检索召回率优化探究五(BGE-M3 混合检索):基于LangChain0.3 集成Milvu2.5 向量数据库构建的智能问答系统
背景
基于 LangChain 0.3 集成 Milvus 2.5 向量数据库构建的 NFRA(National Financial Regulatory Administration,国家金融监督管理总局)政策法规智能问答系统。(具体代码版本,可见)
上一次探究了检索前处理方法——查询扩展。介绍的是一种比较有前景的查询优化技术,假设性文档嵌入(Hypothetical Docunment Embeddings, HyDE),该技术源于一篇论文《Precise Zero-Shot Dense Retrieval without Relevance Labels》。
通过使用不同的模型和构建不同的 prompt 来对查询进行扩展来进行检索评估,最终是得到了一个不错的检索召回率,实现了目标(>= 85%)。实现 HyDE 的检索流程图如下:
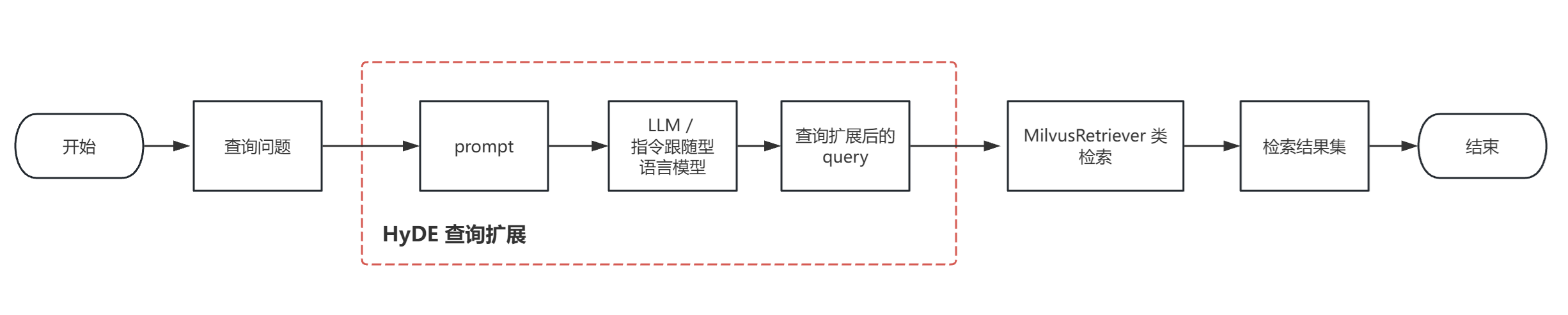
本次按计划进行,来到了索引优化。相对于检索前处理(让查询更清晰、多角度、更丰富)来说,索引优化是通过合理地组织、存储文本分块,从而让它们更高效、更准确地被检索到。
目标
检索召回率 >= 85%
实现方法
本次探究:使用 Milvus 官方推出的 milvus-model,它是 Python SDK 的一部分。它实现了 BGE-M3 模型的集成,用于在 Milvus 向量数据库中进行高效的密集向量(Dense)、稀疏向量(Sparse)和多向量(Multi-Vector)混合检索(Hybrid Search)。同时,它还实现了重排。
这个对应于 RAG系统整体优化思路图(见下图)的“信息嵌入-嵌入模型”,索引优化部分并未在图中体现,而之所以也包含索引优化,是因为原来索引只有密集向量,此次要实现的混合索引,加上了稀疏向量索引。
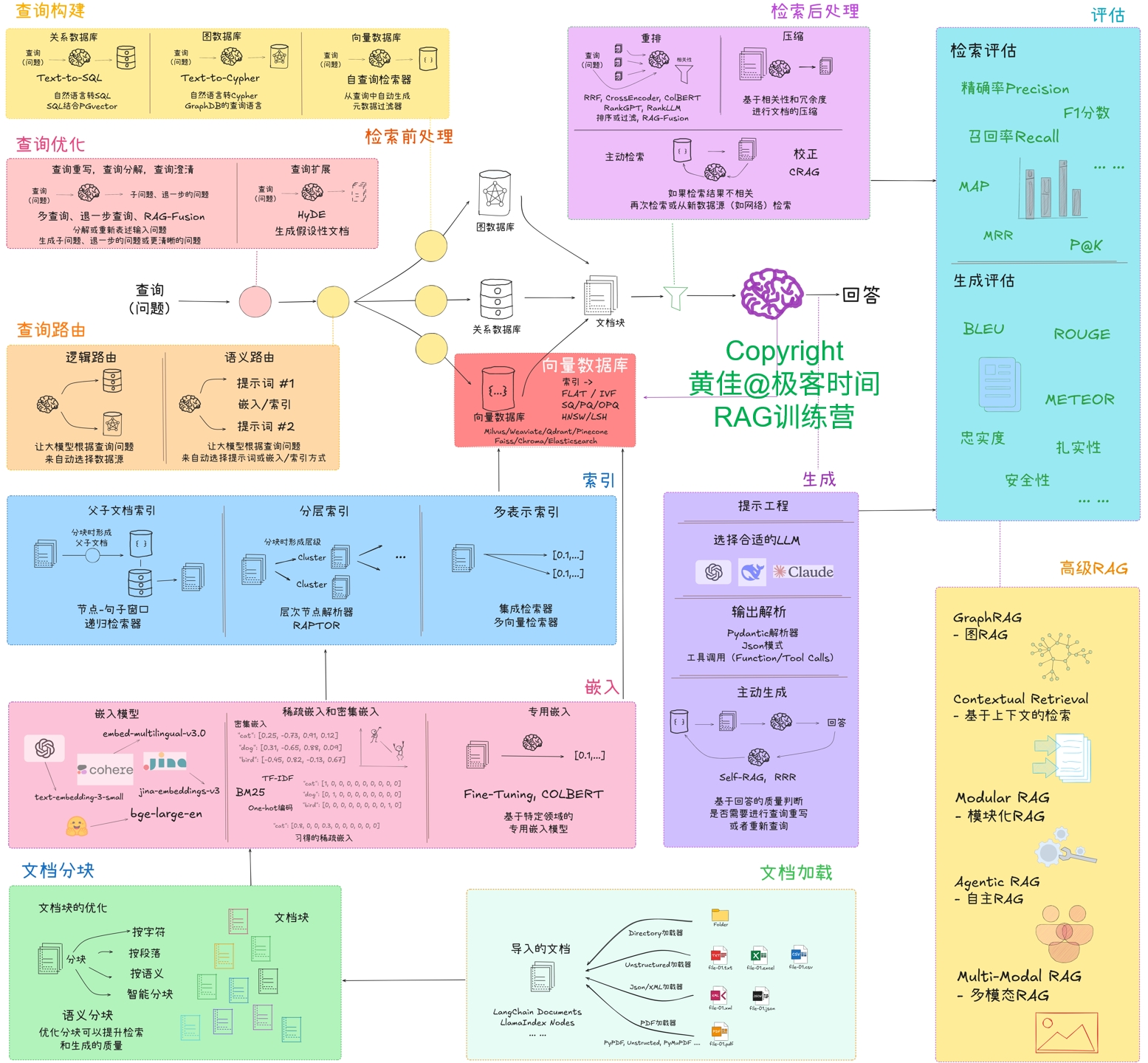
书中还介绍了 LangChain 提供的集成检索器 (EnsembleRetriever),它通过组合不同类型检索器的结果来实现混合检索。它同样也实现了检索后重排。
而之所以没选择这种实现方法,不是因为无法实现,而是因为要单独实现稀疏检索器比较不合目前项目的实现架构。
当前项目的向量存储是使用了 milvus,要实现密集向量和稀疏向量的混合检索,就要根据已嵌入到 milvus 中的文本内容,进行单独的稀疏嵌入,实现稀疏嵌入检索器,从而与 milvus检索器一同传给 EnsembleRetriever。
执行过程
BGE-M3
BGE-M3(Bidirectional Guided Encoder - Multi-Lingual, Multi-Function, Multi-Granularity) 是由智源研究院(BAAI) 推出的优秀的开源文本嵌入模型。
为何叫 M3 呢?是因为它主要有3个特点:
- 多语言性(Multi-Linguality):BGE-M3 支持超过 100种语言,具备强大的多语言、跨语言检索能力。
- 多功能性(Multi-Functionality):BGE-M3 模型集成密集检索、稀疏检索和多向量检索3种功能,能够灵活应对不同的检索需求。
- 多粒度性(Multi-Granularity):可对句子、段落、文档等不同粒度文本进行有效编码,满足不同长度文本的处理需求。
稀疏向量
稀疏向量是一种特殊的高维向量,其中大部分元素为零,只有少数维度的值不为零。
稀疏向量是信息检索和自然语言处理中捕捉表层术语匹配的重要方法。虽然稠密向量在语义理解方面表现出色,但稀疏向量往往能提供更可预测的匹配结果,尤其是在搜索特殊术语或文本标识符时。
实现过程
1. 加载文档、分块、嵌入、存储
前面有说,要实现混合检索,需重新初始化向量集合,因为嵌入模型要换成:BAAI/bge-m3
代码实现如下:
def load_data_milvus_hybrid():# 加载目录文件logger.info("Loading data...")documents = load_pdf2document(config.FILE_PATH)# 分块logger.info("Chucking data...")docs = FileSplitter(chunk_size=config.FILE_CHUNK_SIZE, chunk_overlap=config.FILE_CHUNK_OVERLAP).split_documents(documents)# 嵌入logger.info("Embeddings...")bgem3_ef = BGEM3EmbeddingFunction(use_fp16=config.BGEM3_USE_FP16, device=config.BGEM3_DEVICE)texts = [text.page_content for text in docs]texts_embeddings = bgem3_ef(texts)logger.info(f"向量生成完成,密集向量维度:{bgem3_ef.dim['dense']}")# 存储logger.info("Vectors and Store Milvus...")dense_vector_field = config.DENSE_VECTOR_FIELDsparse_vector_field = config.SPARSE_VECTOR_FIELD# 定义字段fields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),FieldSchema(name="metadata", dtype=DataType.JSON),FieldSchema(name=dense_vector_field, dtype=DataType.FLOAT_VECTOR, dim=bgem3_ef.dim["dense"]),FieldSchema(name=sparse_vector_field, dtype=DataType.SPARSE_FLOAT_VECTOR)]# 创建集合模式schema = CollectionSchema(fields=fields, description="RAG_NFRA Collection hybrid search support")# 创建集合milvus_util = MilvusUtils()collection = milvus_util.create_collection(collection_name=config.COLLECTION_NAME,consistency_level=config.CONSISTENCY_LEVEL,schema=schema)# 构建索引# 密集向量索引dense_index_params = {"index_type": config.INDEX_TYPE,"metric_type": config.METRIC_TYPE,"params": {"nlist": config.NLIST}}collection.create_index(dense_vector_field, dense_index_params)# 稀疏向量索引sparse_index_params = {"index_type": config.SPARSE_INDEX_TYPE,"metric_type": config.SPARSE_METRIC_TYPE}collection.create_index(sparse_vector_field, sparse_index_params)# 插入数据data = [texts, # text 字段[text.metadata for text in docs], # metadata 字段texts_embeddings["dense"], # dense_vector 字段texts_embeddings["sparse"] # sparse_vector 字段,用于稀疏检索]collection.insert(data)# 加载集合到内存collection.load()logger.info(f"成功将 {len(texts_embeddings["dense"])} 条向量存储到 Milvus 集合 {config.COLLECTION_NAME} 并支持混合检索。")
相对于原来只使用密集检索的向量集合初始化过程,主要的变化点:
- 通过使用 BGEM3EmbeddingFunction 来间接使用嵌入模型:BAAI/bge-m3,use_fp16=False, device='cpu', 这两个是配套使用的参数,不使用半精度加速,使用 CPU计算
- 字段定义新增:用于存储稀疏向量的字段,字段类型为:SPARSE_FLOAT_VECTOR
- 创建集合时,声明事务一致性级别为:Strong(强一致性);
- 给新增的稀疏向量字段,建立索引,索引类型为:SPARSE_INVERTED_INDEX
2. 混合检索
def milvus_hybrid_retrieve(collection: Collection, bgem3_ef: BGEM3EmbeddingFunction, query: str, k: int = config.TOP_K,rerank_method: str = config.RERANK_METHOD_RRF):"""在Milvus中执行稠密和稀疏向量混合检索,并对结果进行重排。:param collection: Milvus集合对象,用于执行搜索操作。:param bgem3_ef: 用于生成查询文本的稠密和稀疏向量表示。:param query: 用户输入的查询文本。:param k: 返回的最相似结果数量,默认值由配置项 config TOP_K 指定。:param rerank_method: 指定结果重排方法,支持加权合并或RRF(Reciprocal Rank Fusion),默认值由配置项 config RERANK_METHOD_RRF 指定。:return: list: 检索并重排后的结果 Hits 对象列表"""dense_params = {"metric_type": config.METRIC_TYPE,"params": {"nprobe": config.NPROBE}}sparse_params = {"metric_type": config.SPARSE_METRIC_TYPE,"params": {}}query_embeddings = bgem3_ef([query])dense_req = AnnSearchRequest(data=[query_embeddings["dense"][0]],anns_field=config.DENSE_VECTOR_FIELD,param=dense_params,limit=2 * k)sparse_req = AnnSearchRequest(data=[query_embeddings["sparse"]._getrow(0)],anns_field=config.SPARSE_VECTOR_FIELD,param=sparse_params,limit=4 * k)# 根据选择的重排方法创建不同的重排器if rerank_method == config.RERANK_METHOD_WEIGHTED:sparse_weights = config.SPARSE_WEIGHTEDdense_weights = config.SPARSE_WEIGHTEDrerank = WeightedRanker(dense_weights, sparse_weights)else: # rrfrrf_k = config.RRF_Krerank = RRFRanker(rrf_k)# 执行混合搜索并使用指定的重排器对结果进行重排序results = collection.hybrid_search(reqs=[dense_req, sparse_req],rerank=rerank,limit=k,output_fields=["id", "text", "metadata"],)[0]return results检索评估(召回率)
RAG 相关处理说明:
切分策略:分块大小: 500; 分块重叠大小: 100; 使用正则表达式,[r"第\S*条 "]
嵌入模型:模型名称: BAAI/bge-m3 (使用归一化; 维度:1024)
向量存储:向量索引类型:IVF_FLAT (倒排文件索引+精确搜索)稀疏向量存储: 索引类型:SPARSE_INVERTED_INDEX
密集向量度量标准类型:IP(内积); 聚类数目: 100;查询时聚类数目: 10稀疏向量度量标准类型:IP(内积);存储数据库: Milvus
向量检索:混合检索(具体混合检索策略如下各章节), 混合检索最终返回向量数目: 3
检索评估数据集:evaluation/data/retrieveInputData_V1_2.xlsx
重排策略:RRF(k=60)
(混合检索最终返回向量数目: 3)
| 评估组别 | 密集检索返回数 | 稀疏检索返回数 | 召回率 |
| 1 | 3 | 3 | 95% |
| 2 | 3 | 6 | 93% |
| 3 | 3 | 9 | 94% |
| 4 | 5 | 5 | 94% |
| 5 | 5 | 10 | 95% |
| 6 | 6 | 6 | 94% |
| 7 | 6 | 9 | 96% |
| 8 | 6 | 10 | 96% |
| 9 | 6 | 12 | 95% |
| 10 | 9 | 9 | 95% |
从上表可得:
- 最佳表现:评估组别7(6+9)和8(6+10)均达到最高召回率:96%
- 参数规律:稀疏检索扩展至 9-10 时效果明显;密集检索在 5-6 区间表现稳定
- 稳定性:所有配置召回率差异<3%(93%-96%),系统鲁棒性强
重排策略:权重
(混合检索最终返回向量数目: 3)
| 评估组别 | 密集检索返回数 | 稀疏检索返回数 | 权重配置(密集:稀疏) | 召回率 |
| 1 | 3 | 3 | 0.5 : 0.5 | 95% |
| 2 | 3 | 6 | 0.5 : 0.5 | 95% |
| 3 | 3 | 9 | 0.5 : 0.5 | 95% |
| 4 | 6 | 6 | 0.5 : 0.5 | 94% |
| 5 | 6 | 9 | 0.5 : 0.5 | 95% |
| 6 | 6 | 9 | 0.7 : 0.3 | 95% |
| 7 | 6 | 9 | 0.9 : 0.6 | 95% |
| 8 | 6 | 9 | 0.7 : 0.5 | 95% |
| 9 | 6 | 9 | 1.0 : 0.5 | 95% |
| 10 | 6 | 9 | 1.0 : 0.7 | 95% |
| 11 | 6 | 9 | 1.0 : 1.0 | 95% |
| 12 | 6 | 12 | 1.0 : 0.7 | 95% |
| 13 | 6 | 12 | 1.0 : 1.0 | 95% |
| 14 | 9 | 12 | 1.0 : 1.0 | 94% |
| 15 | 9 | 12 | 0.7 : 1.0 | 94% |
从上表可得:
- 稳定性表现:所有配置召回率差异仅 1个 百分点(94%-95%),系统表现高度稳定
- 参数不敏感现象:权重配置变化(0.3-1.0)未影响召回结果;稀疏检索扩展至 12 仍保持 95%的召回率。
检索评估小结
- 根据上述不同的重排策略评估结果可知,检索召回率在 93%-96%,是超过目标 85%的;
- 在相同的 RAG 处理,及密集与稀疏检索返回数相同的情况下,重排选择:RRF(k=60),获得到了最高召回率:96%。
总结
- 从实践中体会到了 Milvus 结合 BGE-M3 实现混合检索的高召回率,可见 BGE-M3 作为一款嵌入模型的强大;
- Milvus 中集合(collection)提供的 hybrid_search 灵活可配置,不仅支持 RRF重排,还支持权重重排,通过调整密集、稀疏权重,适应不同任务;
- 基于 RAG 实现的智能问答系统,适合选择混合检索,它不仅考虑了语义相关性,还考虑到关键词匹配,而且检索召回率高,能更好地应对用户各种各样的问题。
文中基于的项目代码地址:https://gitee.com/qiuyf180712/rag_nfra
本文关联项目的文章:RAG项目实战:LangChain 0.3集成 Milvus 2.5向量数据库,构建大模型智能应用-CSDN博客