联通用户管理系统(二)
靓号界面开发
上上篇文章没有处理的问题,在这里给出解决,对用户的编辑和删除给出方法。
1、 编辑用户
-
点击编辑,跳转到编辑页面(将编辑行的ID携带过去)。
-
编辑页面(默认数据,根据ID获取并设置到页面中)
-
提交:
-
错误提示
-
数据校验
-
在数据库更新
models.UserInfo.filter(id=4).update(...)
-
def user_edit(request,nid):
"""编辑用户"""
row_object = models.UserInfo.objects.filter(id=nid).first()
if request.method == "GET":
"""设置编辑界面每一项的默认值,根据id去数据库获取要编辑的哪一行数据"""
form = UserModelForm(instance=row_object)
return render(request, 'user_edit.html', {'form':form})
# 要指明将数据更新到nid中,否则mdelform会在list中新增一个数据
form = UserModelForm( data = request.POST, instance = row_object)
if form.is_valid():
# 默认保存的是用户输入的所有数据,如果想要在用户输入以外增加一点值
# form.instance.字段名 = 值
form.save()
return redirect("/user/list/")
return render(request, 'user_edit.html', {'form':form})
2、删除
def user_delete(request,nid):
models.UserInfo.objects.filter(id=nid).delete()
return redirect("/user/list/")
一、靓号管理
1.1 表结构

根据表结构的需求,在models.py中创建类(由类生成数据库中的表)。
class PrettyNum(models.Model):
""" 靓号表 """
mobile = models.CharField(verbose_name="手机号", max_length=11)
# 想要允许为空 null=True, blank=True
price = models.IntegerField(verbose_name="价格", default=0)
level_choices = (
(1, "1级"),
(2, "2级"),
(3, "3级"),
(4, "4级"),
)
level = models.SmallIntegerField(verbose_name="级别", choices=level_choices, default=1)
status_choices = (
(1, "已占用"),
(2, "未使用")
)
status = models.SmallIntegerField(verbose_name="状态", choices=status_choices, default=2)
自己在数据模拟创建一些数据:
insert into app01_prettynum(mobile,price,level,status)values("111111111",19,1,1);
mysql> select * from app01_prettynum;
+----+-----------+-------+-------+--------+
| id | mobile | price | level | status |
+----+-----------+-------+-------+--------+
| 1 | 111111111 | 19 | 1 | 1 |
| 2 | 111111111 | 19 | 1 | 1 |
| 3 | 111111111 | 19 | 1 | 1 |
| 4 | 111111111 | 19 | 1 | 1 |
+----+-----------+-------+-------+--------+
4 rows in set (0.01 sec)
1.2 靓号列表
-
URL
-
函数
-
获取所有的靓号
-
结合html+render将靓号罗列出来
id 号码 价格 级别(中文) 状态(中文)
-
1.3 新建靓号
-
列表点击跳转:
/mobile/add/ -
URL
-
ModelForm类
from django import forms class MobileModelForm(forms.ModelForm): ...
class MobileModelForm(forms.ModelForm):
#使用正则表达式,检验号码是否输入合法
mobile = forms.CharField(
label = "手机号",
validators=[RegexValidator(r'^1[3-9]\d{9}$', '手机号格式错误')],
)
class Meta:
model = models.MobileInfo
##fields = ["mobile", "price", "level", "status"]
fields = '__all__'
# 或则排除那个字段
# exclude =['lecvel']
# 添加bootstrap样式
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
#循环找到所有的插件,添加class=“”样式
for name, field in self.fields.items():
field.widget.attrs = {'class': 'form-control', 'placeholder': field.label}
## 判断手机号是否重复
def clean_mobile(self):
txt_mobile = self.cleaned_data['mobile'] # 获取用户提交的手机号
exists = models.MobileInfo.objects.filter(mobile=txt_mobile).exists() # 正确调用 exists 方法
if exists:
raise ValidationError("手机号已存在") # 如果手机号已经存在,抛出验证错误
return txt_mobile
-
函数
- 实例化类的对象
- 通过render将对象传入到HTML中。
- 模板的循环展示所有的字段。
-
点击提交
- 数据校验
- 保存到数据库
- 跳转回靓号列表
图片中给出两种验证手机号是否合法的方式:

- 代码解析:
mobile = forms.CharField(
label="手机号", # 标签,显示在表单中,用来告诉用户这个字段代表的是手机号
validators=[RegexValidator(r'^1[3-9]\d{9}$', '手机号格式错误')], # 正则验证器
)
forms.CharField:
forms.CharField是 Django 中用于接收字符串输入的表单字段类型。- 它通常用于接收文本数据,像是用户名、手机号等。
这里,mobile 字段的类型是 CharField,意味着它会接收用户输入的手机号作为字符串。
label="手机号":
label是表单字段的标签,表示这个字段的名称,用于向用户描述这个字段的含义。在渲染表单时,label会显示在字段上方或旁边。- 这里的标签是
"手机号",表示这个字段用于输入手机号。
validators=[RegexValidator(r'^1[3-9]\d{9}$', '手机号格式错误')]:
validators是用于字段的验证器。它接受一个列表,其中每个元素都是一个验证函数或验证类。在这里,使用的是RegexValidator。RegexValidator是一个正则表达式验证器,用于根据给定的正则表达式规则验证输入值。
具体来说:
r'^1[3-9]\d{9}$':这是一个正则表达式,用于验证输入的手机号是否符合中国大陆的手机号格式。其含义已经在之前的回答中解释过了,验证规则是手机号以1开头,第二位是3-9之间的任意数字,接下来是 9 个数字。'手机号格式错误':这是当用户输入的手机号不符合正则表达式规则时显示的错误消息。若手机号格式不对,Django 会返回这个错误信息给用户。
正则表达式的含义
^:表示字符串的开始。1:手机号的第一位必须是1。[3-9]:手机号的第二位必须是3-9中的任何一个数字。\d{9}:接下来的 9 位必须是数字(\d表示数字,{9}表示正好 9 个数字)。$:表示字符串的结束。
1.4 编辑靓号
- 列表页面:
/mobile/数字/edit/ - URL
- 函数
- 根据ID获取当前编辑的对象
- ModelForm配合,默认显示数据。
- 提交修改。
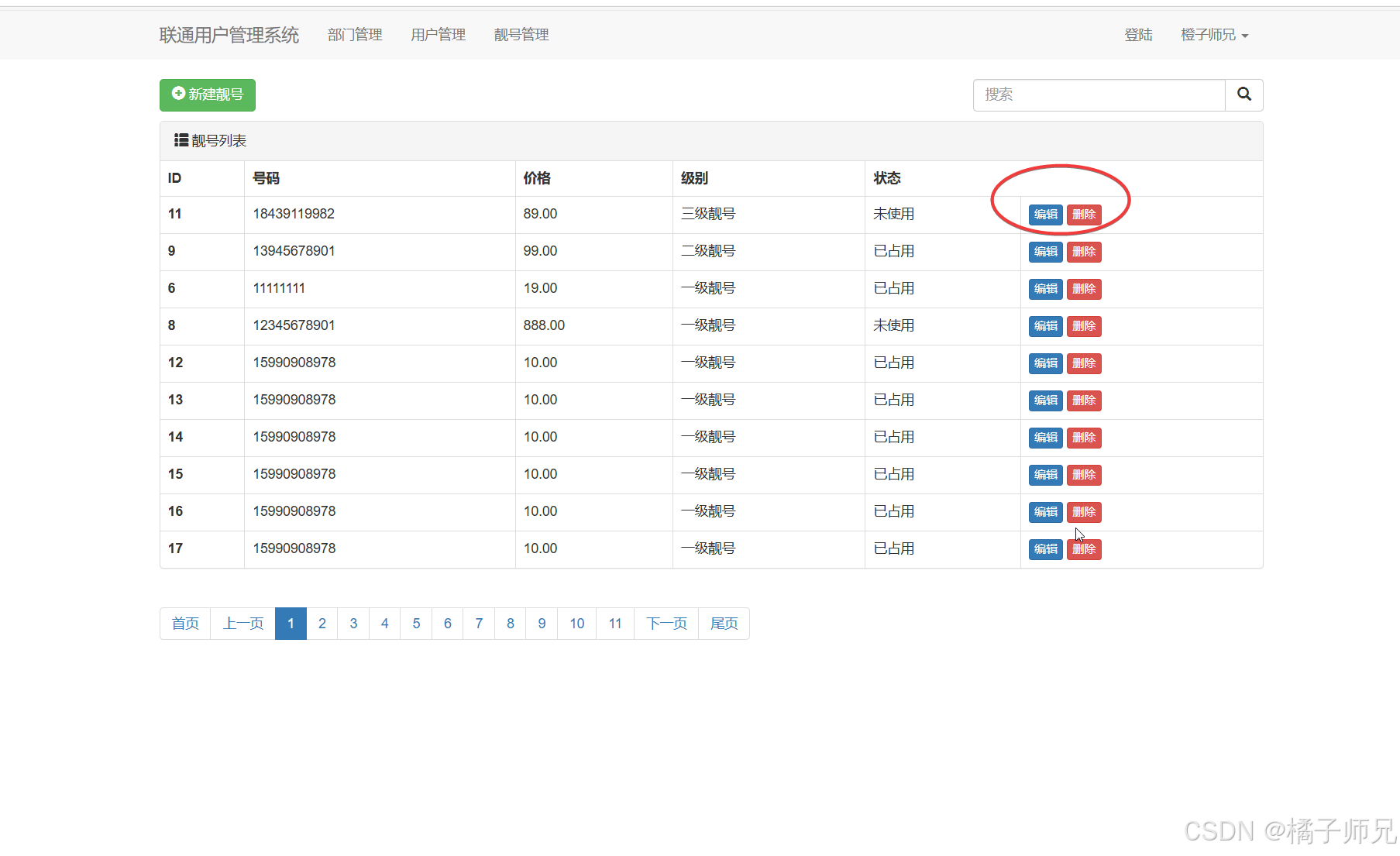
不允许手机号重复。
-
添加:【正则表达式】【手机号不能存在】
# [obj,obj,obj] queryset = models.PrettyNum.objects.filter(mobile="1888888888") obj = models.PrettyNum.objects.filter(mobile="1888888888").first() # True/False exists = models.PrettyNum.objects.filter(mobile="1888888888").exists()
## 判断手机号是否重复
def clean_mobile(self):
txt_mobile = self.cleaned_data['mobile'] # 获取用户提交的手机号
exists = models.MobileInfo.objects.filter(mobile=txt_mobile).exists() # 正确调用 exists 方法
if exists:
raise ValidationError("手机号已存在") # 如果手机号已经存在,抛出验证错误
return txt_mobile
1.5 搜索手机号
models.PrettyNum.objects.filter(mobile="19999999991",id=12)
data_dict = {"mobile":"19999999991","id":123}
models.PrettyNum.objects.filter(**data_dict)
models.PrettyNum.objects.filter(id=12) # 等于12
models.PrettyNum.objects.filter(id__gt=12) # 大于12
models.PrettyNum.objects.filter(id__gte=12) # 大于等于12
models.PrettyNum.objects.filter(id__lt=12) # 小于12
models.PrettyNum.objects.filter(id__lte=12) # 小于等于12
data_dict = {"id__lte":12}
models.PrettyNum.objects.filter(**data_dict)
models.PrettyNum.objects.filter(mobile="999") # 等于
models.PrettyNum.objects.filter(mobile__startswith="1999") # 筛选出以1999开头
models.PrettyNum.objects.filter(mobile__endswith="999") # 筛选出以999结尾
models.PrettyNum.objects.filter(mobile__contains="999") # 筛选出包含999
data_dict = {"mobile__contains":"999"}
models.PrettyNum.objects.filter(**data_dict)
在靓号列表函数中的如下代码便是此功能共:
data_dict = {}
search_data = request.GET.get('q', "")
if search_data:
data_dict['mobile__contains'] = search_data
搜索框提交发出q请求,search_data接受请求,并将内容存放在data_dict中,之后在返回HTML界面显示符合条件的搜索结果
context = {
'queryset': page_queryset, # 分完页的数据
"search_data": search_data,
"page_string": page_string # 页码
}
return render(request, 'mobile_list.html', context)
1.6 分页(使用公共组件)
在上一篇文章中,我们已将介绍了分页组件的使用方法:在这一我们不再重新开发:
下面是分页组件:存放在如图位置即可:
""""
自定义分页组件,之后如果想使用这个分页组件,你需要做如下的事情:
在视图函数中:
def mobile_list(request):
# 1. 筛选自的情况去筛选自己的数据
queryset = models.MobileInfo.objects.filter。all()
# 2. 实例化分页对象
page_object = Pagination(request,queryset)
context = {
'queryset': page_object.page_queryset, # 分完页的数据
"page_string": page_object.html() # 生成所有的页码
}
return render(request, 'mobile_list.html', context)
在HTML页面中进行如下编写
// 数据的循环展示
{% for obj in queryset %}
{{ obj.id }}
{% endfor %}
// 页码的展示
<ul class="pagination">
{{ page_string }}
</ul>
"""
from django.utils.safestring import mark_safe
import copy
class Pagination(object):
def __init__(self, request, queryset, page_size=10, page_param="page", plus=5):
"""
:param request: 请求对象
:param queryset: 查询数据(根据此进行分页)
:param page_size: 每页多少条数据
:param page_param: URL 参数中的分页参数
:param plus: 当前页前后显示几页
"""
query_dict = copy.deepcopy(request.GET)
query_dict.mutable = True
self.query_dict = query_dict
self.params = page_param
page = request.GET.get(page_param, 1)
if str(page).isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.page_size = page_size
self.start = (page - 1) * page_size
self.end = page * page_size
self.page_queryset = queryset[self.start:min(self.end, len(queryset))]
# 计算总页数
total_count = queryset.count()
self.total_page_count = (total_count + page_size - 1) // page_size
self.plus = plus
# # 总页码
# total_count = queryset.count()
# total_page_count, div = divmod(total_count, page_size) ## divmod返回商和余数
# if div:
# total_page_count += 1
# self.total_page_count = total_page_count
# self.plus = plus
def html(self):
# 计算页码区间
if self.total_page_count <= 2 * self.plus + 1:
start_page = 1
end_page = self.total_page_count
else:
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
if (self.page + self.plus) > self.total_page_count:
start_page = self.total_page_count - 2 * self.plus
end_page = self.total_page_count
else:
start_page = self.page - self.plus
end_page = self.page + self.plus
# 页码生成
page_str_list = []
self.query_dict.setlist(self.params, [1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>'
page_str_list.append(prev)
# 上一页
if self.page > 1:
self.query_dict.setlist(self.params, [self.page - 1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">上一页</a></li>'
else:
self.query_dict.setlist(self.params, [1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">上一页</a></li>'
page_str_list.append(prev)
# 页码
for i in range(start_page, end_page + 1):
self.query_dict.setlist(self.params, [i])
if i == self.page:
ele = f'<li class="active"><a href="?{self.query_dict.urlencode()}">{i}</a></li>'
else:
ele = f'<li><a href="?{self.query_dict.urlencode()}">{i}</a></li>'
page_str_list.append(ele)
# 下一页
if self.page < self.total_page_count:
self.query_dict.setlist(self.params, [self.page + 1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">下一页</a></li>'
else:
self.query_dict.setlist(self.params, [end_page])
prev = f'<li><a href="?{self.query_dict.urlencode()}">下一页</a></li>'
page_str_list.append(prev)
# 尾页
self.query_dict.setlist(self.params, [self.total_page_count])
prev = f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>'
page_str_list.append(prev)
page_string = mark_safe("".join(page_str_list))
return page_string
""""
自定义分页组件,之后如果想使用这个分页组件,你需要做如下的事情:
在视图函数中:
def mobile_list(request):
# 1. 筛选自的情况去筛选自己的数据
queryset = models.MobileInfo.objects.filter。all()
# 2. 实例化分页对象
page_object = Pagination(request,queryset)
context = {
'queryset': page_object.page_queryset, # 分完页的数据
"page_string": page_object.html() # 生成所有的页码
}
return render(request, 'mobile_list.html', context)
在HTML页面中进行如下编写
// 数据的循环展示
{% for obj in queryset %}
{{ obj.id }}
{% endfor %}
// 页码的展示
<ul class="pagination">
{{ page_string }}
</ul>
"""
from django.utils.safestring import mark_safe
import copy
class Pagination(object):
def __init__(self, request, queryset, page_size=10, page_param="page", plus=5):
"""
:param request: 请求对象
:param queryset: 查询数据(根据此进行分页)
:param page_size: 每页多少条数据
:param page_param: URL 参数中的分页参数
:param plus: 当前页前后显示几页
"""
query_dict = copy.deepcopy(request.GET)
query_dict.mutable = True
self.query_dict = query_dict
self.params = page_param
page = request.GET.get(page_param, 1)
if str(page).isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.page_size = page_size
self.start = (page - 1) * page_size
self.end = page * page_size
self.page_queryset = queryset[self.start:min(self.end, len(queryset))]
# 计算总页数
total_count = queryset.count()
self.total_page_count = (total_count + page_size - 1) // page_size
self.plus = plus
# # 总页码
# total_count = queryset.count()
# total_page_count, div = divmod(total_count, page_size) ## divmod返回商和余数
# if div:
# total_page_count += 1
# self.total_page_count = total_page_count
# self.plus = plus
def html(self):
# 计算页码区间
if self.total_page_count <= 2 * self.plus + 1:
start_page = 1
end_page = self.total_page_count
else:
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
if (self.page + self.plus) > self.total_page_count:
start_page = self.total_page_count - 2 * self.plus
end_page = self.total_page_count
else:
start_page = self.page - self.plus
end_page = self.page + self.plus
# 页码生成
page_str_list = []
self.query_dict.setlist(self.params, [1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>'
page_str_list.append(prev)
# 上一页
if self.page > 1:
self.query_dict.setlist(self.params, [self.page - 1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">上一页</a></li>'
else:
self.query_dict.setlist(self.params, [1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">上一页</a></li>'
page_str_list.append(prev)
# 页码
for i in range(start_page, end_page + 1):
self.query_dict.setlist(self.params, [i])
if i == self.page:
ele = f'<li class="active"><a href="?{self.query_dict.urlencode()}">{i}</a></li>'
else:
ele = f'<li><a href="?{self.query_dict.urlencode()}">{i}</a></li>'
page_str_list.append(ele)
# 下一页
if self.page < self.total_page_count:
self.query_dict.setlist(self.params, [self.page + 1])
prev = f'<li><a href="?{self.query_dict.urlencode()}">下一页</a></li>'
else:
self.query_dict.setlist(self.params, [end_page])
prev = f'<li><a href="?{self.query_dict.urlencode()}">下一页</a></li>'
page_str_list.append(prev)
# 尾页
self.query_dict.setlist(self.params, [self.total_page_count])
prev = f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>'
page_str_list.append(prev)
page_string = mark_safe("".join(page_str_list))
return page_string
之后根据组件的使用方法,在靓号列表函数中使用:
## 导入自己编写的类,方便分页的代码重复编写
from app01.utils.pagination import Pagination
queryset = models.MobileInfo.objects.filter(**data_dict).order_by('-level')
page_object = Pagination(request,queryset)
page_queryset = page_object.page_queryset
page_string = page_object.html()
context = {
'queryset': page_queryset, # 分完页的数据
"search_data": search_data,
"page_string": page_string # 页码
}
return render(request, 'mobile_list.html', context)
- 分页的逻辑和处理规则
- 封装分页类
- 从头到尾开发
- 写项目用【pagination.py】公共组件。