RAG拓展、变体、增强版(一)
概述
关于RAG的基础概念和知识,请参考RAG概述。
注:本文整理自ChatGPT和网络资料。
大部分公司已经实现的RAG系统,满足召回率95%+,准确率90%+,功能(FAQ、知识库、文档问答)够用;但是在学术界还是会出现各种不同的RAG变体(增强,拓展)版。
对这一现象的解读:
- 研究和论文驱动的“新颖性”
- 学术界(包括大厂的研究院)要发论文,就必须在现有方法上提出“改进”或“新颖点”。RAG本身就是一个很通用的范式,故而改进空间很多:
- 检索部分:向量化、rerank、多模态检索、多阶段检索;
- 增强部分:prompt engineering、fusion-in-decoder、知识融合;
- 生成部分:更好的上下文利用、长上下文建模;
- 训练部分:联合训练、端到端训练、对齐优化。
- 这些点每个都能写一篇论文→导致很多变体。对研究者来说,哪怕你的baseline工程系统“够用”,也不代表他们不能找到一个学术意义上的“可改进点”。
- 学术界(包括大厂的研究院)要发论文,就必须在现有方法上提出“改进”或“新颖点”。RAG本身就是一个很通用的范式,故而改进空间很多:
- 工程和产品驱动的“够用”
工程界的目标是“快速上线+可维护+成本可控”。大部分公司的RAG系统,已经能支撑业务需求。实际工程问题往往不是模型本身,而是:- 数据清洗(垃圾数据、格式化);
- 索引和存储(分片、更新、延迟);
- 多租户和权限;
- 监控和召回率评估;
- 成本和性能的权衡(如Embedding模型选多大,索引是Faiss还是Milvus)。
- 学术与产业之间的断层
- 研究问题vs工程问题:
- 学术界:关心理论上的最优解,比如“检索和生成联合训练能不能带来更好表现”。
- 工程界:关心能不能稳定上线,比如“索引1亿条文档还能不能200ms内返回”。
- 评估指标的差异:
- 学术界:喜欢用开放域QA基准,如NaturalQuestions、HotpotQA等。
- 工程界:只在乎“用户能不能快速拿到正确答案”。很多论文里提升的2~3%在真实场景里根本不重要。
- 资源差异:
- 学术界:有GPU、有论文产出压力。
- 创业公司:没GPU,靠现成的开源工具+小模型,也能跑得很快。
- 研究问题vs工程问题:
总结:工程上的RAG已经“足够好用”,但是研究上的RAG还没有“理论完美”。
- 就像搜索引擎:Google/Baidu的搜索系统早就能用,但学界仍然在研究更好的IR模型、query expansion、学习排序算法。
- 研究界的推动,让未来的系统在一些极端场景(超长上下文、多模态、低资源语言)可能会有质变。
- 工程界的推动,则是保证系统能活着、能赚钱。
Agentic RAG
现有RAG系统仍存在诸多限制:
- 上下文集成能力不足,缺乏对语义的深度理解,常生成片段化、逻辑不连贯的回答;
- 多步推理能力薄弱,难以动态调整检索与生成流程,难以应对复杂问题;
- 系统扩展性有限,在处理大规模数据和实时任务时常因检索延迟而形成瓶颈。
传统RAG大多采用一次性检索并生成答案的方式,灵活性不足,且多依赖单一知识源,难以整合多库或联网信息。模型对检索结果缺乏验证反馈机制,无论检索质量如何都直接用于生成,导致复杂查询或初次检索不到位时容易输出不完整甚至误导性答案。整体而言,传统RAG处于被动响应模式,难以支撑需要推理分解、多轮交互的任务,亟需架构层面的革新与智能化演进。
论文提出Agentic RAG,一种构建在智能体之上的RAG。智能体并非简单地调用检索工具,而是具备自主思考+工具使用+多轮推理的能力。
Agentic RAG:基于智能体的RAG;将智能体纳入RAG流程中,以协调其组件并执行超出简单信息检索和生成的额外行动,以克服非智能体流程的局限性。
智能体可被纳入RAG流程的不同阶段,最常用于检索组件中的智能体。检索组件通过使用具有访问不同检索工具的检索智能体而变得智能体化:
- 向量搜索引擎:查询引擎,在向量索引上执行向量搜索;
- 网络搜索
- 计算器
- 任何用于以编程方式访问软件的API
核心思想是在RAG的每个阶段引入智能体行为:
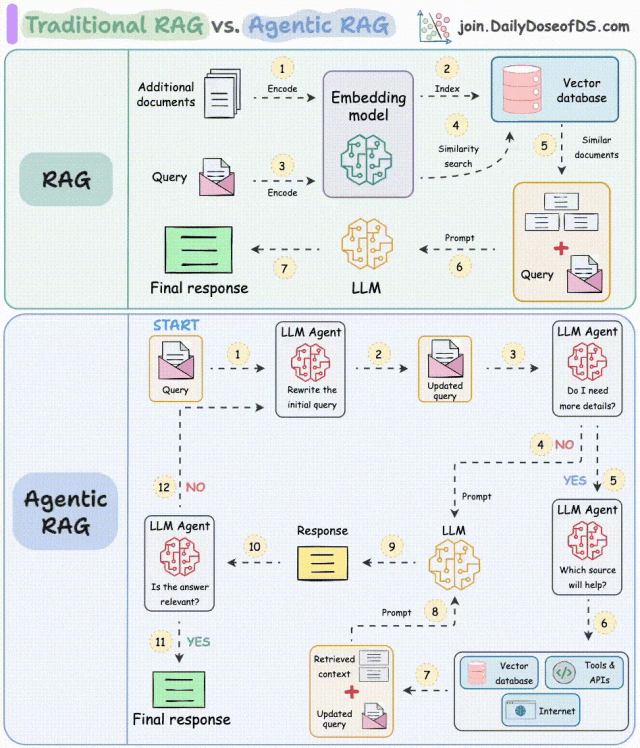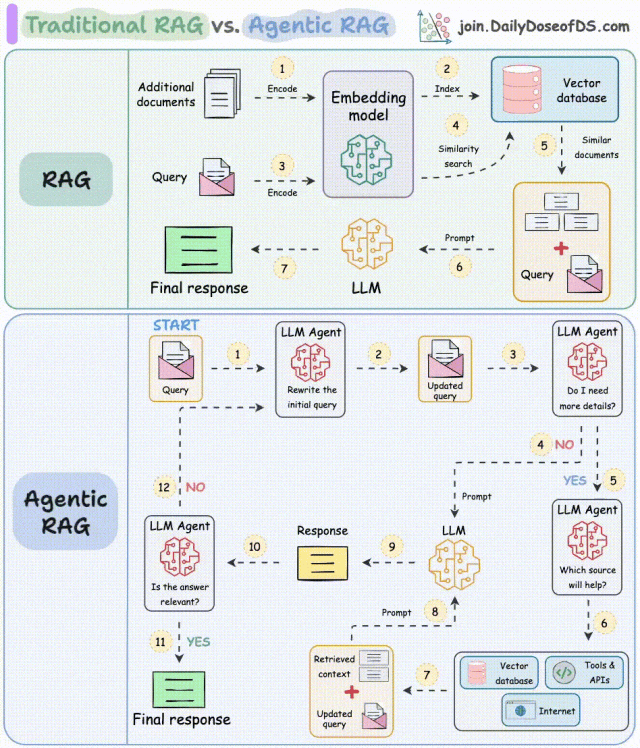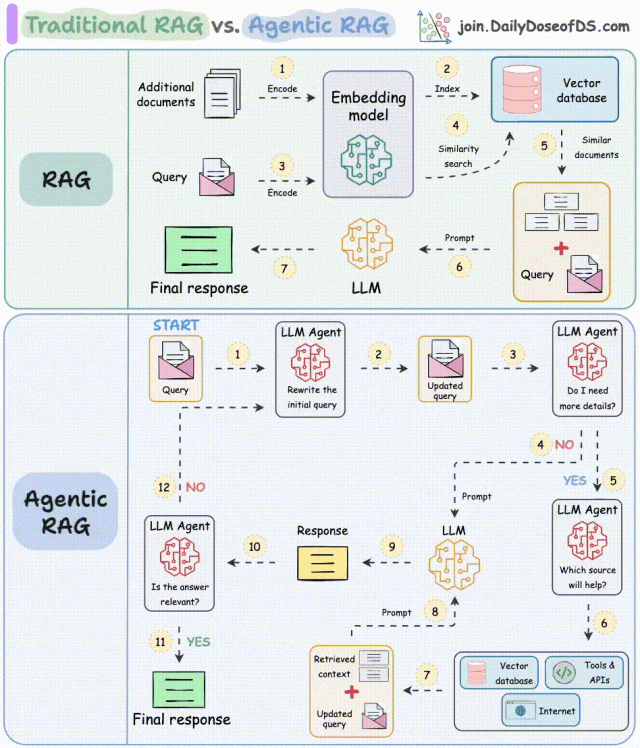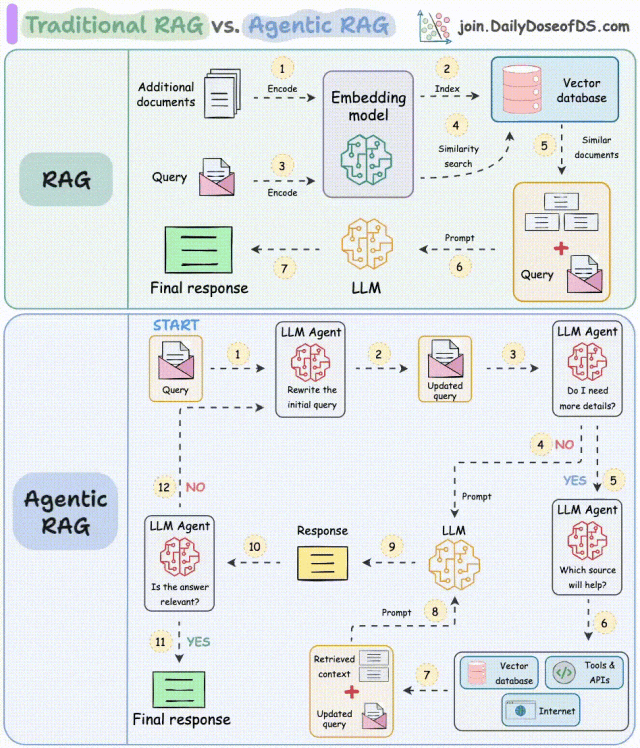
解读:
- 步骤1-2:Agent重写查询,修正拼写错误等;
- 步骤3-8:Agent判断是否需要更多上下文信息:
- 不需要,重写后的查询直接发送给LLM;
- 需要,寻找最佳外部来源获取上下文,并将其传递给LLM。
- 步骤9:系统获取响应;
- 步骤10-12:Agent检查答案是否相关:
- 相关则返回该响应;
- 不相关则返回到步骤1。
该过程会迭代数次,直到获取合适的响应,或系统承认无法回答查询。
核心组件包括:
- LLM本体:语言理解与生成的核心,相当于Agent大脑;
- 短/长时记忆:能保留对话上下文,并在需要时访问长期知识,如向量数据库;
- 规划与推理机制:基于CoT,智能体会主动规划任务、分步推理、策略纠错;
- 工具接口:可调用网络搜索、SQL查询、代码运行等外部能力,提升信息获取与处理范围。
- 工作机制:ReAct式思考-行动-观察循环
Agentic RAG遵循ReAct框架,即:思考→行动→观察→再思考。当接收到用户提问,Agent不直接回答,而是先判断下一步动作,例如是否需要查询定义?→然后执行该动作→观察结果→再判断下一步。通过多轮迭代,逐步构建答案。优势:
- 自主决策:智能体能根据任务复杂度灵活决定是否、何时、如何检索;
- 迭代优化:具备反思与纠错机制,可在生成过程中不断优化答案质量;
- 工具调用能力:能与外部API、数据库等交互,接入多源异构知识;
- 多智能体协作:复杂任务下可拆解为多个子任务,由不同Agent协同完成,提高系统效率与专业度。
Agentic RAG的关键突破在于,不仅让LLM接入知识,更让它学会获取、判断、整合知识。当传统RAG停留在一次性调用检索结果时,Agentic RAG已能自主规划任务路径,动态获取信息,并在多轮思考中完成高质量回答。
类型
随着任务复杂度与智能体能力的提升,Agentic RAG已从早期的单智能体方案,发展出六类具有代表性的系统架构,参考论文Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG。
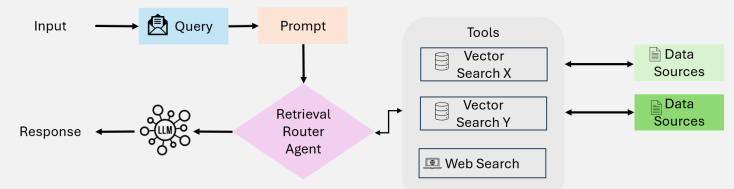
单智能体架构(Single-Agent RAG)
整个任务由一个智能体独立完成,包括检索、信息整合和答案生成等所有流程。可通过模块化链路进行任务分解,但执行逻辑保持单体化。在任务目标明确、信息结构稳定的应用场景中表现良好。
注:图来自上述论文。
典型使用场景包括FAQ、知识库、订单状态查询等。LangGraph即常采用这种方式来构建轻量级问答流程。整体流程集中在一个Agent中,调试与部署较为便捷,适合中小企业或初期系统搭建。
优点在于结构简单、维护成本低、响应速度快,但当面临多跳推理、非结构化信息融合或多模态输入等复杂需求时,能力表现有限。
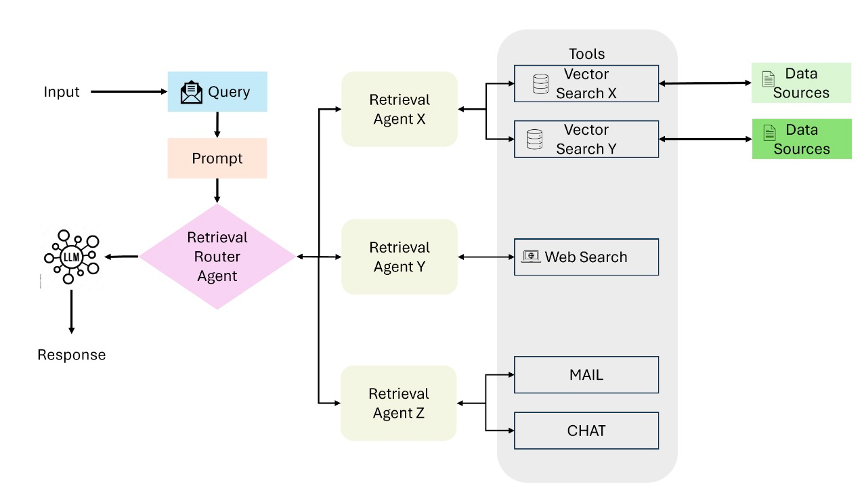
多智能体架构(Multi-Agent RAG)
不同智能体被分配执行特定的子任务,以实现模块解耦与功能分工。Retrieval Router Agent负责接收用户查询并协调多个检索智能体,每个智能体专注于不同的数据源或工具,如语义向量搜索、结构化数据库查询、网页检索或邮件系统等。支持多种查询类型的并行处理与扩展,使系统具备更强的可扩展性与任务适应能力。各智能体可独立优化、灵活替换,从而实现高效可控的多模态信息获取流程。
注:图来自上述论文。
适合任务链条较长、涉及多个知识领域的复杂系统。例如,AIstorian系统通过多个Agent合作生成历史人物传记,每个Agent分别处理历史检索、人物时间线整理和文本撰写等环节。
优势在于扩展性强,适配性好,但也带来Agent协同调度复杂、系统一致性管理难度增加等挑战。
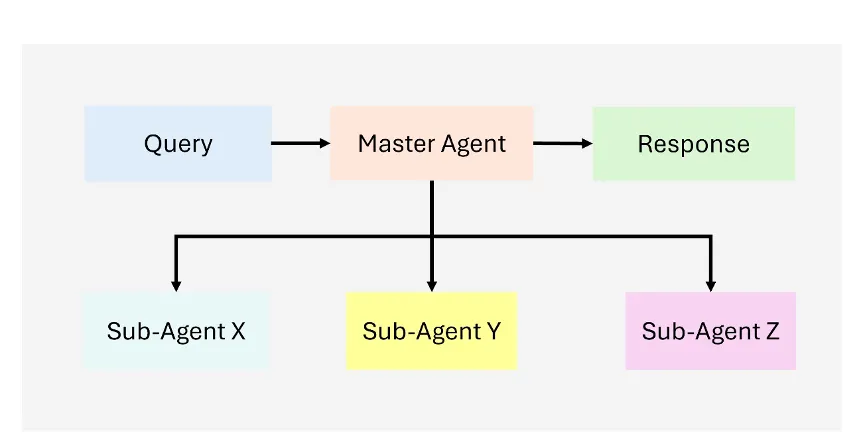
层级智能体架构(Hierarchical Agentic RAG)
相比扁平结构的多智能体系统,层级智能体架构引入一个或多个主控智能体(Manager Agent),负责动态规划任务执行流程与分派下层智能体,从而构建出更具组织性的执行体系。
注:图来自上述论文。
典型框架如HM-RAG,采用三层Agent架构:
- 任务分解Agent:将复杂问题拆解为若干子任务
- 检索Agent:负责多源异构数据获取
- 决策Agent:整合并判断信息质量,最终生成回答。
该结构尤其适合多模态问答、复杂逻辑判断和分布式知识整合等需求。
优势在于任务可控性强、系统具备策略层与执行层的区分,但缺点是设计与调试成本较高,对智能体能力与协调策略依赖更大。
纠错型Agentic RAG(Corrective Agentic RAG)
在标准RAG中,生成结果往往无法被反馈修正,容易出现事实幻觉或答案歧义。纠错型Agentic RAG在生成之后,额外引入一个或多个审查智能体,对生成结果进行验证、改写或提示重检索。
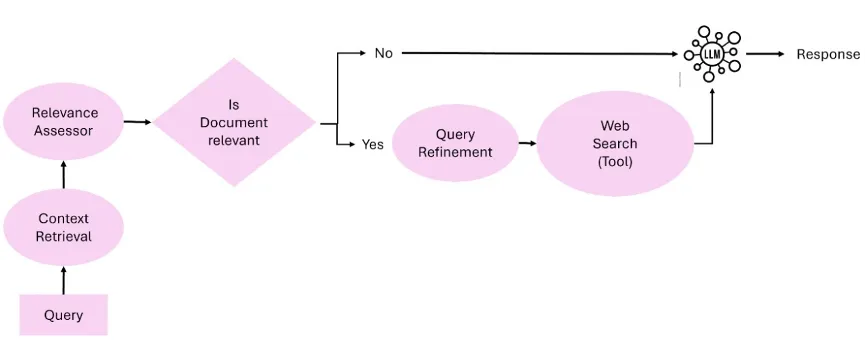
注:图来自上述论文。
如AIstorian系统中设置的事实检测Agent,专门用于捕捉历史错误信息并修正时间线。在医疗、法律、金融等高准确性领域,显著降低错误传播的风险。适用于提升系统稳定性和可解释性,其挑战在于设计出具备强通识验证能力的纠错模块,同时保证整体响应效率不被显著拉低。
自适应型Agentic RAG(Adaptive Agentic RAG)
自适应架构关注系统的任务感知能力,即智能体能够根据输入的复杂度、目标的模糊性、上下文的完整性等动态选择执行路径。这种动态规划机制可以在简单任务中调用快速路径,在复杂任务中自动延长思维链条。
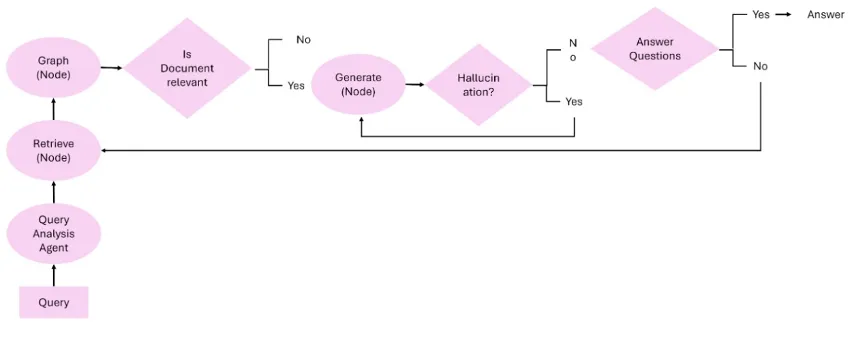
注:图来自上述论文。
LangGraph的Adaptive模块即体现此种思想:对于语义明确的问题直接生成答案;对于背景不全或任务多步的查询,自动扩展检索、插入验证、反复生成等路径。
此类架构体现Agentic系统的自治性,适合部署在面对高并发、查询种类多样的大规模应用中。其难点在于如何训练出具备“任务难度感知”能力的调度策略,避免不必要的计算资源浪费。
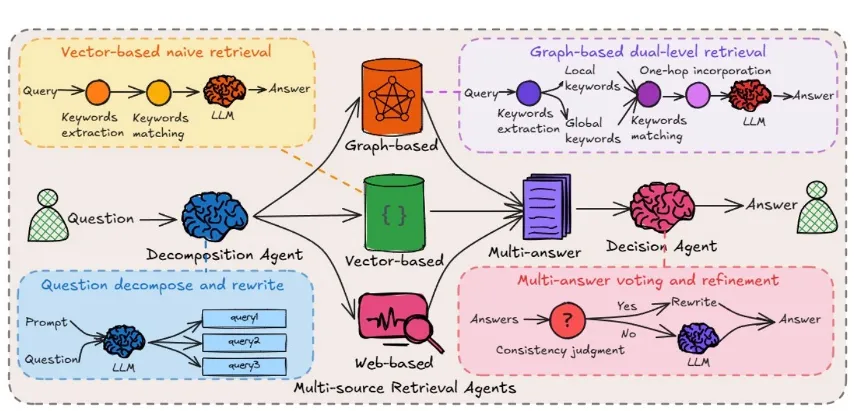
图增强Agentic RAG(Graph-Enhanced Agentic RAG)
图增强型架构融合知识图谱和非结构化文本信息,在语义关系建模、多跳推理和实体对齐任务中具备显著优势。不仅处理自然语言,还能通过图结构推理实体之间的逻辑依赖关系。
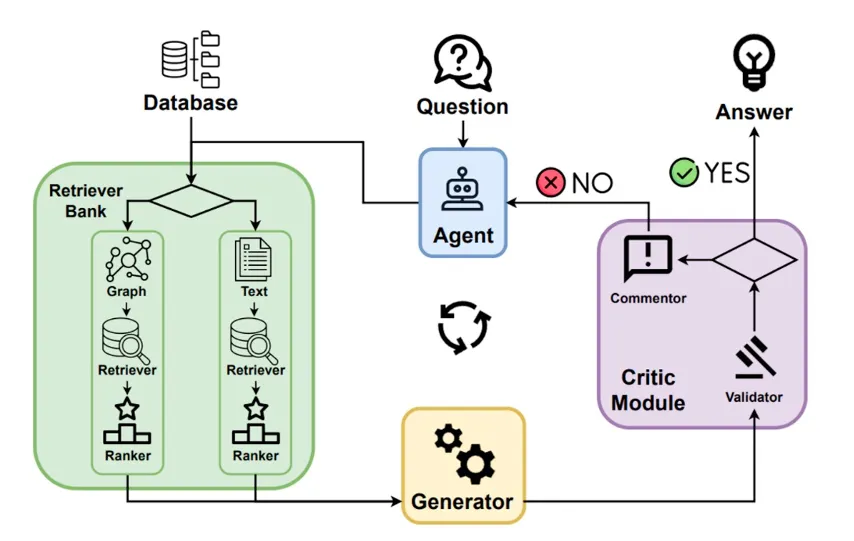
注:图来自上述论文。
以Agent-G为代表,该系统由三个核心模块构成:智能体解析用户意图并提取关键实体与关系;Retriever Bank同时从图谱与文档中检索证据;Critic Module则对生成结果进行质量评估,推动系统迭代优化。
另一代表性系统GeAR进一步扩展图结构在问答任务中的应用,支持跨模态、多跳链式检索。
图增强架构适合面向学术、法律推理等需要精准实体链与推理链的场景。但由于图谱构建门槛高、融合过程复杂,系统设计需具备较强工程与语义建模能力。
实现
构建智能体RAG流程的选择:
- 具有函数调用的LM:允许模型与预定义工具进行交互。LM提供商已将此功能添加到他们的客户端中。参考Function Calling;
- 智能体框架:参考Agent基础、MAS。
其他
未来演进路径
- 多模态能力融合:具备多模态感知与理解能力。可通过视觉模块看图说话,或从语音会议记录中检索信息,实现更自然和全面的交互体验;
- 跨语言智能协同:多语言理解与跨语言检索将成为Agentic RAG的基础能力。这对于构建全球化知识服务平台具有重要意义;
- 更强的自然语言理解与推理能力:借助下一代大模型的进展,Agent将具备更精准的意图识别、语境判断与问题分解能力。其行为将更加贴近人类思维,能主动规避冗余步骤、合理选择工具,输出也将更自然可信;
- 融合其它AI能力:加速与计算机视觉、语音识别、机器人控制等技术融合。未来的Agent不仅能读写听说,还将具备感知环境和执行操作的能力,实现从信息处理到现实行动的闭环。例如,它可一边调用数据库获取信息,一边通过摄像头感知现场,再控制机械臂完成任务,成为具备认知与执行双重能力的全能型智能体;
- 决策透明化与可信监管机制:随着Agent系统复杂度提升,其行为可解释性与可控性将成为关键议题。未来将涌现更多用于监控与解释Agent行为的工具框架,以及相应的伦理规范与法律政策,确保Agent在安全透明合规。
AUTO-RAG
论文,一个以LLM强大的决策能力为核心的自主迭代检索模型,通过多轮对话的方式建立LLM与检索者之间的交互模型,通过迭代推理确定何时检索信息、检索什么内容,在获得足够的外部知识后停止迭代,并将答案提供给用户。
GitHub提供Auto-RAG的GUI交互:提供可部署的用户交互界面,输入问题后,Auto-RAG会自动与检索器进行交互,无需人工干预。用户可以选择是否显示Auto-RAG与检索器交互的详细信息。
基于推理的迭代检索
- 迭代检索过程被概念化为LLM和检索器之间的多轮交互;
- Auto-RAG通过细致的推理来确定是否需要额外的检索以及需要寻找的具体信息;
- 一旦获取到足够的信息,Auto-RAG停止生成新查询并给出最终答案。
1.1 基于推理的规划和查询细化
- 为了提高效率和保持迭代过程中的连贯性,提出了包含三种不同类型推理的迭代检索:检索规划、信息提取和答案推断。
- 使用少样本提示来引导LLM进行这样的推理过程。
- 根据用户输入和之前的检索计划,LLM可以迭代地细化查询。
1.2 数据过滤和格式化
- 对生成的推理和查询进行过滤,以确保质量。
- 如果最终答案与数据集中提供的答案一致,则保留数据。
- 将迭代检索过程概念化为多轮交互对话,并对数据进行格式化
训练
- 采用标准的监督式微调策略,以使任意LLM具备在迭代检索中自主决策的能力。
- 计算每个实例的交叉熵损失,并进行优化。
推理
- 训练完成后,Auto-RAG能够自主地在迭代检索中做出基于推理的决策。
- 在每次迭代中,根据用户查询或检索到的文档提供输入,并提取Auto-RAG指定的后续步骤。
- 如果在与检索器交互T次后仍未终止,Auto-RAG会使用生成的查询来自动生成文档,并将其作为下一次迭代的输入。
- 如果在额外的T_PK次迭代后仍未终止,Auto-RAG会直接预测答案。
Auto-RAG在六个基准测试中的表现优于所有基线:FLARE、Self-RAG、Iter-RetGen、Standard RAG、IRCoT等。
案例对比:Self-RAG与Auto-RAG。Self-RAG只进行一次检索。Auto-RAG能够适应性地调整检索次数,从而获得更好的性能。
ChunkRAG
论文,旨在通过细粒度的过滤机制来提高RAG系统的精确性和事实准确性,分为两个主要阶段:语义分块和混合检索及高级过滤。
语义分块
ChunkRAG的基础步骤,将输入文档转换为语义上有意义的单元,以促进有效的检索和评估。包括三个子过程:
- 输入准备:
使用NLTK的sent_tokenize函数将文档D分词为句子。
每个句子使用预训练的嵌入模型(如text-embedding-3-small)生成嵌入向量。 - 分块形成:
根据语义相似性将连续句子分组为分块,通过余弦相似度测量。
如果连续句子之间的相似性低于阈值(θ=0.7),则创建一个新的分块。
每个分块进一步限制在500个字符以内,以确保在后续阶段的高效性。 - 分块嵌入生成:
每个分块使用与上述相同的预训练嵌入模型表示。
生成的分块嵌入存储在向量数据库中,以便在查询阶段进行高效检索。
混合检索和高级过滤
在检索和过滤阶段,ChunkRAG将传统的RAG组件与高级微调技术集成,以确保稳健和高质量的检索。包括以下步骤:
- 检索器初始化和查询重写:
初始化一个能够将用户查询与分块嵌入进行比较的检索器。
使用GPT-4omini应用查询重写步骤,确保查询与存储的嵌入良好匹配,从而提高检索过程中的召回率和精确度。 - 初始过滤:
使用TF-IDF评分和余弦相似度的组合对检索到的分块进行初始过滤。
消除高冗余(相似性>0.9)的分块。
剩余的分块根据其与重写查询的相似性进行排序。 - 相关性评分和阈值设定:
每个分块由大型语言模型(LLM)分配初始相关性评分。
这些评分通过自我反思和批评模型进行细化,根据领域特定的启发式调整评分。
通过分析评分分布设置最终动态阈值,只有超过该阈值的分块被保留。 - 混合检索策略:
采用结合BM25和基于LLM的检索方法的双重检索策略。
集成方法使用相等的权重(各0.5)来平衡关键词和语义检索。
使用Cohere的重新排序模型(rerank-englishv3.0)对检索到的分块进行排序,通过增强可能被优先级降低的中心上下文的相关性来解决“中间迷失”问题。
响应生成和评估
在过滤后,剩余的分块用作上下文来生成最终响应。步骤包括:
- 响应生成:基于过滤后的上下文分块,LLM生成响应;在生成过程中,严格约束确保仅使用检索到的信息,从而最小化幻觉风险。
- 评估:生成的响应根据一组预验证的答案进行准确性评估。
局限性包括:
- 分块分割的有效性:方法严重依赖于分块分割的有效性。初始分割中的错误可能会创建不相关数据,从而降低响应质量。分块的语义连贯性和大小限制(500个字符以内)可能不适用于所有类型的文档和查询。
- 嵌入质量:
用于分块相关性评估的嵌入质量直接影响过滤效果。低质量的嵌入可能导致不准确的相关性评分和错误的过滤决策。 - 计算成本:多层次评分(在初始级别集成LLM和批评LLM评估)的成本可能很高,特别是在将方法扩展到更大数据集或实时系统部署时。查询重写、多次检索和重新排序步骤增加了计算复杂性和时间开销。
- 可扩展性:尽管ChunkRAG在PopQA数据集上展示积极成果,但在其他领域中的可验证性和在长文本生成任务中的性能尚未得到充分分析,这是由于资源限制。方法在处理大规模数据集和复杂查询时的表现需要进一步验证。
- 动态阈值设定:动态阈值设定依赖于评分分布的分析,这可能受到数据分布和查询类型的影响。不稳定的评分分布可能导致不一致的阈值设定,影响过滤效果。
- 混合检索策略的平衡:混合检索策略中BM25和基于LLM的检索方法的权重分配(各0.5)是固定的,可能不适用于所有查询类型和数据集。需要进一步研究和优化以找到最佳平衡点。
- 生成过程中的约束:在生成过程中严格约束仅使用检索到的信息,虽然减少了幻觉风险,但也可能限制生成响应的创造性和多样性。
FastRAG
论文提出FastRAG,一种针对半结构化数据的新型RAG方法。采用模式学习和脚本学习来提取和结构化数据,而无需将整个数据源提交给LLM。将文本搜索与KG查询相结合,以提高在问答任务中检索上下文丰富信息的准确性。从评估结果来看,FastRAG在提供准确问答的同时,与GraphRAG相比,时间上提高90%,成本上提高85%。
FastRAG提出的动机和背景:
- 网络数据处理的复杂性和挑战
随着网络规模的扩大,网络数据的多样性和复杂性显著增加。网络管理任务需要高效处理和理解半结构化数据,如日志和配置文件。传统的网络数据处理工具虽然在一定程度上提供实用性,但在全面提取和利用嵌入在半结构化数据中的信息方面存在不足。从不同供应商关联这些数据由于网络服务的分散实现而变得更加复杂。 - RAG的局限性
现有的RAG方法在处理半结构化技术数据时存在的局限性:- VectorRAG:基于语义相似性从文本文档中提供上下文检索,但在处理网络数据的领域特定关键词时表现不佳,因为这些关键词在不同上下文中可能具有不同含义。
- GraphRAG:通过利用KG组织从源文档中提取的信息,但在提供有用答案方面存在不足,特别是在查询需要精确匹配的特定值(如名称或类型)时。
- HybridRAG:结合VectorRAG和GraphRAG的优势,提高响应的准确性和上下文相关性,但仍继承其基础方法的局限性。
- 处理时间和成本的挑战
现有RAG系统依赖LLM来提取结构化信息,通常需要将源文档分成小块并逐块处理,这导致处理时间和成本的增加。特别是在处理大规模和频繁变化的网络数据时,这种逐块处理的方法效率低下且成本高昂。 - 信息检索的准确性和效率
在网络管理中,准确和高效的信息检索至关重要。现有RAG方法在处理半结构化技术数据时,往往无法充分利用数据的隐含信息,导致检索效率低下和准确性不足。 - 模式和脚本学习的必要性
引入模式学习和脚本学习技术。通过模式学习,系统能够自动识别和结构化源数据中的实体类型及其属性,而无需将整个数据源提交给LLM。脚本学习则进一步生成解析函数,以高效提取和处理数据。 - 结合文本搜索和KG查询
将文本搜索与KG查询相结合,以提高在问答任务中检索上下文丰富信息的准确性。文本搜索基于精确的措辞或结构进行匹配,而KG查询则利用图数据库的结构化信息,两者结合可以更全面地回答复杂查询。 - 成本和时间的优化
通过生成JSON模式和Python进行数据结构化和解析,避免通过LLM处理所有源数据的昂贵过程。显著减少处理时间和成本,特别是在处理大规模和频繁变化的网络数据时。
架构
旨在高效处理和检索半结构化网络数据,通过结合模式学习、脚本学习和信息检索技术,优化数据处理和问答任务的效率和准确性
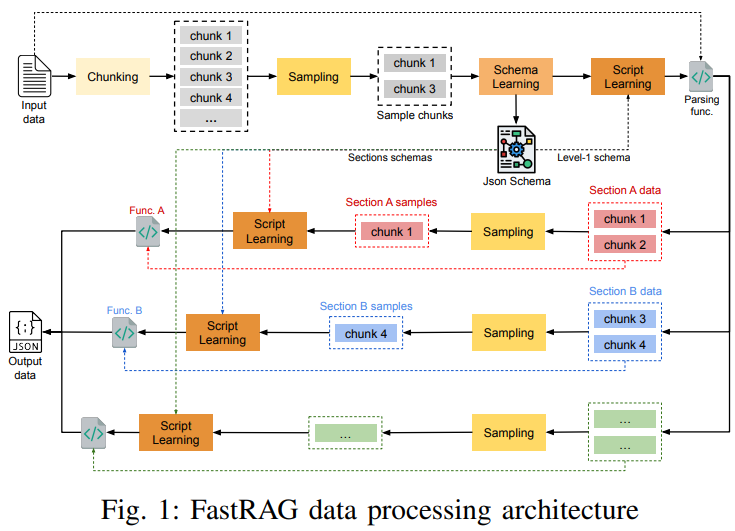
主要包括以下几个关键组件:
- Chunk Sampling:分块采样,选择代表性的数据块进行处理,以减少处理时间和成本;
- Schema Learning:模式学习,自动识别和结构化源数据中的实体类型及其属性;
- Script Learning:脚本学习,生成解析函数,以高效提取和处理数据;
- Information Retrieval:信息检索,结合文本搜索和知识图谱(KG)查询,提高问答任务的准确性。
分块采样
旨在选择代表性的数据块进行处理,以减少处理时间和成本。该过程涉及两个关键程序:关键词提取和块选择。
- 关键词提取从源数据中识别最有意义的术语。包括步骤:
- 文本预处理:去除标点符号并将内容标记化为单个单词;
- 行分割:将文本分成行,并根据单词频率创建矩阵表示;
- K-means聚类:根据术语频率模式的相似性将行分组为nc个簇;
- 关键词选择:在每个簇中选择最接近质心的nt个术语作为关键词。
- 样本选择算法选择包含提取关键词的完整集合的最小块集。包括步骤:
- 预处理:只保留提取的关键词。
- TF-IDF向量计算:计算每个块的术语频率-逆文档频率(TF-IDF)向量。
- 香农熵计算:计算每个块的香农熵以衡量其信息多样性。
- 迭代选择:迭代选择块子集以最大化术语覆盖率,直到达到所需的覆盖率阈值。
模式学习
旨在自动识别和结构化源数据中的实体类型及其属性。包括步骤:
- 模式提取
- 初始模式生成:从第一个样本块开始,LLM被提示识别并将实体类型和属性结构化为JSON模式;
- 迭代细化:通过提交新块给LLM,迭代地细化之前的JSON模式;
- 验证和修正:每次提示后,验证生成的JSON模式是否良构,如有错误则进行修正。
- 模式类型
从最终模式中提取两种类型的对象:- 步骤1模式:仅包括第1级实体类型(部分),每个实体类型包括描述和源数据行;
- 步骤2模式:每个部分与一个数组相关联,数组中的对象对应于该部分的完整模式。
脚本学习
旨在生成解析函数,以高效提取和处理数据。该过程包括以下步骤:
- 脚本生成
- 初始函数生成:从第一个样本块开始,LLM被提示生成解析函数;
- 迭代细化:通过提交新样本块给LLM,迭代地细化之前的函数代码;
- 验证和修正:每次提示后,验证生成的代码是否语法和功能正确,如有错误则进行修正。
- 独立处理
- 步骤1解析:将源数据中的每一行映射到其对应的部分,并将其分成固定大小的块
- 步骤2解析:为每个部分生成特定的解析函数,并使用相应的解析函数处理每个部分内的数据。
信息检索
最终组件,旨在结合文本搜索和KG查询,提高问答任务的准确性。该过程包括以下步骤:
- KG创建
- 实体插入:在JSON对象中识别的每个实体作为节点插入KG中,实体类型作为节点的标签;
- 属性分配:实体的简单类型属性直接分配为节点的属性,而本身是对象的属性则作为子节点插入;
- 输入数据节点:对于每个实体的input_data属性中的每一行,创建相应的节点并链接到父实体节点。
- 检索策略
定义并测试了几种检索策略以与KG交互:- KG查询(图):使用提示向LLM提供KG的模式,生成语法正确的GQL语句,执行并解释结果;
- 文本搜索(文本):使用提示向LLM提供文本搜索功能的示例,生成仅使用文本搜索功能的GQL语句,执行并解释结果;
- 组合查询(组合):为给定的输入查询并行执行KG查询和文本搜索提示,将结果提供给LLM合成最终答案;
- 混合查询(混合):结合KG查询和文本搜索的能力,生成可以利用两种方法中任何相关功能的GQL语句。
Graph RAG
一种基于图数据库的RAG技术,将传统的向量检索与图数据库的语义关系相结合,提供更精准的信息检索和生成能力。
核心特点
- 双重检索机制
- 向量检索:基于语义相似度
- 图检索:基于实体关系和知识图谱
- 知识图谱集成
- 利用图数据库存储实体关系
- 通过图遍历发现深层关联
- 多模态支持
- 支持文本、图像、结构化数据
- 统一的图表示框架
优势
- 检索更精准:结合语义相似度和关系推理,减少幻觉和错误信息
- 可解释性更强:图结构提供推理路径,便于理解AI决策过程
- 扩展性更强:支持复杂的关系查询,易于添加新的知识领域
技术挑战
- 构建成本高:需要构建和维护知识图谱
- 查询复杂度:图查询比向量查询更复杂
- 数据一致性:需要保持图数据和向量数据的一致性
发展趋势
- 自动化图谱构建:减少人工标注成本
- 实时更新机制:支持动态知识更新
- 多语言支持:跨语言的知识图谱
- 边缘计算集成:支持本地化部署
技术架构
用户查询→查询理解→双重检索→结果融合→生成回答↓向量检索 + 图检索↓知识图谱 + 向量数据库
对比与传统RAG
| 特性 | 传统RAG | Graph RAG |
|---|---|---|
| 检索方式 | 纯向量检索 | 向量+图检索 |
| 知识表示 | 文本片段 | 结构化图 |
| 推理能力 | 有限 | 强 |
| 可解释性 | 低 | 高 |
88页综述性论文GraphRAG,
研究难点:
- 图数据的多样性和异构性:图结构数据包含多种格式和领域特定的关系知识;
- 信息独立性与相互依赖性:传统RAG中信息是独立存储和使用的,而图RAG中的节点通过边相连,信息的相互依赖性增加设计复杂性;
- 领域不变性与领域特异性:不同领域的图结构数据具有不同的生成过程,难以设计一个统一的GraphRAG框架来适用于所有领域。
整体框架
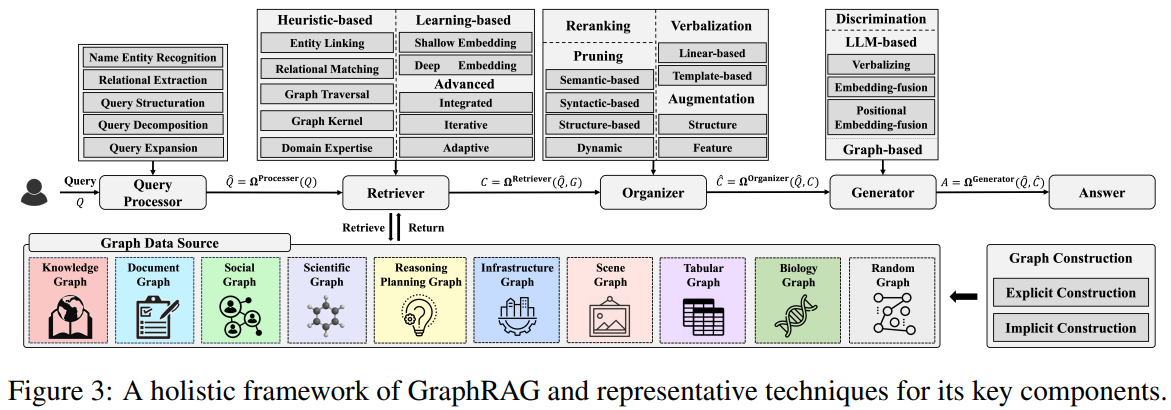
包含五个关键组件:
- 查询处理器:负责处理用户查询,提取实体和关系,并将查询结构化。主要技术包括:
- 实体识别:从查询中识别出文本中的实体;
- 关系提取:从查询中提取实体之间的关系;
- 查询结构化:将提取的实体和关系组织成结构化的查询,以便后续的检索和处理;
- 查询分解:将复杂查询分解为多个子查询,分别进行处理,最后再综合结果;
- 查询扩展:基于语义相似性或其他规则扩展查询,以覆盖更多相关信息。
- 检索器:根据处理后的查询从图数据源中检索相关内容。检索器可以是基于启发式的方法、基于学习的方法或领域特定的方法。
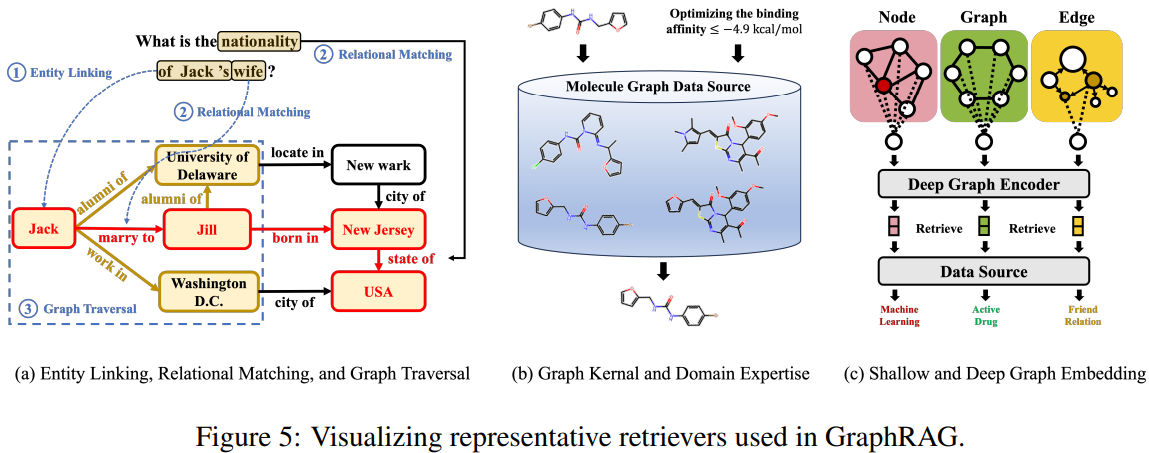
主要有三种类型:- 基于启发式的检索器:使用预定义的规则、领域特定的知识和硬编码的算法来提取相关信息。其优势在于高效且资源消耗较少,特别适用于规则明确且变化不大的场景。例如,基于BFS或DFS的图遍历方法可以在常数时间内执行,且不需要训练数据。
- 基于学习的检索器:通过机器学习模型(如神经网络)来捕捉图结构数据中的模式和关系。其优势在于能够处理复杂的查询和大规模数据集,但需要大量的训练数据和计算资源。例如,使用图神经网络(GNNs)进行节点和边的嵌入表示,可实现高效的图检索。
- 领域特定的检索器:针对特定领域的图结构数据进行优化,利用领域专家知识和特定领域的特征来提高检索效果。其优势在于能够充分利用领域特性,提高检索的准确性和效率。例如,在药物发现领域,可利用已知的药物结构和性质来提高分子检索的准确性。
- 组织者:对检索到的内容进行组织和精炼,以便更好地适应生成器的输入。主要技术包括:
- 图剪枝:去除检索到的图中的冗余和无关节点和边,减少噪声,提高生成内容的质量;
- 重排:对检索到的内容进行重新排序,优先处理与查询最相关的部分,以提高生成内容的连贯性和相关性;
- 图增强:向检索到的图中添加额外的信息,如节点特征、边权重等,以丰富检索内容的多样性,提高生成结果的鲁棒性;
- 文本化:将图结构数据转换为自然语言文本,以便生成器能够直接处理。常用方法包括线性文本化和模型基础的文本化。
- 生成器:基于查询和检索到的信息生成最终答案。生成器可以是基于判别的方法、基于LLM的方法或基于图的方法。
- 图数据源:
不足与反思
- 图谱构建:如何构建图谱、图的格式选择以及多模态图的构建是挑战之一;
- 检索器:区分神经知识和符号知识、内部和外部知识的协调、检索内容的准确性、多样性和新颖性的平衡、推理和规划的动态更新是主要挑战;
- 组织者:在保持信息完整性和简洁性之间的平衡、最优的数据结构化、不同资源的对齐、数据增强是主要挑战;
- 生成器:提示的正确格式、结构编码的集成是主要挑战;
- GraphRAG系统:组件之间的无缝集成、可扩展性、可靠性、鲁棒性、隐私、可解释性是主要挑战;
- 评估:组件级别的最优性、端到端基准、任务和领域特定的评估、可信度基准是主要挑战;
- 新应用:扩展到其他领域(如代码生成和网络安全防御)面临独特的挑战,需要理解特定领域的要求和数据结构。
HtmlRAG
网络是RAG一个非常重要的外部知识来源,传统的RAG系统将网页的HTML内容转换为纯文本后输入LLM,这会导致结构和语义信息的丢失。
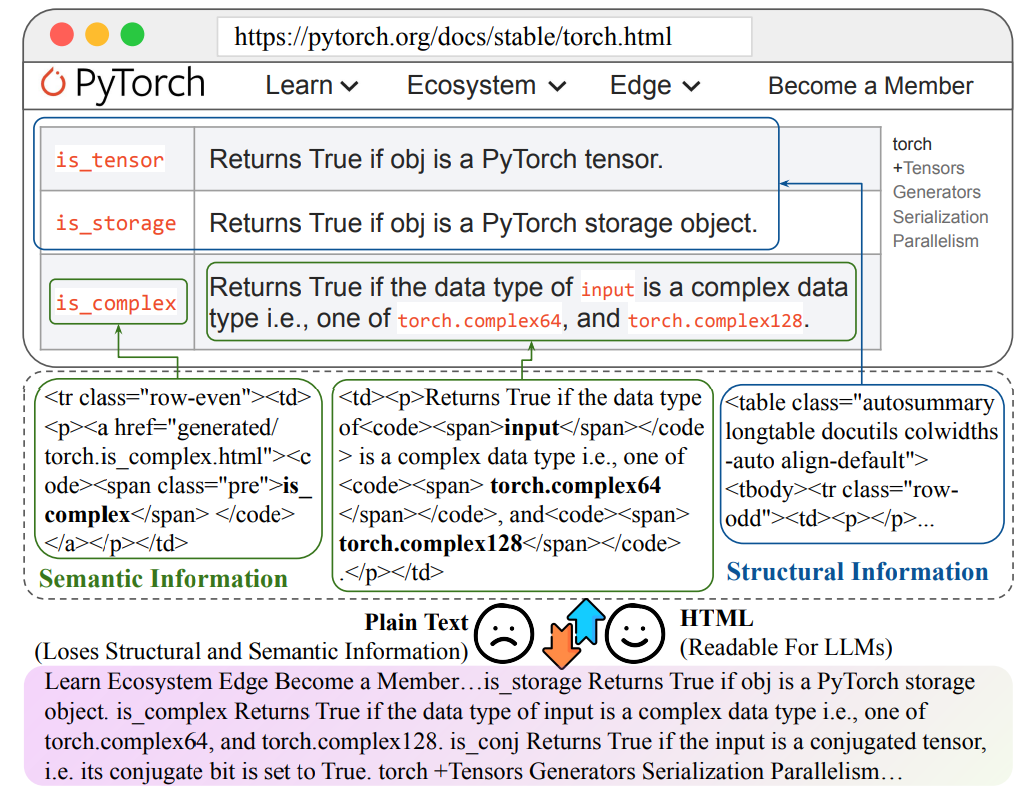
论文提出HtmlRAG,GitHub,使用HTML而不是纯文本作为RAG系统中外部知识的格式。为了应对HTML带来的长上下文,提出:
- 无损HTML清理:仅移除完全不相关内容,并压缩冗余结构,保留原始HTML中的所有语义信息。无损HTML清理压缩后的HTML适用于具有长上下文LLMs的RAG系统,并且不愿意在生成之前丢失任何信息。
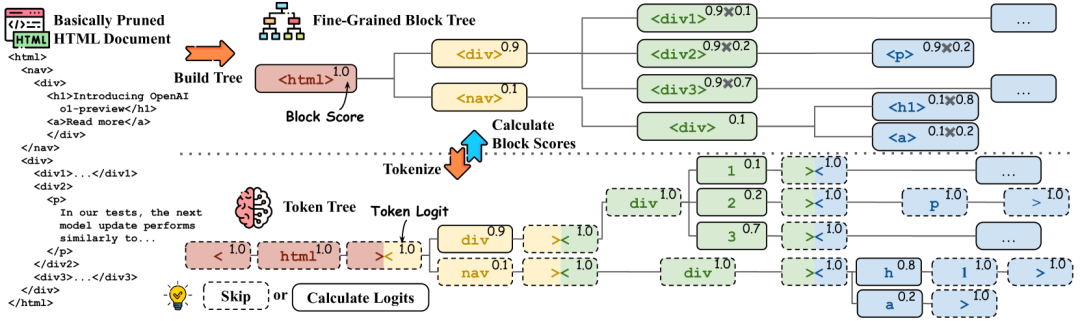
- 基于块树的两步HTML修剪:Two-Step Block-Tree-Based,两个步骤都在块树结构上进行。第一步修剪使用嵌入模型为块计算分数,而第二步使用路径生成模型。第一步处理无损HTML清理的结果,而第二步处理第一步修剪的结果。
HtmlRAG总体概述
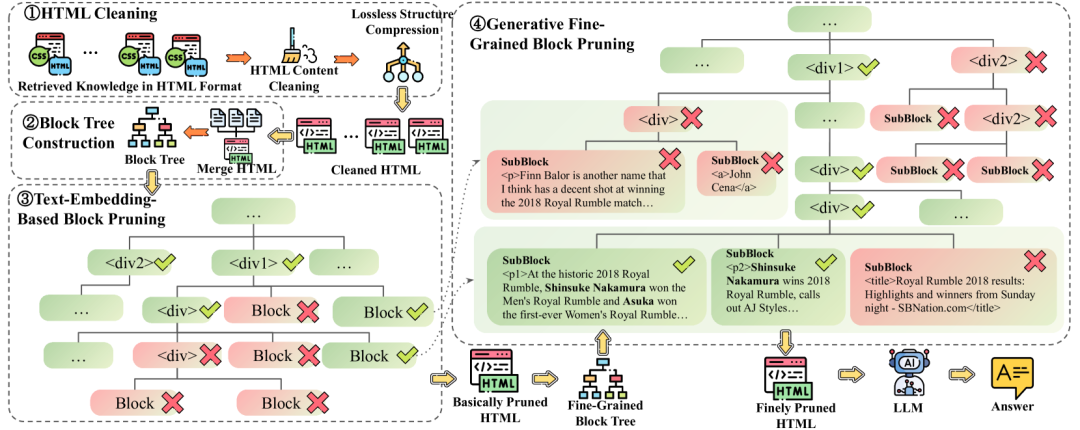
块分数计算。块树通过分词器转换为令牌树,相应的HTML标签和令牌用相同颜色标记。令牌生成概率在右上角显示,虚线框中的令牌不需要推理。在块树的右上角,显示了块概率,概率可以从相应的令牌概率中推导出来
生成模型Prompt
Input:
**HTML**: "{HTML}
**Question**: **{Question}**
Your task is to identify the most relevant text piece to the given question in the HTML document.
This text piece could either be a direct paraphrase to the fact, or a supporting evidence that can be used to infer the fact.
The overall length of the text piece should be more than 20 words and less than 300 words.
You should provide the path to the text piece in the HTML document.
An example for the output is: <html1><body><div2><p>Some
key information...
Output:
<html1><body><div2><p>At the historic 2018 Royal Rumble,
Shinsuke Nakamura won the Men’s Royal Rumble. . .
在六个不同的问答数据集上进行实验,包括模糊问答、自然问答、多跳问答和长形式问答,HtmlRAG在所有数据集上的表现均优于或等于现有的基于纯文本的后检索处理方法:BM25、BGE、E5-Mistral、LongLLMLingua、JinaAI Reader。
参考
- GraphRAG 2025年最新调研综述