【第13话:泊车感知】场景检测与分割:自主泊车场景中的检测及语义分割方法
自主泊车场景中的检测及语义分割方法
泊车库位线检测是自动泊车系统中的核心任务,旨在从车辆摄像头图像中识别停车位边界和可行驶区域。该方法分为三个步骤:图像IPM投影、检测模型与分割模型结合检测库位线、后处理形成库位实例及可行驶区域。下面我将逐步详细解释每个步骤,确保内容结构清晰、专业可靠。
第一步:图像IPM投影
IPM(逆透视映射)投影是将透视图像转换为鸟瞰视图的关键预处理步骤。在泊车场景中,原始图像存在透视变形(如近大远小效应),这会影响库位线的准确检测。IPM通过消除透视变形,生成一个无畸变的俯视图(鸟瞰图),便于后续处理。

得到:

- 原理:IPM基于相机几何模型,使用单应性矩阵HHH将图像点(u,v)(u,v)(u,v)映射到世界坐标(x,y)(x,y)(x,y)。公式如下:
[x′y′w′]=H[uv1] \begin{bmatrix} x' \\ y' \\ w' \end{bmatrix} = H \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} x′y′w′=Huv1
归一化后得(x,y)=(x′/w′,y′/w′)(x,y) = (x'/w', y'/w')(x,y)=(x′/w′,y′/w′)。其中,HHH是3×33 \times 33×3矩阵,由相机内参(如焦距fx,fyf_x, f_yfx,fy)和外参(如俯仰角θ\thetaθ)计算得出,确保映射后图像保持比例一致。 - 实现:通常,先校准相机获取参数,然后应用变换。以下是一个简化的Python实现示例:
import cv2
import numpy as npdef ipm_projection(image, camera_matrix, rotation_matrix, translation_vector):# 计算单应性矩阵HH, _ = cv2.findHomography(camera_matrix, np.dot(rotation_matrix, camera_matrix) + translation_vector)# 应用IPM变换birdseye_view = cv2.warpPerspective(image, H, (image.shape[1], image.shape[0]))return birdseye_view
此步骤输出鸟瞰图像,作为后续模型的输入。
第二步:检测模型+分割模型检测库位线
在IPM投影后的鸟瞰图像上,结合目标检测模型和语义分割模型来精确识别库位线。检测模型定位库位线的位置(如边界框),分割模型提供像素级精度的掩码,两者结合提高鲁棒性和准确性。
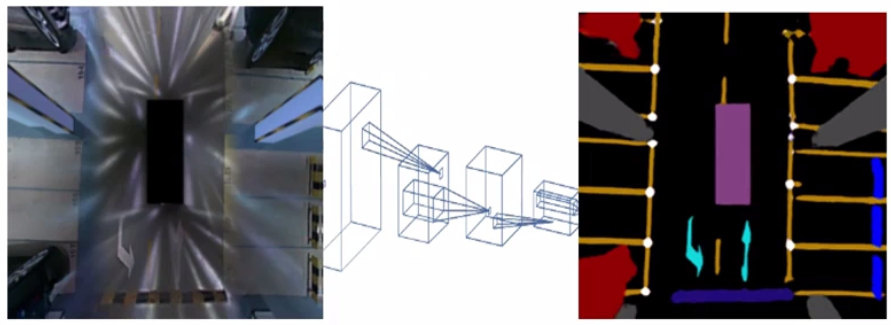
-
检测模型:采用基于卷积神经网络(CNN)的目标检测器,如YOLO或Faster R-CNN。模型输出库位线的候选区域,例如边界框坐标和置信度分数。损失函数常用交叉熵损失Ldet=−∑ylog(y^)L_{det} = -\sum y \log(\hat{y})Ldet=−∑ylog(y^),其中yyy是真实标签,y^\hat{y}y^是预测概率。
-
分割模型:使用语义分割模型(如U-Net或DeepLab),输出每个像素的类别概率(例如,库位线像素 vs. 背景)。模型架构通常包含编码器-解码器结构,优化分割精度。输出为概率图P(line∣x,y)P(\text{line}|x,y)P(line∣x,y)。
-
结合方式:检测模型先提供粗定位(减少搜索空间),分割模型在此基础上细化边缘。例如:
- 输入:IPM图像。
- 检测模型输出候选框。
- 分割模型仅在候选框内运行,生成掩码。
- 最终融合:非极大值抑制(NMS)去除冗余,输出二值掩码表示库位线区域。
以下是一个伪代码示例:
import torch
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.segmentation import deeplabv3_resnet50def detect_and_segment(ipm_image):# 检测模型:输出边界框detection_model = fasterrcnn_resnet50_fpn(pretrained=True)detections = detection_model(ipm_image)boxes = detections[0]['boxes']# 分割模型:在检测框内运行segmentation_model = deeplabv3_resnet50(pretrained=True)mask = segmentation_model(ipm_image)['out']# 融合输出:二值掩码line_mask = (mask > 0.5).float() # 阈值化return line_mask
此步骤输出库位线的精确掩码图像。
第三步:后处理形成库位实例及可行驶区域
后处理步骤将分割掩码转换为结构化输出:库位实例(每个停车位的边界)和可行驶区域(车辆可移动的安全区)。这涉及几何处理和规则推理。
-
形成库位实例:
- 从掩码中提取库位线轮廓(如使用边缘检测算法)。
- 拟合多边形:例如,通过霍夫变换检测直线,然后连接成闭合多边形。每个多边形定义一个停车位边界,顶点坐标表示为{(x1,y1),(x2,y2),… }\{(x_1,y_1), (x_2,y_2), \dots\}{(x1,y1),(x2,y2),…}。
- 实例化:为每个停车位分配唯一ID,并计算属性如面积AAA和方向角θ\thetaθ。
-
形成可行驶区域:
- 基于库位实例和障碍物信息(如从分割模型中获取),推理可行驶区。例如:
- 库位线内部为停车位(不可行驶)。
- 库位线之间或外部区域为可行驶路径。
- 输出为二值掩码或区域多边形,确保连通性分析(如使用形态学操作)。
- 基于库位实例和障碍物信息(如从分割模型中获取),推理可行驶区。例如:
以下是一个后处理伪代码示例:
import cv2
import numpy as npdef postprocess(line_mask):# 提取轮廓并拟合多边形contours, _ = cv2.findContours(line_mask.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)parking_slots = []for cnt in contours:approx = cv2.approxPolyDP(cnt, 0.02 * cv2.arcLength(cnt, True), True)if len(approx) >= 4: # 至少4点形成车位parking_slots.append(approx)# 创建可行驶区域掩码:假设背景为可行驶driveable_mask = np.ones_like(line_mask) - line_maskreturn parking_slots, driveable_mask
最终输出包括库位实例列表和可行驶区域掩码,可直接用于泊车控制。
总结
该方法通过IPM投影消除透视变形,结合检测和分割模型提升库位线识别精度,并通过后处理生成结构化输出。整体流程高效可靠,适用于实时泊车系统。实际应用中,需根据场景调整模型参数(如使用真实数据集训练),以确保鲁棒性。
我还准备了一些用于学习训练的数据集,你们想要吗?