[GLM-4.5] GLM-4.5模型 | Claude Code服务集成
链接:https://chat.z.ai/
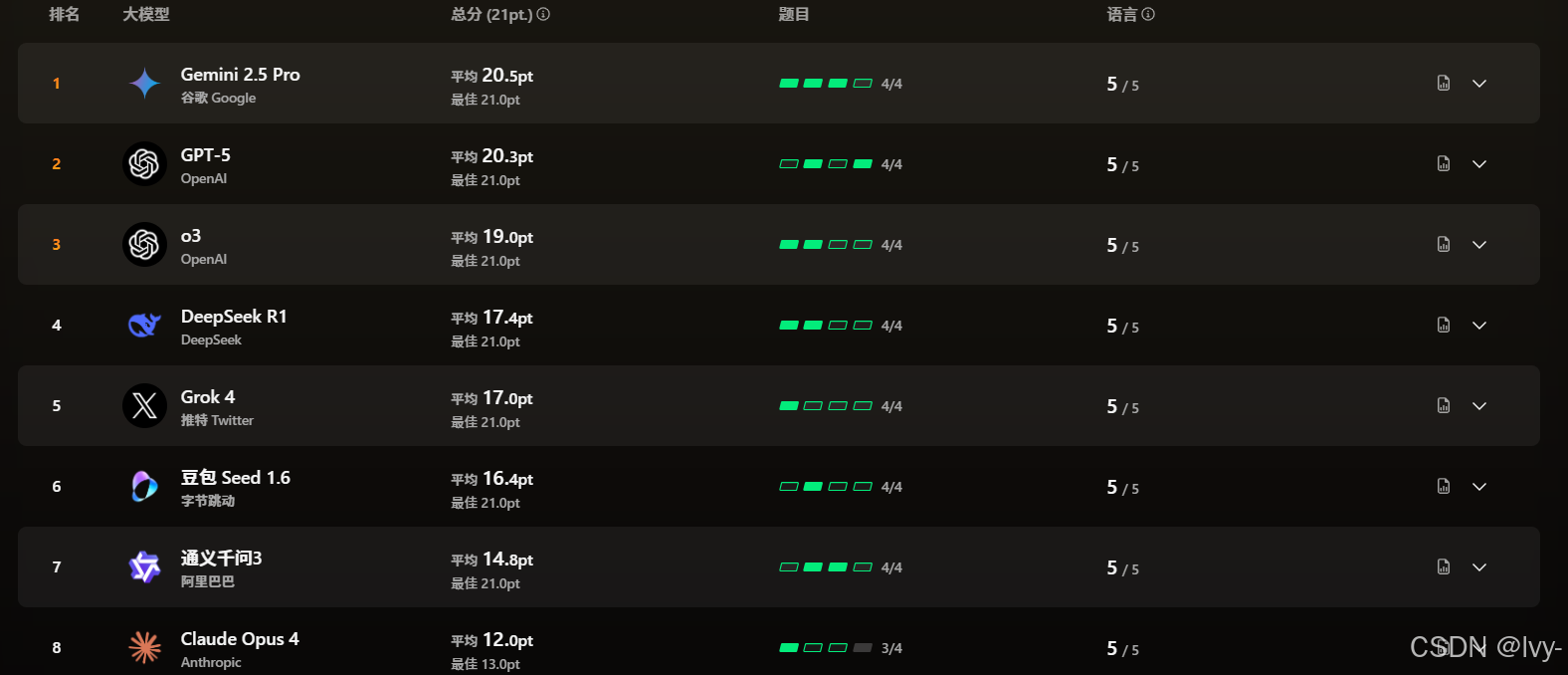
8.17 Model algorithm programming test ranking
docs:GLM-4.5
GLM-4.5项目提供了一套完整的系统,用于部署和使用GLM-4.5模型家族——一个强大的大语言模型
该系统采用专用推理服务器(SGLang/vLLM),这些服务器针对速度和效率进行了高度优化
同时还能无缝集成Claude Code等开发环境,提供交互式的智能代理体验。
可视化
章节
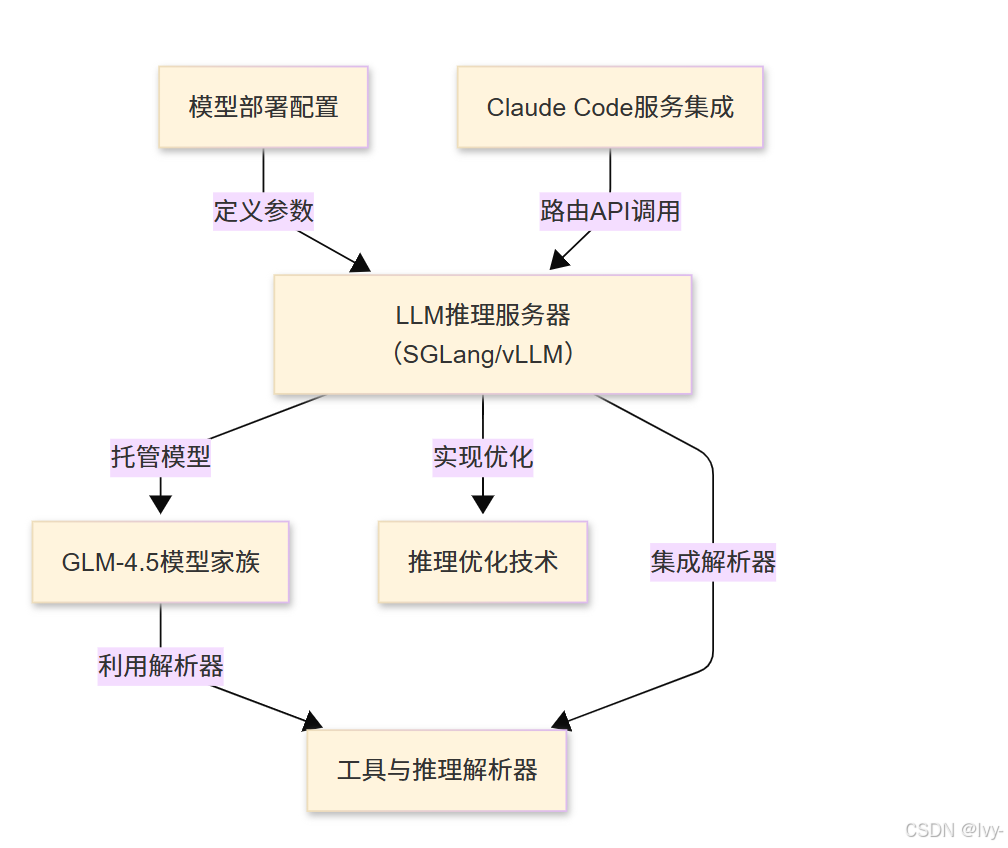
- GLM-4.5模型家族
- Claude Code服务集成
- LLM推理服务器(SGLang/vLLM)
- 工具与推理解析器
- 模型部署配置
- 推理优化技术
GLM-4.5 一个由智谱AI (Z.ai)开源的大语言模型,专为智能代理设计。它提供了强大的推理、编码和智能代理能力,满足了智能代理应用的复杂需求。
Main Function Points
- GLM-4.5是一个混合推理模型,提供
思考模式和非思考模式两种模式 - 开源了GLM-4.5和GLM-4.5-Air的基础模型、混合推理模型和FP8版本
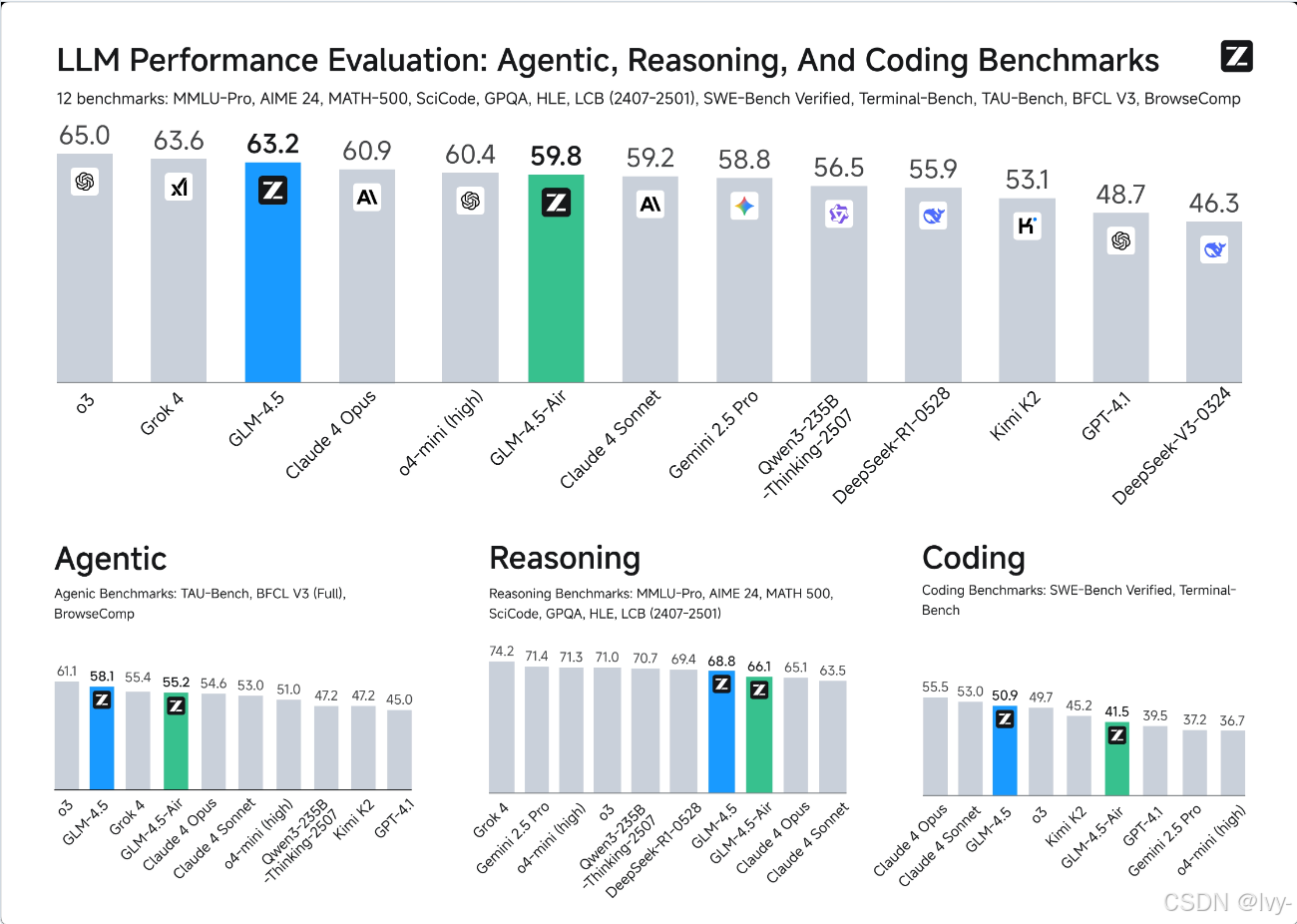
- 在12个行业标准基准测试中取得了出色的性能,GLM-4.5排名第三
Technology Stack
- 使用了
transformers、vLLM和SGLang进行实现 - 支持
BF16和FP8精度
第1章:GLM-4.5模型家族
欢迎来到激动人心的GLM-4.5世界🐻❄️
在这个探索之旅中,我们将揭示这项强大技术的运作原理。想象我们正在建造一个超级智能机器人,在让它施展神奇能力之前,我们需要先了解它的"大脑"。
GLM-4.5的"大脑"是什么?
想象你拥有一位无所不知的超级智能伙伴。
你可以向他提出复杂问题、获取代码编写帮助,甚至咨询决策建议。
这个"超级智能伙伴"就如同GLM-4.5模型家族。
这些就是真正的*大语言模型(LLMs)*本身,是整个GLM-4.5系统的核心"大脑"。
为什么它们如此重要?
GLM-4.5模型赋予系统智能能力。它们通过海量文本和代码训练而成,堪称知识渊博的专家。当你与基于GLM-4.5的系统交互时,这些模型正在幕后进行核心运算。
认识GLM-4.5家族成员
GLM-4.5家族不是单一模型,而是一组各有所长的"大脑"集合:
- GLM-4.5:
旗舰模型,如同家族中最强大全面的专家,专为处理复杂任务、深度推理和高级代码生成而设计 - GLM-4.5-Air:更
轻量高效的版本,像是能快速处理常见任务的专业能手,适合对速度和资源效率要求高的场景
GLM-4.5和GLM-4.5-Air还提供不同"风味"的版本:
- FP8变体:针对速度和内存优化,常用于需要极致性能的生产环境
- 基础变体:基础模型,可用于进一步的专业训练
无论哪种变体,这些模型本质上都是预训练神经网络。暂时不必纠结这个技术术语!只需将它们理解为已经"阅读"并"理解"海量信息的精密学习机器。
如何"加载"GLM-4.5大脑?
要使这些"大脑"发挥作用,我们需要将它们加载到计算机内存中。这通常在强大服务器上完成。
以下是使用SGLang工具(将在LLM推理服务器(SGLang/vLLM)章节详述)启动模型服务的简化示例:
python3 -m sglang.launch_server \--model-path zai-org/GLM-4.5 \# ... (其他性能参数)--served-model-name glm-4.5 \--port 8000
这段代码在做什么?
python3 -m sglang.launch_server:指示服务器启动SGLang提供的特殊程序来运行GLM-4.5模型--model-path zai-org/GLM-4.5:关键参数!指定要加载的GLM-4.5模型,zai-org/GLM-4.5是其在Hugging Face等平台上的唯一标识--served-model-name glm-4.5:为加载的模型赋予简易名称,便于后续引用--port 8000:在服务器上设置"门户"(端口8000),让系统其他部分能与GLM-4.5大脑对话
运行成功后,GLM-4.5"大脑"就已唤醒,准备回答问题或生成代码!
也可以直接将模型加载到Python程序中进行更精细控制:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchMODEL_PATH = "zai-org/GLM-4.5"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH) # 加载模型理解词语的方式
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH,torch_dtype=torch.bfloat16, # 使用特定数据类型进行计算device_map="auto" # 自动分配计算资源
)
# 此时'model'变量即代表加载的GLM-4.5大脑
这段代码在做什么?
AutoTokenizer.from_pretrained(MODEL_PATH):模型"思考"前需要理解输入词语,tokenizer如同模型的语言词典和翻译器AutoModelForCausalLM.from_pretrained(MODEL_PATH, ...):核心代码,加载GLM-4.5"大脑"本身,获取模型学习到的所有复杂模式和知识
运行后,Python脚本中的model变量就成为连接GLM-4.5智能的直接通道。
提问时发生了什么?
延续"大脑"的比喻,当你与基于GLM-4.5的应用交互时,以下是模型家族作为"大脑"的简化流程:
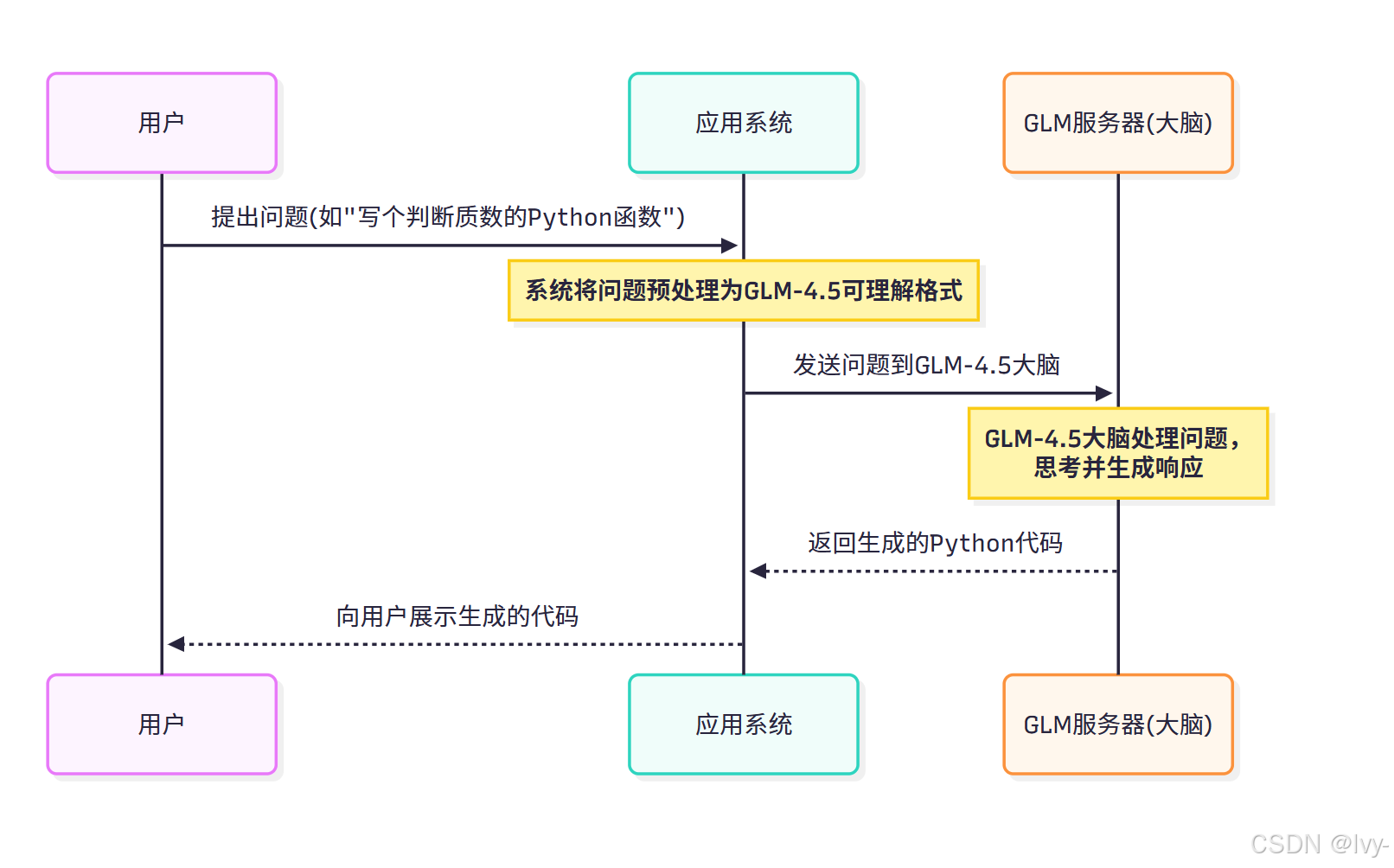
图中GLM服务器(大脑)代表已加载运行的某个GLM-4.5模型(如GLM-4.5或GLM-4.5-Air),它是理解请求并生成智能应答的核心组件。
小结
本章我们认识到GLM-4.5模型家族作为实际的大语言模型,是整个系统的"大脑"。
这些如GLM-4.5和GLM-4.5-Air的模型,是能够进行复杂推理、代码生成和智能代理操作的高级专家。
我们也初步了解了如何将这些"大脑"加载到服务器或程序中投入使用。
现在我们已经理解核心"大脑"的运作,接下来让我们看看如何将这个强大大脑集成到完整系统中,特别是与Claude Code服务的整合。
下一章:Claude Code服务集成
第2章:Claude Code服务集成
在第1章:GLM-4.5模型家族中,我们认识了GLM-4.5模型家族——这个超级智能系统的"大脑"。
我们了解了如何将这些强大模型加载到服务器上,使其能够思考和生成精彩的文本或代码。
但如何从日常开发环境中实际对话这个强大大脑?它如何在编写代码时直接提供帮助、改进建议甚至修复错误?这就是Claude Code服务集成的用武之地🐻❄️
与GLM-4.5大脑对话
想象你有一位超级智能编程专家(我们的GLM-4.5模型)在另一个房间(你的服务器)。你希望直接从工位(本地计算机)向这位专家寻求帮助。你需要一种连接工位与房间的方法,以及特殊的"翻译服务"确保双方理解彼此。
这正是Claude Code服务集成的功能:它将本地开发环境与运行在服务器上的GLM-4.5模型连接起来,让GLM-4.5专家如同坐在身旁协助编程。
集成的主要目标是实现交互式开发体验。这意味着可以向GLM-4.5模型寻求编程帮助,它能直接在开发环境中响应,提供建议、生成代码片段并解释概念。
测试:
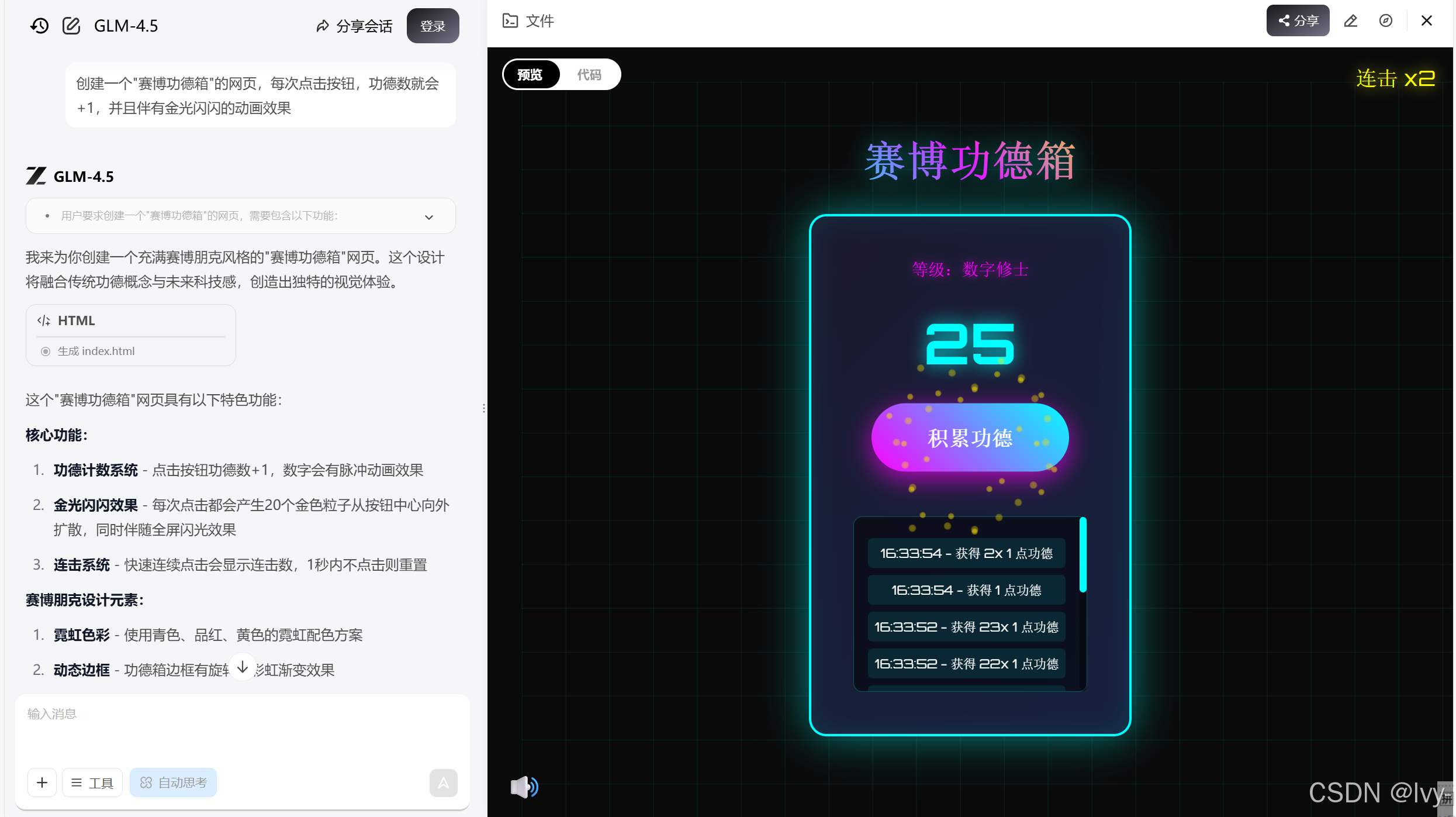
预览:
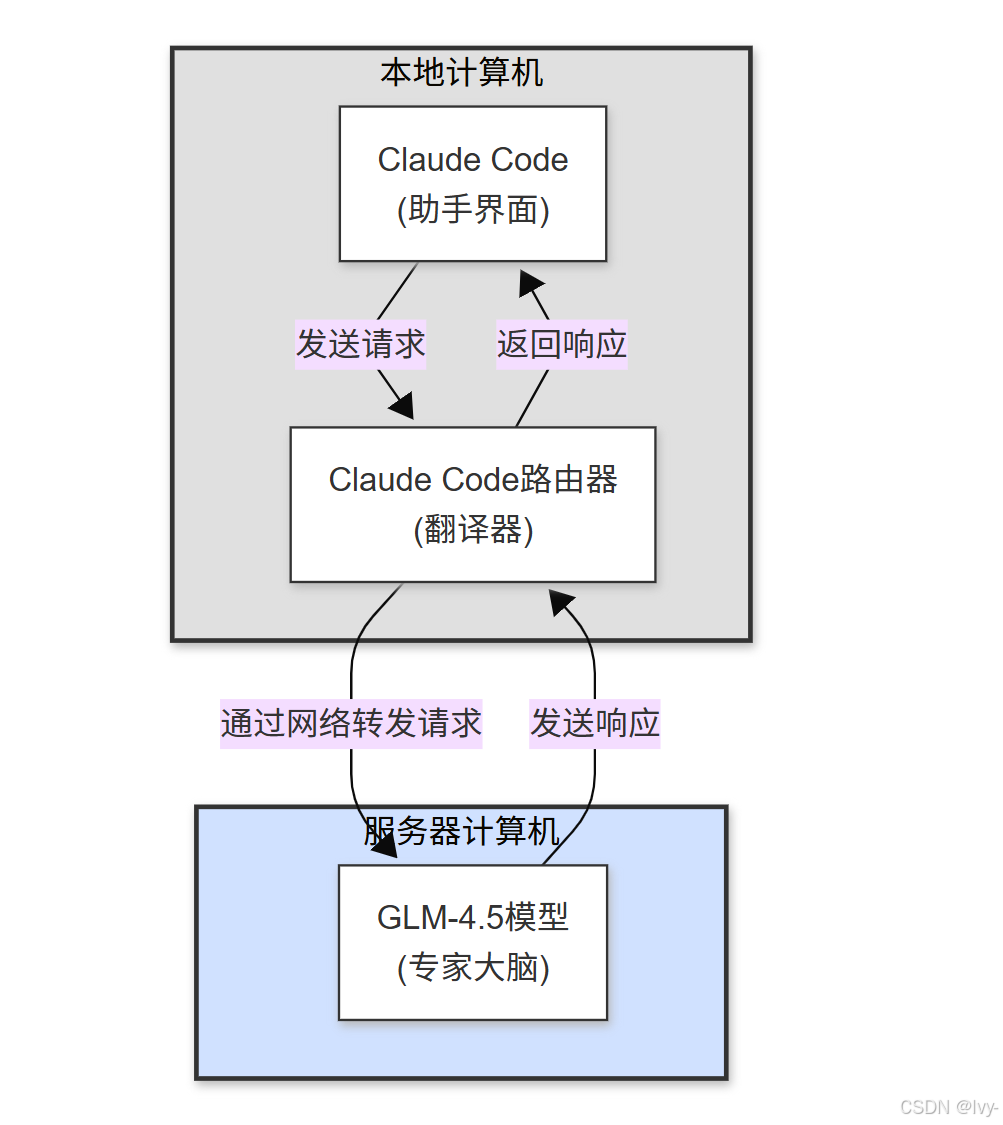
核心组件
要实现这种无缝连接,我们需要几个专用工具:
- Claude Code:智能编程助手界面,直接运行在本地计算机上的程序。当输入问题或编程任务时,使用的就是Claude Code。
- Claude Code路由器:关键的"翻译服务"或"中间人",同样运行在本地计算机。它负责将Claude Code的请求转换为GLM-4.5服务器理解的语言,发送请求并返回响应,确保通信顺畅。
- GLM-4.5服务器:运行GLM-4.5模型(第1章的"大脑")的服务器,随时准备处理请求。
以下是它们协作关系的简单图示:
建立连接
让我们看看建立这种连接的具体步骤。需要准备两个主要部分:本地计算机和服务器计算机。
步骤1:配置本地计算机
在本地机器(笔记本或台式机)上,需要安装Claude Code和Claude Code路由器。这些通常通过JavaScript包管理器npm安装:
npm install -g @anthropic-ai/claude-code
npm install -g @musistudio/claude-code-router
npm install -g:全局安装工具,可从任意文件夹运行@anthropic-ai/claude-code:Claude Code助手本体@musistudio/claude-code-router:连接Claude Code与GLM-4.5的"翻译器"
步骤2:在服务器启动GLM-4.5大脑
确保GLM-4.5模型已在服务器运行并准备接收请求(第1章简要提及)。这里我们使用SGLang工具:
在服务器上首先安装sglang:
pip install sglang
然后启动GLM-4.5模型服务:
python3 -m sglang.launch_server \--model-path zai-org/GLM-4.5 \--served-model-name glm-4.5 \--port 8000 \--host 0.0.0.0
--host 0.0.0.0:使服务器可从任何IP地址访问,包括本地计算机
成功运行后,服务器将监听http://0.0.0.0:8000,表示GLM-4.5"大脑"已就绪
步骤3:配置Claude Code路由器
现在需要告诉Claude Code路由器如何找到GLM-4.5服务器,通过配置文件实现:
- 在GLM-4.5项目的
example/claude_code/文件夹找到config.example.json - 复制或重命名为
config.json - 编辑
api_base_url指向服务器IP和端口(8000)
配置示例:
{"Providers": [{"name": "glm-4.5-sglang","api_base_url": "http://服务器IP:8000/v1/chat/completions","api_key": "EMPTY","models": ["glm-4.5"]}],"Router": {"default": "glm-4.5-sglang,glm-4.5"}
}
服务器IP:替换为运行GLM-4.5的服务器的实际IP。本地测试可使用127.0.0.1api_key: "EMPTY":本地SGLang设置通常不需要API密钥
将配置文件保存到~/.claude-code-router/config.json,然后重启路由器:
ccr restart
使用Claude Code与GLM-4.5交互
连接建立后,即可开始使用Claude Code!在本地终端运行:
ccr code
这将启动Claude Code界面,可以直接输入问题或编程任务。例如询问:how can I run GLM-4.5 in transformers
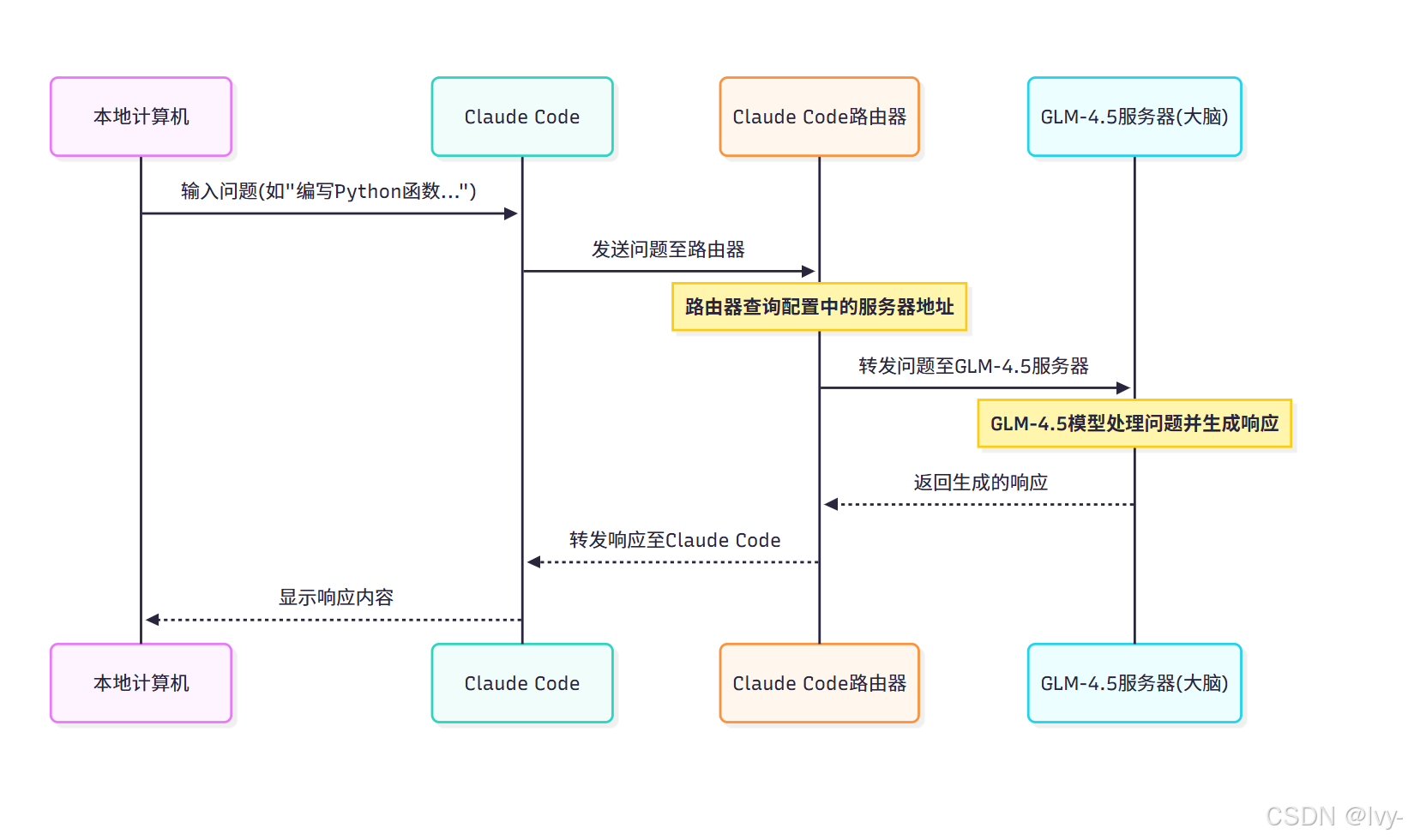
交互流程如下:
- 用户通过Claude Code提问
- Claude Code路由器将请求转发至GLM-4.5服务器
- GLM-4.5模型处理请求并生成响应
- 响应经路由器返回Claude Code显示
底层通信流程
以下是完整的请求-响应序列图:
小结
本章探索了Claude Code服务集成,认识了连接本地开发环境与GLM-4.5模型的核心桥梁。
关键组件Claude Code路由器作为请求翻译器和调度者,通过安装配置步骤,可以将GLM-4.5模型变为交互式编程助手。
现在我们已经理解如何连接GLM-4.5大脑,接下来让我们深入了解服务器本身及高效运行大语言模型的工具。
下一章:LLM推理服务器(SGLang/vLLM)