CPU性能篇-系统的软中断CPU使用率升高如何处理-Day 06
上一章,用一个不可中断进程的案例,学习了 iowait(也就是等待 I/O 的 CPU 使用率)升高时的分析方法。这里要记住,进程的不可中断状态是系统的一种保护机制,可以保证硬件的交互过程不被意外打断。所以,短时间的不可中断状态是很正常的。
但是,当进程长时间都处于不可中断状态时,就得当心了。这时,可以使用 dstat、pidstat 等工具,确认是不是磁盘 I/O 的问题,进而排查相关的进程和磁盘设备。
其实除了 iowait,软中断(softirq)CPU 使用率升高也是最常见的一种性能问题。下面会专门介绍如何处理这种情况。
1. 如何理解软中断
1.1 什么是中断
中断是系统用来响应硬件设备请求的一种机制,它会打断进程的正常调度和执行,然后调用内核中的中断处理程序来响应设备的请求。
1.2 为什么要有中断
比如说你订了一份外卖,但是不确定外卖什么时候送到,也没有别的方法了解外卖的进度,但是,配送员送外卖是不等人的,到了你这儿没人取的话,就直接走人了。所以你只能苦苦等着,时不时去门口看看外卖送到没,而不能干其他事情。
不过呢,如果在订外卖的时候,你就跟配送员约定好,让他送到后给你打个电话,那你就不用苦苦等待了,就可以去忙别的事情,直到电话一响,接电话、取外卖就可以了。
这里的“打电话”,其实就是一个中断。没接到电话的时候,你可以做其他的事情;只有接到了电话(也就是发生中断),你才要进行另一个动作:取外卖。
这个例子就可以发现,中断其实是一种异步的事件处理机制,可以提高系统的并发处理能力。
由于中断处理程序会打断其他进程的运行,所以,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。如果中断本身要做的事情不多,那么处理起来也不会有太大问题;但如果中断要处理的事情很多,中断服务程序就有可能要运行很长时间。
特别是,中断处理程序在响应中断时,还会临时关闭中断。这就会导致上一次中断处理完成之前,其他中断都不能响应,也就是说中断有可能会丢失。
那么还是以取外卖为例。假如你订了 2 份外卖,一份主食和一份饮料,并且是由 2 个不同的配送员来配送。这次你不用时时等待着,两份外卖都约定了电话取外卖的方式。但是,问题又来了。
当第一份外卖送到时,配送员给你打了个长长的电话,商量发票的处理方式。与此同时,第二个配送员也到了,也想给你打电话。
但是很明显,因为电话占线(也就是关闭了中断响应),第二个配送员的电话是打不通的。所以,第二个配送员很可能试几次后就走掉了(也就是丢失了一次中断)。
1.3 软中断
事实上,为了解决中断处理程序执行过长和中断丢失的问题,Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。
简单点理解:
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行。
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行。
这里举个例子:
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。这时,内核就应该调用中断处理程序来响应它。
对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。
而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
1.4 软硬中断本质区别
| 维度 | 硬中断(Hardware Interrupt) | 软中断(Soft Interrupt) |
| 触发源 | 硬件设备(如网卡、硬盘)主动发送中断信号 | 软件主动触发(如内核代码调用raise_softirq()) |
| 处理紧迫性 | 必须立即处理(中断硬件操作会阻塞) | 可延迟处理(在 CPU 空闲时批量执行) |
| 上下文切换 | 会打断当前进程执行,进入内核中断处理程序 | 运行在中断上下文(无进程上下文切换) |
| 典型场景 | 网卡收到新数据包、硬盘读写完成 | 网络包软中断(NET_RX)、定时器软中断(TIMER) |
1.5 查看软中断和内核线程
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
root@yunwei-virtual-machine:/tmp# cat /proc/softirqsCPU0 CPU1 CPU2 CPU3HI: 0 0 0 0TIMER: 3834711 5655276 7761163 4001153NET_TX: 24 22 12 14NET_RX: 6680507 1129977 7504442 72845BLOCK: 324296 421661 420102 371527IRQ_POLL: 0 0 0 0TASKLET: 61 104 32 18SCHED: 18746516 14053296 16608763 11724104HRTIMER: 3199 584 453 1277RCU: 1581698 2091686 2092701 1772466
第一列表示软中断的类型:
- HI: 高优先级软中断,通常用于处理需要快速响应的事件,这里都是 0,属于正常情况。
- TIMER: 定时器软中断,负责处理系统定时器事件。数值较高,可能与系统定时任务有关,但需要看是否在合理范围内。
- NET_TX: 网络发送软中断,处理发送网络数据包,数值较低,正常。
- NET_RX: 网络接收软中断,处理接收数据包。这里 CPU0 和 CPU2 的数值很高,而 CPU1 和 CPU3 相对较低,可能存在网络接收不均衡的问题。
- BLOCK: 块设备软中断,处理磁盘 IO,数值中等,需要结合系统 IO 情况判断。
- IRQ_POLL: 用于轮询中断,这里都是 0,正常。
- TASKLET: 基于软中断的任务,数值较低,正常。
- SCHED: 调度软中断,与进程调度相关,数值较高,可能与系统负载有关。
- HRTIMER: 高精度定时器,数值较低,正常。
- RCU: 读 - 复制更新机制,用于内核同步,数值较高但属于正常范围。
这里需要注意的是,同一个类型的软中断,在不同CPU核心上的次数,正常来说是差不多的。
另外,刚刚提到过,软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
root@yunwei-virtual-machine:/tmp# ps -fe |grep softirq
root 16 2 0 6月12 ? 00:00:01 [ksoftirqd/0]
root 24 2 0 6月12 ? 00:00:00 [ksoftirqd/1]
root 30 2 0 6月12 ? 00:00:01 [ksoftirqd/2]
root 36 2 0 6月12 ? 00:00:00 [ksoftirqd/3]
注意,这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数(cmline)。
一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。
2. 案例分析
2.1 环境准备
- 机器配置:Ubuntu 22.04.5 4C 8G
- 机器数量:2
- 安装软件:docker、sysstat、sar 、hping3、tcpdump 等工具。
- sar:是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
- hping3:是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙测试等。
2.2 操作与分析
2.2.1 VM1操作
root@VM1:~# docker run -itd --name=nginx -p 80:80 nginx
17f46c4789a8d32b2299b556b39b3e4818a1fdbff9d94d6cd8ab48e49a2ea56c
root@VM1:~# docker ps -l
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
17f46c4789a8 nginx "/docker-entrypoint.…" 8 seconds ago Up 4 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp nginx2.2.2 VM2操作
2.2.2.1 curl请求vm1的nginx
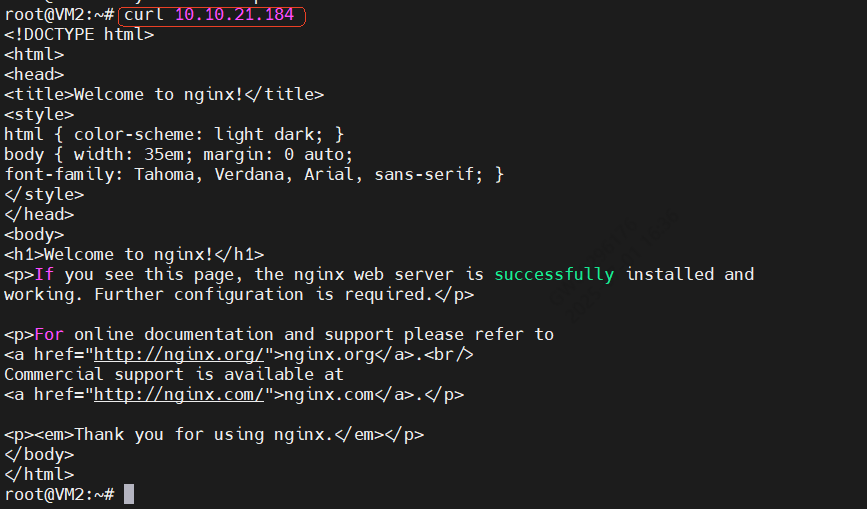
2.2.2.2 运行hping3命令,模拟Nginx的客户端请求
root@VM2:~# apt install hping3
root@VM2:~# hping3 -S -p 80 -i u100 10.10.21.184
# -S参数表示设置TCP协议的SYN(同步序列号),-p表示目的端口为80
# -i u100表示每隔100微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把100调小,比如调成10甚至12.2.3 VM1操作
回到VM1操作的时候,会发现系统卡顿,有时候敲个回车都要很久才能得到响应,为什么?
因为在上面执行的hping3 命令,相当于是一个 SYN FLOOD 攻击,是一种常见的 DoS(拒绝服务)攻击方式。
会伪造大量 SYN 包(通常伪造源 IP),服务器收到后会分配资源并返回 SYN+ACK,但永远等不到 ACK 确认,导致半开连接队列被占满,无法处理正常请求。
最后让目标端资源耗尽(如半开连接队列、CPU、内存),最后无法响应正常用户请求,服务不可用。
这里假设不知道有人在攻击,使用top看看系统。
2.2.3.1 使用top

通过topc,除了软中断指标有点异常,其他都是正常的。
2.2.3.2 使用watch持续观察软中断情况
root@VM1:~# watch -d cat /proc/softirqs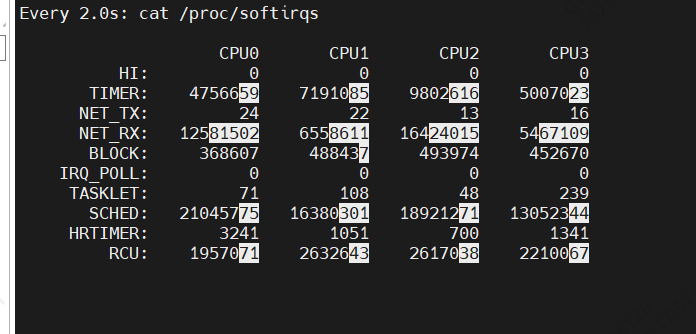
这里可以看到,变化的基本只有:
- TIMER(定时中断)
- NET_RX(网络接收)
- SCHED(内核调度)
- RCU(RCU锁)
其中,NET_RX,也就是网络数据包接收软中断的变化速率最快。而其他几种类型的软中断,是保证 Linux 调度、时钟和临界区保护这些正常工作所必需的,所以它们有一定的变化倒是正常的。
那么接下来,我们就从网络接收的软中断着手,继续分析。
2.2.3.3 使用sar查看系统网络收发情况
sar 可以用来查看系统的网络收发情况,还有一个好处是,不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的 PPS,即每秒收发的网络帧数。
root@VM1:~# apt install sysstat
root@VM1:~# sar -V
sysstat version 12.5.2
(C) Sebastien Godard (sysstat <at> orange.fr)root@VM1:~# sar -n DEV 1 # -n DEV 表示显示网络收发的报告,间隔1秒输出一组数据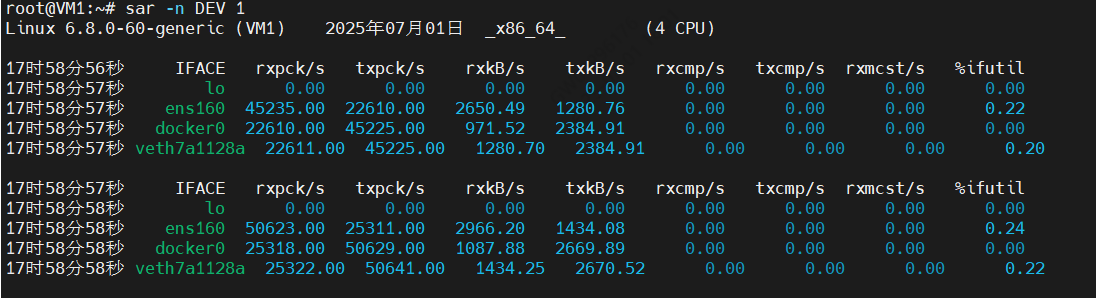
输出介绍:
- 第一列:表示报告的时间。
- 第二列:IFACE 表示网卡。
- 第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS。
- 第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。后面的其他参数基本接近 0,显然跟今天的问题没有直接关系,可以先忽略掉。
然后观察输出可以发现:
- ens160网卡:每秒接收(rxpck/s)的网络帧达到了45235,每秒发送(txpck/s)的网络帧也有22610。但每秒发送(rxkB/s)和每秒接收(txkB/s)的千字节数相对来说就小了很多。
- docker0和veth7a1128a:数据跟 ens160 大差不差,只是发送和接收相反,发送的数据较大而接收的数据较小。这是 Linux 内部网桥转发导致的,是系统把 ens160 收到的包转发给 Nginx 服务即可。
这里重点看ens160网卡:
- 接收的PPS达到了45235.00,但接收的BPS只有2650.49,那2650.49×1024÷45235=60字节,说明平均每个网络包都只有60字节,说明这些网络帧都很小,也就是之前提到的小包问题。
2.2.3.4 使用tcpdump捕获发送方
root@VM1:~# tcpdump -i ens160 -n tcp port 80|head
这里可以很明显的看到,发送方就是10.10.21.183,并且客户端只发syn,单并没有发ack,所以导致有很多Flags [R](RST)。
再加上前面用 sar 发现的, PPS 超过 45235 的现象,现在我们可以确认,这就是从 10.10.21.183 这个地址发送过来的 SYN FLOOD 攻击。
到这里,我们已经做了全套的性能诊断和分析。从系统的软中断使用率高这个现象出发,通过观察 /proc/softirqs 文件的变化情况,判断出软中断类型是网络接收中断;再通过 sar 和 tcpdump ,确认这是一个 SYN FLOOD 问题。
SYN FLOOD 问题最简单的解决方法,就是从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中。
3. 小结
软中断 CPU 使用率(softirq)升高是一种很常见的性能问题。虽然软中断的类型很多,但实际生产中,我们遇到的性能瓶颈大多是网络收发类型的软中断,特别是网络接收的软中断。
在碰到这类问题时,可以借用 sar、tcpdump 等工具,做进一步分析。