CS224n:Word Vectors and Word Senses(二)
目录
一、共现矩阵
1.1 基于共现矩阵的词向量
二、SVD分解
2.1 基于共现矩阵的词向量 vs. Word2Vec词向量
三、GloVe词向量
3.1 GloVe词向量的好处
3.2 GloVe的一些结果展示
部分笔记来源参考
Beyond Tokens - 知乎 (zhihu.com)
NLP教程(1) - 词向量、SVD分解与Word2Vec (showmeai.tech)
一、共现矩阵
1.1 基于共现矩阵的词向量
先来回顾一下上节的Word2Vec的核心思想:让相邻的词的向量表示相似。
我们实际上还有一种更加简单的思路——使用「词语共现性」,来构建词向量,也可以达到这样的目的。即,我们直接统计哪些词是经常一起出现的,那么这些词肯定就是相似的。那么,每一个词,都可以做一个这样的统计,得到一个共现矩阵(word-word co-occurrence matrix)。
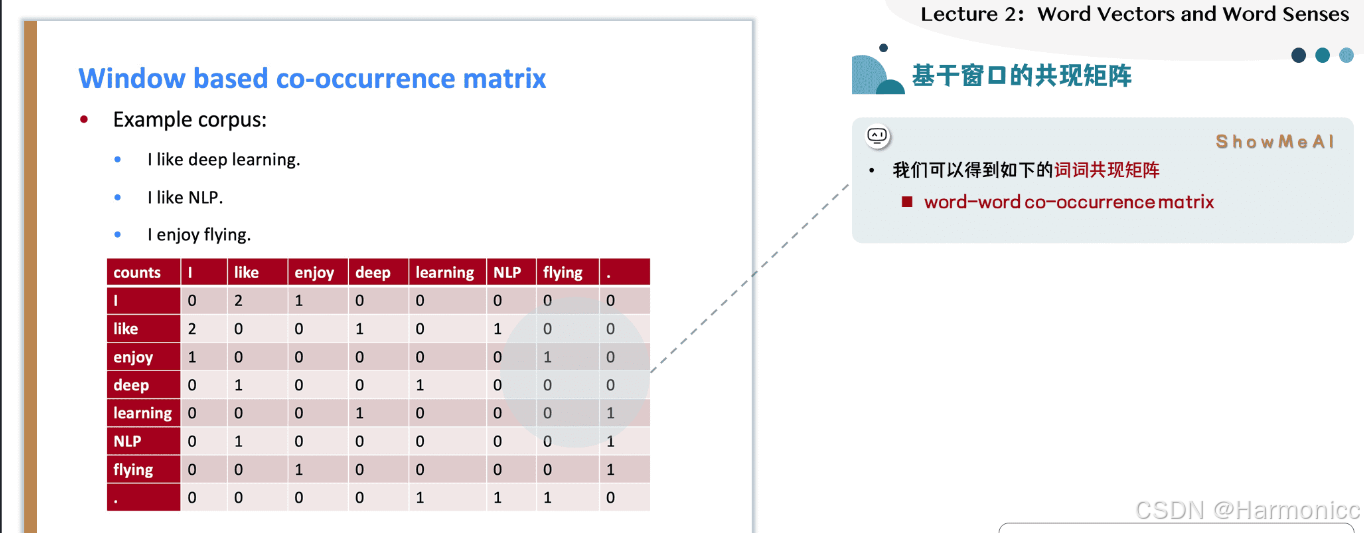
上面的例子中,给出了三句话,假设这就是我们全部的语料。我们使用一个size=1的窗口,对每句话依次进行滑动,相当于只统计紧邻的词。这样就可以得到一个共现矩阵。
共现矩阵的每一列,自然可以当做这个词的一个向量表示。这样的表示明显优于one-hot表示,因为它的每一维都有含义——共现次数,因此这样的向量表示可以求词语之间的相似度。
直接基于共现矩阵构建词向量,会有一些明显的问题,如下:

怎么解决这个问题呢?这就引出了我们第二节要讲的SVD矩阵分解。
二、SVD分解
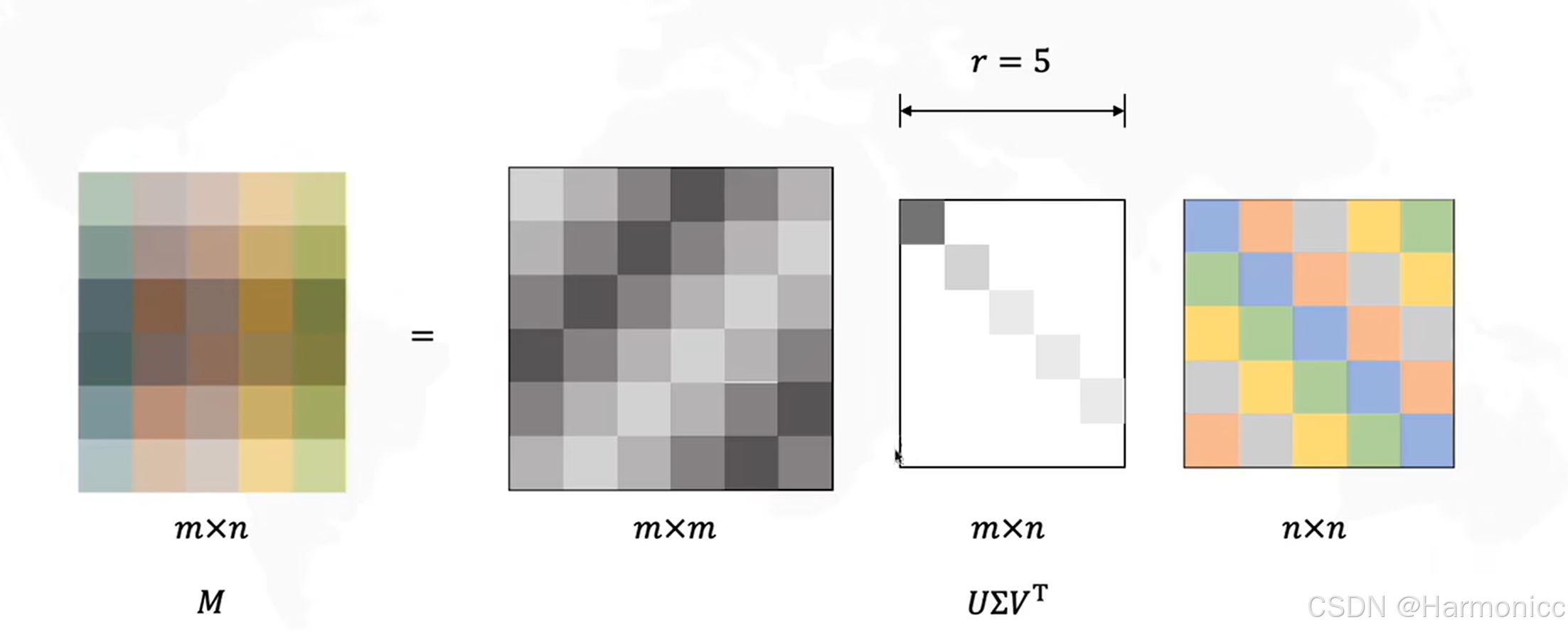
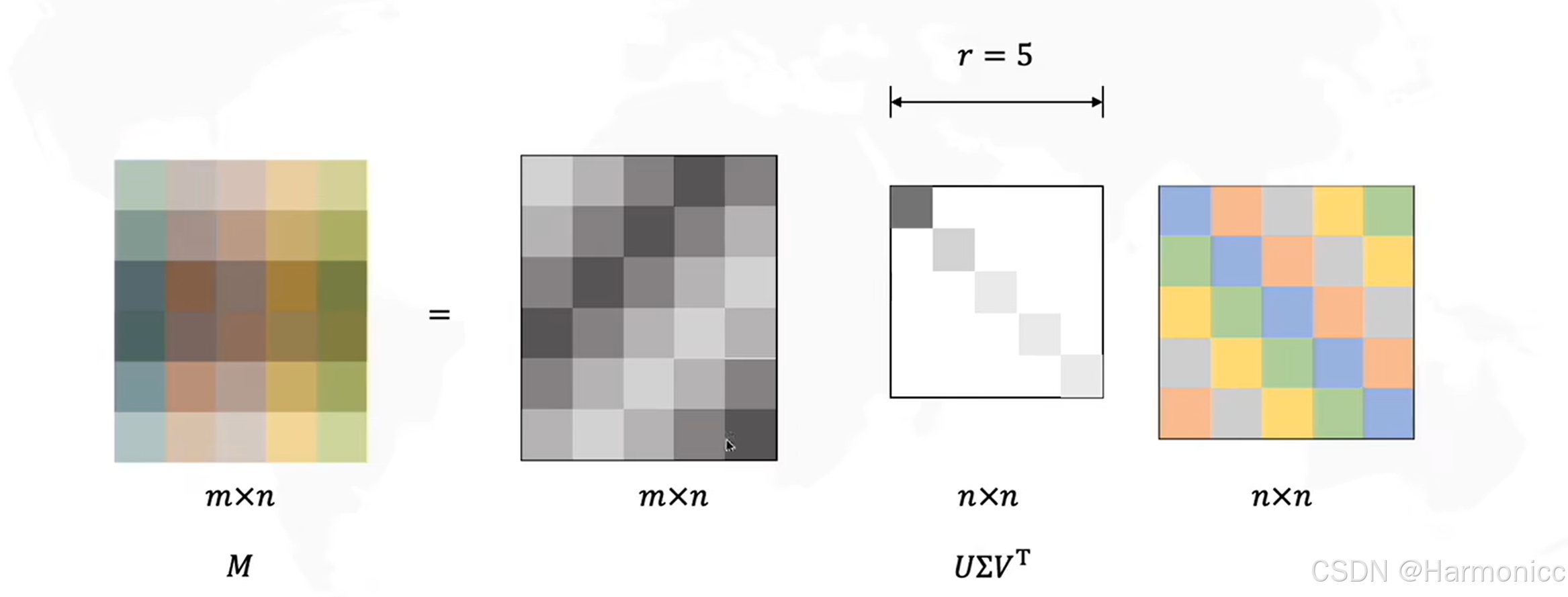
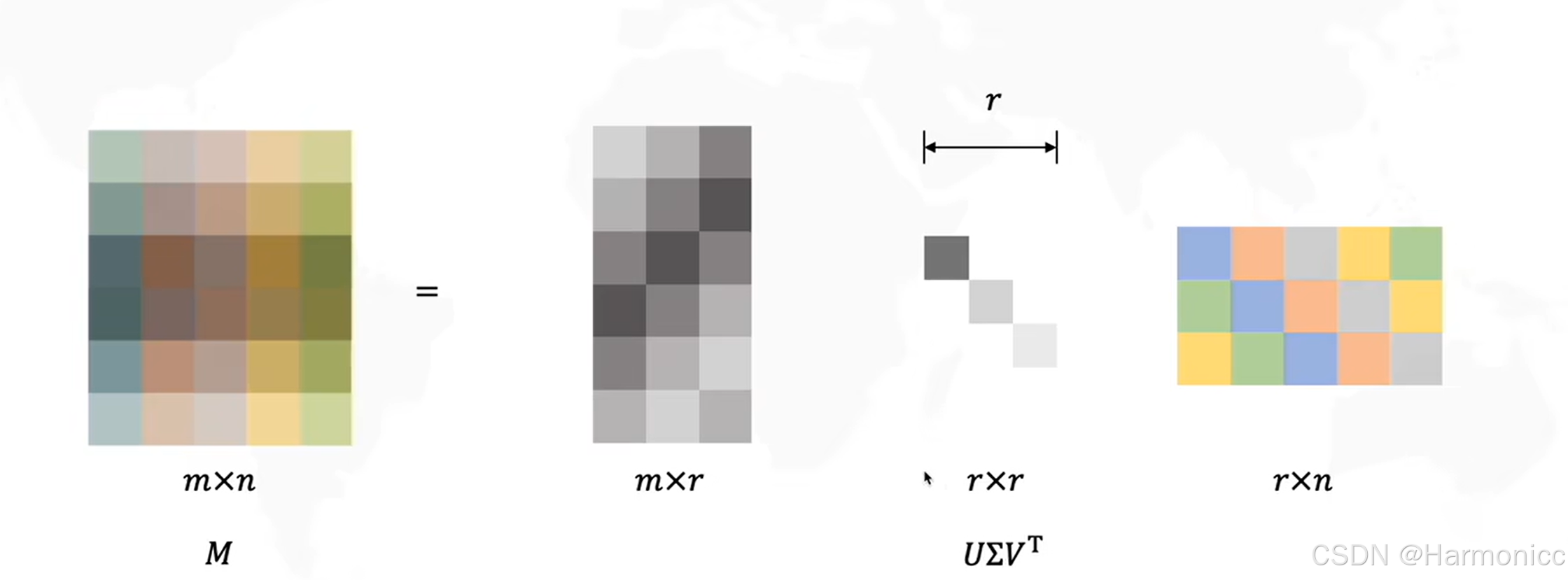
我们将巨大的共现矩阵进行SVD分解后,只选取最重要的几个特征值,得到每一个词的低维表示,从而解决维度问题,讲到这里了,顺便讲讲SVD的数学原理。
它可以将任意一个实数矩阵 分解成三个特殊矩阵的乘积,如下:
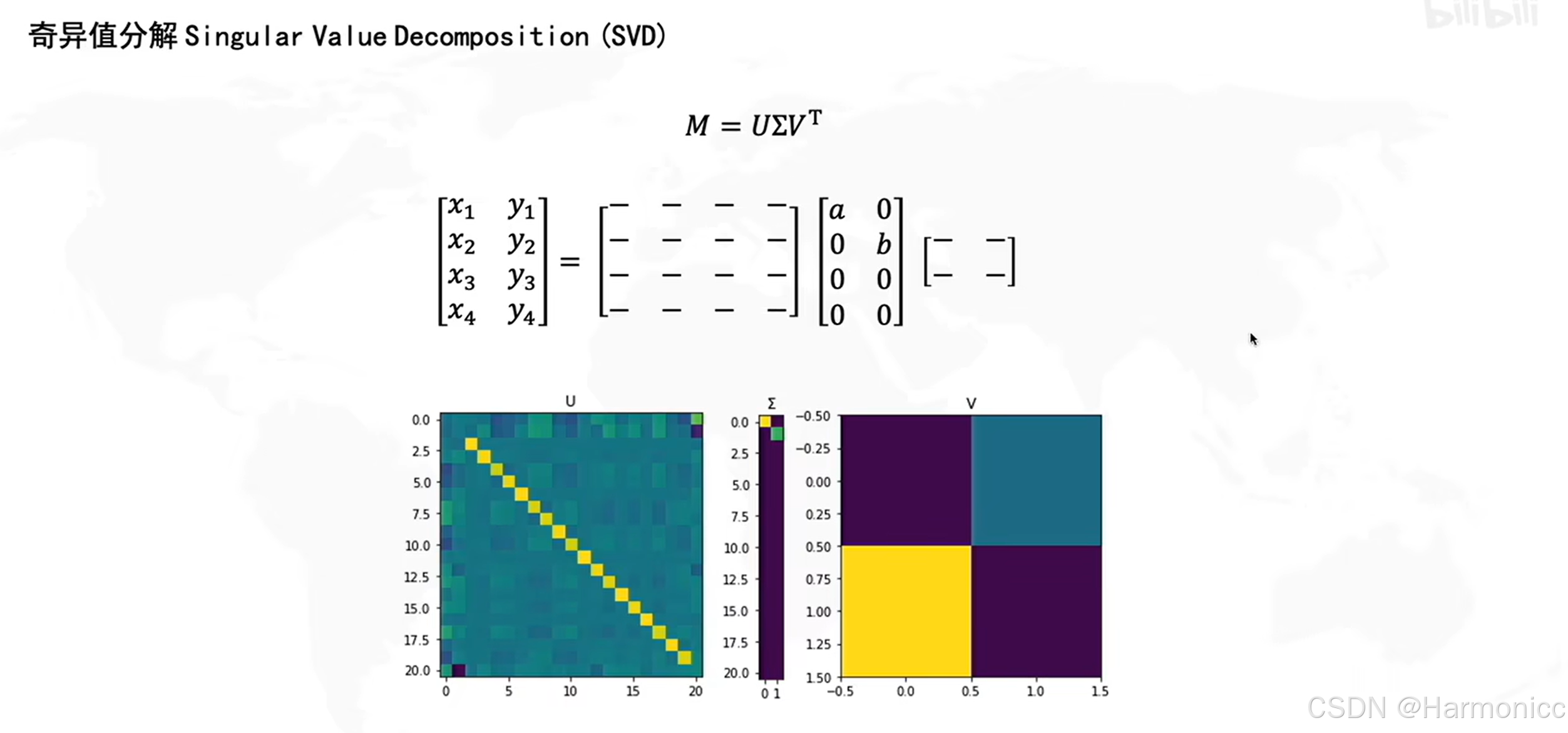
从几何的意义很好理解,记是一个线性变换,即对一个向量从
的空间旋转(
)、拉伸(
)、再旋转(
)到
的空间,如下:
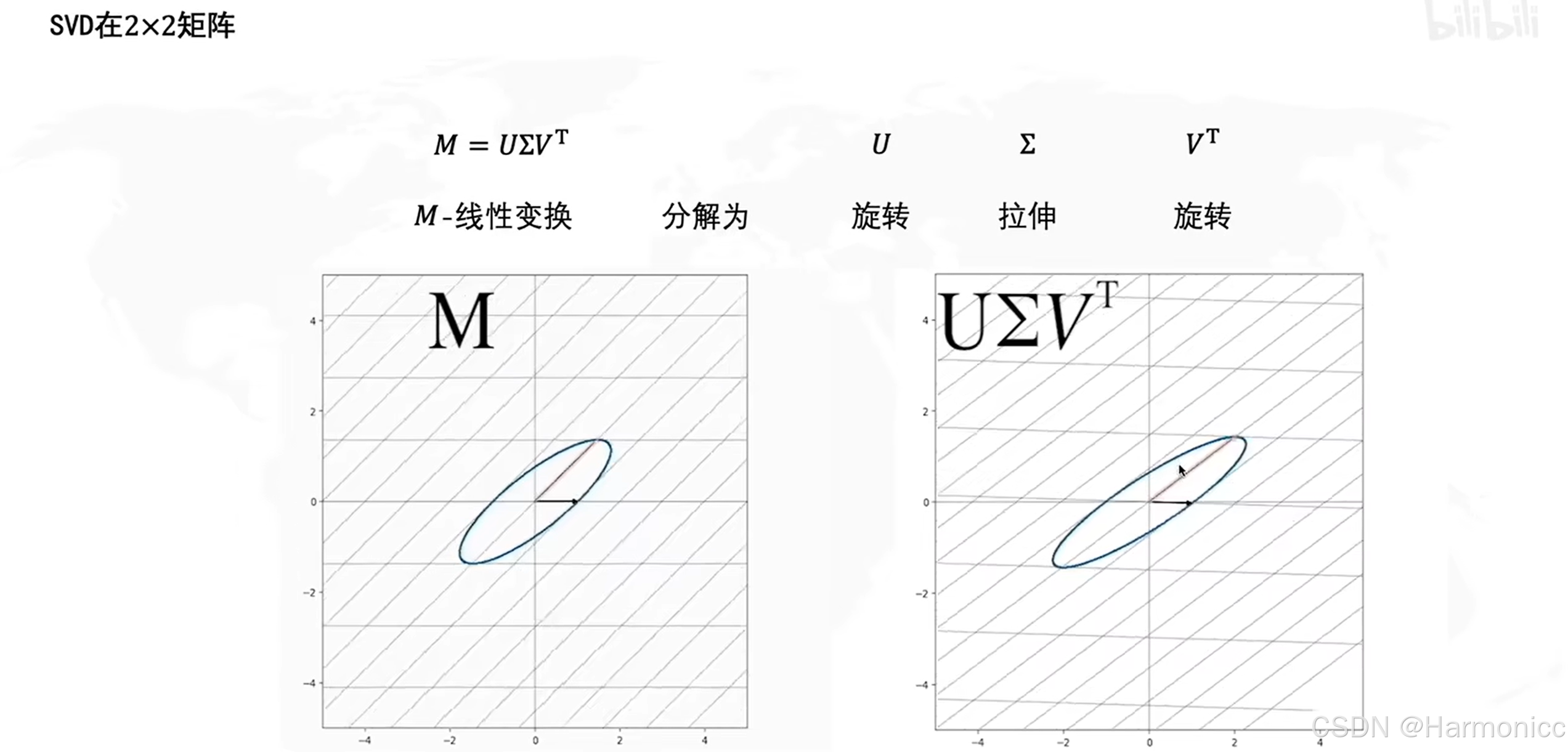
从几何的意义上,具体的原理如下:
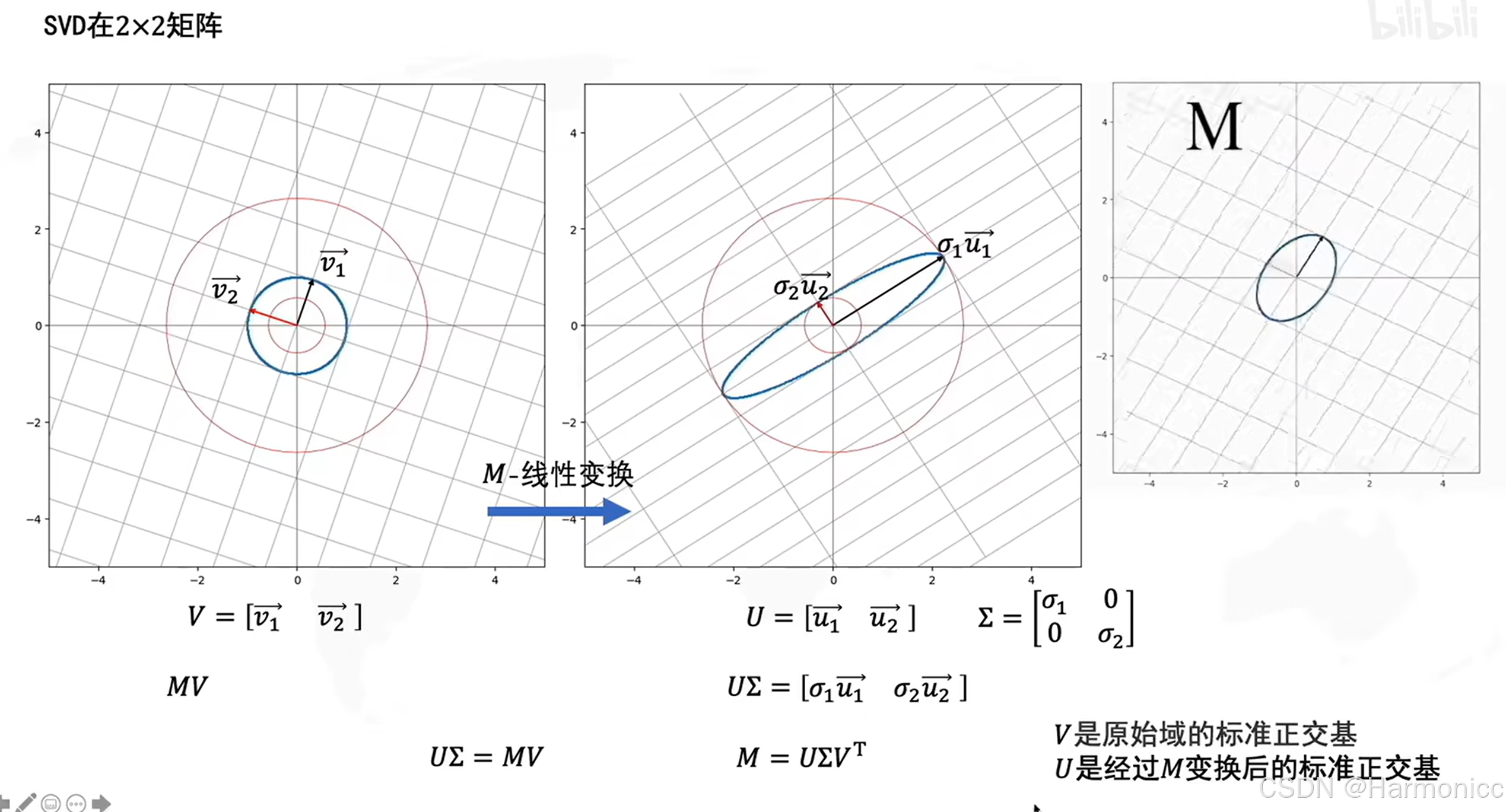
而经过数次迭代后可以整理成我们想要得到的样子

我们通过构建共现矩阵、进行SVD降维,可视化,依然呈现出了类似Word2Vec的效果。
但是还有一些问题,由于共现矩阵巨大,SVD分解的计算代价也是很大的。另外,像a、the、is这种词,与其他词共现的次数太多,也会很影响效果。所以,我们需要使用很多技巧,来改善这样的词向量。例如,直接把一些常见且意义不大的词忽略掉;把极度不平衡的计数压缩到一个范围;使用皮尔逊相关系数,来代替共现次数等等很多技巧。
2.1 基于共现矩阵的词向量 vs. Word2Vec词向量

三、GloVe词向量

这里我们采用第一种

我们和Word2vec的loss函数(下图)对比一下,会发现这里loss的分母没有显式出现,这是因为分母已通过 Softmax 中的归一化项隐式包含在中。
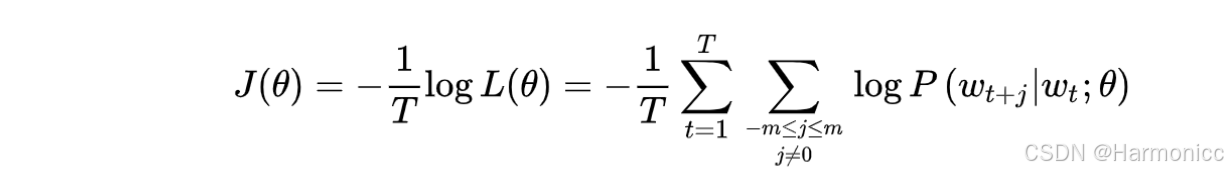

其实就是一个新的交叉熵函数。交叉熵,只是众多损失函数中的一种,而交叉熵损失函数天然有一些缺陷:由于它是处理两个分布,而很多分布都具有「长尾」的性质,这使得基于交叉熵的模型常常会给那些不重要、很少出现的情形给予过高的权重。另外,由于我们需要计算概率,所以「必须进行合理的规范化」(normalization),规范化,就意味着要除以一个「复杂的分母」,像Softmax中,我们需要遍历所有的词汇来计算分母,这样的开销十分巨大。


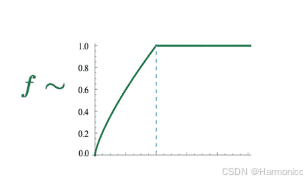
至此,我们得到了GloVe的损失函数(一套词向量版):
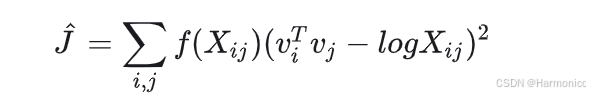
3.1 GloVe词向量的好处


3.2 GloVe的一些结果展示

本小节结束