全景式综述|多模态目标跟踪全面解析:方法、数据、挑战与未来

【导读】
目标跟踪(Visual Object Tracking, VOT)一直是计算机视觉领域的核心问题之一,广泛应用于自动驾驶、无人机监控、人机交互等场景。随着单模态方法在复杂环境下逐渐遇到瓶颈,多模态视觉目标跟踪(Multi-Modal VOT)应运而生,它通过融合不同传感器模态(RGB、红外、深度、语义等),显著提升了鲁棒性与精度。本文将带你走进最新的多模态目标跟踪研究进展。
目录
一、为什么需要多模态目标跟踪?
二、方法发展脉络
三、一个全景式框架:四大核心环节
多模态数据采集(Data Collection)
模态对齐与标注(Alignment & Annotation)
多模态模型设计(Model Designing)
评测与基准(Evaluation & Benchmarking)
四、框架亮点:两个首次提出的问题
多模态融合是否总是更优?
数据分布的偏差
五、未来发展方向
总结
一、为什么需要多模态目标跟踪?
传统的单模态视觉跟踪往往依赖RGB视频。然而在弱光、遮挡、背景杂乱等情况下,RGB信息容易失效。多模态跟踪的优势在于:
-
互补性:红外可在夜间或低光环境中稳定工作,深度信息能提供空间结构,语义模态带来场景理解。
-
鲁棒性:在目标外观变化、尺度变化或部分遮挡时,多模态融合往往比单模态更可靠。
-
广泛应用:自动驾驶中的激光雷达与摄像头、安防监控中的红外与可见光融合,都是多模态跟踪的典型需求。
近日,一篇综述论文《Omni Survey for Multimodality Analysis in Visual Object Tracking》对该领域进行了全面梳理。这篇综述堪称“全方位”(Omni),不仅因为它覆盖了迄今为止最广泛的多模态跟踪任务,还因为它从数据、模型、评估等多个维度,深入剖析了该领域的现状、挑战与未来。论文共引用了338篇参考文献,为研究者提供了一个极其宝贵的知识库和路线图。

论文标题:
Omni Survey for Multimodality Analysis in Visual Object Tracking
论文链接:
https://arxiv.org/abs/2508.13000
二、方法发展脉络
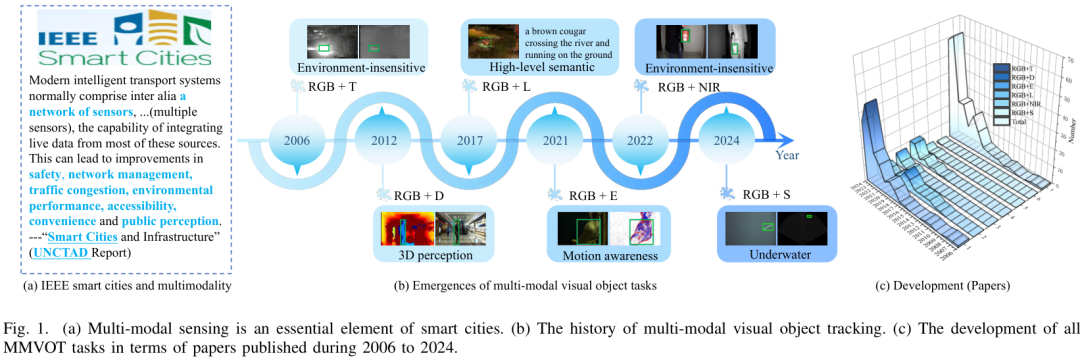
-
早期传统方法:基于滤波、光流与手工特征的跨模态对齐。
-
深度学习方法:利用卷积神经网络(CNN)、Transformer等结构对不同模态特征进行融合与增强。
-
融合策略创新:包括特征级融合(early fusion)、决策级融合(late fusion)以及跨模态注意力机制,近年来的趋势是更灵活的自适应融合。
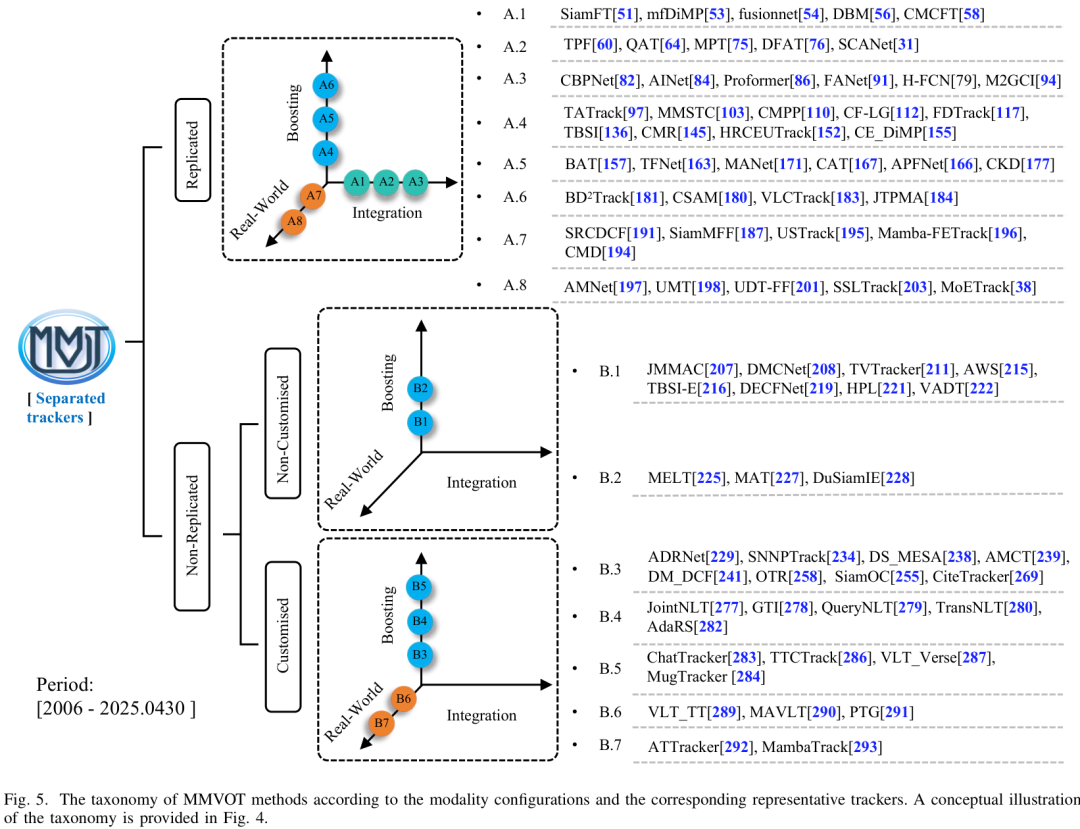
三、一个全景式框架:四大核心环节
MMVOT 的研究可以被拆解为四个关键环节,它们构成了一个全景式的分析框架:
-
多模态数据采集(Data Collection)
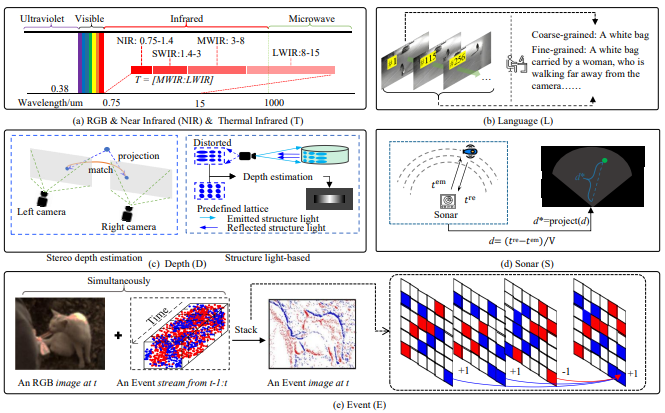
视觉模态不仅包括 RGB,还扩展到热红外(T)、深度(D)、事件相机(E)、近红外(NIR)、语言描述(L)、声呐(S)。
各模态具有物理互补性:例如红外能在夜晚保持清晰,事件相机对快速运动特别敏感,语言模态能提供高层语义信息。
论文首次系统比较了这些模态的物理特性及优势,为多模态融合提供理论基础。
在实际研究或应用中,如何快速调用多模态数据集和主流模型是一个难题。Coovally 平台内置了400+开源数据集,并集成了YOLO、DETR、Swin-Transformer等前沿模型,用户可以一键调用、训练与验证,大幅降低了入门与实验成本。

-
模态对齐与标注(Alignment & Annotation)
不同传感器的分辨率、采样频率和空间位置往往不同,如何对齐数据是核心挑战。
RGB+T、RGB+D、RGB+E 数据集需要进行严格的几何或时间对齐,而 RGB+L、RGB+S 则天然具备语义对齐特性。
在标注方面,大部分仍依赖人工的边框框选,但论文也指出了半自动标注与大语言模型生成描述的趋势。
-
多模态模型设计(Model Designing)
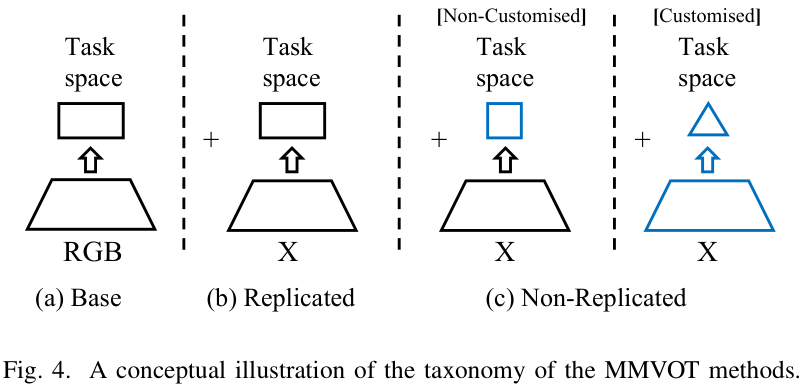
-
复制式配置:X分支(如红外/深度分支)直接复制RGB分支结构,常见于早期工作。
-
非复制式配置:为不同模态设计定制化结构,例如热红外分支引入温度交叉处理,事件相机分支借鉴类神经元的脉冲网络。
-
融合策略:从早期的像素级拼接,到特征级跨模态注意力,再到多层次的渐进式融合,方法越来越灵活。
-
现实考量:在效率、鲁棒性、跨任务统一模型(Unified Trackers)上,论文也进行了全景总结。
-
评测与基准(Evaluation & Benchmarking)
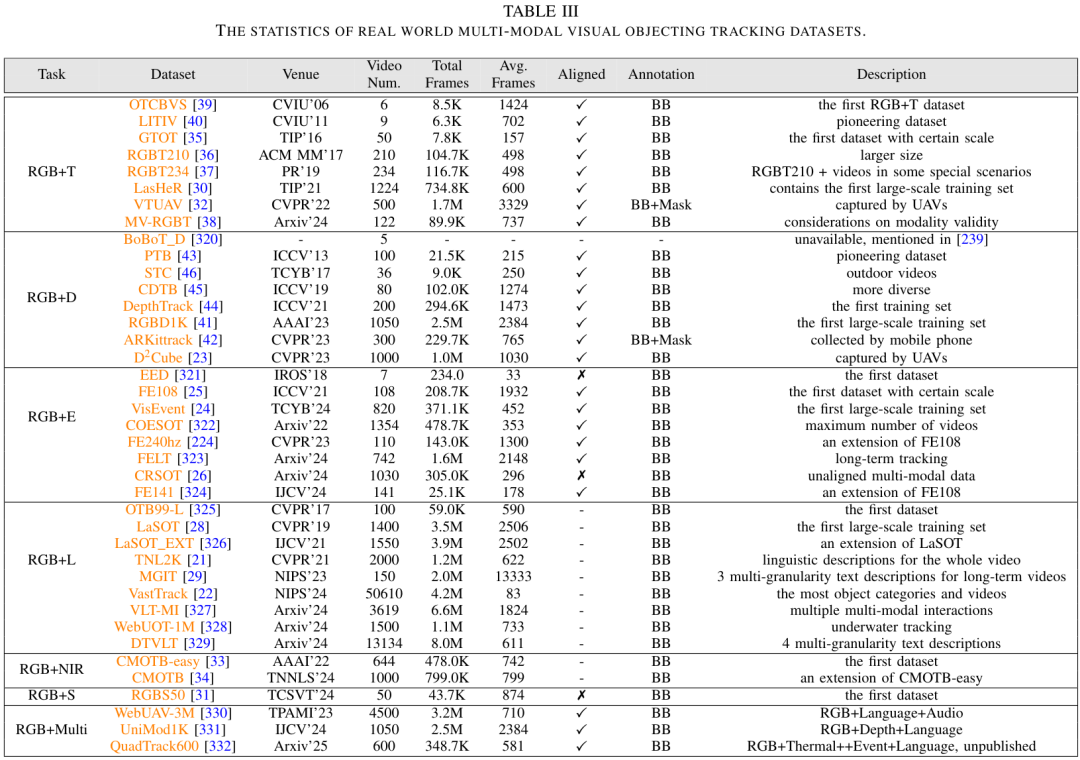
该研究收录并分析了338篇相关研究,覆盖六大类任务(RGB+T、RGB+D、RGB+E、RGB+L、RGB+NIR、RGB+S)。
提供了详细的数据集梳理:从最早的GTOT、PTB到近期的LasHeR、DepthTrack、VisEvent、TNL2K。
论文特别指出:现有数据集普遍存在 长尾分布 和 动物类缺失,这对泛化能力构成严重挑战。
在应用层面,如何快速复现这些研究、调用合适的数据与模型,同样是研究者和企业的痛点。Coovally 平台通过内置数据仓库与模型库,让用户能够即调即用,极大缩短了实验准备与验证的周期。
四、框架亮点:两个首次提出的问题
这篇全景式综述不仅总结了进展,还提出了两个前所未有的关键问题:
-
多模态融合是否总是更优?
常规思路认为多模态融合必然带来提升,但论文指出,当某一模态质量极差时(如夜间RGB图像严重噪声),盲目融合反而会拖累整体性能。
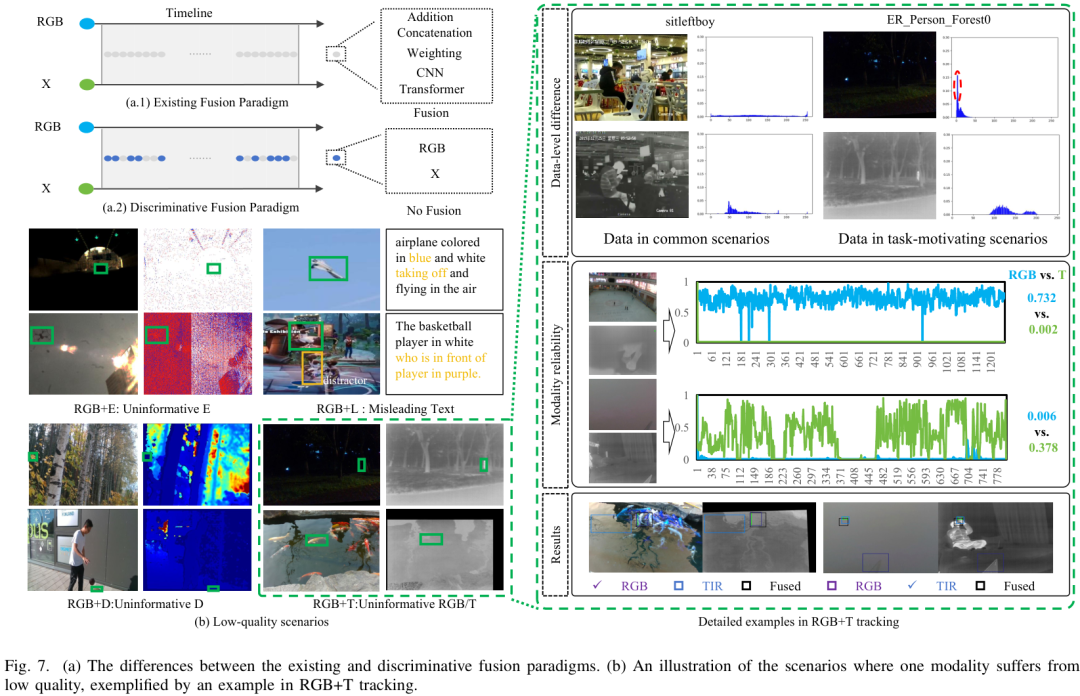
因此,选择性融合(Discriminative Fusion)比盲目融合更有前景。
-
数据分布的偏差
当前多模态数据集中,大部分目标类别集中在少数几类,形成严重的长尾分布。
特别是“动物类数据”的缺失,限制了多模态跟踪在生态监测、野生动物保护等实际应用中的推广。

五、未来发展方向
尽管多模态目标跟踪取得了长足进展,但论文也指出了几大挑战:
-
跨模态对齐问题:不同传感器的数据在时空分辨率上差异明显。
-
计算效率:多模态输入会显著增加模型复杂度,不利于实时应用。
-
标注成本高:构建大规模高质量的多模态数据集需要大量人力。
-
通用性与泛化性不足:现有方法在跨场景迁移时性能不稳定。
作者提出了几条值得关注的研究路线:
-
轻量化与实时跟踪:让多模态方法能部署在无人机、嵌入式等低算力设备上。
-
自监督与弱监督学习:减少对人工标注的依赖。
-
跨模态预训练与大模型结合:利用多模态大模型提升特征表示能力。
-
与下游任务融合:如多模态跟踪 + 行为识别、事件检测,提升应用价值。
总结
这篇综述论文系统梳理了多模态视觉目标跟踪的研究进展,从方法到数据集,再到挑战与未来趋势,都为后续研究提供了清晰的脉络。可以预见,随着多模态感知和大模型的快速发展,未来的目标跟踪将在更多实际场景中落地,助力智慧交通、公共安全、智能制造等领域。
Coovally平台也在探索多模态大模型在目标跟踪中的应用,未来,依托平台的持续更新,用户可以更方便地将学术前沿成果转化为实际生产力。
