论文阅读:DMD蒸馏 | One-step Diffusion with Distribution Matching Distillation
论文地址:https://arxiv.org/abs/2311.18828
发表时间:2023年11月30日
项目地址:https://tianweiy.github.io/dmd/
代码地址:https://github.com/Zeqiang-Lai/OpenDMD (非官网)

扩散模型能够生成高质量图像,但通常需要进行数十次前向传播。我们提出了一种称为“分布匹配蒸馏”(Distribution Matching Distillation,简称 DMD)的方法,可以将扩散模型转化为一个一步式图像生成器,同时对图像质量的影响极小。
我们通过最小化一个近似KL散度,强制让一步式生成器在分布层面上与扩散模型保持一致。该KL散度的梯度可以表示为两个得分函数之间的差异:一个是目标分布的得分函数,另一个是我们的一步式生成器所生成的合成分布的得分函数。这两个得分函数分别由两个扩散模型参数化,并针对各自对应的分布单独训练。
结合一种简单的回归损失(用于匹配多步扩散输出的大尺度结构),我们的方法超越了所有已发布的少步扩散方法,在ImageNet 64×64上达到了2.62的FID,在零样本COCO-30k数据集上达到了11.49的FID,其性能与Stable Diffusion相当,但速度快了数个数量级。利用FP16推理,我们的模型在现代硬件上可以达到每秒20帧的图像生成速度。
1、算法背景
扩散加速
加速扩散模型的推理过程一直是该领域的研究重点,由此催生了两种主要方法。第一类方法是推进快速扩散采样器[31, 41, 45, 46, 91],这些采样器能够显著减少预训练扩散模型所需的采样步数——从上千步减少到仅需20至50步。然而,进一步减少采样步数往往会导致性能急剧下降。
另一种方法是扩散蒸馏(diffusion distillation),它作为进一步提升速度的可行途径逐渐崭露头角。这类方法将扩散蒸馏视为知识蒸馏[19]的一种形式,即通过训练一个学生模型,将原始扩散模型的多步输出“蒸馏”为单步输出。Luhman等人[47]以及DSNO[93]提出了一种简单的方法:预先计算去噪轨迹,并在像素空间中利用回归损失来训练学生模型。但一个显著的挑战在于,对于每次损失函数的计算,运行完整的去噪轨迹成本非常高昂。为了解决这一问题,渐进式蒸馏,每个模型的采样步数是前一个模型的一半。InstaFlow [42, 43] 逐步学习更“直”的流(flows),使得在这些流上的一步预测能在更大的时间跨度内保持准确。一致性蒸馏(CD)[75]、TRACT [3] 和 BOOT [16] 则训练一个学生模型,使其在常微分方程(ODE)流上的某个时间步的输出与另一个时间步自身的输出相匹配,而后者又进一步被强制与再另一个时间步的输出相匹配。
相比之下,我们的方法表明,一旦我们将分布匹配作为训练目标,像 Luhman 等人以及 DSNO 那样采用预计算扩散输出这种简单的方法就已经足够。
分布匹配
近年来,一些生成模型类别通过恢复被预定义机制(如噪声注入[21, 61, 64]或标记掩码[5, 60, 87])破坏的样本,在扩展至复杂数据集方面取得了成功。
另一方面,也存在不依赖样本重建作为训练目标的生成方法。相反,它们在分布层面上对合成样本与目标样本进行匹配,例如基于高斯混合最大均值差异(GMMD)的方法[10, 39],或者生成对抗网络(GANs)[15]。
其中,生成对抗网络在真实感方面展现出了前所未有的质量[4, 26–28, 30, 67],尤其是当GAN损失可以与任务特定的辅助回归损失相结合以缓解训练不稳定性时,其应用范围从配对图像翻译[24, 54, 79, 90]到非配对图像编辑[37, 55, 95]。
尽管如此,GAN在文本引导的合成任务中仍不太受欢迎,因为要确保其在大规模应用中的训练稳定性,需要进行精心的架构设计[26]。
最近,多项研究[1, 12, 82, 86]揭示了基于分数的模型(score-based models)与分布匹配(distribution matching)之间的联系。 特别是,ProlificDreamer [80] 提出了变分分数蒸馏(Variational Score Distillation, VSD),该方法利用预训练的文本到图像扩散模型作为分布匹配损失函数。 由于VSD能够在非配对设置下[17, 58]使用大型预训练模型,它在基于粒子的优化方法中,为文本条件下的三维合成任务展现了令人印象深刻的效果。
我们的方法对VSD进行了改进和扩展,用于训练一个深度生成神经网络以实现扩散模型的蒸馏。此外,受生成对抗网络(GANs)在图像转换任务中成功应用的启发,我们引入了一个回归损失来增强训练的稳定性。
因此,我们的方法在像LAION[69]这样复杂的数据集上成功地实现了高度的真实感。 与近期将GAN与扩散模型结合的研究[68, 81, 83, 84]不同,我们的方法并不基于GAN框架。 我们的方法与同期工作[50, 85]在动机上有共通之处——它们同样利用VSD目标来训练生成器,但我们的方法通过引入回归损失,专门针对扩散模型蒸馏进行了优化,并在文本到图像任务中展示了最先进的性能。
2、算法介绍
2.1 算法架构
DMD的目的是训练一个单步生成器Gθ,但不包含时间条件,将随机噪声z映射为一张逼真的图像。其通过最小化两个损失的和来训练快速生成器:一个是分布匹配损失,其梯度更新可以表示为两个得分函数的差值;另一个是回归损失,它鼓励生成器在固定的噪声-图像对数据集上匹配基础模型输出的大尺度结构。
为了匹配(对齐)扩散模型的多步采样输出的效果,作者预先计算了一组噪声–图像对,并偶尔从该集合中加载噪声,同时在单步生成器(student)与扩散模型(teacher)输出之间施加LPIPS [89] 回归损失,也就是前面的回归损失。
此外,还向生成的假图像提供分布匹配梯度 ∇θDKL∇θ D_{KL}∇θDKL,以增强其真实感。具体操作为:
- 向假图像(student模型的输出)注入随机量的噪声,并将其输入到两个扩散模型中:一个是基于真实数据预训练的模型**(被冻结参数的teacher模型),另一个是基于假图像通过扩散损失持续训练的模型(在线更新的teacher模型)**。
- 基于两个teacher模型输出的去噪得分(在图中以均值预测的形式可视化)指示了使图像更真实或更假的方向。两者之间的差异代表了朝向更真实、更少虚假的方向,该方向通过反向传播传递给单步生成器。

在这个步骤中,一共有三个模型,分别为:单步生成器Gθ、被冻结参数的teacher模型、在线更新的teacher模型,这三个模型都源自相同的预训练模型初始化。被冻结参数的teacher模型、在线更新的teacher模型(基于diffusion loss实时进行参数更新)用于输出对nosiy image的噪声估计【进行带时间t输入的估计】,根据二者的差异对单步生成器Gθ进行梯度更新。此外,单步生成器Gθ,还基于regression loss进行迭代。
作者表明,在刚初始化时单步生成器Gθ输出的结果只是勉强接近teacher模型的某个分布,
- 按图a示例仅最大化真实分数时,生成的假样本全部坍缩到真实分布最接近的模态上 只使用real score,这与直接知识蒸馏有点类似,学生模型仅学习到教师模型的某个固定分布。
- 按图b示例使用我们的分布匹配目标但没有回归损失时,生成的假数据覆盖了更多真实分布区域,但仅恢复了最接近的模态,完全遗漏了第二个模态。 fake score源自于在线更新的teacher模型,故其输出能表示某个模态下更为发散的表示
- 按图c示例包含回归损失成功恢复了目标分布的两个模态。 regression loss来自fake image与GT图像的LPIPS loss,故可以表示所有的分布;

2.2 分布匹配 loos
理想情况下,我们希望快速生成器生成的样本与真实图像无法区分。受ProlificDreamer [80]的启发,我们最小化真实图像分布preal与生成(假)图像分布pfake之间的Kullback–Leibler(KL)散度。计算概率密度来估计这个损失通常是难以处理的,但我们只需要关于θ的梯度,就可以通过梯度下降来训练我们的生成器。

使用近似分数进行梯度更新。对公式(1)关于生成器参数求梯度:

其中,sreal(x)=∇xlogpreal(x),sfake(x)=∇xlogpfake(x)s_real(x) = ∇_x log p_{real}(x),s_{fake}(x) = ∇_x log p_{fake}(x)sreal(x)=∇xlogpreal(x),sfake(x)=∇xlogpfake(x)分别是真实分布和生成分布的得分(score)。直观上来说,sreals_{real}sreal 会将样本 x 推向prealp_{real}preal 的模态(即高概率区域),而 −sfake−s_{fake}−sfake 则会使它们彼此远离,如图 3(a, b) 所示。

然而,计算这个梯度仍然存在两个挑战:首先,对于低概率样本,得分会发散——特别是对于生成样本,prealp_{real}preal 会趋近于零;其次,我们原本用于估计得分的工具(即扩散模型)只能提供扩散后分布的得分。Score-SDE [73, 74] 为这两个问题提供了解决方案。
通过使用不同标准差的高斯随机噪声扰动数据分布,我们构建了一系列在环境空间上完全支撑(fully-supported)的“模糊”分布,因此这些分布之间会存在重叠,从而使得公式(2)中的梯度是良定义的(图4)。Score-SDE 方法进一步表明,经过训练的扩散模型能够近似该扩散分布的得分函数(score function)。
因此,我们的策略是使用一对扩散去噪器来对高斯扩散后真实分布和伪造分布的得分进行建模。在不严格区分符号的情况下,我们将它们分别定义为 sreal(xt,t)s_{real}(x_t, t)sreal(xt,t)和 sfake(xt,t)s_{fake}(x_t, t)sfake(xt,t)。扩散样本 xt q(xt∣x)x_t ~ q(x_{t} | x)xt q(xt∣x)是通过在扩散时间步 t 向生成器输出 x=Gθ(z)x = G_θ(z)x=Gθ(z) 添加噪声而获得的。

其中,αₜ 和 σₜ 来自扩散噪声调度(diffusion noise schedule)。
Real score 真实分布是固定的,由冻结参数的teacher模型针对实时生成的noisy image进行估计得出。具体定义如下:

fake score 虚假分布的定义与real score是类似,但其是动态变化的(每一个随机生成的noisy样本,都在基于diffusion loss更新在线更新的teacher模型的参数):

Distribution matching gradient update 被定义为两个扩散模型在扰动样本noisy image下的得分差异,具体如下

这里的wtw_twt是一个随时间变化的标量权重,我们添加它是为了改善训练动态。我们设计这个权重因子,以在不同噪声水平下对梯度的幅度进行归一化。具体来说,我们计算去噪图像与输入图像在空间维度和通道维度上的平均绝对误差,并将其设
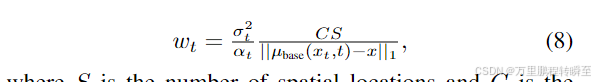
其中,S 表示空间位置的数量,C 表示通道的数量。在 4.2 节中,我们展示了这种加权方式优于先前的设计[58, 80]。我们按照 DreamFusion [58] 的设置,令 Tmin = 0.02T 和 Tmax = 0.98T。
2.3 回归loss
上一节中引入的分布匹配目标在 t ≫ 0 时(即生成的样本被大量噪声污染时)是明确定义的。
然而,当噪声较小时,由于 preal(xt,t)p_{real}(x_t, t)preal(xt,t) 趋近于零, sreal(xt,t)s_{real}(x_t, t)sreal(xt,t) 往往变得不可靠。
此外,由于得分 ∇xlog(p)∇_xlog(p)∇xlog(p)对概率密度函数 p 的缩放具有不变性,优化过程容易受到模式坍塌(mode collapse)或模式丢失(mode dropping)的影响,即虚假分布会对部分模式赋予更高的整体密度。
为了避免这种情况,我们引入了一个额外的回归损失来确保所有模式都被保留;参见图 3(b)。
**该损失函数衡量的是在给定相同输入噪声的情况下,生成器与基础扩散模型输出之间的逐点距离。**具体来说,我们构建了一个配对数据集 D = {z, y},其中 z 是随机高斯噪声图像,y 是通过使用确定性常微分方程(ODE)求解器[31, 41, 72]从预训练的扩散模型 中采样得到的对应输出。
在我们的 CIFAR-10 和 ImageNet 实验中,我们使用了 EDM [31] 中的 Heun 求解器,其中 CIFAR-10 使用了 18 步,ImageNet 使用了 256 步。对于 LAION 实验,我们使用 PNDM [41] 求解器,采样步数为 50 步。我们发现,即使只使用少量噪声–图像配对(例如,在 CIFAR-10 的情况下,这些配对仅使用了不到 1% 的训练计算量),也能起到有效的正则化作用。我们的回归损失函数定义如下,具体基于(Learned Perceptual Image Patch Similarity,LPIPS)进行计算。


2.4 最终目标
在线更新的teacher模型通过diffusion loss进行训练,该损失函数用于辅助计算∇θ DKL。
在训练单步生成器Gθ时,最终的目标函数为DKL+λregLregD_{KL} + λ_{reg}L_{reg}DKL+λregLreg,其中λregλ_{reg}λreg默认取值为0.25,除非另有说明。梯度∇θDKL∇θ D_{KL}∇θDKL通过公式(7)计算,而梯度∇θLreg∇θ L_{reg}∇θLreg则通过公式(9)利用自动微分方法计算得出。
我们将这两个损失函数应用于不同的数据流:分布匹配梯度使用未配对的假样本(unpaired fake samples),而回归损失则使用配对样本(paired examples)。
2.5 Classifier-Free Guidance
无分类器引导(Classifier-Free Guidance)[20] 被广泛用于提升文本到图像扩散模型的图像质量。我们的方法同样适用于采用无分类器引导的扩散模型。我们首先通过从引导模型中采样,生成相应的噪声-输出对,以构建回归损失$ L_{reg}$ 所需的配对数据集。在计算分布匹配梯度 ∇θDKL∇θ D_{KL}∇θDKL 时,我们使用用来自均值的推导得分替代真实得分。引导模型预测的同时,我们并未修改假分数的公式。我们以固定的引导比例训练单步生成器。
3、具体实现
3.1 具体流程
这里对论文中给出的算法流程进行解释说明:
1、先基于预训练模型生成,数据对(latent,image)==》zref,yref{z_{ref}, y_{ref}}zref,yref
2、基于预训练模型初始化,单步生成器Gθ、被冻结参数的teacher模型、在线更新的teacher模型三个模型
3、训练循环中,随机采样噪声z,与数据对样本KaTeX parse error: Expected '}', got 'EOF' at end of input: {z_{ref}
4、训练循环中,利用G与z生成x,同时基于被冻结参数的teacher模型、在线更新的teacher模型对x推理得到fake score、real score。然后计算出分布匹配loss;
5、训练循环中,利用G与KaTeX parse error: Expected '}', got 'EOF' at end of input: {z_{ref}生成KaTeX parse error: Expected '}', got 'EOF' at end of input: {x_{ref},再基于LPIPS计算G的输出与teacher模型输出的回归loss
6、训练循环中,计算G的最终loss,并进行梯度更新
7、训练循环中,随机采样时间t,基于数据x、t,被冻结参数的teacher模型生成目标,然后蒸馏在线更新的teacher模型

通过对论文流程的解释说明,可以发现这里的x就是流程图fake image,z就是 random laten z。x与KaTeX parse error: Expected '}', got 'EOF' at end of input: {x_{ref}是不一样的,但在流程图中都是同一个了。

3.2 相关代码
https://github.com/Zeqiang-Lai/OpenDMD/blob/main/train_dmd.py
3.2.1 模型初始化
可以发现student_model与fake_model的权重全部来自real_model。real_model参数冻结,不进行更新。student_model与fake_model的权重会在训练中进行迭代更新。
def setup_model(args, accelerator, weight_dtype):noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler")tokenizer = AutoTokenizer.from_pretrained(args.pretrained_teacher_model, subfolder="tokenizer", legacy=False, use_fast=False)if args.text_encoder_class == "clip":text_encoder = CLIPTextModel.from_pretrained(args.pretrained_teacher_model, subfolder="text_encoder")elif args.text_encoder_class == "bert":text_encoder = BertModel.from_pretrained(args.pretrained_teacher_model, subfolder="text_encoder")elif args.text_encoder_class == "t5":text_encoder = T5EncoderModel.from_pretrained(args.pretrained_teacher_model, subfolder="text_encoder")if args.vae_class == "tiny":vae = AutoencoderTiny.from_pretrained(args.pretrained_vae_model_name_or_path)else:vae = AutoencoderKL.from_pretrained(args.pretrained_teacher_model, subfolder="vae")real_model = MODEL_CLS.from_pretrained(args.pretrained_teacher_model, subfolder=args.model_class)vae.requires_grad_(False)text_encoder.requires_grad_(False)real_model.requires_grad_(False)fake_model = MODEL_CLS(**real_model.config)fake_model.load_state_dict(real_model.state_dict(), strict=False)fake_model.train()student_model = MODEL_CLS(**real_model.config)student_model.load_state_dict(real_model.state_dict(), strict=False)student_model.train()# Move model, vae and text_encoder to device and cast to weight_dtype# The VAE is in float32 to avoid NaN losses.vae.to(accelerator.device)text_encoder.to(accelerator.device, dtype=weight_dtype)# Move teacher_model to device, optionally cast to weight_dtypereal_model.to(accelerator.device)fake_model.to(accelerator.device)student_model.to(accelerator.device)if args.cast_teacher_model:real_model.to(dtype=weight_dtype)if args.gradient_checkpointing:student_model.enable_gradient_checkpointing()fake_model.enable_gradient_checkpointing()return real_model, fake_model, student_model, noise_scheduler, tokenizer, text_encoder, vaedef setup_optimizer_scheduler(args, fake_model, student_model):fake_optimizer = torch.optim.AdamW(fake_model.parameters(),lr=args.learning_rate,betas=(args.adam_beta1, args.adam_beta2),weight_decay=args.adam_weight_decay,eps=args.adam_epsilon,)student_optimizer = torch.optim.AdamW(student_model.parameters(),lr=args.learning_rate,betas=(args.adam_beta1, args.adam_beta2),weight_decay=args.adam_weight_decay,eps=args.adam_epsilon,)fake_lr_scheduler = get_scheduler(args.lr_scheduler,optimizer=fake_optimizer,num_warmup_steps=args.lr_warmup_steps,num_training_steps=args.max_train_steps,)student_lr_scheduler = get_scheduler(args.lr_scheduler,optimizer=student_optimizer,num_warmup_steps=args.lr_warmup_steps,num_training_steps=args.max_train_steps,)return fake_optimizer, student_optimizer, fake_lr_scheduler, student_lr_scheduler
3.2.2 reg_loss
这里可以发现是单步生成器基于latents_ref得到latents_ref_pred ,然后基于vae.decode进行解码,最后计算lpips loss
latents_ref, images_ref, prompts_ref = next(reg_dataloader)latents_ref = latents_ref.to(accelerator.device)images_ref = images_ref.to(accelerator.device)if args.gradient_checkpointing:accelerator.unwrap_model(fake_model).disable_gradient_checkpointing()tracker.update({"data_time": time.time() - start_time})logs = {}# ------------ train student model ------------- #loss_g = 0if args.reg_loss_weight > 0:prompt_ref_embeds, prompt_ref_attention_masks = encode_prompt(prompts_ref, text_encoder, tokenizer)latents_ref_pred = generate(student_model, noise_scheduler, latents_ref, prompt_ref_embeds, prompt_ref_attention_masks)images_ref_pred = vae.decode(latents_ref_pred.to(vae.dtype) / vae.config.scaling_factor).sampleimages_ref_pred = (images_ref_pred / 2 + 0.5).clamp(0, 1)images_ref_pred = images_ref_pred.to(dtype=images_ref.dtype)loss_reg = lpips(images_ref, images_ref_pred)loss_g += loss_reg * args.reg_loss_weight3.2.3 kl_loss
student_model模型对latents 进行去噪,得到latents_pred
if args.kl_loss_weight > 0:prompt_embeds, prompt_attention_masks = encode_prompt(prompts, text_encoder, tokenizer)latents = prepare_latents(accelerator.unwrap_model(student_model), vae, batch_size=len(prompts), device=accelerator.device, dtype=weight_dtype)latents_pred = generate(student_model, noise_scheduler, latents, prompt_embeds, prompt_attention_masks)if args.reg_loss_weight > 0:latents_pred = torch.cat([latents_pred, latents_ref_pred], dim=0)prompts = prompts + prompts_refprompt_embeds = torch.cat([prompt_embeds, prompt_ref_embeds], dim=0)if prompt_attention_masks is not None:prompt_attention_masks = torch.cat([prompt_attention_masks, prompt_ref_attention_masks], dim=0)negative_prompt_embeds, negative_prompt_attention_masks = encode_prompt([""] * len(prompts), text_encoder, tokenizer)loss_kl = distribution_matching_loss(real_model,fake_model,noise_scheduler,latents_pred,prompt_embeds,prompt_attention_masks,negative_prompt_embeds,negative_prompt_attention_masks,args,)loss_g += loss_kl * args.kl_loss_weight
#---------------
def generate(model, scheduler, latents, prompt_embeds, prompt_attention_masks=None):t = torch.full((1,), scheduler.config.num_train_timesteps - 1, device=latents.device).long()noise_pred = forward_model(model,latents=latents,timestep=t,prompt_embeds=prompt_embeds,prompt_attention_masks=prompt_attention_masks,)latents = eps_to_mu(scheduler, noise_pred, latents, t)return latents
。。。。noise_scheduler对latents_pred进行加噪得到noisy_latents ,分别由fake_model、real_model得到噪声估计,即fake score,real score具体为pred_fake_latents 、pred_real_latents 。这里需要注意,pred_real_latents 已经注入了cfg信息。
def distribution_matching_loss(real_model,fake_model,noise_scheduler,latents, #这里的具体实际参数为学生模型输出的latents_predprompt_embeds,prompt_attention_masks,negative_prompt_embeds,negative_prompt_attention_masks,args,
):bsz = latents.shape[0]min_dm_step = int(noise_scheduler.config.num_train_timesteps * args.min_dm_step_ratio)max_dm_step = int(noise_scheduler.config.num_train_timesteps * args.max_dm_step_ratio)timestep = torch.randint(min_dm_step, max_dm_step, (bsz,), device=latents.device).long()noise = torch.randn_like(latents)noisy_latents = noise_scheduler.add_noise(latents, noise, timestep)with torch.no_grad():noise_pred = forward_model(fake_model,latents=noisy_latents,timestep=timestep,prompt_embeds=prompt_embeds.float(),prompt_attention_masks=prompt_attention_masks,)# fake scorepred_fake_latents = eps_to_mu(noise_scheduler, noise_pred, noisy_latents, timestep) noisy_latents_input = torch.cat([noisy_latents] * 2)timestep_input = torch.cat([timestep] * 2)prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)if prompt_attention_masks is not None:prompt_attention_masks = torch.cat([negative_prompt_attention_masks, prompt_attention_masks], dim=0)noise_pred = forward_model(real_model,latents=noisy_latents_input,timestep=timestep_input,prompt_embeds=prompt_embeds.float(),prompt_attention_masks=prompt_attention_masks,)noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + args.guidance_scale * (noise_pred_text - noise_pred_uncond)# real scorepred_real_latents = eps_to_mu(noise_scheduler, noise_pred, noisy_latents, timestep)weighting_factor = torch.abs(latents - pred_real_latents).mean(dim=[1, 2, 3], keepdim=True)grad = (pred_fake_latents - pred_real_latents) / weighting_factorloss = F.mse_loss(latents, stopgrad(latents - grad))return lossdef eps_to_mu(scheduler, model_output, sample, timesteps):alphas_cumprod = scheduler.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)alpha_prod_t = alphas_cumprod[timesteps]while len(alpha_prod_t.shape) < len(sample.shape):alpha_prod_t = alpha_prod_t.unsqueeze(-1)beta_prod_t = 1 - alpha_prod_tpred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)return pred_original_sample
3.2.4 train model
前面2节的代码完成了student梯度的计算与更新。这里主要是对各种数据的梯度计算范围进行截断,确保其只影响fake_model的梯度更新。
student_optimizer.step()student_lr_scheduler.step()student_optimizer.zero_grad(set_to_none=True)logs.update({"loss_g": loss_g.detach().item()})tracker.update({"loss_g": loss_g.detach().item()})# ------------ train fake model ------------- #if args.train_fake_model:if args.gradient_checkpointing:accelerator.unwrap_model(fake_model).disable_gradient_checkpointing()if args.kl_loss_weight > 0:latents = stopgrad(latents_pred)encoder_hidden_states = stopgrad(prompt_embeds)if prompt_attention_masks is not None:prompt_attention_masks = stopgrad(prompt_attention_masks)else:latents = stopgrad(latents_ref_pred)encoder_hidden_states = stopgrad(prompt_ref_embeds)prompt_attention_masks = Noneif prompt_ref_attention_masks is not None:prompt_attention_masks = stopgrad(prompt_ref_attention_masks)# Sample noise that we'll add to the latentsnoise = torch.randn_like(latents)bsz = latents.shape[0]# Sample a random timestep for each imagetimesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)timesteps = timesteps.long()noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)if noise_scheduler.config.prediction_type == "epsilon":target = noiseelif noise_scheduler.config.prediction_type == "v_prediction":target = noise_scheduler.get_velocity(latents, noise, timesteps)else:raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")# Predict the noise residual and compute lossmodel_pred = forward_model(fake_model,latents=noisy_latents,timestep=timesteps,prompt_embeds=encoder_hidden_states,prompt_attention_masks=prompt_attention_masks,)if args.snr_gamma is None:loss_d = F.mse_loss(model_pred.float(), target.float(), reduction="mean")else:# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.# Since we predict the noise instead of x_0, the original formulation is slightly changed.# This is discussed in Section 4.2 of the same paper.snr = compute_snr(noise_scheduler, timesteps)if noise_scheduler.config.prediction_type == "v_prediction":# Velocity objective requires that we add one to SNR values before we divide by them.snr = snr + 1mse_loss_weights = torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snrloss = F.mse_loss(model_pred.float(), target.float(), reduction="none")loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weightsloss_d = loss.mean()accelerator.backward(loss_d)if accelerator.sync_gradients:accelerator.clip_grad_norm_(fake_model.parameters(), args.max_grad_norm)fake_optimizer.step()fake_lr_scheduler.step()fake_optimizer.zero_grad()logs.update({"loss_d": loss_d.detach().item()})tracker.update({"loss_d": loss_d.detach().item()})tracker.update({"optim_time": time.time() - start_time})
4、实施效果
4.1 与原始step对比
根据官网提供的效果,可以发现大部分数据效果是不分上下,输出结果在构图上是高度相近的。但是1 step推理的效果还是存在一定瑕疵,如下图小鹿背景中的树叶,小鸟背景中的树叶均存在瑕疵。

在背景简单(无结构化要求)的数据下,可以发现一步推理,与多步推理结果均保持了高质量。

4.2 与同类方法对比
与同类方法对比可以发现,DMD效果是最接近原始模型的。

以论文中给出的FID分数,可以发现DMD方法保持了断崖式领先。与官网给出的示例效果高度一致。

