Vscode Data Wrangler 数据查看和处理工具
0、简介
Data Wrangler 是一款以代码为中心的数据查看和清理工具,它集成在 VS Code 和 VS Code Jupyter Notebooks 中。它提供了一个丰富的用户界面,用于查看和分析你的数据,显示富有洞察力的列统计信息和可视化,并在你清理和转换数据时自动生成 Pandas 代码。
- 可视化界面,便于查看和分析
- 丰富的列统计信息
- 自动生成处理数据的代码
1、安装和设置 Data Wrangler
- 安装python(支持3.8以上版本)
- 安装VScode
- 安装 Data Wrangler 扩展
2、使用 Data Wrangler
无论何时你使用 Data Wrangler,你都处于一个沙盒环境中,这意味着你可以安全地探索和转换数据。原始数据集在你明确导出更改之前不会被修改。
2.1 从 Jupyter Notebook 启动 Data Wrangler
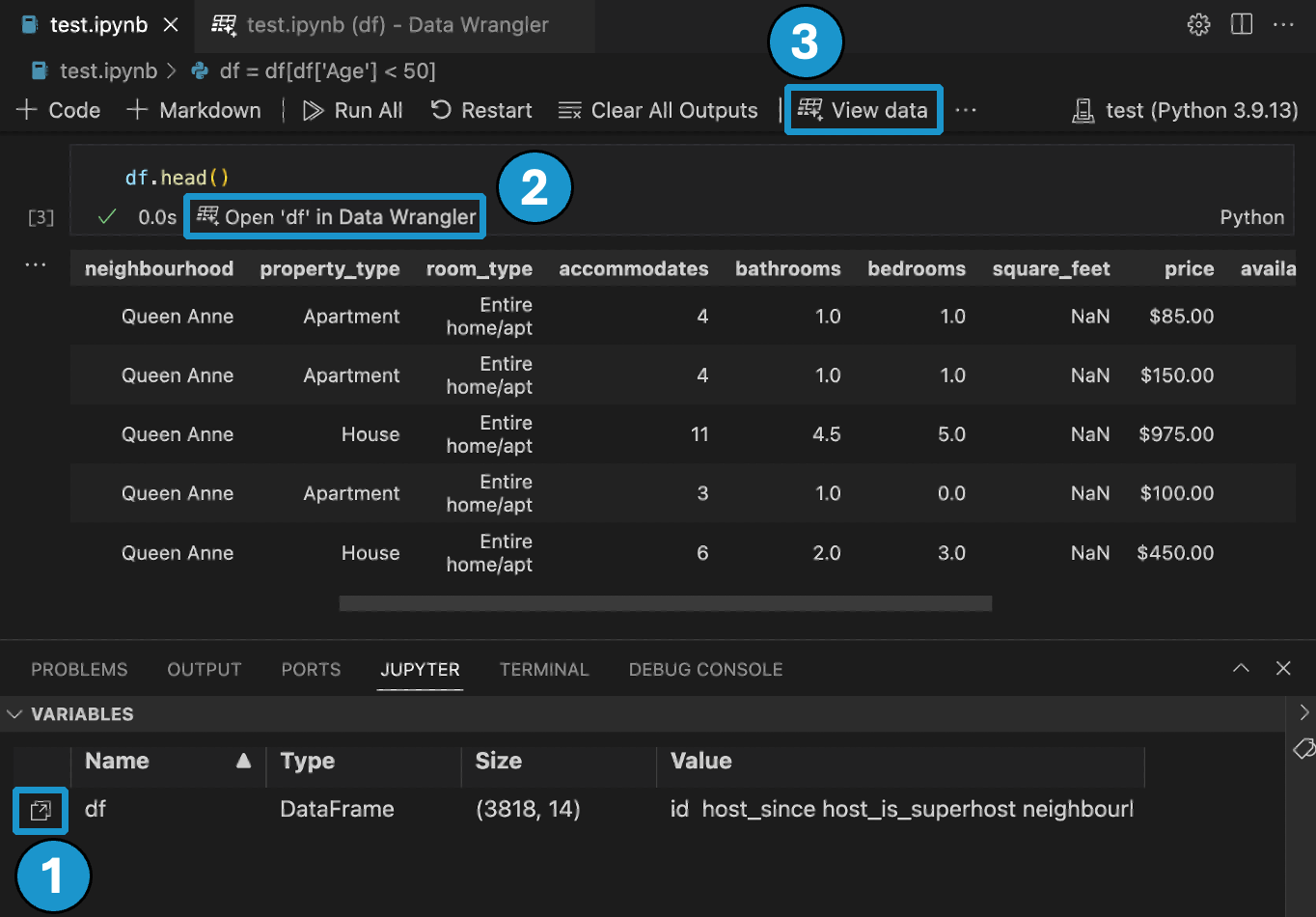
有三种方法可以从你的 Jupyter Notebook 启动 Data Wrangler
- 在 Jupyter > 变量面板中,在任何受支持的数据对象旁边,你都可以看到一个用于启动 Data Wrangler 的按钮。
- 在运行输出Pandas 数据框的代码后,在单元格底部看到一个在 Data Wrangler 中打开 ‘df’ 按钮。包括 1) df.head(), 2) df.tail(), 3) display(df), 4) print(df), 5) df 等代码。
- 在笔记本工具栏中,选择查看数据会弹出一个列表,其中包含笔记本中所有受支持的数据对象。然后你可以选择该列表中你希望在 Data Wrangler 中打开的变量。
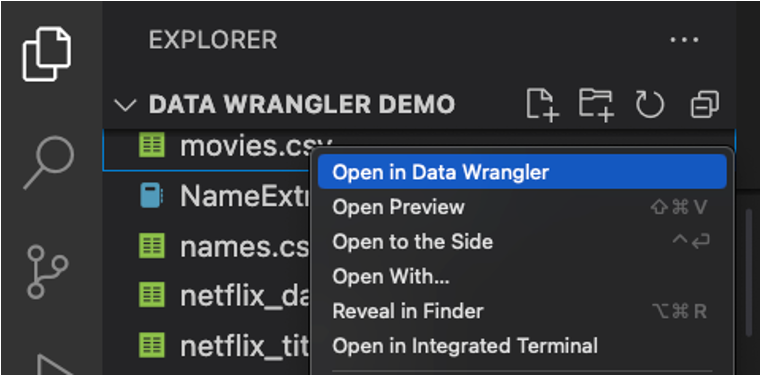
2.2 直接打开表格文件启动 Data Wrangler
直接从本地文件(例如 .csv 文件)启动 Data Wrangler。在文件资源管理器视图中,右键单击该文件,然后点击在 Data Wrangler 中打开。支持文件类型包括 .csv/.tsv/.xls/.xlsx/.parquet
3、查看数据
Data Wrangler 在处理数据时有两种模式。
- 查看模式:查看模式优化了界面,使你能够快速查看、筛选和排序数据。此模式非常适合对数据集进行初步探索。
- 编辑模式:编辑模式优化了界面,使你能够对数据集应用转换、清理或修改。当你在界面中应用这些转换时,Data Wrangler 会自动生成相关的 Pandas 代码,这些代码可以导出回你的笔记本以供重用。
3.1 查看模式界面
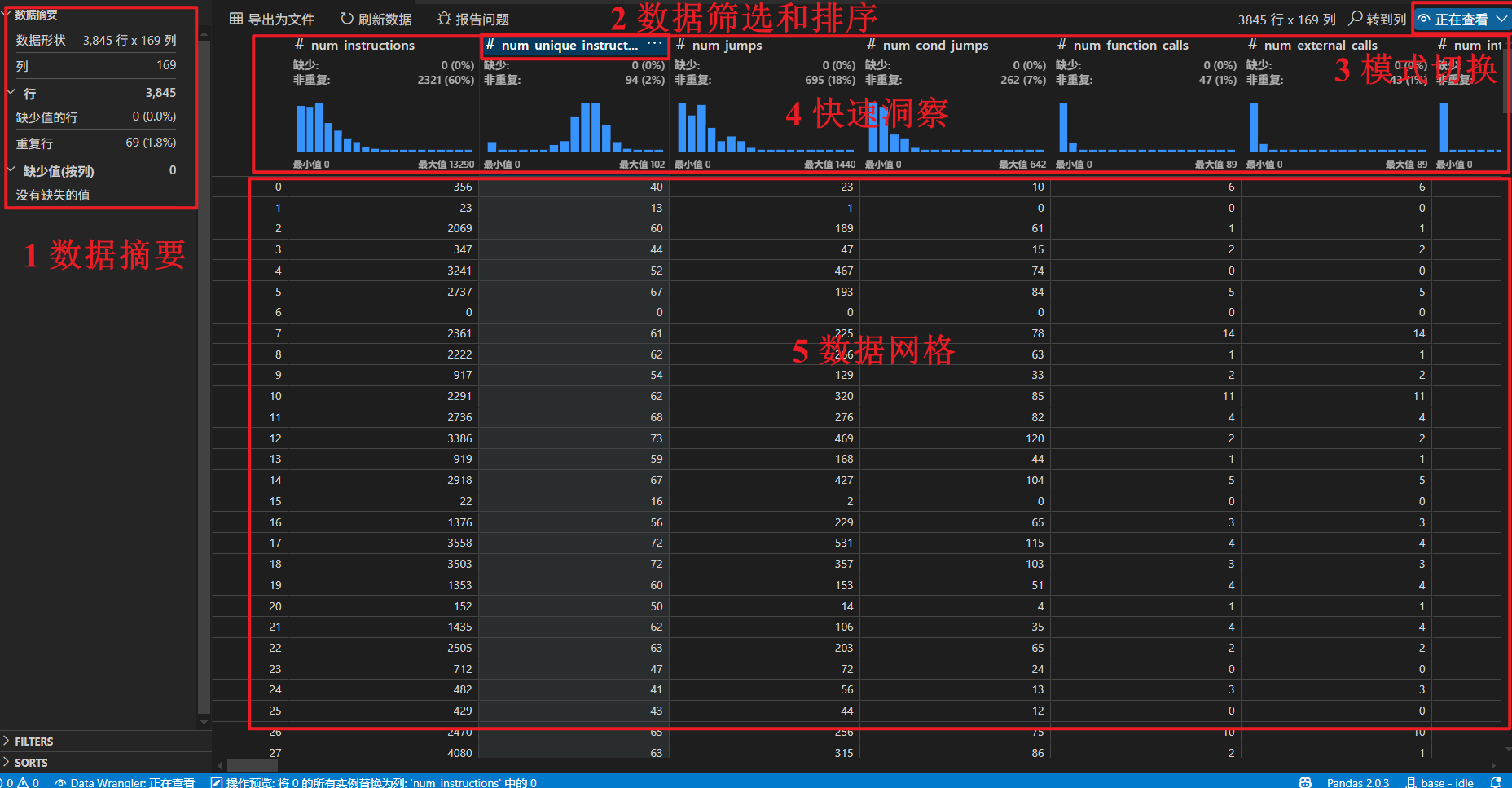
- 数据摘要:显示数据集整体统计信息,包括数据形状、行、列、缺少值等;
- 数据筛选和排序;
- 模式切换:查看模型和编辑模式切换;
- 快速洞察:快速查看每列有价值信息的地方。根据列的数据类型,快速洞察会显示数据的分布、数据点的频率、缺失值和唯一值;
- 数据网格:提供一个可滚动窗格,查看整个数据集。
3.2 编辑模式界面
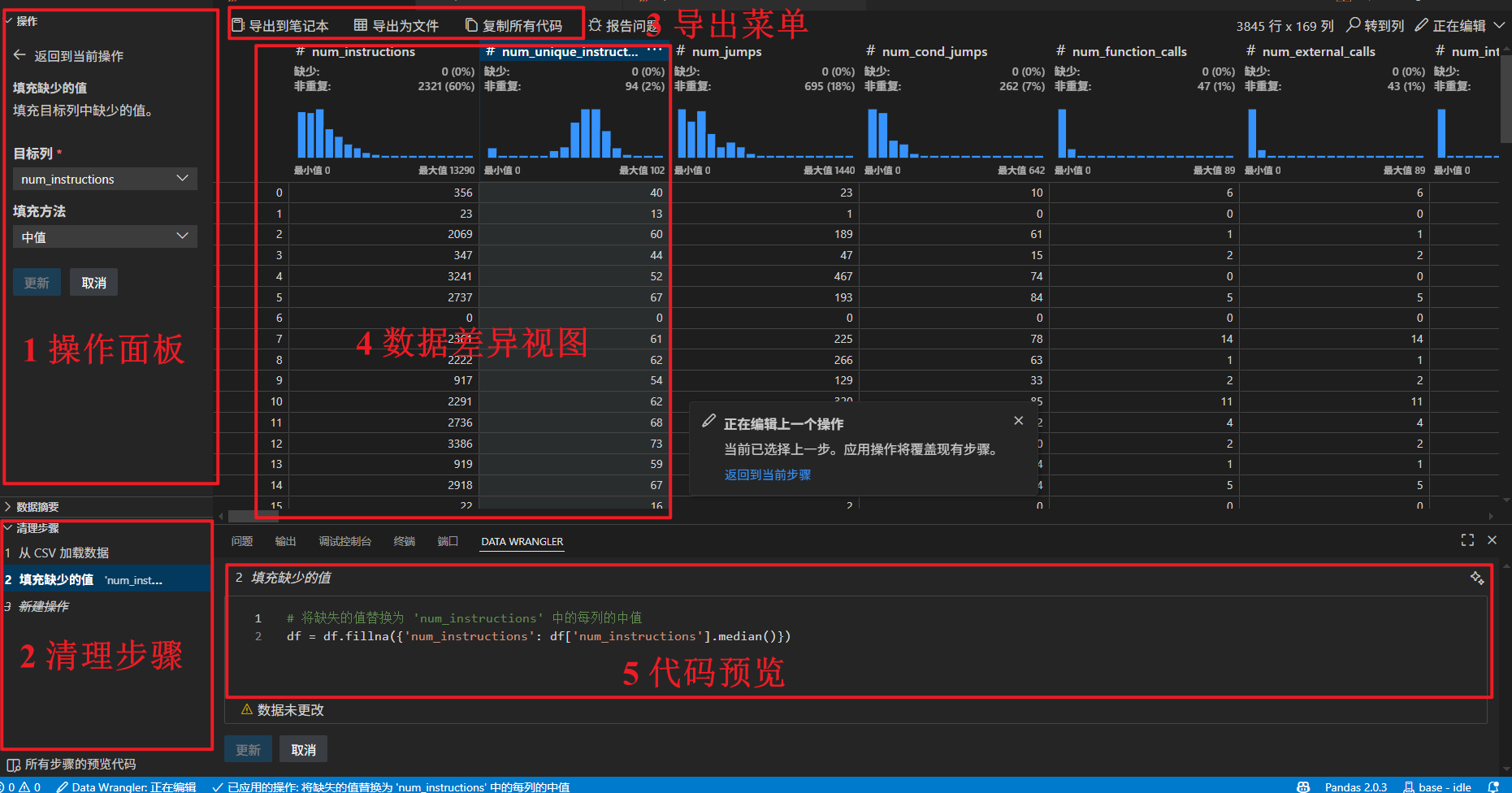
切换到编辑模式会启用 Data Wrangler 中的额外功能和用户界面元素。
- 操作面板:所有内置数据操作的地方,包括查找和替换、格式、公式、架构、排序和筛选、数值等;
- 清理步骤面板:显示了已应用的所有操作的列表。它使用户能够撤消特定操作或编辑最新操作。选择一个步骤将突出显示数据差异视图中的更改,并显示与该操作相关的生成代码。
- 导出菜单:将代码导出到 Jupyter Notebook 或将数据导出到新文件。
- 数据差异视图:显示对数据所做的更改。
- 代码预览部分:显示在选择操作时生成的 Python 和 Pandas 代码,也可以编辑生成的代码,此时数据网格将突出显示对数据的影响。
4、数据操作
| 操作 | 描述 |
|---|---|
| 排序 | 按升序或降序排序一列或多列 |
| 筛选 | 根据一个或多个条件筛选行 |
| 计算文本长度 | 创建新列,其值等于文本列中每个字符串值的长度 |
| 独热编码 | 将分类数据拆分为每个类别的新列 |
| 多标签二值化 | 使用分隔符将分类数据拆分为每个类别的新列 |
| 从公式创建列 | 使用自定义 Python 公式创建列 |
| 更改列类型 | 更改列的数据类型 |
| 删除列 | 删除一列或多列 |
| 选择列 | 选择要保留的一列或多列,并删除其余列 |
| 重命名列 | 重命名一列或多列 |
| 克隆列 | 创建一列或多列的副本 |
| 删除缺失值 | 删除包含缺失值的行 |
| 删除重复行 | 删除在一列或多列中具有重复值的所有行 |
| 填充缺失值 | 用新值替换包含缺失值的单元格 |
| 查找并替换 | 用匹配模式替换单元格 |
| 按列分组并聚合 | 按列分组并聚合结果 |
| 去除空白字符 | 去除文本开头和结尾的空白字符 |
| 拆分文本 | 根据用户定义的分隔符将一列拆分为多列 |
| 首字母大写 | 将第一个字符转换为大写,其余转换为小写 |
| 将文本转换为小写 | 将文本转换为小写 |
| 将文本转换为大写 | 将文本转换为大写 |
| 通过示例进行字符串转换 | 当你提供的示例中检测到模式时,自动执行字符串转换 |
| 通过示例进行日期时间格式化 | 当你提供的示例中检测到模式时,自动执行日期时间格式化 |
| 通过示例创建新列 | 当你提供的示例中检测到模式时,自动创建一列。 |
| 缩放最小值/最大值 | 将数值列缩放到最小值和最大值之间 |
| 四舍五入 | 将数字四舍五入到指定的小数位数 |
| 向下取整(向下舍入) | 将数字向下舍入到最近的整数 |
| 向上取整(向上舍入) | 将数字向上舍入到最近的整数 |
| 自定义操作 | 根据示例和现有列的派生自动创建新列 |