Open-Source Agentic Hybrid RAG Framework for Scientific Literature Review
Open-Source Agentic Hybrid RAG Framework for Scientific Literature Review
Authors: Aditya Nagori, Ricardo Accorsi Casonatto, Ayush Gautam, Abhinav Manikantha Sai Cheruvu, Rishikesan Kamaleswaran
Deep-Dive Summary:
开源代理混合RAG框架用于科学文献综述
摘要
科学出版物的激增对传统文献综述提出了挑战,需要整合结构化元数据和全文分析的工具。混合检索增强生成(Hybrid Retrieval Augmented Generation, RAG)系统结合了图查询和向量搜索,但通常是静态的(每个提示使用固定流程),依赖于专有服务,并且缺乏不确定性估计。在这项工作中,我们开发了一种代理方法,将混合RAG流程封装在一个自主代理中,该代理能够:(1) 动态推理出哪种检索模式——GraphRAG或VectorRAG——最适合每个查询;(2) 根据研究人员的需求即时调整指令调优生成;(3) 在运行时纳入不确定性量化。这种动态编排提高了相关性,减少了幻觉,并确保了透明、可重复的工作流程。系统利用ArXiv和Google Scholar API,构建了一个包含引用关系的Neo4j知识图谱(KG),并使用all-MiniLM-L6-v2模型将公开可用的全文PDF嵌入到FAISS向量存储(VS)中。Llama-3.3-70B-versatile代理动态地在GraphRAG(将用户查询转换为对KG的Cypher搜索)和VectorRAG(结合稀疏和密集检索方法并重新排序以提供相关信息)之间进行选择。指令调优优化了领域特定的生成,通过自举评估(12次重采样)计算评估指标的标准差。代理系统的有效性通过针对现实场景定制的合成基准进行评估。采用直接偏好优化(DPO)的指令调优代理在性能上显著优于基线检索系统,在VS上下文召回率上提升了0.63,在整体上下文精度上提升了0.56。其他改进包括:VS忠实度提升0.24,VS精度和KG答案相关性均提升0.12,整体忠实度评分提升0.11,KG上下文召回率提升0.05,以及VS答案相关性和整体精度均提升0.04。这些改进凸显了模型在从异构来源检索、推理和整合信息方面的增强能力。通过动态选择最佳检索路径并量化不确定性,我们的开源框架显著提高了文献探索的准确性和稳健性,为自主代理科学知识发现奠定了可扩展的基础。
CCS概念
- 信息系统 → 信息检索;
- 计算方法论 → 人工智能。
关键词
AI代理,文献综述,图数据库,检索增强生成(RAG),指令调优,合成基准
1 引言
科学文献的数量正以前所未有的速度增长,这使得研究人员越来越难以跟上最新的研究进展。近期文献计量学研究证实,科学出版物的数量激增 [3]。传统的手工文献综述耗时且容易导致信息过载,因为没有个人能够全面阅读和综合每年发表的数百万篇论文。为了减轻这一负担,已经开始利用人工智能来自动化文献综述过程的部分环节。例如,文本挖掘和机器学习技术已被应用于协助系统性综述,通过优先筛选相关引用或甚至自动生成摘要 [1, 8, 37],但这些方法的范围有限,通常依赖于关键词匹配或主题建模,而非真正的内容理解。
与此同时,大型语言模型(LLMs)近期作为文本理解和生成的强大工具崭露头角。理论上,LLMs 能够阅读并总结大量论文,帮助研究人员在充分语境下识别主题和联系。之前的作品显示出对使用 LLMs 简化学术工作流程的日益兴趣 [26]。然而,仍存在重大限制。单独运行的 LLMs——即没有访问外部知识的情况下——常常会产生“幻觉” [9, 17]。这些观察结果强调,仅依靠独立的 LLMs 进行文献综述是危险的,必须将其与可靠的文献检索相结合,以确保准确性和可信度。
另一个重要的发展领域是检索增强生成(RAG),该方法通过将语言模型的输出基于检索到的文档来增强其能力。这种方法已被证明可以提高事实准确性并提供来源出处。例如,[22] 引入了一个 RAG 模型,该模型基于维基百科段落条件化序列到序列生成器,在开放域问答上取得了最先进的结果。类似地,像 Semantic Scholar 这样的工具已开始整合神经检索和摘要,反映出搜索与生成能力相结合的更广泛趋势。尽管有这些进展,当前的系统往往依赖于固定的、一次性的检索流程,并且仅支持单一检索模式——通常是语义向量搜索 [5]。这种僵化限制了它们在处理复杂的科学查询时的有效性,这些查询可能需要结合不同的策略,如引用图遍历或全文语义搜索。此外,许多 AI 驱动的文献工具是专有的或不透明的,这引发了关于可重复性和信任的担忧。
因此,本研究的动机源于三个关键差距:科学文献数量的加速增长、静态流程和手工综述方法的局限性,以及将结构化知识与自适应语言模型相结合以创建强大文献综述助手的未开发机会。本研究的目标是设计一个精确、可解释且自适应的文献综述框架——能够动态编排不同的检索策略,将输出基于最新的来源,量化不确定性,并在最少人工干预的情况下运行。
本文首先介绍了文献综述自动化、检索增强生成和语言模型代理的相关工作背景和综述。方法部分随后介绍了所提出的系统,详细描述了混合检索组件和代理编排框架。实验程序描述了用于测试系统在各种科学信息任务中性能的评估设置。接着呈现并分析结果,随后讨论关键发现、局限性和潜在的改进方向。论文最后概述了对未来研究支持系统的更广泛影响。
2.1 传统文献综述方法
传统文献综述方法,包括系统性综述和元分析,长期以来一直是证据综合的黄金标准。研究人员按照明确定义的协议,精心搜索数据库,筛选成百上千的标题和摘要,从相关研究中提取并比较数据。尽管这一过程非常严谨,但耗时长且容易导致信息过载。科学出版物的数量呈指数级增长,以至于“研究人员无法跟上每年发表的文章数量”[19]。即使是遵循既定指南的系统性综述者,也难以应对需要纳入的大量新文献;一项研究指出,传统的手工方法无法跟上“随之而来的工作量”,导致大多数系统性综述在发表时已部分过时[19]。这种信息过载不仅减缓了综述过程,还增加了遗漏相关信息的风险。
为了应对这一问题,半自动化策略应运而生,以协助进行文献综述。参考管理软件(如EndNote、Zotero)和具有高级查询功能的学术搜索引擎帮助更高效地组织引文和执行关键词搜索。还开发了用于自动标题/摘要筛选和研究选择的工具,例如Rayyan和Abstrackr等应用,它们使用机器学习来优先审查相关的摘要。这些工具可以加速特定步骤,例如过滤明显不相关的论文,但仍面临重大挑战。一项关于系统性综述自动化工具的范围综述发现,许多原型工具(如LitSuggest、RobotAnalyst)在筛选和数据提取方面显示出潜力,“然而,它们并非没有局限性”[15]。许多工具需要技术专长或仅能处理工作流程的一部分。关键的高层次任务——即跨研究综合发现和得出细致结论——仍然需要大量的人力。此外,人的错误和偏见仍然是一个问题:制定全面的搜索查询很困难,即使是小的遗漏也可能导致错过关键研究。事实上,对已发表的系统性综述的分析发现,92.7%的综述存在搜索策略错误,最常见的问题是遗漏相关术语(影响了78%的综述的召回率)[16]。这些发现强调了当前的手工和半自动化方法往往导致综述劳动密集、易出错且可能不完整。
2.2 图数据库在学术研究中的应用
图数据库已成为建模和探索学术数据中关系的重要工具。在基于图的文献表示中,节点可以代表论文、作者、期刊或关键科学概念等实体,而边则捕捉诸如“论文A引用论文B”、“作者X与作者Y合著”或“概念Z与概念Y相关”等关系。这种格式自然反映了学术知识的结构。例如,引用网络形成有向图,作者合作网络形成合著图。知识图谱(KGs)还可以编码更高层次的连接:一个“主题图”可能会将论文与其涉及的科学主题或方法论联系起来。图数据库(如Neo4j)由于其高效的关系遍历能力,非常适合存储和查询此类网络。
在学术研究中使用基于图的模型为文献挖掘和知识发现提供了强大的能力。Iancarelli等人(2022年)构建了人类攻击性研究文献的引用图,以映射其主题结构;他们的分析发现了不同的集群(例如,媒体和视频游戏、激素影响),并找出了连接社区的关键“桥梁”论文[15]。像开放研究知识图谱(ORKG)这样的项目以结构化形式表示论文的核心贡献,使学术知识具有机器可操作性[16]。通过将论文整理成概念和关系的知识图谱,可以查询诸如“哪些试验使用了方法X并取得了结果Y?”的问题——这是无结构文本难以完成的任务。
2.3 RAG(检索增强生成)
大型语言模型(LLMs)展示了生成流畅文本的惊人能力,但其知识受限于训练数据,容易产生幻觉。RAG(检索增强生成)通过外部文档对LLM的输出进行 grounding。在RAG系统中,检索器首先从语料库中获取相关段落,然后生成器基于这些段落生成响应[22]。这种非参数和参数记忆空间的结合显著提高了事实准确性和可追溯性。Lewis等人通过将Wikipedia上的神经段落检索器与序列到序列生成器结合,展示了RAG,使实时事实查找成为可能[22]。实证评估表明,RAG模型生成的语言比类似的非检索模型更具体、多样且符合事实。
在科学领域,RAG已被应用于文献问答和摘要。PaperQA代理使用期刊文章语料库,通过检索和综合相关摘录来回答研究查询,在多文档基准测试中达到了专家级性能[21]。Han等人调查了RAG在自动化系统文献综述中的潜力,强调其能够忠实于源材料地检索和总结关键研究[14]。
2.4 自然语言处理中的指令微调
指令微调通过在指令-响应对数据集上对预训练的大型语言模型(LLMs)进行微调,以提高对用户指令的遵循能力。Wei等人引入了FLAN,通过将T5在作为指令的任务混合上进行微调,在多样化的基准测试中实现了强大的零样本性能[38]。Sanh等人发布了T0,一个在开源提示上训练的110亿参数指令微调模型,展示了强大的跨任务泛化能力[30]。Alpaca基于LLaMA-7B构建,仅使用52K自生成示例就复制了类似GPT-3.5的指令遵循能力[36]。这些模型在科学情境下更好地执行学术任务,如摘要和比较。
2.5 相关方法
Semantic Scholar 等系统将检索和生成以固定顺序结合,通常依赖于专有的 LLM API,并且缺乏不确定性量化。这些系统在初始检索不足时无法适应,也无法提供置信度估计。我们的 Agentic Hybrid RAG 框架通过以下方式解决这些问题:
(1) 动态选择基于图的检索模式和基于向量的检索模式。
(2) 使用经过指令调整的代理来规划和分解查询为工具调用(例如,图查询、向量搜索)。
(3) 在运行时估计不确定性,以标记低置信度或矛盾的结果 [23]。
这种代理方法实现了灵活、透明和可信的 AI 辅助文献综合。
3 方法论
本文提出了一种全新的、完全开源的基于Python的接口,用于从多个电子数据库中提取和结构化数据,并将其同时组织成知识图谱(KG)和向量存储(VS)。这种混合存储架构旨在充分利用基于Cypher的查询和向量搜索的优势,使AI工具代理能够根据给定的提示动态选择最合适的策略。
所提出的流程包括通过问答(QA)格式对出版物进行收集、过滤、预处理和分析的步骤,从而在研究者分享搜索查询(可选日期范围)后,自动从学术文献中收集相关见解。流程的总体概念如图1所示。
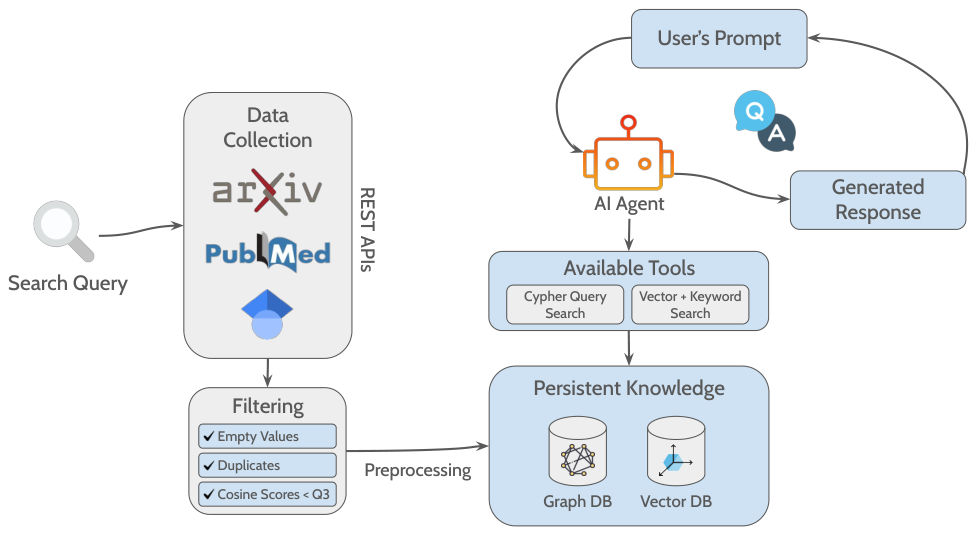
首先,从PubMed、ArXiv和Google Scholar的API中收集公开的文献计量数据。从这些数据库中索引的出版物提取的初始数据包括DOI、标题、摘要、出版年份、作者、PDF链接和来源数据库。然后,将获得的结果整合到一个数据框中,丢弃具有缺失值的条目。随后,还会基于DOI和标题子集删除重复记录。
在过滤阶段,通过对标题和摘要的拼接文本应用TF-IDF向量化器(考虑单词和双词组合),从每篇文章中提取五个关键词。提取的关键词随后通过词干化和小写处理,并用于两个不同的目的:(1) 计算其与初始搜索查询关键词的余弦相似度(CS)分数,(2) 作为单独的节点纳入知识图谱(KG),与其各自的源文章建立一级连接。
余弦相似度(CS)分数计算公式如下:
CS(X,Y)=X⋅Y∥X∥∥Y∥CS(X,Y)={\frac{X \cdot Y}{\|X\|\|Y\|}} CS(X,Y)=∥X∥∥Y∥X⋅Y
其中,X⋅YX \cdot YX⋅Y 表示两个向量的点积,∥X∥=∑i=1Xi2\|X\| = \sqrt{\sum_{i=1} X_i^2}∥X∥=∑i=1Xi2 是向量X的范数,∥Y∥=∑i=1Yi2\|Y\| = \sqrt{\sum_{i=1} Y_i^2}∥Y∥=∑i=1Yi2 是向量Y的范数。CS值的范围在[-1, 1]之间,其中CS=1CS = 1CS=1表示完全一致,CS=−1CS = -1CS=−1表示完全相反。
通过这种方式,仅保留CS分数高于第三四分位数(即分布中前25%)的研究,以确保选择与研究最相关的文献。使用CS分数进行此目的的动机在于其在文献中广泛应用于文本比较和相关性过滤[10, 13, 20, 29]。
在选择出版物后,流程会下载并解析开放获取的全文,将其分块存储为向量存储(VS)中的向量。此外,初始提取的文献计量数据被结构化为知识图谱(KG)中的节点,与其源文章建立直接关系。例外的是标题、DOI和摘要,这些被存储为所属论文节点的属性。对于全文中的参考文献部分,算法会收集可用的DOI,并将其作为单独的节点存储在知识图谱中,从而有效跟踪引用的来源并促进审查论文之间共同引用网络的检测。
设置完成后,基于LLaMA-3.3-70B-versatile模型构建了一个聊天界面,该模型能够调用两种不同的功能:基于Cypher的检索和基于相似度的检索。为确保准确的工具选择,采用了10个少样本示例(每种方法各5个),每个示例展示了完整的推理链:初始用户问题、相应的检索工具、检索到的上下文以及生成的最终答案。这种结构化的提示策略指导代理的决策,并促进不同查询类型的一致性能。
Cypher检索功能能够将问题转换为Cypher查询,然后将其应用于知识图谱(KG)。同时,相似度检索功能采用集成方法,结合语义搜索和关键词搜索并重新排序,以找到与用户问题最相关的文本块。根据代理的决策,适当的功能会检索必要的上下文,并通过Mistral-7B-Instruct-v0.3模型直接生成有意义的答案,从而降低幻觉风险并确保与原始问题的相关性。在消费级机器上,每次查询的延迟约为2分钟,主要是由于硬件限制。然而,当部署在具有GPU加速的合适服务器基础设施上时,延迟显著减少到每次查询约10秒。
3.1 图数据库整合
图知识库(KG)结构因其在从大规模数据中挖掘、组织和管理知识方面的高效性而被选中 [4]。该架构利用数据中已有的关系和层级结构,增强了多跳推理和上下文丰富能力,这对于需要关系理解的任务尤为有用 [32]。图2展示了在开发的KG中实例化的节点和关系的示意图,如单个出版物节点的结构所定义。
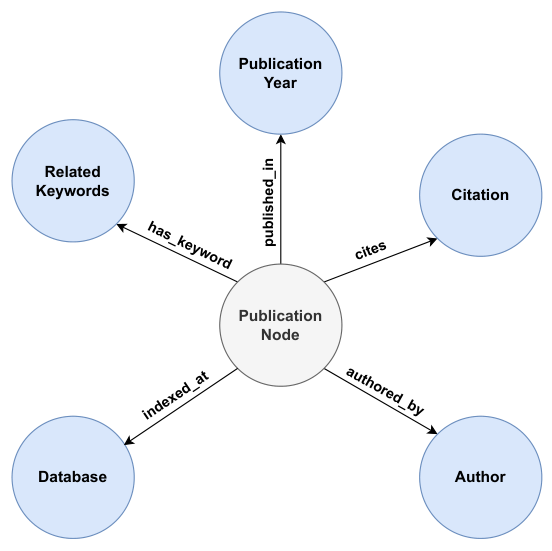
通过该模式,作者、数据库、相关关键词、出版年份和引文等节点可以在多篇文章之间共享,确保文档内创建相互连接的网络。此外,出版物节点包含个体内部属性,如DOI、标题和摘要,可供进一步分析使用。通过在KG中使用文献计量数据,该流程扩展了其对结构和描述属性的全局查询能力,例如作者合作模式、数据库分布、出版时间线和引文关系,从而提供了研究领域的更广泛概览。
3.2 向量数据库整合
向量存储(VS)因其通过使用密集检索模型增强语义理解和上下文感知的能力而被广泛整合到RAG系统中 [32]。这种检索过程本质上是基于相似性的,其中通过计算特征向量之间的相似度分数来量化相似程度 [28]。
遵循这一原则并基于先前的方法,所提出的流程将从论文中提取的文本递归地分割成每批2024个字符的片段,相邻片段之间有50个字符的重叠 [31]。这些片段随后使用all-MiniLM-L6-v2模型进行嵌入,得到的向量通过FAISS库存储和索引,从而实现高效的基于相似性的检索。向量数据库的整合通过支持语义级查询,补充了KG的关系视角,同时也促进了对单个文章内容的深入探索。
3.3 RAG
本文使用了一种中介工具代理,能够动态选择基于图的检索和结合密集与稀疏向量检索及重排的混合策略。通过利用 GraphRAG 和 VectorRAG 的优势,该方法增强了检索和生成性能,根据每个提示的性质调整方法。
3.3.1 GraphRAG
GraphRAG 机制通过利用基于 Cypher 的函数运行,该函数将自然语言查询翻译成 Cypher 查询——一种用于与图数据库交互的声明式图查询语言,然后在 KG 数据库上执行。整体流程如图 3 所示。
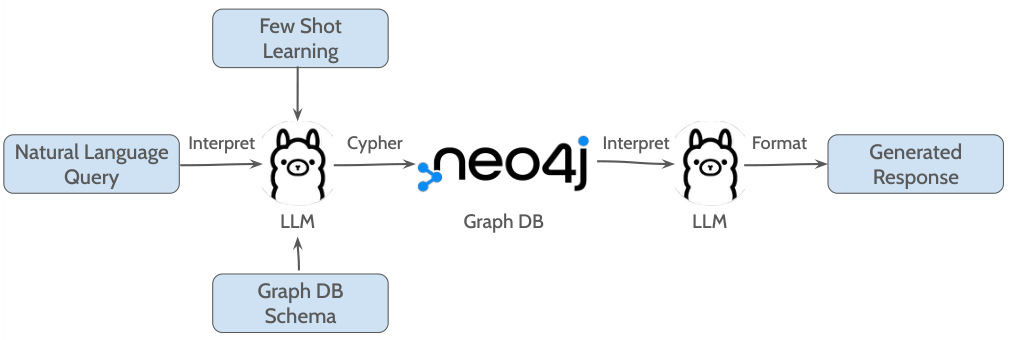
自然语言查询与 KG 模式一起提供给 LLM,同时附带三十个输入-输出示例对,用于指导生成相应的 Cypher 查询。这种策略被称为少样本学习(few-shot learning),有助于更快地进行上下文学习,从而在特定任务上获得更好的性能 [33]。生成后,Cypher 查询在托管于 Neo4j 实例的 KG 上执行,检索结果随后返回给 LLM 进行最终响应格式化。
3.3.2 VectorRAG
与此同时,VectorRAG 功能采用了一种集成检索策略,结合基于关键字的检索器和语义搜索检索器。检索到的文本片段被合并,然后使用 Cohere 的 rerank-english-v3.0 模型根据相关性进行重排。在这一阶段,查询和检索到的段落被连接并由 Cohere 的基于 Transformer 的重排器处理,该重排器在大规模语料库上预训练,通过深度交叉注意力机制分配精细的相关性分数,优先考虑最具信息性的结果,从而提高检索质量 [39]。排名靠前的段落随后作为上下文输入提供给 LLM,生成并格式化最终响应。图 4 展示了工作流程。
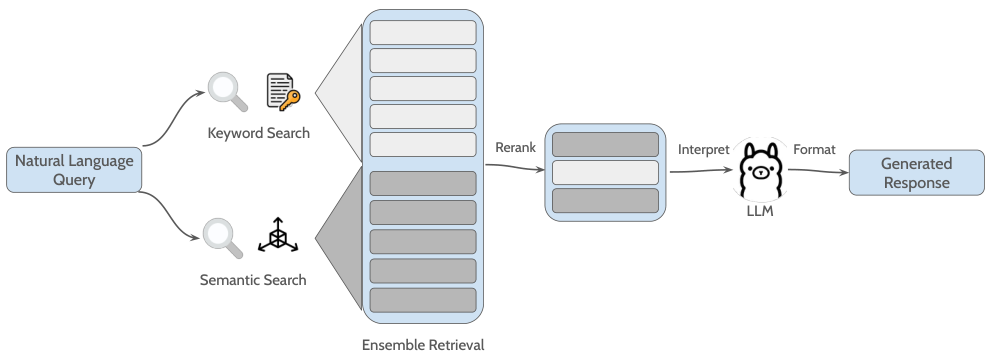
关键字搜索应用了 BM25 算法,该算法将查询和文档视为稀疏的词袋向量,并在词级进行匹配。对于给定的查询 QQQ,每个片段 CCC 的得分计算如下:
BM25(C,Q)=∑w∈QIDF(w)⋅f(w,C)⋅(k1+1)f(w,C)+k1⋅(1−b+b⋅∣C∣avgdl)\mathrm{BM25}(C,Q)=\sum_{w\in Q}\mathrm{IDF}(w)\cdot\frac{f(w,C)\cdot(k_{1}+1)}{f(w,C)+k_{1}\cdot\left(1-b+b\cdot\frac{|C|}{\mathrm{avgdl}}\right)} BM25(C,Q)=w∈Q∑IDF(w)⋅f(w,C)+k1⋅(1−b+b⋅avgdl∣C∣)f(w,C)⋅(k1+1)
其中 f(w,C)f(w, C)f(w,C) 表示词 www 在片段 CCC 中的频率,∣C∣|C|∣C∣ 表示片段中的总词数,avgdl\mathrm{avgdl}avgdl 是集合中平均片段长度。参数 k1k_1k1 和 bbb 是超参数,而 IDF(w)\mathrm{IDF}(w)IDF(w) 是词 www 的逆文档频率,旨在降低常见词的权重。
虽然 BM25 通过精确词匹配有效捕捉词汇相似性,但往往难以处理语言中的语义变化。为了解决这一局限性并增强检索鲁棒性,通常结合稀疏和密集检索器,因为它们往往能互补彼此的优势 [7]。因此,除了稀疏检索方法外,还采用了语义搜索,基于 L2 分数(也称为欧几里得距离)计算两个密集连续语义向量之间的相似性。向量 xxx 和 yyy 之间的 L2 距离定义为:
L2(x,y)=∑i=1n(xi−yi)2L2(x, \mathbf{y})=\sqrt{\sum_{i=1}^{n}(x_{i}-y_{i})^{2}} L2(x,y)=i=1∑n(xi−yi)2
较低的 L2 分数表示较高的语义相似性,意味着查询和候选片段的向量表示在嵌入空间中位置更接近。通过结合稀疏和密集检索策略,该框架结合了稀疏搜索的精确词汇匹配能力和密集搜索的语义表示能力。在这种设置中,两种方法各自独立返回前五个候选片段,随后通过之前提到的重排过程进行排名和压缩,生成最终结果集。
论文总结(中文)及原文格式保留
3.4 直接偏好优化(DPO)
我们将直接偏好优化(DPO)直接应用于RAG管道中的响应生成器,仅使用了15个高质量的人工标注偏好对。这一方法在忠实度和上下文检索指标上均带来了明显的改进,优于未经DPO训练的模型。
DPO明确指导响应生成器优先选择基于检索上下文的答案,直接将模型输出与人类判断对齐。这减少了幻觉现象,并鼓励模型依赖外部证据而非内部知识。即使数据集较小,DPO也能有效引导生成器生成更准确、更具上下文相关性的响应,这解释了在忠实度和上下文利用率方面的显著提升。
3.5 合成基准评估
据我们所知,并与[31]一致,目前尚无公开可用的基准数据集用于评估通用领域中的VectorRAG和GraphRAG方法。因此,我们开发了一个定制数据集。选择合成数据是因为它能够控制问题难度,覆盖广泛的检索场景,同时以较低成本解决真实数据有限可用性的挑战[18]。
合成基准旨在评估两种检索类型的代理框架。它包括只能通过正确工具调用回答的问题,即答案仅存在于向量存储(VS)或知识图谱(KG)中。通过将搜索条件输入管道并选择2023-2025年日期范围,检索到的论文被用于生成40个问答对——20个专门针对VectorRAG,20个针对GraphRAG,从而确保两种检索方法的平衡评估。
4 实验设置
本节详细描述了实验设置,包括评估问题的特征、使用的指标以及实验过程中遵循的程序。
4.1 数据集与基准
4.1.1 VectorRAG基准
为了验证管道的VectorRAG能力,从论文全文提取的最终生成块中随机选择了20个文本块作为样本。每个文本块作为输入提供给LLaMa 3.3实例,并要求其根据提示“生成一个只能从给定上下文中回答的问题。不要创建泛化问题。不要提及具体的图表、表格、章节甚至提供的实际文档。仅关注其内容和主要思想”生成问题,并附带三个输出示例。生成的问答被存储与其对应的文本块一起以供进一步分析。
4.1.2 GraphRAG基准
知识图谱KG = {(s, p, o) | s, o ∈ E, p ∈ R}由事实三元组组成,其中s表示主语,p表示谓语,o表示宾语。所有主语和宾语的集合定义了实体集E,而所有谓语的集合形成了关系集R。在此基础上,设计了五种不同类型的问题以全面评估管道的GraphRAG能力,扩展了[24]提出的四种原始变体。问题类型在表1中描述。
通过随机选择节点和关系,然后使用针对KG中每种问题模式的模板Cypher查询生成结果,为每种问题类型生成了四个样本。生成的问答随后与20个VectorRAG数据点结合,形成了最终测试集。
4.2 评估指标
为了评估所提出框架的有效性,在受控实验设置中对三种方法进行了比较分析:(i) 非代理RAG(Non-Agentic RAG),在向量搜索(VS)和知识图谱(KG)上执行向量搜索并合并结果(作为基线);(ii) 代理RAG(Agentic RAG);(iii) 微调代理RAG(Fine Tuned Agentic RAG)。实施了一套全面的评估指标来捕捉代理输出质量的各个方面,特别关注忠实度(Faithfulness)、答案相关性(Answer Relevance)、上下文精度(Context Precision)和上下文召回率(Context Recall)[12]。每个指标提供了对系统优势和局限性的不同见解。
忠实度(F)衡量生成答案在所提供上下文中的依据程度。为了计算此指标,从生成的答案中提取语句,并与检索到的上下文进行比较。最终分数计算为F=(此处原文未完整提供具体公式),其中涉及上下文支持的语句数量与总语句数量的比值。
答案相关性(AR)量化答案对原始问题的有效回应程度。方法包括仅基于答案生成辅助问题(qi),然后计算它们与原始问题(q)的相似度分数。AR反映了生成答案与初始查询的对齐程度。上下文精度(CP)评估检索到的上下文元素对支持生成答案的相关性,具体来说,它衡量排名靠前的上下文块中相关项目的比例。上下文精度在K处的定义如下,其中K表示考虑的上下文块数量,uk是排名k处的相关性指标:
∑k=1K(Precision(ωˉ)k×vk)\textstyle\sum_{k=1}^{K}\,(\mathrm{Precision}(\bar{\omega})\mathrm{k}\times v_{k}) ∑k=1K(Precision(ωˉ)k×vk)
Precision(ωk=truepositives(ωktruepositives(ωk+falsepositives(ωk){\mathrm{Precision}}(\omega\mathbf{k}={\frac{{\mathrm{true~positives}}(\omega\mathbf{k}}{{\mathrm{true~positives}}(\omega\mathbf{k}+{\mathrm{false~positives}}(\omega\mathbf{k}})} Precision(ωk=true positives(ωk+false positives(ωktrue positives(ωk)
最后,上下文召回率(CR)检查是否充分涵盖了相关信息,识别是否有重要元素被遗漏。具体来说,它评估检索到的上下文支持了多少来自地面真实数据(ground truth)的语句。CR的计算公式为CR = V,其中|V’|表示检索上下文支持的地面真实语句数量,|G|表示地面真实语句的总数。
4.3 实验程序
为了确保结果的统计显著性,评估流程采用了自举技术(bootstrap technique),这是一种重复从原始数据中抽取样本的重采样方法,以更好地估计潜在分布[25]。分析通过12次重采样进行,每次包括20个随机选择的问题——10个对应于VectorRAG,10个对应于GraphRAG——显著性水平(α)设定为0.05。重采样后,计算结果的均值和标准差,并使用t分布估计误差范围,考虑有限样本量。具体来说,误差范围(ME)的计算公式为:
KaTeX parse error: Undefined control sequence: \f at position 82: …hat{L}_{\cdot}d\̲f̲\times\frac{S}{…

其中,给定显著性水平和自由度df = n - 1,s是自举估计的标准差,n是自举样本的数量。
5 结果与分析
本文的评估指标如图5所示,对三种配置进行了比较分析:基线方法、提出的智能体框架以及使用DPO进行优化的增强型智能体版本。基线方法定义为一种非智能体方法,它对向量搜索(VS)和知识图谱(KG)进行联合语义搜索,并整合检索结果以生成最终响应。智能体框架引入了由AI智能体指导的动态工具选择,而经过DPO增强的变体则基于偏好对齐优化进一步改进最终输出的质量。为了清晰起见,评估按问题范围进行分段:特定于KG、特定于VS以及称为“总体”的组合类别。
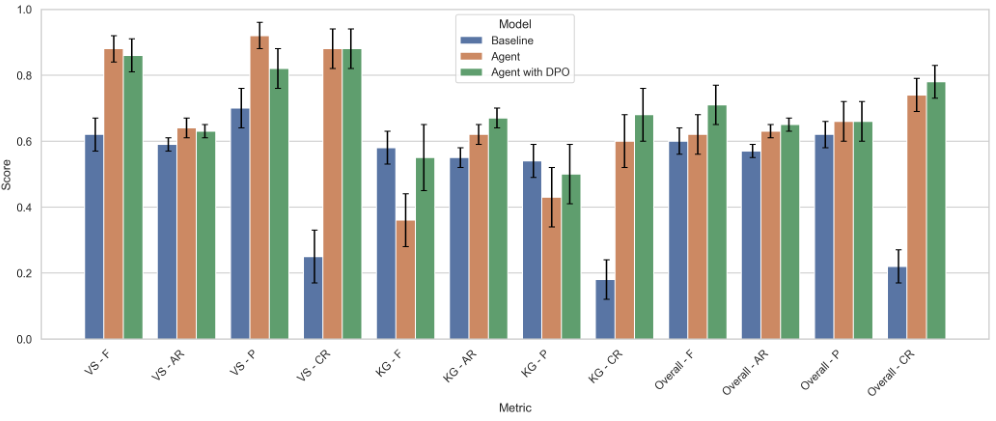
引入经过微调的智能体模型(采用直接偏好优化),以绿色表示,相较于原始智能体方法(橙色)取得了显著的改进。具体而言,其在KG的F分数上提升了0.19,在总体F分数上提升了0.09,同时在KG的CR上提升了0.08,在KG的P上提升了0.07,在KG的AR上提升了0.05。值得注意的是,这些改进表明生成的响应更加准确和完整。在VS方面,CR指标保持不变,但观察到了一些轻微的下降:P下降了0.10,F下降了0.02,AR下降了0.01。
与基线方法相比,经过微调的智能体模型在几乎所有评估指标上均表现出显著的性能提升。最值得注意的是,其在VS的CR上提升了0.63,在总体的CP上提升了0.56,凸显了其在从两个检索器中有效检索和整合信息方面的增强能力。其他改进包括VS的F提升了0.24,VS的P和KG的AR均提升了0.12,以及总体的F提升了0.11。此外,在KG的CR(提升0.05)、VS的AR(提升0.04)和总体的P(提升0.04)上也观察到适度且一致的提升。这些结果凸显了该模型在生成连贯且上下文准确的响应方面相较于非智能体RAG基线的优越性。尽管取得了这些进展,KG的P(下降0.04)和KG的F(下降0.03)略有下降,表明虽然符号推理总体上有所改进,但在生成精确的Cypher输出方面仍有改进空间。
6 讨论
我们的研究结果表明,将混合RAG封装在代理框架内——动态选择GraphRAG和VectorRAG——相较于静态的非代理基线取得了显著的改进。对Mistral-7B-Instruct-v0.3模型进行指令微调进一步提升了精度和召回率,通过使生成内容与领域特定的问答任务对齐,同时自举评估提供了透明的误差估计,并确认了我们所获收益的统计显著性(标准误差 ≤ 0.10)[2, 11, 25]。
根据所得结果,显然代理方法在增强文献综述过程中具有巨大潜力。通过显著优于传统的向量搜索RAG流程,我们的框架使研究问题能够以更自动化、高效和上下文感知的方式被探索——最终为研究人员提供更丰富的洞察,同时减少手动工作量[32]。
我们方法的一个关键优势在于其能够利用互补的检索模式。GraphRAG在结构化、元数据驱动的查询(如作者合作、出版时间线)方面表现出色,而VectorRAG则更好地捕捉细致的全文信息[31]。代理根据每个查询动态推理调用哪个模式,避免了固定流程的“一刀切”局限性,并通过将每个响应基于最合适的来源来减轻幻觉问题。
直接偏好优化(DPO)的引入取得了令人鼓舞的结果,特别是在需要结构化查询的任务中。然而,在知识图谱(KG)特定问题上的指标(忠实度和精度)表现下降,表明可能需要额外的指令微调或DPO重点示例,以充分释放信息检索管道的潜力[27]。这凸显了一个机会,可以进一步调整模型的决策过程,以实现更准确和上下文敏感的检索策略。
尽管取得了这些进展,仍有几个方面可以进一步改进:
- Cypher翻译器的微调:GraphRAG目前使用少样本提示生成Cypher,这可能会误解复杂的查询。在一组精心策划的(自然语言查询,Cypher)对上微调模型——或利用LLM函数调用API——应减少翻译错误并提高多跳召回率[33]。
- 整合光学字符识别以扩大覆盖范围:引入光学字符识别(OCR)管道(如Tesseract [34])将允许处理扫描或非数字化结构化的文档,扩大上下文覆盖范围并增强知识图谱。
- 强化学习用于策略优化:强化学习(RL,例如RLHF或奖励模型微调)可以基于最终任务奖励学习GraphRAG和VectorRAG的最佳组合[6, 35]。虽然完整的RL计算量大,但离线RL或模型蒸馏技术可能以适度的资源实现这些收益。
- 局限性与未来方向:我们的合成基准——虽然在KG和VS特定问题之间平衡——可能无法完全捕捉真实科学探究的复杂性,例如对图表和表格的多模态推理[7]。对外部API(PubMed, ArXiv, Google Scholar)的依赖也带来了数据可用性和速率限制的变数。未来的工作应在领域特定语料库(如临床试验、专利文献)上验证性能,整合表格和图表感知的检索,并支持交互式、用户参与的细化。持续摄取新出版物和用于查询路由的主动学习可以进一步增强适应性和覆盖范围[18]。
总之,我们的开源代理混合RAG框架代表了迈向自主、可靠的科学文献综述的重要进步。通过结合动态检索选择、指令微调、DPO洞察和严格的不确定性量化——并为基于RL的策略优化指明道路——我们为下一代知识发现工具奠定了可扩展的基础。
7 结论
在这项工作中,我们介绍了一个开源的、具有代理能力的混合RAG框架,该框架结合了Neo4j知识图谱、FAISS向量存储、LLaMA-3.3-70B-versatile以及在Mistral-7B-Instruct-v0.3上的直接偏好优化(Direct Preference Optimization, DPO),以实现科学文献综述的自动化。通过对每个查询动态选择GraphRAG和Vector-RAG,并通过自举评估(bootstrapped evaluation)量化不确定性,采用直接偏好优化的指令调整代理(Instruction-Tuned Agent with DPO)相较于非代理基线取得了显著的提升:VS上下文召回率(VS Context Recall)提高了+0.63,整体上下文精度(Context Precision)提高了+0.56,同时在VS忠实度(VS Faithfulness)上提高了+0.24,在VS精度(VS Precision)和知识图谱答案相关性(KG Answer Relevance)上均提高了+0.12,在整体忠实度(Faithfulness)上提高了+0.11,在知识图谱上下文召回率(KG Context Recall)上提高了+0.05,以及在VS答案相关性(VS Answer Relevance)和整体精度(Precision)上均提高了+0.04。
自举置信度估计证实了这些提升的稳健性,而我们完全基于Python且可Docker化的实现确保了透明度和可重复性。展望未来,我们计划优化Cypher翻译,扩展指令调整数据集,集成OCR以处理非结构化来源,并探索轻量级强化学习以进一步优化检索和生成策略,为真正的自主、可扩展的知识发现铺平道路。
8 安全与负责任的创新声明
我们的代理RAG框架仅处理公开可用的文献计量记录,并遵守所有API使用政策,从而确保安全和低置信度输出。该系统是开源的,以促进透明度和社区审计。为防止误用,例如自动化传播错误摘要,我们集成了严格的自举评估,并鼓励在部署中进行人工监督。我们还通过支持多个研究领域和API允许的语言来设计包容性。通过嵌入这些保障措施,我们旨在促进代理文献综述工具的伦理和公平创新。
9 代码可用性
我们的最新代码可在Github项目仓库中获取:https://github.com/Kamaleswaran-Lab/Agentic-Hybrid-Rag
Original Abstract: The surge in scientific publications challenges traditional review methods,
demanding tools that integrate structured metadata with full-text analysis.
Hybrid Retrieval Augmented Generation (RAG) systems, combining graph queries
with vector search offer promise but are typically static, rely on proprietary
tools, and lack uncertainty estimates. We present an agentic approach that
encapsulates the hybrid RAG pipeline within an autonomous agent capable of (1)
dynamically selecting between GraphRAG and VectorRAG for each query, (2)
adapting instruction-tuned generation in real time to researcher needs, and (3)
quantifying uncertainty during inference. This dynamic orchestration improves
relevance, reduces hallucinations, and promotes reproducibility.
Our pipeline ingests bibliometric open-access data from PubMed, arXiv, and
Google Scholar APIs, builds a Neo4j citation-based knowledge graph (KG), and
embeds full-text PDFs into a FAISS vector store (VS) using the all-MiniLM-L6-v2
model. A Llama-3.3-70B agent selects GraphRAG (translating queries to Cypher
for KG) or VectorRAG (combining sparse and dense retrieval with re-ranking).
Instruction tuning refines domain-specific generation, and bootstrapped
evaluation yields standard deviation for evaluation metrics.
On synthetic benchmarks mimicking real-world queries, the Instruction-Tuned
Agent with Direct Preference Optimization (DPO) outperforms the baseline,
achieving a gain of 0.63 in VS Context Recall and a 0.56 gain in overall
Context Precision. Additional gains include 0.24 in VS Faithfulness, 0.12 in
both VS Precision and KG Answer Relevance, 0.11 in overall Faithfulness score,
0.05 in KG Context Recall, and 0.04 in both VS Answer Relevance and overall
Precision. These results highlight the system’s improved reasoning over
heterogeneous sources and establish a scalable framework for autonomous,
agentic scientific discovery.
PDF Link: 2508.05660v1
部分平台可能图片显示异常,请以我的博客内容为准
