数据处理和统计分析——04 Pandas DataFrame
1 Pandas DataFrame简介
- Pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能;
- DataFrame和Series是Pandas最基本的两种数据结构;
- DataFrame用来处理结构化数据(SQL数据表,Excel表格);
- Series用来处理单列数据,也可以把DataFrame看作由Series对象组成的字典或集合
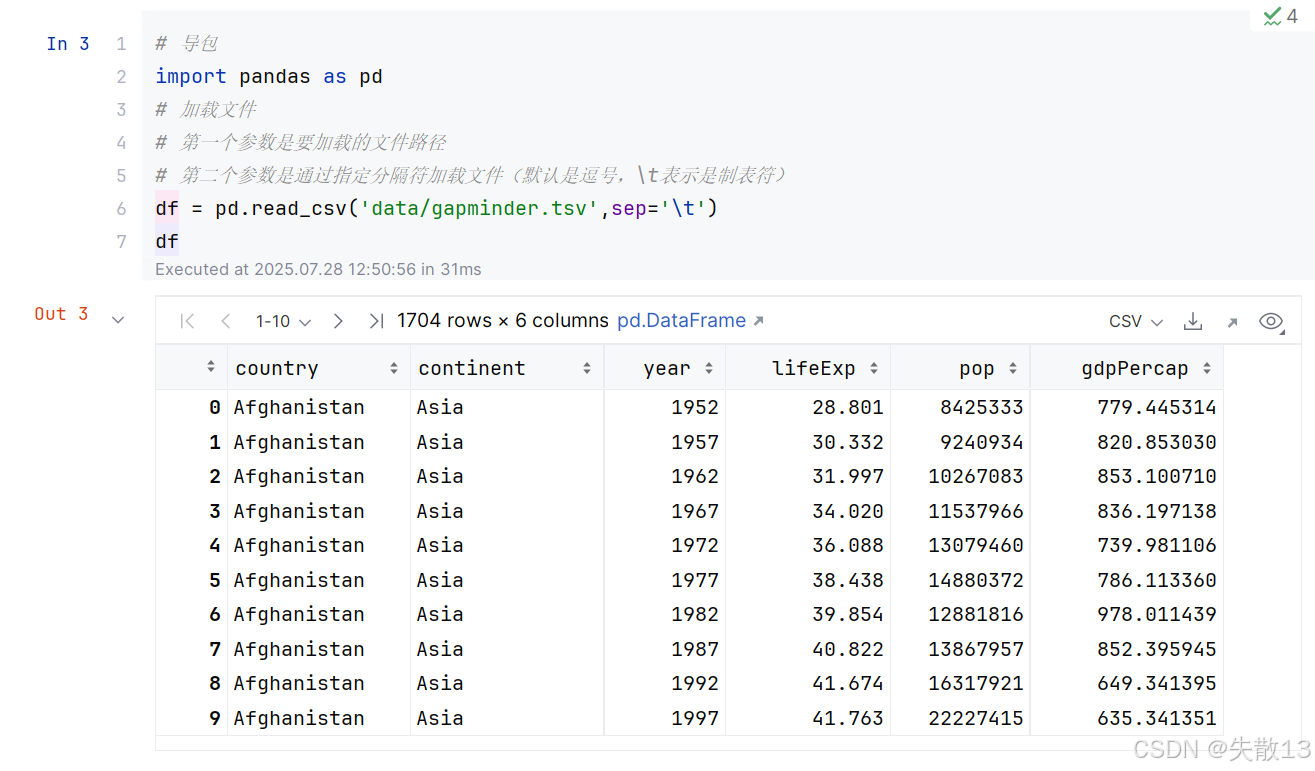
2 加载数据集
-
目的:
- 做数据分析首先要加载数据,并查看其结构和内容,对数据有初步的了解;
- 查看行,列数据分布情况;
- 查看每一列中存储的信息的类型;
-
步骤:
- tsv,即Tab-Separated Values
-
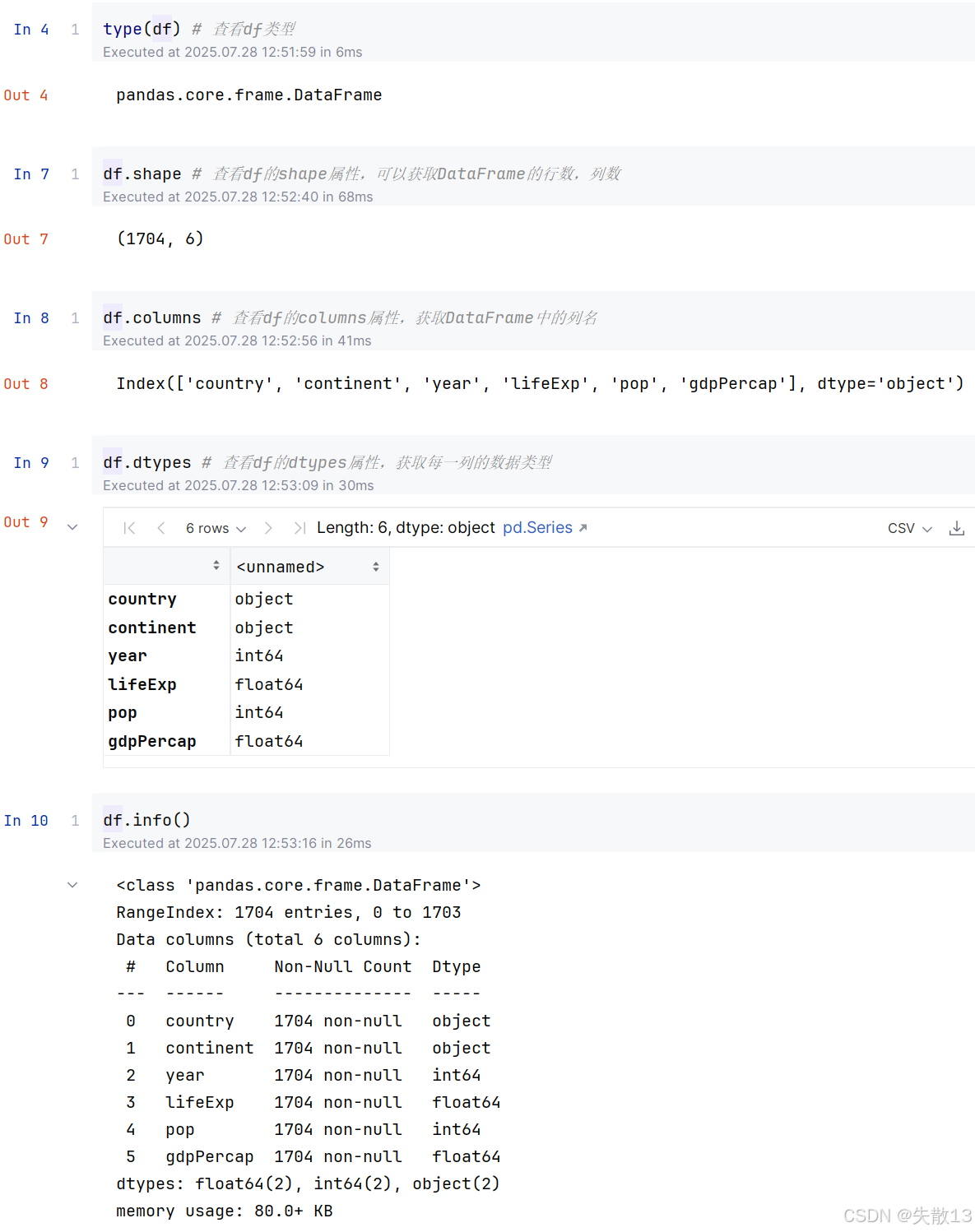
查看数据类型及属性:
-
Pandas和Python常用数据类型对照
Pandas 类型 Python 类型 说明 Object string 字符串类型 int64 int 整形 float64 float 浮点型 datetime64 datetime 日期时间类型
3 查看部分数据
3.1 根据列名加载部分列数据
-
df['列名']:加载一列数据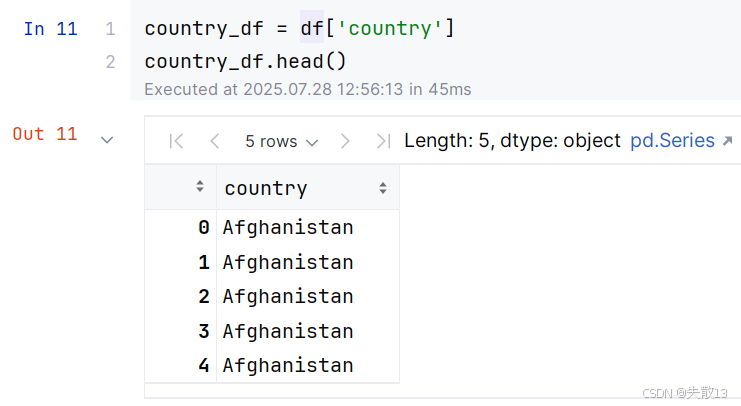
-
df[['列名1','列名2',...]]:加载多列数据- 注意:这里是两层
[],可以理解为df[列名的list]
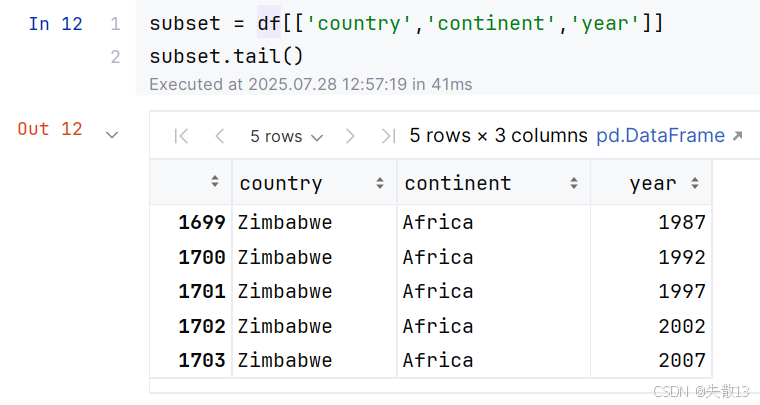
- 注意:这里是两层
3.2 按行加载部分数据
-
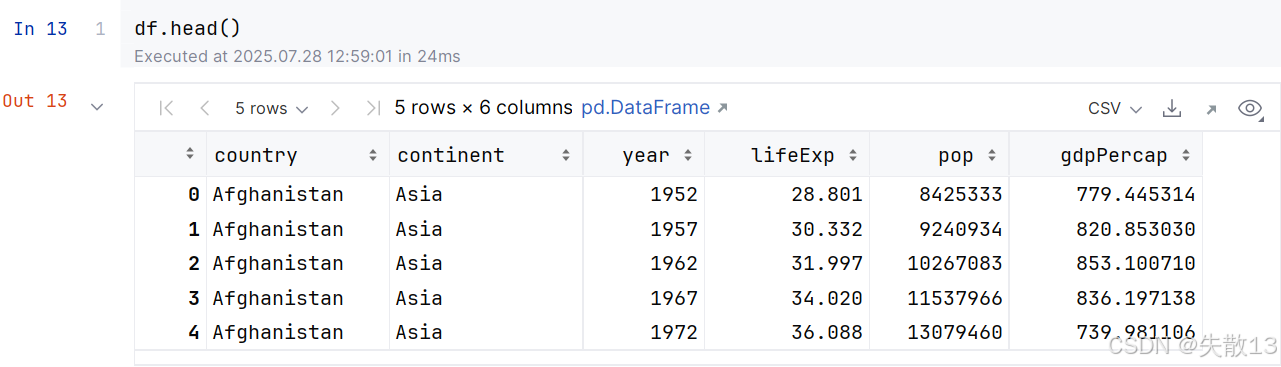
行索引介绍:
- 最左边一列是行号,也就是DataFrame的行索引;
- Pandas默认使用行号作为行索引;
-
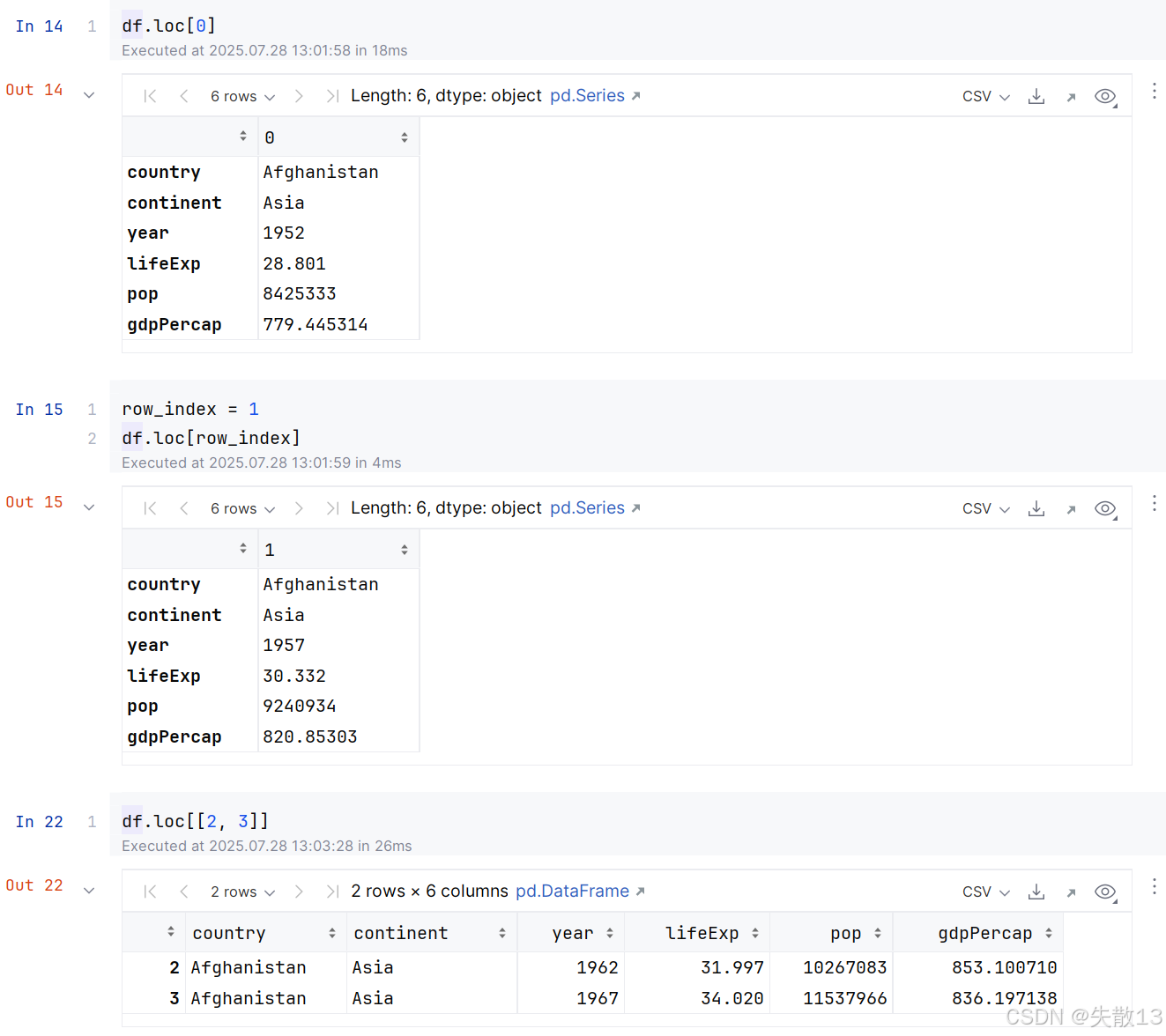
loc[]:传入单个或多个行索引,可以获取到DataFrame的单行或多行数据- 注意:若传入多个行索引,那么这多个行索引必须是一个列表;
-
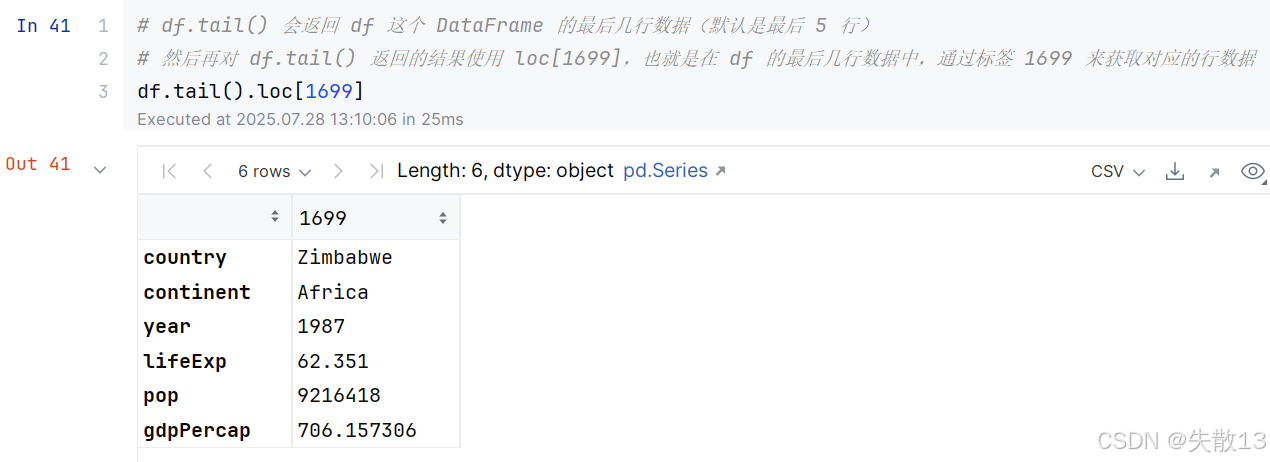
tail():获取最后一行数据
-
可以组合使用:
3.3 loc和iloc
-
在 Python 的
pandas库中,loc和iloc都是用于数据选取的索引器,但它们在使用方式和选取依据上存在明显区别;loc:基于**标签(label)**来选取数据。这里的标签可以是行索引标签、列索引标签。比如在一个 DataFrame 中,如果行索引是自定义的字符串,像['row1', 'row2'],或者是数值但表示特定含义(非默认整数位置) ,就可以用loc按照这些自定义的标签来获取数据;iloc:基于**整数位置(integer position)**来选取数据。它把 DataFrame 的行和列看作是从 0 开始编号的数组,通过整数位置来访问特定的行和列;
-
例:假设有如下的
DataFrame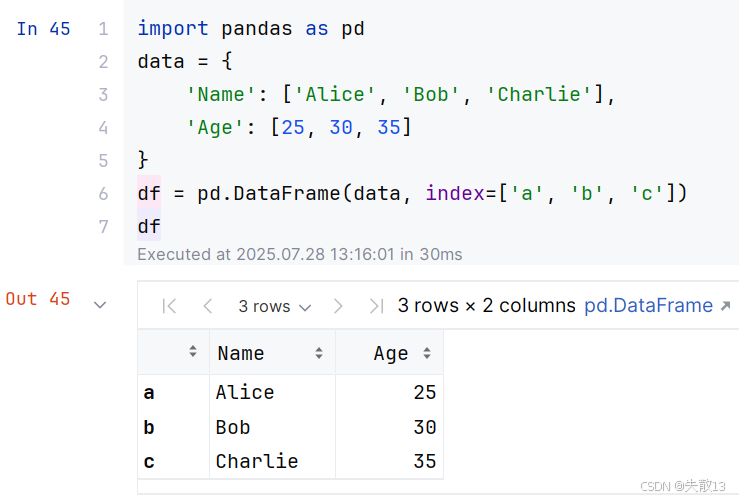
-
loc的使用: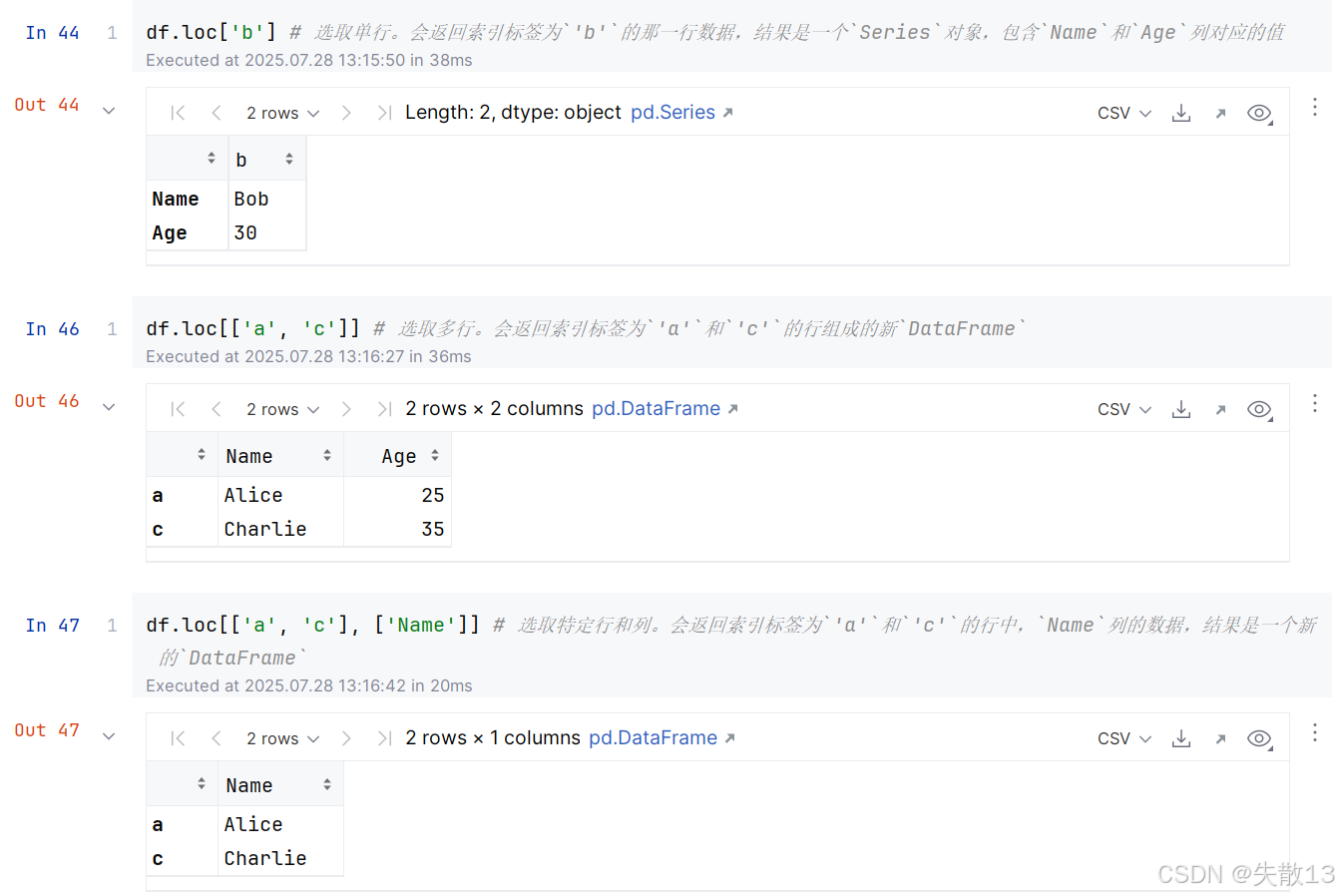
-
iloc的使用: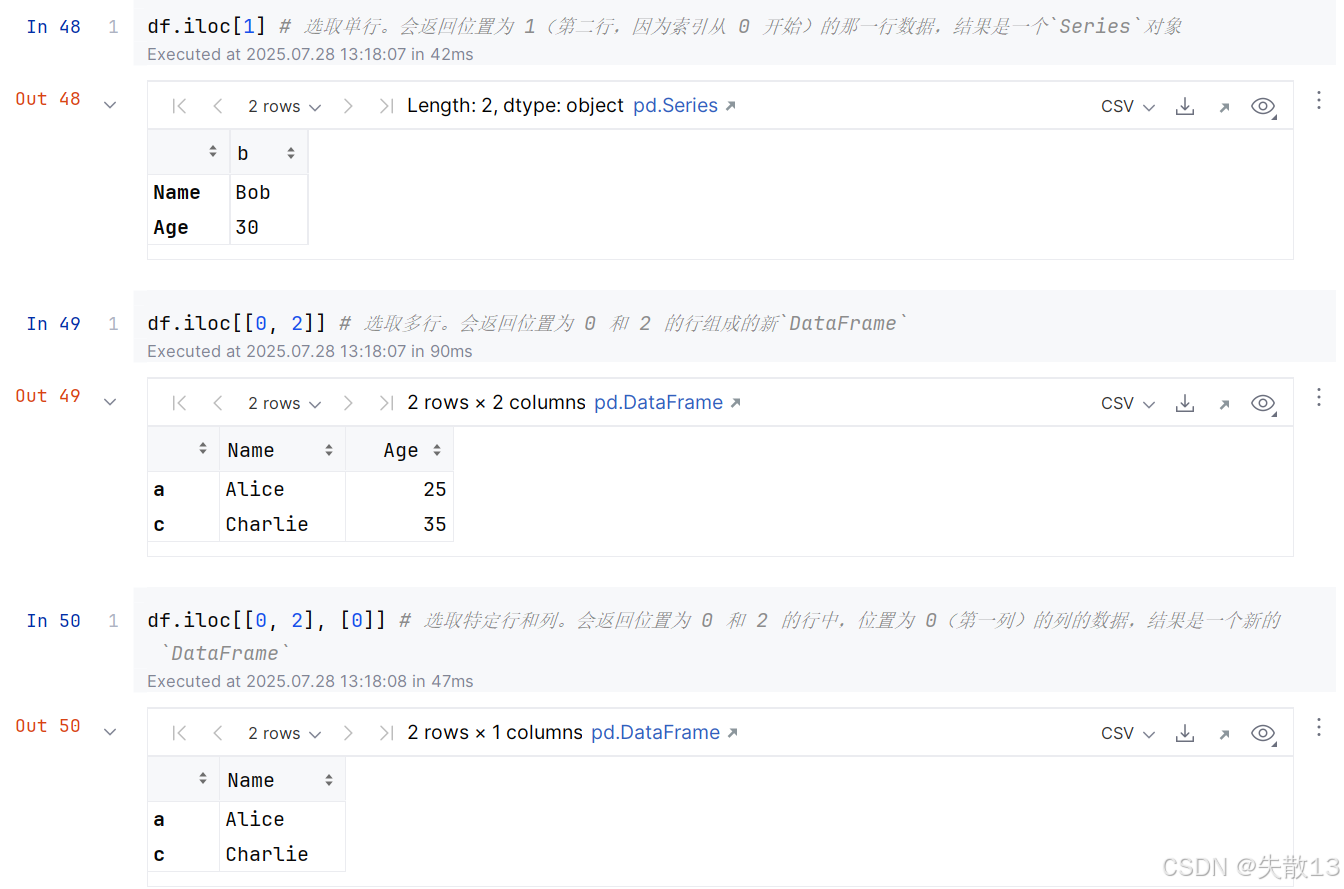
-
-
切片操作区别
loc切片:使用loc进行切片时,端点是包含的。比如df.loc['a':'b'],会返回索引标签从'a'到'b'的所有行(包含'a'和'b');iloc切片:使用iloc进行切片时,端点是不包含的,类似 Python 普通的列表切片规则。比如df.iloc[0:2],会返回位置从 0 到 1(不包含 2)的行,也就是第一行和第二行;
-
布尔索引:
loc:loc可以接受布尔型的Series或者DataFrame来进行数据筛选。例如df.loc[df['Age'] > 28],会返回Age列中值大于 28 的所有行;iloc:iloc也可以使用布尔型的Series来筛选行,但不能直接使用布尔型DataFrame筛选列(除非转换为整数位置的形式) ,比如df.iloc[(df['Age'] > 28).values],(df['Age'] > 28).values将布尔型Series转换为布尔型数组 ,以此筛选出行。
3.4 获取指定行或列的数据
-
先来看一下df中有哪些列:

-
df.loc[ : , [列名]]:取出所有行的一列或多列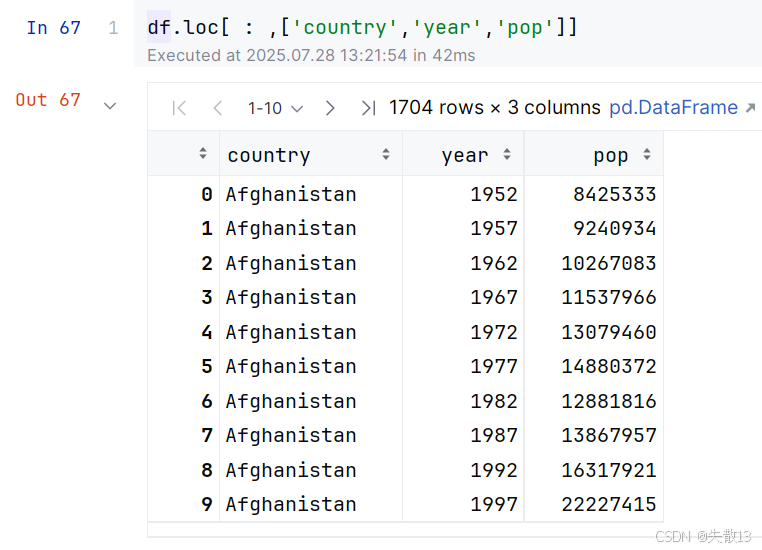
-
df.iloc[ : , [列序号]]:取出所有行的一列或多列。列序号可以使用-1代表最后一列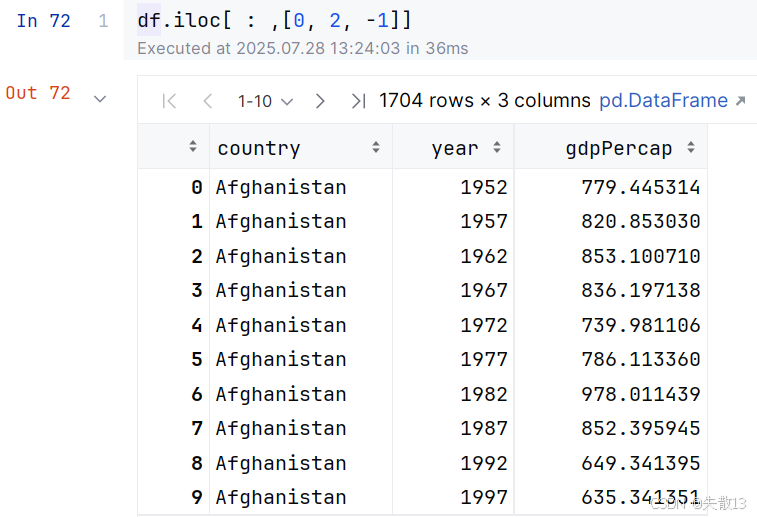
-
通过
range()生成序号,结合iloc获取连续多列数据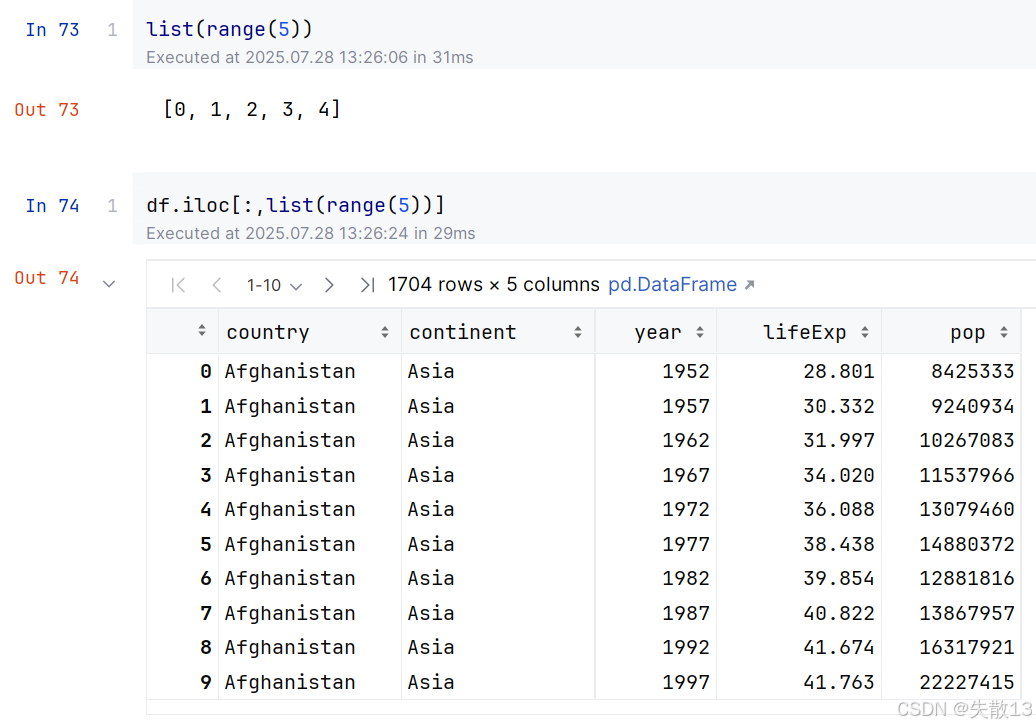
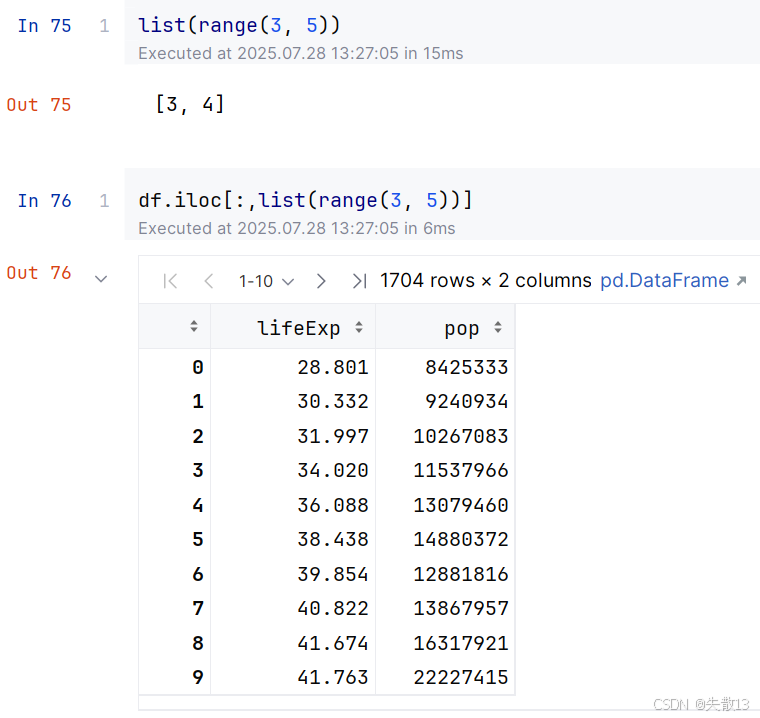
-
在
iloc中使用切片语法获取几列数据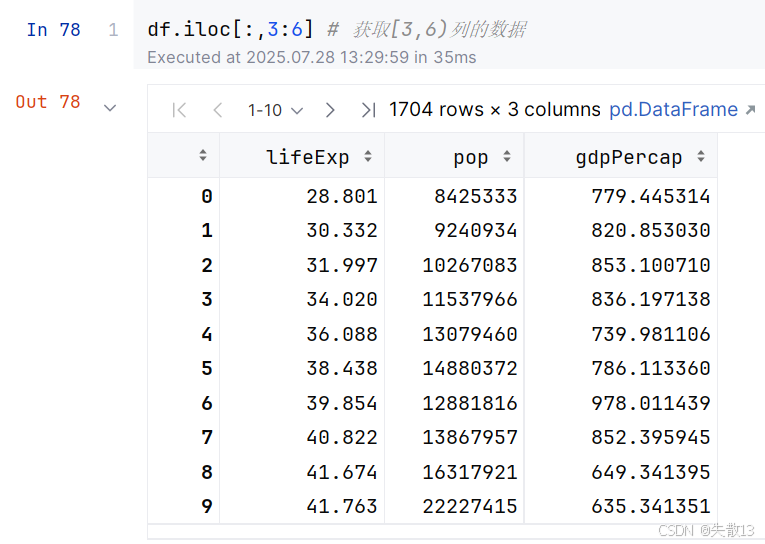
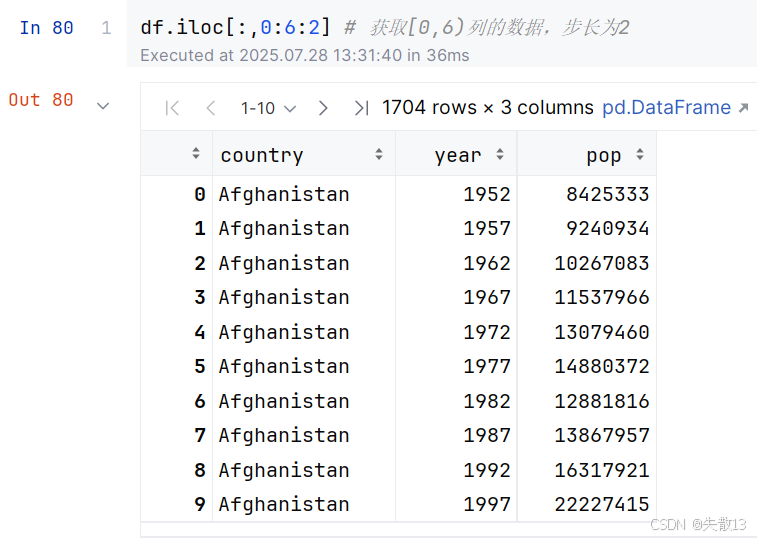
-
使用
loc或iloc获取指定行,指定列的数据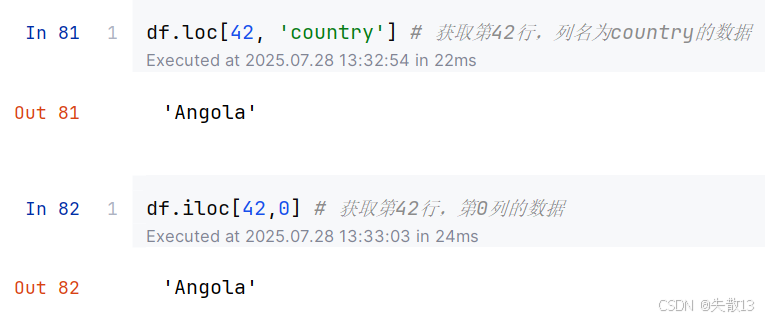
-
获取多行多列:
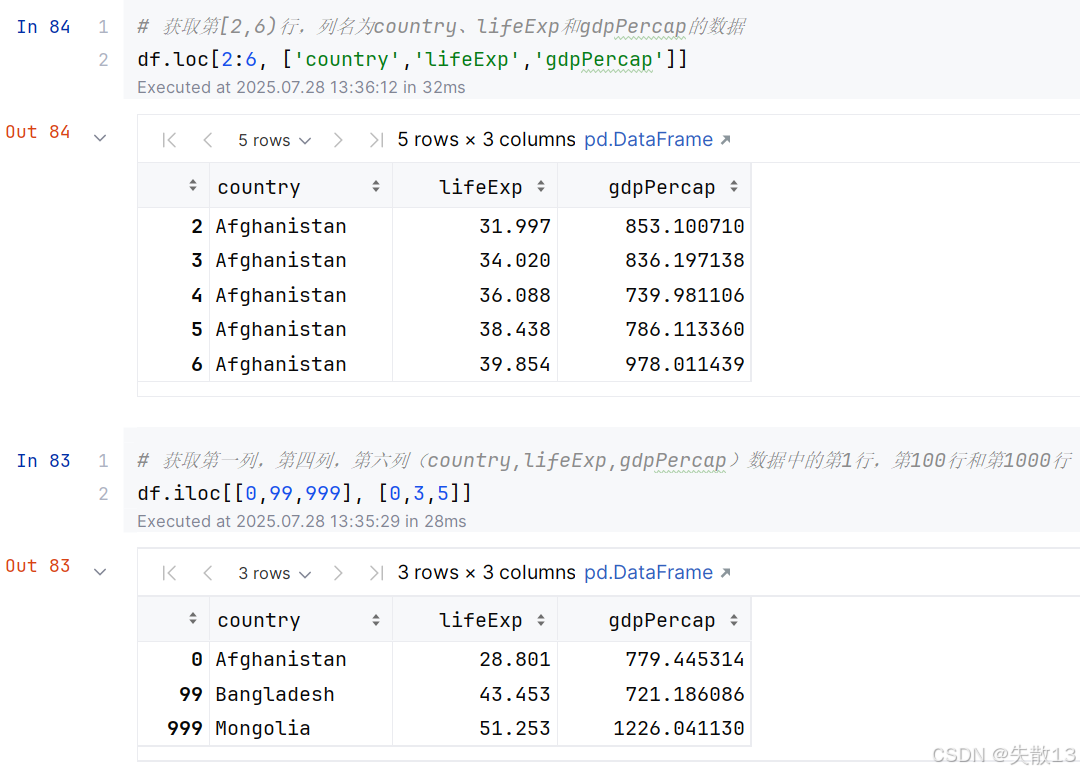
4 分组-聚合计算
4.1 简介
-
在我们使用Excel或者SQL进行数据处理时,Excel和SQL都提供了基本的统计计算功能;
-
当我们再次查看
gapminder.tsv的数据的时候,可以根据数据提出几个问题:- 每一年的平均预期寿命是多少?每一年的平均人口和平均GDP是多少?
- 如果我们按照大洲来计算,每个大洲的平均预期寿命,平均人口,平均GDP情况又如何?
- 在数据中,每个大洲列出了多少个国家和地区?
-
对于上面提出的问题,需要进行分组-聚合计算
- 先将数据分组(比如对于第一个问题的第一个小问,可以按照年份将相同年份的数据分成一组);
- 对每组的数据再去进行统计计算,如:求平均,求每组数据条目数(频数)等;
- 再将每一组计算的结果合并起来。
4.2 分组-聚合方式
-
对于第一个问题的第一个小问,可以按照年份将相同年份的数据分成一组:可以使用DataFrame的
groupby()方法完成分组-聚合计算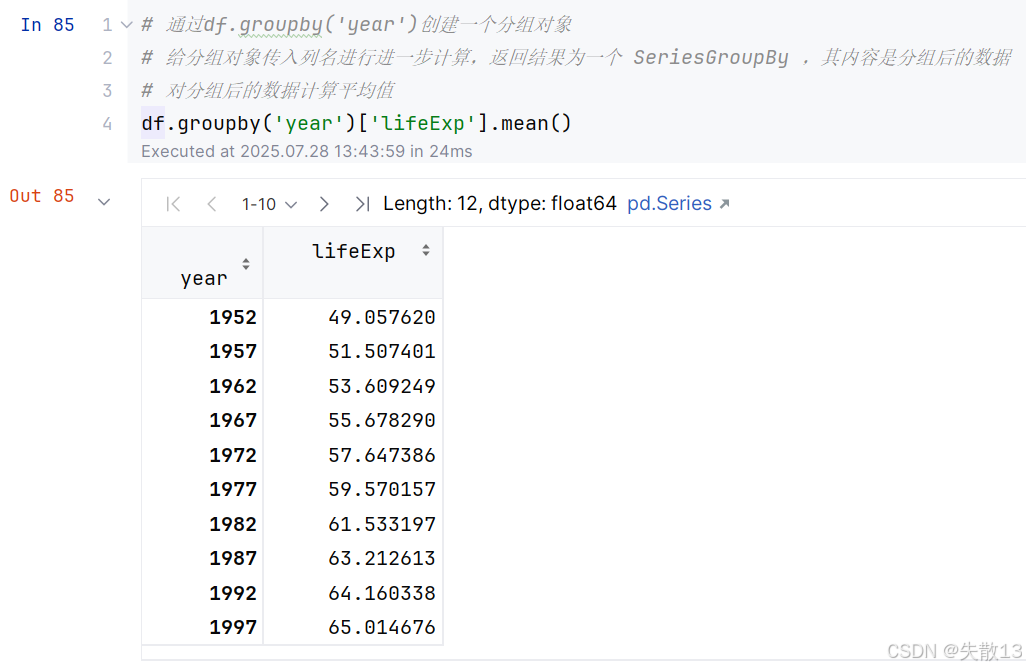
-
若想要的得到的返回结果是 DataFrame:
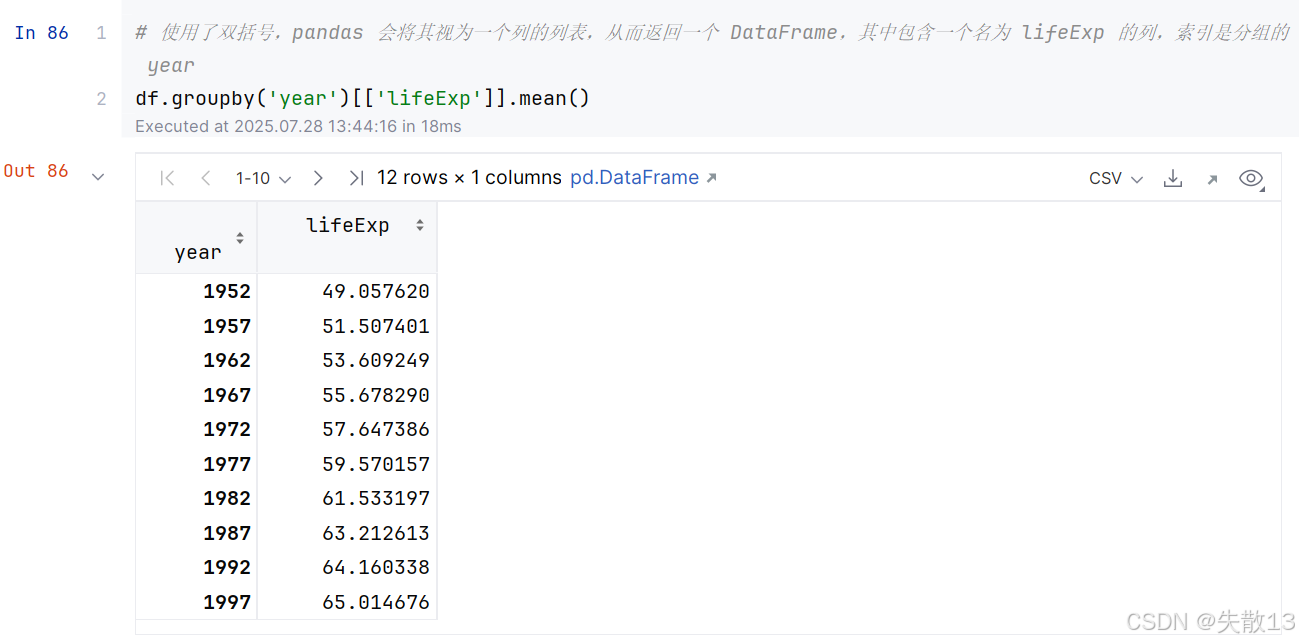
-
对多列进行分组聚合
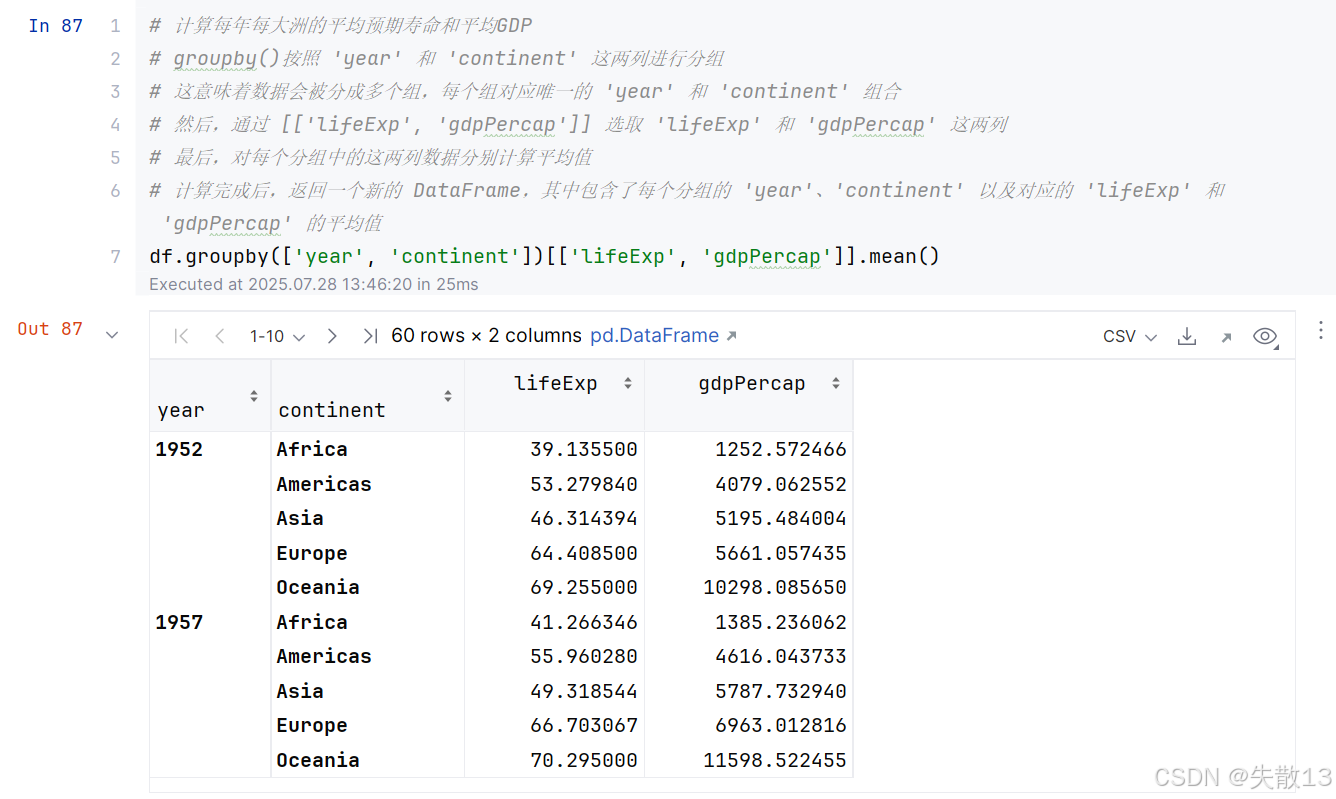
-
对单列多项进行分组聚合
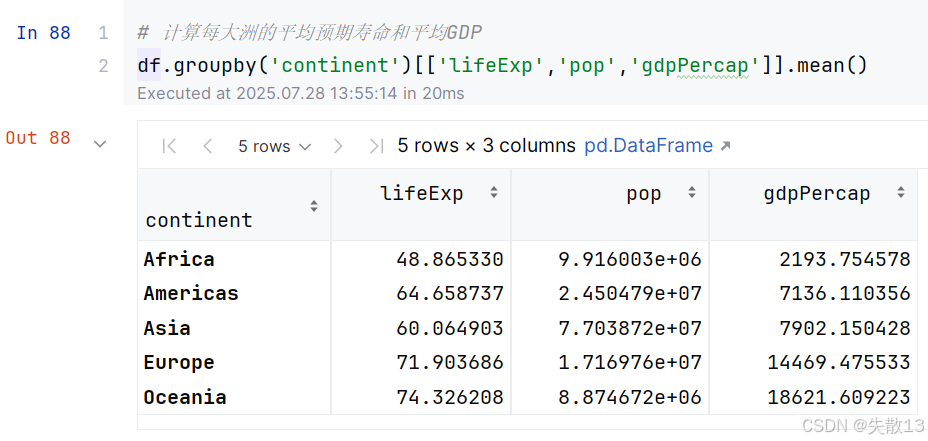
4.3 分组频数计算
-
nunique():计算每个分组中唯一值的数量;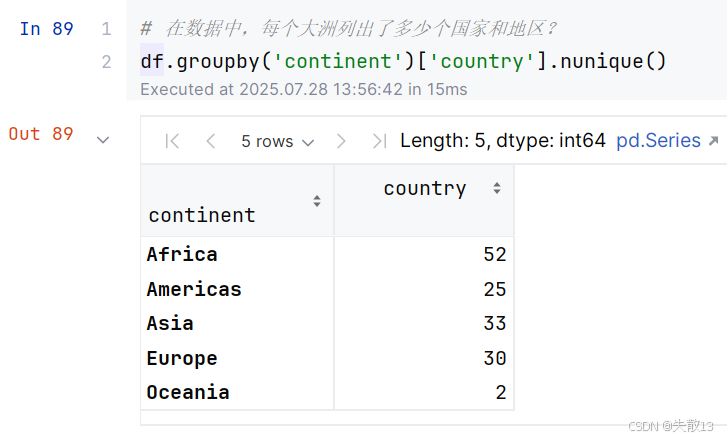
-
value_counts():计算每个分组中每个值出现的次数;
5 基本绘图
-
对某个
Series对象调用plot()方法,pandas会自动使用matplotlib库来绘制一个折线图;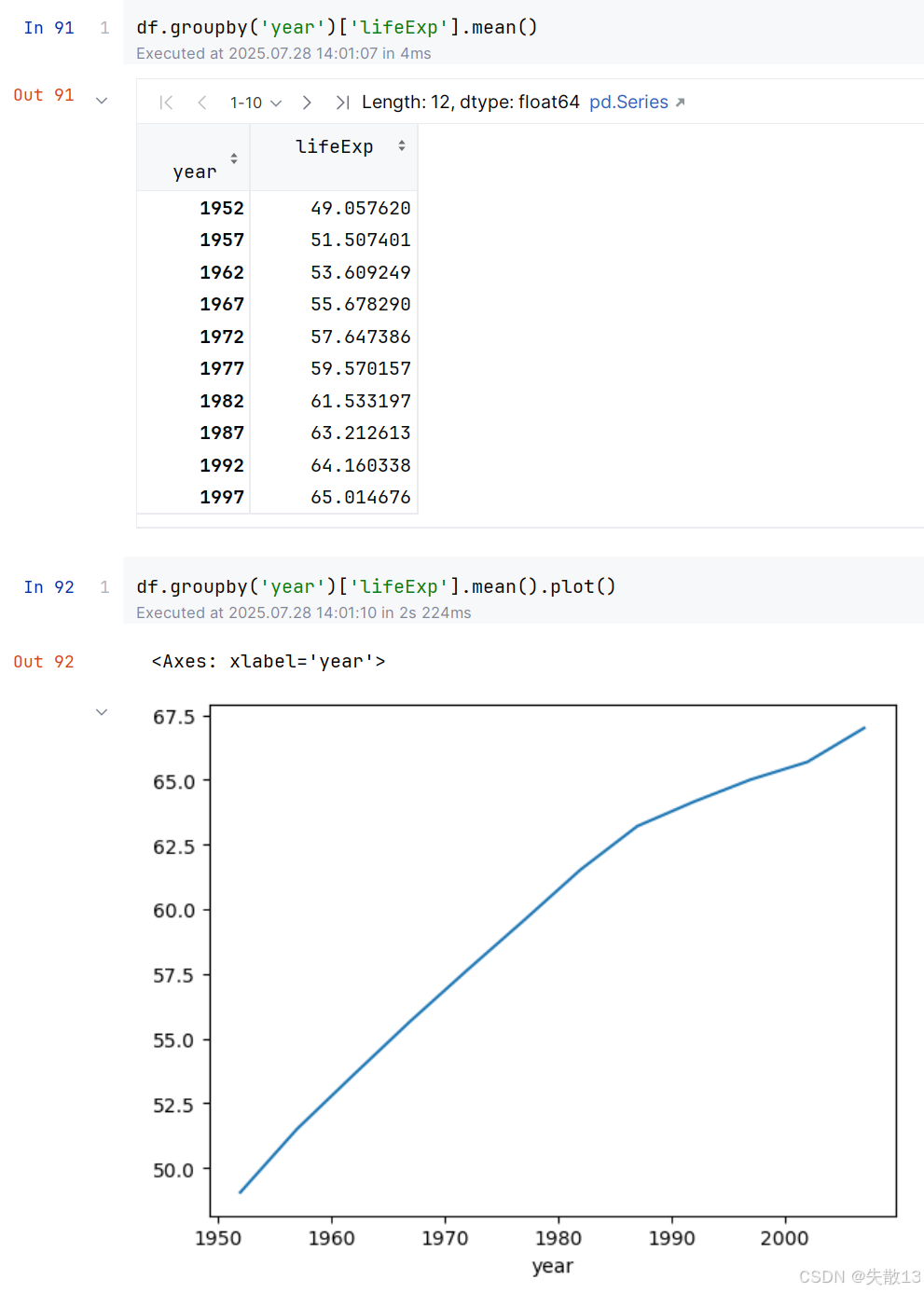
- x 轴是年份(
year),y 轴是平均预期寿命(lifeExp的平均值)
- x 轴是年份(