【网络】高级IO
目录
前言
一,IO
1.1.什么是IO?
1.2.IO操作
二,阻塞IO,非阻塞IO,异步IO,同步IO
2.3.总结
三,五种IO模型
3.1.复习
3.2.阻塞IO模型
3.3.非阻塞式IO模式
3.4.多路复用IO模式
3.5、信号驱动IO(signal driven IO)
3.6、异步IO( asynchronous IO)
四.文件描述符的默认行为——阻塞IO
4.1.非阻塞IO
在打开文件或创建套接字时设置非阻塞模式:
4.2.在使用网络I/O接口时请求非阻塞行为:
4.3.fcntl函数
五,select函数
5.1.参数一:nfds
5.2.参数二: readfds, writefds, exceptfds
5.2.1.fd_set类型和相关操作宏
5.2.2.readfds, writefds, exceptfds
5.2.3.怎么理解 readfds, writefds, exceptfds是输入输出型参数
5.3.参数三: timeout
5.3.1.timeval结构体
5.3.1.timeout参数的设定
5.4.返回值
5.5.select的工作流程
六,select版TCP服务器
6.1.编写准备
6.2.SelectServer.hpp的编写
6.2.1.为什么要设置辅助数组
6.2.2.select的优缺点
前言
我们在本专栏前面的文章中大概学习了TCP/IP四层模型,因为我们不学网络,所以那些知识也是够用的。我们接下来要回归到我们的应用层的学习——也就是写代码。
接下来我们要学习一下IO
一,IO
1.1.什么是IO?
在计算机中,输入/输出(即IO)是指信息处理系统(比如计算机)和外部世界(可以是人或其他信息处理系统)的通信。输入是指系统接收的信号或数据,输出是指从系统发出的数据或信号。这个术语可以用作某个动作的一部分:“执行I/O”就是指执行输入输出动作。
I/O设备是指用户和计算机之间沟通的硬件部分。例如,键盘或鼠标就是计算机的输入设备,显示器和打印机是输出设备。用来在计算机之间通信的设备,例如调制解调器和网卡,通常同时执行输入输出动作。
还记得冯诺依曼体系不?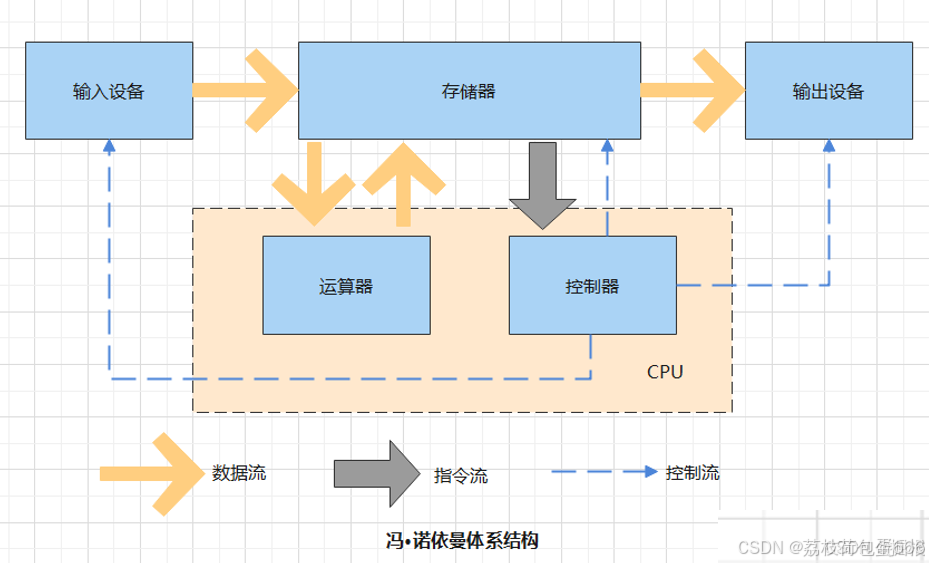
在我们自己的电脑内部其实就无时不刻的在进行着IO,因为冯诺依曼体系已经决定了计算机是要无时不刻进行IO的,从存储设备中拿取数据到内存,将处理结果再返回至内存
在计算机的体系结构中,CPU和主存的组合被认为是计算机的大脑,因为CPU可以直接执行单个指令读或写。任何与CPU和内存的这个组合(大脑)的信息传输,例如从硬盘读数据,都可以被称为I/O。
也就是说从计算机架构上来讲,任何涉及到计算机核心(CPU和内存)与其他设备间的数据转移的过程就是IO。本体就是计算机核心(CPU和内存)。
例如从硬盘上读取数据到内存,是一次输入,将内存中的数据写入到硬盘就产生了输出。在计算机的世界里,这就是IO的本质。
我们可以从编程的角度去理解IO。
此时,IO的主体是其应用程序的运行态,即进程,特别强调的是我们的应用程序其实并不存在实质的IO过程,真正的IO过程是操作系统的事情,这里把应用程序的IO操作分为两种动作:IO调用和IO执行。IO调用是由进程发起,IO执行是操作系统的工作。因此,更准确些来说,此时所说的IO是应用程序对操作系统IO功能的一次触发,即IO调用。
IO调用的目的是将进程的内部数据迁移到外部即输出,或将外部数据迁移到进程内部即输入。这里,外部数据指非进程空间数据,在编程时,通常讨论的场景是来自外部存储设备的数据,如硬盘、CD-ROM、以及需要socket通信传输的网络数据。
以一个进程的输入类型的IO调用为例,它将完成或引起如下工作内容:
- 进程向操作系统请求外部数据
- 操作系统将外部数据加载到内核缓冲区
- 操作系统将数据从内核缓冲区拷贝到进程缓冲区
- 进程读取数据继续后面的工作
从上面的描述来看,我们更容易理解一个IO操作,应用程序和操作系统都干了些什么,也帮助我们更容器理解阻塞和非阻塞,异步和同步的相关IO编程概念。
1.2.IO操作
IO操作会涉及到用户空间和内核空间的转换,先来理解以下规则:
- 内存空间分为用户空间和内核空间,也称为用户缓冲区和内核缓冲区;
- 用户的应用程序不能直接操作内核空间,需要将数据从内核空间拷贝到用户空间才能使用;
- 无论是read操作,还是write操作,都只能在内核空间里执行;
- 磁盘IO和网络IO请求加载到内存的数据都是先放在内核空间的;
再来看看所谓的读(Read)和写(Write)操作:
读操作:操作系统检查内核缓冲区有没有需要的数据,如果内核缓冲区已经有需要的数据了,那么就直接把内核空间的数据copy到用户空间,供用户的应用程序使用。如果内核缓冲区没有需要的数据,对于磁盘IO,直接从磁盘中读取到内核缓冲区(这个过程可以不需要cpu参与)。而对于网络IO,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议找中读取客户端发送的数据到内核空间,然后把内核空间的数据copy到用户空间,供应用程序使用。
写操作:用户的应用程序将数据从用户空间copy到内核空间的缓冲区中(如果用户空间没有相应的数据,则需要从磁盘—>内核缓冲区—>用户缓冲区依次读取),这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘或通过网络发送出去,由操作系统决定。除非应用程序显示地调用了sync 命令,立即把数据写入磁盘,或执行flush()方法,通过网络把数据发送出去。
绝大多数磁盘IO和网络IO的读写操作都是上述过程,除了零拷贝IO。
本质来说,IO的本质就是等待+数据拷贝。
我们以网络IO为例子,看看一个单纯的IO是什么样子的
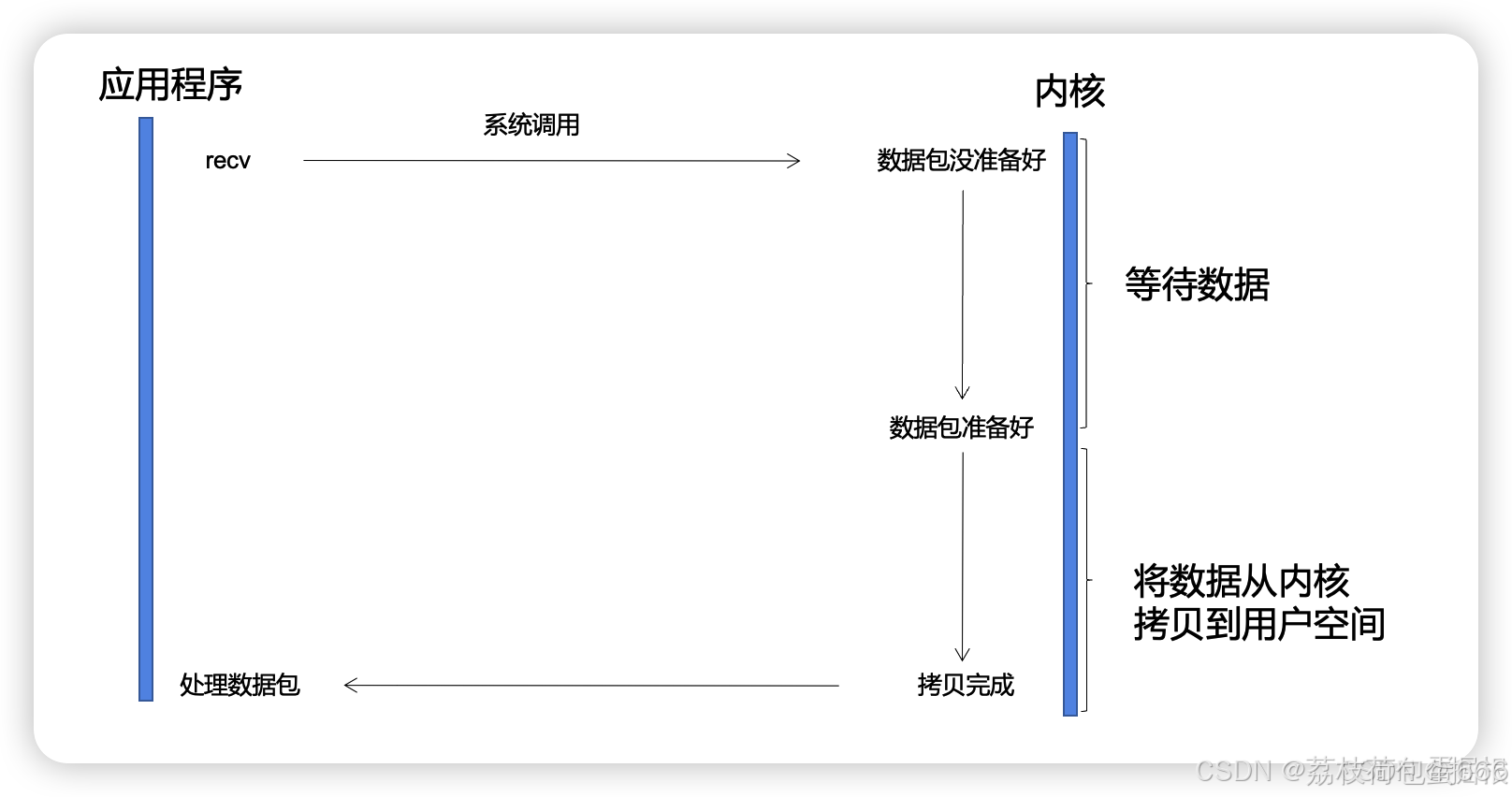
客户端发起系统调用之后,内核的操作可以被分成两步:
-
等待数据
此阶段网络数据进入网卡,然后网卡将数据放到指定的内存位置,此过程CPU无感知。然后经过网卡发起硬中断,再经过软中断,内核线程将数据发送到socket的内核缓冲区中。
-
数据拷贝
数据从socket的内核缓冲区拷贝到用户空间
那什么是高效的IO呢?
- 单位时间内,IO过程中,等待的比重越小,IO效率越高。
二,阻塞IO,非阻塞IO,异步IO,同步IO
2.1.阻塞IO和非阻塞IO
阻塞和非阻塞强调的是进程对于操作系统IO是否处于就绪状态的处理方式。
上面已经说过,应用程序的IO实际是分为两个步骤,IO调用和IO执行。IO调用是由进程发起,IO执行是操作系统的工作。操作系统的IO情况决定了进程IO调用是否能够得到立即响应。如进程发起了读取数据的IO调用,操作系统需要将外部数据拷贝到进程缓冲区,在有数据拷贝到进程缓冲区前,进程缓冲区处于不可读状态,我们称之为操作系统IO未就绪。
进程的IO调用是否能得到立即执行是需要操作系统IO处于就绪状态的,对于读取数据的操作,如果操作系统IO处于未就绪状态,当前进程或线程如果一直等待直到其就绪,该种IO方式为阻塞IO。如果进程或线程并不一直等待其就绪,而是可以做其他事情,这种方式为非阻塞IO。所以对于非阻塞IO,我们编程时需要经常去轮询就绪状态。
我们得搞清楚,这个阻塞描述的对象是谁?
- 是一个函数调用!!!函数调用过程会阻塞,一直不返回,从而导致进程/线程阻塞在这里。
- 阻塞
阻塞调用是指函数调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。
有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回,它还会抢占cpu去执行其他逻辑,也会主动检测io是否准备好。
- 非阻塞:非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
事实上,在socket编程中,阻塞与非阻塞在API上区别在于socket是否设置了SOCK_NONBLOCK这个参数,默认情况下是阻塞的,设置了该参数则为非阻塞。
2.2.同步IO和异步IO
我们经常会谈及同步IO和异步IO。同步和异步描述的是针对当前执行线程、或进程而言,发起IO调用后,当前线程或进程是否挂起等待操作系统的IO执行完成。
- 我们说一个IO执行是同步执行的,意思是程序发起IO调用,当前线程或进程需要等待操作系统完成IO工作并告知进程已经完成,线程或进程才能继续往下执行其他既定指令。
- 如果说一个IO执行是异步的,意思是该动作是由当前线程或进程请求发起,且当前线程或进程不必等待操作系统IO的执行完毕,可直接继续往下执行其他既定指令。操作系统完成IO后,当前线程或进程会得到操作系统的通知。
以一个读取数据的IO操作而言,在操作系统将外部数据写入进程缓冲区这个期间,进程或线程挂起等待操作系统IO执行完成的话,这种IO执行策略就为同步,如果进程或线程并不挂起而是继续工作,这种IO执行策略便为异步。
同步IO会阻塞当前的调用线程,而异步IO则允许发起IO请求的调用线程继续执行,等到IO请求被处理后,会通知调用线程。
对于异步的IO请求,其最大的好处是:慢速的IO请求相对于应用程序而言是异步执行,这样可以极大提高应用程序的处理吞吐量。
发起IO请求的应用程序需要关心的是IO执行完成的结果,而不必忙等IO请求执行的过程。它只需要提交一个IO操作,当内核执行这个IO操作时,线程可以去运行其他逻辑,也不需要定期去查看IO是否完成,当内核完成这个IO操作后会以某种方式通知应用。 此时应用的运行和IO执行变成了并行的关系,可以批量的进行IO操作,让设备的能力得到最大发挥
在“发出IO请求”到收到“IO完成”的这段时间里,同步IO模型下,主线程只能挂起,但异步IO模型下,主线程并没有休息,而是续处理其他消息。这样,在异步IO模型下,一个线程就可以同时处理多个IO请求,并且没有切换线程的操作。对于大多数IO密集型的应用程序,使用异步IO将大大提升系统的多任务处理能力。
- 同步的执行效率会比较低,耗费时间,但有利于我们对流程进行控制,避免很多不可掌控的意外情况;
- 异步的执行效率高,节省时间,但是会占用更多的资源,也不利于我们对进程进行控制
同步IO的优点
- 1、同步流程对结果处理通常更为简单,可以就近处理。
- 2、同步流程对结果的处理始终和前文保持在一个上下文内。
- 3、同步流程可以很容易捕获、处理异常。
- 4、同步流程是最天然的控制过程顺序执行的方式。
异步IO的优点
- 1、异步流程可以立即给调用方返回初步的结果。
- 2、异步流程可以延迟给调用方最终的结果数据,在此期间可以做更多额外的工作,例如结果记录等等。
- 3、异步流程在执行的过程中,可以释放占用的线程等资源,避免阻塞,等到结果产生再重新获取线程处理。
- 4、异步流程可以等多次调用的结果出来后,再统一返回一次结果集合,提高响应效率。
异步IO使用场景
- 1、不涉及共享资源,或对共享资源只读,即非互斥操作
- 2、没有时序上的严格关系
- 3、不需要原子操作,或可以通过其他方式控制原子性
- 4、常用于IO操作等耗时操作,因为比较影响客户体验和使用性能
- 5、不影响主线程逻辑
2.3.总结
再简单点理解就是:
- 1. 同步,就是我调用一个功能,该功能没有结束前,我死等结果。
- 2. 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)。
- 3. 阻塞,就是调用我(函数),我(函数)没有接收完数据或者没有得到结果之前,我不会返回。
- 4. 非阻塞,就是调用我(函数),我(函数)立即返回,通过select通知调用者
同步IO和异步IO的区别就在于: 数据拷贝的时候进程是否阻塞
阻塞IO和非阻塞IO的区别就在于: 应用程序的调用是否立即返回
综上可知,同步和异步,阻塞和非阻塞,有些混用,其实它们完全不是一回事,而且它们修饰的对象也不相同。
说完了同步异步、阻塞非阻塞,一个很自然的操作就是对他们进行排列组合。
- 同步阻塞
- 同步非阻塞
- 异步非阻塞
- 异步阻塞
我们可以举个例子来理解这四种情况
这个故事以老张煮开水为引子,生动地解释了同步与异步、阻塞与非阻塞的概念,这些概念在编程和网络通信中尤为重要。下面是对这四个场景的详细解释:
同步阻塞
- 老张操作:老张直接把水壶放到火上,然后站在旁边等待水开。
- 解释:在这个过程中,老张无法做其他事情,必须等待水开,这就是同步阻塞。程序执行到这里会暂停,直到水开(即操作完成)后才会继续执行后面的代码。
同步非阻塞
- 老张操作:老张还是把水壶放到火上,但这次他选择去客厅看电视,并时不时回到厨房查看水是否开了。
- 解释:虽然老张没有在厨房一直等,但他还是需要时不时去查看水是否开了,这种“轮询”的方式就是同步非阻塞。程序会定期检查某个操作是否完成,但这仍然需要占用程序的时间来检查,效率并不高。
异步阻塞
- 老张操作:老张买了会响的水壶,并把它放到火上,但他还是选择站在旁边等水开,只不过这次他可以通过水壶的响声来判断水是否开了。
- 解释:这里的“异步”实际上是指老张不需要一直盯着水壶看水是否开了,但他仍然选择等在原地,等待水壶响。这种方式并没有真正提高老张的效率,因为他仍然被“阻塞”在原地等待,所以称为异步阻塞。但这里的核心是“异步”的概念被误解了,因为老张仍然是在等待,并没有去执行其他任务。在编程中,真正的异步是程序可以继续执行其他任务,而不必等待当前任务完成。
- 很显然这个阻塞是多余的。
异步非阻塞
- 老张操作:老张再次使用响水壶,但这次他完全放心地去客厅看电视,直到水壶响了才去厨房拿壶。
- 解释:这是真正的异步非阻塞模式。老张不需要一直等待水壶,他可以继续做其他事情(如看电视),当水壶的水开了(即某个操作完成)时,他会通过水壶的响声(回调或通知)得知,并去处理(拿壶)。这种方式下,老张的效率最高,因为他可以在等待水开的同时做其他事情。在编程中,这种模式允许程序在等待某个操作完成时,继续执行其他任务,从而提高程序的并发性和效率。
看到这里大家应该明白了,这四种组合吧!!!
注意:异步阻塞是什么鬼?
按照上文的解释,该IO模型在第一阶段应该是用户线程阻塞,等待数据;第二阶段应该是内核线程(或专门的IO线程)处理IO操作,然后把数据通过事件或者回调的方式通知用户线程,既然如此,那么第一步的阻塞完全没有必要啊!非阻塞调用,然后继续处理其他任务岂不是更好。
因此,压根不存在异步阻塞这种模型哦~
三,五种IO模型
IO模型分为五种,分别是阻塞式IO,非阻塞IO,信号驱动IO,多路转接IO,异步IO。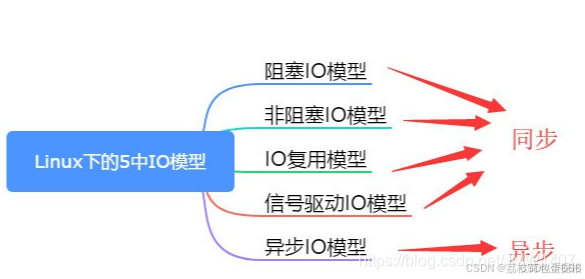
下面我们讲一个例子先来浅浅谈一下这5个模型IO的做法。
- 从前有一条小河,河里有许多条鱼,一个叫张三的少年就很喜欢钓鱼,他带着自己的鱼竿就去钓鱼了,但张三这个人很固执,只要鱼没上钩,张三就一直等着,什么都不干,死死的盯着鱼漂,只有鱼漂动了,张三才会动,然后把鱼钓上来,钓上来之后,张三就又会重复之前的动作,一动不动的等待鱼儿上钩。
-
而此时走过来一个李四,李四这名少年也很喜欢钓鱼,但李四和张三不一样,李四左口袋装着《Linux高性能服务器编程》,右口袋装着一本《算法导论》,左手拿手机,右手拿了一根鱼竿,李四拿了钓鱼凳坐下之后,李四就开始钓鱼了,但李四不像张三一样,固执的死盯着鱼漂看,李四一会看会儿左口袋的书,一会玩会手机,一会儿又看算法导论,一会又看鱼漂,所以李四一直循环着前面的动作,直到循环到看鱼漂时,发现鱼漂已经动了好长时间了,此时李四就会把鱼儿钓上来,之后继续重复循环前面的动作。
-
此时又来了一个王五少年,王五就拿着他自己的iphone14pro max和一根鱼竿外加一个铃铛,然后就来钓鱼了,王五把铃铛挂到鱼竿上,等鱼上钩的时候,铃铛就会响,王五根本不看鱼竿,就一直玩自己的iphone,等鱼上钩的时候,铃铛会自动响,王五此时再把鱼儿钓上来就好了,之后王五又继续重复前面的动作,只要铃铛不响,王五就一直玩手机,只有铃铛响了,王五才会把鱼钓上来。
-
此时又来了一个赵六的人,赵六和前面的三个人都不一样,赵六是个小土豪,赵六手里拿了一堆鱼竿,目测有几百根鱼竿,赵六到达河边,首先就把几百根鱼竿每隔几米插上去,总共插了好几百米的鱼竿,然后赵六就依次遍历这些鱼竿,哪个鱼竿上的鱼漂动了,赵六就把这根鱼竿上的鱼钓上来,然后接下来赵六就又继续重复之前遍历鱼竿的动作进行钓鱼了。
-
然后又来了一个钱七,钱七比赵六还有钱,钱七是上市公司的CEO,钱七有自己的司机,钱七不喜欢钓鱼,但钱七喜欢吃鱼,所以钱七就把自己的司机留在了岸边,并且给了司机一个电话和一个桶,告诉司机,等你把鱼钓满一桶的时候,就给我打电话,然后我就从公司开车过来接你,所以钱七就直接开车回公司开什么股东大会去了,而他的司机就被留在这里继续钓鱼了。
在上面的例子中,你认为谁的钓鱼方式更加高效呢?
首先我们认为,如果一个人在不停的钓鱼,时不时的就收鱼竿,把鱼钓上来,等待鱼儿上钩的时间比重却很低,那么这个人在我看来他的钓鱼方式就是高效的。而如果一个人大部分的时间都是在等待,只有那么极少数次在收杆把鱼钓上来,那么这个人的钓鱼方式就是低效的。
而上面的例子中,鱼其实就是数据,鱼竿其实就是文件描述符fd,每个人都算是进程,但除了钱七的司机,这个司机算是操作系统,河流就是内核缓冲区,鱼漂就是就绪的事件,代表钓鱼这件事情已经就绪了,进程可以对数据做拷贝了。
其实赵六的方式是最高效的,也就是多路转接这种IO模型是最高效的,因为赵六的鱼竿多啊,钓上鱼的几率就大啊,其他人只有一根鱼竿,只能关心这一根鱼竿上的数据,自然就没有赵六的效率高,同理为什么渣男的女朋友多啊,因为广撒网嘛,找到女朋友的概率要比普通的老实人高啊,因为人家一次可以关心那么多的微信账号,哪个女孩发消息了人家就和谁聊天,肯定比你只有一个女孩的微信效率要高。
所以本文章主要来介绍多路转接这种IO模型,同时也会讲解阻塞和非阻塞IO,需要注意的是,实际项目中,最常用的就是阻塞IO,同时大部分的fd默认就是阻塞的,因为这种IO太简单了,越简单的东西往往就越可靠,代码编写也越简单,调试和找bug的难度也就越低,这样的代码可维护性很高,所以他就越常用。
阻塞,非阻塞,信号驱动在IO效率上是没有差别的,因为他们三个人都只有一根鱼竿,等待鱼上钩的概率都是一样的,相当于他们等待事件就绪的概率是相同的,所以从IO效率上来看,这三个模型之间是没有差别的。只不过三者等待的方式是不同的,阻塞是一直在进行等待,而非阻塞可能会使用轮询的方式来进行等待,在等待的时间段内,非阻塞可能还会做一些其他的事情,信号驱动和非阻塞一样,在等待的时间段内,信号驱动会做一些其他的事情,比如监管一下其他的连接是否就绪等等事情。所以从IO的效率角度来讲,这三种IO并无差别,因为IO的过程分为等待和数据拷贝,三者在这个工作上的效率都是一样的,只不过非阻塞和信号驱动的等待方式与阻塞IO不同。信号驱动只不过是被动的等待,阻塞和非阻塞都是主动的等待,当信号到来时,信号驱动IO会通过回调的方式来处理就绪的事件。
而多路转接相比前三种IO模型更为高效一些,因为他能够一次等待多个文件描述符,但这四种IO都有一个共同的特征,就是直接参与了IO的过程,这样的通信我们称之为同步通信,而异步IO是典型的异步通信,他将等待数据就绪的事情交给了内核来处理,当数据准备好后,操作系统会以信号或回调函数的方式来通知进程可以处理数据了,因为数据已经准备好了,这就是典型的异步通信。
3.1.复习
要深入的理解各种IO模型,那么必须先了解下产生各种IO的原因是什么,要知道这其中的本质问题那么我们就必须要知道一条消息是如何从一个人发送到另外一个人的;
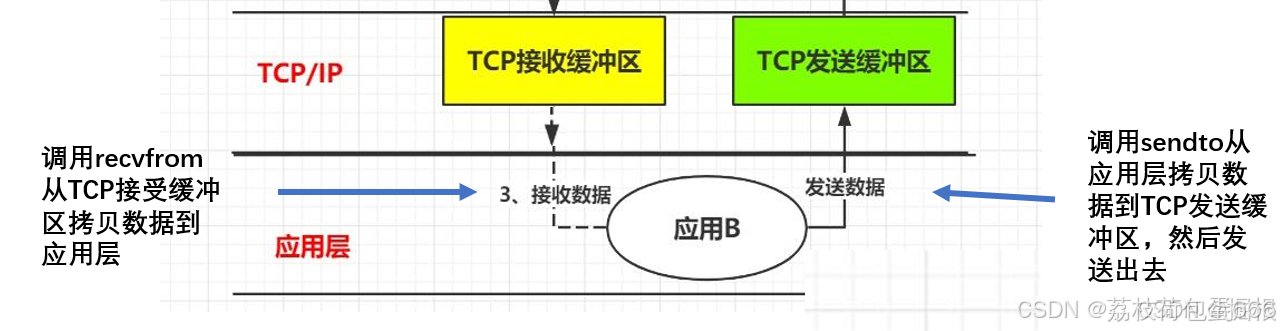
以两个应用程序通讯为例,我们来了解一下当“A”向"B" 发送一条消息,简单来说会经过如下流程:
- 第一步:应用A把消息发送到 TCP发送缓冲区。
- 第二步: TCP发送缓冲区再把消息发送出去,经过网络传递后,消息会发送到B服务器的TCP接收缓冲区。
- 第三步:B再从TCP接收缓冲区去读取属于自己的数据。
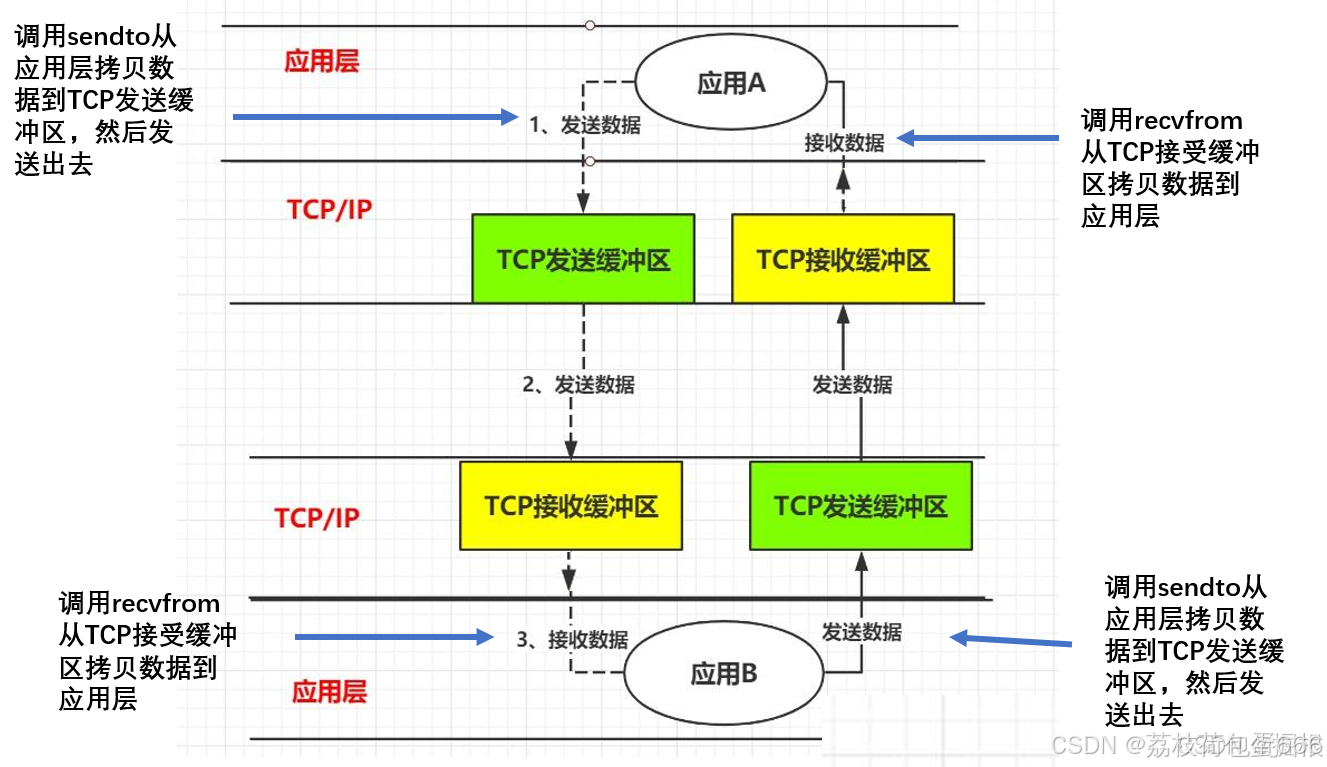
根据上图我们基本上了解消息发送要经过 应用A、应用A对应服务器的TCP发送缓冲区、经过网络传输后消息发送到了应用B对应服务器TCP接收缓冲区、然后最终B应用读取到消息。
如果理解了上面的消息发送流程,那么我们下面开始进入主题;
3.2.阻塞IO模型
我们把视角切换到上面图中的第三步, 也就是应用B从TCP缓冲区中读取数据。
思考一个问题:
因为应用之间发送消息是间断性的,也就是说在上图中TCP缓冲区还没有接收到属于应用B该读取的消息时,那么此时应用B向TCP缓冲区发起读取申请,TCP接收缓冲区是应该马上告诉应用B 现在没有你的数据,还是说让应用B在这里等着,直到有数据再把数据交给应用B。
把这个问题应用到第一个步骤也是一样,应用A在向TCP发送缓冲区发送数据时,如果TCP发送缓冲区已经满了,那么是告诉应用A现在没空间了,还是让应用A等待着,等TCP发送缓冲区有空间了再把应用A的数据访拷贝到发送缓冲区。
如果上面的问题你已经思考过了,那么其实你已经明白了什么是阻塞IO了,所谓阻塞IO就是当应用B发起读取数据申请时,在内核数据没有准备好之前,应用B会一直处于等待数据状态,直到内核把数据准备好了交给应用B才结束。
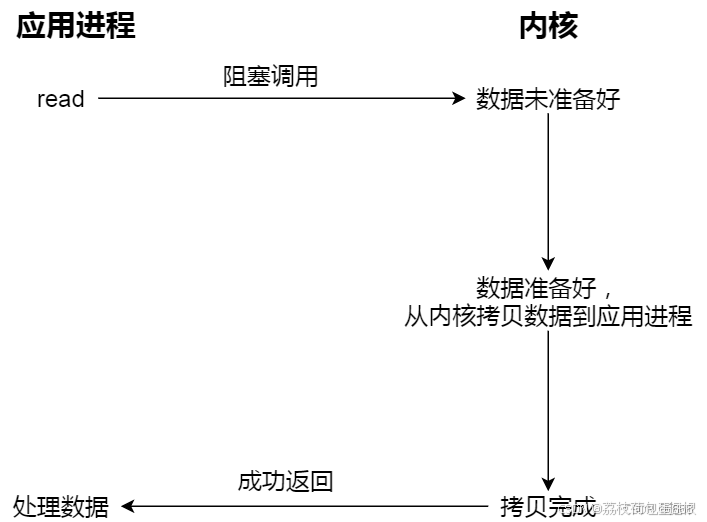
阻塞式IO流程:
进程发起IO系统调用后,进程被阻塞,转到内核空间处理,整个IO处理完毕后返回进程,操作成功则进程获取到数据。
假设socket为阻塞模式,则IO调用如下图所示。
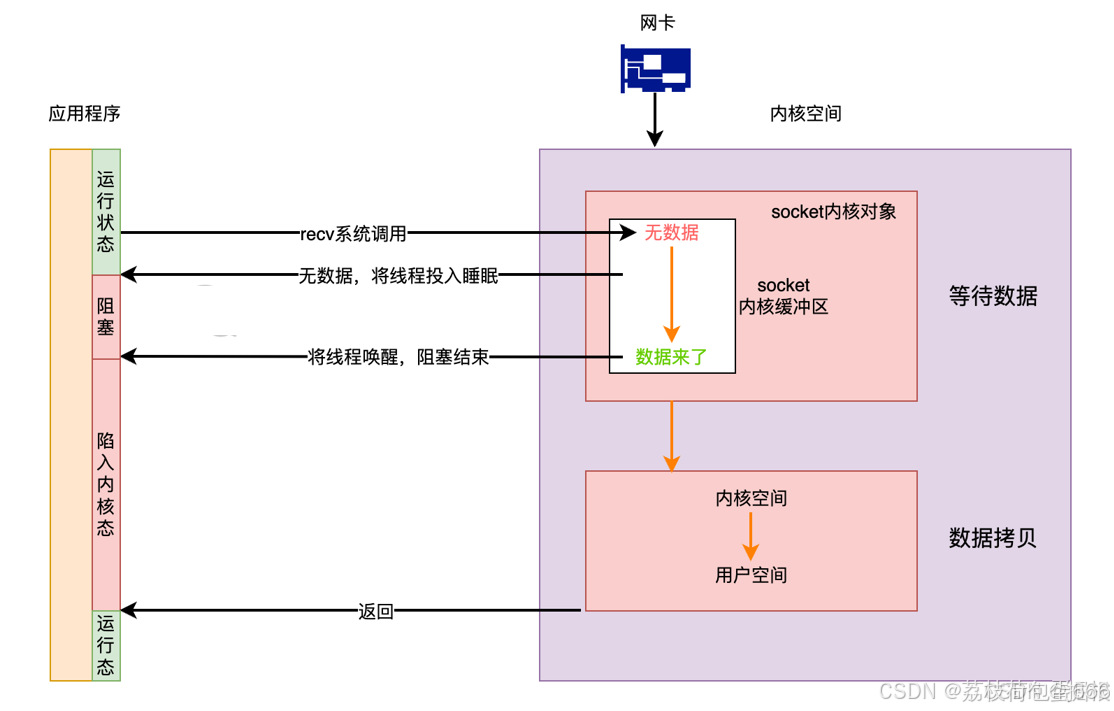
当处于运行状态的用户线程发起recv系统调用时,如果socket内核缓冲区内没有数据,则内核会将当前线程投入睡眠,让出CPU的占用。
直到网络数据到达网卡,网卡DMA数据到内存,再经过硬中断、软中断,由内核线程唤醒用户线程。
此时socket的数据已经准备就绪,用户线程由用户态进入到内核态,执行数据拷贝,将数据从内核空间拷贝到用户空间,系统调用结束。此阶段,开发者通常认为用户线程处于等待(称为阻塞也行)状态,因为在用户态的角度上,线程确实啥也没干(虽然在内核态干得累死累活)。
3.3.非阻塞式IO模式
按照上面的思路,所谓非阻塞IO就是当应用B发起读取数据申请时,如果内核数据没有准备好会即刻告诉应用B,不会让B在这里等待。
定义
-
非阻塞IO是在应用调用recvfrom读取数据时,如果该缓冲区没有数据的话,就会直接返回一个
EWOULDBLOCK错误,不会让应用一直等待中。 -
在没有数据的时候会即刻返回错误标识,那也意味着如果应用要读取数据就需要不断的调用recvfrom请求,直到读取到它数据要的数据为止。
非阻塞式IO流程:
和上面的阻塞IO模型相比,非阻塞IO模型在内核数据没准备好,需要进程阻塞的时候,就返回一个错误,以使得进程不被阻塞。
- 进程发起IO系统调用后,如果内核缓冲区没有数据,需要到IO设备中读取,进程返回一个错误而不会被阻塞。
- 进程发起IO系统调用后,如果内核缓冲区有数据,内核就会把数据返回进程。
这种工作方式下需要不断轮询查看状态
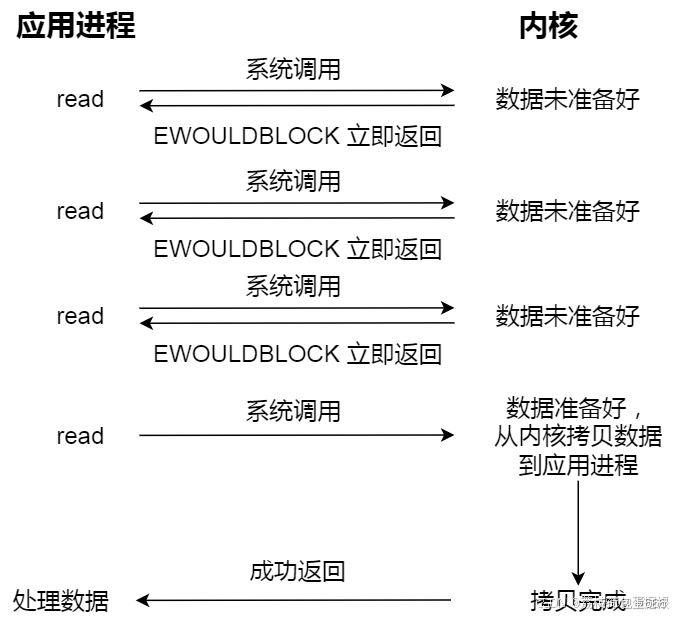
非阻塞式IO的过程大概如下:
- 1、应用进程向内核发起recvfrom读取数据。
- 2、没有数据报准备好,即刻返回EWOULDBLOCK错误码。
- 3、应用进程向内核发起recvfrom读取数据。
- 4、已有数据包准备好就进行一下 步骤,否则还是返回错误码。
- 5、将数据从内核拷贝到用户空间。
- 6、完成后,返回成功提示。
如果将socket设置为非阻塞模式,调用便换了一副光景。
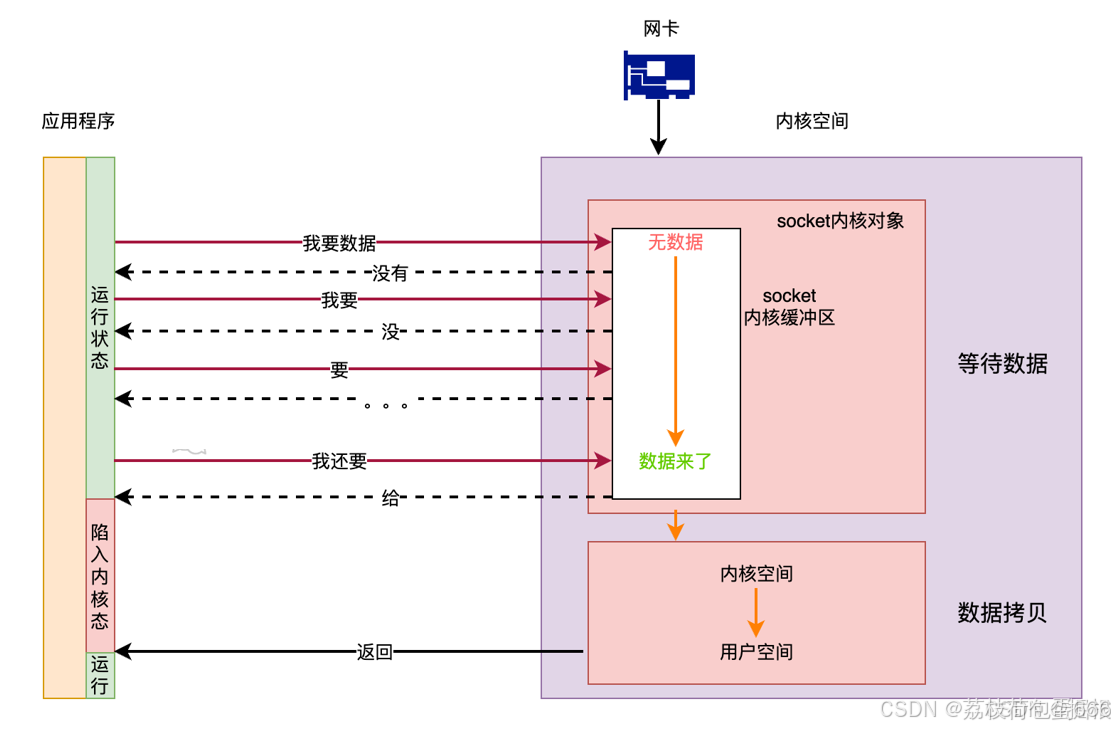
用户线程发起系统调用,如果socket内核缓冲区中没有数据,则系统调用立即返回,不会挂起线程。而线程会继续轮询,直到socket内核缓冲区内有数据为止。
如果socket内核缓冲区内有数据,则用户线程进入内核态,将数据从内核空间拷贝到用户空间。
3.4.多路复用IO模式
思考一个问题:
我们还是把视角放到应用B从TCP缓冲区中读取数据这个环节来。如果在并发的环境下,可能会N个人向应用B发送消息,这种情况下我们的应用就必须创建多个线程去读取数据,每个线程都会自己调用recvfrom 去读取数据。那么此时情况可能如下图: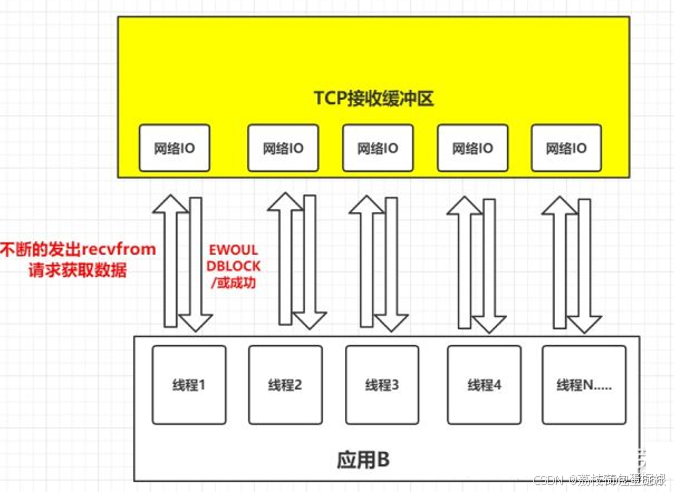
如上图一样,并发情况下服务器很可能一瞬间会收到几十上百万的请求,这种情况下应用B就需要创建几十上百万的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送recvfrom 请求来读取数据;
那么问题来了,这么多的线程不断调用recvfrom 请求数据,先不说服务器能不能扛得住这么多线程,就算扛得住那么很明显这种方式是不是太浪费资源了,线程是我们操作系统的宝贵资源,大量的线程用来去读取数据了,那么就意味着能做其它事情的线程就会少。
所以,有人就提出了一个思路,能不能提供一种方式,可以由一个线程监控多个网络请求(我们后面将称为fd文件描述符,linux系统把所有网络请求以一个fd来标识),这样就可以只需要一个或几个线程就可以完成数据状态询问的操作,当有数据准备就绪之后再分配对应的线程去读取数据,这么做就可以节省出大量的线程资源出来,这个就是IO复用模型的思路。 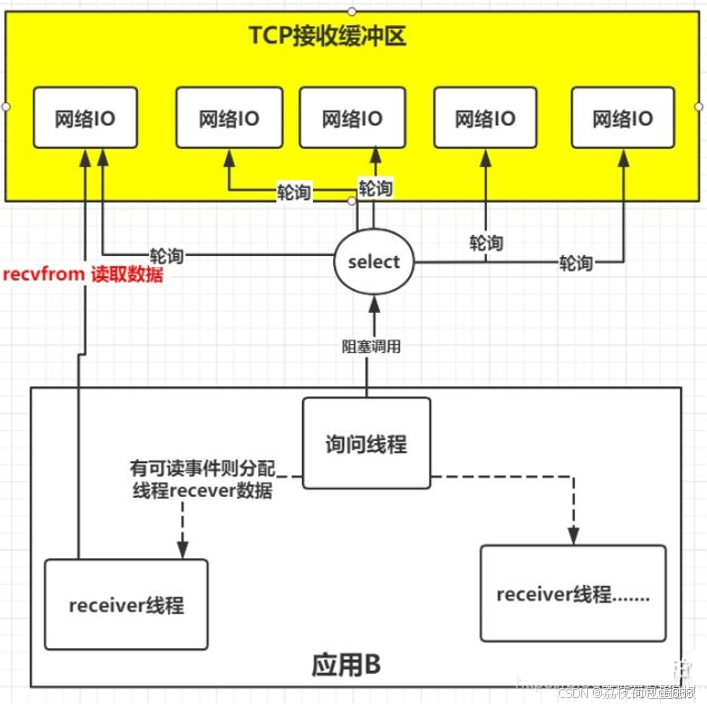
正如上图,IO复用模型的思路就是系统提供了一种函数可以同时监控多个fd的操作,这个函数就是我们常说到的select、poll、epoll函数,有了这个函数后,应用线程通过调用select函数就可以同时监控多个fd,select函数监控的fd中只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时询问线程再去通知处理数据的线程,对应线程此时再发起recvfrom请求去读取数据。
Linux中IO复用的实现方式主要有Select,Poll和Epoll:
- Select:注册IO、阻塞扫描,监听的IO最大连接数不能多于FD_ SIZE(1024)。
- Poll:原理和Select相似,没有数量限制,但IO数量大,扫描线性性能下降。
- Epoll :事件驱动不阻塞,mmap实现内核与用户空间的消息传递,数量很大,Linux2.6后内核支持。
定义
多个的进程的IO可以注册到一个复用器(select)上,然后用一个进程调用该select,,select会监听所有注册进来的IO,每个IO都会有一个文件描述符fd。
进程通过将一个或多个fd传递给select(或者其他IO复用API),阻塞在select操作上,select帮我们侦测多个fd是否准备就绪,当有fd准备就绪时,select返回数据可读状态,应用程序再调用recvfrom读取数据。
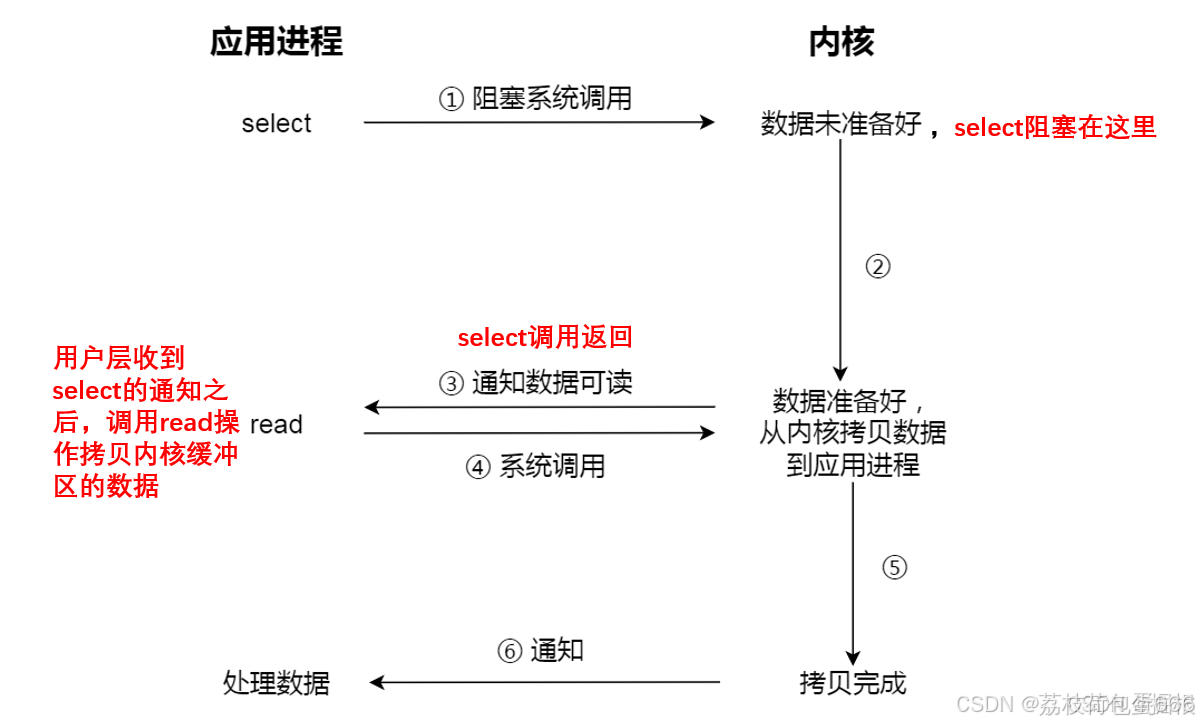
总结:
复用IO的基本思路就是通过slect或poll、epoll 来监控多fd ,来达到不必为每个fd创建一个对应的监控线程,从而减少线程资源创建的目的。
3.5、信号驱动IO(signal driven IO)
复用IO模型解决了一个线程可以监控多个fd的问题,但是select是采用轮询的方式来监控多个fd的,通过不断的轮询fd的可读状态来知道是否就可读的数据,而无脑的轮询就显得有点暴力,因为大部分情况下的轮询都是无效的,所以有人就想,能不能不要我总是去问你是否数据准备就绪,能不能我发出请求后等你数据准备好了就通知我,所以就衍生了信号驱动IO模型。
于是信号驱动IO不是用循环请求询问的方式去监控数据就绪状态,具体如下:
1、调用sigaction时候建立一个SIGIO的信号联系,
2、当内核数据准备好之后再通过SIGIO信号通知线程数据准备好后的可读状态,
3、当线程收到可读状态的信号后,此时再向内核发起recvfrom读取数据的请求,因为信号驱动IO的模型下应用线程在发出信号监控后即可返回,不会阻塞
4、所以这样的方式下,一个应用线程也可以同时监控多个fd。
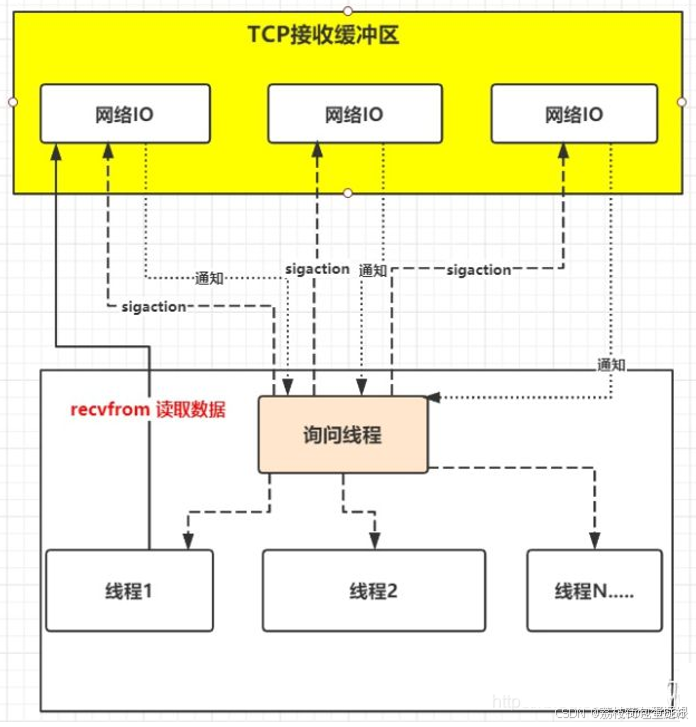
定义
当进程发起一个IO操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用IO读取数据。
首先开启套接口信号驱动IO功能,并通过系统调用sigaction执行一个信号处理函数,此时请求即刻返回,当数据准备就绪时,就生成对应进程的SIGIO信号,通过信号回调通知映应用线程调用recvfrom来读取数据。
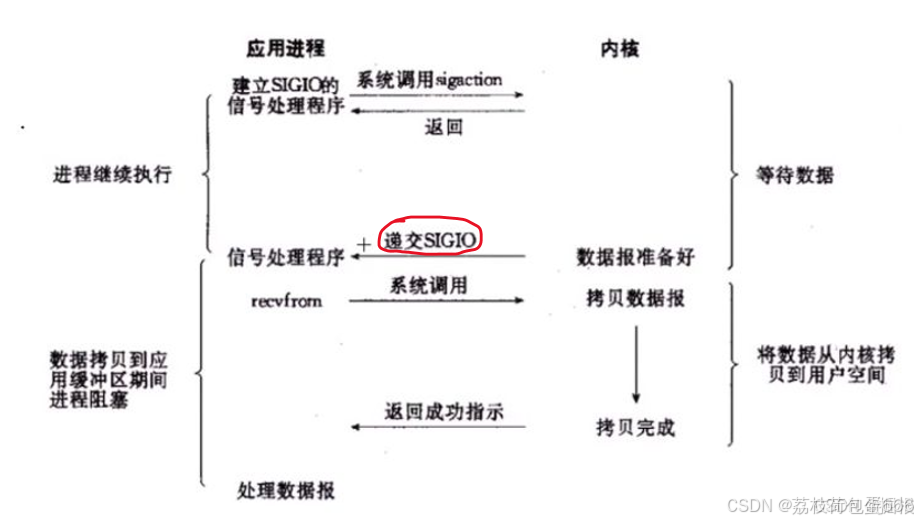
总结:
IO复用模型里面的select虽然可以监控多个fd了,但select其实现的本质上还是通过不断的轮询fd来监控数据状态, 因为大部分轮询请求其实都是无效的,所以信号驱动IO意在通过这种建立信号关联的方式,实现了发出请求后只需要等待数据就绪的通知即可,这样就可以避免大量无效的数据状态轮询操作。
3.6、异步IO( asynchronous IO)
通过观察我们发现,不管是IO复用还是信号驱动,我们要读取一个数据总是要发起两阶段的请求,第一次发送select请求,询问数据状态是否准备好,第二次发送recevform请求读取数据。(这也就是为什么上面四种都是同步IO)
在IO模型里面如果请求方从发起请求到数据最后完成的这一段过程中都需要自己参与,那么这种我们称为同步;
如果应用发送完指令后就不再参与过程了,只需要等待最终完成结果的通知,那么这就属于异步。
思考一个问题:
也许你一开始就有一个疑问,为什么我们明明是想读取数据,什么非得要先发起一个select询问数据状态的请求,然后再发起真正的读取数据请求,能不能有一种一劳永逸的方式,我只要发送一个请求我告诉内核我要读取数据,然后我就什么都不管了,然后内核去帮我去完成剩下的所有事情? 有人设计了一种方案,应用只需要向内核发送一个read 请求,告诉内核它要读取数据后即刻返回;内核收到请求后会建立一个信号联系,当数据准备就绪,内核会主动把数据从内核复制到用户空间,等所有操作都完成之后,内核会发起一个通知告诉应用,我们称这种一劳永逸的模式为异步IO模型。 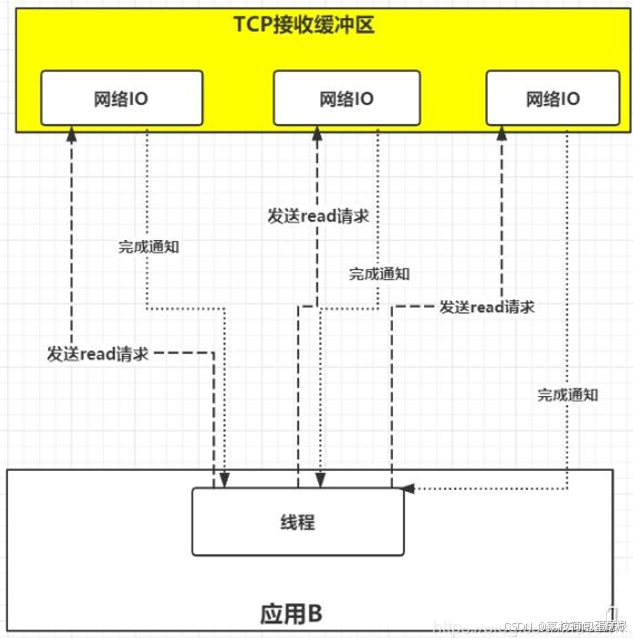
定义
应用告知内核启动某个操作,并让内核在整个操作完成之后,通知应用,这种模型与信号驱动模型的主要区别在于,信号驱动IO只是由内核通知我们合适可以开始下一个IO操作,而异步IO模型是由内核自动完成IO操作,并通知我们操作什么时候完成。
当进程发起一个IO操作,进程返回(不阻塞),但也不能返回结果。内核把整个IO处理完后,会通知进程结果,如果IO操作成功则进程直接获取到数据。
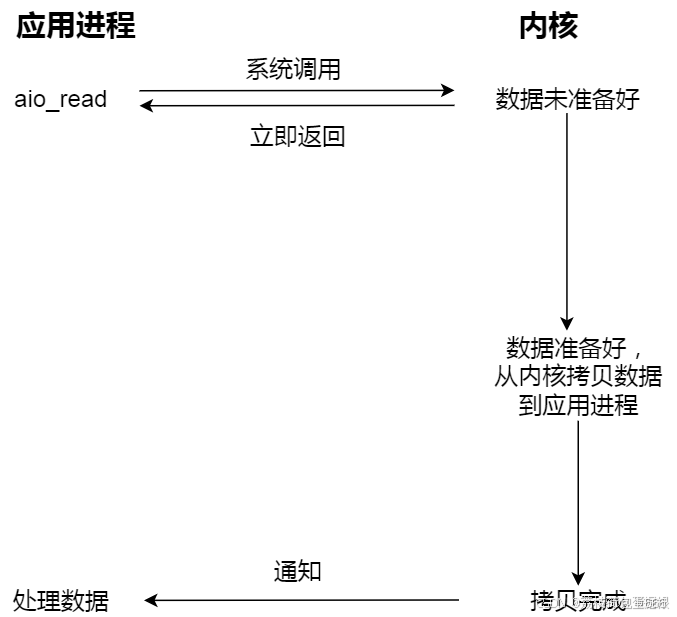
此模型和前面模型最大的区别是:前4个从内核空间拷贝数据这一过程是阻塞的,需要自己把准备好的数据,放到用户空间。
而全异步不同,异步IO是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。用户线程完全不需要关心实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据,它是最理想的模型。
总结:
异步IO的优化思路是解决了应用程序需要先后发送询问请求、发送接收数据请求两个阶段的模式,在异步IO的模式下,只需要向内核发送一次请求就可以完成状态询问和数拷贝的所有操作。
四.文件描述符的默认行为——阻塞IO
在Linux系统中,无论是通过open系统调用打开的文件(包括系统文件、设备文件等),还是通过socket创建的网络套接字(sock),它们对应的文件描述符(fd)默认都是阻塞的。这种阻塞行为是操作系统为了简化同步I/O操作而设计的。
当进程尝试对一个文件描述符执行读或写操作时,如果所需的数据当前不可用(例如,读操作而缓冲区为空)或无法立即写入数据(例如,写操作而缓冲区已满或磁盘I/O繁忙),则进程将被挂起(阻塞),直到以下条件之一发生:
- 对于读操作:有数据可供读取,或者到达文件末尾(EOF)。
- 对于写操作:数据已经被成功写入到内核的缓冲区中,即使这些数据还没有被实际写入到磁盘上。
在阻塞模式下,进程需要等待这些条件成立才能继续执行,这可能会导致进程在I/O操作上花费大量时间,从而降低程序的响应性和吞吐量。
下面是一个简单的例子。
#include <iostream>
#include <unistd.h>
#include <string.h>
int main() {
std::cout << "This program echoes input in blocking mode. Try typing something and pressing enter.\n";
char buffer[100];
while (true) {
ssize_t bytes_read = read(STDIN_FILENO, buffer, sizeof(buffer) - 1);
if (bytes_read > 0) {
buffer[bytes_read] = '\0'; // 确保字符串以null字符结束
std::cout << "Echo: " << buffer << std::endl;
} else if (bytes_read == 0) {
// 对于文件描述符如stdin,在阻塞模式下,read返回0通常意味着EOF(文件结束)
// 但对于stdin,这通常不会发生,除非输入被重定向自一个文件或管道,并且该文件或管道已经到达末尾
std::cout << "Unexpected end of input (this should not normally happen with stdin)." << std::endl;
break;
} else {
// read返回-1时表示发生错误
std::cerr << "Error reading input: " << strerror(errno) << std::endl;
break;
}
}
return 0;
}上面这就是典型的阻塞式IO,当程序运行起来时,执行流会在read处阻塞,因为read今天读取的是0号文件描述符,也就是键盘文件上的数据,只要我不从键盘上输入数据的话,read就会一直阻塞,此时进程会被操作系统挂起,直到硬件设备键盘上有数据时,进程才会重新投入CPU的运行队列,当我们输入数据后,可以立马看到进程显示出了echo回应的结果,同时进程又立马陷入阻塞,等待我进行下一次的输入数据,这样的IO方式就是典型的阻塞式,同时也是最常用,最简单的IO方式。
为了解决这个问题,Linux提供了非阻塞I/O(Non-blocking I/O)和异步I/O(Asynchronous I/O)等机制。通过设置文件描述符为非阻塞模式,进程可以在I/O操作无法立即完成时立即返回一个错误(通常是EAGAIN或EWOULDBLOCK),而不是被挂起。这样,进程就可以继续执行其他任务,而不会因等待I/O操作而阻塞。
对于网络套接字,除了设置非阻塞模式外,还可以使用I/O多路复用技术(如select、poll、epoll)来同时监视多个文件描述符的状态,从而在不增加线程或进程数量的情况下处理多个并发连接。这些技术允许进程在单个线程中高效地管理多个I/O操作,提高了程序的性能和可扩展性。
4.1.非阻塞IO
在Linux操作系统中,关于设置文件描述符(fd)为非阻塞模式的方式主要有两种。下面是对这两种主要方式的准确描述:
在打开文件或创建套接字时设置非阻塞模式:
对于文件(包括设备文件),通常不建议也不常见将其设置为非阻塞模式,因为文件I/O操作(如读、写)通常是同步完成的,且没有像网络I/O那样的等待状态。但是,如果您确实需要对文件描述符设置非阻塞模式(例如,对于管道、FIFO或某些特殊类型的文件),可以在使用open系统调用时,在flags参数中包含O_NONBLOCK标志。
- 对于套接字,由于套接字是通过socket系统调用创建的,而不是open,因此您不能在socket调用时直接设置O_NONBLOCK。但是,您可以在socket调用之后,使用fcntl函数和F_SETFL命令来修改套接字文件描述符的标志,以包含O_NONBLOCK。
// 创建套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 设置套接字为非阻塞模式
fcntl(sockfd, F_SETFL, fcntl(sockfd, F_GETFL, 0) | O_NONBLOCK); 注意:像fcntl这样的方式,无论对于系统文件还是网络套接字都是完全适用的。
4.2.在使用网络I/O接口时请求非阻塞行为:
对于网络套接字,虽然您已经在套接字级别设置了非阻塞模式,但在某些情况下,您可能还想在特定的send、recv等I/O调用中请求非阻塞行为,以确保该调用不会因等待数据而阻塞。这可以通过在调用这些函数时包含MSG_DONTWAIT标志来实现。但是,请注意,如果套接字已经设置为非阻塞模式,那么即使没有指定MSG_DONTWAIT,这些调用也不会阻塞。
MSG_DONTWAIT主要用于在套接字处于阻塞模式时,临时请求非阻塞行为。
// 套接字已经设置为非阻塞模式,但显式使用MSG_DONTWAIT也可以
ssize_t n = recv(sockfd, buf, len, MSG_DONTWAIT);
if (n == -1 && errno == EAGAIN) {
// 处理非阻塞情况下没有数据可读的情况
} 然而,在实际应用中,当您希望套接字以非阻塞方式工作时,通常会在套接字创建后立即使用fcntl设置其非阻塞模式,并在后续的网络I/O调用中不再需要显式地指定MSG_DONTWAIT(除非您有特定的理由需要在某些调用中临时恢复阻塞行为)。
因此,总结来说,设置文件描述符为非阻塞模式的主要方式是通过fcntl和O_NONBLOCK标志(对于套接字和某些特殊类型的文件),而不是通过open的O_NONBLOCK选项(因为套接字不是通过open创建的),并且MSG_DONTWAIT是在网络I/O调用中请求非阻塞行为的额外选项,但它不是设置文件描述符非阻塞模式的独立方法。
4.3.fcntl函数
当涉及到在Linux中对文件进行控制和管理时,fcntl(file control)函数是一个强大的工具。它提供了一种灵活的方式来执行各种文件操作,从修改文件属性到锁定文件,甚至是改变文件的行为。本文将深入探讨fcntl函数的用法、参数和示例,帮助读者更好地了解如何利用这个功能强大的API来操作文件。
fcntl函数是Linux系统中用于执行各种文件控制操作的系统调用之一。它可以用于修改文件描述符的属性,如文件状态标志(file status flags)、文件描述符标志(file descriptor flags)、文件锁(file locks)以及其他的一些操作。fcntl函数提供了对文件或文件描述符进行底层控制的接口,使得开发者可以更精细地管理文件的行为。
fcntl函数的原型和参数
在C语言中,fcntl函数的原型如下:
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* arg */);- fd 是要操作的文件描述符。
- cmd 是控制操作的命令。
- arg 是与命令相关联的可选参数。
fcntl函数的cmd参数决定了具体执行的操作类型,常见的一些操作包括:
- F_GETFL:获取文件描述符的状态标志。
- F_SETFL:设置文件描述符的状态标志。
- F_GETLK:获取文件锁。
- F_SETLK:设置或释放文件锁。
- F_SETLKW:阻塞地设置或释放文件锁。

文件状态标志(File status flags)
- O_RDONLY:只读打开。
- O_WRONLY:只写打开。
- O_RDWR:读写打开。
- O_APPEND:追加写入。
- O_CREAT:如果文件不存在则创建文件。
- O_EXCL:与O_CREAT一起使用,如果文件存在则报错。
- O_TRUNC:如果文件存在且为只写或读写,则将其长度截断为0。
文件描述符标志(File descriptor flags):
- FD_CLOEXEC:在exec执行期间关闭文件描述符。
- 其他标志:
- O_NONBLOCK:非阻塞模式,用于文件描述符,使得对文件的读写操作不会阻塞进程。
- O_SYNC:使得每次write都等到物理 I/O 操作完成后才返回。
- O_DIRECTORY:如果文件名是目录,则打开失败。
- O_DSYNC:等待物理 I/O 数据完成,不等待文件属性更新。
- O_NOATIME:不更新访问时间戳。
- O_NOCTTY:如果设备是终端,不将其分配为控制终端。
下面是一个简单的将文件描述符设置为非阻塞的例子
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
int main() {
std::cout << "This program echoes input in non-blocking mode. Try typing something and pressing enter.\n";
char buffer[100];
while (true) {
ssize_t bytes_read = read(STDIN_FILENO, buffer, sizeof(buffer) - 1);
if (bytes_read > 0) {
buffer[bytes_read] = '\0'; // 确保字符串以null字符结束
std::cout << "Echo: " << buffer << std::endl;
} else if (bytes_read == 0) {
// 对于文件描述符如stdin,read返回0通常不表示结束,但在某些特殊情况下(如管道关闭)可能会发生
std::cout << "Unexpected end of input (this should not happen with stdin)." << std::endl;
break;
} else {
// read返回-1且errno被设置时表示发生错误
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 这是非阻塞模式下期望的行为,表示没有数据可读
std::cout << "No data available. Waiting...\n";
sleep(1); // 等待一秒后再次尝试
} else {
// 处理其他类型的错误
std::cerr << "Error reading input: " << strerror(errno) << std::endl;
break;
}
}
}
return 0;
}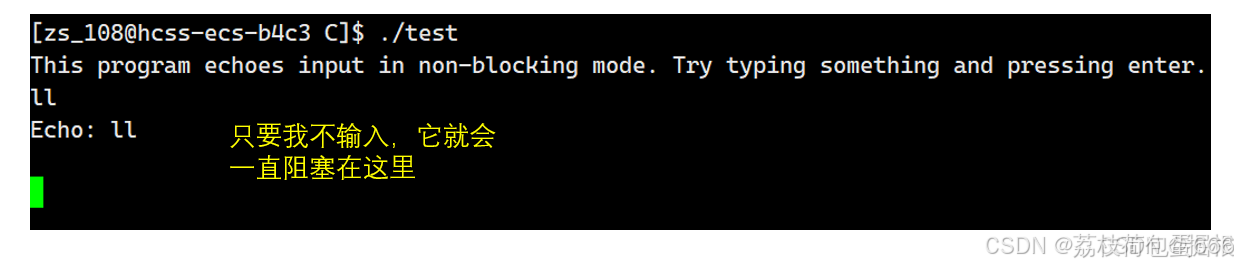
我们看到它阻塞了。
接下来我将使用fcntl函数来将fd的属性改为非阻塞
#include <iostream>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
/**
* 将指定的文件描述符设置为非阻塞模式。
*
* @param fd 需要设置为非阻塞模式的文件描述符。
*/
void set_no_block(int fd) {
// 尝试获取文件描述符的当前标志(flags)
int flags = fcntl(fd, F_GETFL, 0);
// 检查fcntl调用是否失败
if (flags == -1) {
// 如果失败,则打印错误消息并返回
perror("fcntl"); // 使用perror打印错误信息,它会自动添加"fcntl: "前缀
return;
}
// 使用OR操作将O_NONBLOCK标志添加到现有的flags中
// 这样做的目的是保留文件描述符的其他标志不变,只添加非阻塞特性
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
// 注意:这里没有检查fcntl的返回值,因为即使设置失败,也可能不会立即影响程序的行为
// 在实际使用中,可能需要根据需要添加错误处理逻辑
}
int main() {
std::cout << "This program echoes input in non-blocking mode. Try typing something and pressing enter.\n";
// 将标准输入设置为非阻塞模式
set_no_block(STDIN_FILENO); // 使用STDIN_FILENO代替0,更具可读性
char buffer[100];
while (true) {
ssize_t bytes_read = read(STDIN_FILENO, buffer, sizeof(buffer) - 1);
if (bytes_read > 0) {
buffer[bytes_read] = '\0'; // 确保字符串以null字符结束
std::cout << "Echo: " << buffer << std::endl;
} else if (bytes_read == 0) {
// 对于文件描述符如stdin,read返回0通常不表示结束,但在某些特殊情况下(如管道关闭)可能会发生
std::cout << "Unexpected end of input (this should not happen with stdin)." << std::endl;
break;
} else {
// read返回-1且errno被设置时表示发生错误
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 这是非阻塞模式下期望的行为,表示没有数据可读
std::cout << "No data available. Waiting...\n";
sleep(1); // 等待一秒后再次尝试
} else {
// 处理其他类型的错误
std::cerr << "Error reading input: " << strerror(errno) << std::endl;
break;
}
}
}
return 0;
}注意:
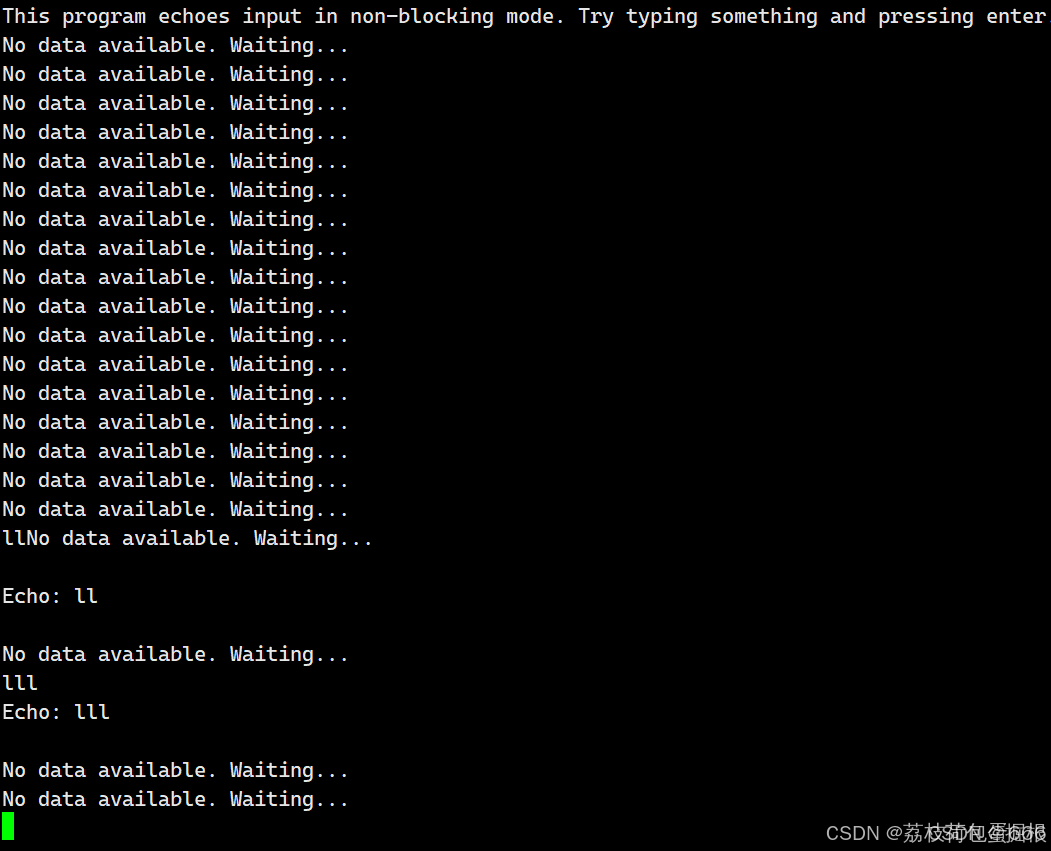
F_GETFL操作用于获取文件描述符的当前标志,这些标志包括文件的访问模式(如只读、只写、读写)和文件状态标志(如同步、异步、非阻塞等)。F_SETFL操作用于设置文件描述符的标志。O_NONBLOCK是一个标志,用于指示文件描述符应处于非阻塞模式。在非阻塞模式下,如果操作(如读取或写入)不能立即完成,则调用将返回一个错误,而不是阻塞等待操作完成。这对于需要处理多个输入源或避免阻塞的应用程序非常有用。- 先通过F_GETFL选项获取原有文件描述符的标志位,然后再通过F_SETFL选项将原有的标志位与O_NONBLOCK按位或之后,再重新设置回文件中。这样就可以将文件描述符设置为非阻塞了。
- 非阻塞IO时,read的返回结果是-1,这样合理吗?
当在非阻塞模式下调用
read函数,并且底层没有数据时,read会返回-1,并设置errno为EAGAIN或EWOULDBLOCK(这两个错误码在大多数系统上可互换,表示资源暂时不可用)。这是非阻塞IO的一种标准行为,用于告诉调用者当前没有数据可读,而不是表示read函数本身出现了错误。底层没有数据,这算错误吗?其实这并不算错误,只不过当底层没有数据时,read以错误的方式返回了,但我们该如何区分read接口是真的调用失败了(比如read读取了一个不存在的fd),还是仅仅底层没有数据罢了,当然通过read的返回值我们是无法区分的,因为read在这两种情况下都返回-1,但可以通过错误码来区分,当非阻塞IO返回时,如果是底层没有数据,错误码会是EWOULDBLOCK或EAGAIN,如果read是真的出错调用了,会有相对应的错误码。
因此,在处理非阻塞IO时,一种常见的做法是在read返回-1时检查errno,并根据errno的值来决定下一步的操作。如果errno表示资源暂时不可用(EAGAIN或EWOULDBLOCK),则程序可能会选择等待一段时间后再次尝试读取,或者执行其他任务。如果errno表示真正的错误(如EBADF),则程序应该采取适当的错误处理措施。
在Linux系统中,
EAGAIN和EWOULDBLOCK是两个常见的错误码,它们通常用于指示资源暂时不可用的情况。具体来说:1.EAGAIN:这个错误码代表“Try again”(再试一次),意味着请求的操作暂时无法完成,但之后可能会成功。在网络编程中,EAGAIN经常出现在非阻塞套接字的读写操作中,表示暂时没有数据可读或数据无法立即写入。在文件操作中,如果文件描述符被设置为非阻塞模式,并且请求的操作不能立即完成(例如,读取时文件指针已经到达文件末尾,或者写入时磁盘空间不足但系统决定不等待),那么也会返回EAGAIN。
2.EWOULDBLOCK:这个错误码在某些情况下与EAGAIN可互换,同样表示资源暂时不可用。然而,在某些系统或特定的上下文中,EWOULDBLOCK可能更具体地用于指示某个操作被阻塞了,因为它会等待某个条件(如数据到达)变为真,但在非阻塞模式下,这个等待被阻止了。在大多数情况下,EAGAIN和EWOULDBLOCK可以视为同义词,尤其是在处理非阻塞I/O时。
怎么样?是不是很神奇?
五,select函数
我们今天要讲的select,select的原理就像下面的赵六一样。
赵六去钓鱼,他是个小土豪,赵六手里拿了一堆鱼竿,目测有几百根鱼竿,赵六到达河边,首先就把几百根鱼竿每隔几米插上去,总共插了好几百米的鱼竿,然后赵六就依次遍历这些鱼竿,哪个鱼竿上的鱼漂动了,赵六就把这根鱼竿上的鱼钓上来,然后接下来赵六就又继续重复之前遍历鱼竿的动作进行钓鱼了。
select是我们学习的第一个多路转接IO接口,我们知道IO是由等待和拷贝两部分组成的。select只负责IO过程中等待的这一步,也就是说,用户可能关心一些sock上的读事件,想要从sock中读取数据,直接读取,可能recv调用会阻塞,等待数据到来,而此时服务器进程就会被阻塞挂起,但服务器挂起就完蛋了,服务器就无法给客户提供服务,可能会产生很多无法预料的不好影响,万一客户正转账呢,服务器突然挂起了,客户的钱没了,但商家这里又没有收到钱,客户找谁说理去啊,所以服务器挂起是一个问题,我们要避免产生这样的问题。
select函数是I/O多路复用的经典实现,其基本原型如下: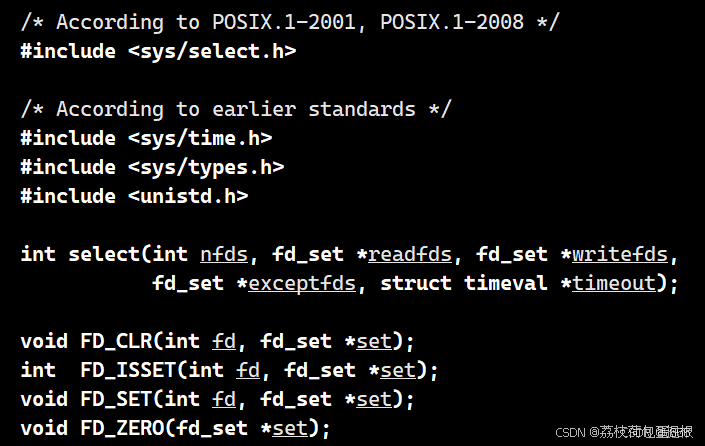
select函数的功能
select的作用就是帮用户关心sock上的读事件,等sock中有数据时,select此时会返回,告知用户你所关心的sock上的读事件已经就绪了,用户你可以调用recv读取sock中的数据了!所以多路转接其实是把IO的过程分开来执行了,用多路复用接口来监视fd上的事件是否就绪,一旦就绪就会立马通知上层,让上层调用对应的接口进行数据的处理,等待和数据拷贝的工作分开执行,这样的IO效率一定是高的,因为像select这样的多路转接接口,一次能够等待多个fd,在返回时,它可以把多个fd中所有就绪的fd全部返回并通知给上层。
select()函数允许程序监视多个文件描述符,等待所监视的一个或者多个文件描述符变为“准备好”的状态。所谓的”准备好“状态是指:文件描述符不再是阻塞状态,可以用于某类IO操作了,包括可读,可写,发生异常三种。
我们使用select来监视文件描述符时,要向内核传递的信息包括:
- 1、我们要监视的文件描述符个数
- 2、每个文件描述符,我们可以监视它的一种或多种状态,包括:可读,可写,发生异常三种。
- 3、要等待的时间,监视是一个过程,我们希望内核监视多长时间,然后返回给我们监视结果呢?
- 4、监视结果包括:准备好了的文件描述符个数,对于读,写,异常,分别是哪儿个文件描述符准备好了。
参数详解
5.1.参数一:nfds
nfds: 这个参数是监控的文件描述符集合中最大文件描述符的值加1。在使用select函数时,必须确保这个参数正确设置,以便函数能监视所有相关的文件描述符。
比如说我们的文件描述符有0,1,2,3,4,5,如果我们想要监视所有的文件描述符,我们这个nfds参数就该填6,也就是5+1.
当程序运行时,程序其实会在select这里进行等待,遍历一次底层的多个fd,看其中哪个fd就绪了,然后就将就绪的fd返回给上层,select的第一个参数nfds代表监视的fd中最大的fd值+1,其实就是select在底层需要遍历所有监视的fd,而这个nfds参数其实就是告知select底层遍历的范围是多大
5.2.参数二: readfds, writefds, exceptfds
5.2.1.fd_set类型和相关操作宏
fd_set是一个通过位图来管理文件描述符集合的数据结构,它允许高效地测试和修改集合中的成员。
- fd_set类型本质是一个位图,位图的位置 表示 相对应的文件描述符,内容表示该文件描述符是否有效,1代表该位置的文件描述符有效,0则表示该位置的文件描述符无效。
- 如果将文件描述符2,3设置位图当中,则位图表示的是为1100。
- fd_set的上限是1024个文件描述符。
由于文件描述符是整数,且通常范围有限(尤其是在UNIX和类UNIX系统中),因此使用位图来表示它们是一种非常有效的空间和时间优化方法。
- FD_SET(fd, &set):此宏将文件描述符fd添加到set集合中。它实际上是将set中与fd对应的位设置为1。
- FD_CLR(fd, &set):此宏从set集合中移除文件描述符fd。它实际上是将set中与fd对应的位清零。
-
FD_ISSET(fd, &set):此宏检查文件描述符fd是否已经被加入到set集合中。如果set中与fd对应的位为1,则返回非零值(真),否则返回0(假)。
-
FD_ZERO(&set):此宏用于清空set集合中的所有文件描述符,即将集合中的所有位都设置为0。这是在使用set之前的一个好习惯,以确保集合从一个已知的状态开始。
我们看个例子
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/select.h>
#include <sys/types.h>
#include <sys/socket.h>
int main() {
// 假设fd是一个已经打开的文件描述符,这里我们用socket作为示例
int fd = socket(AF_INET, SOCK_STREAM, 0); // 创建一个socket,实际使用中需要设置地址并连接
if (fd == -1) {
perror("socket");
exit(EXIT_FAILURE);
}
// 创建一个文件描述符集合
fd_set readfds;
// 清空集合
FD_ZERO(&readfds);
// 将文件描述符fd添加到集合中
FD_SET(fd, &readfds);
// 假设我们想要等待这个fd变得可读,最长等待时间为5秒
struct timeval tv;
tv.tv_sec = 5; // 秒
tv.tv_usec = 0; // 微秒
// 使用select等待文件描述符变得可读
int ret = select(fd + 1, &readfds, NULL, NULL, &tv);
if (ret == -1) {
perror("select");
close(fd); // 不要忘记关闭文件描述符
exit(EXIT_FAILURE);
} else if (ret == 0) {
printf("Timeout occurred! No data after 5 seconds.\n");
close(fd); // 即使没有数据,也要关闭文件描述符
} else {
// 检查fd是否就绪
if (FD_ISSET(fd, &readfds)) {
printf("Data is available now on fd %d.\n", fd);
// 在这里处理数据,例如使用read()函数读取数据
// 假设处理完数据后,我们不再需要等待这个fd
// 可以在这里调用FD_CLR来从集合中移除它,但在这个简单的例子中我们直接关闭它
close(fd);
}
}
return 0;
}5.2.2.readfds, writefds, exceptfds
这三个参数都是输入输出型参数
readfds, writefds, exceptfds: 这三个参数分别代表读、写和异常监视的文件描述符集合。它们使用fd_set类型表示,这是一种通过位图来管理文件描述符的数据结构
readfds
- readfds:这是一个指向fd_set的指针,用于指定程序关心的、希望进行读操作的文件描述符集合。如果select函数返回时,某个文件描述符在该集合中被标记为就绪(即可以进行无阻塞的读操作),则可以通过FD_ISSET宏来检查。
-
readfds是 等待读事件的文件描述符集合,.如果不关心读事件(缓冲区有数据),则可以传NULL值
-
应用进程和内核都可以设置readfds,应用进程设置readfds是为了通知内核去等待readfds中的文件描述符的读事件,而内核设置readfds是为了告诉应用进程哪些读事件生效

writefds
writefds:同样是一个指向fd_set的指针,但这次它用于指定程序希望进行写操作的文件描述符集合。如果select返回时某个文件描述符在该集合中被标记为就绪(即可以进行无阻塞的写操作),则同样可以通过FD_ISSET宏来检查。
与readfds类似,writefds是等待写事件(缓冲区中是否有空间)的集合,如果不关心写事件,则可以传值NULL。
exceptfds
exceptfds:这个参数也是指向fd_set的指针,用于指定程序希望监视异常条件的文件描述符集合。这里的“异常”通常指的是网络套接字上的带外数据(out-of-band data)到达,或者其他一些非标准的I/O事件。
如果内核等待相应的文件描述符发生异常,则将失败的文件描述符设置进exceptfds中,如果不关心错误事件,可以传值NULL。
使用注意事项
- 在调用select之前,必须正确地使用FD_ZERO、FD_SET、FD_CLR等宏来初始化和修改readfds、writefds、exceptfds这三个集合。
- nfds参数的值应该设置为这三个集合中最大文件描述符值加1,以确保select能够正确地监视所有相关的文件描述符。
- select函数会阻塞调用它的线程(或进程),直到以下条件之一发生:
- 有一个或多个文件描述符在readfds集合中变得可读。
- 有一个或多个文件描述符在writefds集合中变得可写。
- 有一个或多个文件描述符在exceptfds集合中发生了异常条件。
- 超时时间到达(如果timeout参数非NULL且指定了超时时间)。
- select函数返回后,应该使用FD_ISSET宏来检查哪些文件描述符已经就绪,并据此执行相应的I/O操作。
5.2.3.怎么理解 readfds, writefds, exceptfds是输入输出型参数
输入方面:
在调用 select 之前,调用者会设置这三个参数指向的 fd_set 集合,以指定哪些文件描述符(fd)是调用者感兴趣的。具体来说,readfds 集合包含了调用者想要检查是否有数据可读的文件描述符,writefds 集合包含了调用者想要检查是否可以写入数据的文件描述符,而 exceptfds 集合则包含了调用者想要检查是否有异常条件(如带外数据、连接挂断等)的文件描述符。
输出影响方面:
当 select 调用返回时,这三个集合会被 select 函数内部修改,以反映哪些文件描述符在调用期间变得就绪或遇到异常条件。具体来说,如果某个文件描述符在 select 等待期间变得可读、可写或出现异常,那么相应的集合中的该文件描述符的位将被设置(如果它之前没有被设置的话)。但是,这并不意味着 select 在这些集合中添加了新的文件描述符或移除了原有的文件描述符;它只是在修改集合中文件描述符的“就绪”状态位。
5.3.参数三: timeout
5.3.1.timeval结构体
struct timeval 是一个在多种编程环境中,尤其是在 UNIX 和类 UNIX 系统(包括 Linux)的 C 语言标准库中定义的结构体,用于表示时间间隔或时间点。他的定义如下
struct timeval {
long tv_sec; // seconds
long tv_usec; // microseconds
};它通常与需要精确到微秒(microseconds)的时间操作的函数一起使用,比如 select(), gettimeofday(), setitimer(), 和 utimes() 等。
这个结构体包含两个成员:
long tv_sec;:这个成员表示自 Unix 纪元(即 1970 年 1 月 1 日 00:00:00 UTC)以来的秒数。它是一个长整型(long),通常可以存储非常大的数,足以表示从 Unix 纪元到现在的时间(以秒为单位)。
long tv_usec;:这个成员表示秒之后的微秒数。它也是一个长整型(long),但用于存储 0 到 999999 之间的值,表示在 tv_sec 所表示的秒之后,再过去多少微秒。
这两个成员结合起来,就可以精确地表示一个时间点或时间间隔,精确到微秒级别。
例如,如果你想要表示一个从 Unix 纪元开始算起,经过了 123 秒又 456789 微秒的时间点,你可以这样设置 struct timeval 结构体:
struct timeval time;
time.tv_sec = 123;
time.tv_usec = 456789; 这个结构体经常与 gettimeofday() 函数一起使用,以获取当前时间(从 Unix 纪元开始的时间,精确到微秒)。例如:
#include <sys/time.h>
#include <stdio.h>
int main() {
struct timeval now;
gettimeofday(&now, NULL);
printf("Current time: %ld.%06ld\n", now.tv_sec, now.tv_usec);
return 0;
} 这段代码会输出当前的时间,格式为秒数和微秒数(微秒数前面补零至6位)。
5.3.1.timeout参数的设定
这是一个输入型参数!!
- timeout: 这是一个指向timeval结构的指针,该结构用于设定select等待I/O事件的超时时间。结构定义如下:
timeout的设定有三种情况:
1.当timeout为NULL时,select会无限等待,直到至少有一个文件描述符就绪。
fd_set fds; FD_ZERO(&fds); FD_SET(0, &fds); // 假设监听标准输入 int ret = select(1, &fds, NULL, NULL, NULL); // 无限期等待 // 检查ret和fds...2.当timeout设置为0时(即tv_sec和tv_usec都为0),select会立即返回,用于轮询。这个就是非阻塞轮询。
struct timeval tv = {0, 0}; fd_set fds; FD_ZERO(&fds); FD_SET(0, &fds); // 假设监听标准输入 int ret = select(1, &fds, NULL, NULL, &tv); // 立即返回 // 检查ret和fds...3.设置具体的时间,select将等待直到该时间过去或者有文件描述符就绪。
struct timeval tv = {2, 500000}; // 2秒500毫秒 fd_set fds; FD_ZERO(&fds); FD_SET(0, &fds); // 假设监听标准输入 int ret = select(1, &fds, NULL, NULL, &tv); // 等待2.5秒或直到文件描述符就绪 // 检查ret和fds...
5.4.返回值
select函数的返回值有三种可能:
- 大于0:返回值表示就绪的文件描述符数量,即有多少文件描述符已经准备好进行I/O操作。
- 等于0:表示超时,没有文件描述符在指定时间内就绪。
- 小于0:发生错误。错误发生时,应使用perror或strerror函数来获取具体的错误信息。
5.5.select的工作流程
应用进程和内核都需要从readfds和writefds获取信息,其中,内核需要从readfds和writefds知道哪些文件描述符需要等待,应用进程需要从readfds和writefds中知道哪些文件描述符的事件就绪.
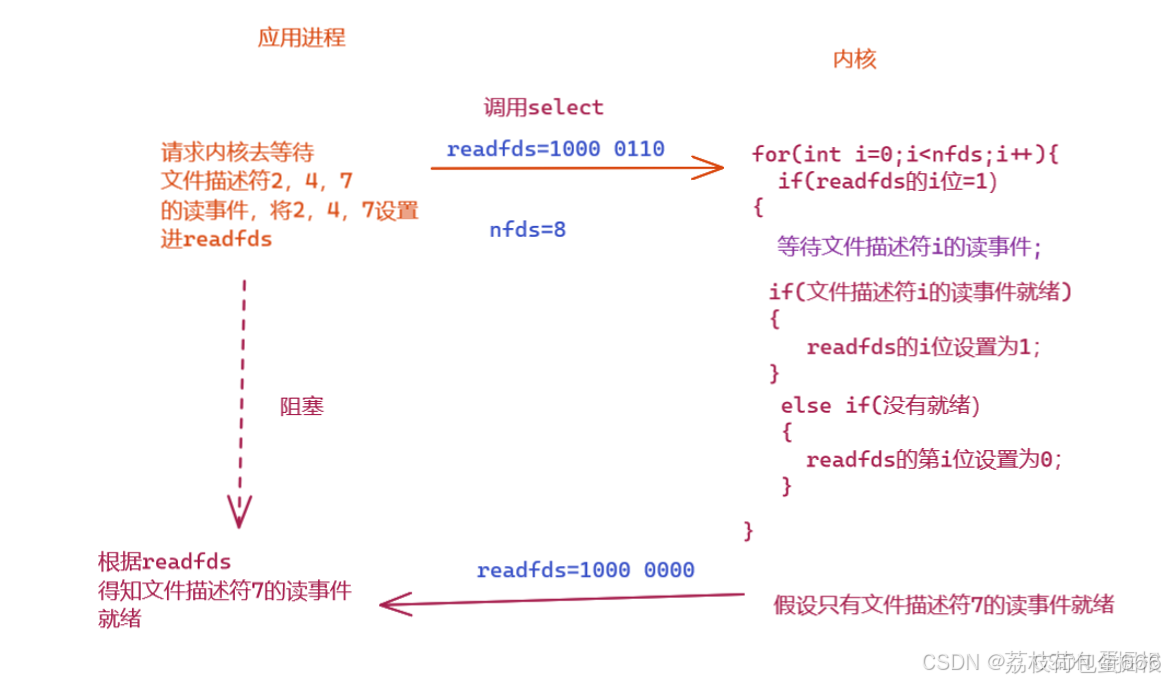
如果我们要不断轮询等待文件描述符,则应用进程需要不断的重新设置readfds和writefds,因为每一次调用select,内核会修改readfds和writefds,所以我们需要在 应用程序 中 设置一个数组 来保存程序需要等待的文件描述符,保证调用 select 的时候readfds 和 writefds中的将如下:
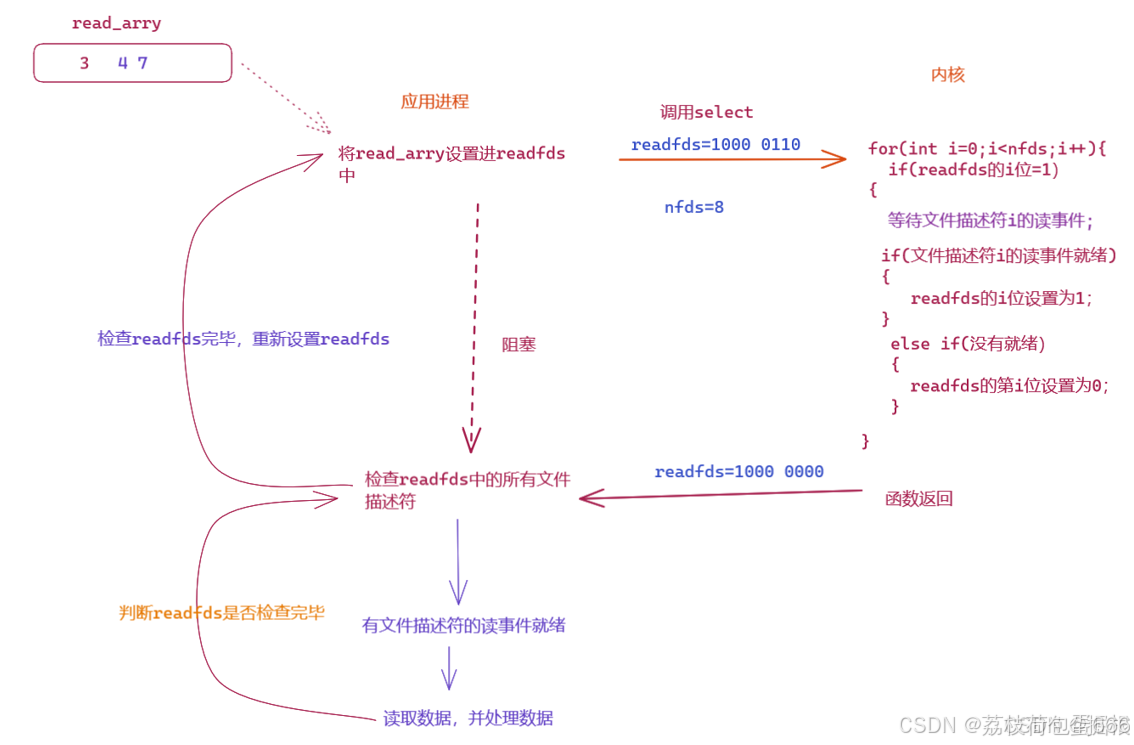
六,select版TCP服务器
接下来我们将用select来重新编写一下我们的TCP服务器。
6.1.编写准备
还记得TCP服务器怎么写吗?
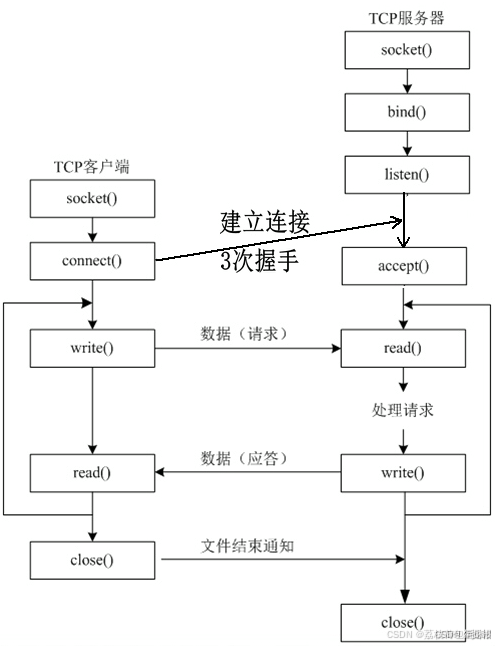
为了节约我们的时间,我们复制一下我们之前封装好的Socket.hpp
Socket.hpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstring>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/in.h>
// 定义一些错误代码
enum
{
SocketErr = 2, // 套接字创建错误
BindErr, // 绑定错误
ListenErr, // 监听错误
};
// 监听队列的长度
const int backlog = 10;
class Sock //服务器专门使用
{
public:
Sock() : sockfd_(-1) // 初始化时,将sockfd_设为-1,表示未初始化的套接字
{
}
~Sock()
{
// 析构函数中可以关闭套接字,但这里选择不在析构函数中关闭,因为有时需要手动管理资源
}
// 创建套接字
void Socket()
{
sockfd_ = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd_ < 0)
{
printf("socket error, %s: %d", strerror(errno), errno); //错误
exit(SocketErr); // 发生错误时退出程序
}
int opt=1;
setsockopt(sockfd_,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt)); //关闭后快速重启
}
// 将套接字绑定到指定的端口上
void Bind(uint16_t port)
{
//让服务器绑定IP地址与端口号
struct sockaddr_in local;
memset(&local, 0, sizeof(local));//清零
local.sin_family = AF_INET; // 网络
local.sin_port = htons(port); // 我设置为默认绑定任意可用IP地址
local.sin_addr.s_addr = INADDR_ANY; // 监听所有可用的网络接口
if (bind(sockfd_, (struct sockaddr *)&local, sizeof(local)) < 0) //让自己绑定别人
{
printf("bind error, %s: %d", strerror(errno), errno);
exit(BindErr);
}
}
// 监听端口上的连接请求
void Listen()
{
if (listen(sockfd_, backlog) < 0)
{
printf("listen error, %s: %d", strerror(errno), errno);
exit(ListenErr);
}
}
// 接受一个连接请求
int Accept(std::string *clientip, uint16_t *clientport)
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int newfd = accept(sockfd_, (struct sockaddr*)&peer, &len);
if(newfd < 0)
{
printf("accept error, %s: %d", strerror(errno), errno);
return -1;
}
char ipstr[64];
inet_ntop(AF_INET, &peer.sin_addr, ipstr, sizeof(ipstr));
*clientip = ipstr;
*clientport = ntohs(peer.sin_port);
return newfd; // 返回新的套接字文件描述符
}
// 连接到指定的IP和端口——客户端才会用的
bool Connect(const std::string &ip, const uint16_t &port)
{
struct sockaddr_in peer;//服务器的信息
memset(&peer, 0, sizeof(peer));
peer.sin_family = AF_INET;
peer.sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &(peer.sin_addr));
int n = connect(sockfd_, (struct sockaddr*)&peer, sizeof(peer));
if(n == -1)
{
std::cerr << "connect to " << ip << ":" << port << " error" << std::endl;
return false;
}
return true;
}
// 关闭套接字
void Close()
{
close(sockfd_);
}
// 获取套接字的文件描述符
int Fd()
{
return sockfd_;
}
private:
int sockfd_; // 套接字文件描述符
};首先我们要创建一个SelectServer.hpp,main.cc,makefile
makefile
select_server:main.cc
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -rf select_serverSelectServer.hpp
#pragma once
#include<iostream>
#include"Socket.hpp"
const uint16_t default_port = 8877; // 默认端口号
const std::string default_ip = "0.0.0.0"; // 默认IP
class SelectServer
{
public:
SelectServer(const uint16_t port = default_port, const std::string ip = default_ip)
: ip_(ip), port_(port)
{
}
~SelectServer()
{
listensock_.Close();
}
bool Init()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
return true;
}
void Start()
{
}
private:
uint16_t port_;//绑定的端口号
Sock listensock_;//专门用来listen的
std::string ip_; // ip地址
};main.cc
#include"SelectServer.hpp"
#include<memory>
int main()
{
std::unique_ptr<SelectServer> svr(new SelectServer());
svr->Init();
svr->Start();
}6.2.SelectServer.hpp的编写
接下来我们就只剩下
class SelectServer{
void Start()
{
}
};没有编写了。
我们可以看看我们之前编写的TCP服务器是怎么编写的。
void Start()
{
while(true)
{
std::string clientip;
uint16_t clientport;
int sockfd=listensock_.Accept(&clientip,&clientport);//这里会返回一个新的套接字
if(socket<0)
continue;
//提供服务
if(fork()==0)
{
listensock_.Close();
//通过sockfd使用提供服务
std::string inbuf;
while (1)
{
char buf[1024];
// 1.读取客户端发送的信息
ssize_t s = read(sockfd, buf, sizeof(buf) - 1);
if (s == 0)
{ // s == 0代表对方发送了空消息,视作客户端主动退出
printf("client quit: %s[%d]", clientip.c_str(), clientport);
break;
}
else if (s < 0)
{
// 出现了读取错误,打印错误后断开连接
printf("read err: %s[%d] = %s", clientip.c_str(), clientport, strerror(errno));
break;
}
else // 2.读取成功
{
}
}
exit(0);//子进程退出
}
close(sockfd);//
}
}我们发现,我们首先进行的就是accept啊!!那我们这里能不能里面进行accept呢?答案是不能的。accept本质就是检测并建立listen上面有没有新连接的到来。
还记得我们最开始讲的例子吗?
赵六去钓鱼,他是个小土豪,赵六手里拿了一堆鱼竿,目测有几百根鱼竿,赵六到达河边,首先就把几百根鱼竿每隔几米插上去,总共插了好几百米的鱼竿,然后赵六就依次遍历这些鱼竿,哪个鱼竿上的鱼漂动了,赵六就把这根鱼竿上的鱼钓上来,然后接下来赵六就又继续重复之前遍历鱼竿的动作进行钓鱼了。
这个新链接就是鱼啊!!!新连接的到来就相当于鱼咬钩了。所以我们处理新连接的时候就得采用IO多路复用思想。
如果是一个select服务器进程,则服务器进程会不断的接收有新链接,每个链接对应一个文件描述符,如果想要我们的服务器能够同时等待多个链接的数据的到来,我们监听套接字listen_sock读取新链接的时候,我们需要将新链接的文件描述符保存到read_arrys数组中,下次轮询检测的就会将新链接的文件描述符设置进readfds中,如果有链接关闭,则将相对应的文件描述符从read_arrys数组中拿走。
一张图看懂select服务器: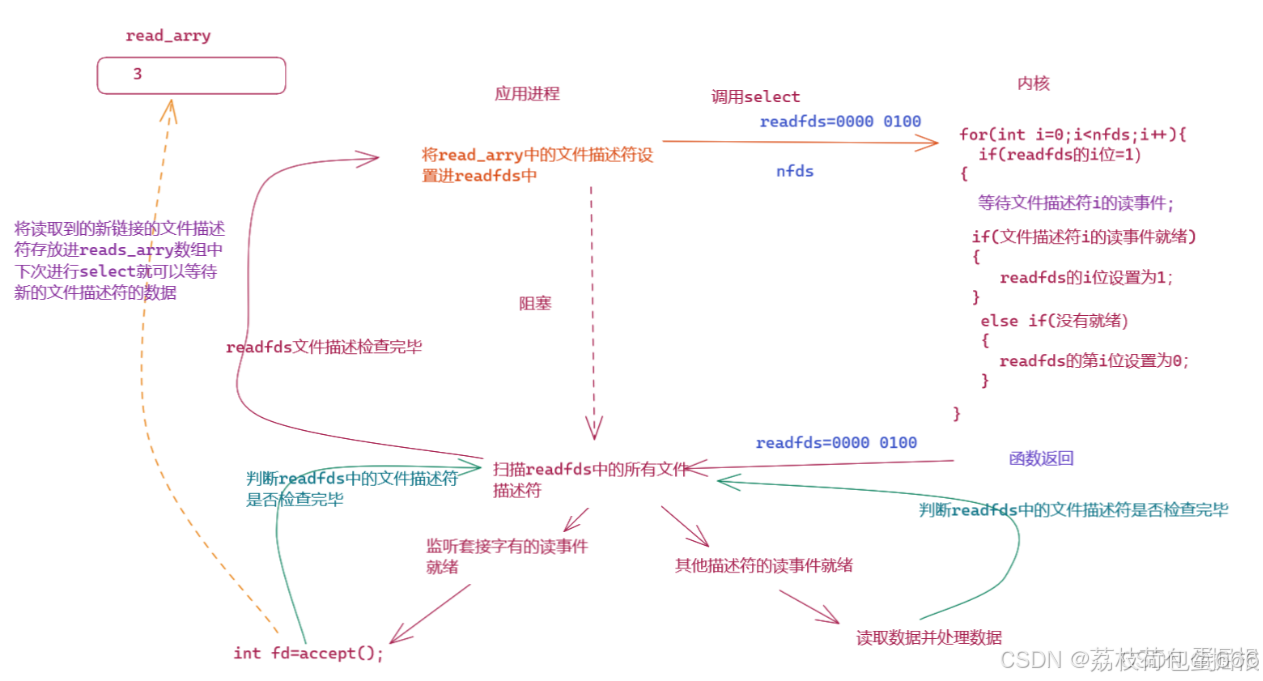
按照上面的思路,我们暂且写出了下面这个
SelectServer.hpp
#pragma once
#include<iostream>
#include"Socket.hpp"
#include<sys/select.h>
#include<sys/time.h>
const uint16_t default_port = 8877; // 默认端口号
const std::string default_ip = "0.0.0.0"; // 默认IP
class SelectServer
{
public:
SelectServer(const uint16_t port = default_port, const std::string ip = default_ip)
: ip_(ip), port_(port)
{
}
~SelectServer()
{
listensock_.Close();
}
bool Init()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
return true;
}
void Start()
{
int listensock=listensock_.Fd();
struct timeval timeout ={5,0};
for(;;)
{
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(listensock,&rfds);
int n=select(listensock+1,&rfds,NULL,NULL,&timeout);//刚开始的时候只有1个连接啊!!!
switch(n)
{
case 0:
std::cout<<"time out"<<std::endl;
break;
case -1:
std::cout<<"select error"<<std::endl;
break;
default:
//有事件就绪
break;
}
}
}
private:
uint16_t port_;//绑定的端口号
Sock listensock_;//专门用来listen的
std::string ip_; // ip地址
};这里需要补充一些知识:
当一个新的连接请求到达监听套接字时,操作系统会接受这个请求(但不在用户空间的应用程序中立即处理它),并将监听套接字的状态标记为可读。这是因为从技术上讲,新的连接请求会导致监听套接字上有一些数据可读——具体来说,是新的连接的信息(例如,客户端的地址和端口号),这些信息将用于后续的 accept 调用。
当一个新的连接请求到达监听套接字时,操作系统会在底层进行一系列的操作来处理这个请求,并使得在用户空间的应用程序能够检测到这个新连接的存在。这个过程涉及到TCP/IP协议栈的多个层次,但我们可以从高层角度来简化地理解它。
- 监听套接字上的“可读”数据
当应用程序通过
listen函数将套接字设置为监听状态时,它实际上是在告诉操作系统:“我准备好了,可以开始接受来自这个套接字的新连接了。”但是,listen函数本身并不涉及任何阻塞操作,它只是改变了套接字的状态。现在,当一个新的TCP连接请求(通常来自客户端的
connect调用)到达时,操作系统会检查是否有相应的监听套接字在监听这个端口。如果有,操作系统会为该新连接创建一个新的套接字(通常称为“已连接套接字”或“子套接字”),并保存与该连接相关的所有信息,包括客户端的地址和端口号。然而,从用户空间的应用程序角度来看,这个新创建的套接字并不是直接可见的。相反,监听套接字上的“可读”状态会被触发,以指示有新的连接请求到来。这里的“可读”状态并不是说监听套接字本身有任何用户数据可读(尽管在某些上下文中,套接字被视为文件描述符,可以像文件一样读取数据),而是说它现在“准备好”被accept调用以接收新的连接。
- accept 调用
当
select或类似的多路复用函数(如poll或epoll)指示监听套接字上有数据可读时,应用程序就会知道有一个或多个新的连接请求正在等待被接受。此时,应用程序可以调用accept函数来尝试接受这些连接。accept函数会从监听套接字的“等待队列”中取出一个新的连接请求,并基于这个请求创建一个新的套接字(即已连接套接字)。这个新套接字包含了与客户端通信所需的所有信息,包括客户端的地址和端口号。然后,accept将这个新套接字的文件描述符返回给应用程序,以便它可以与客户端进行数据传输。
- 总结
因此,从技术上讲,监听套接字上的“可读”状态并不是指套接字上有实际的数据可读,而是指有新的连接请求等待被
accept函数处理。这种机制允许应用程序在多个连接请求同时到达时有效地管理它们,而无需为每个连接都创建一个单独的线程或进程。
我们编译运行一下
我们看看
我们回去再看看我们运行情况 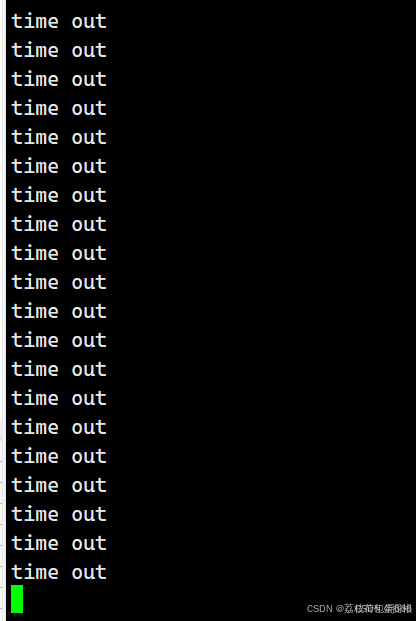
嗯?什么情况?为什么一直在打印time out?这个是因为timeout参数是个输入输出型参数
- 事实上,select函数后四个参数全部是输入输出型参数,兼具用户告诉内核 和 内核告诉用户消息的作用,
比如timeout参数,输入时,代表用户告知内核select监视等待fd时的方式,nullptr代表select阻塞等待fd就绪,当有fd就绪时,select才会返回,传0代表非阻塞等待fd就绪,即select只会遍历检测一遍底层的fd,不管有没有fd就绪,select都会返回,传大于0的值,代表在该时间范围内select阻塞等待,超出该时间select直接非阻塞返回。
假设你输入的timeout参数值为5s,如果在第3时select检测到有fd就绪并且返回时,内核会在select调用内部将timeout的值修改为2s,这就是输出型参数的作用,内核告知用户,timeout值为2s,select等待的时间为3s。
所以对应timeout参数,需要周期性的进行重新设置
我们现在需要修改一下代码
SelectServer.hpp
void Start()
{
int listensock=listensock_.Fd();
for(;;)
{
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(listensock,&rfds);
struct timeval timeout ={5,0};//注意这里
int n=select(listensock+1,&rfds,NULL,NULL,&timeout);//刚开始的时候只有1个连接啊!!!
switch(n)
{
case 0:
std::cout<<"time out"<<std::endl;
break;
case -1:
std::cout<<"select error"<<std::endl;
break;
default:
//有事件就绪
break;
}
}
}现在就不会变了。 一直为5秒了。
我们可以把timeout参数设置为nullptr参数,这样子代表,会一直阻塞到有新连接到来.
SelectServer.hpp
#pragma once
#include<iostream>
#include"Socket.hpp"
#include<sys/select.h>
#include<sys/time.h>
const uint16_t default_port = 8877; // 默认端口号
const std::string default_ip = "0.0.0.0"; // 默认IP
class SelectServer
{
public:
SelectServer(const uint16_t port = default_port, const std::string ip = default_ip)
: ip_(ip), port_(port)
{
}
~SelectServer()
{
listensock_.Close();
}
bool Init()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
return true;
}
void Start()
{
int listensock=listensock_.Fd();
for(;;)
{
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(listensock,&rfds);
int n=select(listensock+1,&rfds,NULL,NULL,nullptr);
switch(n)
{
case 0:
std::cout<<"time out"<<std::endl;
break;
case -1:
std::cout<<"select error"<<std::endl;
break;
default:
//有事件就绪
std::cout<<"get a new link"<<std::endl;
break;
}
}
}
private:
uint16_t port_;//绑定的端口号
Sock listensock_;//专门用来listen的
std::string ip_; // ip地址
};
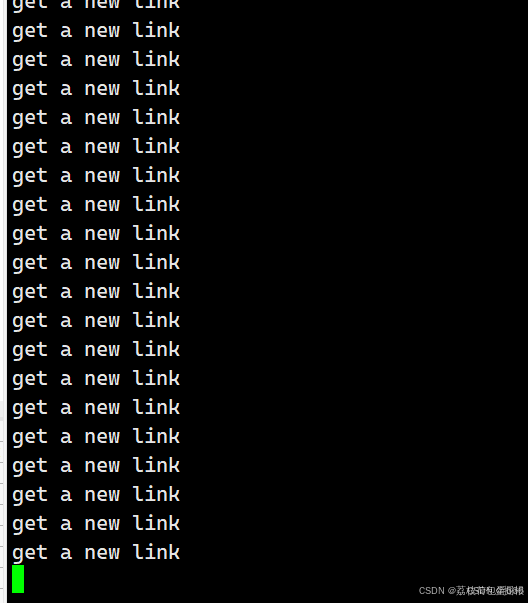
我们发现程序怎么一直打印get a new link啊?这是因为我们没有把连接处理。
其实这个是select的特点:如果事件就绪,上层不处理的话,select会一直通知你!!
如果select告诉我们就绪,接下来的一次读取,我们读取fd的时候,不会被阻塞
接下来我们就要来处理这个连接了!!!
我们需要澄清一些细节,因为
select函数本身并不直接“知道”一个监听套接字(listening socket)何时有新的连接请求。然而,它确实能够检测到在监听套接字上有数据可读,这通常意味着一个新的连接请求已经到达。这里是如何工作的:
监听套接字:当你使用
socket函数创建一个套接字,并用bind和listen函数将它设置为监听状态时,这个套接字就开始等待传入的连接请求(即客户端发起的连接)。但是,listen函数本身并不阻塞,它只是将套接字设置为接受连接请求的状态。使用 select 监视监听套接字:在你的代码中,你将监听套接字的文件描述符
listensock添加到select调用的可读文件描述符集合中。select函数将阻塞(除非指定了超时时间),直到以下任一情况发生:- 可读文件描述符集合中的某个文件描述符变得可读。
- 可写文件描述符集合中的某个文件描述符变得可写(但在这个例子中没有使用)。
- 异常文件描述符集合中的某个文件描述符有异常条件(同样,没有使用)。
- 指定的超时时间到达(如果提供了超时时间)。
新的连接请求:当一个新的连接请求到达监听套接字时,操作系统会接受这个请求(但不在用户空间的应用程序中立即处理它),并将监听套接字的状态标记为可读。这是因为从技术上讲,新的连接请求会导致监听套接字上有一些数据可读——具体来说,是新的连接的信息(例如,客户端的地址和端口号),这些信息将用于后续的 accept 调用。
select 返回:由于监听套接字现在被标记为可读,
select函数会返回,并且返回值会大于 0(表示有文件描述符就绪)。然后,你可以通过FD_ISSET(listensock, &rfds)检查监听套接字是否确实在就绪的文件描述符集合中。接受连接:如果
FD_ISSET(listensock, &rfds)返回真,你就可以使用accept函数来接受这个新的连接请求。accept函数将创建一个新的套接字来与客户端通信,并将监听套接字返回到等待新连接请求的状态。所以,虽然
select函数本身并不“知道”有新的连接请求,但它能够检测到监听套接字上何时有数据可读(这通常意味着有新的连接请求),并允许你的程序在适当的时候调用accept函数来接受这个连接。
为了让代码看起来更好看一点,我们将处理连接这部分封装起来。
void HandlerEvent(fd_set& rfds)
{
// 检查监听套接字是否就绪
if(FD_ISSET(listensock_.Fd(),&rfds))
// 监听套接字上有新的连接请求
// 调用accept来接受连接
{
//我们的连接事件就绪了
std::string clientip;
uint16_t clientport;
int sockfd=listensock_.Accept(&clientip,&clientport);//这里会返回一个新的套接字
//请问进程会阻塞在Accept这里吗?答案是不会的,因为上层的select已经完成的了等待部分,accept只需要完成建立连接即可
if(sockfd<0)
return;
}
}注意:
- FD_ISSET(fd, &set):此宏检查文件描述符fd是否已经被加入到set集合中。如果set中与fd对应的位为1,则返回非零值(真),否则返回0(假)。
现在有一个问题,
我们现在可不可以在后面使用read对socked直接进行读数据呢?
答案是不可以。!!!!!
为什么呢?
因为我们一旦调用read,万一客户端没有发数据过来,服务器进程就会阻塞在read这里!!这样子就会导致HandlerEvent函数调用不会返回,继而导致Start函数的循环阻塞,无法调用select函数监视新加入的连接。
注意:socket函数返回的文件描述符和accept返回的文件描述符是不一样的。
void HandlerEvent(fd_set& rfds) { //1.判断哪个读事件就绪 if(FD_ISSET(listensock_.Fd(),&rfds))// { //我们的连接事件就绪了 std::string clientip; uint16_t clientport; int sockfd=listensock_.Accept(&clientip,&clientport);//这里会返回一个新的套接字 //请问进程会阻塞在Accept这里吗?答案是不会的,因为上层的select已经完成的了等待部分,accept只需要完成建立连接即可 if(sockfd<0) return; std::cout<<"accept's fd:"<<sockfd<<std::endl; } } void Start() { int listensock=listensock_.Fd(); std::cout<<"socket's fd:"<<listensock<<std::endl; for(;;) { fd_set rfds; FD_ZERO(&rfds); FD_SET(listensock,&rfds); int n=select(listensock+1,&rfds,NULL,NULL,nullptr);//注意这里会修改rfds,返回的rfds有效位代表着哪个位置的有效事件就绪了 switch(n) { case 0: std::cout<<"time out"<<std::endl; break; case -1: std::cout<<"select error"<<std::endl; break; default: //有事件就绪 std::cout<<"get a new link"<<std::endl; HandlerEvent(rfds);//处理事件 break; } }我们使用telnet来测试一下
很明显了。
我们发现服务器只有一个文件描述符是来监听新的连接的,接受新连接的时候是会有新的文件描述符用来进行网络通信的
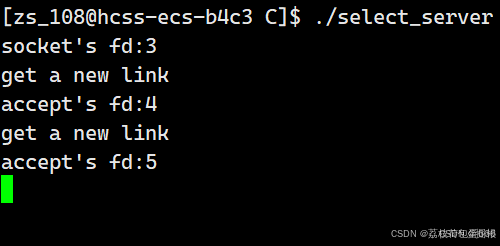
我们发现
所以在accept函数后面我们不能直接调用read函数,而是将新连接加入到select中。
可是我们发现,我们的select和我们的accept在不同的函数里面,我们怎么让select来设置我们的文件描述符呢?这个时候我们就要设置一个辅助数组了。
6.2.1.为什么要设置辅助数组
- 原因一
我们不能在accept这里调用新的select
为什么?
- 一般都是在主循环处持续调用select,高效且简洁
- 如果使用多个select,会导致代码逻辑复杂化,也难以管理
- 所以,需要我们把这个新套接字的fd设置进刚才的select的位图中
- 这一过程就相当于在不断增加自己鱼竿的数量
但是,这两个数据在不同的函数中(我们在处理函数中获取新连接,而select的使用在主逻辑函数中),如何传递呢?
因为这两个函数都在类中,所以我们搞一个类内变量 -- 辅助数组
int fds_[def_max_num]; // 辅助数组这里补充一个知识点:fd_set有多少个比特位
std::cout<<"fd_set:"<<sizeof(fd_set)*8<<std::endl;
于fd_set每个比特位代表一个连接,fd_set有1024位比特位,所以最多可以同时处理1024个连接
- 原因二
我们知道select的rfds参数是个输入输出型参数,而且应用进程和内核都可以设置readfds,应用进程设置readfds是为了通知内核去等待readfds中的文件描述符的读事件,而内核设置readfds是为了告诉应用进程哪些读事件生效,就像下面这样子。
也就是说每调用一次select函数,参数rfds会变化!!!但是再看看我们的代码,我们可是把select放在一个循环里面,这意味着会多次调用select,这样子下去,只有第一次调用select时监听的是我们想要监听的,后续的rfds都变化了,调用select就不是我们想要监听的了!!! 这就意味着,每调用一次select函数,就要重新设定一次rfds参数!!!

- 原因三
我们select函数的第一个参数 nfds: 这个参数是监控的文件描述符集合中最大文件描述符的值加1。可是在我们的代码里面,我们却直接填了一个listensock+1,这就固定死了监听范围,可是我们是写服务器,当新连接到来的时候,会产生新的文件描述符,如果select的第一个参数不变的话,我们就不能监听到这些新的文件描述符了。
所以这个select的第一个参数要通过计算来进行动态设置!!!
我们可以让新增的fd都添加进辅助数组中,然后让select每次动态设置max_fd,以及三个位图(新增操作在"处理函数"中介绍)
可以固定监听套接字(也就是我们创建的第一个套接字)作为数组的第一项,方便我们后续区分[获取新连接] 和 [读写事件]。
因为在过程中,可能会陆陆续续关掉一些文件(断开连接时),所以原本添加进的连续fd,会变成零零星星的,所以需要我们每次都重新整理一下这个数组,把有效的fd统一放在左侧,我们每次在循环开头就处理数组中的值,合法的fd就让它设置进位图中
不仅如此,在这个过程中,我们还可以找到fd中的最大值,来填充select的第一个参数
接下来我们就修改一下Start函数
void Start()
{
int listensock = listensock_.Fd();
fd_arry[0] = listensock; // 将监听套接字加入辅助数组
for (;;)
{
fd_set rfds;//每调用一次select函数rfds需要重新设定
FD_ZERO(&rfds);
int maxfd = fd_arry[0]; // 最大有效数组下标
for (int i = 0; i < fd_num_max; ++i)
{
if (fd_arry[i] == default_fd)
{
continue;
}
FD_SET(fd_arry[i], &rfds);
//注意辅助数组第一个元素是listen套接字,所以最开始的时候一定会执行到这里
if (maxfd<fd_arry[i])//如果有更大的文件描述符,就替换掉maxfd
{
maxfd = fd_arry[i];
}
}
int n = select(maxfd + 1, &rfds, NULL, NULL, nullptr); // 注意这里会修改rfds,返回的rfds有效位代表着哪个位置的有效事件就绪了
switch (n)
{
case 0:
std::cout << "time out" << std::endl;
break;
case -1:
std::cout << "select error" << std::endl;
break;
default:
// 有事件就绪
std::cout << "get a new link" << std::endl;
HandlerEvent(rfds); // 处理事件
break;
}
}
}接下来需要修改一下我们的HandlerEvent函数,我们accept新连接后不能直接读取,会阻塞,我们需要将这个新连接加入我们的select函数的范围,这就需要我们借助辅助数组了
当我们识别到有事件就绪,获取连接后获得新套接字fd,之后就该将该fd设置进辅助数组中了
- 需要我们遍历数组,找到空位(值为-1/其他你设定的[数组内的初始值]),然后添加进去
- 但是要注意位图还有没有空位置(别忘了位图是有上限的)
- 所以,还需要加个判断
HandlerEvent函数
void HandlerEvent(fd_set &rfds)
{
// 1.判断哪个读事件就绪
if (FD_ISSET(listensock_.Fd(), &rfds)) //
{
// 我们的连接事件就绪了
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport); // 这里会返回一个新的套接字
// 请问进程会阻塞在Accept这里吗?答案是不会的,因为上层的select已经完成的了等待部分,accept只需要完成建立连接即可
if (sockfd <0)
return;
else // 把新fd加入位图
{
int i = 1;
for (; i < fd_num_max; i++)//为什么从1开始,因为我们0号下标对应的是listen套接字,我们不要修改
{
if (fd_arry[i] !=default_fd ) // 没找到空位
{
continue;;
}
else{//找到空位,但不能直接添加
break;
}
}
if (i != fd_num_max)//没有满
{
fd_arry[i] = sockfd;//把新连接加入数组
}
else // 满了
{
close(sockfd);//处理不了了,直接关闭连接吧
}
}
}
}一旦有新连接的到来,我们就是只先把连接放到辅助数组里面。
为了方便大家观察,我们写一个测试函数
void Printfd() { std::cout<<"online fd list: "; for(int i=0;i<fd_num_max;i++) { if(fd_arry[i]==default_fd) continue; std::cout<<fd_arry[i]<<" "; } std::cout<<std::endl; }
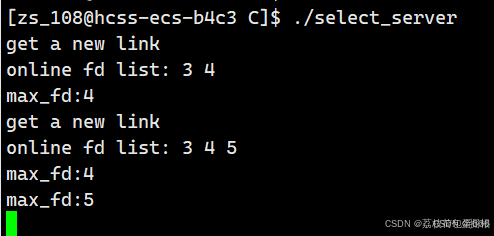
大家有没有发现,这个辅助数组里面的事件有两类啊!!!!就是[新连接]和[读写事件],如何区分fd集上的事件就绪究竟是[新连接]还是[读写事件]呢?
如何区分fd集上的事件就绪究竟是[新连接]还是[读写事件]呢?
- 前面我们提到,将监听套接字固定在数组第一项,就是为了区分两者,所以写个判断语句就行
HandlerEvent函数
void HandlerEvent(fd_set &rfds)
{
for (int n = 0; n < fd_num_max; n++)
{
int fd = fd_arry[n];
if (fd == default_fd) // 无效的
continue;
if (FD_ISSET(fd, &rfds)) // fd套接字就绪了
{
// 1.是listen套接字就绪了
if (fd == listensock_.Fd()) // 如果是listen套接字就绪了!!!
{
// 我们的连接事件就绪了
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport); // 这里会返回一个新的套接字
// 请问进程会阻塞在Accept这里吗?答案是不会的,因为上层的select已经完成的了等待部分,accept只需要完成建立连接即可
if (sockfd < 0)
continue;
else // 把新fd加入位图
{
int i = 1;
for (; i < fd_num_max; i++) // 为什么从1开始,因为我们0号下标对应的是listen套接字,我们不要修改
{
if (fd_arry[i] != default_fd) // 没找到空位
{
continue;
}
else
{ // 找到空位,但不能直接添加
break;
}
}
if (i != fd_num_max) // 没有满
{
fd_arry[i] = sockfd; // 把新连接加入数组
Printfd();
}
else // 满了
{
close(sockfd); // 处理不了了,直接关闭连接吧
}
}
}
// 2.是通信的套接字就绪了,fd不是listen套接字
else // 读事件
{
char in_buff[1024];
int n = read(fd, in_buff, sizeof(in_buff) - 1);
if (n > 0)
{
in_buff[n] = 0;
std::cout << "get message: " << in_buff << std::endl;
}
else if (n == 0) // 客户端关闭连接
{
close(fd);//我服务器也要关闭
fd_arry[n] = default_fd; // 重置数组内的值
}
else
{
close(fd);//我服务器也要关闭
fd_arry[n] = default_fd; // 重置数组内的值
}
}
}
}
}我们做个实验
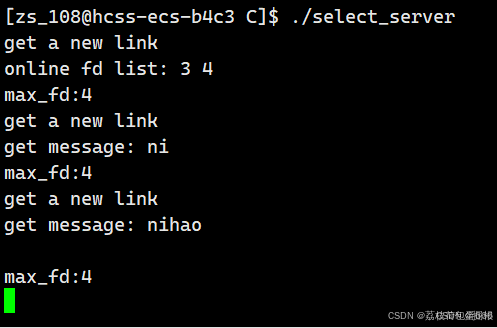
很完美啊
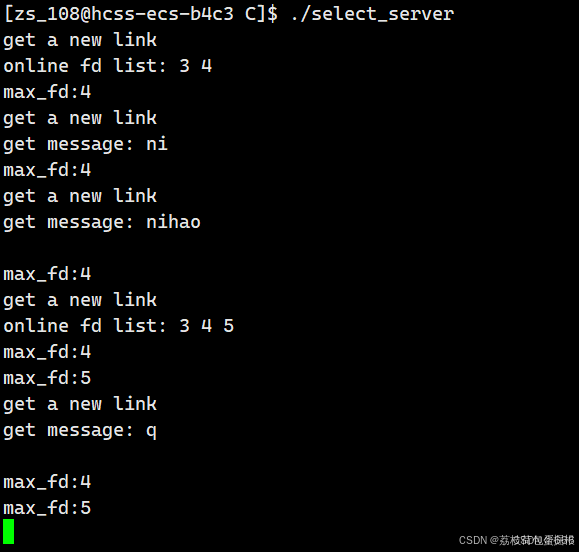
很好!!
我们也可以把处理过程单拎出来封装成两个函数
- 就相当于我们把收到的事件根据类型不同,派发给不同的模块进行处理
HandlerEvent函数
void Accept()
{
// 我们的连接事件就绪了
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport); // 这里会返回一个新的套接字
// 请问进程会阻塞在Accept这里吗?答案是不会的,因为上层的select已经完成的了等待部分,accept只需要完成建立连接即可
if (sockfd < 0)
return;
else // 把新fd加入位图
{
int i = 1;
for (; i < fd_num_max; i++) // 为什么从1开始,因为我们0号下标对应的是listen套接字,我们不要修改
{
if (fd_arry[i] != default_fd) // 没找到空位
{
continue;
}
else
{ // 找到空位,但不能直接添加
break;
}
}
if (i != fd_num_max) // 没有满
{
fd_arry[i] = sockfd; // 把新连接加入数组
Printfd();
}
else // 满了
{
close(sockfd); // 处理不了了,直接关闭连接吧
}
}
}
void Receiver(int fd, int i)
{
char in_buff[1024];
int n = read(fd, in_buff, sizeof(in_buff) - 1);
if (n > 0)
{
in_buff[n] = 0;
std::cout << "get message: " << in_buff << std::endl;
}
else if (n == 0) // 客户端关闭连接
{
close(fd); // 我服务器也要关闭
fd_arry[i] = default_fd; // 重置数组内的值
}
else
{
close(fd); // 我服务器也要关闭
fd_arry[i] = default_fd; // 重置数组内的值
}
}
void HandlerEvent(fd_set &rfds)
{
for (int n = 0; n < fd_num_max; n++)
{
int fd = fd_arry[n];
if (fd == default_fd) // 无效的
continue;
if (FD_ISSET(fd, &rfds)) // fd套接字就绪了
{
// 1.是listen套接字就绪了
if (fd == listensock_.Fd()) // 如果是listen套接字就绪了!!!
{
Accept();
}
// 2.是通信的套接字就绪了,fd不是listen套接字
else // 读事件
{
Receiver(fd,n);
}
}
}
}6.2.2.select的优缺点
select并不是多路转接中好的一个方案,当然这并不代表他是有问题的,只不过他用起来成本较高,要关注的点也比较多,所以我们说他并不是一个好的方案。
总的来说,select最重要的就是思维方式 -- 我们要将所有等待的过程都交给select
并且优缺点很明显
优点
- 确实实现了多路转接,可以等待多个fd
- 代码简单明了
缺点
比如select监视的fd是有上限的,我的云服务器内核版本下最大上限是1024个fd,主要还是因为fd_set他是一个固定大小的位图结构,位图中的数组开辟之后不会在变化了,这是内核的数据结构,除非你修改内核参数,否则不会在变化了,所以一旦select监视的fd数量超过1024,则select会报错。
除此之外,select大部分的参数都是输入输出型参数,用户和内核都会不断的修改这些参数的值,导致每次调用select前,都需要重新设置fd_set位图中的内容,这在用户层面上会带来很多不必要的遍历+拷贝的成本。
同时select还需要借助第三方数组来维护用户需要关心的fd,这也是select使用不方便的一种体现。而上面的这些问题,正是其他多路转接接口所存在的意义,poll解决了很多select接口存在的问题。