Datawhale AI 夏令营 让AI读懂财报PDF(多模态RAG)202508
import fitz # PyMuPDF
import json
from pathlib import Pathdef process_pdfs_to_chunks(datas_dir: Path, output_json_path: Path):"""使用 PyMuPDF 直接从 PDF 提取每页文本,并生成最终的 JSON 文件。Args:datas_dir (Path): 包含 PDF 文件的输入目录。output_json_path (Path): 最终输出的 JSON 文件路径。"""all_chunks = []# 递归查找 datas_dir 目录下的所有 .pdf 文件pdf_files = list(datas_dir.rglob('*.pdf'))if not pdf_files:print(f"警告:在目录 '{datas_dir}' 中未找到任何 PDF 文件。")returnprint(f"找到 {len(pdf_files)} 个 PDF 文件,开始处理...")for pdf_path in pdf_files:file_name_stem = pdf_path.stem # 文件名(不含扩展名)full_file_name = pdf_path.name # 完整文件名(含扩展名)print(f" - 正在处理: {full_file_name}")try:# 使用 with 语句确保文件被正确关闭with fitz.open(pdf_path) as doc:# 遍历 PDF 的每一页for page_idx, page in enumerate(doc):# 提取当前页面的所有文本content = page.get_text("text")# 如果页面没有文本内容,则跳过if not content.strip():continue# 构建符合最终格式的 chunk 字典chunk = {"id": f"{file_name_stem}_page_{page_idx}","content": content,"metadata": {"page": page_idx, # 0-based page index"file_name": full_file_name}}all_chunks.append(chunk)except Exception as e:print(f"处理文件 '{pdf_path}' 时发生错误: {e}")# 确保输出目录存在output_json_path.parent.mkdir(parents=True, exist_ok=True)# 将所有 chunks 写入一个 JSON 文件with open(output_json_path, 'w', encoding='utf-8') as f:json.dump(all_chunks, f, ensure_ascii=False, indent=2)print(f"\n处理完成!所有内容已保存至: {output_json_path}")def main():base_dir = Path(__file__).parentdatas_dir = base_dir / 'datas'chunk_json_path = base_dir / 'all_pdf_page_chunks.json'process_pdfs_to_chunks(datas_dir, chunk_json_path)if __name__ == '__main__':main()本次赛题的核心目标是打造一个能看懂图片、读懂文字、并将两者关联起来思考的AI助手,构建一个先进的智能问答系统,以应对真实世界中复杂的、图文混排的信息环境。
-
让 AI模型能够阅读并理解包含大量图标、图像和文字的pdf文档 ,基于信息回答用户问题。
-
能找到答案的同时还需要标注出答案的出处,比如源自于哪一个文件的哪一页。
多模态检索增强生成 (Multimodal RAG)!其中需要涉及到——
多模态信息处理 (Multimodal Information Processing)、向量化与检索技术 (Embeddings & Retrieval)
跨模态检索与关联 (Cross-Modal Retrieval)、大语言模型(LLM)的应用与推理 (LLM Application & Reasoning)
相关知识点及参考资料
PDF文档解析库PyMuPDF官方教程:PyMuPDF 1.26.3 documentation
强大的中文OCR工具PaddleOCR:https://github.com/PaddlePaddle/PaddleOCR
领先的中文文本向量化模型库FlagEmbedding (BGE模型):https://github.com/FlagOpen/FlagEmbedding
经典图文多模态向量化模型CLIP (Hugging Face实现):https://huggingface.co/docs/transformers/model_doc/clip
高性能向量检索引擎FAISS入门指南:https://github.com/facebookresearch/faiss/wiki/Getting-started
简单易用的向量数据库ChromaDB快速上手:Getting Started - Chroma Docs
通义千问Qwen大模型官方仓库 (含多模态VL模型):https://github.com/QwenLM/Qwen-VL
集成化RAG开发框架LlamaIndex五分钟入门:Redirecting...
Xinference官方仓库(模型推理框架):
https://github.com/xorbitsai/inference
此次 多模态RAG任务 有四大核心要素
此次赛题的核心不仅仅是简单的问答,而是基于给定的pdf知识库的、可溯源的多模态 问答。
数据源:一堆图文混排的PDF,这是我们唯一的数据。
可溯源:必须明确指出答案的出处。
多模态:问题可能需要理解文本,也可能需要理解图表(图像)。
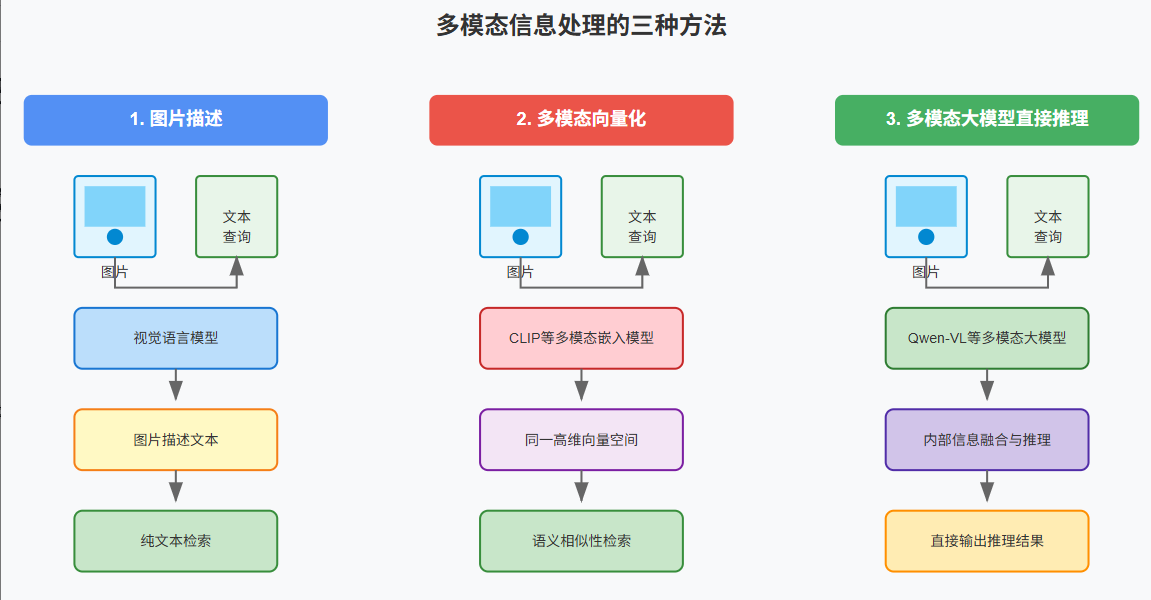
问答:根据检索的信息生成一个回答。
输出 (Output):我们需要提交什么?
我们的最终任务是为 test.json 中的每一个问题,预测出三个信息: 答案 ( answer ) 、 来源文件名 ( filename ) 和 来源页码 ( page ) 。
总结一下 :整个任务流程就是,
-
读取
test.json里的一个问题, -
驱动你的系统去
财报数据库中查找信息, -
然后生成答案和出处,
-
最后将这几项信息作为一行写入到最终的
submit.json文件中。
对 test.json 中的所有问题重复此过程,即可得到最终的提交文件.
其中的train.json文件主要是用来在训练非生成式模型环节中使用的,比如训练embedding模型,或者是微调LLM。
遇到的卡点及解决建议
在实际操作中,最主要的瓶颈在于 时间消耗 :
-
pymupdf解析 :处理整个财报数据库会稍微消耗一些时间,特别是如果使用基于深度学习的方式提取内容,比如mineru,不过我们本次baseline使用pymupdf速度会有比较大的提升。
-
批量Embedding :将接近5000的内容块进行向量化,也会消耗不少时间,如果是基于CPU运行的话大概会慢十倍,使用A6000这样的GPU也需要消耗大概1分钟的时间。
核心痛点 :如果在处理过程中代码出现一个小错误,比如数据格式没对齐,就需要从头再来,这将浪费大量时间。
解决与建议 : 不要在一个脚本里完成所有事 。强烈建议使用 Jupyter Notebook 进行开发调试,并将流程拆分:
-
第一阶段:解析 。在一个Notebook中,专门负责调用pymupdf,将所有PDF解析为JSON并 保存到本地 。这个阶段成功运行一次后,就不再需要重复执行。
-
第二阶段:预处理与Embedding 。在另一个Notebook中,读取第一步生成的JSON文件,进行图片描述生成、数据清洗,并调用Embedding模型。将最终包含向量的知识库 保存为持久化文件 。
-
第三阶段:检索与生成 。在第三个Notebook中,加载第二步保存好的知识库,专注于调试检索逻辑和Prompt工程。
通过这种 分步执行、缓存中间结果 的方式,可以极大地提高调试效率,每次修改只需运行对应的、耗时较短的模块。
第一次运行时解压了财报数据库,以后再运行时可以跳过此步骤,修改程序为:
import os
import zipfileoutput_dir = "datas/财报数据库"
zip_file = "datas/财报数据库.zip"if not os.path.exists(output_dir) or not os.listdir(output_dir):with zipfile.ZipFile(zip_file, 'r') as z:z.extractall("datas/")print("已解压财报数据库。")
else:print("财报数据库已存在,跳过解压。")第二句不变:
!pip install -r requirements.txt第三句原为:
!python fitz_pipeline_all_1.py改为:
import os, subprocess
json_file = "all_pdf_page_chunks.json"
if not os.path.exists(json_file):subprocess.run(["python", "fitz_pipeline_all_1.py"])
else:print("JSON 已存在,跳过提取。")文件为: