Harmon、TokLIP论文解读
目录
一、MAR
2、传统AR
3、MAR方法
4、技术细节
二、Harmon
1、概述
2、方法
3、训练过程
4、实验分析
三、TokLIP
1、概述
2、方法
3、训练过程
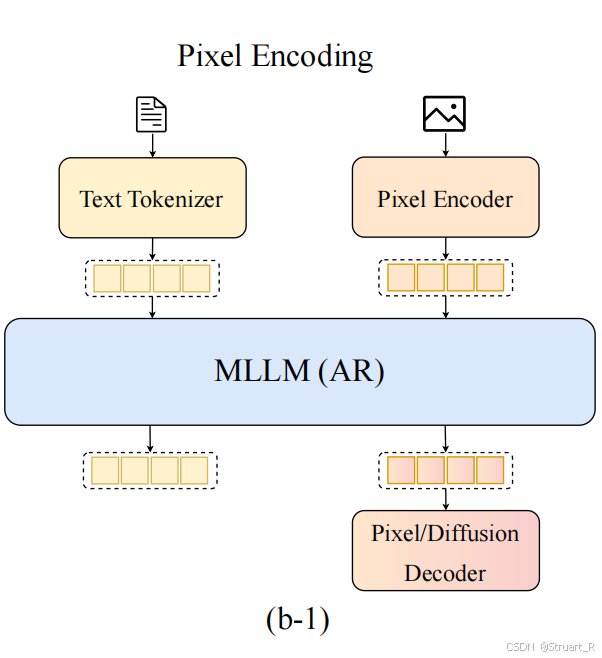
Harmon和TokLIP从整体架构来说,都可以理解为输入文本和Pixel Encoder编码的图像特征到MLLM中最终解码出文本或图像信息。而Harmon是完全摒弃了以往理解和生成解耦的方法,认为MAR编码器兼具语义和全局细节能力,替换了以往的VQGAN作为Visual Encoder。而TokLIP则是依赖CLIP的语义提取能力,对Token ENcoder进行蒸馏,使得一个Pixel Encoder融合高层语义特征。
一、MAR
1、概述
MAR颠覆了自回归生成模型依赖离散token,需要将连续空间特征通过量化方法转为离散特征输入到自回归生成模型的传统认知,通过一种无需向量量化的自回归图像生成方法,利用扩散过程对每个token的概率分布进行建模,避免了向量量化过程中的信息损失问题。
自回归模型与tokens时离散或是连续的无关,只需要对每个token的概率分布进行合理的建模。
2、传统AR
传统自回归模型目的是预测下一个位置的真实token,自回归模型本身则是一个Transformer架构,假设下一个位置预测的真实token为,token的词汇表大小为K,那么自回归模型的输出头将会产生连续的向量
,最后通过Softmax分类器输出K类的概率分布:
而如果我们去除量化操作,输入的就是一组连续浮点向量序列,而为了实现生成式建模,自回归得到的概率分布又必须满足两个属性:
(1)损失函数来估计真实分布与估计分布的差异,离散情况下通过交叉熵损失完成。
(2)采样器,推理时从估计分布中抽取样本,离散情况下通过softmax完成。
在连续值下,真实值是一个连续信息,估计值也是一个连续信息,所以如果再用交叉熵损失,并用softmax回归,缺少类别信息,不能实现,但又不得不需要对每一个token进行建模分布,所以采用了Diffusion loss。
3、MAR方法
DIffusion loss
对比以往自回归模型,假设需要预测下一个位置预测的token,他是一个连续向量,而自回归模型在此位置生成一个向量
,所以我们同样是要得到一个概率分布
,损失函数和采样器可按照扩散模型定义:
其中为采样的噪声向量,满足高斯分布,
为预测的噪声向量,其中噪声预测网络为一个小型的MLP网络,输入
,以
和
为条件。由于MLP网络很小,所以只对t采样4次。
连续采样
推理过程中,需要从预测概率中抽取样本,也就是去噪过程。
其中为高斯分布中采样的噪声,
是时间步t下的噪声级别。
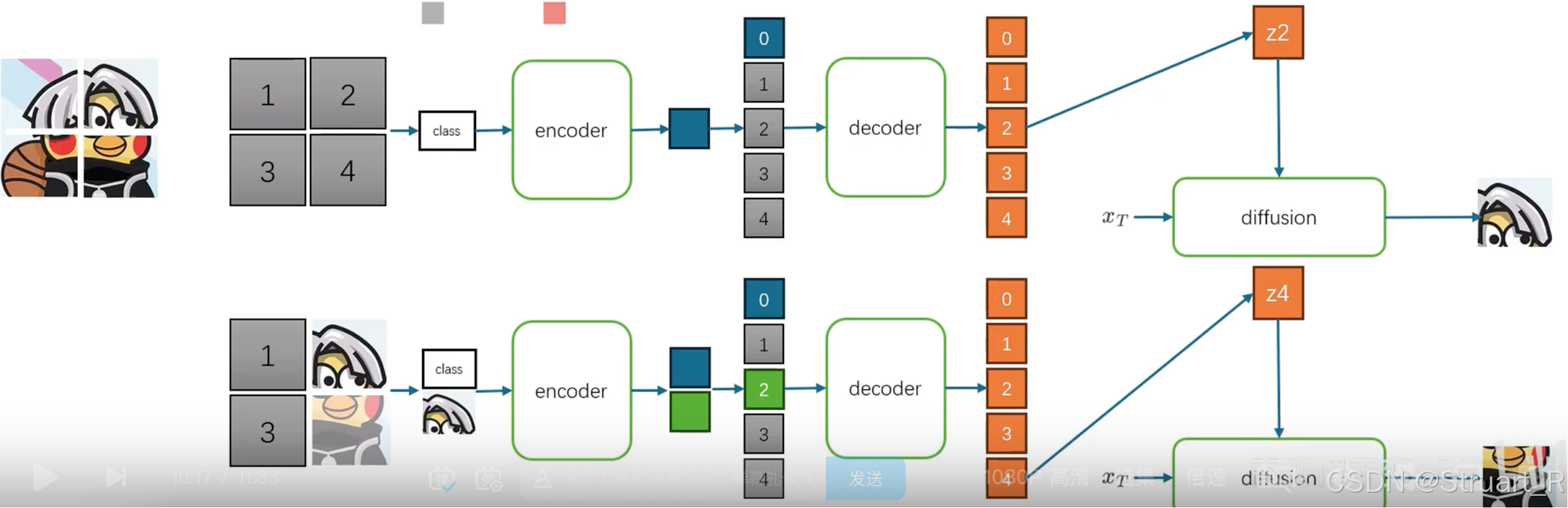
整体推理过程可以参见下图,假设有一个image,先经过分块以及分词器,得到一个连续的序列特征(比如以往每一个patch的特征经过量化输出一个整数,这里就是一个浮点数),但是不作为输入,这个作为GT,初始化为被mask,在后续输入自回归模型后逐渐解除mask。
第一轮,在一个空序列中的开头加一个class信息(在CFG情况下就是拼接一个可学习的token,保证不为空)输入到自回归模型(大Transformer)中,经过encoder后得到一个同样的维度的向量(与class信息的token一致),之后用随机噪声补满mask的信息,经过decoder解码,并随机采样一个token利用扩散损失解码图像。
之后每一轮补充这个解码图像重新进入自回归模型输出新的解码图像。
每一轮不一定只有一个token被预测,这个过程在反向扩散中可以同时采样,并解码多张图片。
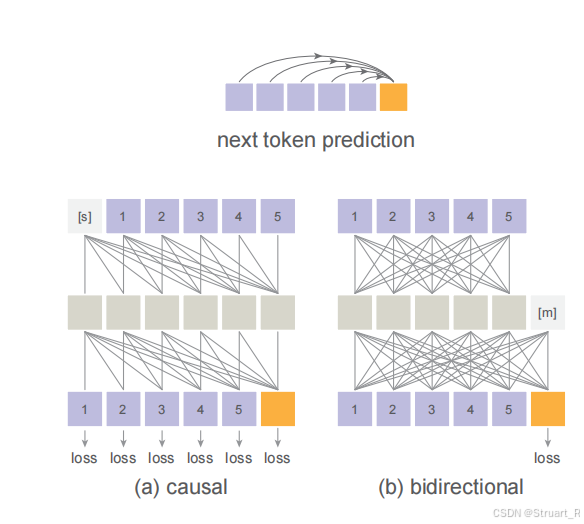
双向注意力机制
以往预测next-token的自回归模型都是基于因果注意力机制,保证给定前n-1个token情况下预测第n个token,而这里采用双向注意力机制,允许所有已知token相互查看token,可以快速预测多个tokens信息。
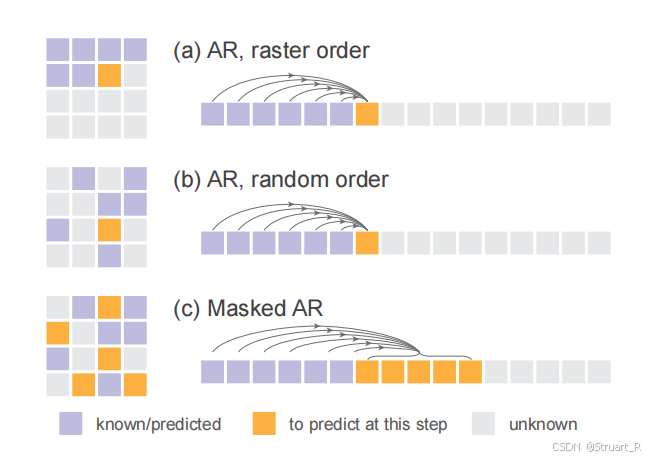
MAR
根据以上的原理,构建了一个Masked Generative Model也就是下图的(c),给定随机的顺序同时预测下一个或下多个tokens。而(a)光栅顺序(b)随机顺序只能一次生成一个token。
4、技术细节
对于图像的分词器部分采用的LDM中的tokenzier,包括KL-16和VQ-16两个版本编码器,扩散MLP采用3层,1024channel的线性层+SiLU+线性层的结构,每层包含LN层。
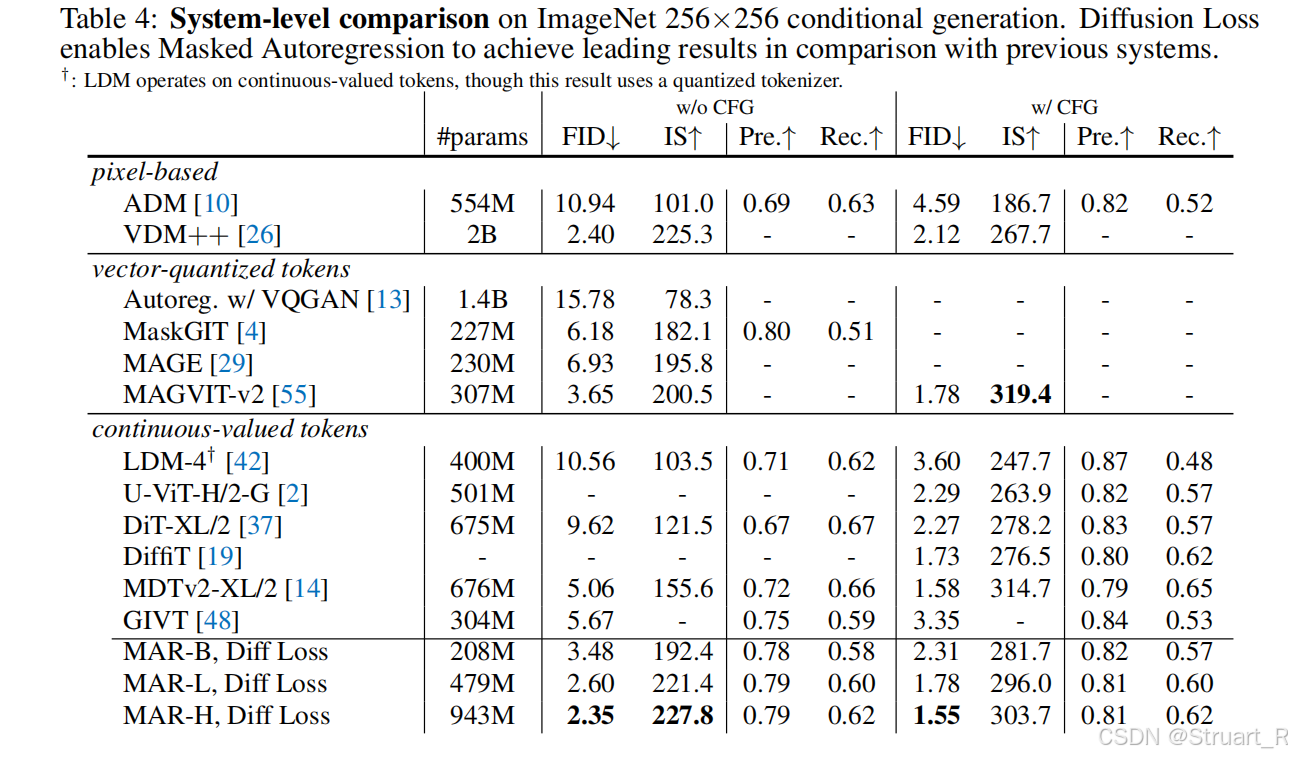
在ImageNet上进行图像生成对比实验。跟MAGVIT-V2性能相近情况下,参数量增长了两倍。
二、Harmon
1、概述
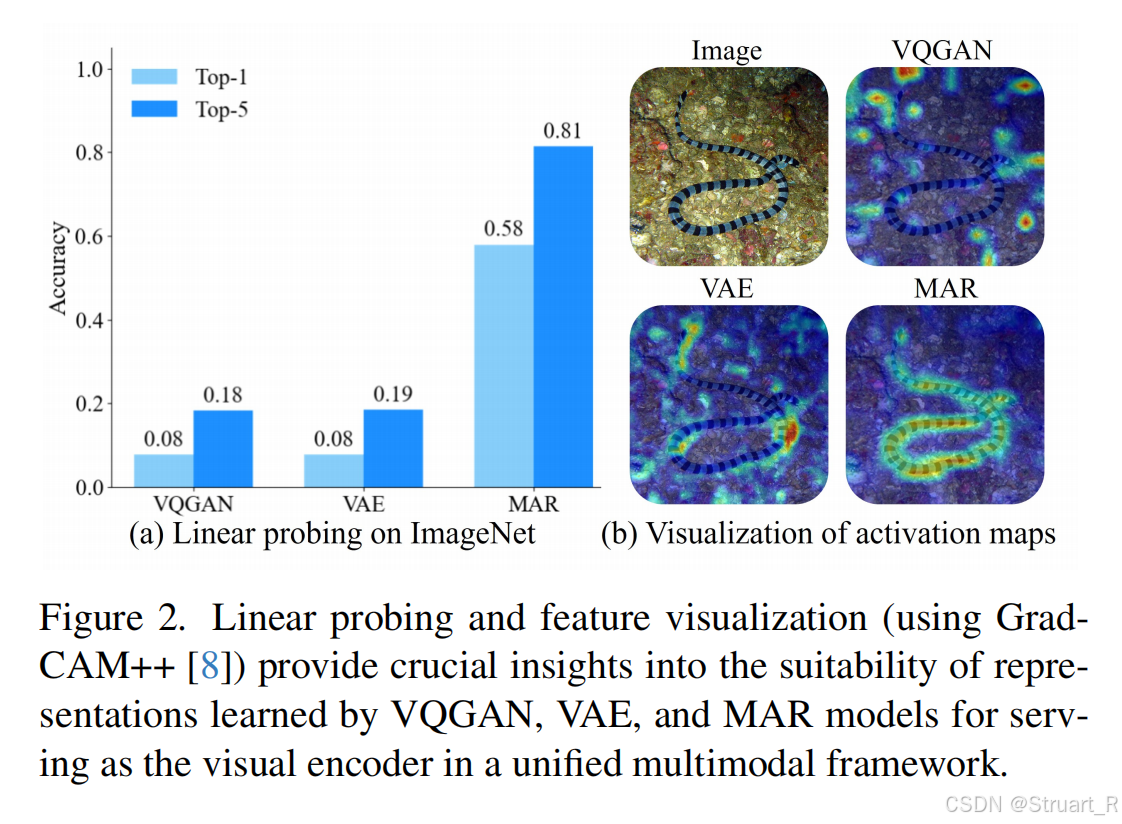
首先受MAR启发,并通过热力图推理,发现MAR作为Encoder进行图像特征提取训练,本身具有很高的语义提取能力,而且远超过VQGAN或VAE。所以提出统一的VIsual Encoder架构,通过共享MAR Encoder同时促进理解和生成。
2、方法
Harmon框架分为图像生成和图像理解两个部分,将生成和理解解耦可以说是2025年的工作的一致操作。
VIsual Encoder
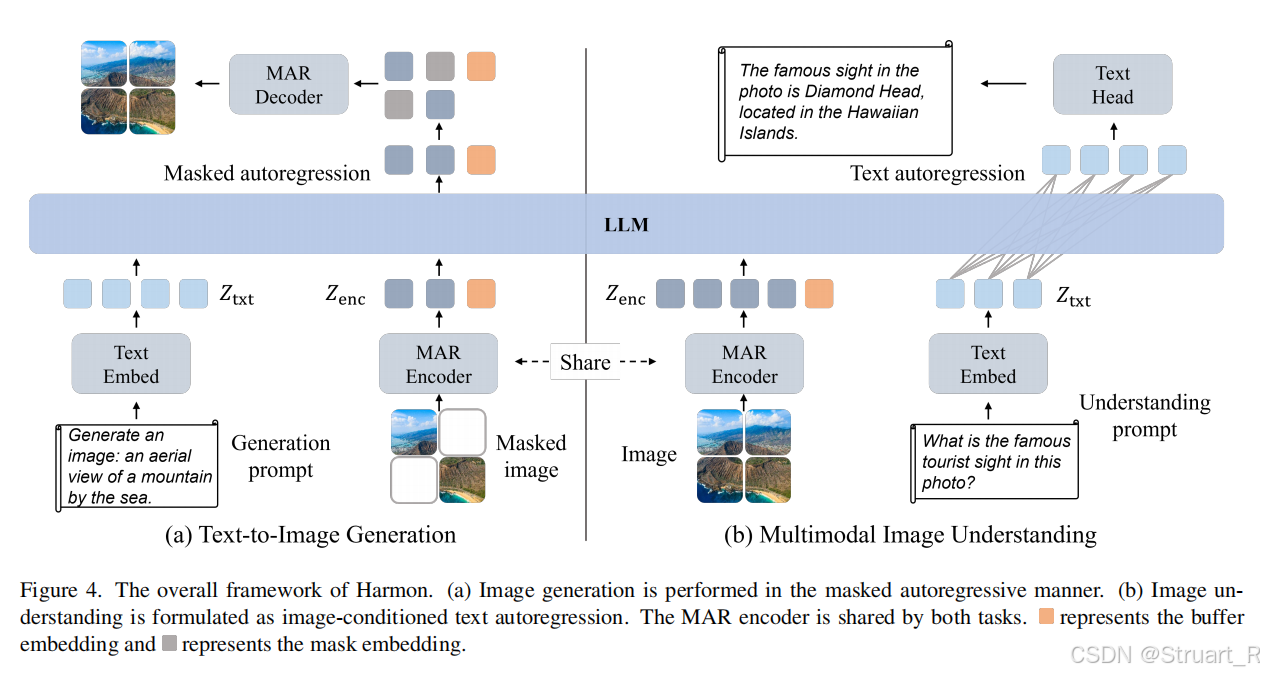
图像生成部分,沿用MAR的掩码建模范式,输入Masked Image,利用MAR Encoder处理可见的图像生成,并经过LLM与Text进行模态交互后,MAR Decoder预测剩余的图像内容。
图像理解部分,直接利用MAR Encoder处理完整图像,LLM根据图像内容和用户指令输出推理文本。
LLM
Qwen2.5输入用于生成描述的文本和推理理解的文本经过分词器得到文本特征与MAR Encoder的特征
拼接,作为LLM的输入。下图中橘色方块为缓冲区,其实就是为了满足next-token预测的。
3、训练过程
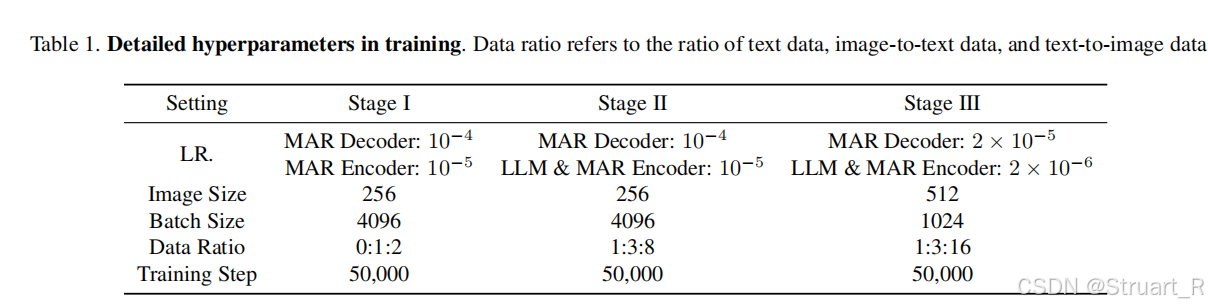
类似以往方法的三阶段训练。
Stage1:对齐MAR和LLM,冻结LLM参数训练MAR Encoder和Decoder,22M图文对+1.2M的ImageNet
Stage2:解冻LLM,引入CFG机制,大规模图文数据训练50M生成数据,25M理解数据
Stage3:分辨率提高256->512,精选10M(50M的20%生成数据)+6M合成数据集用于图文生成,LLaVA-Oneversion用于理解。
4、实验分析
多模态理解上接近Janus-Pro效果。
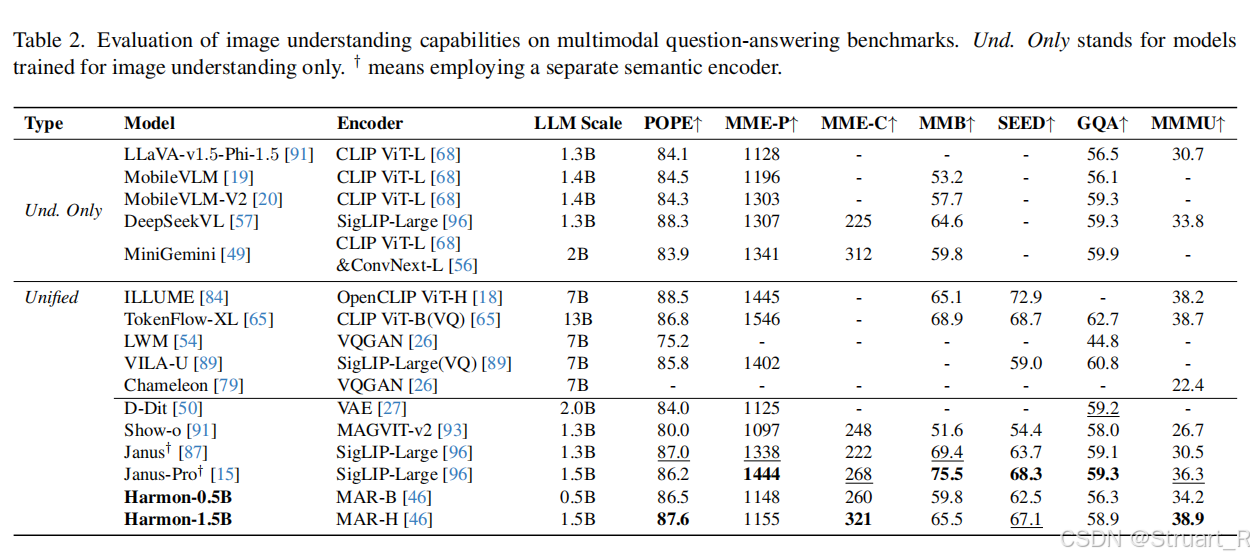
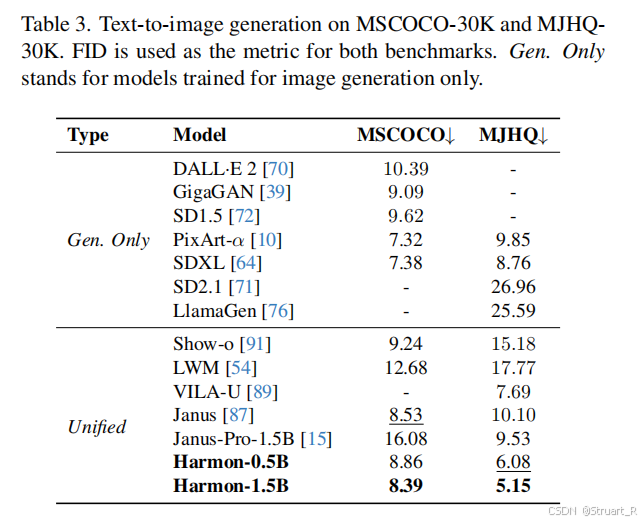
文生图上不仅可以超越以往的统一模型的SOTA,而且在Gen. only 上也可以超过SDXL模型。
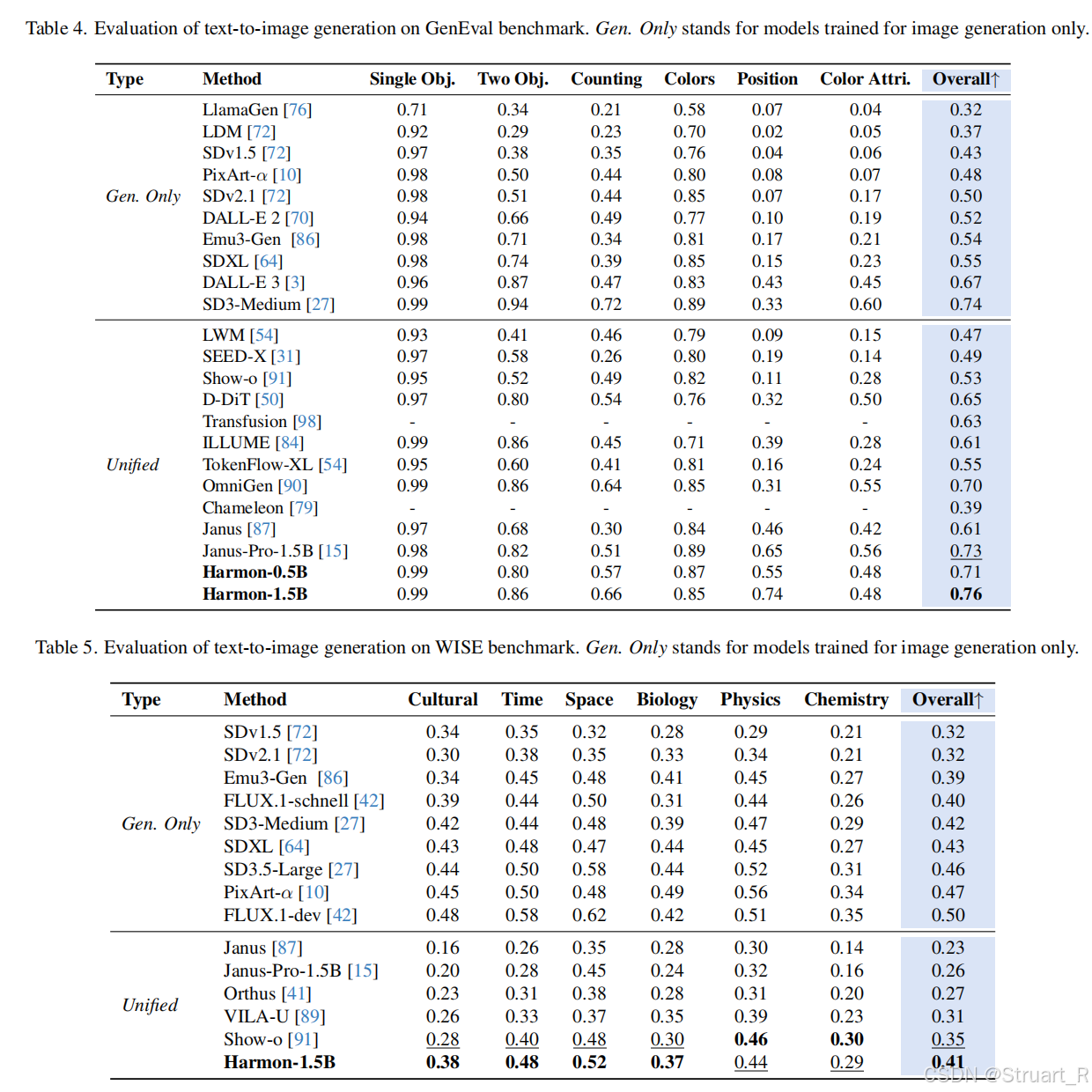
并且在GenEval指标上超过了所有模型成为了SOTA,WISE指标上超过了Janus-pro,show-o这些统一模型。

三、TokLIP
1、概述
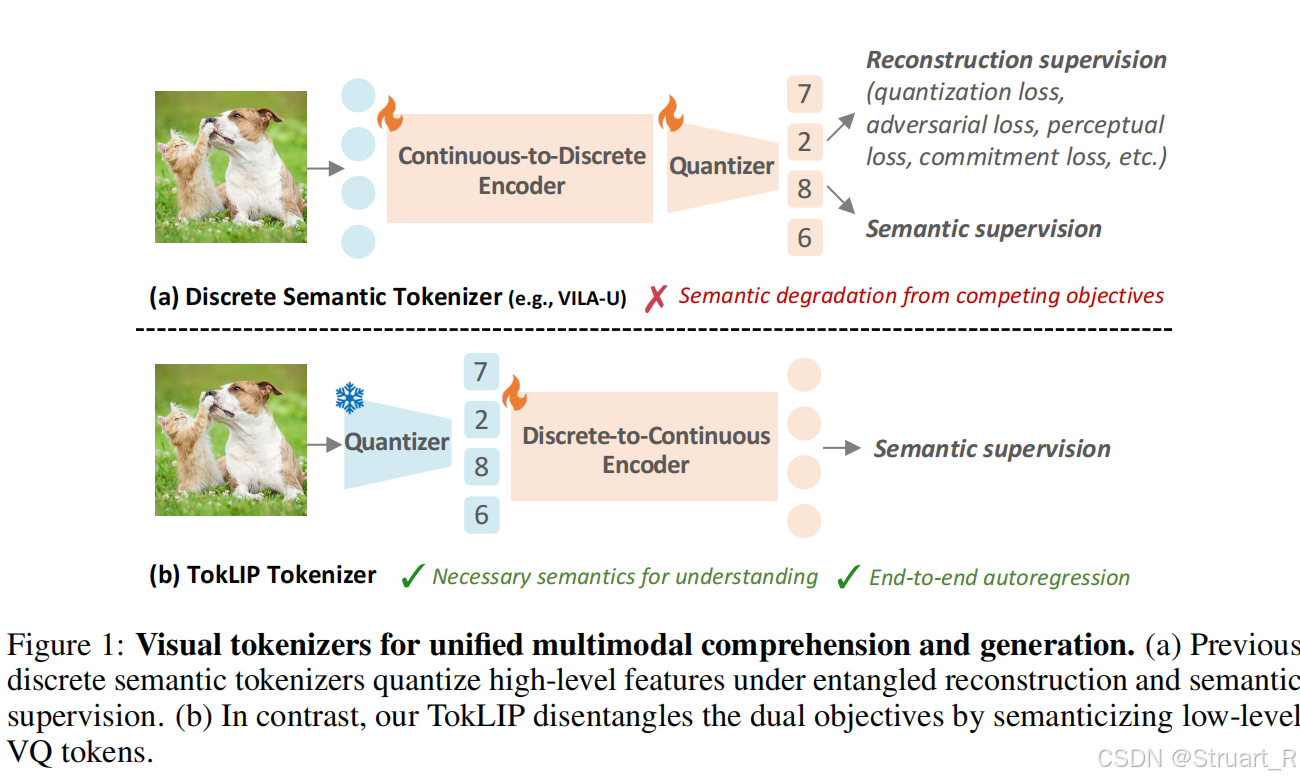
TokLIP在整体架构上与Harmon相似,都是将理解和生成解耦的操作,不同的在于Visual Encoder的处理。同样是解决VQGAN工作中缺乏高层语义的问题,对照的是VILA-U方案,VILA-U中将CLIP特征离散化,量化过程存在语义损失,另外VILA-U中将生成和理解任务统一来做,联合训练容易冲突。
2、方法
Visual Tokenizer
相较于以往的利用VQGAN提取特征后利用离散token直接进行自回归,TokLIP方法则通过一个MLP+Casual Token Encoder将离散转化会连续特征。MLP用于将离散特征维度映射到CLIP维度(512),因果编码器继承SigLIP的预训练权重,采用因果注意力。
训练过程冻结VQGAN(利用LlamaGen中的VQGAN),只训练MLP和因果ViT层,通过对比损失和蒸馏损失。对比损失利用InfoNCE对齐TokLIP的特征与文本特征,蒸馏损失利用MSE最小化TokLIP输出与SigLIP教师模型特征,但只训练[CLS]token。
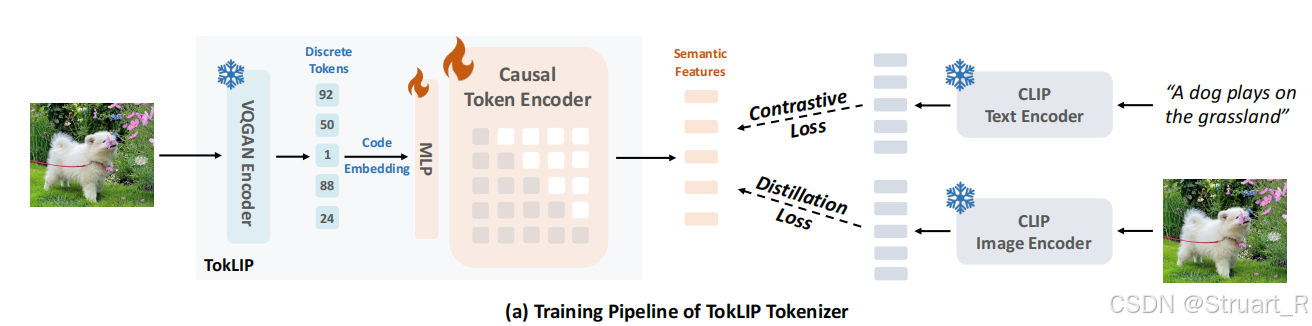
LLM
使用Qwen2.5-7B-Instruct作为基底,输入部分沿用视觉生成和视觉理解解耦,并且利用MLP对齐LLM特征空间,视觉生成部分使用LlamaGen的Decoder。

3、训练过程
一阶段训练MLP和LLM模型,数据来自LLaVA-OneVision的450W带详细caption的图像。
二阶段引入LLaMaGen中的生成部分,数据集来自LLaVA-v1.5-mix-665K,训练图像生成部分。
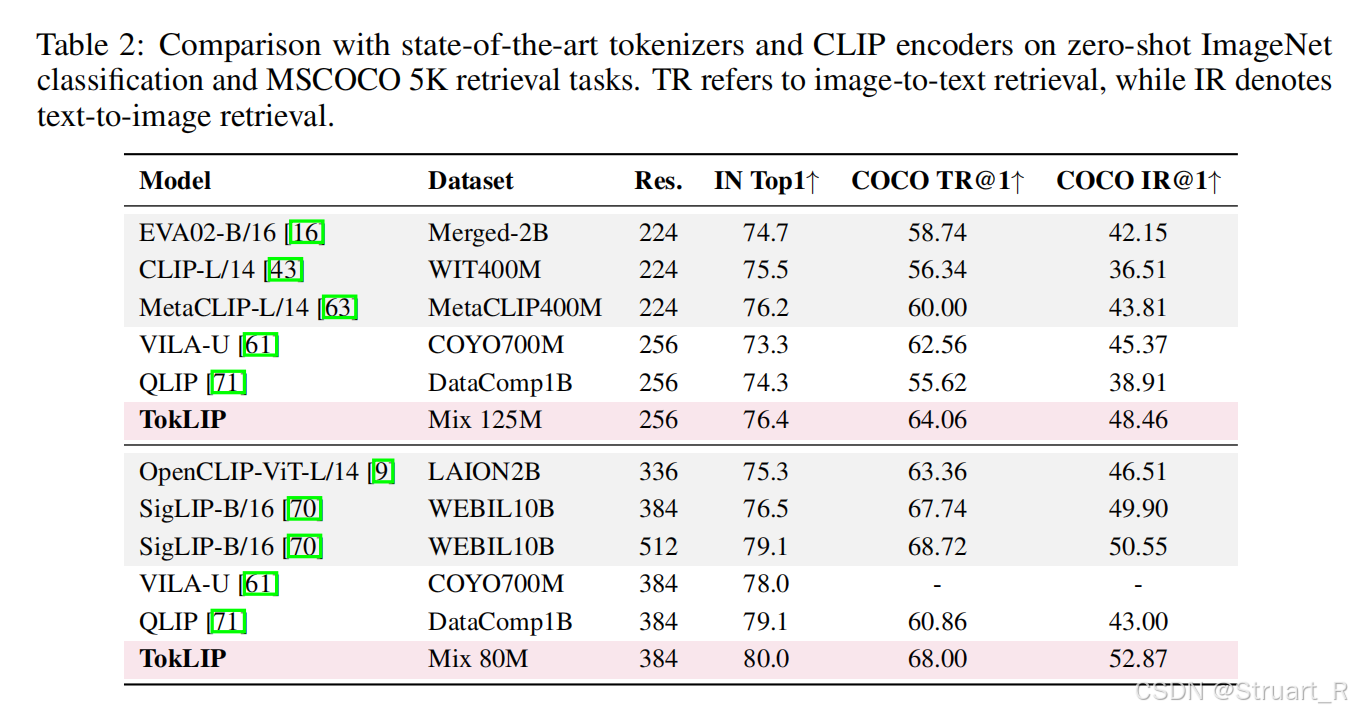
在零样本ImageNet分类上,对比图像到文本的检索和文本到图像的检索
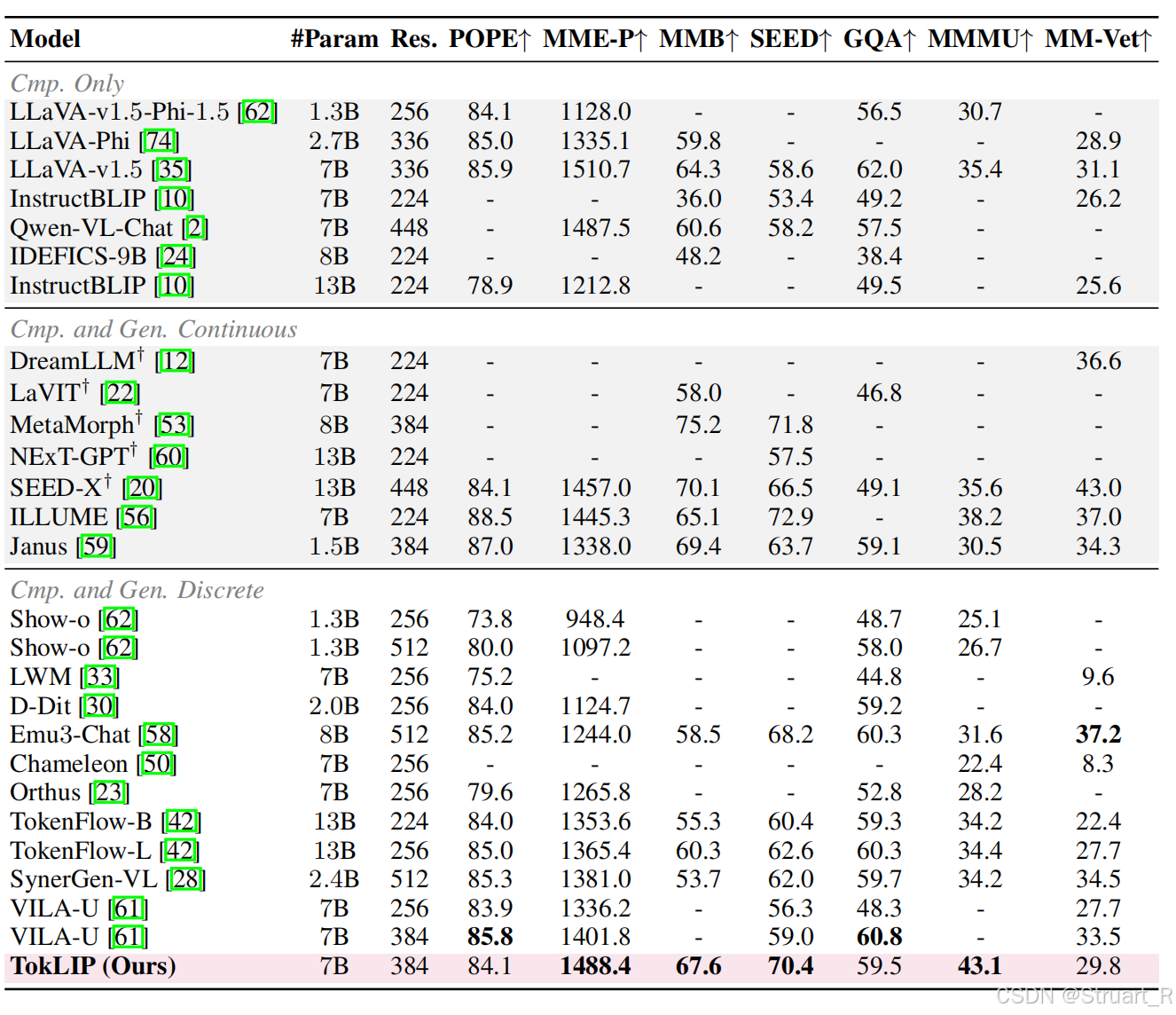
对比多模态理解能力,离散语义标记器在理解任务上缺乏语义信息,另外对于统一模型也会存在训练目标冲突而面临性能下降的问题。TokLIP实现了更突出的语义理解能力。
参考论文:
[2406.11838] Autoregressive Image Generation without Vector Quantization
[2503.21979] Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
[2505.05422] TokLIP: Marry Visual Tokens to CLIP for Multimodal Comprehension and Generation