Spring AI RAG 检索增强 应用
1.RAG概念
1.什么是RAG
首先我们先理清楚什么是RAG(检索增强) 是一种信息检索技术结合AI进行内容生成的混合架构,可以有效解决大模型产生幻觉
简单说,当我们向大模型进行提问时,大模型可以从数据库中拿到相关性比较强的数据来进行结合回答,比如我们想要知道某个商品的某些详细数据,大模型不知道这些参数,就可以结合数据库中已经存在的数据进行结合回答。
2.RAG的作用
RAG技术的出现能够使得大模型问题会更加精确
1. 知识实时性增强
通过RAG改造后的大模型可以通过更新RAG的知识库来使得大模型能学习新的知识,例如回答“2023年世界杯冠军是谁?”时,RAG可直接检索最新结果,而非依赖训练数据(可能截止到更早时间)。
2. 减少幻觉(Hallucination)
基于事实生成:传统生成模型可能编造不存在的信息(如虚假数据、事件)。RAG通过检索真实来源提供依据,生成内容更可信
3. 处理长尾/专业领域问题
弥补训练数据不足:大模型在冷门或专业领域(如医学、法律)可能表现不佳。RAG通过检索领域特定知识库(如论文、法规),生成更专业的回答。
2.Spring AI RAG应用开发
2.1 基于阿里百联的向量数据库
2.1.1创建知识库
在百练平台创建一个知识库
知识库名称 是我们后续所需要写到代码中的
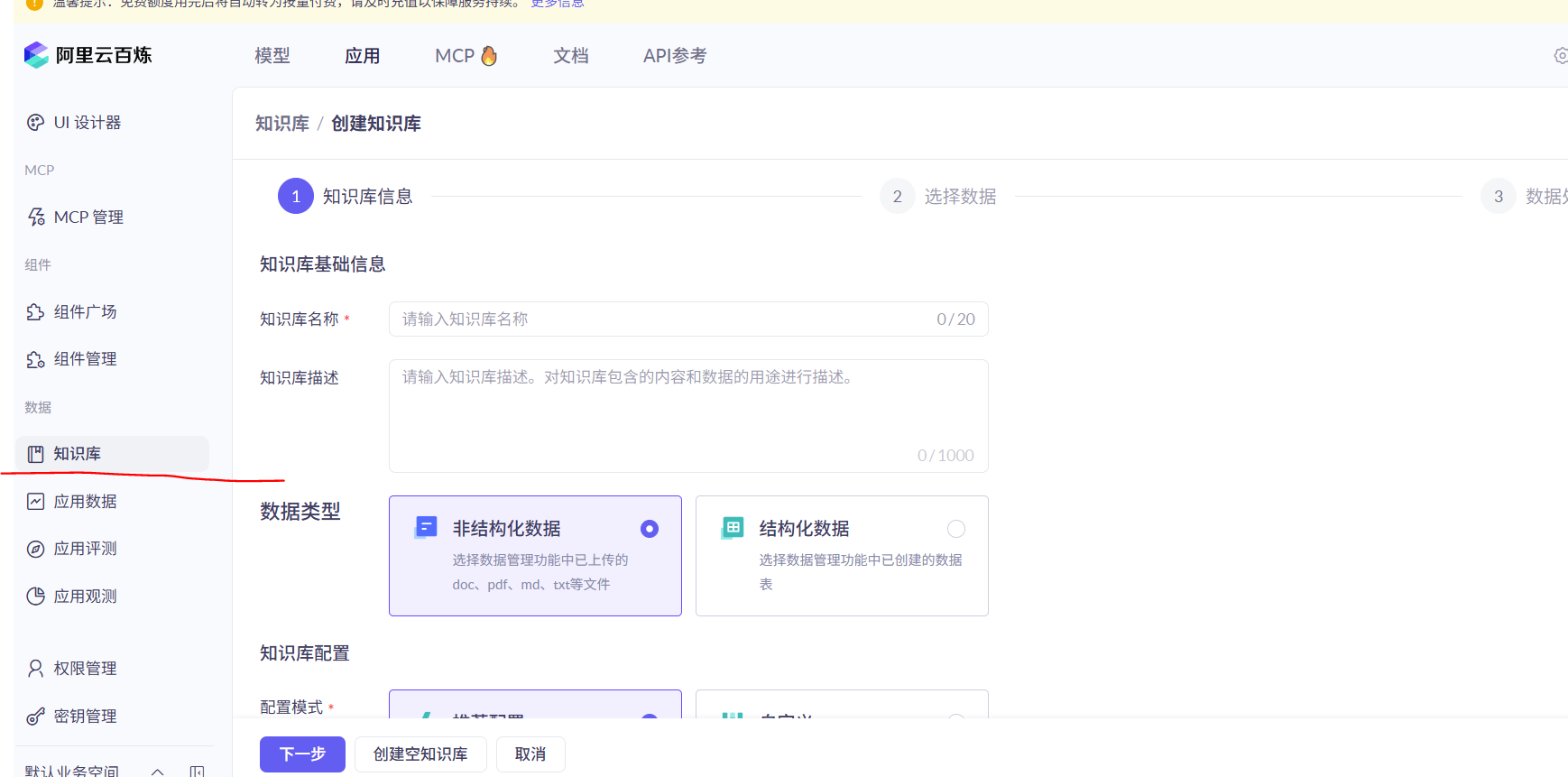
创建知识库前如果我们并没有添加任何文件内容,则需要先进入下一步时
点击数据中心添加数据
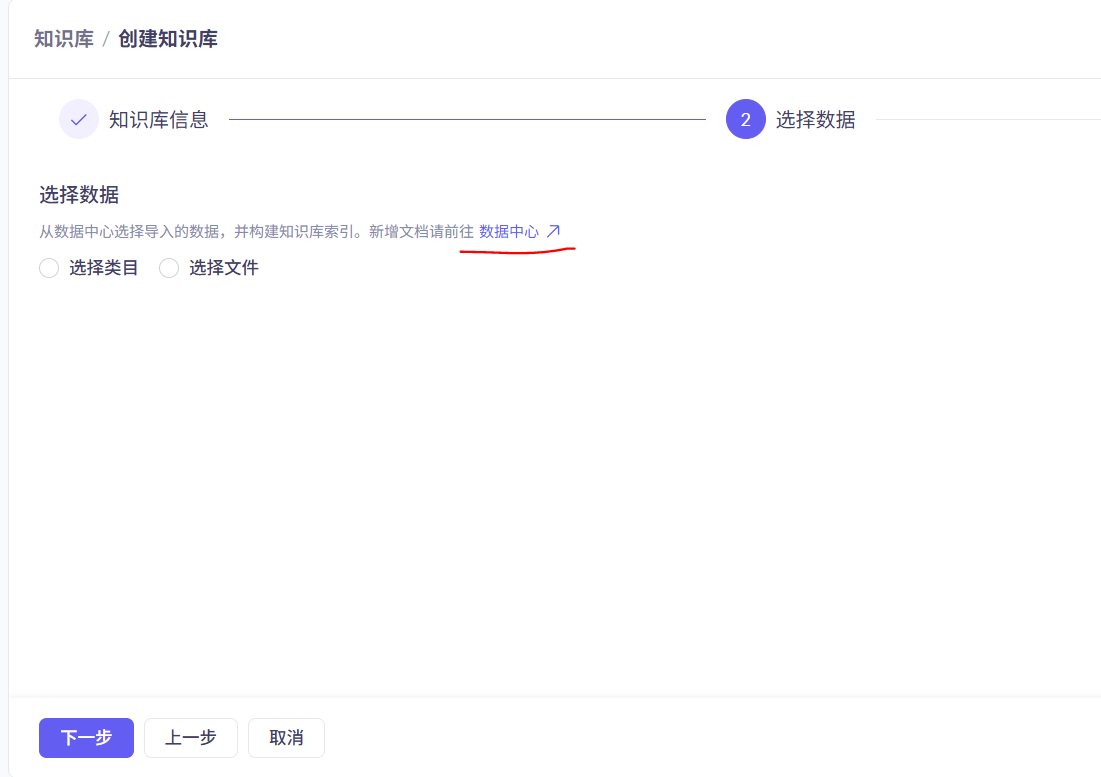
先添加类目
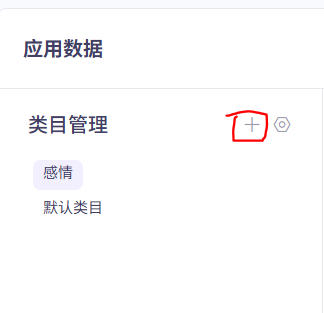
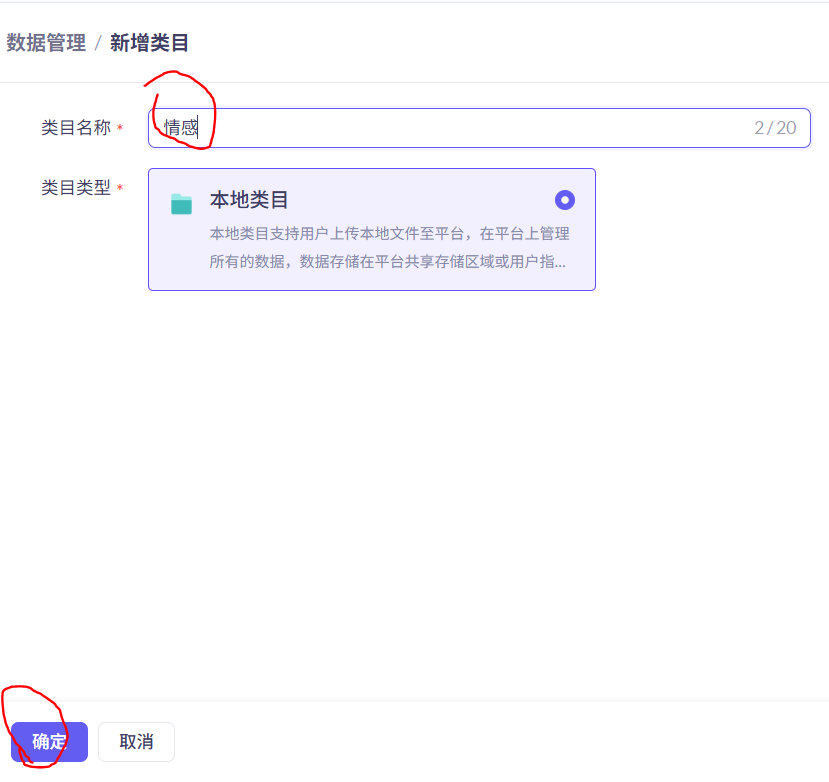
然后往该目录中倒入数据
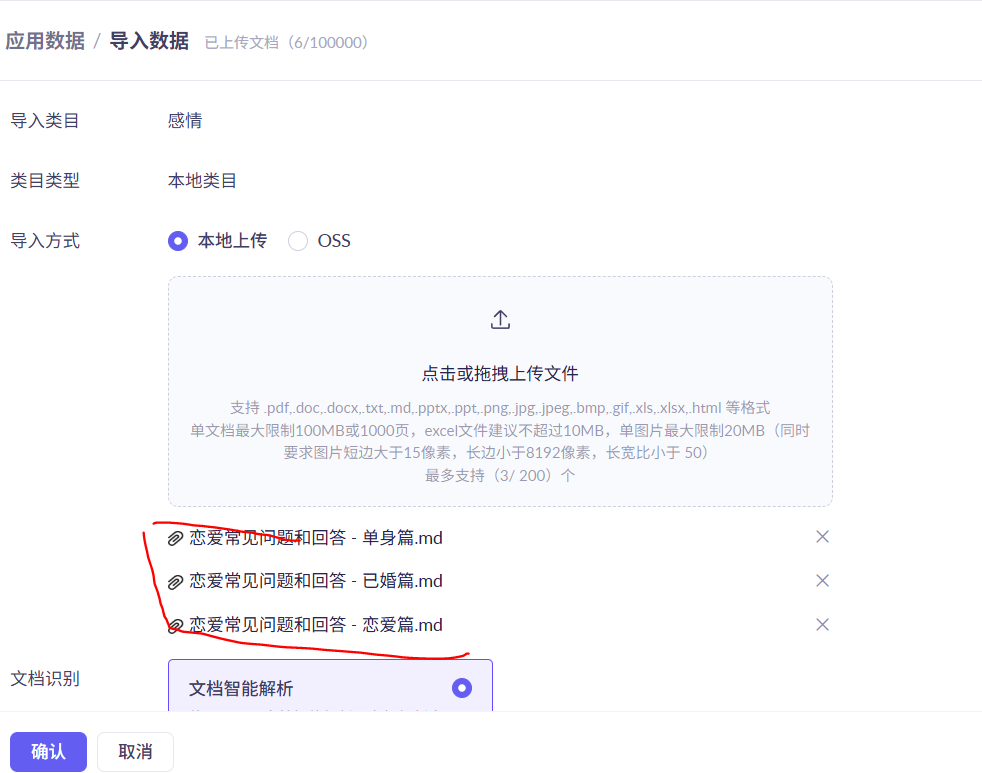
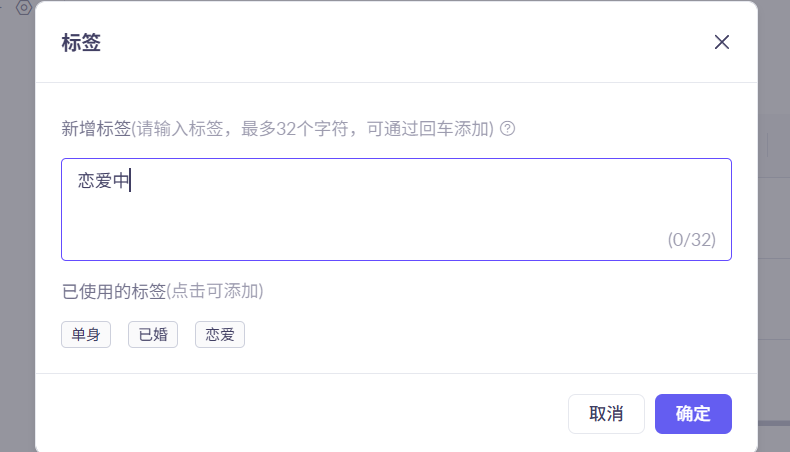
上传完成后可以对对应的文档进行打标签
这样能更精准的召回所需要的内容
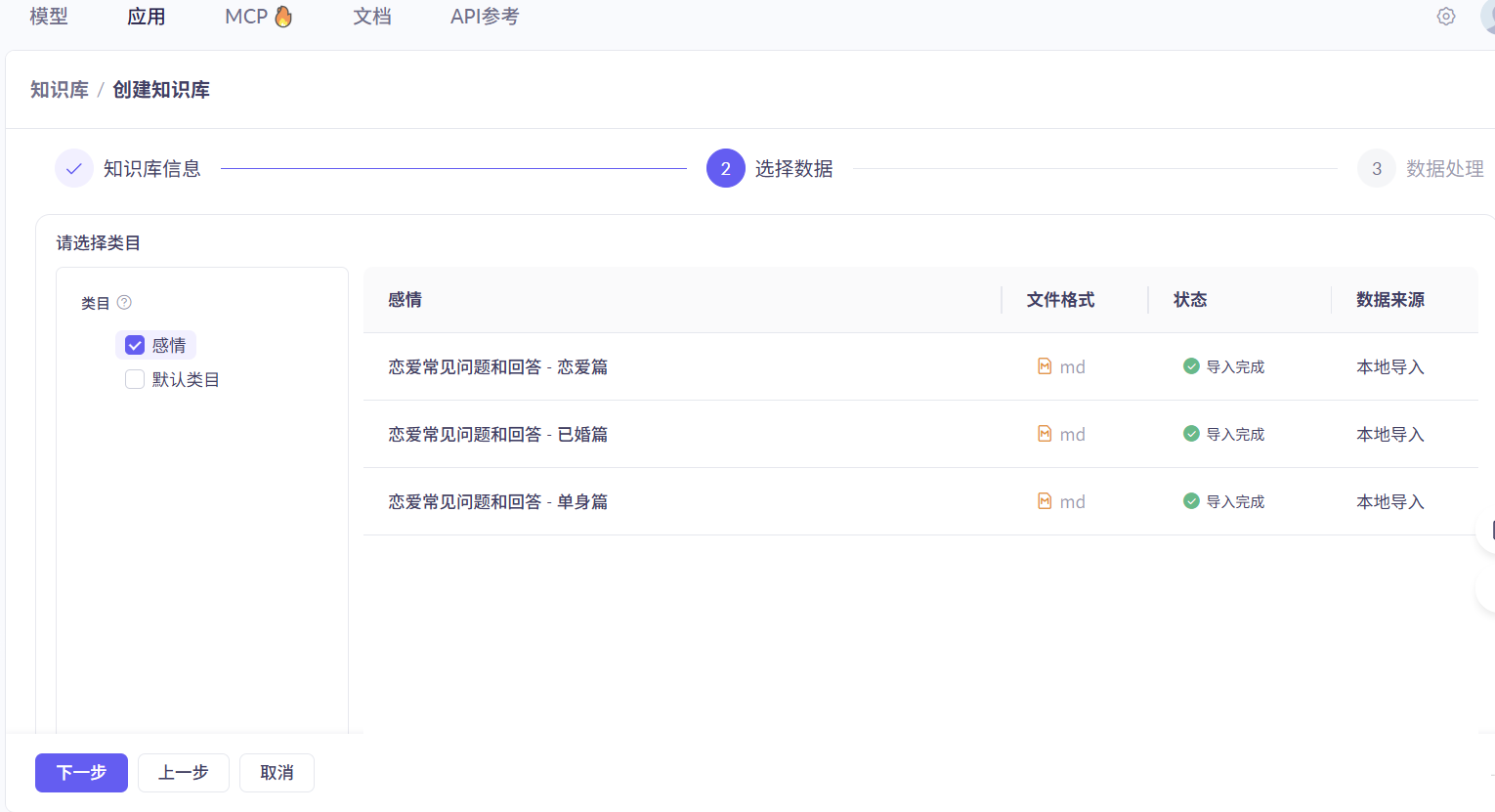
此时回到创建知识库
选择对应的泪目
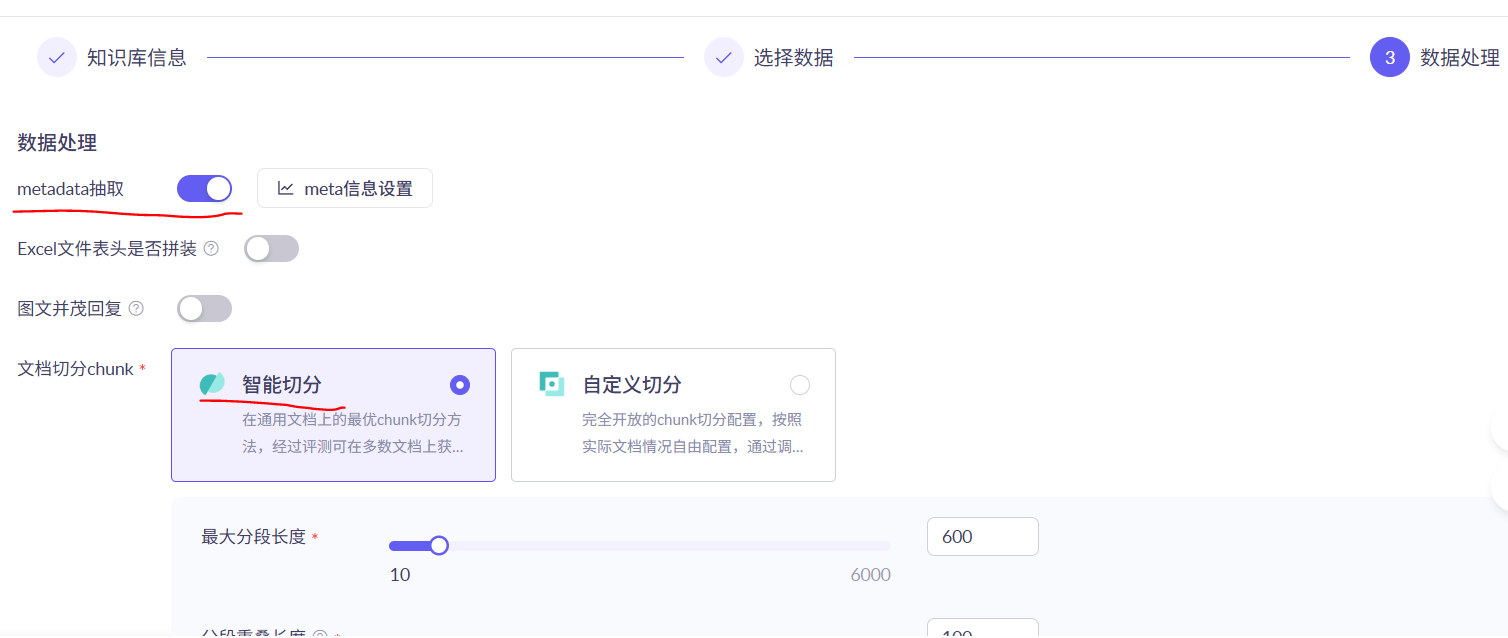
metaData抽取一定要现在开启,不然创建后就不能开启了
选择智能切分,会调用ai大模型进行文档的切割,最大长度是指切分后的文章大小,重叠程度就可以强化上下文的联系
创建完成后我们就可以测试命中率

可以测试我们的输入,所能召回的被切割文档有哪些

2.1.2 Spring AI 结合 云知识库
package com.xiaog.aiapp.RAG;import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.rag.DashScopeDocumentCloudReader;
import com.alibaba.cloud.ai.dashscope.rag.DashScopeDocumentRetriever;
import com.alibaba.cloud.ai.dashscope.rag.DashScopeDocumentRetrieverOptions;
import org.springframework.ai.chat.client.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.retrieval.search.DocumentRetriever;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** 基于阿里百联平台自己搭建的知识库*/@Configuration
public class LoveAppRagCloudAdvisorConfig{@Value("${spring.ai.dashscope.api-key}")private String apiKey;@Beanpublic Advisor loveAppRagCloudAdvisor() {DashScopeApi dashScopeApi = new DashScopeApi(apiKey);// 初始化基于阿里百联的向量数据库DocumentRetriever documentRetriever = new DashScopeDocumentRetriever(dashScopeApi, DashScopeDocumentRetrieverOptions.builder().withIndexName("小G的知识库") //知识库的名称.build());//构建检索增强return RetrievalAugmentationAdvisor.builder().documentRetriever(documentRetriever).build();}}
//注入Advisor@Resourceprivate Advisor loveAppRagCloudAdvisor;/*** 基于云知识库 的对话*/public void dochatRag(String message , String sessionId){ChatResponse chatResponse = chatClient.prompt().user(message).user(message).advisors(advisorSpec -> advisorSpec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId) //根据会话id获取对话历史.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))//获取历史消息的条数.advisors(loveAppRagCloudAdvisor).call().chatResponse();System.out.println(chatResponse.getResult().getOutput().getText());}
测试
@Testvoid dochatRag() {app.dochatRag("小明现在是单身,想在网上交友谈恋爱,请给他一点建议,精简总结一下", "1");}输出:
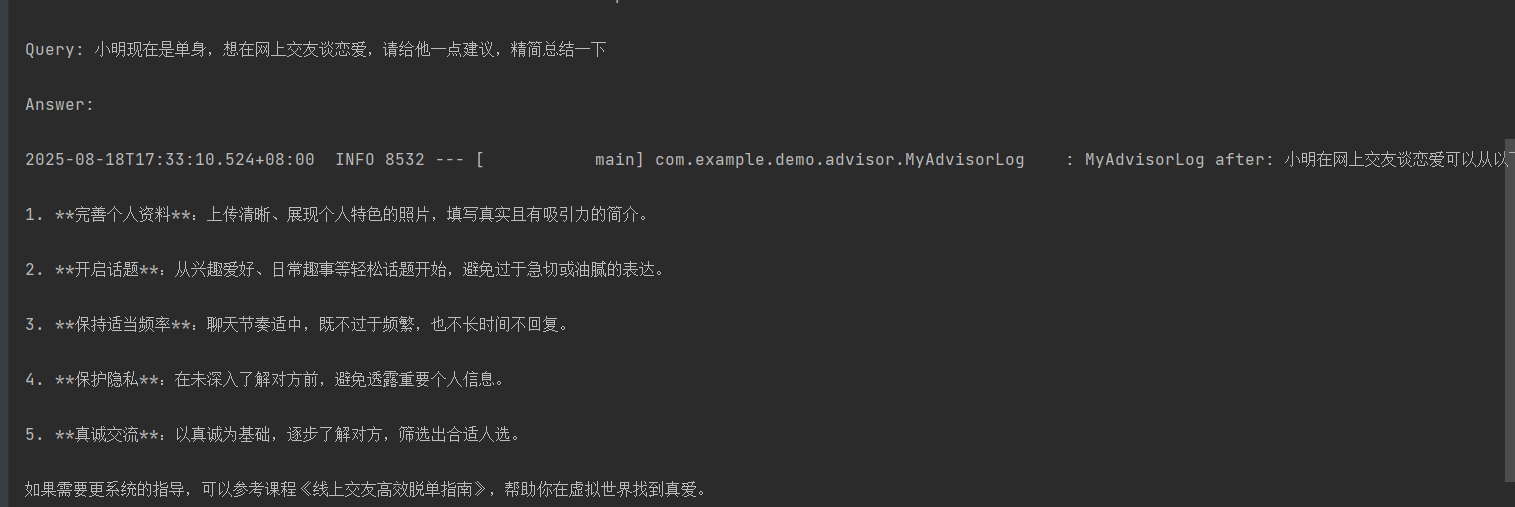
被召回的分片,通过自定义Advisor捕捉 到被一同传入
内容:

2.2 基于本地内存向量数据库
2.2.1 读取文档
创建一个读取文档的类,并且写一个读取文档的方法
我们此次所读取的文档是Markdown文档,所以编写一个读取markdown文档的方法
需要引入读取Markdown的依赖
<!--spring AI Markdown 文件读取--> <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId><version>1.0.0-M6</version> </dependency>
编写读取的类和方法
package com.example.demo.RAG;import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;@Component
@Slf4j
public class LoveAppDocumentLoader {//文件解析private final ResourcePatternResolver resourcePatternResolver;LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {this.resourcePatternResolver = resourcePatternResolver;}public List<Document> loadMarkdownDocuments(){List<Document> documentList=new ArrayList<>();try {// 这里可以修改为你要加载的多个 Markdown 文件的路径模式 读取资源目录下的所有 Markdown 文件Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");//加载多篇Markdown文件for (Resource resource : resources) {String fileName = resource.getFilename(); // 获取文件名//读取的配置设置MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true)//添加水平线.withIncludeCodeBlock(false)//添加代码块.withIncludeBlockquote(false)//添加引用.withAdditionalMetadata("filename", fileName) //添加(元信息)而外信息 //比如文件名 其他标签等.build();MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);//添加到集合documentList.addAll(reader.get());}} catch (Exception e){log.error("loadMarkdownDocuments error 文件读取失败",e);}return documentList;}}
2.2.2.加载文档到 基于内存的 向量数据库
将加载到的文档 进行 切割 、添加关键词 和摘要 再添加到向量数据库
所使用的 关键词 和文本摘要都需要涉及到大模型,所以也需要消耗对应的Token,在当前学习阶段用一次证明可以使用就能关掉了,否这token消耗大,且大模型回复较慢
package com.example.demo.RAG;import jakarta.annotation.Resource;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.transformer.KeywordMetadataEnricher;
import org.springframework.ai.transformer.SummaryMetadataEnricher;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.List;@Configuration
public class AppDocumentVectorStoreConfig {@Resourceprivate LoveAppDocumentLoader loveAppDocumentLoader;@AutowiredChatModel chatModel;@Beanpublic VectorStore appVectorStore(EmbeddingModel dashScopeEmbeddingModel){//初始化一个基于内存的向量数据库SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashScopeEmbeddingModel).build();//读取文挡List<Document> documents = loveAppDocumentLoader.loadMarkdownDocuments();//切分文档 文档按照Token进行切分 可以配置token数量 上下文token交集TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();List<Document> documentsSplitter = tokenTextSplitter.apply(documents);// 添加元数据 提取关键词生成器KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(chatModel,3);List<Document> documentsMetaDataEnricher = keywordMetadataEnricher.apply(documentsSplitter);//摘要生成器 生产 摘要SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(chatModel,List.of(SummaryMetadataEnricher.SummaryType.PREVIOUS, //结合之前的文档SummaryMetadataEnricher.SummaryType.CURRENT, //当前的文档SummaryMetadataEnricher.SummaryType.NEXT)); //下一个文档List<Document> documentList = summaryMetadataEnricher.apply(documentsMetaDataEnricher);//添加到向量数据库simpleVectorStore.add(documentList);//返回向量数据库return simpleVectorStore;}}
编写对话 接口
@Resourceprivate VectorStore appVectorStore;public void dochatRag(String message , String sessionId){ChatResponse chatResponse = chatClient.prompt().user(message).advisors(advisorSpec -> advisorSpec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId) //根据会话id获取对话历史.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))//获取历史消息的条数.advisors(new QuestionAnswerAdvisor(appVectorStore)).call().chatResponse();System.out.println(chatResponse.getResult().getOutput().getText());}编写测试
@Testpublic void testLoveAppRag(){app.dochatRag("我是小明 我是单身线上交友有哪些注意事项能提高脱单成功率,简略的回答一下","1");app.dochatRag("有没有相应的课程推荐?","1");}结果:
