ConcurrentHashMap源码详解
文章目录
- ConcurrentHashMap源码深度解析:put方法的高并发设计艺术
- 引言
- 一、ConcurrentHashMap概述
- 结构图:
- 核心特性:
- Node 主要节点表示状态常量有:
- 二、put方法执行流程总览
- 三、putVal方法逐行解析
- 1. 参数校验与哈希计算
- 2. 自旋插入逻辑
- 3. 关键方法解析
- 4. 哈希冲突处理
- 5. 扩容机制
- 四、设计亮点
- 五、性能对比
- 六、最佳实践
- 结语
ConcurrentHashMap源码深度解析:put方法的高并发设计艺术
引言
在Java并发编程中,ConcurrentHashMap是使用最频繁的并发容器之一,它完美地平衡了线程安全和性能。本文将深入剖析ConcurrentHashMap的核心方法——put的实现原理,揭示其在高并发环境下的设计哲学。
一、ConcurrentHashMap概述
ConcurrentHashMap是Java集合框架中提供的线程安全的哈希表实现,与Hashtable和Collections.synchronizedMap不同,它采用了更细粒度的锁机制,实现了更高的并发性能。
结构图:
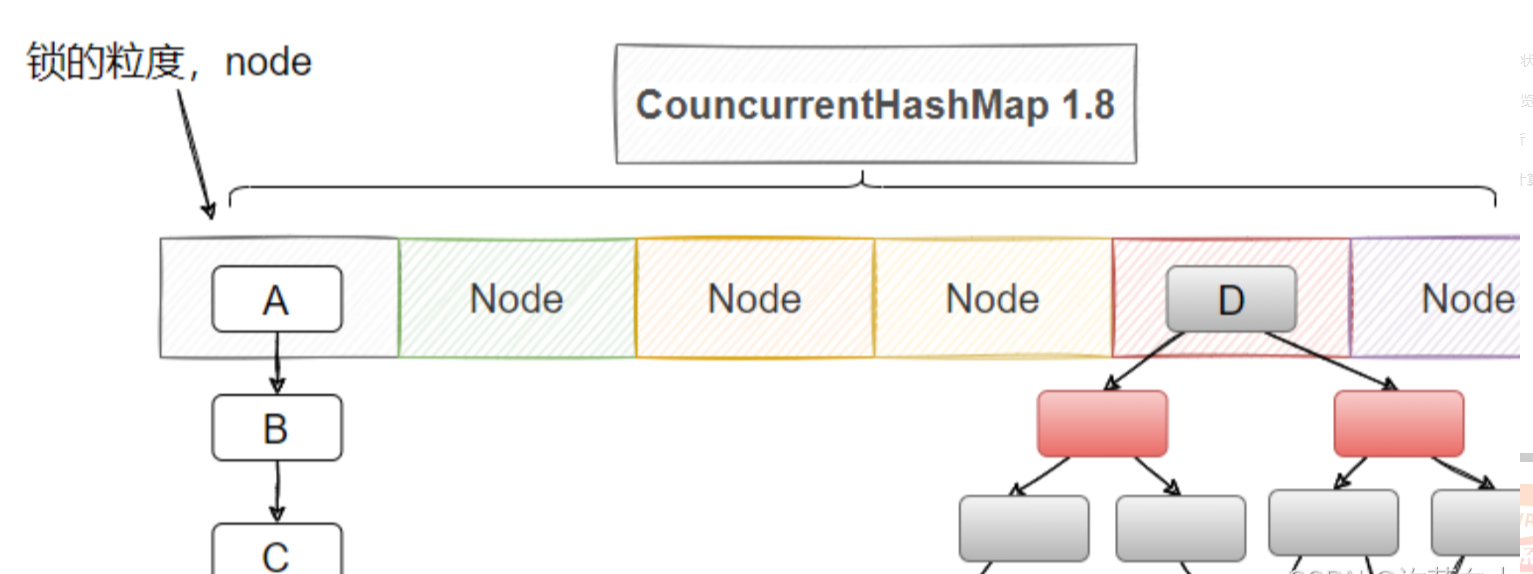
核心特性:
- 线程安全且高并发
- 键值不允许为null
- 动态扩容
- 链表转红黑树优化
- 利用Node数组构成整个数据结构
这几个常量来自 JavaConcurrentHashMap的内部实现,主要用于表示特殊的哈希值,以区分普通节点与特殊节点。它们的作用如下:
Node 主要节点表示状态常量有:
MOVED = -1
- 含义:表示Forwarding Node(转发节点)。
- 作用:当 ConcurrentHashMap 进行扩容时,旧表中的某些桶(bin)会被迁移到新表中。此时,旧桶中的节点会被替换为一个“转发节点”,其哈希值标记为 MOVED。
其他线程在访问到这个桶时,会根据这个标记知道该桶的数据已经迁移,并跳转到新表中查找。
TREEBIN = -2
- 含义:表示TreeBin(树根节点)。
- 作用:当同一个桶中的节点数过多(通常大于 8),
ConcurrentHashMap会将该桶的链表结构转化为红黑树以提高查找效率。
TREEBIN用来标识树的根节点,从而区分它与普通链表节点。
RESERVED = -3
- 含义:表示暂时保留(transient reservation)。
- 作用:在某些特殊情况下(例如在
computeIfAbsent或者其他需要暂时占用 bin 的操作中),会用到RESERVED来表示这个桶正处于临时保留状态,避免其他线程对其进行不恰当的操作。
HASH_BITS = 0x7fffffff
- 含义:用于获取正数哈希值。
- 作用:
ConcurrentHashMap会通过 (hash & HASH_BITS) 去除符号位,以确保哈希值为非负数(最高位保留给特殊用途,比如上述MOVED、TREEBIN等负数标记)。
二、put方法执行流程总览
put方法的核心实现在putVal中,主要流程如下:
- 参数校验
- 计算键的哈希值
- 定位哈希桶
- 根据桶状态执行不同操作
- 处理哈希冲突
- 检查是否需要扩容
三、putVal方法逐行解析
putval 源码
/*** 核心的键值对插入方法,实现线程安全的插入逻辑* @param key 键,不允许为null* @param value 值,不允许为null* @param onlyIfAbsent 如果为true,当键已存在时不覆盖原有值* @return 如果键已存在且onlyIfAbsent为true,返回原值;否则返回null*/
final V putVal(K key, V value, boolean onlyIfAbsent) {// 1. 参数校验:不允许null键或null值if (key == null || value == null) throw new NullPointerException();// 2. 计算键的哈希值(通过spread方法进行二次哈希,减少碰撞)int hash = spread(key.hashCode());int binCount = 0; // 记录链表长度(用于判断是否要树化)// 3. 自旋插入(直到成功插入或发现重复键)for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh; K fk; V fv;// CASE 1: 表未初始化if (tab == null || (n = tab.length) == 0)tab = initTable(); // 初始化哈希表(懒加载)// CASE 2: 目标桶为空(无哈希冲突)else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 使用CAS尝试无锁插入新节点if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break; // CAS成功,插入完成// CAS失败说明有竞争,继续自旋}// CASE 3: 桶正在迁移(扩容中)else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f); // 协助完成数据迁移// CASE 4: 快速检查键是否已存在(不加锁优化)else if (onlyIfAbsent // 只有当onlyIfAbsent为true时才检查&& fh == hash // 哈希值匹配&& ((fk = f.key) == key || (fk != null && key.equals(fk))) // 键相等&& (fv = f.val) != null) // 值不为nullreturn fv; // 直接返回现有值(不覆盖)// CASE 5: 处理哈希冲突(加锁)else {V oldVal = null;// 对桶的头节点加锁(细粒度锁)synchronized (f) {// 双重检查(防止锁期间桶被修改)if (tabAt(tab, i) == f) {// CASE 5.1: 普通链表节点if (fh >= 0) {binCount = 1; // 链表长度计数// 遍历链表for (Node<K,V> e = f;; ++binCount) {K ek;// 找到相同key的节点if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;// 根据onlyIfAbsent决定是否覆盖if (!onlyIfAbsent)e.val = value;break;}// 到达链表尾部,追加新节点Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key, value);break;}}}// CASE 5.2: 红黑树节点else if (f instanceof TreeBin) {binCount = 2; // 树节点计数为2// 调用红黑树的插入方法Node<K,V> p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value);if (p != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}// CASE 5.3: 保留节点(不应该出现)else if (f instanceof ReservationNode)throw new IllegalStateException("Recursive update");}}// 后处理if (binCount != 0) {// 链表长度达到阈值,转为红黑树if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);// 如果覆盖了旧值,返回旧值if (oldVal != null)return oldVal;break;}}}// 6. 更新元素计数(可能触发扩容)addCount(1L, binCount);return null; // 插入新节点时返回null
}// --------------- 关键工具方法注释 --------------- ///*** 原子性读取哈希桶数组中的元素(保证内存可见性)*/
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}/*** CAS更新哈希桶数组中的元素*/
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v) {return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}/*** 哈希扰动函数 - 将原始哈希码的高位与低位混合*/
static final int spread(int h) {return (h ^ (h >>> 16)) & HASH_BITS;
}1. 参数校验与哈希计算
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
- 空值检查:
ConcurrentHashMap不允许null键值 - 哈希扰动:
spread方法对原始哈希值进行二次处理,减少哈希冲突
2. 自旋插入逻辑
for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 表未初始化if (tab == null || (n = tab.length) == 0)tab = initTable();// 目标桶为空// 然后进行CAS操作else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break;}// 桶正在迁移else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);// 键已存在且onlyIfAbsent为trueelse if (onlyIfAbsent && fh == hash && ((fk = f.key) == key || (fk != null && key.equals(fk))) &&(fv = f.val) != null)return fv;// 处理哈希冲突else {// ...详细代码在下文解析}
}
3. 关键方法解析
tabAt:安全读取桶节点
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getReferenceAcquire(tab, ((long)i << ASHIFT) + ABASE);}
- 使用
Unsafe.getReferenceAcquire保证内存可见性 - 通过内存偏移量直接访问数组元素
casTabAt:CAS更新桶节点
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v) {return U.compareAndSetReference(tab, ((long)i << ASHIFT) + ABASE, c, v);}
- compareAndSetReference的CAS 对象原子操作
- 成功条件:当前值等于预期值c
4. 哈希冲突处理
当发生哈希冲突时,"ConcurrentHashMap"采用 基于节点的细粒度锁(JDK8 之后锁定的是 单个桶的头节点)
synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) { // 链表节点// 遍历链表...}else if (f instanceof TreeBin) { // 树节点// 红黑树操作...}}
}
- 细粒度锁:只锁住当前桶的头节点
- 双重检查:防止锁期间桶状态被修改
- 链表转树:当链表长度超过阈值(默认8)时转为红黑树
5. 扩容机制
if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;
}
addCount(1L, binCount);
- 树化检查:链表长度超限时转为红黑树
- 计数更新:
addCount可能触发扩容
四、设计亮点
- 某桶头节点锁策略
- 桶粒度锁而非全局锁
- 无锁化CAS操作优化空桶插入
- 内存可见性保证
- volatile变量与Unsafe配合
- 内存屏障的正确使用
- 动态扩容机制
- 多线程协同扩容
- 渐进式数据迁移
- 数据结构优化
- 链表转红黑树
- 节点类型多样化(Node/TreeBin/ReservationNode)
五、性能对比
| 操作 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| put | O(1) | O(1) | O(1) |
| 线程安全 | 不安全 | 安全(全局锁) | 安全(分段锁) |
| 并发度 | - | 低 | 高 |
六、最佳实践
- 合理设置初始容量
new ConcurrentHashMap<>(initialCapacity)
- 避免频繁扩容
- 预估最终size
- 设置合适的负载因子
- 键对象设计
- 实现良好的hashCode()
- 保证不可变性
结语
ConcurrentHashMap的put方法展现了Java并发编程的精妙设计,通过CAS、volatile和细粒度锁的组合,实现了高并发下的线程安全与性能平衡。理解其实现原理,有助于我们编写更高效、更可靠的并发代码
本人水平有限,有错的地方还请批评指正。
什么是精神内耗?
简单地说,就是心理戏太多,自己消耗自己。
所谓:
言未出,结局已演千百遍;
身未动,心中已过万重山;
行未果,假想灾难愁不展;
事已闭,过往仍在脑中演。