动手学习深度学习-深度学习知识大纲
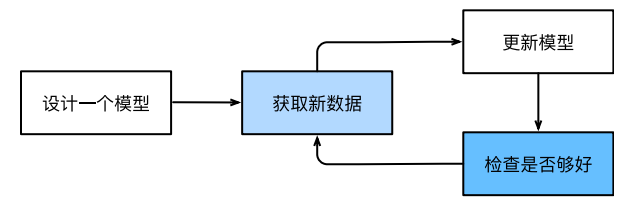
使用数据集训练一个模型的过程:
1、构造随机初始化参数的模型
2、获取数据集
3、构造损失和优化器用于调整参数,使模型在数据样本中表现更好
4、重复第2步和第3步
1、机器学习组件
1.1、数据处理(包含一定数学知识)
- 数据+=样本/数据点/数据实例(独立且同分布)
- 独立:一个样本的出现不影响其他样本的出现概率。
- 同分布:所有样本都来自相同的概率分布,即它们具有相似的统计特性。
- 样本+=特征/协变量属性(机器学习模型会根据这些属性进⾏预测,要预测的是⼀个特殊的属性,它被称为标签(label),或⽬标(target))
- 假设我们处理的是图像数据,每⼀张单独的照⽚即为⼀个样本,它的特征由每个像素数值的有序列表表示。⽐如,200 × 200彩⾊照⽚由200 × 200 × 3 = 120000个数值组成,其中的“3”对应于每个空间位置的红、绿、蓝通道的强度。
- 特征向量:将样本的所有特征值组合成一个向量。
- 维度:特征的个数,或特征向量的长度
1.2、模型(神经网络)
- 深度学习关注的是功能强⼤的模型,这些模型由神经⽹络(CNN、RNN等)错综复杂的交织在⼀起,且包含层层的数据转换。
1.3、目标函数(loss)
- 目标函数(损失函数loss/cost):定义模型优劣程度的度量,一般越低越好。
- 预测数值:平方误差,预测值与实际值之差的平方
- 分类问题:最小化错误率,即预测与实际情况不符的样本⽐例
- 损失函数是根据模型参数定义的,并取决于数据集。数据集分为两部分:
- 训练数据集:拟合模型参数
- 测试数据集:评估拟合模型
1.4、优化算法(grad)
- 梯度下降:在每个步骤中检查每个参数,观察对该参数进行少量变动时,训练集损失会朝哪个⽅向移动,然后在减少损失的方向上优化参数。
2、机器学习问题分类
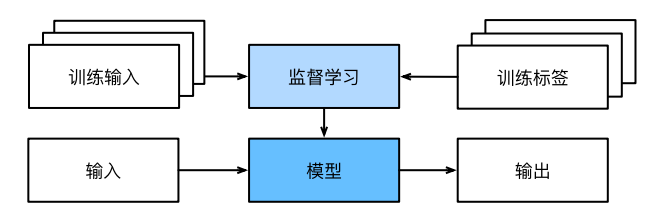
2.1、监督学习(supervised learning)--有目标(标签)
监督学习擅⻓在“给定输⼊特征”的情况下预测标签。即在给定⼀组特定的可⽤数据的情况下,估计未知事物的概率。
- 预测:能够将任何输⼊特征映射到标签
- 样本:特征+标签
监督学习的学习过程:
1、从已知⼤量数据样本中随机选取⼀个⼦集,为每个样本获取基本的真实标签。这些输⼊和相应的标签⼀起构成了训练数据集。
2、选择有监督的学习算法,它将训练数据集作为输⼊,并输出⼀个“完成学习模型”。
3、将之前没⻅过的样本特征(测试数据集)放到这个“完成学习模型”中,使⽤模型的输出作为相应标签的预测。
- 常见监督学习
- 回归问题:
- 标签取任意值,且⽬标是⽣成⼀个预测⾮常接近实际标签值的模型。即需要根据输入预测出一个值的问题很可能就是回归问题。
- 其损失函数常用最小化平方误差函数。
- 分类问题:
- 标签取任意值,且⽬标是生成⼀个能够预测样本属于哪个类别(category,正式称为类(class))分类器模型。即需要根据输入预测出类别的问题就是分类问题。
- 其损失函数常用交叉熵函数。
- 标记问题:
- 学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。
- 搜索问题:
- 在海量搜索结果中找到最需要的那部分后,让搜索结果以“有序的元素⼦集”形式输出。
- 推荐系统:
- 对于任何给定的⽤⼾,推荐系统都可以检索得分最⾼的对象集,然后将其推荐给用户。
- 序列学习:
- 用于前后有关联的问题。例如,视频、文本、病人死亡风险评估等。
2.2、无监督学习(unsupervised learning)--无目标(标签)
- 常见无监督学习
- 聚类问题:无标签的情况下给数据分类。
- 主成分分析问题:用少量的参数来准确地捕捉数据的线性相关属性。
- 因果关系与概率图模型问题:描述观察到的许多数据的根本原因。
- 生成对抗性网络:⼀种合成数据的⽅法
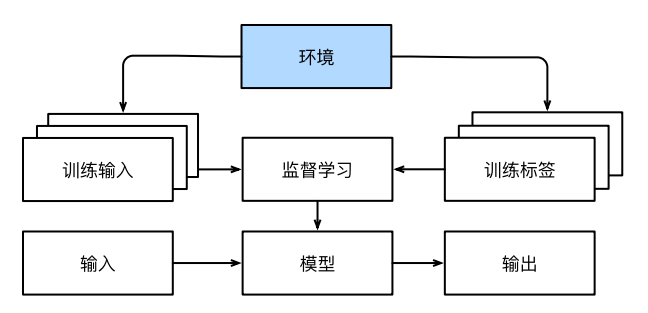
2.3、与环境互动
从环境中为监督学习收集数据的过程为:
2.4、强化学习
- 强化学习的过程:
- 智能体(agent)在一系列的时间步骤上与环境交互,在每个特定时间点,智能体从环境接收一些观察,并且必须选择一个动作,然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励。此后新⼀轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
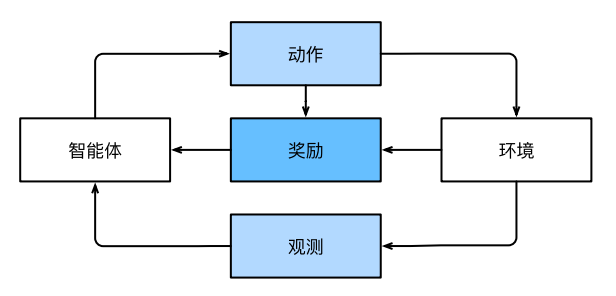
- 在任何时间点上,强化学习agent可能知道⼀个好的策略,但可能有许多更好的策略从未尝试过的。强化学习agent必须不断地做出选择:是应该利⽤当前最好的策略,还是探索新的策略空间。
- 强化学习的目标:
- 产⽣⼀个好的策略(policy)。策略会控制强化学习agent从环境观察映射到⾏动的功能。
- 强化学习的作用:
- 可以解决许多监督学习⽆法解决的问题,且可以将任何监督学习问题转化为强化学习问题。
- 常见强化学习问题
- 马尔可夫决策过程:环境可被完全被观察。
- 上下文赌博机:状态不依赖于之前操作。
- 多臂赌博机:没有状态,只有一组最初未知回报的可用动作。