RNN——LSTM(deep-learning)学习
一,为什么需要RNN
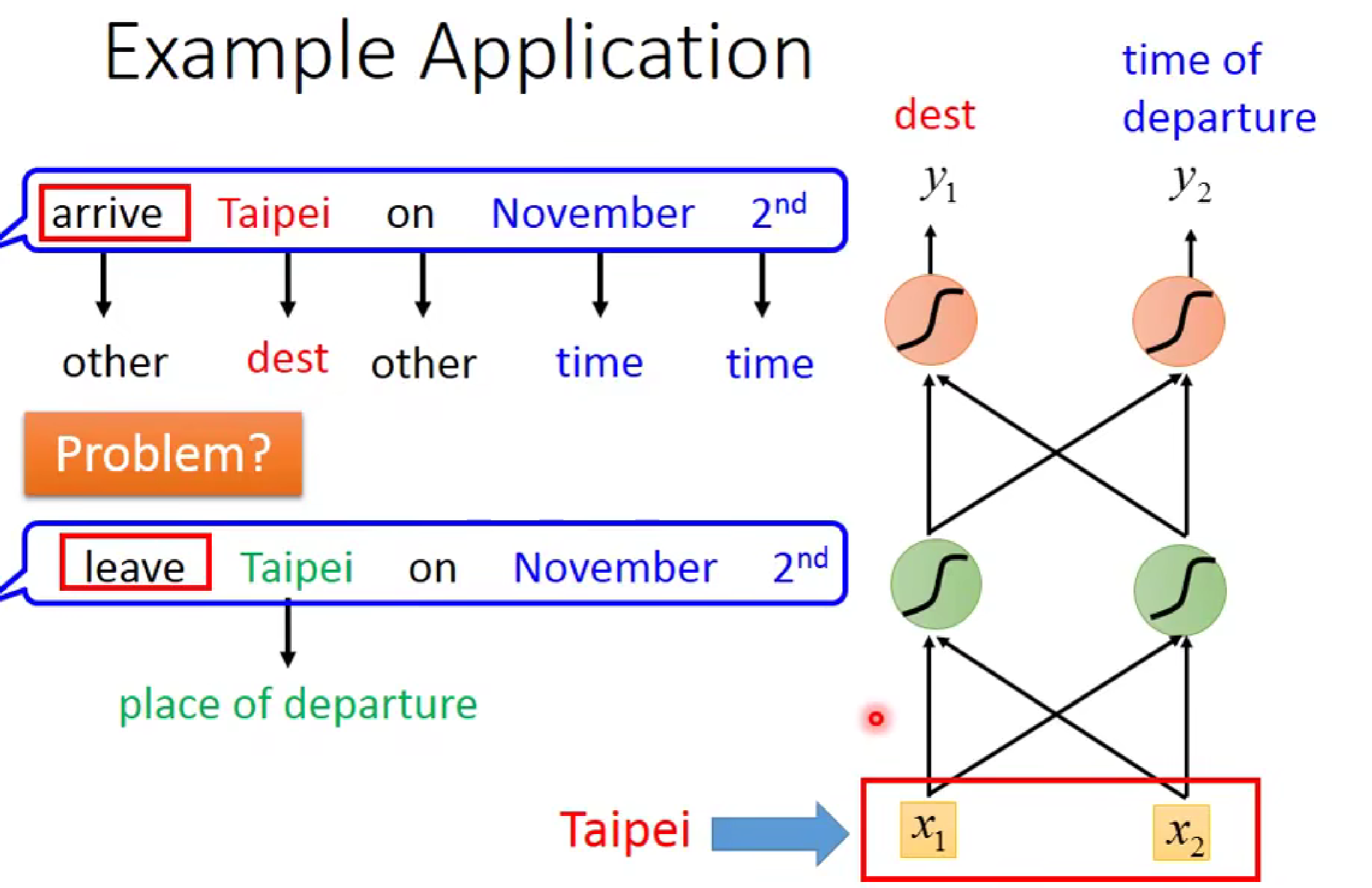
如图,在进行智慧客服等项目场景中,如果我们用前馈神经网络。当我们输入同一个词汇Taipei时,神经网络并不能知道此时的问题是目的地还是出发地,因为神经网络不能做到联系上下文的词汇(也就是没有记忆性),为此,RNN等一系列神经网络横空出世。
二,推导过程
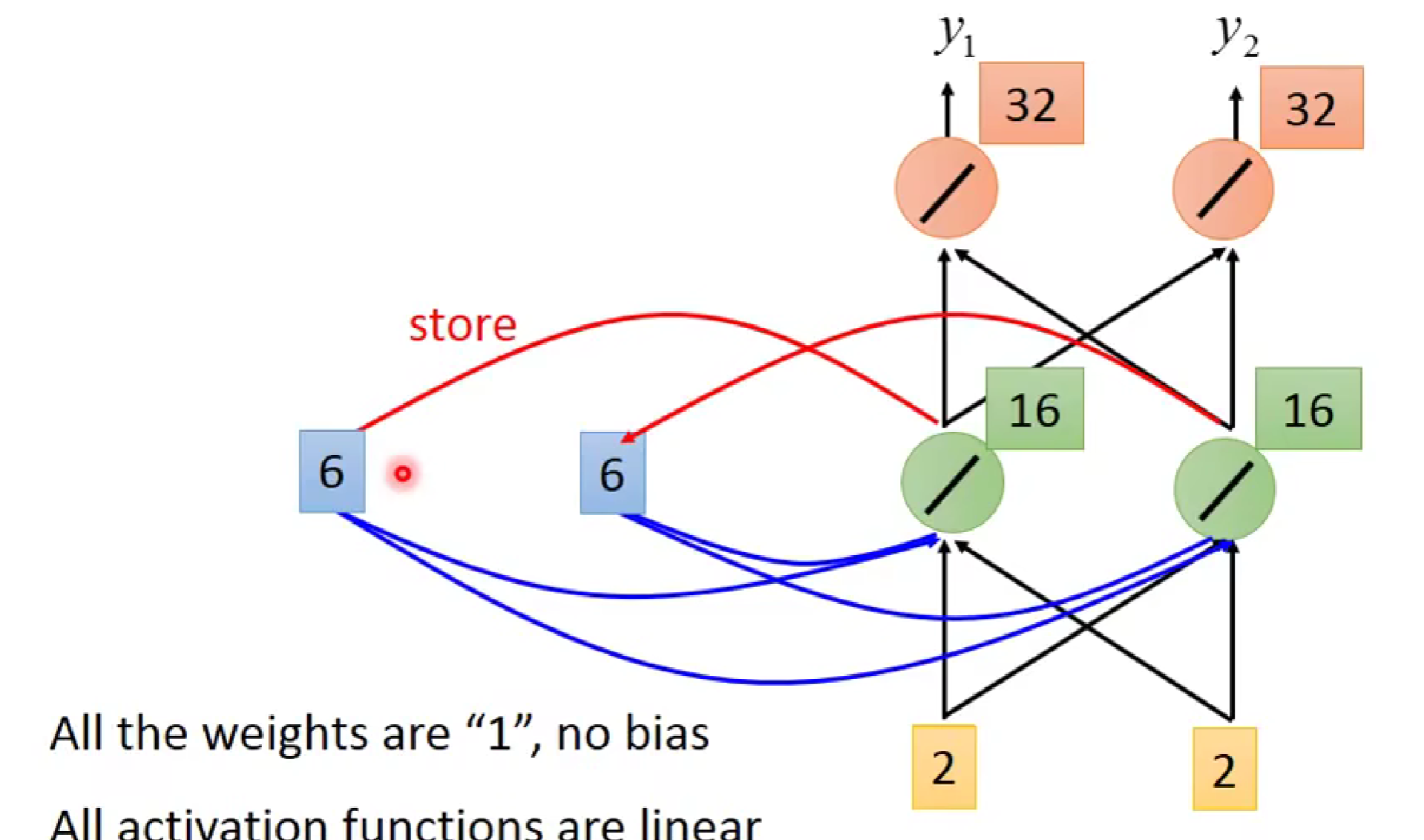
如图,为了使输入具有记忆性,我们对每一个神经元的输出(绿色部分)进行memory,在下一次输入时,上一次储存的输出同这一次输入共同作为输入,起到联系上下文的效果。当开始时,我们先对记忆单元进行初始化00.同时,此神经网络的所有权重都为1,偏置为0.
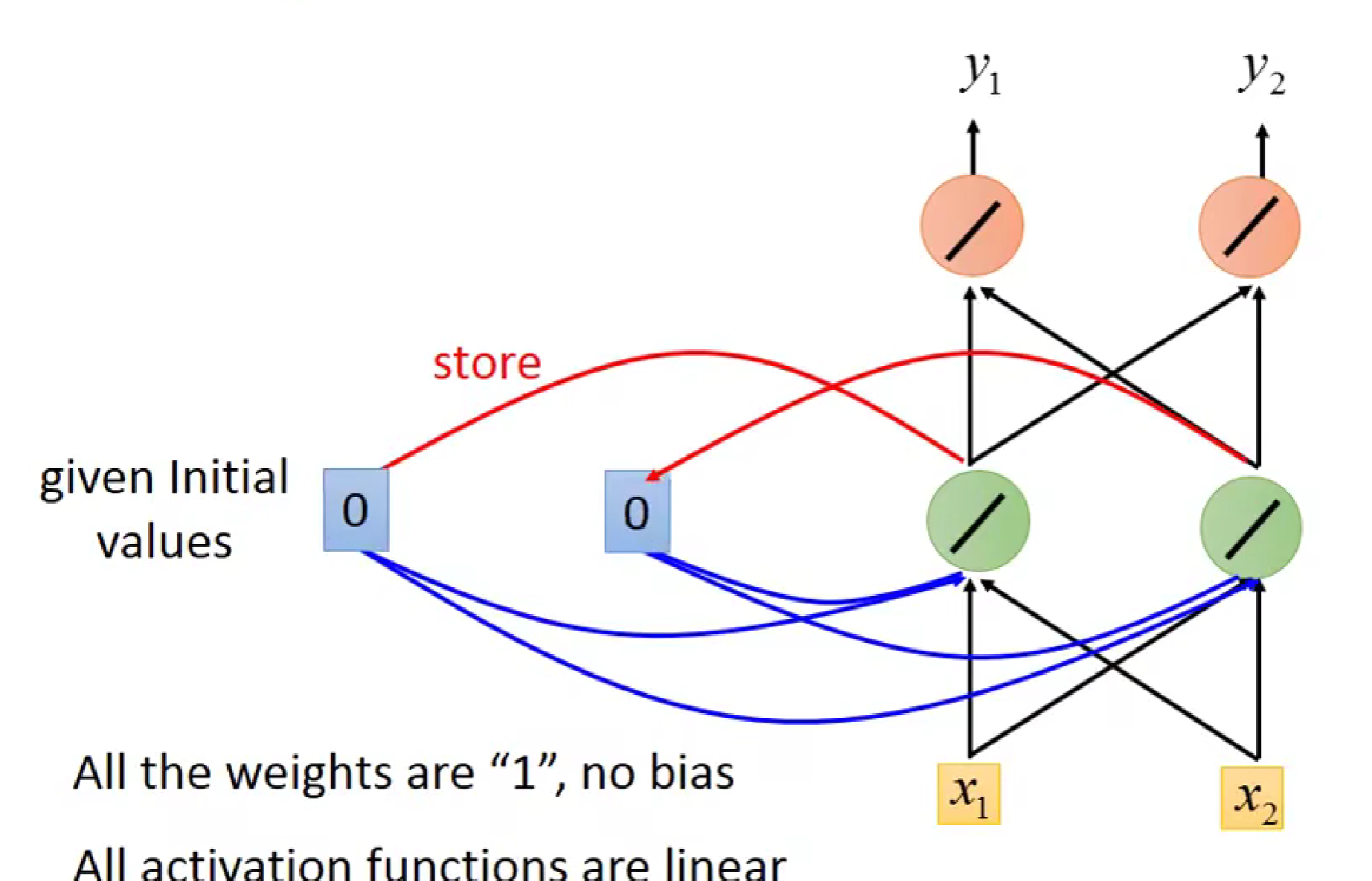
接着,我们对x1,x2输入1,1。可知,绿色神经元输出分别为2,2,橙色神经元输出为4,4.
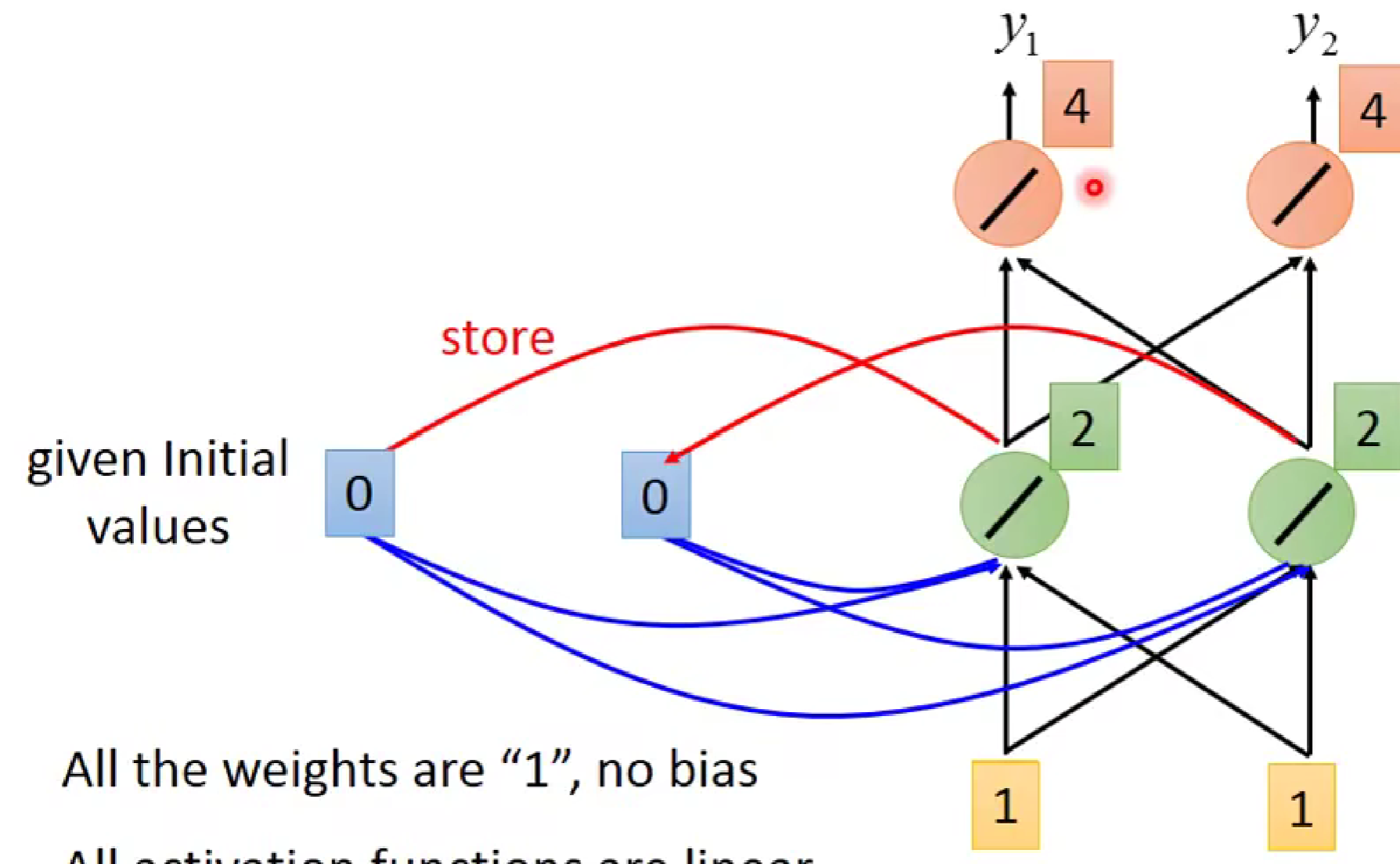
在第一次输入后,蓝色记忆储存部分就把绿色部分的输出进行储存。蓝色部分由00变为2,2
接着,我们再进行1,1的输入。
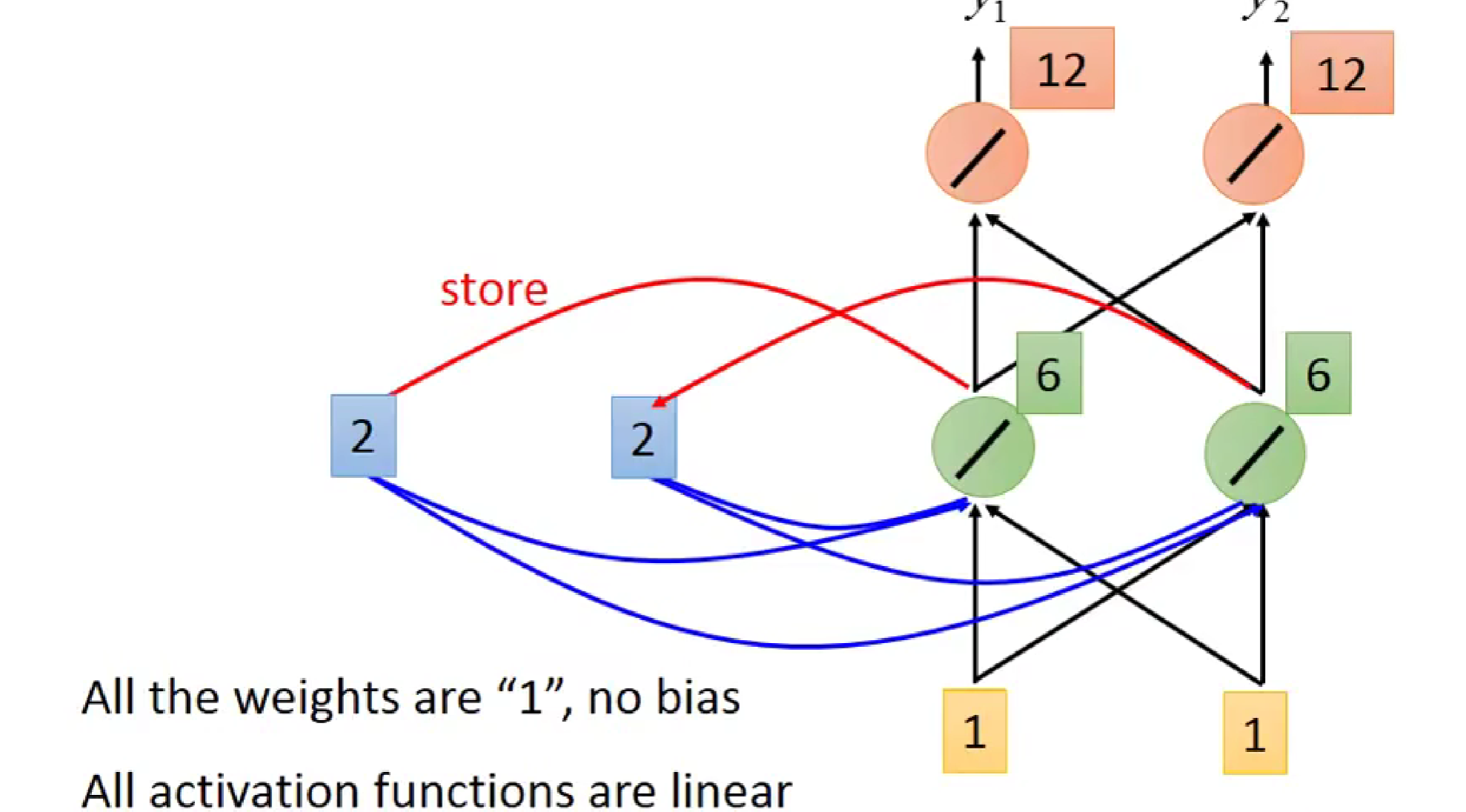
由图知,绿色的输入为1+1+2+2+2为6(全连接哦),橙色部分为6+6=12
同理,当我们再输入2,2时,各部分·输出为:
也就是说,输入和输出分别为:
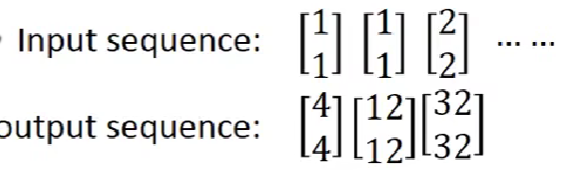
基于此原理,RNN便构造出来了(注意:这里只是一层,是一层中的不同时刻)
对于RNN,他有很多变式,比如:
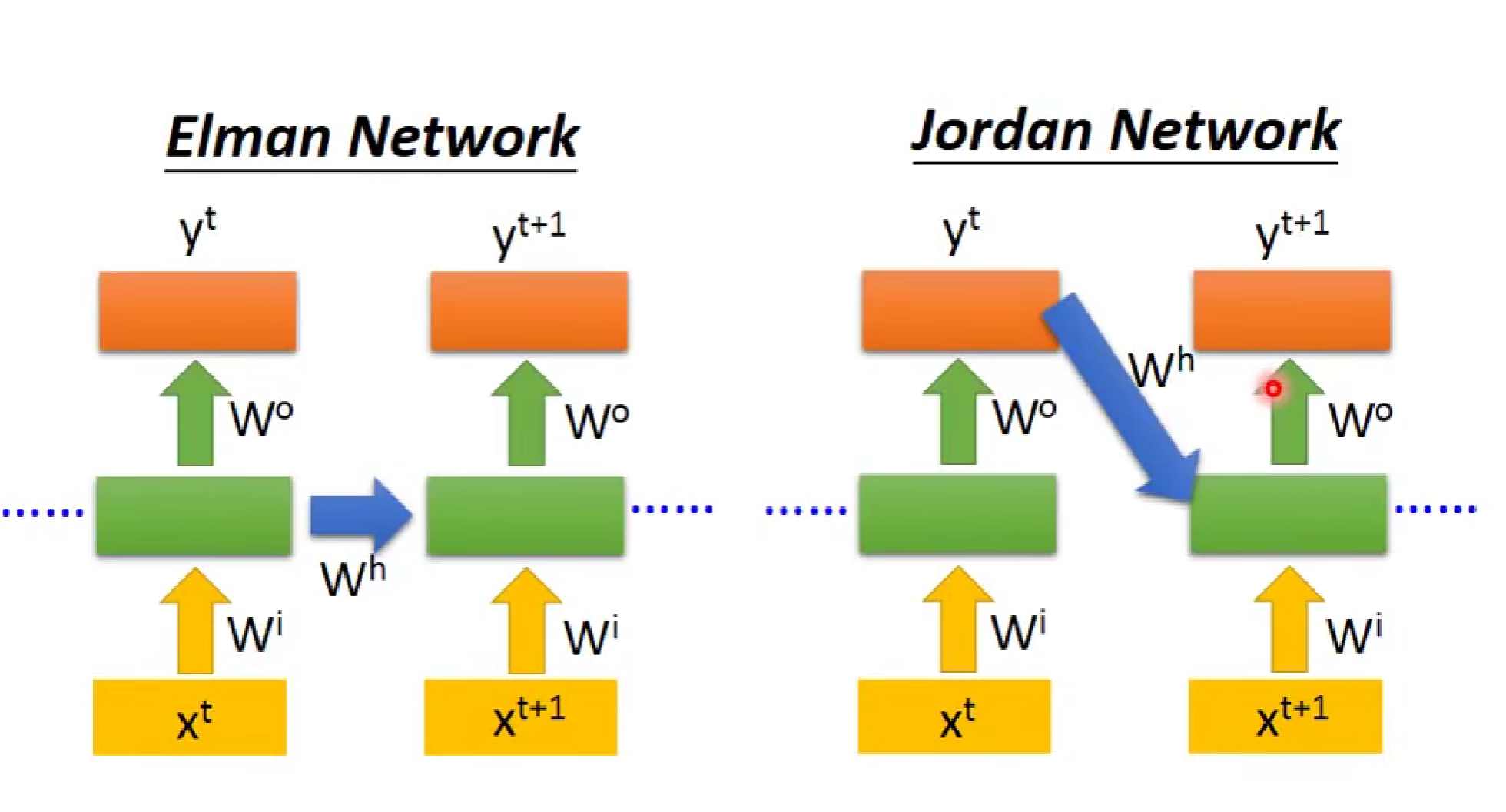
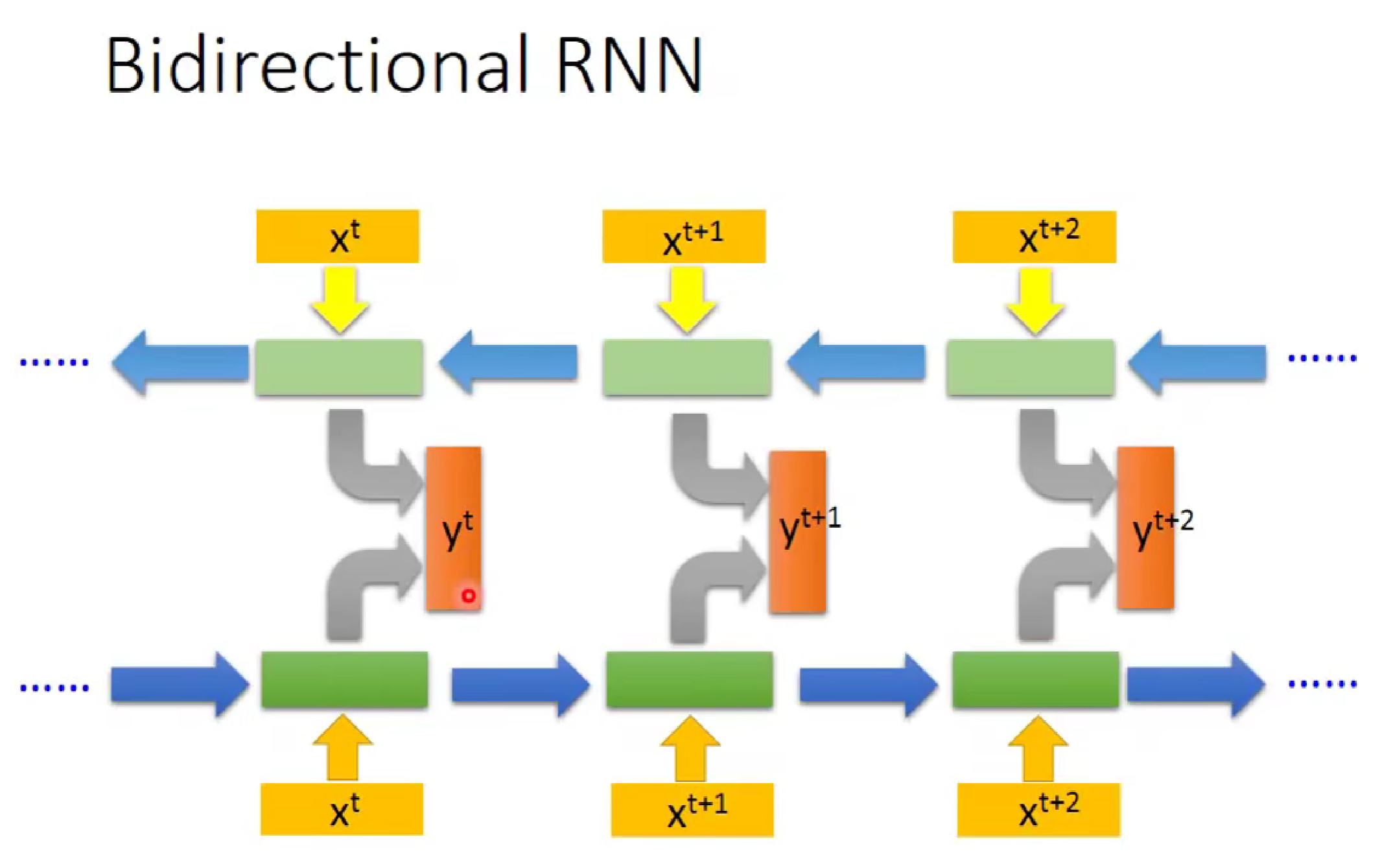
三 改进记忆部分--引入LSTM
由于上述RNN的记忆单元只能记忆很短的部分,似乎不太好,为此我们引入了长短序列记忆单元。
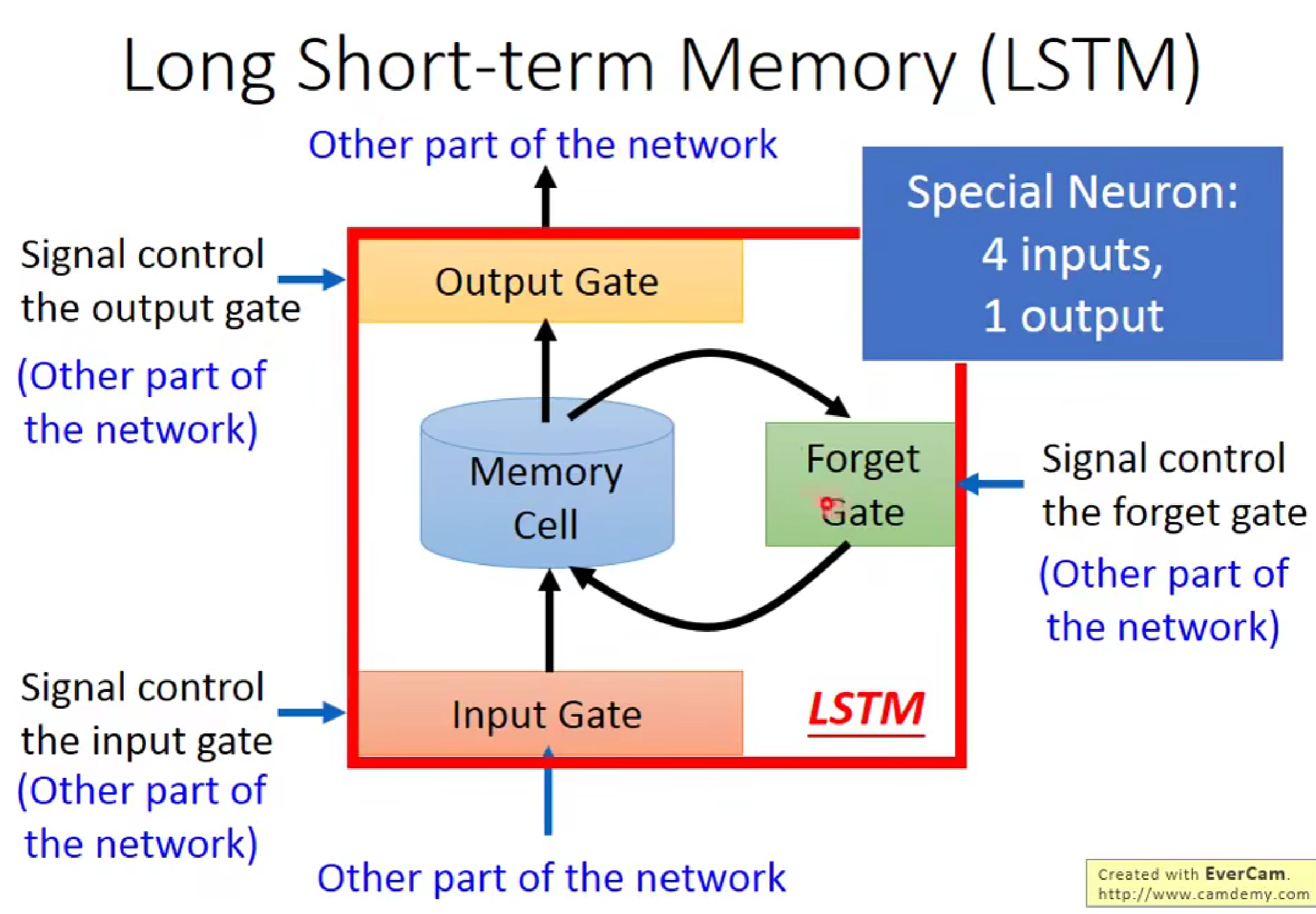
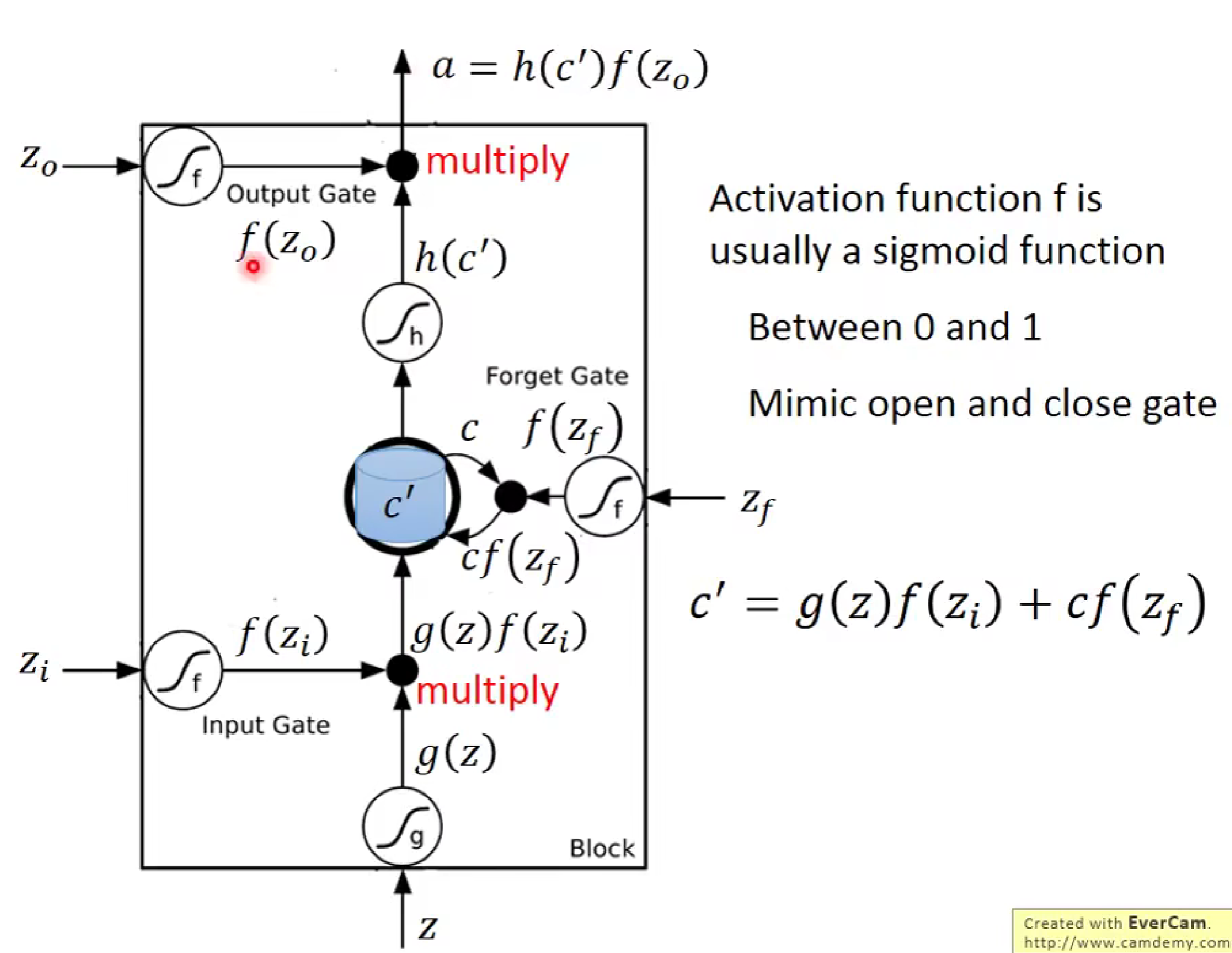
如上图所示输入Z为输入口,Zi为输入控制门,Zo为输出控制门,Zf为记忆单元的原谅门,他们都采用sigmod函数(0,1控制),c为记忆单元,c'为下一更新的记忆单元。
LSTM流程为,当我们输入z,经过激活函数G(z)后,需要与input gate 进行相乘来控制是否将输入进行进一步输入,此时输出结果会来到记忆单元处,记忆单元原先记忆值会与f(zf)函数进行相乘判断是否将先前记忆值进行加入,最后两者相加经过激活函数来到输出处,输出值通过与输出控制门相乘来决定是否将输出值输出。
这里举一个具体的例子:
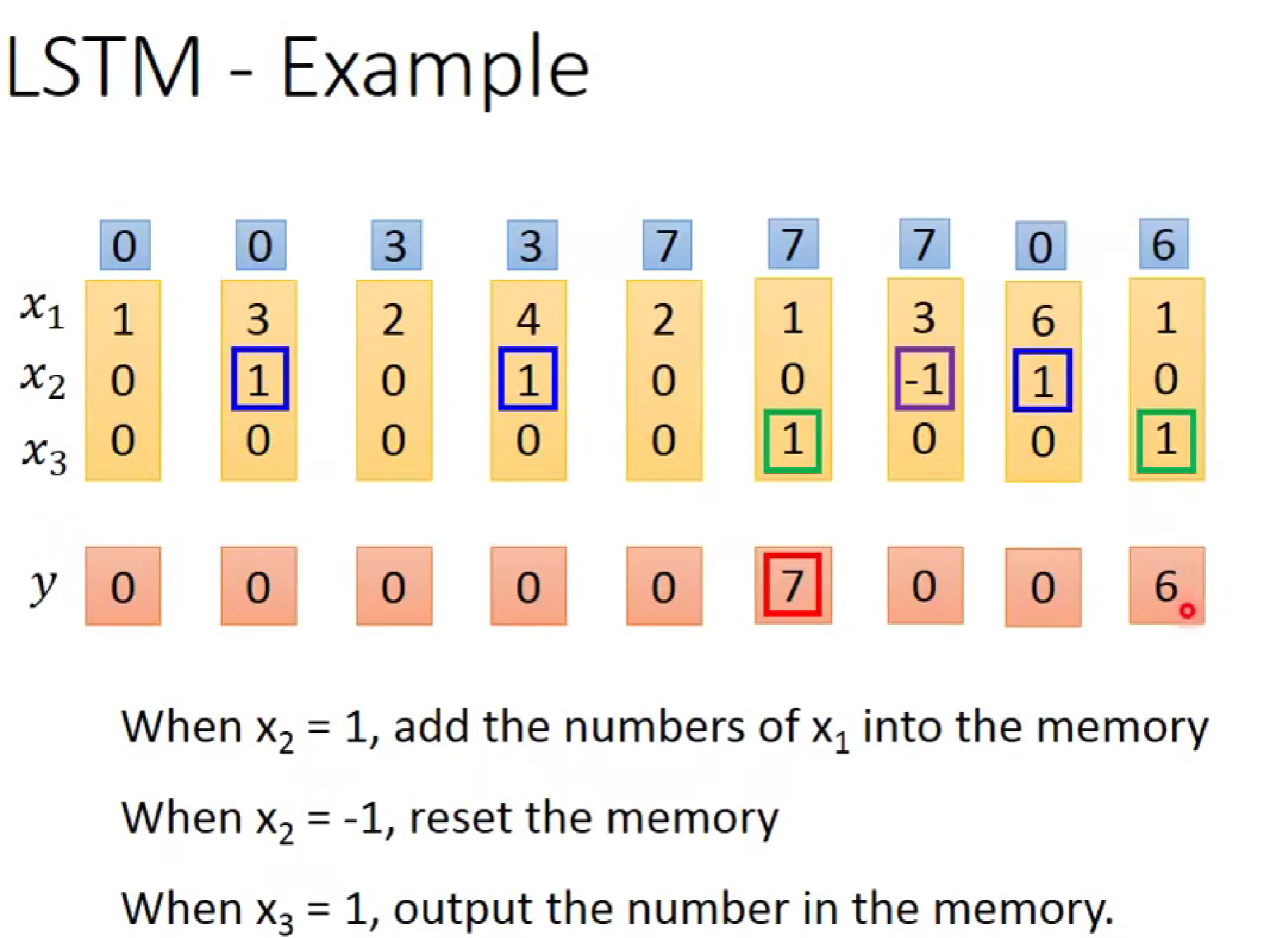
如图,当x2是1时,会把记忆值加入后面的输出,所以第二列x2为1时,输入值x1=3被记忆,第三列的记忆值由0--->3;第七列的x2为-1时,记忆值被丢弃,所以第八列的记忆值变为了0,当x3为1时,将输出值进行输出,所以第6列输出y为7.
注意:当我们输入词向量Xt时,每一个控制门的参数并不是相同的,对于输入的X,会经过参数矩阵生成4个不同的参数向量(vectors),然后以矩阵形式同时传递给不同的LSTM。
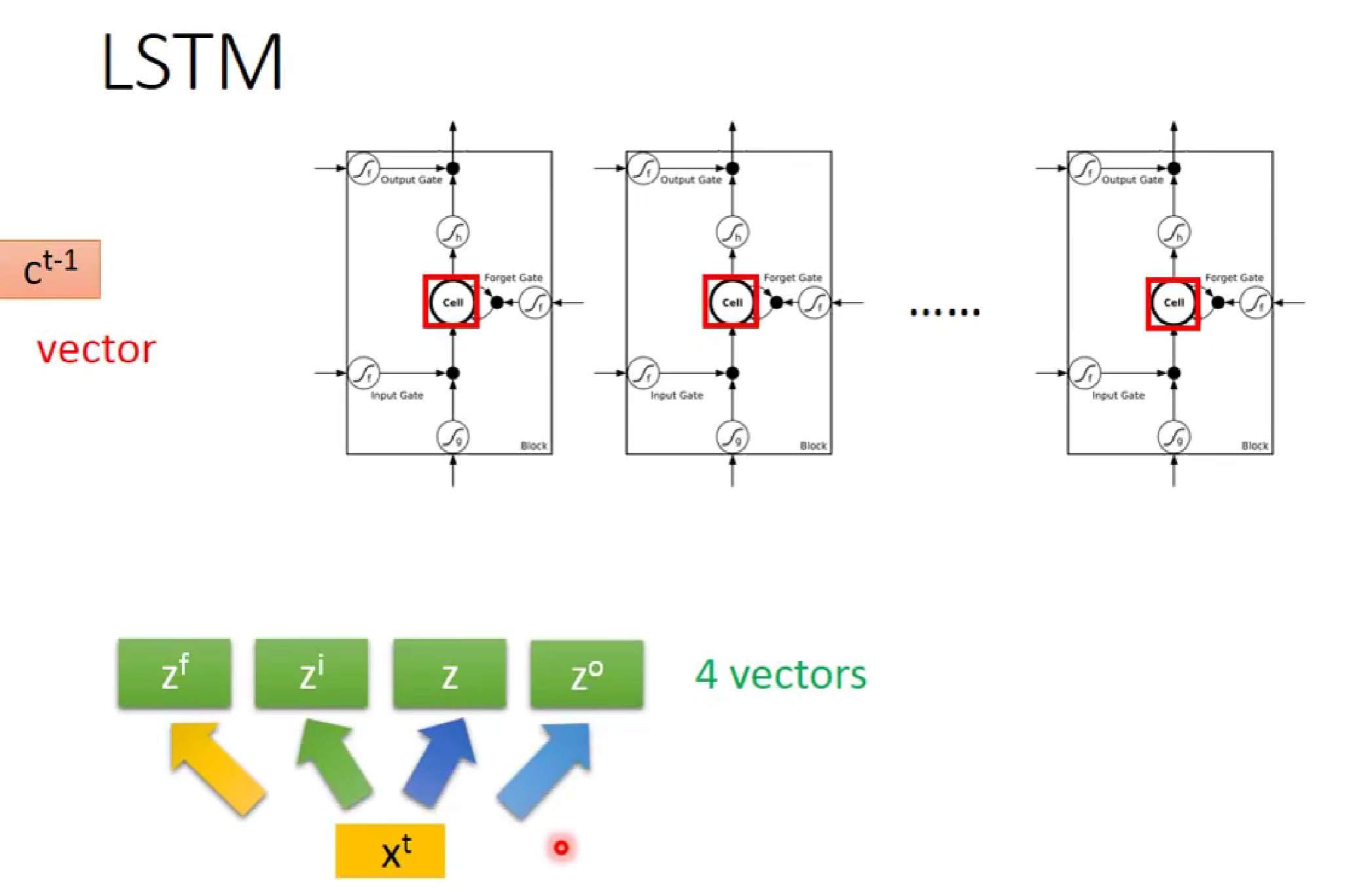
由此,LSTM的流程便为:
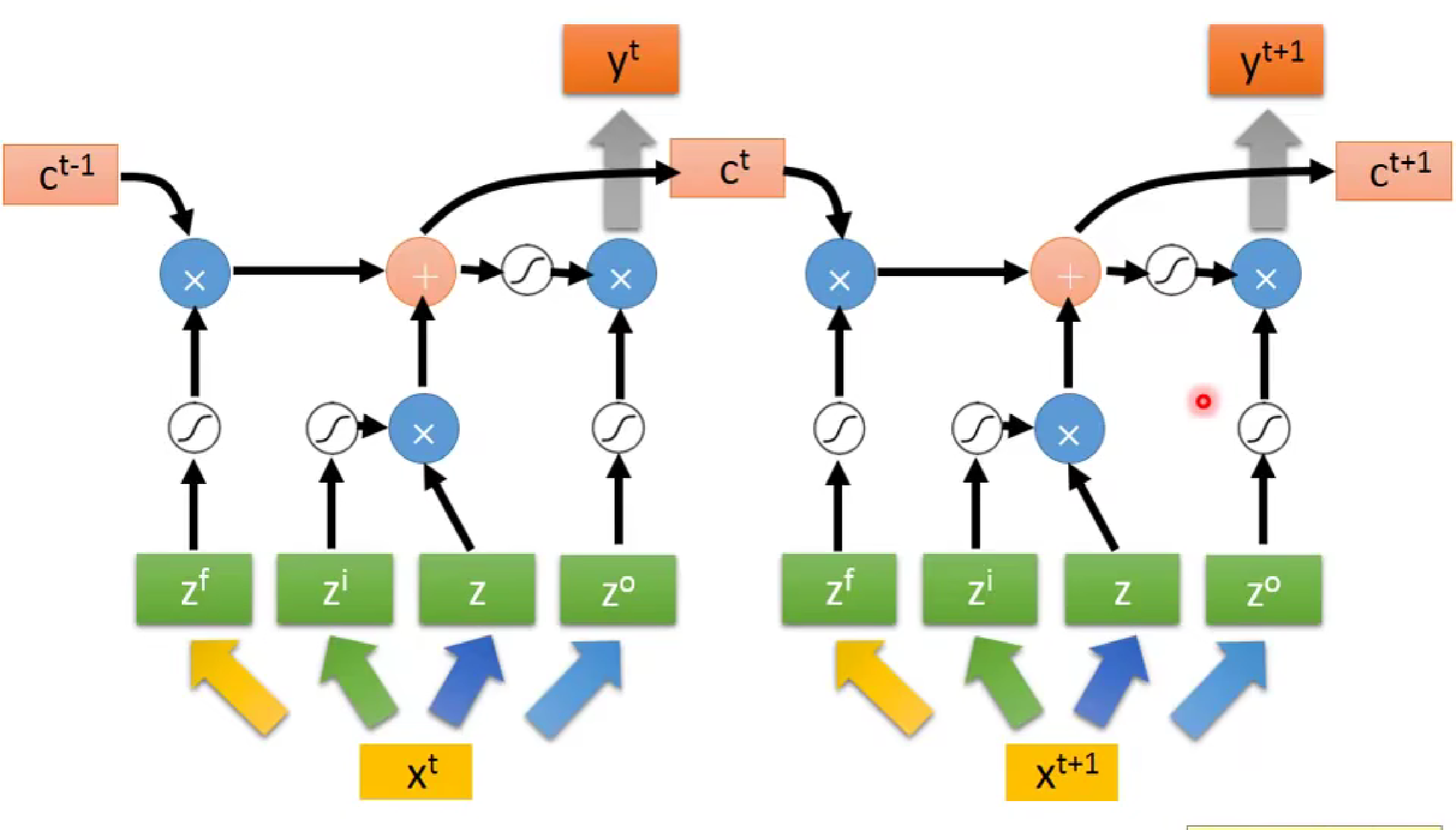
此时,LSTM 并不是最终形态,有时候(如下图,)LSTM会把上一次的输出和记忆值也作为下一次的输入。
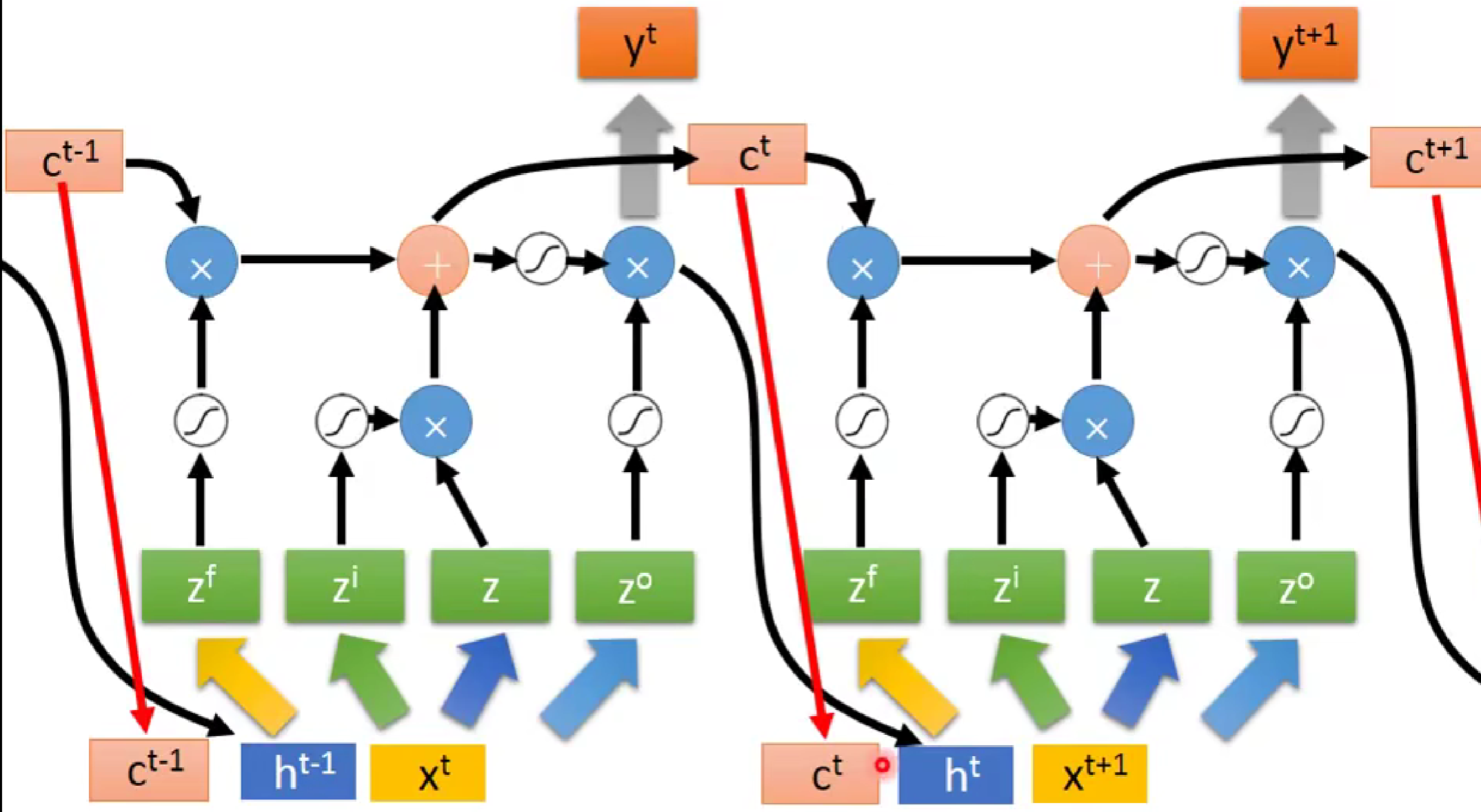
由此,最终形态的LSTM就形成了。
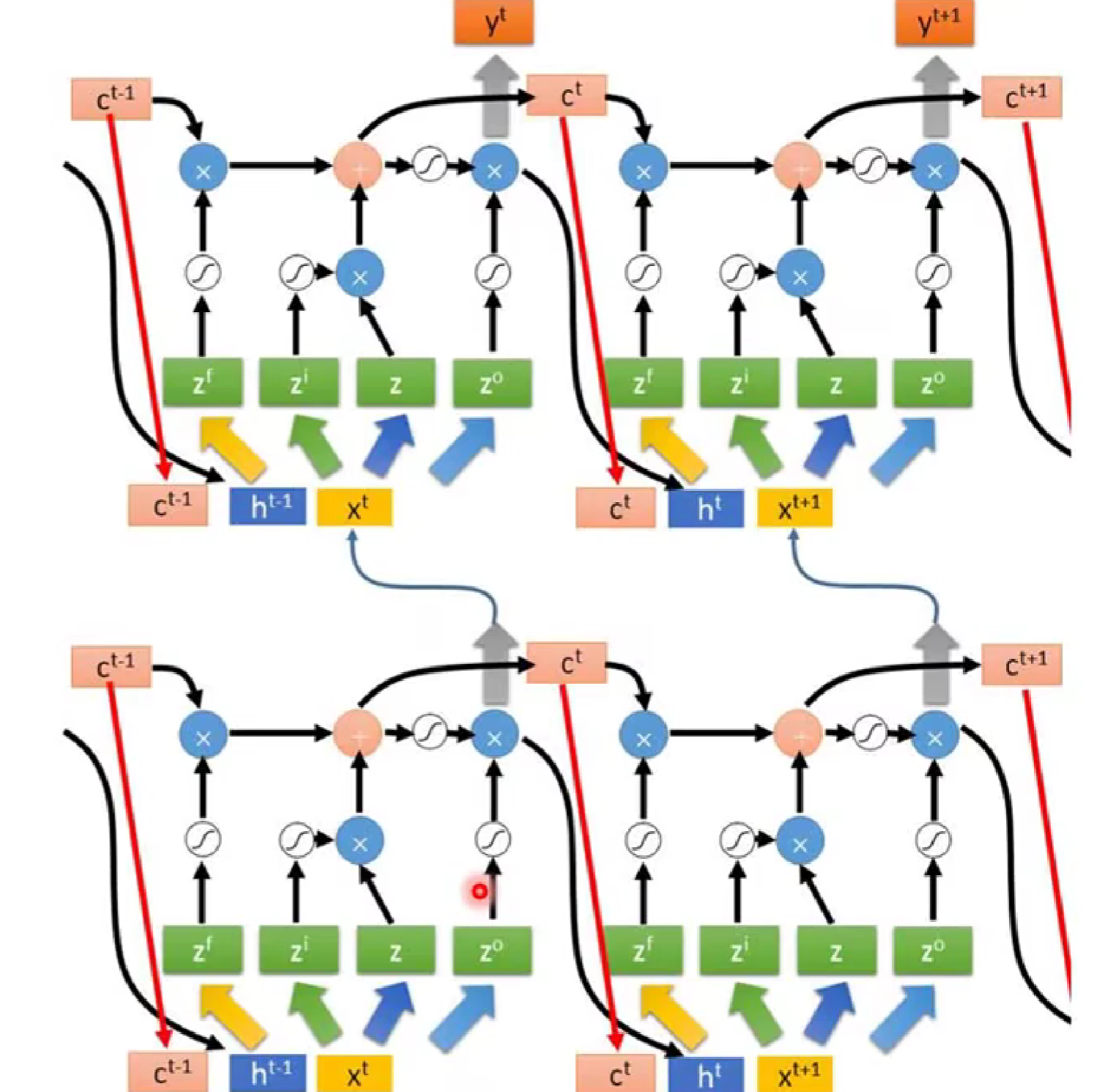
四,关于RNN 的LOSS参数更新
在RNN的参数更新中,是非常容易导致梯度爆炸的。
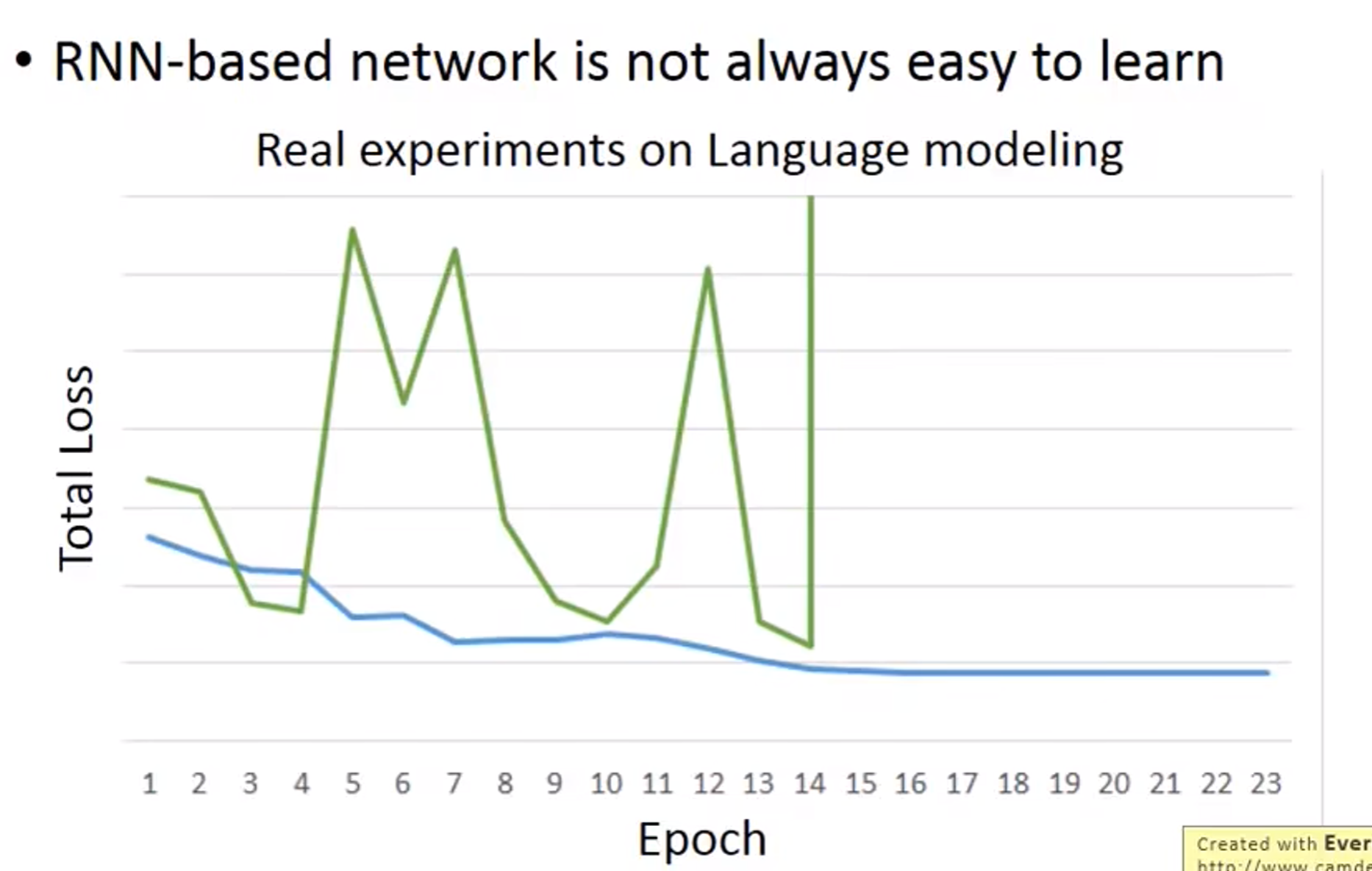
为了解决这种问题,有一篇论文用到了梯度裁剪(clipping)
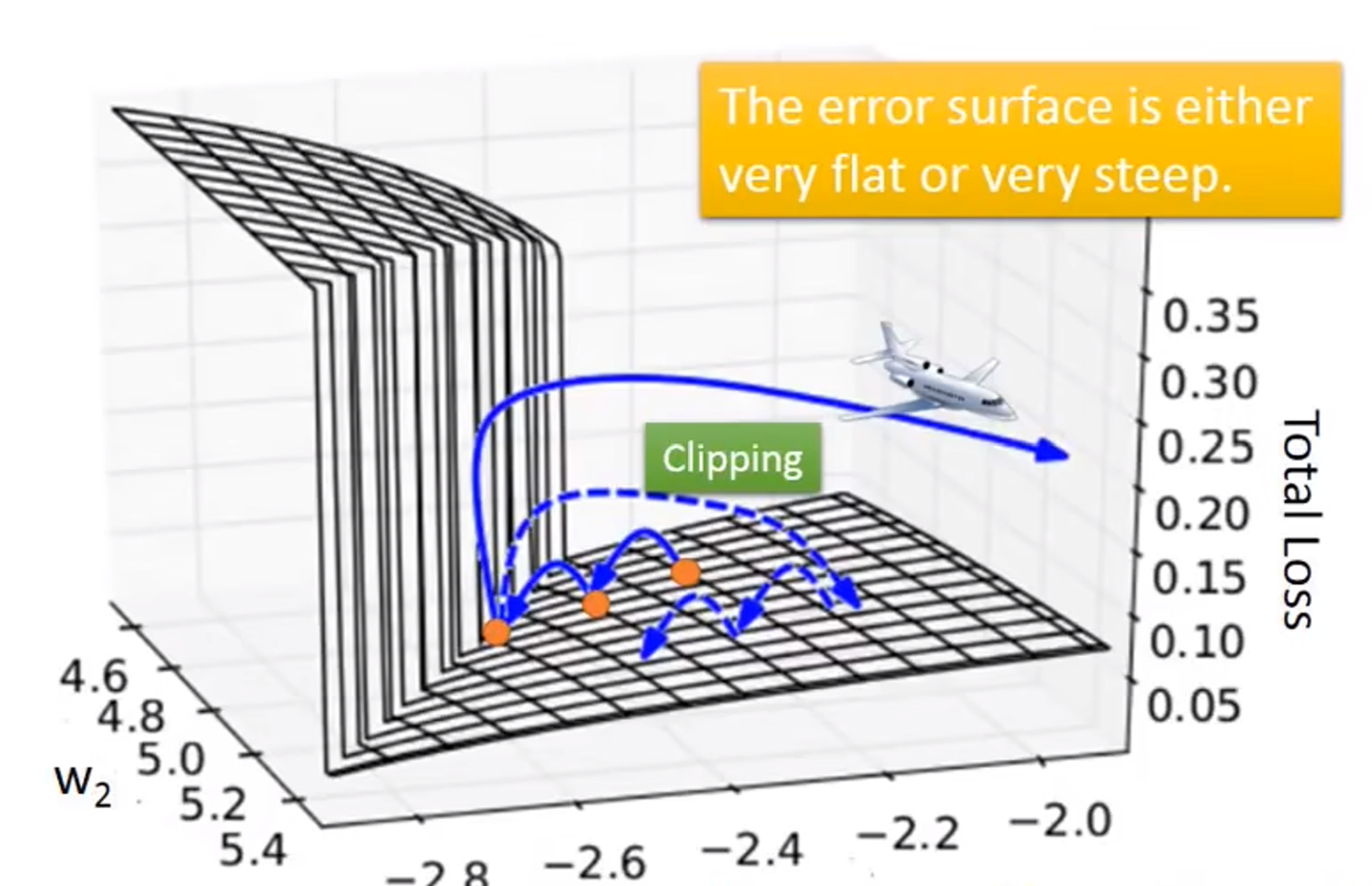
当然了,我们需要思考,是什么导致了梯度爆炸。
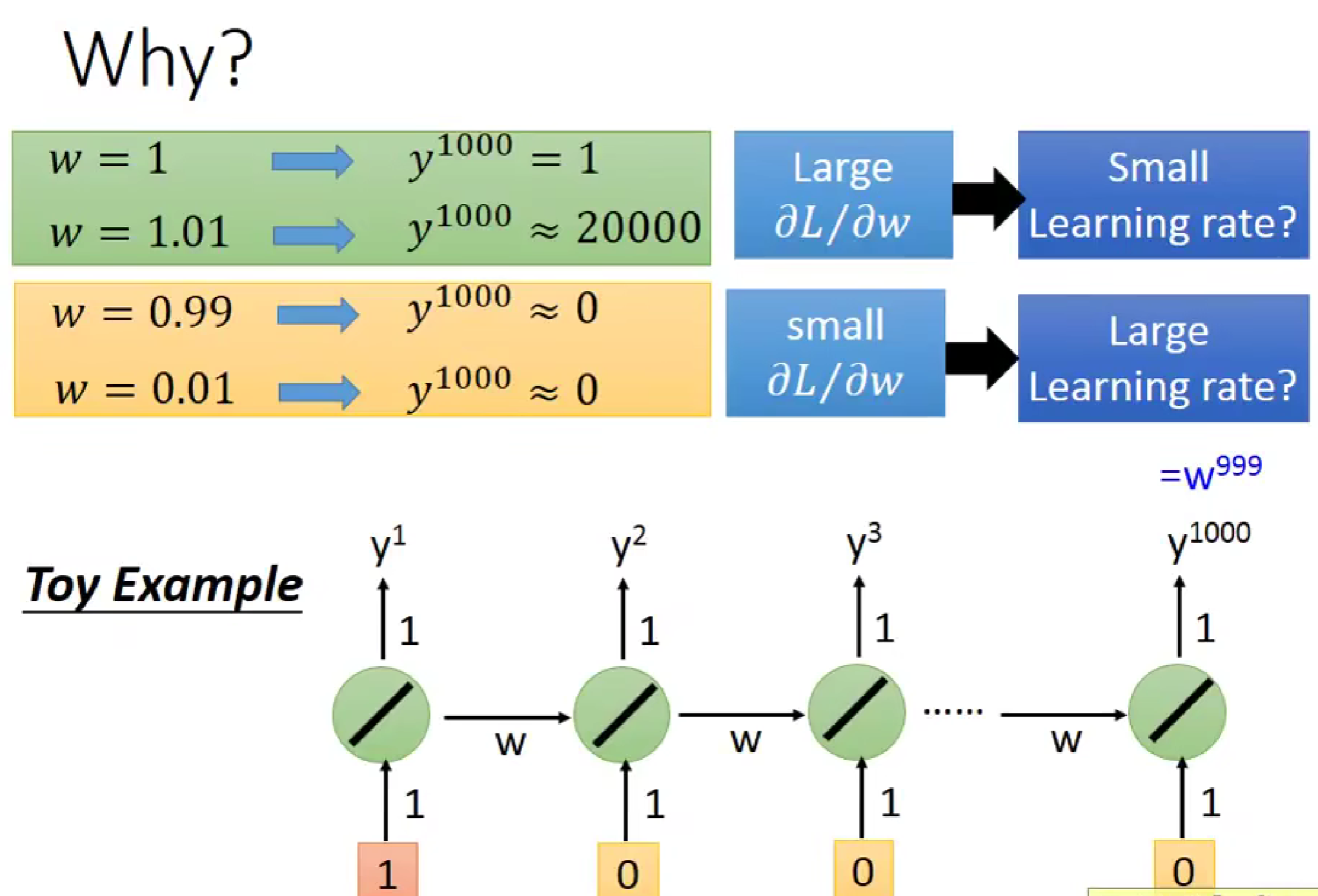
图解分析
上半部分
权重 ww 对输出的影响:
- 当 w=1w=1 时,y1000=1y1000=1。这意味着输出稳定在一个常数。
- 当 w=1.01w=1.01 时,y1000≈20000y1000≈20000。这说明即使是很小的增量(0.01),经过多次迭代后也会导致输出急剧增加,这就是梯度爆炸的根源。
- 当 w=0.99w=0.99 或 w=0.01w=0.01 时,y1000≈0y1000≈0。这表明权重小于1时,输出会趋向于零,即梯度消失。
梯度和学习率的关系:
- 大的 ∂L∂w∂w∂L (损失函数对权重的导数)对应小的学习率,以避免过大的更新步长。
- 小的 ∂L∂w∂w∂L 对应大的学习率,以便让模型能够快速收敛。
下半部分
- 玩具示例:
- 这是一个简单的RNN结构,每个时间步的输出都会作为下一个时间步的输入。
- 权重 ww 在每个时间步都被重复使用,这导致了梯度在反向传播过程中的累积效应。
梯度爆炸的解释
在RNN中,梯度爆炸主要发生在权重接近或大于1的情况下。由于RNN的结构特性,梯度会在时间维度上累积。具体来说:
- 如果权重 ww 接近1,每次反向传播时梯度都会被放大。
- 经过多个时间步后,这些放大的梯度会累积成一个非常大的数值,导致参数更新的幅度过大,从而引发梯度爆炸。
好喽好喽,看了两遍才看懂,本来不看的,但是transform要有这些基础知识。
拜拜了您嘞
