Transformer解析——(五)代码解析及拓展
本系列已完结,全部文章地址为:
Transformer解析——(一)概述-CSDN博客
Transformer解析——(二)Attention注意力机制-CSDN博客
Transformer解析——(三)Encoder-CSDN博客
Transformer解析——(四)Decoder-CSDN博客
Transformer解析——(五)代码解析及拓展-CSDN博客
1 代码解析
代码参考了基于Tensorflow实现一个Transformer翻译器_tensorflow transformer-CSDN博客,非常感谢原作者。笔者在此基础上跑通并增加了很多注释,带注释的版本已上传到Github(https://github.com/cufewxy/transformer_with_remark)。注意需要下载语料库corpus放到目录data\transformer_demo\corpus下。具体细节请参考注释,下面仅展示整体代码结构。
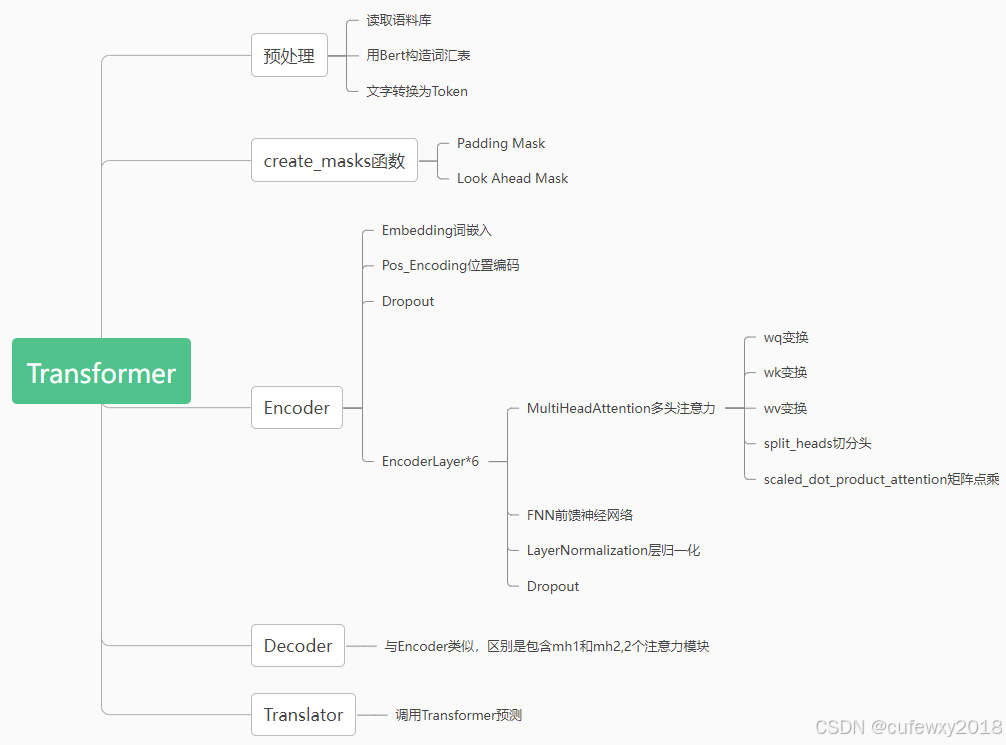
2 Transformer拓展方法
Transformer有很多拓展方法,帮助模型减少参数。
| 方法 | 原理 |
| 低秩分解 | 注意力矩阵维度很大,但它是低秩的,可以使用低秩矩阵近似,减少参数 |
| 量化 | 将网络转换为低比特表示,从而减少计算需求和内存占用 |
| 剪枝 | 移出某个注意力权重/神经元/注意力头,从而减少参数 |
| 知识蒸馏 | 训练一个参数较小的学生模型,使其与参数较大的老师模型的距离越小越好。比如OpenAI的部分GPT模型API可以提供输出的前5大概率分布,可以训练学生模型的概率分布与老师模型越接近越好 |
| KV Cache | 在生成目标序列时,已生成的token与token之间的q与k相乘结果可以缓存下来,每次新生成一个token后传入自注意力模块不用重复计算 |
3 Attention与CNN、RNN的关系
CNN使用卷积核提取信息,只能考虑序列中某个数据点四周小范围的数据;而Attention是考虑了序列中每个数据点。通过设置特定的注意力权重,CNN实际是特殊的Attention。
RNN使用模型上一时刻的输出作为下一时刻的输入,因此只能考虑到序列某个数据点以前的数据,而Attention计算自注意力权重是考虑了整个序列。如果考虑双向RNN,RNN对于长序列的支持不好,比如某个位置i的数据点如果想考虑i-5的数据,必须通过i-1,i-2...i-5等过程,用5步才可以利用i-5的信息,可能发生梯度爆炸或梯度消失;而Attention是通过注意力权重直接一步利用i-5的信息。此外RNN必须逐步计算,Attention可以并行计算。RNN像是机制僵化、等级森严的结构,Attention更像是扁平化的组织。
4 参考资料
神经网络算法 - 一文搞懂Transformer
Transformer模型详解(图解最完整版)
基于Tensorflow实现一个Transformer翻译器_tensorflow transformer-CSDN博客
一文详解视觉Transformer模型压缩和加速策略(量化/低秩近似/蒸馏/剪枝)_transformer剪枝-CSDN博客
李宏毅Transformer课程