[工具类] 分片上传下载,MD5校验
参考文章
Spring Boot 实现高效文件上传:分片上传、MD5校验、线程池处理高并发_springboot 分片上传文件-CSDN博客
引言
在现代web应用中,文件上传是一个常见而重要的功能。本文将介绍如何使用Spring Boot实现高效的文件上传,重点关注前端的分片上传技术、后端使用多线程处理高并发文件上传技术。
前端分片上传
分片上传原理
前端分片上传将大文件分成多个小文件(分片),每个分片独立上传,最后合并成完整文件。这种方式可以有效降低单次上传的复杂度,提高用户体验。
分片上传实现
1、用户选择文件后,JavaScript会将文件分成20MB的分片,并逐个上传。
2、每个分片还会计算其MD5值,以便后端进行校验,同时使用已上传的分片比例显示上传进度。
3、前端使用websocket进行监听,如果后端所有分片合并完成,会往前端的socket发送完成,前端进行显示
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><title>分片上传文件</title><!-- 使用本地路径 --><script src="/js/spark-md5.min.js"></script><!-- 在head中添加WebSocket库 --><script src="/js/sockjs.min.js"></script><script src="/js/stomp.min.js"></script>
</head>
<body><form id="uploadForm"><!-- 文件选择控件 -->文件: <input type="file" id="file" name="file" required><br><!-- 上传进度展示 --><progress id="progressBar" value="0" max="100" style="width: 300px;"></progress><p id="status"></p><button type="submit">提交</button>
</form><script>// 常量定义:每个分片大小20MB(需与后端协商)const chunkSize = 20 * 1024 * 1024;//初始化WebSocket的方法let stompClient;function initWebSocket() {const socket = new SockJS('/upload-websocket');stompClient = Stomp.over(socket);stompClient.connect({}, () => {reconnectAttempts = 0;console.log('WebSocket连接成功');stompClient.subscribe('/topic/mergeStatus', (message) => {try {const result = JSON.parse(message.body);// 验证消息完整性if("COMPLETED" === result.status) {updateStatusUI(result);}} catch (e) {console.error('消息处理错误', e);}});}, (error) => {console.error('连接失败', error);});}function updateStatusUI(result) {const statusEl = document.getElementById("status");statusEl.innerHTML = `<div class="alert alert-success"><strong>✅ 文件合并完成!</strong><p>文件名:${result.fileName}</p><p>总耗时:${result.totalTime}</p></div>`;}// 表单提交事件处理document.getElementById("uploadForm").onsubmit = async function(event) {event.preventDefault(); // 阻止默认表单提交行为initWebSocket();// 获取文件对象const fileInput = document.getElementById("file");const file = fileInput.files[0];if (!file) {alert("请选择文件!");return;}// 计算总分片数(向上取整) 总分片数=文件总字节数/每片字节数const totalChunks = Math.ceil(file.size / chunkSize);// 已上传分片计数器let uploadedChunks = 0;// 分片上传循环for (let chunkNumber = 1; chunkNumber <= totalChunks; chunkNumber++) {// 计算当前分片的起止位置const start = (chunkNumber - 1) * chunkSize;const end = Math.min(start + chunkSize, file.size);// 切割文件获取分片数据const chunk = file.slice(start, end);// 计算分片MD5(需引入SparkMD5库)const md5 = await calculateMd5(chunk);// 构建FormData对象const formData = new FormData();formData.append("file", chunk, file.name); // 分片数据formData.append("md5", md5); // 校验码formData.append("chunkNumber", chunkNumber); // 分片序号formData.append("totalChunks", totalChunks); // 总分片数try {// 执行分片上传await uploadChunk(formData);uploadedChunks++;// 更新进度显示updateProgress(uploadedChunks, totalChunks);} catch (error) {console.error("上传分片失败:", error);document.getElementById("status").innerText = "上传失败,请重试";return; // 出错终止上传}}// 所有分片上传完成提示document.getElementById("status").innerText = "所有分片上传完成,正在合并文件";};/*** 计算文件分片的MD5值* @param {Blob} blob - 文件分片数据* @returns {Promise<string>} MD5哈希值*/function calculateMd5(blob) {return new Promise((resolve, reject) => {const reader = new FileReader();reader.readAsBinaryString(blob);reader.onloadend = function () {const md5 = SparkMD5.hashBinary(reader.result);resolve(md5);};reader.onerror = function (error) {reject(error);};});}/*** 执行分片上传请求* @param {FormData} formData - 包含分片数据的表单*/function uploadChunk(formData) {return new Promise((resolve, reject) => {const xhr = new XMLHttpRequest();xhr.open("POST", "/uploadPart/upload", true);xhr.onload = function() {if (xhr.status === 200) {resolve(xhr.responseText);} else {reject(new Error("上传失败,错误代码:" + xhr.status));}};xhr.onerror = function() {reject(new Error("网络错误"));};xhr.send(formData);});}/*** 更新进度显示* @param {number} uploaded - 已上传数* @param {number} total - 总分片数*/function updateProgress(uploadedChunks, totalChunks) {const percentComplete = Math.round((uploadedChunks / totalChunks) * 100);document.getElementById("progressBar").value = percentComplete;document.getElementById("status").innerText = "上传进度: " + percentComplete + "%";}
</script></body>
</html>后端分片接收
文件上传处理
后端使用Spring Boot接收每个分片,并进行MD5校验:
import io.swagger.annotations.Api;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.messaging.simp.SimpMessagingTemplate;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.util.DigestUtils;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.Resource;
import java.io.*;
import java.nio.channels.FileChannel;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;@RestController
@RequestMapping("/uploadPart")
@Api(tags = "分片上传下载模块")
@Slf4j
public class UploadPartController {@Value("${file.uploadPath}")private String uploadPath;@Resourceprivate ThreadPoolTaskExecutor taskExecutor;@Resourceprivate SimpMessagingTemplate messagingTemplate;long startTime = 0L;/*** 分片上传接口* @param file 分片文件* @param md5 分片校验码* @param chunkNumber 当前分片序号(从1开始)* @param totalChunks 总分片数*/@PostMapping("/upload")public String upload(@RequestParam("file") MultipartFile file,@RequestParam("md5") String md5,@RequestParam("chunkNumber") int chunkNumber,@RequestParam("totalChunks") int totalChunks) throws IOException {// 空文件检查if (file.isEmpty()) {log.warn("上传的文件为空");return "文件为空";}// 确保上传目录存在File uploadDir = new File(this.uploadPath);if (!uploadDir.exists()) {uploadDir.mkdirs();}// 记录第一个分片的上传开始时间if(chunkNumber == 1) {startTime = System.currentTimeMillis();}String originalFilename = file.getOriginalFilename();log.info("开始上传文件: {}, 分片: {}/{}", originalFilename, chunkNumber, totalChunks);// 构建分片文件名,写入分片String chunkFileName = originalFilename + ".part" + chunkNumber;File chunkFile = new File(this.uploadPath, chunkFileName);file.transferTo(chunkFile);log.info("分片文件保存成功: {}", chunkFileName);// MD5校验(确保数据传输完整性)String calculatedMd5 = calculateMd5(chunkFile);if (!calculatedMd5.equals(md5)) {chunkFile.delete();log.error("MD5校验失败,分片: {}", chunkNumber);return "MD5校验失败,请重新上传分片";}log.info("MD5校验成功,分片: {}", chunkNumber);//仅当最后一个分片(chunkNumber == totalChunks)上传成功时才触发合并,此时所有分片已确定存在,触发异步合并if (chunkNumber == totalChunks) {log.info("所有分片上传完成,开始合并文件: {}", originalFilename);//通过CompletableFuture.runAsync将合并任务提交到线程池异步执行,避免阻塞上传接口的主线程//taskExecutor作为自定义线程池(如ThreadPoolTaskExecutor)可控制并发资源CompletableFuture.runAsync(() -> {try {mergeChunks(originalFilename, totalChunks);} catch (IOException e) {log.error("文件合并失败: {}", originalFilename, e);}}, taskExecutor);return "所有分片上传完成,正在合并文件";}return "分片" + chunkNumber + "上传成功";}// 计算文件的MD5值private String calculateMd5(File file) throws IOException {try (InputStream is = Files.newInputStream(file.toPath())) {return DigestUtils.md5DigestAsHex(is);}}/*** 合并分片文件* @param fileName 原始文件名* @param totalChunks 总分片数*/private void mergeChunks(String fileName, int totalChunks) throws IOException {log.info("开始合并文件: {}", fileName);//采用NIO通道技术提升合并速度Path targetPath = Paths.get(uploadPath, fileName);try (FileChannel destChannel = FileChannel.open(targetPath,StandardOpenOption.CREATE,StandardOpenOption.WRITE)) {IntStream.rangeClosed(1, totalChunks).forEach(i -> {Path chunkPath = Paths.get(uploadPath, fileName + ".part" + i);try (FileChannel srcChannel = FileChannel.open(chunkPath, StandardOpenOption.READ)) {destChannel.transferFrom(srcChannel, destChannel.position(), srcChannel.size());Files.delete(chunkPath);} catch (IOException e) {throw new UncheckedIOException(e);}});}// 计算总耗时(上传+合并)long totalTime = TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis() - startTime);String totalTimeStr = totalTime + "s";log.info("文件合并完成:{},总耗时:{}", fileName,totalTimeStr);// 合并逻辑完成后发送WebSocket通知Map<String, Object> result = new HashMap<String, Object>() {{put("fileName", fileName);put("totalTime", totalTimeStr);put("status", "COMPLETED");}};messagingTemplate.convertAndSend("/topic/mergeStatus", result);}}WebSocket配置
引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId>
</dependency>WebSocket建立持久连接实现服务器主动推送,相比轮询方案更高效
import org.springframework.context.annotation.Configuration;
import org.springframework.messaging.simp.config.MessageBrokerRegistry;
import org.springframework.web.socket.config.annotation.EnableWebSocketMessageBroker;
import org.springframework.web.socket.config.annotation.StompEndpointRegistry;
import org.springframework.web.socket.config.annotation.WebSocketMessageBrokerConfigurer;@Configuration
@EnableWebSocketMessageBroker
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {@Overridepublic void configureMessageBroker(MessageBrokerRegistry config) {//启用简单内存消息代理,处理以"/topic"为前缀的消息config.enableSimpleBroker("/topic");//设置应用消息前缀为"/app"config.setApplicationDestinationPrefixes("/app");}@Overridepublic void registerStompEndpoints(StompEndpointRegistry registry) {//定义WebSocket端点URLregistry.addEndpoint("/upload-websocket").withSockJS() //启用SockJS回退选项.setHeartbeatTime(10000); // 心跳间隔}
}线程池与异步合并
这个配置类创建了一个 ThreadPoolTaskExecutor bean,用于管理文件上传的线程池。合并文件的操作在所有分片上传完成后异步执行,减少了主线程的阻塞时间。
线程池详细参数介绍:
corePoolSize: 线程池的核心线程数,即在没有任务时,线程池中保持的线程数。
maxPoolSize: 线程池的最大线程数,即线程池中允许的最大线程数。
queueCapacity: 线程池的队列容量,即线程池中等待执行的任务队列的最大长度。
threadNamePrefix: 线程池中线程的名称前缀,用于区分不同的线程。
@Configuration
public class ThreadPoolConfig {@Beanpublic ThreadPoolTaskExecutor fileUploadExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();int cores = Runtime.getRuntime().availableProcessors();executor.setCorePoolSize(cores * 2 + 1); // 弹性核心数executor.setMaxPoolSize(cores * 10); // 10倍扩容空间executor.setQueueCapacity(200); // 平衡队列executor.setThreadNamePrefix("FileUploadThread-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;}
}文件合并
文件合并是将所有上传的分片合并成一个完整文件的过程,在这个方法中,后端将所有分片合并为一个完整的文件,并记录合并成功的日志。
这里会判断所有分片上传完毕,然后进行合并。


总结
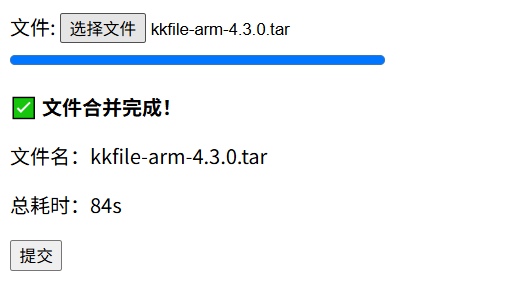
测试结果正常
通过使用Spring Boot和前端分片上传技术,我们可以实现高效的大文件上传。前端分片上传降低了单次上传的复杂度,提升了用户体验;后端多线程处理和文件合并的优化则大大提高了上传效率,减少了对服务器资源的占用