JVM字节码文件结构
Class文件结构
class文件是二进制文件,这里要介绍的是这个二级制文件的结构。
思考:一个java文件编译成class文件,如果要描述一个java文件,需要哪些信息呢?
- 基本信息:类名、父类、实现哪些接口、方法个数、每个方法名称和参数和访问属性、每个方法的内容、属性个数、属性名称和类型和访问属性、构造方法。
- 编译信息:编译的JDK版本
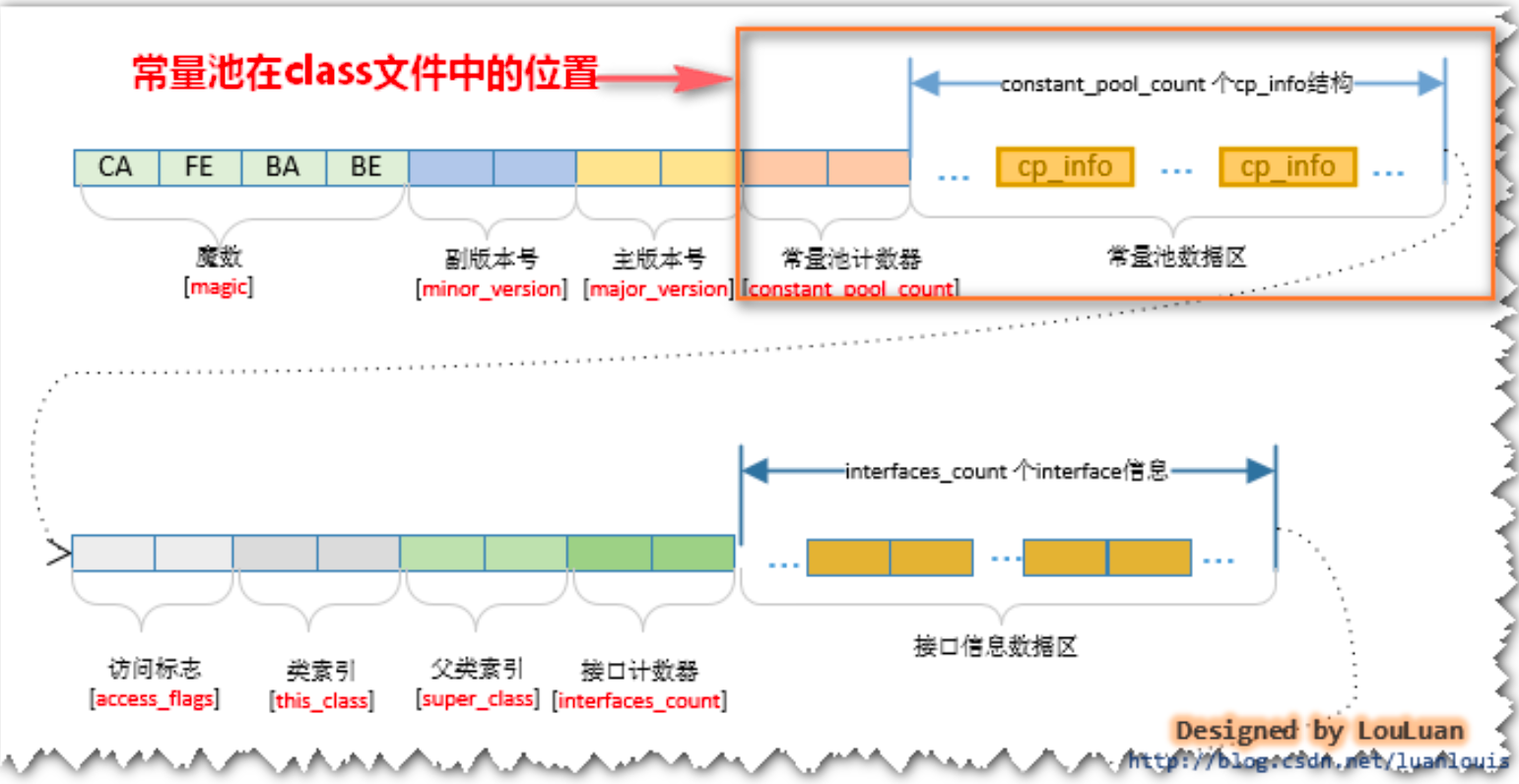
Class文件结构参照表

- 常量池表长度 = constant_pool_count(常量个数) - 1, 原因是 常量池第0个位置被JVM占用了表示为null
Class文件示例分析
.java文件
public class TulingByteCode {private String userName;public String getUserName() {return userName;}public void setUserName(String userName) {this.userName = userName;}
}先将其编译成class文件:javac TulingByteCode.java
再将.class文件反编译:javap -v TulingByteCode.class
.class文件反编译
Classfile /Users/xxxx/Documents/xxx/xxxx/app/test/src/test/java/com/xxxx/xxxxx/TulingByteCode.classLast modified 2025-8-14; size 450 bytesMD5 checksum 9e4f059c2aa6ec60f9c7f0093b58a2f6Compiled from "TulingByteCode.java"
public class com.xxxxx.xxxxxxx.TulingByteCodeminor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPER
Constant pool:#1 = Methodref #4.#17 // java/lang/Object."<init>":()V#2 = Fieldref #3.#18 // com/xxxx/xxxxx/TulingByteCode.userName:Ljava/lang/String;#3 = Class #19 // com/xxxxx/xxxxxxx/TulingByteCode#4 = Class #20 // java/lang/Object#5 = Utf8 userName#6 = Utf8 Ljava/lang/String;#7 = Utf8 <init>#8 = Utf8 ()V#9 = Utf8 Code#10 = Utf8 LineNumberTable#11 = Utf8 getUserName#12 = Utf8 ()Ljava/lang/String;#13 = Utf8 setUserName#14 = Utf8 (Ljava/lang/String;)V#15 = Utf8 SourceFile#16 = Utf8 TulingByteCode.java#17 = NameAndType #7:#8 // "<init>":()V#18 = NameAndType #5:#6 // userName:Ljava/lang/String;#19 = Utf8 com/xxxx/xxxxxx/TulingByteCode#20 = Utf8 java/lang/Object
{public com.xxxxx.xxxxxx.TulingByteCode();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 7: 0public java.lang.String getUserName();descriptor: ()Ljava/lang/String;flags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: getfield #2 // Field userName:Ljava/lang/String;4: areturnLineNumberTable:line 11: 0public void setUserName(java.lang.String);descriptor: (Ljava/lang/String;)Vflags: ACC_PUBLICCode:stack=2, locals=2, args_size=20: aload_01: aload_12: putfield #2 // Field userName:Ljava/lang/String;5: returnLineNumberTable:line 15: 0line 16: 5
}
SourceFile: "TulingByteCode.java".class文件二进制
部分截图如下:
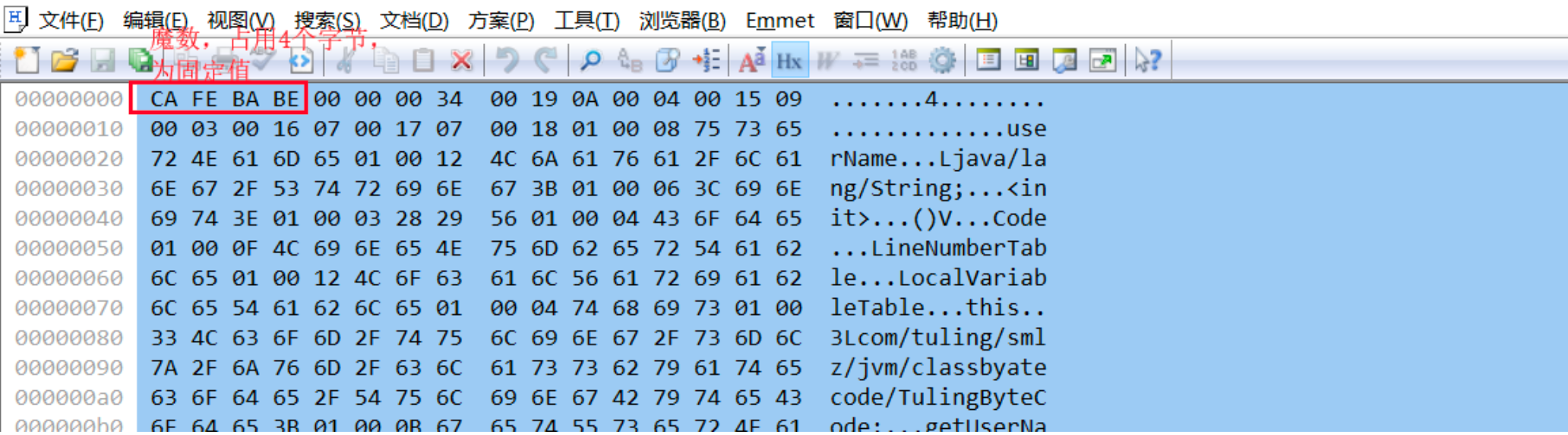
.class文件分析
1. 常量池入口
第一行 00 09
常量池入口(常量个数),占用二个字节,表示常量池中的个数=00 19 (25)-1=24个, 为啥需要-1,因为常量池中的第0个位置被JVM占用了表示为null ,所以编译出来的常量池索引是从1开始的.
对应的.class反编译结果中,常量池有24个,索引从1开始。
2. 常量池类
JVM数据类型
JVM表示数据类型时,表示数据类型时有自己的规范。
基本参数类型和void类型都是用一个大写的字符来表示,对象类型是通过一个大写L加全类名表示,这么做的好处就是在保证jvm能读懂class文件的情况下尽量的压缩class文件体积.
基本数据类型表示:
- B---->byte
- C---->char
- D---->double
- F----->float
- I------>int
- J------>long
- S------>short
- Z------>boolean
- V------->void
对象类型:
- String------>Ljava/lang/String;(后面有一个分号)
对于数组类型: 每一个唯独都是用一个前置 [ 来表示比如:
- int[] ------>[ I,
- String [][]------>[[Ljava.lang.String;
用描述符来描述方法,先参数列表,后返回值的格式,参数列表按照严格的顺序放在()中。
比如源码 String getUserInfoByIdAndName(int id,String name) 的方法描述符号(I,Ljava/lang/String;)Ljava/lang/String;
常量池类型分类
u1,u2,u4,u8分别代表1个字节,2个字节,4个字节,8个字节的无符号数。
规范性的数据,暂时不全列出来了, 举个栗子吧
| 常量 | 项目 | 类型 | 描述 |
| CONSTANT_Utf8_info | tag | u1 | 值为1 |
| length | u2 | UTF-8编码的字符串占用的字节数 | |
| bytes | u1 | 长度为length的UTF-8编码的字符串 | |
| CONSTANT_Methodref_info | tag | u1 | 值为10 |
| class_index | u2 | 指向声明方法的类描述符CONSTANT_Class_info的索引项 | |
| name_and_type_index | u2 | 指向名称和类型描述符CONSTANT_NameAndType 的索引项 |
分析常量池的第一个常量:
- class_index 00 04 : 二个字节表示的是是方法所在类 指向常量池的索引位置为#4,然后我们发现#4的常量类型是Class,也是符号引用类型,指向常量池#24的位置,而#24是的常量池类型是字面量值为:java/lang/Object
- name_and_type_index 00 15:二个字节表示是方法的描述符,指向常量池索引#21的位置,我们发现#21的常量类型是"NameAndType类型"属于引用类型,指向常量池的#7 #8位置,#7常量类型是UTF-8类型属于字面量值为:<init> 构造方法, #8常量也是UTF-8类型的字面量值为:()V
所以常量池中的第一个常量是:java/lang/Object."<init>":()V
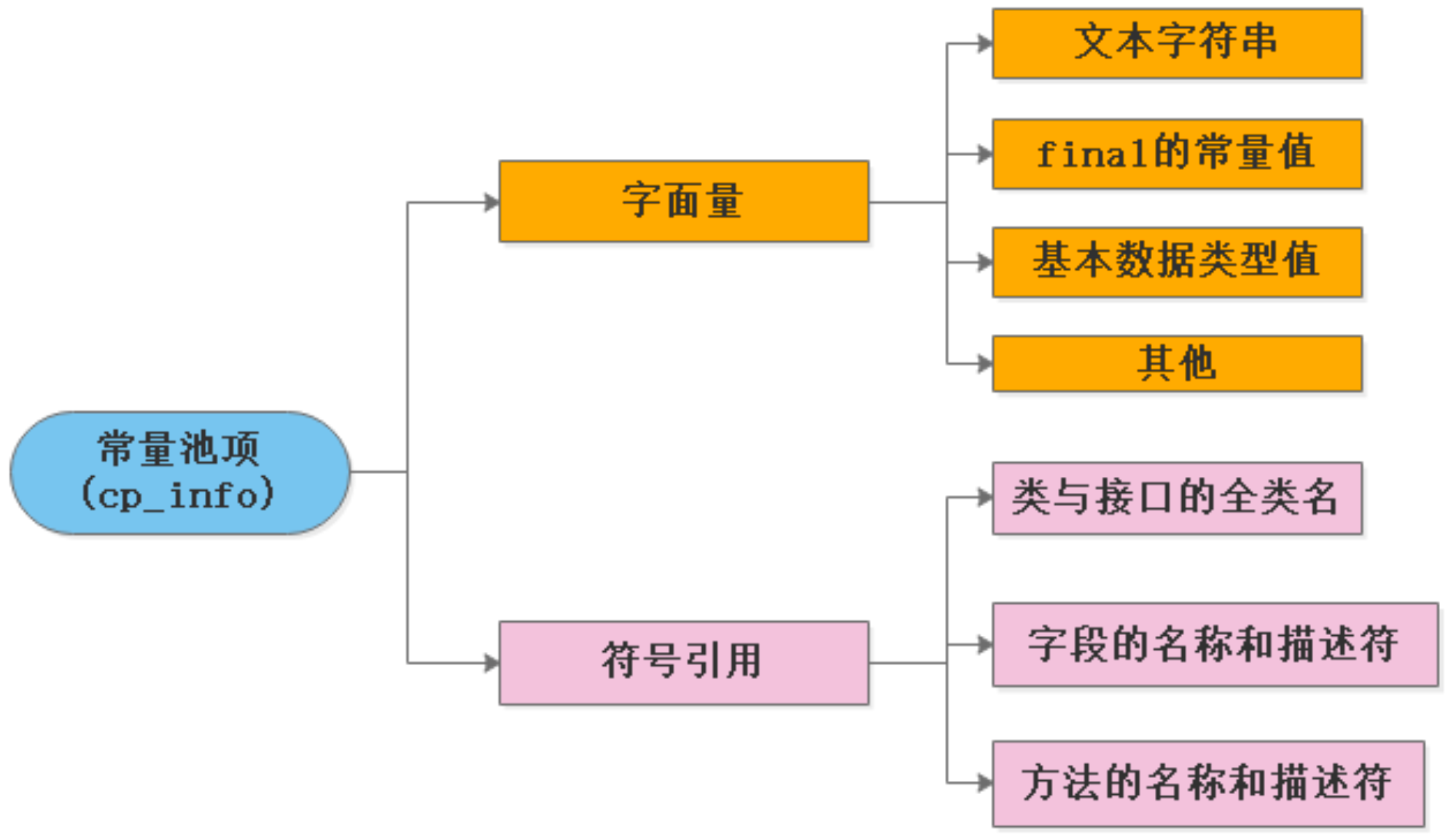
常量池可以看作java class类的一个资源仓库(比如Java类定的方法和变量信息),我们后面的方法 类的信息的描述信息都是通过索引去常量池中获取。
常量池中主要存放两种常量,一种是字面量 ,一种是符号引用。
编译的时候确认局部变量表的长度
