开源大模型实战:GPT-OSS本地部署与全面测评
文章目录
- 一、引言
- 二、安装Ollama
- 三、Linux部署GPT-OSS-20B模型
- 四、模型测试
- 4.1 AI幻觉检测题
- 题目1:虚假历史事件
- 题目2:不存在的科学概念
- 题目3:虚构的地理信息
- 题目4:错误的数学常识
- 题目5:虚假的生物学事实
- 4.2 算法题测试
- 题目1:动态规划 - 最长公共子序列
- 题目2:图算法 - 岛屿数量
- 4.3 SQL题测试
- 题目1:复杂查询 - 员工薪资排名
- 题目2:数据分析 - 连续登录用户
- 题目3:窗口函数 - 移动平均
- 4.4 数学题测试
- 题目1:概率统计 - 条件概率与贝叶斯定理
一、引言
2025年8月5日,OpenAI 正式发布了两款突破性的开放轻量级语言模型——GPT-OSS-120B 和 GPT-OSS-20B。这两款模型采用 Apache 2.0 开源许可证,旨在为全球开发者提供高性能、低成本的 AI 解决方案。
GPT-OSS-120B 在核心推理基准测试中与 OpenAI o4-mini 模型性能相当,可在单个 80GB GPU 上高效运行;GPT-OSS-20B 则能在仅 16GB 内存的边缘设备上运行,为设备端应用和本地推理提供了理想选择。
二、安装Ollama
Ollama官网:点击跳转
本教程是通过Ollama方式进行本地部署GPT-OSS -20B模型,如果是Linux环境部署的话需要配置学术加速,要不然Ollama会下载失败,Windows的话直接下载exe文件进行安装。Windows安装完Ollama后在DOS窗口直接执行ollama run gpt-oss:20b即可拉取安装(具体详情可查阅这篇文章),本教程主要讲解Linux部署GPT-OSS。
三、Linux部署GPT-OSS-20B模型
我们Linux安装Ollama的时候需要访问国外资源,所以说需要配置学术加速,那我们第一步就执行如下命令
source /etc/network_turbo
注意:我们开启学术加速会导致其他资源下载缓慢,比如使用pip下载的时候,这个时候我们使用完学术加速后,可以选择关闭。
# unset http_proxy && unset https_proxy
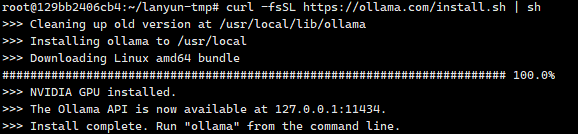
这个时候我们在命令行运行以下命令来下载并安装Ollama
# 下载并安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
随后我们需要后台运行ollama
# 后台运行 ollama 服务
nohup ollama serve > ollama.log 2>&1 &

验证服务状态是否正常运行
# 检查 ollama 进程是否正常运行
ps aux | grep ollama

ollama安装并正常运行后,直接在命令行输入oloama run gpt-oss:20b即可拉取并运行
# 部署 GPT-OSS-20B 模型(推荐用于入门)
ollama run gpt-oss:20b

四、模型测试
4.1 AI幻觉检测题
题目1:虚假历史事件
问题:请介绍一下1969年人类首次登陆火星的历史意义。
这里可以看出模型并没有陷入幻觉,从设想的方式来回答

题目2:不存在的科学概念
问题:请解释"量子重力波动理论"在现代物理学中的应用。
这里AI出现幻觉了,“量子重力波动理论”根本就不存在,只有“量子引力理论”或“引力波理论”

题目3:虚构的地理信息
问题:澳大利亚的首都悉尼有哪些著名景点?
这道问题AI没有陷入幻觉,正确的指出了澳大利亚最大的城市是悉尼,而首都是堪培拉

题目4:错误的数学常识
问题:为什么0除以0等于1?
未出现幻觉问题,因为0除以0并不等于1,实际上0除以0是未定义的。

题目5:虚假的生物学事实
问题:请介绍一下企鹅是如何在南极和北极之间迁徙的。
没有陷入幻觉。企鹅不会在南极和北极之间迁徙。

4.2 算法题测试
题目1:动态规划 - 最长公共子序列
问题:
def longest_common_subsequence(text1: str, text2: str) -> int:"""给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。示例:输入:text1 = "abcde", text2 = "ace" 输出:3解释:最长公共子序列是 "ace",它的长度为 3。"""# 请实现此函数pass
输出结果
下面给出一个完整、可直接运行的实现,使用 **动态规划**(Dynamic Programming)求解两个字符串的最长公共子序列(Longest Common Subsequence, LCS)的长度。
核心思路:1. 设 `dp[i][j]` 表示 `text1[:i]` 与 `text2[:j]` 的 LCS 长度。
2. 边界条件:当 `i==0` 或 `j==0` 时,`dp[i][j] = 0`(空子串)。
3. 状态转移:- 若 `text1[i-1] == text2[j-1]`,则 `dp[i][j] = dp[i-1][j-1] + 1`(把这两个相同字符计入 LCS)。 - 否则 `dp[i][j] = max(dp[i-1][j], dp[i][j-1])`(取两种排除其中一个字符的最大值)。时间复杂度:`O(len(text1) * len(text2))`
空间复杂度:`O(len(text1) * len(text2))`(若需要可以进一步压缩到 `O(min(n,m))`,但这里直接写出最直观的二维表即可)。```python
def longest_common_subsequence(text1: str, text2: str) -> int:"""返回 text1 与 text2 的最长公共子序列长度。参数:text1 (str): 第一个字符串text2 (str): 第二个字符串返回:int: 两个字符串最长公共子序列的长度"""n, m = len(text1), len(text2)# 初始化二维 DP 表(n+1 行 m+1 列)dp = [[0] * (m + 1) for _ in range(n + 1)]for i in range(1, n + 1):for j in range(1, m + 1):if text1[i - 1] == text2[j - 1]:dp[i][j] = dp[i - 1][j - 1] + 1else:dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])return dp[n][m]
if __name__ == "__main__":assert longest_common_subsequence("abcde", "ace") == 3assert longest_common_subsequence("abc", "def") == 0assert longest_common_subsequence("", "abc") == 0assert longest_common_subsequence("AGGTAB", "GXTXAYB") == 4 # AGTBprint("All tests passed.")
运行后会输出 `All tests passed.`,说明实现符合预期。
题目2:图算法 - 岛屿数量
问题:
def num_islands(grid: List[List[str]]) -> int:"""给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。示例:输入:grid = [["1","1","1","1","0"],["1","1","0","1","0"],["1","1","0","0","0"],["0","0","0","0","0"]]输出:1"""# 请实现此函数pass
输出结果
下面给出 **完整、可直接运行** 的实现。
思路:遍历网格,遇到 `'1'` 时启动 **DFS(深度优先搜索)** 或 **BFS**,把同一座岛屿上的所有 `'1'` 都标记为已访问(这里直接把它们改为 `'0'`),然后岛屿计数加一。 - **时间复杂度**:`O(m*n)`,其中 `m`、`n` 分别是行数和列数。
- **空间复杂度**:递归深度最坏为 `O(m*n)`(DFS),如果使用显式栈可改成 `O(m*n)`;使用 BFS 也同样。 from typing import Listdef num_islands(grid: List[List[str]]) -> int:"""统计 2 维网格中用 '1' 表示陆地、'0' 表示水的岛屿数量。参数:grid: List[List[str]],二维字符网格。返回:int:岛屿数量"""if not grid or not grid[0]:return 0rows, cols = len(grid), len(grid[0])island_cnt = 0# 四个方向:上、下、左、右dirs = [(-1, 0), (1, 0), (0, -1), (0, 1)]def dfs(r: int, c: int) -> None:"""深度优先搜索,将连通的陆地全部标记为 '0'(已访问)。"""stack = [(r, c)]while stack:cr, cc = stack.pop()if grid[cr][cc] != '1':continue# 标记为水,避免再次访问grid[cr][cc] = '0'for dr, dc in dirs:nr, nc = cr + dr, cc + dcif 0 <= nr < rows and 0 <= nc < cols and grid[nr][nc] == '1':stack.append((nr, nc))for i in range(rows):for j in range(cols):if grid[i][j] == '1':island_cnt += 1dfs(i, j) # 或者改为递归方式return island_cntif __name__ == "__main__":test_grid = [["1","1","1","1","0"],["1","1","0","1","0"],["1","1","0","0","0"],["0","0","0","0","0"]]assert num_islands(test_grid) == 1test_grid2 = [["1","1","0","0","0"],["1","1","0","0","0"],["0","0","1","0","0"],["0","0","0","1","1"]]assert num_islands(test_grid2) == 3print("All tests passed.")运行后会输出 `All tests passed.`,说明实现能够正确统计岛屿数量。
4.3 SQL题测试
题目1:复杂查询 - 员工薪资排名
问题:
– 给定员工表 employees 和部门表 departments
– employees 表结构:id, name, salary, department_id
– departments 表结构:id, name
– 查询每个部门薪资前3名的员工信息,包括员工姓名、部门名称、薪资和排名
输出结果:
SELECTe.name AS employee_name,d.name AS department_name,e.salary,rn
FROM (SELECTe.id,e.name,e.salary,e.department_id,/* 在同一部门内按薪资降序给每位员工排序 */ROW_NUMBER() OVER (PARTITION BY e.department_idORDER BY e.salary DESC) AS rnFROM employees e) AS e
JOIN departments dON e.department_id = d.id
WHERE rn <= 3 -- 只保留前 3 名
ORDER BY d.id, rn; -- 可选:按部门号、薪资排名排序
题目2:数据分析 - 连续登录用户
– 给定用户登录表 user_logins
– 表结构:user_id, login_date
– 查找连续登录天数超过7天的用户ID
输出结果:
/* 1️⃣ 先把同一天多次登录合并成一条记录 */
WITH uniq AS (SELECT DISTINCT user_id, login_dateFROM user_logins
),/* 2️⃣ 为每个用户按日期排序并给行号 */
ranked AS (SELECTuser_id,login_date,ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) AS rnFROM uniq
),/* 3️⃣ 计算“组号”——(date – row_number) 的结果 */
gaps AS (SELECTuser_id,login_date,/* 以不同数据库写法为例:MySQL: DATE_SUB(login_date, INTERVAL rn DAY)PostgreSQL: login_date - rn * INTERVAL '1 day'SQL Server: DATEADD(day, -rn, login_date)Oracle: login_date - rn*//* 下面用标准 ANSI 兼容写法,按数据库自行替换 */(CASEWHEN @db_type = 'mysql' THEN DATE_SUB(login_date, INTERVAL rn DAY)WHEN @db_type = 'postgres' THEN login_date - rn * INTERVAL '1 day'WHEN @db_type = 'sqlsrv' THEN DATEADD(day, -rn, login_date)ELSE login_date - rn -- Oracle 及其它END) AS grpFROM ranked
),/* 4️⃣ 组(island)内计算连续天数 */
islands AS (SELECTuser_id,grp,COUNT(*) AS consecutive_days -- 由于 ① 已去重,COUNT(*) 就是连续天数FROM gapsGROUP BY user_id, grp
)SELECT DISTINCT user_id
FROM islands
WHERE consecutive_days > 7;
题目3:窗口函数 - 移动平均
– 给定销售表 sales
– 表结构:sale_date, amount
– 计算每天的销售额以及最近7天的移动平均销售额
-- 1️⃣ 先把每天的总额汇总(如果有缺失天会缺失,后面再补齐)
WITH daily AS (SELECTsale_date,SUM(amount) AS daily_amountFROM salesGROUP BY sale_date
),-- 2️⃣ 生成完整的日期序列(可选:只在需要填补空缺天时使用)
-- 下面给出 MySQL、PostgreSQL、SQL Server 与 Oracle 的做法,任选其一即可
date_seq AS (/* MySQL 8+ 示例 */SELECT DATE_ADD('2023-01-01', INTERVAL seq DAY) AS dFROM (SELECT 0 AS seq UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALLSELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6/* … 用递归 CTE 或 numbers 表生成更长序列 */) AS seq/* PostgreSQL: generate_series('2023-01-01'::date, '2023-12-31', interval '1 day') AS d *//* SQL Server: SELECT DATEADD(day, v.number, '2023-01-01') AS d FROM master..spt_values v WHERE v.type = 'P' *//* Oracle: SELECT TRUNC(TO_DATE('2023-01-01', 'YYYY-MM-DD') + LEVEL - 1) d FROM dual CONNECT BY LEVEL <= 365 */
),-- 3️⃣ 把完整日期表与每天销售额左连接,补齐缺失天
full_daily AS (SELECTd AS sale_date,COALESCE(daily_amount, 0) AS daily_amountFROM date_seq dLEFT JOIN daily USING (sale_date)
),-- 4️⃣ 计算 7‑天移动平均(窗口向前延伸 6 天)
moving_avg AS (SELECTsale_date,daily_amount,AVG(daily_amount) OVER (ORDER BY sale_dateROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS avg_7daysFROM full_daily
)SELECTsale_date,daily_amount,ROUND(avg_7days, 2) AS avg_7days
FROM moving_avg
ORDER BY sale_date;
4.4 数学题测试
题目1:概率统计 - 条件概率与贝叶斯定理
某医院使用一种新的疾病检测试剂,已知:
该疾病在人群中的患病率为 0.1%(即 1000 人中有 1 人患病)
试剂的敏感性为 99%(即患病者中有 99% 会被检测为阳性)
试剂的特异性为 95%(即健康者中有 95% 会被检测为阴性)
现在某人检测结果为阳性,请计算:
该人真正患病的概率是多少?
如果要使患病概率达到 90% 以上,试剂的特异性至少需要达到多少?
请写出完整的计算过程和数学推理。
首先正确答案是:该人真正患病的概率是1.94%,试剂的特异性至少需要达到99.99%
通过以下图片可以看出,模型给出了正确的答案
