《R for Data Science (2e)》免费中文翻译 (第4章) --- Workflow: code style
写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
4.1 命名
-
4.2 空格
-
4.3 管道
-
4.4 ggplot2
-
4.5 分段注释
-
4.6 练习
-
4.7 总结
良好的编码风格就像正确的标点符号:你可以不用它来管理,但它肯定会让事情更容易阅读。即使作为一个非常新的程序员,研究您的代码风格也是一个好主意。使用一致的风格可以让其他人(包括未来的你!)更容易阅读你的作品,如果你需要从别人那里获得帮助,这一点尤为重要。本章将介绍整本书中使用的 tidyverse style guide 的最重要的要点。
设计代码样式一开始会觉得有点乏味,但如果你练习它,它很快就会成为第二天性。此外,还有一些很棒的工具可以快速重新设计现有代码的样式,例如 Lorenz Walthert 的 styler 包。使用 install.packages("styler") 安装后,使用它的一种简单方法是通过 RStudio 的命令面板(command palette)。命令面板允许您使用任何内置的 RStudio 命令和包提供的许多插件。按 Cmd/Ctrl + Shift + P 打开调色板,然后键入 “styler” 以查看 styler 提供的所有快捷方式。Figure 4.1 显示了结果。
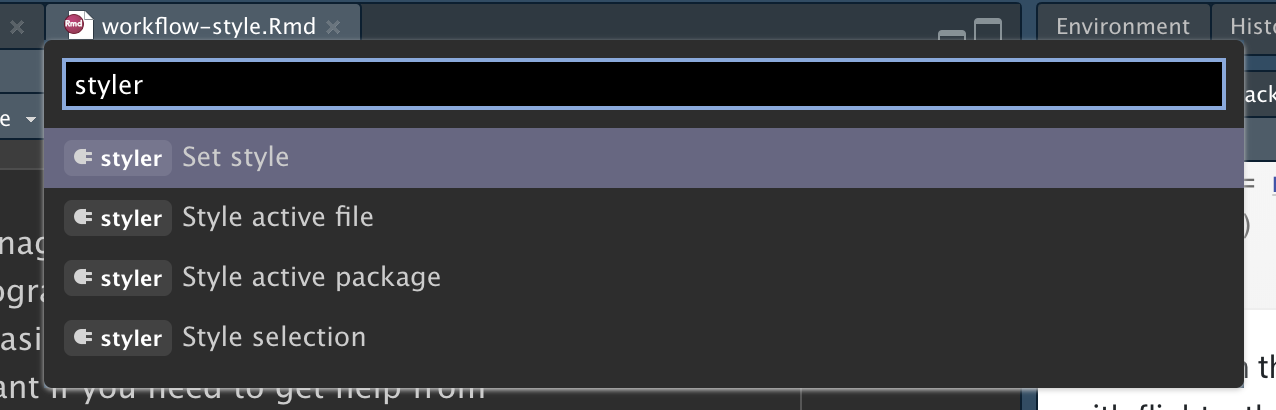
Figure 4.1:Rstudio 的命令面板使仅使用键盘访问每个 RStudio 命令变得易于使用。
在本章中,我们将使用 tidyverse 和 nycflights13 包作为代码示例。
library(tidyverse)
library(nycflights13)
4.1 命名
我们在 Section 2.3 中简要讨论了命名(names)。请记住,变量名(由 <- 创建的和由 mutate() 创建的)应仅使用小写字母、数字和 _。使用 _ 分隔名称中的单词。
# Strive for:
short_flights <- flights |> filter(air_time < 60)# Avoid:
SHORTFLIGHTS <- flights |> filter(air_time < 60)
作为一般经验法则,最好选择易于理解的长描述性名称,而不是快速键入的简洁名称。短名称在编写代码时节省的时间相对较少(尤其是因为自动完成功能会帮助您完成输入),但当您返回旧代码并被迫拼出一个神秘的缩写时,它可能会很耗时。
如果您有一堆相关事物的名称,请尽量保持一致。当您忘记以前的约定时很容易出现不一致,所以如果您不得不返回并重命名事物,请不要难过。一般来说,如果你有一堆变量是同一个主题的变体,你最好给它们一个共同的前缀而不是一个共同的后缀,因为自动完成在变量的开头效果最好。
4.2 空格
除了 ^(即 +、-、==、<、...)和赋值运算符 (<-) 外,在数学运算符的两边放置空格。
# Strive for
z <- (a + b)^2 / d# Avoid
z<-( a + b ) ^ 2/d
不要在常规函数调用的括号内或括号外放置空格。总是在逗号后加一个空格,就像标准英语一样。
# Strive for
mean(x, na.rm = TRUE)# Avoid
mean (x ,na.rm=TRUE)
如果可以改善对齐方式,可以添加额外的空格。例如,如果您在 mutate() 中创建多个变量,您可能需要添加空格以便所有 = 排成一行。这样可以更轻松地浏览代码。
flights |> mutate(speed = distance / air_time,dep_hour = dep_time %/% 100,dep_minute = dep_time %% 100)
4.3 管道
|> 前面应该始终有一个空格,并且通常应该放在一行的最后。这使得添加新步骤、重新排列现有步骤、修改步骤中的元素以及通过浏览左侧的 verbs 获得 10,000 英尺的视图变得更加容易。
# Strive for
flights |> filter(!is.na(arr_delay), !is.na(tailnum)) |> count(dest)# Avoid
flights|>filter(!is.na(arr_delay), !is.na(tailnum))|>count(dest)
如果您要输入的函数具有命名参数(如 mutate() 或 summarize()),请将每个参数放在一个新行中。如果函数没有命名参数(如 select() 或 filter()),请将所有内容放在一行中,除非它不适合,在这种情况下,您应该将每个参数放在自己的行中。
# Strive for
flights |> group_by(tailnum) |> summarize(delay = mean(arr_delay, na.rm = TRUE),n = n())# Avoid
flights |>group_by(tailnum) |> summarize(delay = mean(arr_delay, na.rm = TRUE), n = n())
在流水线的第一步之后,每行缩进两个空格。RStudio 会在 |> 后的换行符后自动为您添加空格。如果您将每个参数放在自己的行中,请额外缩进两个空格。确保 ) 独占一行,并且未缩进以匹配函数名称的水平位置。
# Strive for
flights |> group_by(tailnum) |> summarize(delay = mean(arr_delay, na.rm = TRUE),n = n())# Avoid
flights|>group_by(tailnum) |> summarize(delay = mean(arr_delay, na.rm = TRUE), n = n())# Avoid
flights|>group_by(tailnum) |> summarize(delay = mean(arr_delay, na.rm = TRUE), n = n())
如果您的管道很容易放在一条线上,那么可以避开其中一些规则。 但根据我们的集体经验,短片段变长是很常见的,因此从长远来看,从所需的所有垂直空间开始通常会节省时间。
# This fits compactly on one line
df |> mutate(y = x + 1)# While this takes up 4x as many lines, it's easily extended to
# more variables and more steps in the future
df |> mutate(y = x + 1)
最后,要小心写很长的管道,比如超过 10-15 行。试着把它们分解成更小的子任务,给每个任务一个信息丰富的名称。这些名称将有助于提示读者了解正在发生的事情,并更容易检查中间结果是否符合预期。每当你可以给一些东西一个信息性名称时,你应该给它一个信息性名称,例如当你从根本上改变数据的结构时,例如,在旋转或总结之后。不要指望第一次就做对!这意味着如果存在可以获得好名字的中间状态,则打破长管道。
4.4 ggplot2
适用于管道的相同基本规则也适用于 ggplot2;只需将 + 视为与 |> 相同的方式。
flights |> group_by(month) |> summarize(delay = mean(arr_delay, na.rm = TRUE)) |> ggplot(aes(x = month, y = delay)) +geom_point() + geom_line()
同样,如果您不能将函数的所有参数放在一行中,请将每个参数放在其自己的行中:
flights |> group_by(dest) |> summarize(distance = mean(distance),speed = mean(distance / air_time, na.rm = TRUE)) |> ggplot(aes(x = distance, y = speed)) +geom_smooth(method = "loess",span = 0.5,se = FALSE, color = "white", linewidth = 4) +geom_point()
注意从 |> 到 + 的过渡。我们希望这种转换不是必需的,但不幸的是,ggplot2 是在发现管道之前编写的。
4.5 分段注释
随着您的脚本变长,您可以使用 sectioning 注释将您的文件分解成可管理的部分:
# Load data --------------------------------------# Plot data --------------------------------------
RStudio 提供了一个键盘快捷键来创建这些标题(Cmd/Ctrl + Shift + R),并将它们显示在编辑器左下角的代码导航下拉列表中,如 Figure 4.2 所示。
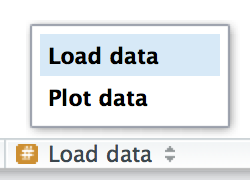
Figure 4.2: 将分段注释添加到脚本后,您可以在脚本编辑器的左下方使用代码导航工具轻松导航到它们。
4.6 练习
-
按照上述指南重新设计以下管道。
flights|>filter(dest=="IAH")|>group_by(year,month,day)|>summarize(n=n(), delay=mean(arr_delay,na.rm=TRUE))|>filter(n>10)flights|>filter(carrier=="UA",dest%in%c("IAH","HOU"),sched_dep_time> 0900,sched_arr_time<2000)|>group_by(flight)|>summarize(delay=mean( arr_delay,na.rm=TRUE),cancelled=sum(is.na(arr_delay)),n=n())|>filter(n>10)
4.7 总结
在本章中,您学习了代码风格的最重要原则。从这些开始可能感觉像是一组任意规则(因为它们确实如此!),但随着时间的推移,随着您编写更多代码并与更多人共享代码,您会发现一致的风格是多么重要。并且不要忘记 styler 包:它是快速提高样式不佳代码质量的好方法。
在下一章中,我们将切换回数据科学工具,学习整理数据。Tidy data 是组织数据框的一致方式,在整个 tidyverse 中使用。这种一致性让您的生活更轻松,因为一旦您拥有整洁的数据,它就可以与绝大多数 tidyverse 函数一起使用。当然,生活从来都不是一帆风顺的,您在野外遇到的大多数数据集都不是整洁的。因此,我们还将教您如何使用 tidyr 包来整理您不整洁的数据。
-
由于
dep_time是HMM或HHMM格式,我们使用整数除法(%/%)得到 hour,使用余数(也称为取模,%%)得到 minute。
--------------- 本章结束 ---------------
本期翻译贡献:
-
@TigerZ生信宝库