机器学习——XGBoost算法
XGBoost(eXtreme Gradient Boosting)是一种高效、灵活且可扩展的梯度提升决策树(GBDT)算法实现,由陈天奇博士于2014年开发。它已成为机器学习竞赛和工业应用中广泛使用的强大工具。
XGBoost 核心原理
1.1 算法本质
XGBoost (eXtreme Gradient Boosting) 是梯度提升决策树(GBDT)的一种高效优化实现。其核心思想可以概括为:
基础模型:基于梯度提升框架的决策树集成方法,通过迭代地添加新树来修正之前模型的错误。
核心思想:
加法训练:采用前向分步算法,每次迭代添加一个新树模型来优化整体模型。具体公式为:
ŷ_i^(t) = ŷ_i^(t-1) + f_t(x_i)其中t表示第t次迭代,f_t表示第t棵树的预测结果。
二阶泰勒展开:不同于传统GBDT只使用一阶梯度,XGBoost使用损失函数的二阶泰勒展开来更精确地近似目标函数。例如对于平方损失函数:
L ≈ Σ[g_i f_t(x_i) + 1/2 h_i f_t^2(x_i)] + Ω(f_t)其中g_i和h_i分别是一阶和二阶梯度。
正则化控制:通过显式地加入正则化项来控制模型复杂度,防止过拟合。
1.2 目标函数
XGBoost的目标函数由两部分组成:
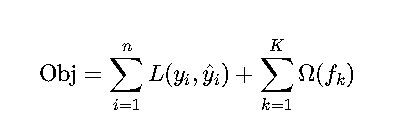
详细说明:
损失函数L:
- 回归问题常用均方误差(MSE):
L = (y_i - ŷ_i)^2 - 分类问题常用对数损失(LogLoss):
L = -[y_i log(p_i) + (1-y_i)log(1-p_i)] - 支持自定义损失函数,只需满足二阶可导
- 回归问题常用均方误差(MSE):
正则化项Ω:
Ω(f) = γT + 1/2 λ||w||^2- T:树的叶子节点数
- w:叶子节点权重
- γ和λ:可调超参数
树模型f_k:
- 每棵树将输入x映射到某个叶子节点
- 叶子节点包含权重w表示预测值
- 树结构通过贪心算法学习得到
1.3 关键改进
XGBoost相较于传统GBDT的主要创新点:
| 特性 | 详细说明 | 实际优势 |
|---|---|---|
| 二阶导数 | 利用Hessian矩阵(二阶导数)信息,更精确地估计步长 | 收敛速度比GBDT快3-5倍,特别在后期优化阶段 |
| 正则化 | 同时控制叶子节点数量(T)和权重值(w)的L2正则化 | 在噪声数据上表现更稳定,如Kaggle竞赛中常见 |
| 缺失值处理 | 为每个节点学习默认分裂方向,自动处理缺失值 | 简化数据预处理流程,适合真实世界的不完整数据 |
| 并行化 | 1. 特征预排序和分位点计算并行化<br>2. 特征分裂点评估并行化 | 充分利用多核CPU,百万级数据训练时间从小时级降至分钟级 |
| 其他优化 | 1. 基于直方图的近似算法<br>2. 缓存感知访问<br>3. 块压缩等技术 | 内存使用效率提升5-10倍,支持十亿级数据的训练 |
应用场景示例:
- 点击率预测(CTR)中,XGBoost可以自动处理用户行为数据中的大量缺失值
- 金融风控建模时,正则化机制有效防止对少数异常样本的过拟合
- 推荐系统中,并行化特性支持快速迭代更新模型
XGBoost的详细运用指南
基本训练函数
xgboost.train(params, dtrain, num_boost_round=10, evals=(), early_stopping_rounds=None, verbose_eval=True
)
参数详解:
params: 参数字典,控制模型行为。例如:{'max_depth':5,'objective':'binary:logistic','eval_metric':'auc' }dtrain: 训练数据,必须转换为DMatrix格式:dtrain = xgb.DMatrix(X_train, label=y_train)num_boost_round: 迭代次数,默认10次。对于大型数据集通常设置为100-1000evals: 验证数据集列表,格式为(数据集, 名称)元组列表:[(dtrain,'train'), (dtest,'test')]early_stopping_rounds: 早停轮数,需配合evals使用。当验证集指标在指定轮数内没有提升时停止训练
关键参数分类
通用参数
booster: 选择基础模型类型gbtree(默认): 基于树的模型gblinear: 线性模型dart: 使用dropout的树模型
nthread: 并行线程数,设置为-1自动使用所有可用核心
树模型参数
max_depth: 树的最大深度,典型值3-10- 过深容易过拟合
- 过浅可能欠拟合
min_child_weight: 子节点最小权重和(Hessian)- 控制模型复杂度
- 典型值1-10
gamma: 分裂所需最小损失减少量- 值越大算法越保守
- 典型值0-1
训练控制参数
eta(learning_rate): 学习率- 典型值0.01-0.3
- 较小的学习率通常需要更大的n_estimators
subsample: 样本采样比例- 防止过拟合
- 典型值0.5-1
colsample_bytree: 特征采样比例- 每棵树随机选择的特征比例
- 典型值0.5-1
目标函数
objective: 定义学习任务- 分类:
binary:logistic:二分类逻辑回归multi:softmax:多分类softmax
- 回归:
reg:squarederror:均方误差
- 排序:
rank:pairwise:pairwise排序
- 分类:
eval_metric: 评估指标auc:ROC曲线下面积rmse:均方根误差logloss:对数损失
参数调优方法
网格搜索
from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth': [3, 5, 7],'learning_rate': [0.01, 0.1, 0.2],'n_estimators': [100, 200]
}grid = GridSearchCV(estimator=XGBClassifier(),param_grid=param_grid,cv=5, # 5折交叉验证scoring='accuracy',n_jobs=-1 # 使用所有CPU核心
)grid.fit(X_train, y_train)
print("最佳参数:", grid.best_params_)
print("最佳分数:", grid.best_score_)
贝叶斯优化
from bayes_opt import BayesianOptimization
from sklearn.model_selection import cross_val_scoredef xgb_cv(max_depth, learning_rate, n_estimators):model = XGBClassifier(max_depth=int(max_depth),learning_rate=learning_rate,n_estimators=int(n_estimators),eval_metric='auc')return cross_val_score(model, X, y, cv=5, scoring='roc_auc').mean()optimizer = BayesianOptimization(f=xgb_cv,pbounds={'max_depth': (3, 10),'learning_rate': (0.01, 0.3),'n_estimators': (50, 300)},random_state=42
)optimizer.maximize(init_points=5, # 初始随机搜索点n_iter=20, # 优化迭代次数
)print("最佳参数:", optimizer.max)
模型分析与解释
特征重要性可视化
from xgboost import plot_importance
import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))
plot_importance(model, max_num_features=10, # 显示最重要的10个特征importance_type='weight' # 也可以选择'gain'或'cover'
)
plt.title('XGBoost Feature Importance')
plt.tight_layout()
plt.show()
SHAP值解释
import shap# 创建解释器
explainer = shap.TreeExplainer(model)# 计算SHAP值
shap_values = explainer.shap_values(X_test)# 特征重要性摘要图
plt.figure(figsize=(10, 6))
shap.summary_plot(shap_values, X_test,plot_type="bar", # 也可以选择"dot"或其他类型max_display=10 # 显示最重要的10个特征
)
plt.tight_layout()
plt.show()# 单个预测解释
shap.force_plot(explainer.expected_value,shap_values[0,:], X_test.iloc[0,:],matplotlib=True
)
实际应用建议
数据预处理:
- 缺失值处理(XGBoost可以自动处理)
- 类别变量编码(建议使用LabelEncoder)
- 数值变量标准化(对于线性booster)
训练技巧:
- 使用早停法防止过拟合
- 从小学习率开始,配合更多迭代次数
- 使用交叉验证评估模型性能
部署注意事项:
- 保存模型:
model.save_model('xgboost.model') - 加载模型:
model = xgb.Booster(model_file='xgboost.model') - 生产环境注意线程设置(nthread参数)
- 保存模型: