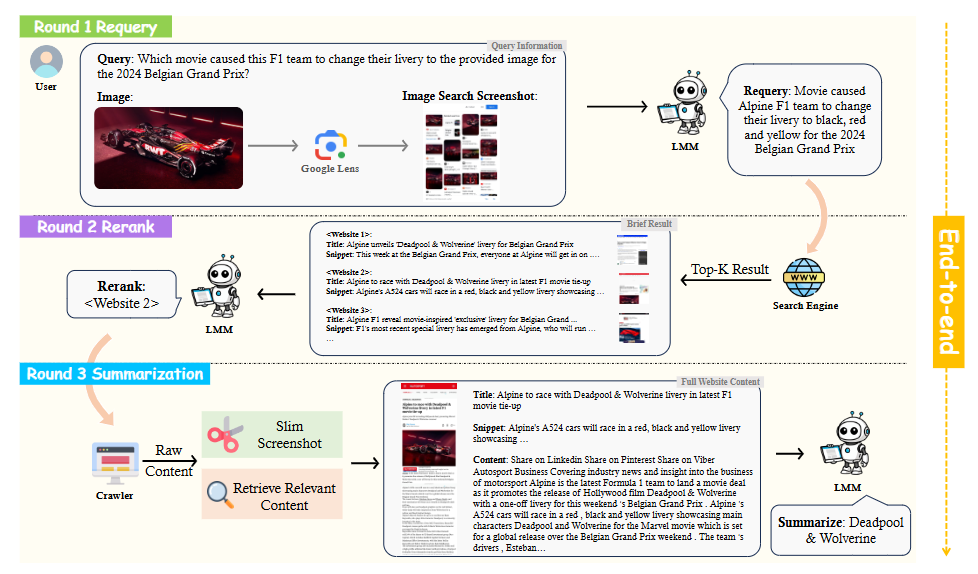
总结:作者先让LMM把含图用户问题改写成搜索引擎友好的文本,再利用Google Lens与网页截图获取多模态候选,随后让模型从中挑选最相关站点并爬取精简内容,最后生成简洁答案;整个过程在MMSEARCH基准上以分步评分揭示当前模型在重查询与重排序环节的明显短板,并通过扩大推理轮次而非参数规模显著提升性能。
关注gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯