从零开始学习Dify-爬取网站文章,批量提取和输出热点摘要(十)
概述
本篇文章将带领大家从零开始,通过一个实际案例掌握如何使用Dify结合Firecrawl工具,实现对指定AI资讯网站的内容进行快速批量爬取和热点摘要提取,轻松实现工作流的转化与发布。
工作流配置
2.1 安装Firecrawl工具
- 在工具中输入Firecrawl,找到后点击安装。
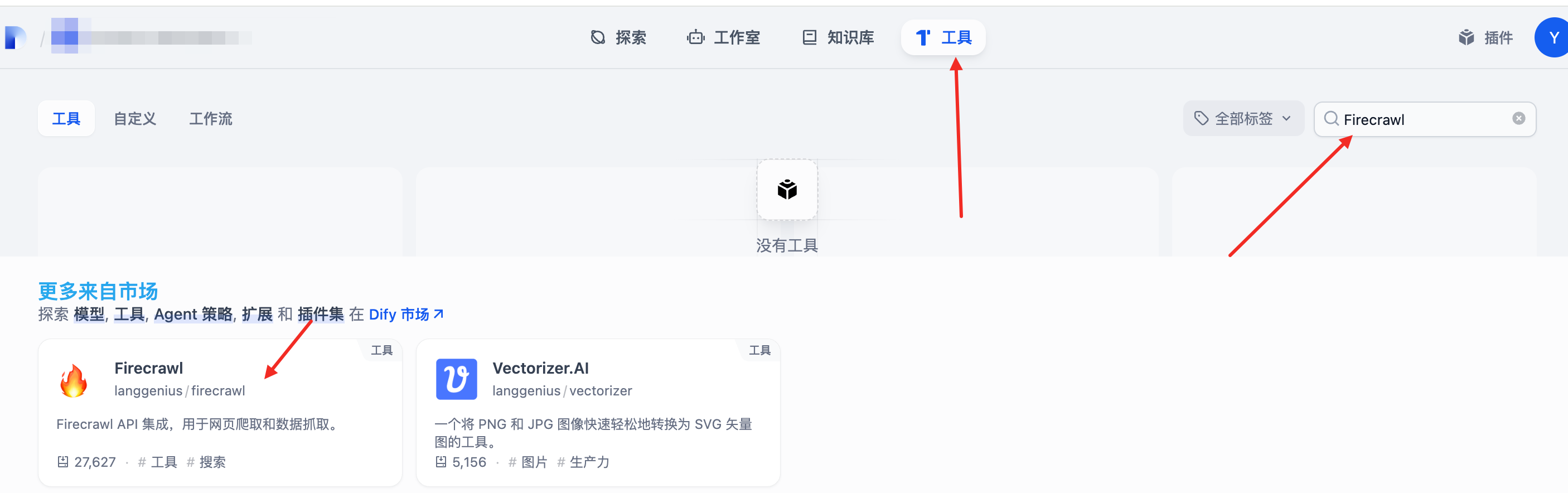
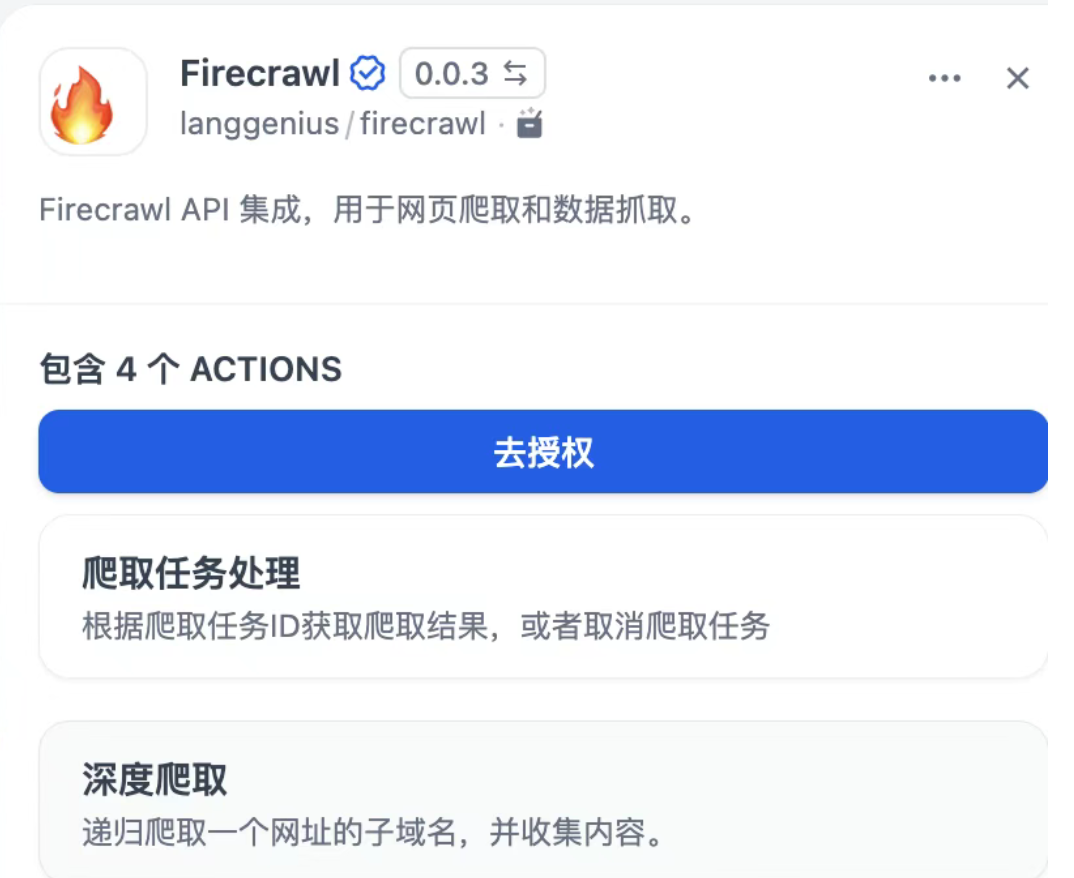
- 点击 firecrawl,去授权,注册后获取并填入密钥。
2.2 创建Dify应用
- 点击创建工作流,命名 "AI资讯助手"
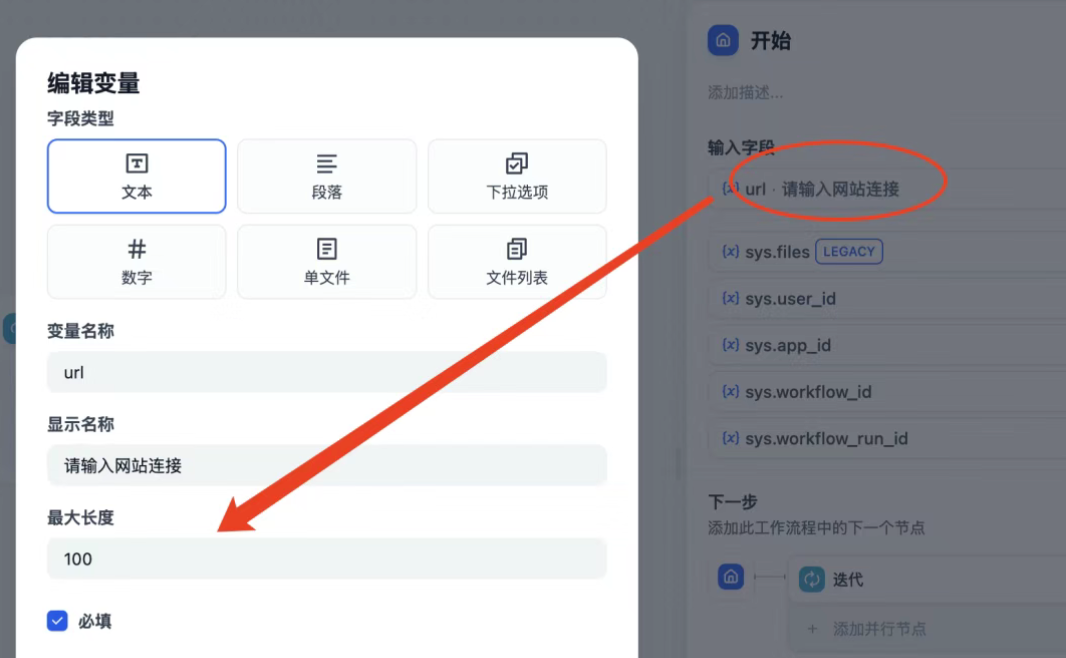
- 配置开始节点
- 添加变量,选取文本类型,用于输入需要抓取网页URL。
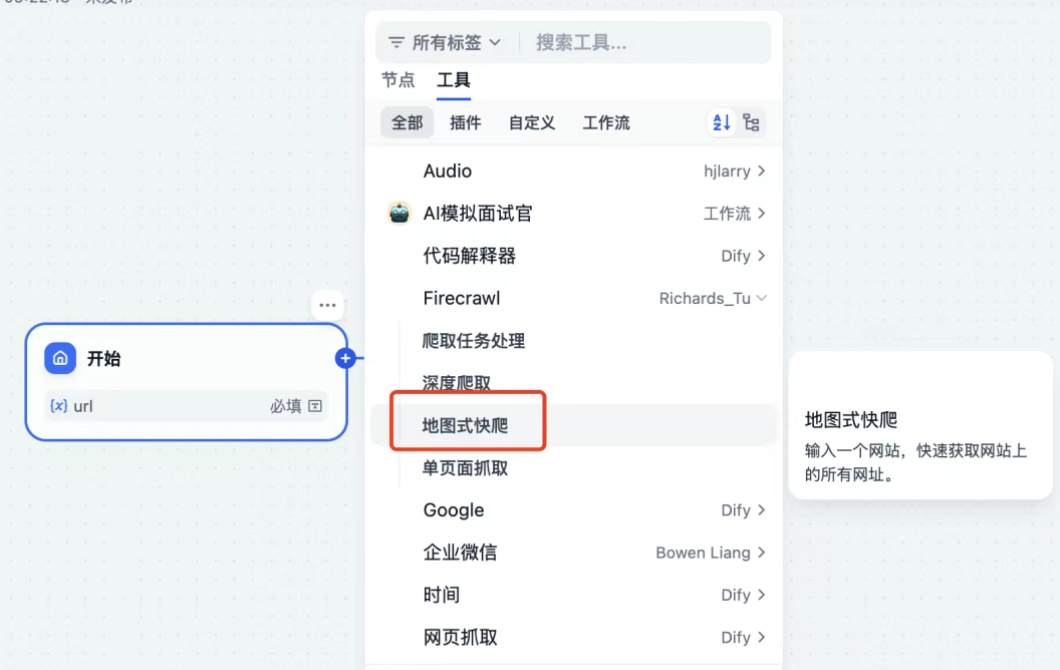
- 配置网页工具节点
- 选择“工具”节点,点击选取已安装的
Firecrawl。 - 选用“地图式快爬”功能,能够自动获取网站上所有可用的网址。
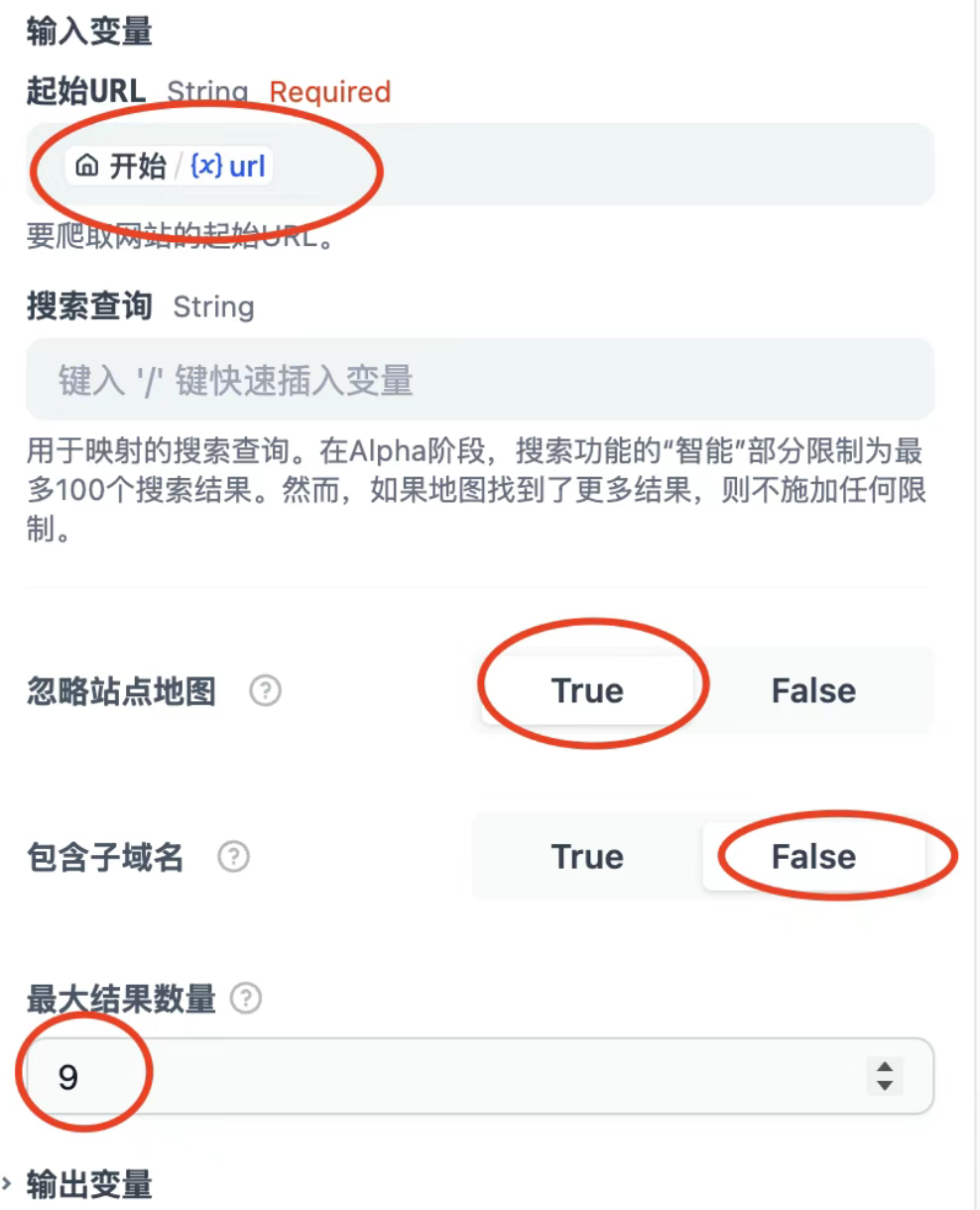
- 设置输入变量:链接到开始节点定义的URL参数。
- 注意以下参数的配置说明(演示场景):
- 忽略站点地图:勾选
- 不包含子域名:勾选
- 最大结果数量:设置为9(实际使用时,可根据需求适当调整)
- 选择“工具”节点,点击选取已安装的
2.3 调试
初次配置后,建议先进行一次调试,以确保爬取的结果符合预期。
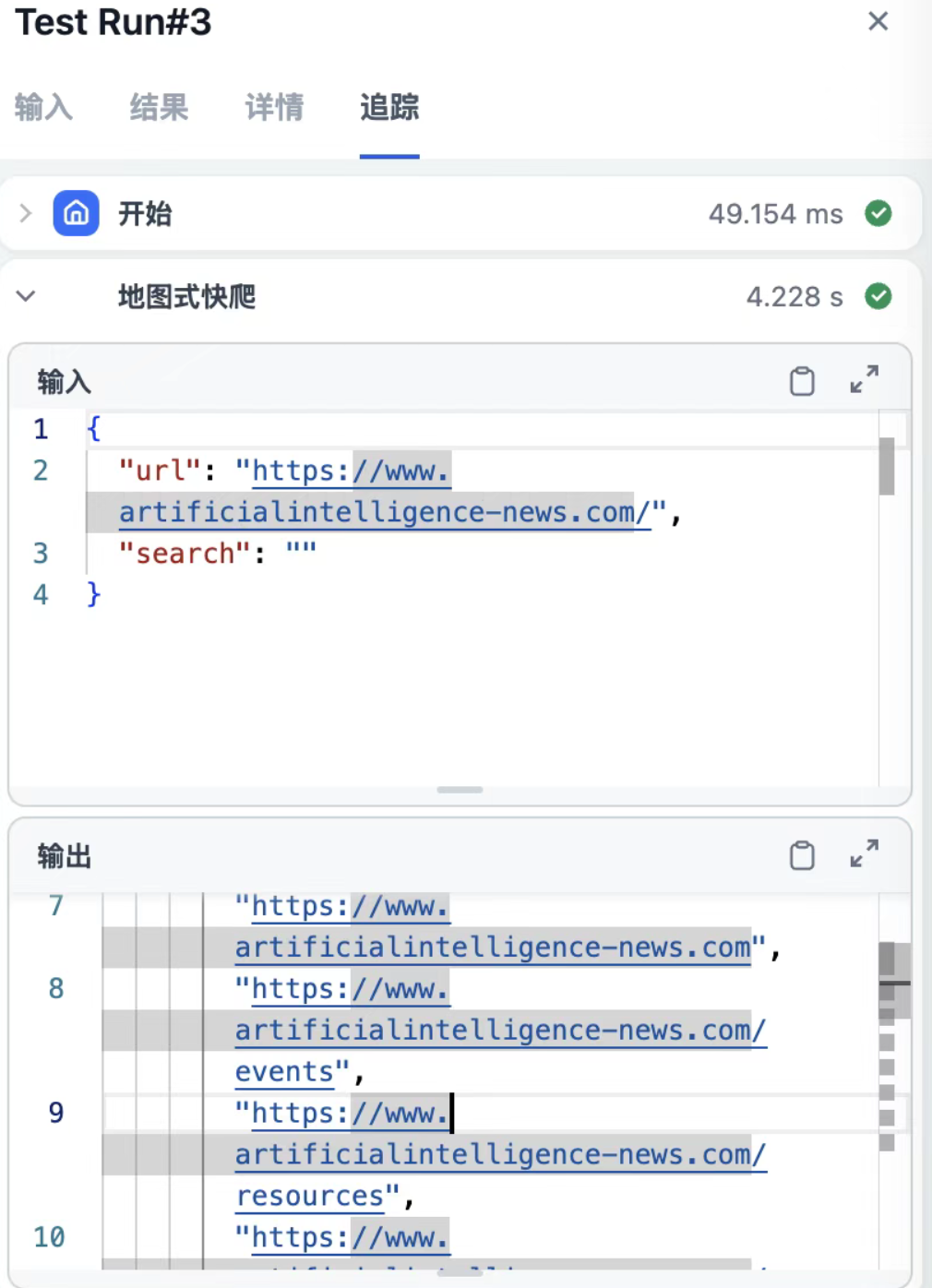
- 点击“调试”,检查爬取结果。
- 一般情况下,Firecrawl爬取速度较快,通常只需几秒钟便能看到输出内容。
看到结果正常,即表示网页抓取配置成功。
2.4 爬取多个文章URL
在前置节点添加一个数据转换,将爬取到的json内容转换为文本。将其转换后的输出,作为LLM模型的输入。
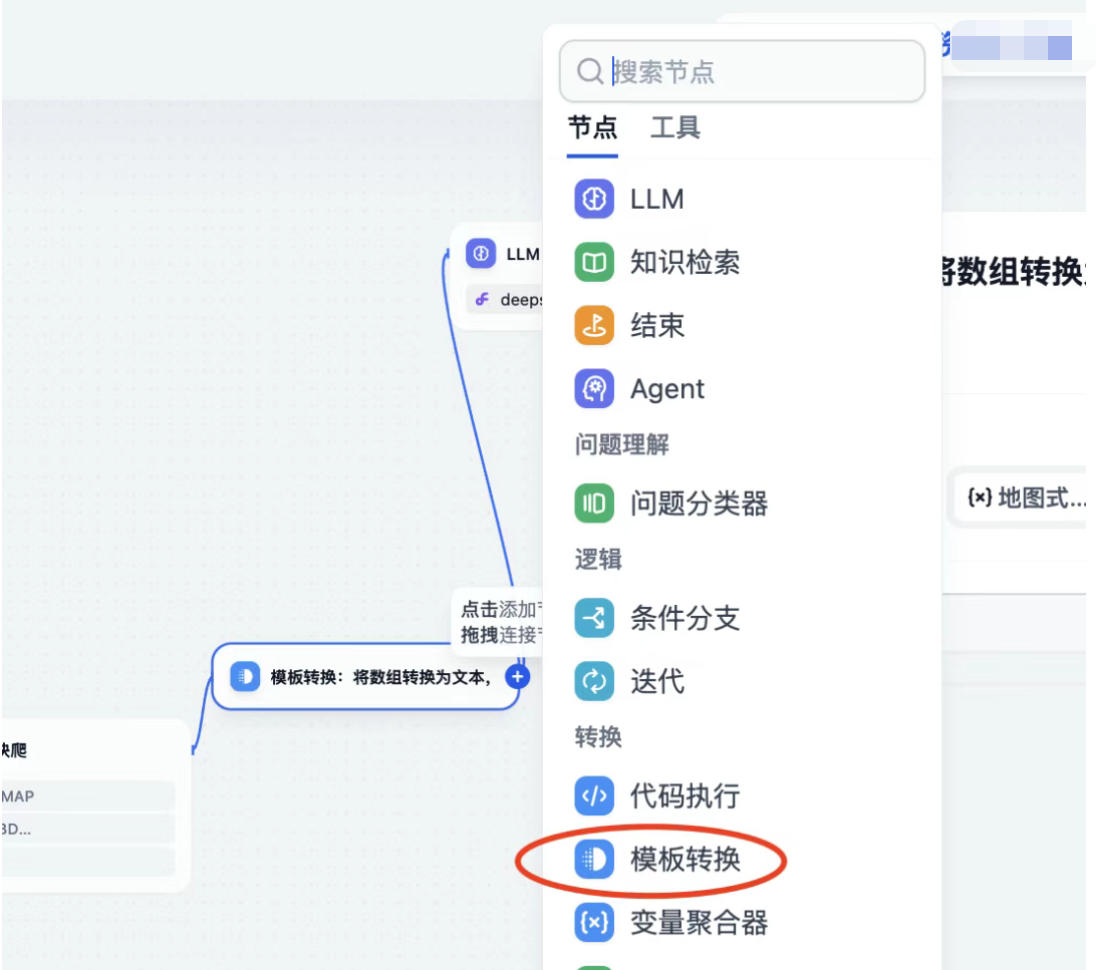
- 同理,大模型提炼输出后的输出是文本格式,因此为了让迭代可以使用,需要转换为数组,添加代码模块。
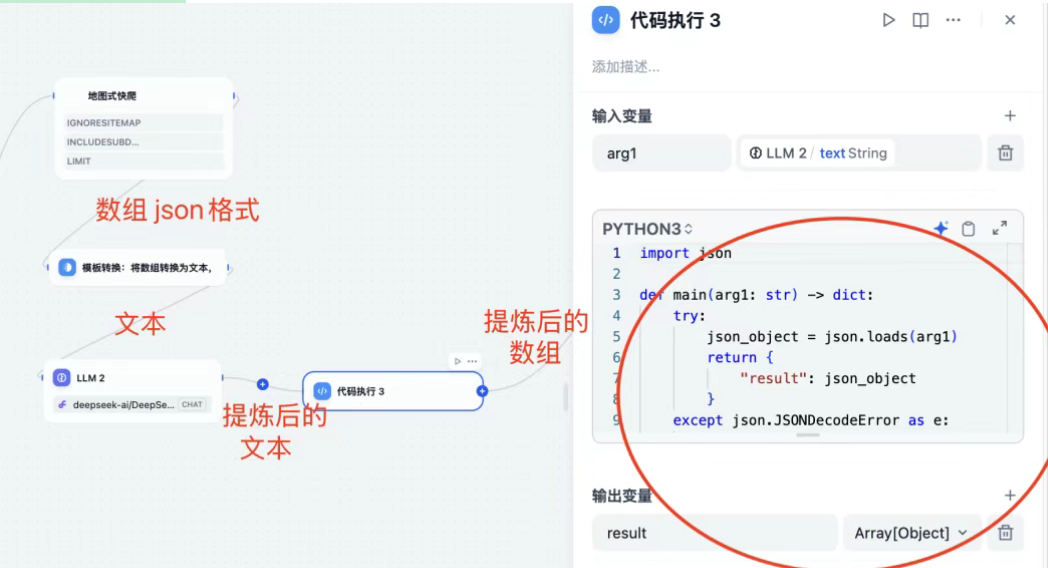
- 转换代码:
import jsondef main(arg1: str) -> dict:try:# 尝试将输入字符串解析为JSON对象json_object = json.loads(arg1)return {"result": json_object}except json.JSONDecodeError as e:# 处理JSON解析错误并返回错误信息return {"result": None,"error": f"Invalid JSON: {str(e)}"}
- 最终输出:一个N*2的数组(这里只爬取了两条,N=2)
{"result": [{"title": "Artificial Intelligence News","url": "https://www.artificialintelligence-news.com/artificial-intelligence-news"},{"title": "Artificial Intelligence News - Page 2","url": "https://www.artificialintelligence-news.com/artificial-intelligence-news/page/2"}]
}至此,我们完成了从一个热点网页爬取多个热点文章URL,并进行清洗,成为了一个可以给到迭代使用的数组。前置所有步骤如下:
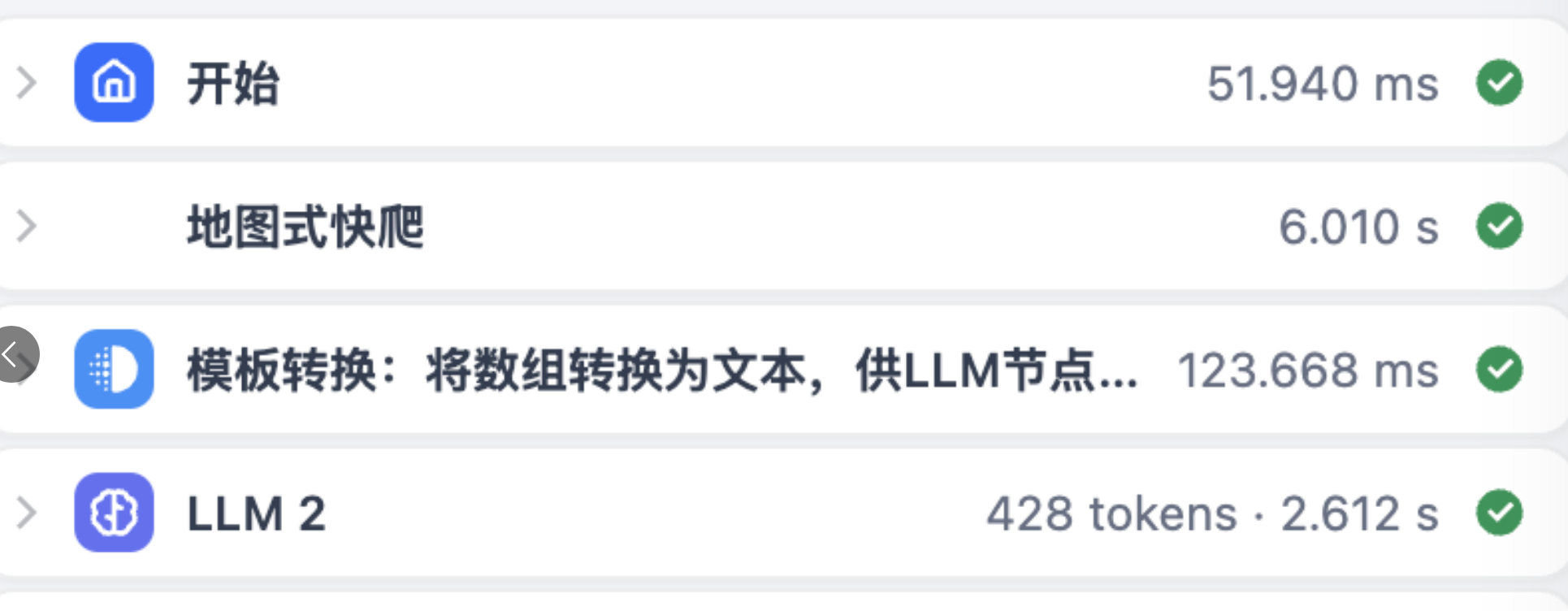
2.5 内容提取
按照上面的输入,第一步我们需要先从第一条链接里,精确地拿到URL链接,然后才可以给到网页抓取工具。否则,就还是会报错。
- 添加迭代转换:取出URL,输入 VS 输出如下:
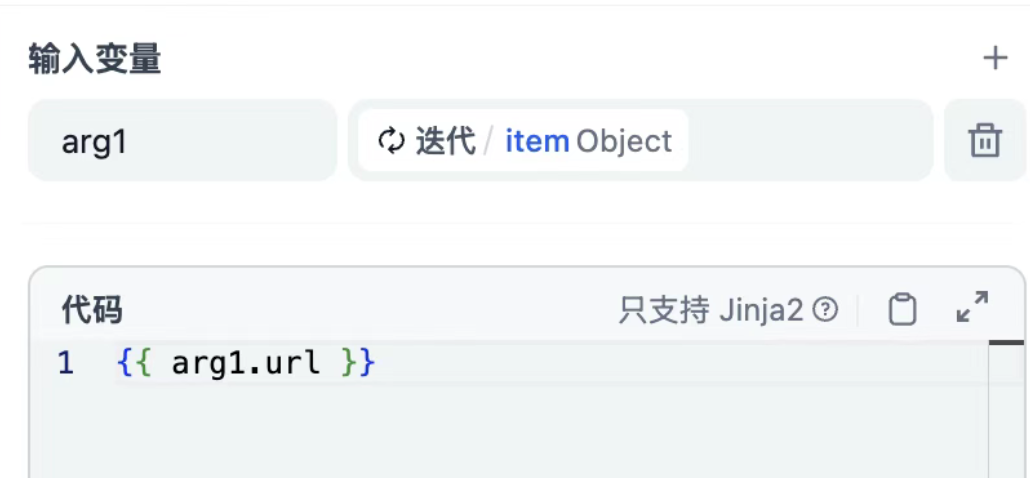
- Firecrawl:单页面抓取,拿到网页重点信息
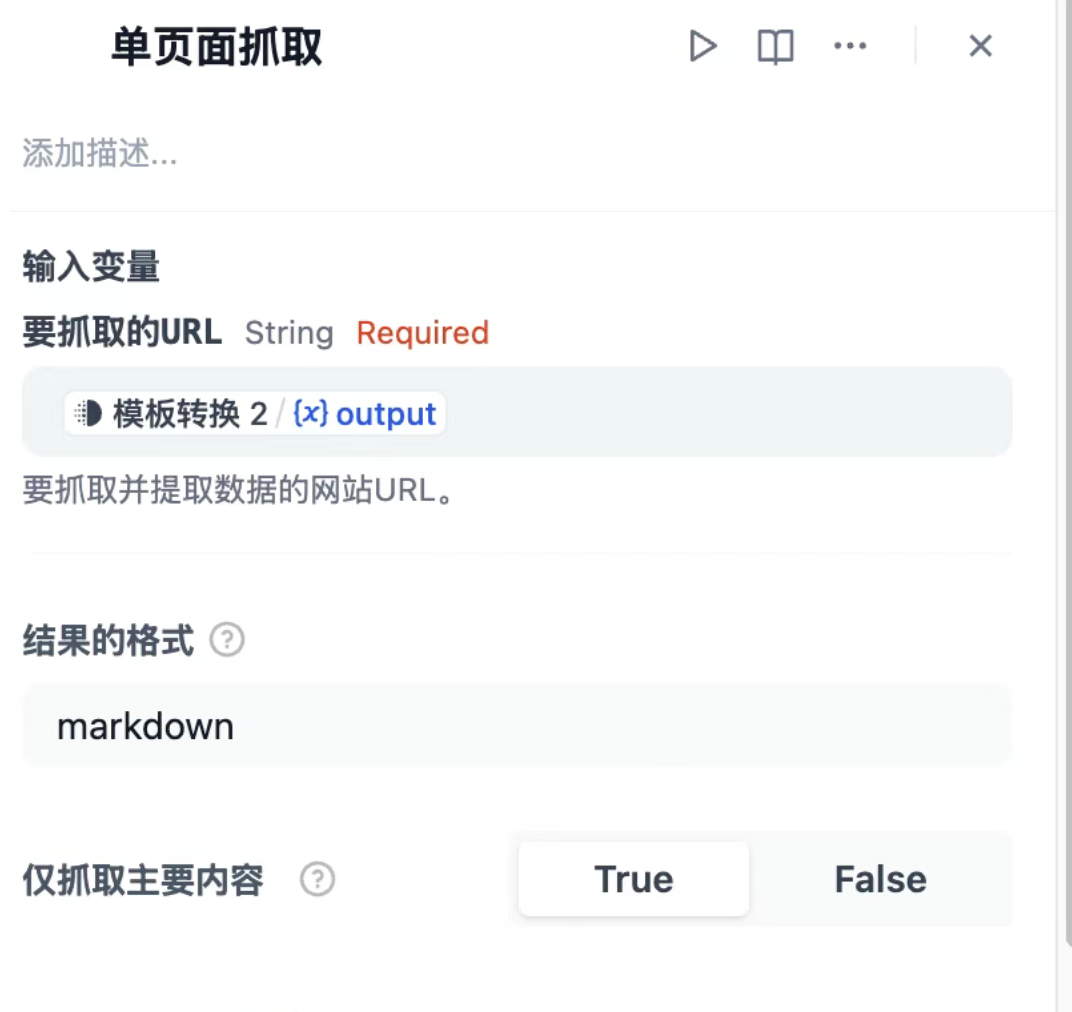
- LLM大模型:输入提示词,将网页抓取的信息进行提炼
1. 标题:
2. 发布时间:
3. 正文总结:(不超过300字)
4. URL链接:2.6 内容输出
- 迭代输出的结果是数组格式,需要转化为文本;采用模板转换节点。
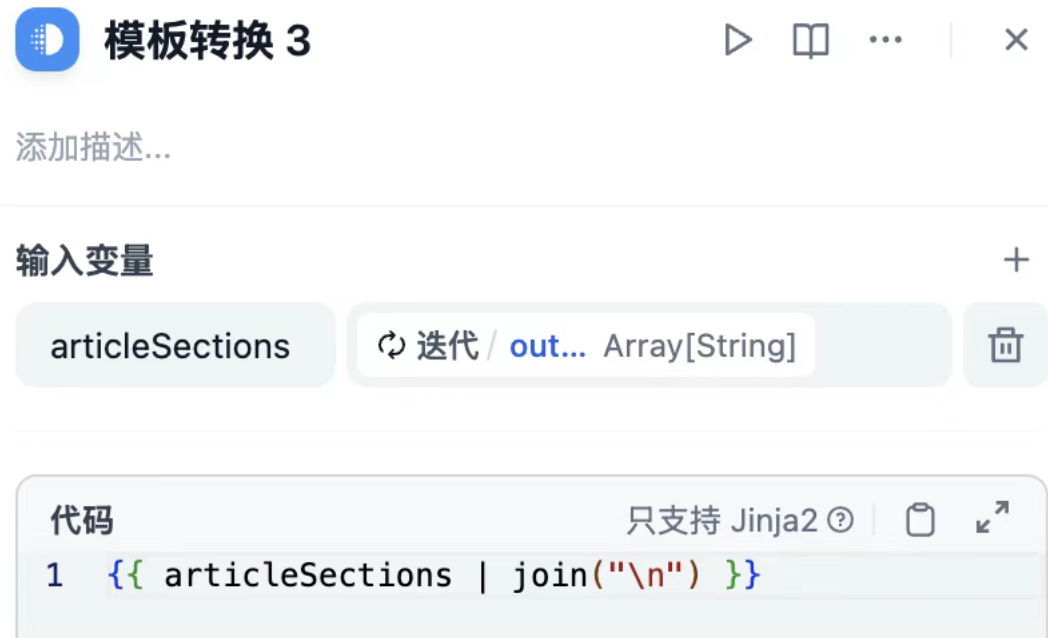
- 最终,我们拿到了想要的结果。

总结
通过以上步骤,我们成功实现了Dify与Firecrawl工具的整合,能够快速批量爬取并提炼指定AI资讯网站内容的热点摘要。这不仅有效提高了信息处理效率,也为进一步扩展和深入应用提供了有力支撑。未来,可以继续探索更多工具的集成和工作流优化,使Dify成为更加强大的智能化工具平台。