【Linux内核】进程管理(下)
一、进程调度
1.进程的分类
站在处理器的角度看进程的行为,你会发现有的进程一直占用处理器,有的进程只需要处理器的一部分计算资源即可。所以进程按照这个标准可以分成两类:一类是CPU消耗型(CPU-Bound),另外一类是IO消耗型(I/O-Bound)CPU消耗型的进程会把大部分时间用在执行代码上,也就是一直占用CPU。一个常见的例子就是执行while循环。实际上,常用的例子就是执行大量数学计算的程序,比如MATLAB等。IO消耗型的进程大部分时间在提交IO请求或者等待IO请求,所以这种类型的进程通常只需要很少的处理器计算资源即可,比如需要键盘输入的进程或者等待网络IO的进程。
2. 进程优先级和权重
进程的优先级越高,代表进程的任务越紧急。Linux系统最早采用nice值来调整优先级。我们又戏称nice值为”好人值“,nice值越高,优先级反而越低,代表这个进程更愿意将CPU让给其他的进程,是不是特别的好人。其范围为+19~-20。
而在内核中,优先级被分为0~139,其中0~99是提供给实时进程使用,而100~139则是给普通进程使用。其中普通进程的nice值+19~-20会被映射到内核优先级的0~139上。比如-20的nice值对应的内核优先级为100。进程的数据结构task_struct结构中有四个成员用于描述进程的优先级
struct task_struct{
...
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
...
}
static_prio是静态优先级,在进程启动时分配。内核不存储nice值,取而代之的是static_prio。NICE_TO_PRIO()宏可以把nice值转换成static_prio。之所以被称为静态优先级,是因为它不会随着时间而改变,用户可以通过nice或sched_setscheduler等系统调用来修改该值。normal_prio是基于static_prio和调度策略计算出来的优先级,在创建进程时会继承父进程的normal_prio。对于普通进程来说,normal_prio等同于static_prio;对于实时进程,会根据rt_priority重新计算normal_prio,详见effective_prio()函数。prio保存着进程的动态优先级,也是调度类考虑使用的优先级。有些情况下需要暂时提高进程的优先级,例如实时互斥量等。rt_priority是实时进程的优先级。
3. 调度策略
进程的调度依赖进程的调度策略。Linux内核将相同类型的调度策略抽象成了调度类,一个调度类中有若干种同类型调度策略。这五种调度策略分别是stop、deadline、realtime、CFS、idle。他们是使用sched_class来定义的
| 调度类 | 调度策略 | 使用范围 | 说明 |
|---|---|---|---|
| stop | 无 | 最高优先级 | 在每个CPU上实现一个名为“migration/N”的内核线程,N表示CPU的编号。该内核线程优先级最高,可以用于抢占任何进程的执行,一般用于特殊功能,比如CPU热插拔等 |
| deadline | SCHED_DEADLINE | 最高优先级的实时进程,优先级为-1 | 用于调度有严格时间要求的实时进程,比如视频编解码 |
| realtime | SCHED_FIFO、SCHED_RR | 用于一般的实时进程,比如IRQ线程化 | |
| CSF | SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE | 普通进程,优先级为100~139 | 通过CFS来调度 |
| idle | 无 | 最低优先级进程 | idle进程所在位置 |
用户可以通过使用调度策略API,比如sched_setscheduler()来设定用户进程的调度方式。接下来我们来了解下各种调度方式:
SCHED_RR:循环调度策略,优先级相同的进程会以固定长度的时间片循环执行。进程在获取到时间片后占有CPU直到下面任一条件出现才会退出:1.时间片用完 2.自愿放弃CPU 3.进程终止 4.被更高优先级抢占
SCHED_FIFO:先进先出调度策略和SCHED_RR类似,只是没有了时间片的概念,一旦获取到CPU进程会一直占有它,直到1.进程自愿放弃CPU 2.进程被终止 3.被更高优先级的进程抢占
SCHED_NORMAL:分时调度策略是非实时进程的默认调度策略。所有普通类型的进程的静态优先级都为0,因此,任何使用SCHED_FIFO或SCHED_RR调度策略的就绪进程都可以抢占它们。基于完全公平调度器(CFS)实现。
SCHED_BATCH:批处理调度策略,通常用于 CPU 密集型的非交互式进程。针对不需要实时交互的批处理任务进行了优化。进程会尽可能长时间地运行,以减少上下文切换开销,从而提高处理器密集型任务的吞吐量。适用于长时间运行的大批处理作业,如生成大型报表、科学计算等。
4. 调度算法
有人会搞混调度算法和调度策略,调度策略是操作系统提供给用户或开发者的一种规则集,用于定义进程或线程的调度行为。它规定了进程的优先级、抢占性、时间片分配等基本规则。用户可以通过系统调用(如sched_setscheduler)为进程或线程显式指定调度策略。关于Linux调度算法,我们可能需要捋一下他的发展脉络
4.1 多级反馈队列MLFQ
多级反馈队列是操作系统中常用的调度算法之一,Linux中的数种调度算法都是基于MLFQ延伸而来,它的核心思想是将进程按照优先级分为多个队列,将同一优先级的放置在同一队列中。有如下几个规则:
规则1.如果进程A优先级大于进程B,则调度器优先调度进程A
规则2.如果A和B优先级相同,那么使用轮转调度算法来选择
MLFQ中“反馈”二字表示调度器可以动态地修改进程的优先级,对于IO消耗型,这种进程需要的CPU时间很少,但是需要敏捷的响应,可以适当提高其优先级;对于CPU消耗型任务,则会完全占用时间片,但是对时间敏感度不高,所以优先级可以稍低
规则3:当新进程进入调度器的时候,放置到最高优先级的队列中
规则4:当一个进程吃满时间片,说明他是CPU消耗型进程,需要降低一级优先级;当一个进程在时间片还没结束之前就放弃CPU,证明他是一个IO消耗型进程,维持原来的优先级
多级反馈队列看起来很不错,但是实际上有一些漏洞:
- 在有大量IO消耗型进程的时候,位于低优先级的CPU消耗型进程容易长期无法获得CPU时间片
- 存在CPU消耗型进程在时间片即将用光的时候,假装大度主动让出CPU,伪装成IO消耗型进程。
- 部分进程有可能一会是IO消耗型,一会是CPU消耗型的
因此提出了一些补充机制:
针对第一个问题,多级反馈队列算法提出了一种改良方案,也就是在一定的时间周期后,把系统中的全部进程都提升到最高优先级,相当于系统中的进程过了一段时间又重新开始一样。就像是过一段时间就重开一把游戏,不要让CPU消耗型一直位于低优先级。
规则5:每隔时间周期S之后,把系统中所有进程的优先级都提到最高级别。
针对第二个问题,需要对规则4做一些改进。
新的规则4:当一个进程使用完时间片后,不管它是否在时间片的最末尾发生IO请求从而放弃CPU,都把它的优先级降一级。
经过改进后的规则4可以有效地避免进程的欺骗行为。
在介绍完多级反馈队列算法的核心实现后,在实际工程应用中还有很多问题需要思考和解决,其中一个最难的问题是参数如何确定和优化。比如,系统需要设计多少个优先级队列?时间片应该设置成多少?规则5中的时间间隔S又应该设置成多少,才能实现既不会让进程饥饿,又不会影响交互性和响应速度
4.2 Linux O(n)调度算法
O(n)调度器是Linux内核最早采用的一种基于优先级的调度算法。Linux 2.4之前的内核都采用这种算法。就绪队列是一个全局链表,当需要调度的时候会遍历就绪队列选出其优先级最高的进程,因为耗费的时间为O(n),所以称为O(n)调度器。当就绪队列里的进程很多时,选择下一个就绪进程会变得很慢,从而导致系统整体性能下降。
每个进程在创建时都会被赋予一个固定时间片。当前进程的时间片使用完之后,调度器会选择下一个进程来运行。当所有进程的时间片都用完之后,才会对所有进程重新分配时间片。
4.3 Linux O(1) 调度算法
在 Linux 内核中,O(1) 调度算法是一种在 2.4 和 2.6 版本早期使用的调度器,旨在提供高效的调度决策。每个CPU维护一个自己的就绪队列,从而减少了锁的争用。CPU中的就绪队列由两个优先级数组组成,分别是活跃优先级数组和过期优先级数组。每个优先级数组包含140个优先级队列,也就是每个优先级对应一个队列。(这和Linux 内核中的140个优先级对上了不是吗)调度器在选择需要运行哪个进程,只需要直接在优先级队列中找到最高优先级的非空队列即可,而如何找到最高优先级的非空队列和位图有关。
内核使用一个位图来记录哪些优先级队列中有可运行的进程。位图中的每个位对应一个优先级队列,如果某个优先级队列中有可运行的进程,对应的位被标记为 1,否则为 0。通过位图,调度器可以快速找到有可运行进程的优先级队列,而不需要遍历所有队列,这是实现O(1)的关键。位图可以在O(1)的时间内定义到第一个非零位置,这和与运算有关。
4.4 Linux CSF算法:
CSF调度类中所使用的调度算法,它抛弃了之前使用固定时间片和固定调度周期的算法,而是采用进程权重值的比重来计算实际运行时间。它引入两个新的概念**:虚拟时间(vruntime)**,也称为虚拟运行时间;真实时间(realruntime),也称为真实运行时间,也就是进程在物理时钟下实际运行的时间。
当一个进程的nice值越小,代表这个进程的优先级越高,他的权重比值越高,他的虚拟时间会比真实时间过得更慢;反之,当一个进程的nice值越大,代表这个进程的优先级越低,他的权重比值越低,他的虚拟时间会比真实时间过得更快。当进程A的nice值小于进程B的nice值的时候,代表进程A的优先级更高,他的虚拟时间流逝更慢。当A和B都在虚拟时间里运行了1秒的时候,由于A的虚拟时间比现实时间慢,实际上A在真实时间里运行的时间>1s;而B因为虚拟时间比现实时间快,实际上B在真实时间里运行的时间<1s。通过这种方式,调度系统只需要保持各个进程(即使这些进程优先级不一样)的虚拟执行时间保持一致就好,高优先级的进程会由于它们的高权重,在真实时间上拥有更长的执行时间。
所以调度器需要做的事情很简单:无脑地选择虚拟运行时间最小的进程运行就好,这能保持所有的进程的虚拟运行时间基本一致,而实际的真实执行时间会根据他们的优先级高低而产生区别。CFS 确保所有进程都能获得公平的 CPU 时间分配,避免了某些进程长时间占用 CPU 资源,但是对实时性支持不足,可能不适合对实时性要求较高的场景,这也解释了为什么它应用于于CSF调度类中——如果是需要实时性的进程,请使用realtime调度类
vrutime计算
Linux内核使用load_weight数据结果来记录调度实体的权重信息。首先,p->se.lead可以获得进程p的nice值,然后去查一个叫做sched_prio_to_weight[40]的数组,数组下标i代表nice=i的时候的权重weight。然后再把weight的权重记录到load_weight中
CSF中通过calc_delta_fair()函数来计算虚拟时间中进程运算了多久:
v
r
u
n
t
i
m
e
=
d
e
l
t
a
_
e
x
e
c
×
n
i
c
e
_
0
_
w
e
i
g
h
t
w
e
i
g
h
t
vruntime = \frac{delta\_exec \times nice\_0\_weight}{weight}
vruntime=weightdelta_exec×nice_0_weight
其中delta_exec为真实运行时间,nice_0_weight表示nice=0的权重,为1024,weight为当前进程权重,CSF会维持各个进程的vruntime基本一致,但是优先级高的进程weight更大,因此delta_exec也越大,所以在实际中获得了更多的CPU运行时间
4.5 进程切换
__schedule()是调度器的核心函数,作用是让调度器选择并且切换到一个合适的进程并且运行,其核心代码片段如下:
static void sched schedule(void){
next = pick_next_task(rq, prev);
if(likely(prve != next)){
rq = context_switch(rq, prev, next);
}
}
主要实现了两个功能,一个是选择下一个需要运行的进程,另外一个就是调用context_switch进行上下文切换。context_switch是Linux内核实现进程切换的核心函数。
每个进程可以拥有属于自己的进程地址空间,但是所有进程都必须共享CPU的寄存器等资源。所以,在切换进程时必须把即将切换到的进程在上一次挂起时保存的寄存器值重新装载到CPU里。在进程恢复执行前必须装入CPU寄存器的数据,则称为硬件上下文。进程的切换可以总结为如下两步。
(1)切换进程的进程地址空间,也就是切换next进程的页表到硬件页表中,这是由switch_mm()函数实现的。
(2)切换到next进程的内核态栈和硬件上下文,这是由switch_to()函数实现的。硬件上下文提供了内核执行next进程所需要的所有硬件信息。
switch_mm函数详解
switch_mm函数实质上是把新进程的页表基地址设置到页表基地址寄存器。对于ARM64处理器,switch_mm()函数的主要作用是完成ARM架构相关的硬件设置,例如刷新TLB以及设置硬件页表等。TLB会负责缓存常用物理地址和虚拟地址的映射,从而加快虚拟地址到物理地址的转换。进行进程上下文切换的时候,留在TLB上的是上一个进程的地址映射,因此需要进行擦除,但是对整个TLB进行擦除,会导致新进程在刚开始执行的时候出现很严重的TLB未命中和缓存未命中。
实际上,对于页表来说,有一些页表是全局页表,是所有进程公用的内存页,而一些是进程独有的页表。为了区分这些进程独有的页表,ARM引入了ASID解决方案(x86上类似的机制被称为PCID)。他会为每一个TLB项加多一个ASID用于区分这个TLB属于哪个进程,因此进程的切换就不需要刷新整个TLB。
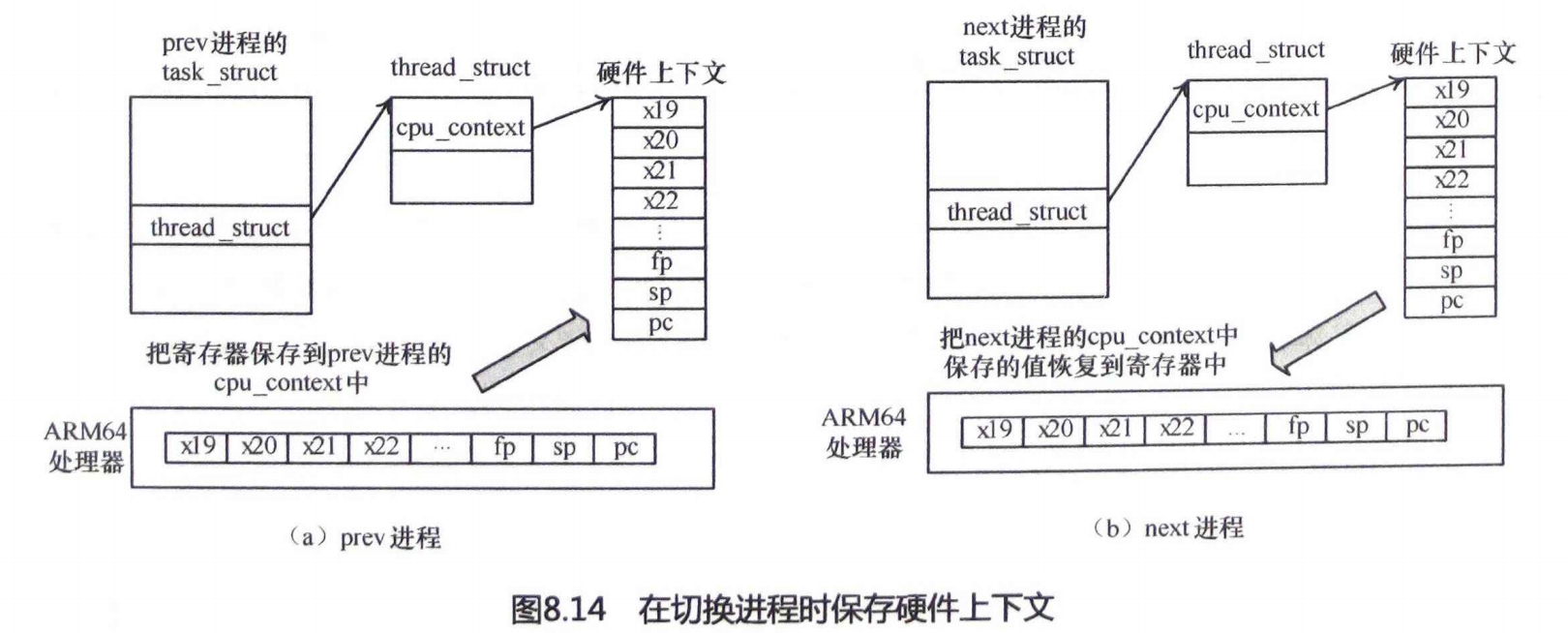
上下文切换所需的硬件
task_struct数据结构下的thread_struct用来存放一些和具体架构相关的信息,thread_struct->cpu_context用于指明进行进程切换的时候,CPU需要保存哪些寄存器,这又称为“硬件上下文”。以ARM64为例子,切换进程的时候,需要将被切换的进程的x19~x28寄存器,以及fp, sp和pc寄存器保存到cpu_context数据结构中。然后将要切换的目标进程的cpu_context的值恢复到实际的硬件寄存器中,这样就完成了硬件上下文切换。
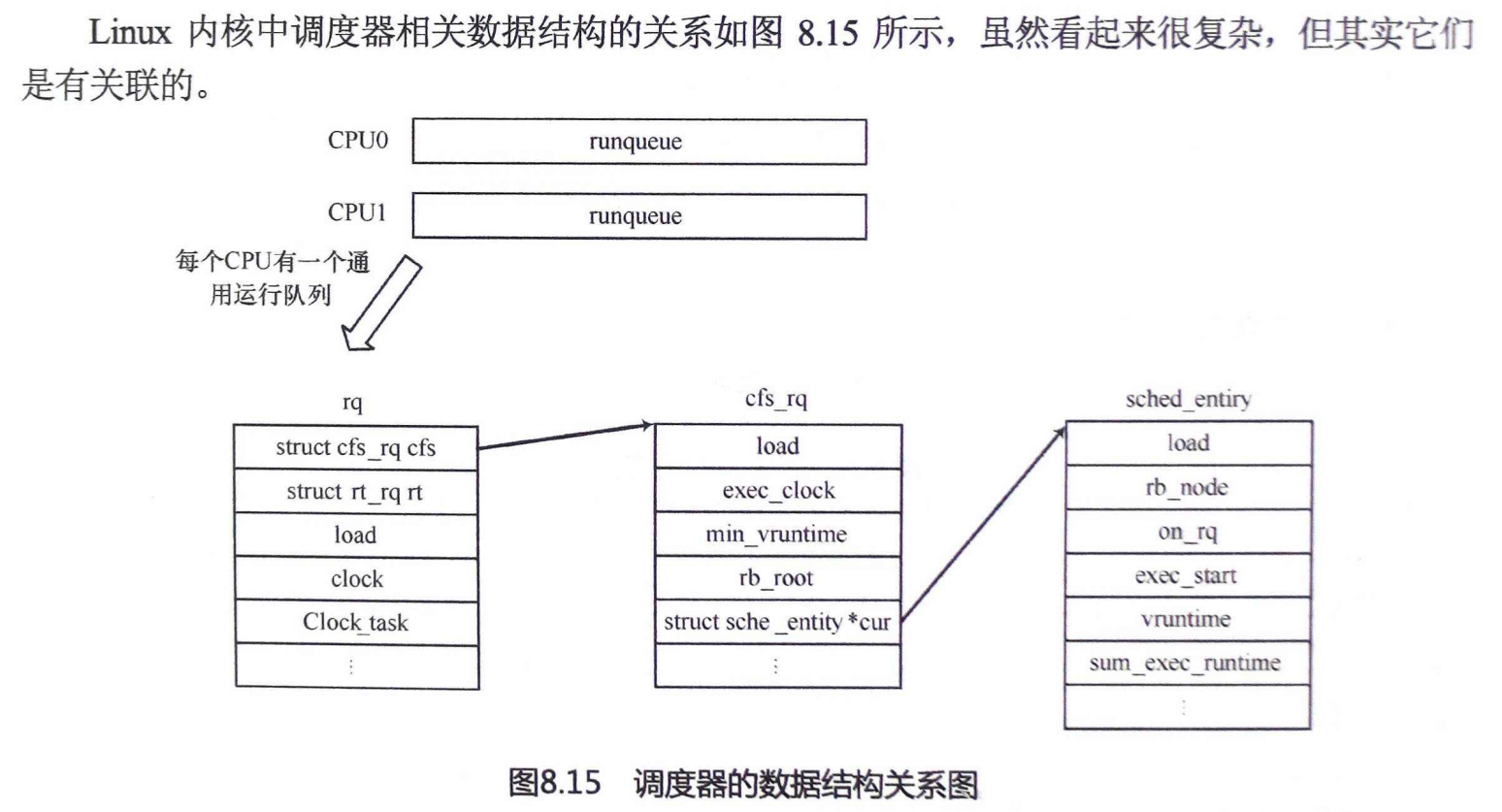
4.6 与调度相关的数据结果
上面这么多数据结构,一定看起来很晕了,现在我们来浅浅做个汇总:
1.task_struct
Linux内核使用task_struct数据结构来描述我们常说的进程描述符PCB。进程描述符taskstruct用来描述进程运行状况以及控制进程运行所需要的全部信息。
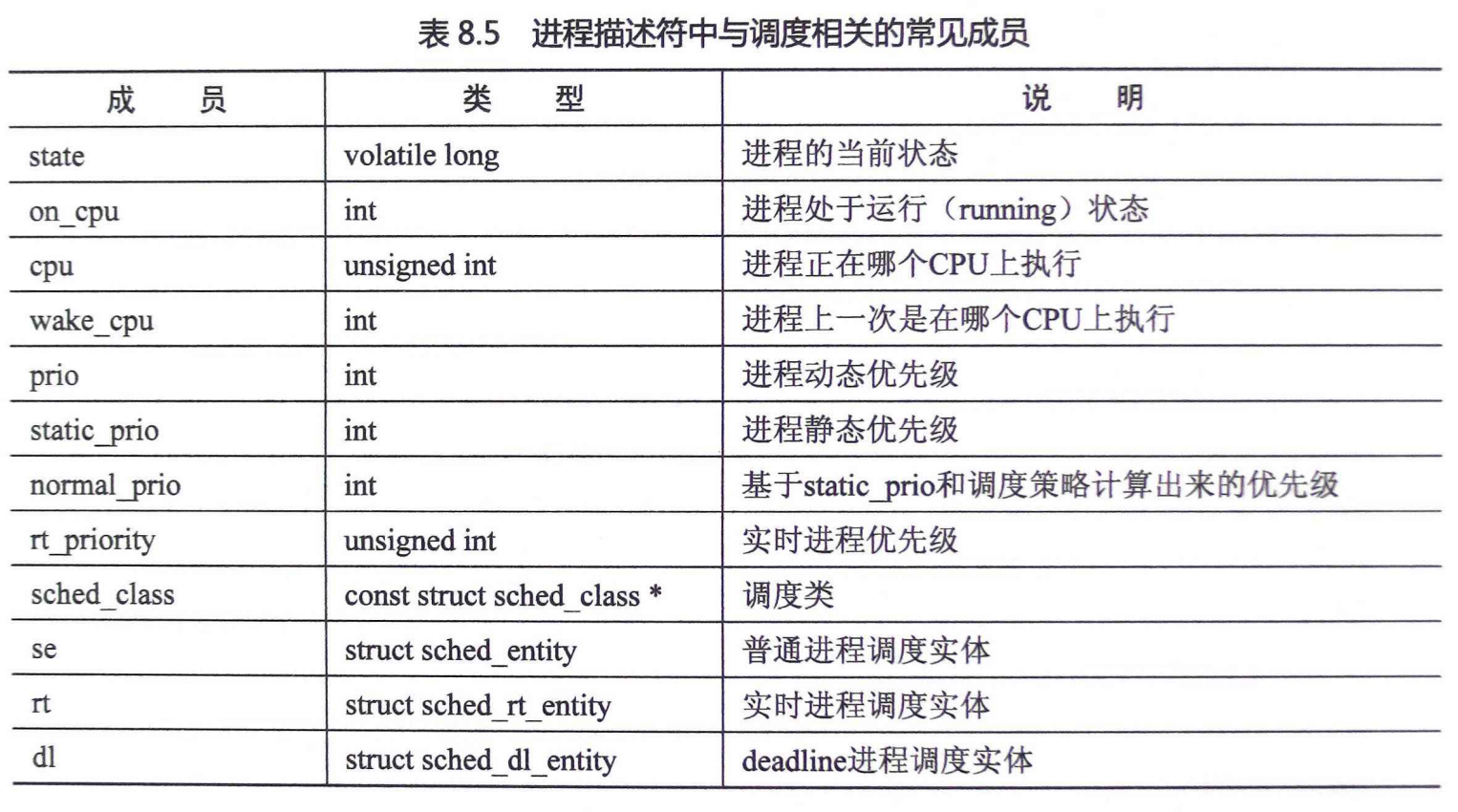
2.sched_entity
进程调度有一种非常重要的数据结构sched_entity,称为调度实体,这种数据结构描述了进程作为调度实体参与调度所需要的所有信息,例如load表示调度实体的权重,run_node表示调度实体在红黑树中的节点。sched_entity数据结构定义在include/linux/sched.h中。
3.rq
rq数据结构是描述CPU的通用就绪队列,rq数据结构中记录了一个就绪队列所需要的全部信息,不仅包括一个CFS的数据结构cfs_rq、一个实时进程调度器的数据结构rt_rq和一个deadline调度器的数据结构dl_rg,还包括就绪队列的load权重等信息。