HashMap 与 ConcurrentHashMap 深度解析
文章目录
- 一、HashMap 核心原理
- 1. 数据结构演进
- 2. 核心参数
- 3. 哈希算法优化
- 4. put() 流程详解
- 5. 扩容机制(resize)
- 二、ConcurrentHashMap 并发实现
- 1. JDK 版本演进
- 2. JDK1.8 核心机制
- 2.1 关键数据结构
- 2.2 并发控制技术
- 3. put() 并发流程
- 3.1. 无锁CAS操作
- 3.2. 细粒度锁(哈希冲突处理)
- 3.3. 多线程协作扩容
- 4. 并发扩容机制
- 5. size() 精确计数
- 三、高频面试题深度解析
- 1. HashMap 线程安全问题及表现
- 2. 为什么链表长度超过8转红黑树?
- 3. ConcurrentHashMap 读操作为什么不需要加锁?
- 4. ConcurrentHashMap 的 size() 是精确值吗?
- 5. Key 的设计要求?
- 四、性能优化实践
- 1. HashMap 初始化优化
- 2. ConcurrentHashMap 复合操作安全
- 五、JDK 新特性
- 1. JDK8 新增方法
- 六、经典问题对比总结
一、HashMap 核心原理
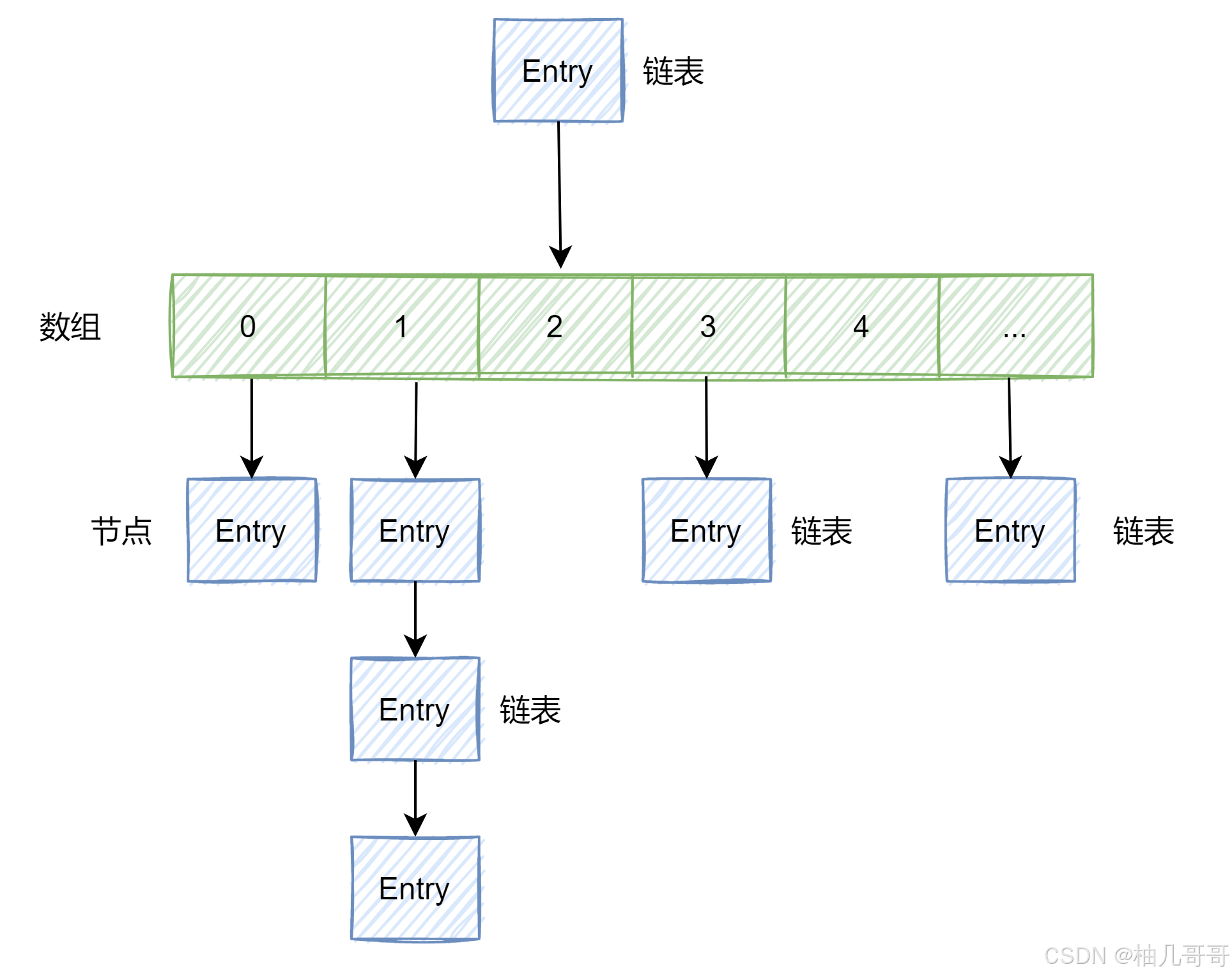
1. 数据结构演进
- JDK1.7:数组 + 链表
- JDK1.8+:数组 + 链表 + 红黑树(链表长度 ≥ 8 且数组长度 ≥ 64 时树化)
// JDK 17 节点定义
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next; // 链表指针
}static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 红黑树父节点TreeNode<K,V> left; // 左子节点TreeNode<K,V> right; // 右子节点TreeNode<K,V> prev; // 前驱节点(删除时快速定位)boolean red; // 颜色标记
}
2. 核心参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| DEFAULT_INITIAL_CAPACITY | 16 | 默认初始容量 |
| MAXIMUM_CAPACITY | 1 << 30 | 最大容量 (1073741824) |
| DEFAULT_LOAD_FACTOR | 0.75f | 负载因子(扩容阈值比例) |
| TREEIFY_THRESHOLD | 8 | 链表转红黑树阈值 |
| UNTREEIFY_THRESHOLD | 6 | 红黑树转链表阈值 |
| MIN_TREEIFY_CAPACITY | 64 | 最小树化容量 |
3. 哈希算法优化
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 高位扰动:
hashCode()高16位与低16位异或,减少哈希碰撞 - 索引计算:
(n - 1) & hash替代取模运算
4. put() 流程详解
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);} final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {// tab:指向哈希桶数组的引用;// p:当前定位到的桶中的节点;// n:哈希桶数组长度;// i:键的哈希值计算出的桶下标Node<K,V>[] tab; Node<K,V> p; int n, i;// 初始化哈希桶数组(懒加载),未初始化则调用 resize() 初始化数组并获取新长度 nif ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 如果目标桶为空,直接创建新节点放入该桶if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {// 目标桶不为空,表示发生了哈希冲突,分三种情况Node<K,V> e; K k;// 情况1:桶的首节点就是目标键if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))// 标记已存在节点e = p;// 情况2:桶中是红黑树节点else if (p instanceof TreeNode)// putTreeVal在树中插入/查找e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 情况3:桶中是链表else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {// 到达链表尾部:插入新节点p.next = newNode(hash, key, value, null);// 检查是否需树化(链表长度≥8)if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}// 链表中找到相同键if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;// 继续遍历p = e;}}//键已存在if (e != null) {V oldValue = e.value;// 允许覆盖值 或 原值为null时更新if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);// 返回旧值return oldValue;}}// 修改次数+1(用于快速失败机制)++modCount;// 超过扩容阈值if (++size > threshold)// 扩容哈希表resize();// 回调方法(LinkedHashMap使用)afterNodeInsertion(evict);return null;}
5. 扩容机制(resize)
final Node<K,V>[] resize() {// 1.扩容// 当前哈希桶数组Node<K,V>[] oldTab = table;// 当前容量int oldCap = (oldTab == null) ? 0 : oldTab.length;// 当前扩容阈值int oldThr = threshold;// 新容量、新阈值(初始0)int newCap, newThr = 0;// 情况1:当前表已初始化(扩容操作)if (oldCap > 0) {// 容量已达上限(1<<30)if (oldCap >= MAXIMUM_CAPACITY) {// 阈值设为int最大值threshold = Integer.MAX_VALUE;// 直接返回原表,不再扩容return oldTab;}// 正常扩容:新容量=旧容量*2else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)// 新阈值=旧阈值*2newThr = oldThr << 1; }// 新容量=构造时计算的阈值else if (oldThr > 0) newCap = oldThr;else { // 默认容量16newCap = DEFAULT_INITIAL_CAPACITY;// 16*0.75=12newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {// 新容量*负载因子float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}// 更新全局阈值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];// 更新全局table引用table = newTab;// 2.数据迁移(重哈希)if (oldTab != null) {// 遍历每个桶for (int j = 0; j < oldCap; ++j) {Node<K,V> e;// 桶中有数据if ((e = oldTab[j]) != null) {// 清空旧桶(帮助GC)oldTab[j] = null;// 情况1:桶中只有一个节点if (e.next == null)// 直接放入新桶newTab[e.hash & (newCap - 1)] = e;// 情况2:红黑树节点else if (e instanceof TreeNode)// 拆分红黑树((TreeNode<K,V>)e).split(this, newTab, j, oldCap);// 情况3:链表节点(保持顺序迁移)else { // 低位链表Node<K,V> loHead = null, loTail = null;// 高位链表Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {// 通过 hash & oldCap 判断位置next = e.next;if ((e.hash & oldCap) == 0) {if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);// 低位链表放在原索引位置if (loTail != null) {loTail.next = null;newTab[j] = loHead;}// 高位链表放在 [原索引+oldCap] 位置if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
- 位置重计算:
e.hash & oldCap== 0 保持原位,否则移动到原位置 + oldCap - 链表拆分:保持原有顺序(JDK1.8优化)
二、ConcurrentHashMap 并发实现
1. JDK 版本演进
| 版本 | 实现方式 | 锁粒度 | 并发度限制 |
|---|---|---|---|
| JDK1.7 | 分段锁(Segment) | 段级别 | 最大并发数=段数 |
| JDK1.8 | CAS + synchronized | 桶级别(首节点) | 无上限 |
2. JDK1.8 核心机制
2.1 关键数据结构
transient volatile Node<K,V>[] table; // volatile 保证可见性
private transient volatile int sizeCtl; // 控制标识符
2.2 并发控制技术
- CAS:用于无锁化初始化、计数更新等
- synchronized:锁定桶的首节点(细粒度锁)
- volatile:保证数组引用的可见性
- ForwardingNode:扩容时标记迁移完成的桶
3. put() 并发流程
final V putVal(K key, V value, boolean onlyIfAbsent) {// 1. 计算hashfor (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;// 2. 延迟初始化if (tab == null || (n = tab.length) == 0)tab = initTable();// 3. CAS尝试无锁插入else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break;}// 4. 检测到扩容中,协助扩容else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);// 5. 锁住桶首节点else {synchronized (f) {if (tabAt(tab, i) == f) {// 6. 链表或树插入}}}}// 7. 计数更新(LongAdder思想)addCount(1L, binCount);
}
3.1. 无锁CAS操作
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break;
}
- 原理:
- 通过
tabAt()获取最新桶状态(使用volatile读) - 当桶为空时,用CAS原子操作设置新节点
- 失败时重试(自旋)
- 通过
- 优势:避免锁开销,实现最高效的空桶插入
3.2. 细粒度锁(哈希冲突处理)
synchronized (f) {if (tabAt(tab, i) == f) {// 链表/树操作}
}
- 防护机制:桶级别锁(而非整个map)
- 关键点:
- 只锁定当前桶的首节点
f - 二次检查
tabAt(tab, i) == f(防止锁前状态变化) - 不同桶的操作完全并行
- 只锁定当前桶的首节点
- 优势:将锁竞争范围从全局缩小到单个桶
3.3. 多线程协作扩容
else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);
- 防护机制:状态检测+协作扩容
- 工作原理:
- 当节点hash=MOVED(-1)表示桶正在迁移
- 当前线程调用
helpTransfer()参与数据迁移 - 多线程共同完成扩容任务
- 优势:化阻塞为协作,加速扩容过程
4. 并发扩容机制
- 多线程协作:每个线程处理固定步长(stride)的桶
- 迁移标记:ForwardingNode 标记已迁移的桶
- 扩容触发:
- 链表转树时检测容量
- 新增节点后检测总节点数
5. size() 精确计数
// 使用 CounterCell 数组分散计数
@sun.misc.Contended static final class CounterCell {volatile long value;CounterCell(long x) { value = x; }
}final long sumCount() {CounterCell[] as = counterCells;long sum = baseCount;if (as != null) {for (CounterCell a : as) {if (a != null)sum += a.value;}}return sum;
}
三、高频面试题深度解析
1. HashMap 线程安全问题及表现
| 问题类型 | JDK1.7 表现 | JDK1.8 表现 |
|---|---|---|
| 数据覆盖 | ✅ 存在(hash碰撞时) | ✅ 存在(hash碰撞时) |
| 死循环 | ✅ 扩容时链表反转导致 | ❌ 已修复(尾插法) |
| 扩容丢失数据 | ✅ 并发扩容可能导致 | ✅ 仍可能(需外部同步) |
解决方案:
// 1. 使用 Collections.synchronizedMap
Map<String, String> syncMap = Collections.synchronizedMap(new HashMap<>());// 2. 使用 ConcurrentHashMap(推荐)
Map<String, String> safeMap = new ConcurrentHashMap<>();
2. 为什么链表长度超过8转红黑树?
- 概率依据:根据泊松分布,哈希冲突达到8的概率小于千万分之一
- 性能权衡:
- 链表查询:O(n)
- 红黑树查询:O(log n)
- 阈值选择:8是经验值,平衡转换成本和性能收益
3. ConcurrentHashMap 读操作为什么不需要加锁?
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
- volatile 读:通过
Unsafe.getObjectVolatile保证可见性 - 不变性保证:Node 的 key 和 hash 声明为 final
- 扩容安全:读操作遇到 ForwardingNode 会转到新表查询
4. ConcurrentHashMap 的 size() 是精确值吗?
- JDK1.7:分段计算,可能不是绝对精确(锁分段时变化)
- JDK1.8:基于
CounterCell的LongAdder实现,理论上是精确值- 实际使用中可作为精确值使用
- 高并发下可能有短暂延迟
5. Key 的设计要求?
-
不可变性:推荐使用不可变对象(如 String、Integer)
// 错误示例:可变Key导致哈希值变化 class MutableKey {int id;// 省略hashCode和equals }MutableKey key = new MutableKey(1); map.put(key, "A"); key.id = 2; // 修改后无法再通过原key访问 -
重写 hashCode() 和 equals() 的契约:
- 相等对象必须有相同 hashcode
- 不相等的对象尽量产生不同的 hashcode
四、性能优化实践
1. HashMap 初始化优化
// 已知元素数量时避免多次扩容
int expectedSize = 10000;
Map<String, Integer> map = new HashMap<>((int)(expectedSize / 0.75f) + 1);
2. ConcurrentHashMap 复合操作安全
// 非原子操作:先检查后执行(存在竞态条件)
if (!map.containsKey(key)) {map.put(key, value); // 可能被其他线程覆盖
}// 解决方案1:使用 putIfAbsent
map.putIfAbsent(key, value);// 解决方案2:使用 compute 原子方法
map.compute(key, (k, v) -> v == null ? newValue : v);
五、JDK 新特性
1. JDK8 新增方法
// 1. 原子更新
map.compute("key", (k, v) -> v == null ? 1 : v + 1);// 2. 键值对遍历
map.forEach(2, (k, v) -> System.out.println(k + ": " + v), entry -> entry.getValue() > 100
);// 3. 搜索操作
String result = map.search(1, (k, v) -> v.startsWith("A") ? k : null
);
六、经典问题对比总结
| 特性 | HashMap | ConcurrentHashMap |
|---|---|---|
| 线程安全 | ❌ | ✅ (CAS + synchronized) |
| 锁粒度 | 无锁(非线程安全) | 桶级别(首节点) |
| Null支持 | ✅ key/value可为null | ❌ 禁止null键值(避免歧义) |
| 迭代器一致性 | Fail-Fast | 弱一致性 |
| 性能开销 | 最低 | 读接近HashMap,写有额外开销 |
| 适用场景 | 单线程环境 | 高并发环境 |
注意事项:
- 在单线程场景优先使用 HashMap
- 并发场景使用 ConcurrentHashMap,避免使用 Hashtable
- 分布式场景考虑 Redis 等分布式缓存