Gemini 2.5 Flash-Lite与 DeepSeek-V3 深度对比:谁在性价比上更胜一筹?
面对琳琅满目的大模型API,开发团队如何摆脱选择困难症?一份基于客观数据的深度对比或许能为你指明方向。
对于广大AI应用开发者和技术决策者而言,2024年既是最好的时代,也是最困惑的时代。闭源大模型选择从未如此丰富,但性能与成本之间的权衡却变得愈发复杂。
一个看似性价比高的模型,可能在实际业务场景中因能力不足而导致重试率飙升;一个能力强大的模型,又可能因价格高昂而让创业公司望而却步。在这种两难困境下,精细化模型选型不再是可选项,而是必修课。
01 模型选型困境,开发者面临的双重挑战
当前技术团队在选择大模型时主要面临两大挑战:信息不对称和决策维度单一。
大多数开发者依赖模型厂商的宣传资料或社区碎片化的评测信息,缺乏一站式、客观中立的对比平台。同时,很多人过度关注模型参数规模或单一能力指标,忽视了成本、上下文长度、特定场景适配性等关键因素。
这种片面的选型方式往往导致实际应用中效果不及预期,或者项目预算快速超支。正是在这样的背景下,像AIbase模型选型对比平台(model.aibase.cn/compare)这样的工具显得尤为重要,它为开发者提供了数据驱动的决策依据。
02 核心性能对比,多维能力全面解析
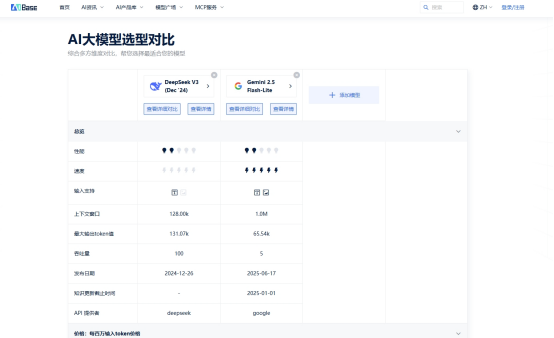
基于AIbase平台上的客观数据,我们对Gemini 2.5 Flash-Lite和DeepSeek-V3进行了全面对比。在核心能力方面,两个模型各有千秋。
Gemini 2.5 Flash-Litet在综合能力上表现均衡,特别是在多语言理解和通用推理任务上具有明显优势。其综合评分达到了较高水平,适合需要处理多样化任务的综合型应用场景。
DeepSeek-V3则展现出了在代码生成和逻辑推理方面的特长,在相关专项评测中得分领先。对于开发者工具、自动化编程助手等应用场景,这一优势尤为明显。
在数学能力方面,两个模型相差不大,都能较好地处理需要数值计算和公式推理的任务。这种能力分布差异直接影响着它们在不同应用场景中的适用性。
03 价格体系分析,实际成本一目了然
价格是模型选型的核心考量因素之一。我们对比了两个模型的官方定价方案,发现存在显著差异。
Gemini 2.5 Flash-Lite的定价策略相对高端,这种定价反映了其在综合能力上的优势定位。
DeepSeek-V3则采取了更加亲民的定价策略,相比前者有数量级上的优势。
为了直观展示这种差异,我们设计了一个典型应用场景:处理1000篇万字文档(约10亿token的输入处理量)。这种巨大的价格差异使得DeepSeek-V3在大规模应用和高频使用场景中具有压倒性的性价比优势。
04 上下文长度,128K的实际价值
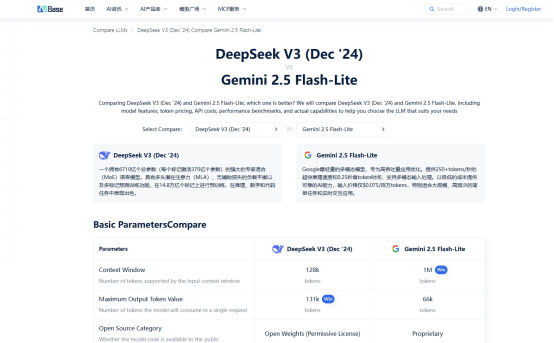
两个模型都支持128K超长上下文,这一能力在实际项目中具有重要价值。
超长上下文使得模型能够处理长文档摘要、代码库分析、学术论文解读等复杂任务。开发者可以将整个项目代码库或长篇报告一次性输入模型,获得更加连贯和准确的分析结果。
对于法律文档分析、技术代码审查、学术研究辅助等场景,128K上下文长度几乎成为了必备能力。它不仅提高了任务完成的效率,也显著提升了输出结果的质量和相关性。
在这方面,两个模型的能力相当,都能很好地支持长上下文应用场景。
05 特色与适用场景,如何选择?
基于以上对比数据,我们可以总结出两个模型的最佳适用场景:
Gemini 2.5 Flash-Litet更适合:需要强大多语言支持的国际业务;对通用推理能力要求较高的综合型AI应用;预算相对充足且更看重综合性能的项目。
DeepSeek-V3更适合:开发者工具和编程辅助应用;对成本敏感的大规模应用场景;需要处理长上下文但预算有限的项目;代码生成和逻辑推理密集型任务。
对于技术决策者来说,关键在于明确自己项目的首要需求:是追求极致的性价比,还是需要超长上下文支持,或是某项特定的能力优势。
06 理性选型,数据驱动决策
在实际的模型选型过程中,我们建议开发团队采用系统化的方法:
首先明确项目的核心需求和约束条件,包括性能要求、预算限制、技术栈兼容性等要素。然后基于客观数据进行比较分析,避免受主观偏好或市场宣传的影响。
AIbase模型选型对比平台提供了便捷的工具,允许开发者并排比较多个模型的各项参数和性能指标。这种数据驱动的选型方法能够显著提高决策质量,避免常见的选型误区。
最终决策应该基于实际测试验证,建议通过小规模试点项目评估模型在真实场景中的表现,包括效果、稳定性、延迟和综合成本等指标。
选择大模型没有标准答案,只有最适合的方案。Gemini 2.5 Flash-Lite和DeepSeek-V3各有其优势领域,关键是要匹配项目的具体需求。
如果你正在为AI模型选型而纠结,不妨访问AIbase模型选型对比平台(model.aibase.cn/compare),亲自对比这些模型的详细参数和性能数据。通过数据驱动的决策方式,找到最符合你项目需求和预算条件的那一个。
毕竟,在快速演变的大模型生态中,保持理性比较的能力比追逐任何一个特定模型都更加重要。只有基于客观数据和实际需求做出的选择,才能在技术和商业上都具有可持续性。