循环神经网络 中文情感分析案例
目录
一、数据处理
1、读取原始文件
2、清洗数据
3、分词
4、构建词典并保存
5、把每条文本编码成数字列表
6、固定长度
二、设置数据集、数据加载器
三、构建模型结构
四、配置具体模型参数与训练细节
五、开始训练并保存
六、模型测试(测试集)
七、单条评论测试(可选)
又做了一个小案例,刚好来复盘一下,是关于分析酒店评论的好坏,首先原始数据集如下:

前面一列是标签,1代表好评,0代表差评,后面的是评论内容,一共有5000多条评论,下面开始:
一、数据处理
这里我总结了一下大概的步骤:
读取原始文件 --> 清洗数据(去除标点符号等) --> 分词 --> 构建词典(包含去重)并保存 --> 编码(将文本全部用词典中的编号显示) --> 固定长度(补齐或者截断)
代码如下(其实每一步都可以封装成一个函数,这里我没有这样做,详细的可以看第七步单条评论测试,那个文件我每一步都封装了函数):
1、读取原始文件
#读取数据集
labels = []
comments = []# 读取文件,r表示只读
with open("./data/hotel_discuss2.csv", "r", encoding="utf-8-sig") as f:for line_num, line in enumerate(f, 1): # 遍历每一行,加上行号方便出错排查line = line.strip() #去除首尾空白字符if not line:continue # 跳过空行parts = line.split(",") #用逗号分割行得到片段partsif len(parts) < 2: #如果某一行分割后的parts数量少于2(即没有标签和评论),就打印警告并跳过该行print(f"⚠️ 第{line_num}行太短,跳过: {line}")continuelabel = parts[0] #第一个片段是标签comment = ",".join(parts[1:]) # 把剩下所有片段重新拼成一句完整评论labels.append(label) #分别存入列表comments.append(comment)#保存干净的csv文件
dataclean = pd.DataFrame({'label': labels, 'comment': comments})这样做是因为原始数据有可能被污染,导致不止两列,所以直接手动拆分成两个部分,将第一部分存为标签,剩下的所有都存为评论内容
2、清洗数据
因为我们要分析评论的好坏,只有中文或英文对我们有用,所以我们要处理一下其他字符:
#数据清洗函数
def clean_text(text):text = re.sub(r'[^\u4e00-\u9fa5A-Za-z ]+', '', str(text))return text
clean_comments = [clean_text(comment) for comment in comments]这里使用的正则表达式(苯人刚刚恶补了一下), re.sub() 是查找并替换的方法,里面的 \u4e00- \u9fa5 匹配所有中文字符,A-Za-z 匹配所有的英文字母,后面的空格是匹配空格,而前面的 ^ 表示取反,也就是说将除中文、英文和空格以外的所有特殊字符都用空字符串替代
3、分词
因为中文没有空格,所以需要用分词工具手动将评论文本分成一个个词:
def word_segment(text):words = jieba.cut(text)#只保留2个字及2个字以上的中文return [w for w in words if re.fullmatch(r'[\u4e00-\u9fa5]{2,}', w)]
segmented_comments = [' '.join(word_segment(c)) for c in clean_comments]
# print("清洗后评论示例:", segmented_comments[:3])返回的是一个列表推导式,首先遍历分词得到的每一个词,然后用正则表达式检查是否每个词都由两个及两个以上的中文字符组成,re.fullmatch() 要求字符串必须从头到尾都严格匹配要求,后面的 [\u4e00-\u9fa5]{2,} 就是要求,这个2表示前面的要求至少重复2次,这样留下的词就用空格拼成了一个列表(里面的每个元素代表每条评论)可以打印前几行看看
4、构建词典并保存
这里要构建词典是因为神经网络只认识数字,所以要给每个词分配一个独一无二的编号,本质上是在把词变成数字,代码如下:
all_words = ' '.join(segmented_comments).split() #所有词拼成一个大列表
unique_word = sorted(set(all_words)) #去重并排序
# 得到词到索引的映射词典
word_idx = {w:i for i, w in enumerate(unique_word)}
#保存词典
with open('./data/word_idx.pkl', 'wb') as f:pickle.dump(word_idx, f)这里用 all_words 是为了拿到所有词组成的大列表,前面的 segmented_comments 里面的每个元素代表每条评论,sorted 排序是为了每次运行时生成词典的顺序都不变,set 去重,然后后面是一个字典推导式,for语句是遍历去重排序后的列表并返回每个词的索引和词本身,换个位置就是词到索引的映射,最后保存词典后面有用
5、把每条文本编码成数字列表
这一步是为了将文本喂给词嵌入层,它读取每条数字组成的评论后就会从前面创建的词典查找并为每个词创建词向量,所以这一步是为了转成词嵌入层的输入格式,代码如下:
#把每个评论变成数字ID组成的列表
#编码函数
comment2code = [[word_idx[word] for word in comment.split()] for comment in segmented_comments]
# print(comment2code[:3]) [[382, 382, 21180, 382, 2851, 13491, 14423, 20106, 19958, 7330, 13491, 23174, 16658, 11081, 6293, 14423, 20106],
这个列表推导式的逻辑首先是拿到 segmented_comments 里的每个元素,也就是分词后用空格拼好的每条评论,然后再将每条评论用空格分开得到每条评论包含的分词,最后匹配词典拿到对应的编号
6、固定长度
深度学习的输入必须是形状统一的张量,所以要统一一下输入评论的长度:
#固定输入长度
max_comment = 200
def padding_comment(comment, max_comment):if len(comment) >= max_comment:return comment[:max_comment]else:return comment + [0]*(max_comment - len(comment))
commenttocode = [padding_comment(comment, 200) for comment in comment2code] #处理所有评论
# print(commenttocode[:3])设置最长为200字,多了就截断,少了就用0填充,将 commenttocode 丢进去处理
二、设置数据集、数据加载器
这一步就不用多说了,就是注意一下 x 和 y,x 就是已经固定长度的 commenttocode,y 是标签值:
x = commenttocode
y = dataclean['label'].astype(int).tolist() #这里转成列表
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8) #划分数据集#转成tensor
x_train = torch.tensor(x_train)
x_test = torch.tensor(x_test)
y_train = torch.tensor(y_train)
y_test = torch.tensor(y_test)注意这里最后要转成 tensor,因为模型的输入要求是 tensor,下一步封装数据集:
#封装数据集
train_dataset = TensorDataset(x_train, y_train)
test_dataset = TensorDataset(x_test, y_test)数据加载器:
#数据加载器
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32)三、构建模型结构
这里使用的是 LSTM网络模型,具体网络结构如下图:
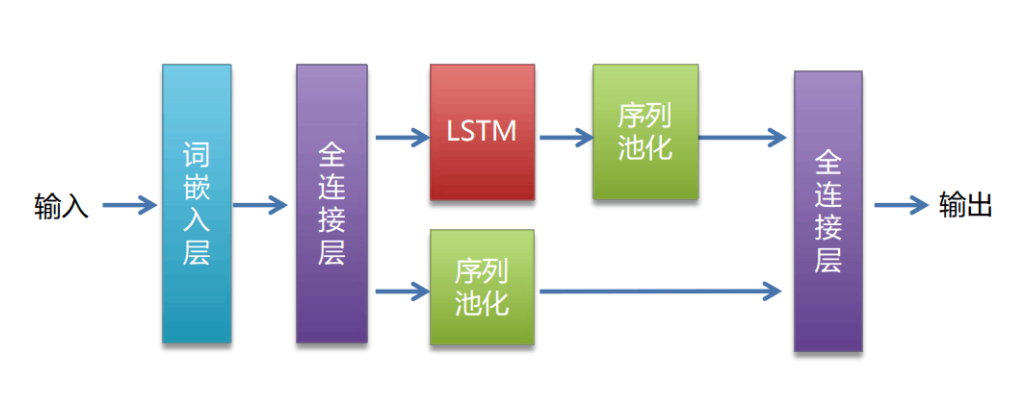
代码如下:
import torch.nn as nn#构建模型结构
class LSTMmodel(nn.Module):def __init__(self, vocab_size, output_size, embedding_dim, hidden_dim, num_layers):super(LSTMmodel, self).__init__()#词嵌入层self.embedding = nn.Embedding(vocab_size, embedding_dim)#lstmself.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, batch_first = True)# 防止过拟合self.dropout = nn.Dropout(0.3)#激活函数self.tah = nn.Tanh()#全连接层self.fc = nn.Linear(hidden_dim, output_size)def forward(self, x):x = self.embedding(x)lstm_out, _ = self.lstm(x)#序列池化 取最后一个时间步的输出out = lstm_out[:, -1, :]out = self.dropout(out)out = self.tah(out)out = self.fc(out)return out这里可以单独写一个 py 文件,后面好导入
四、配置具体模型参数与训练细节
#配置模型参数
vocab_size = len(word_idx)
embedding_dim = 128
hidden_dim = 128
output_size = 2 #二分类
num_layers = 2
model = LSTMmodel(vocab_size, output_size, embedding_dim, hidden_dim, num_layers)
model.load_state_dict(torch.load(model_path)) #继续训练device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
model.to(device)#配置训练细节
criterion = nn.CrossEntropyLoss()
optimizer = opt.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)注意继续训练那一行代码,如果第一次训练后模型效果不佳,可以保存模型参数然后继续训练时直接加载,效果会好很多
五、开始训练并保存
代码如下:
#训练
epochs = 10
for epoch in range(epochs):model.train()running_loss = 0total = 0correct = 0for batch_inputs, batch_labels in train_loader:batch_inputs, batch_labels = batch_inputs.to(device), batch_labels.to(device)#得到预测值output = model(batch_inputs)pred = torch.argmax(output, dim=1)loss = criterion(output, batch_labels)optimizer.zero_grad()#梯度清零loss.backward() #反向传播optimizer.step() #根据梯度参数更新running_loss += loss.item()correct += (pred == batch_labels).sum().item()total += batch_labels.size(0)acc = correct/total *100torch.save(model.state_dict(), model_path)print(f"[Epoch {epoch + 1}/{epochs}] Loss: {running_loss:.4f}, Accuracy: {acc:.2f}%")
这里跟上一篇香蕉案例差不多,详细可看上一篇深度学习 pytorch图像分类(详细版)-CSDN博客
训练结果(苯人这里是继续训练的结果,第一次忘截图了):
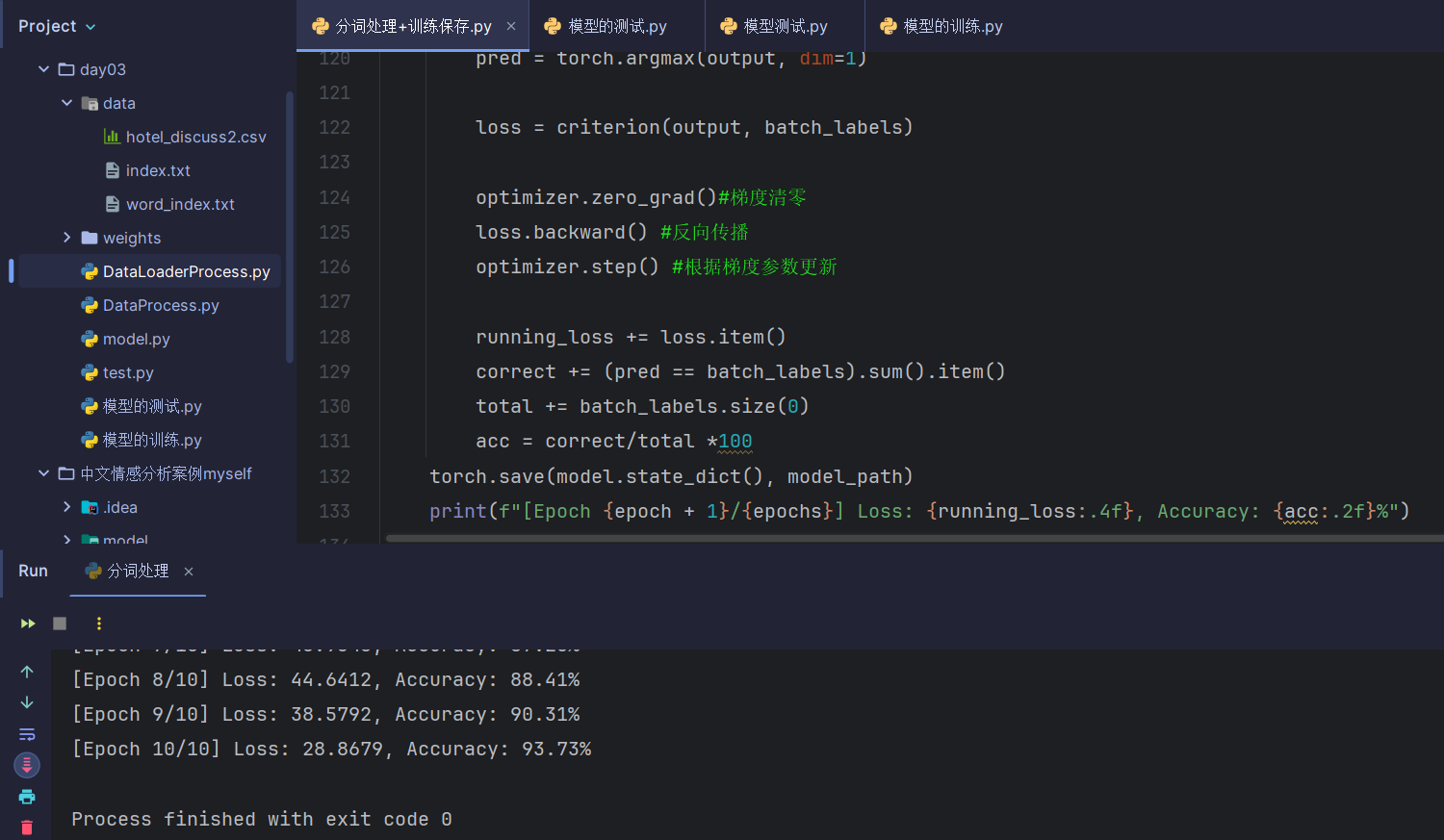
六、模型测试(测试集)
前面的步骤都和训练不变,就是模型结构那块可以直接导入:
from model import LSTMmodel主要是测试代码不同:
#测试
acc = 0
correct = 0
total = 0
running_loss = 0
model.eval()
with torch.no_grad():for batch_inputs, batch_labels in test_loader:batch_inputs, batch_labels = batch_inputs.to(device), batch_labels.to(device)output = model(batch_inputs)loss = criterion(output, batch_labels)running_loss = loss.item()pred = torch.argmax(output, dim=1)correct += (pred == batch_labels).sum().item()total += batch_labels.size(0)acc = correct/total *100print(f"Loss: {running_loss:.4f}, Accuracy: {acc:.2f}%")测试结果:
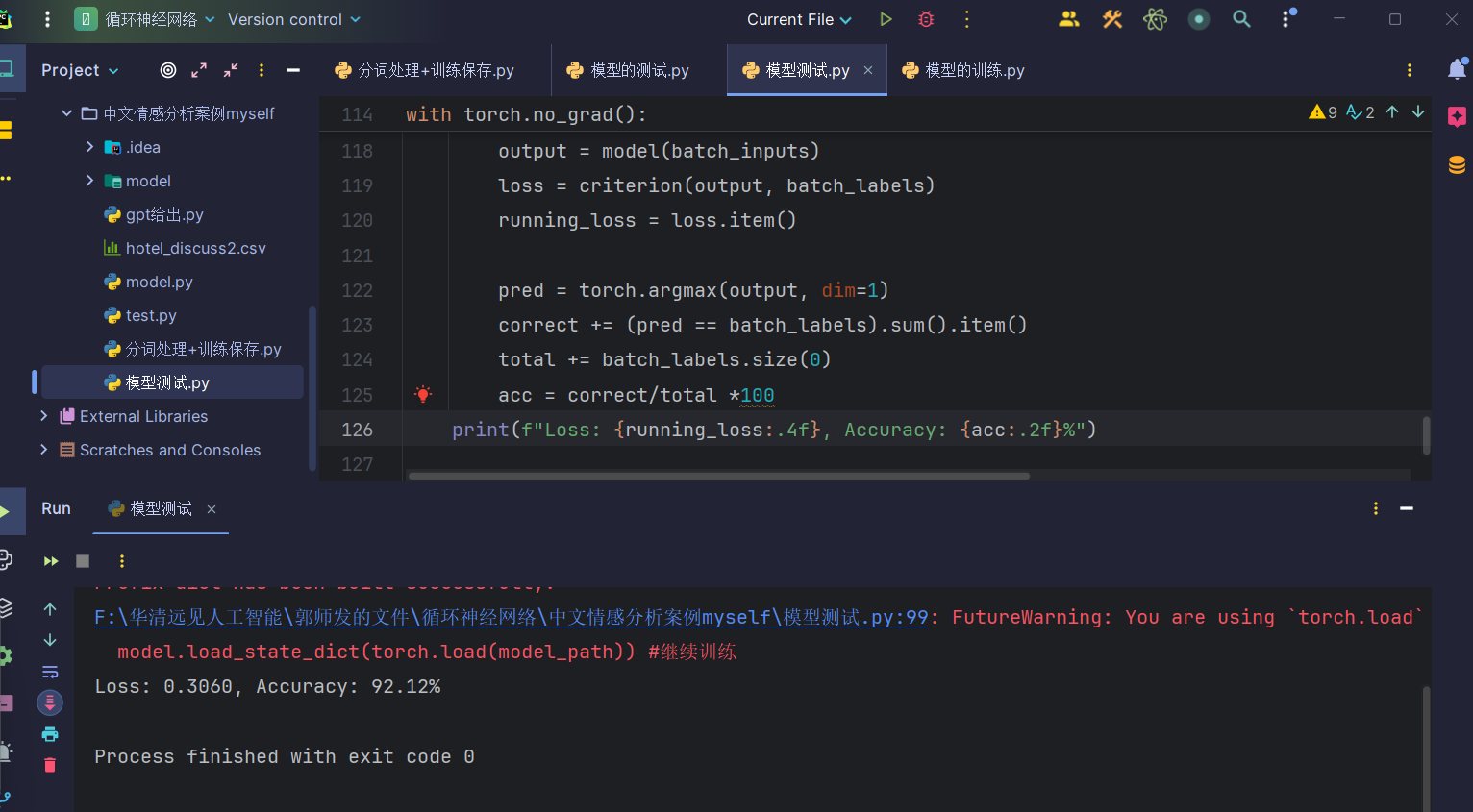
可以看到,测试集的结果还是可以的,接下来就可以用单条评论测试了
七、单条评论测试(可选)
代码如下:
import torch
import re
import jieba
import pickle
from model import LSTMmodelmodel_path = './model/last.pth'# 加载词典
with open('./data/word_idx.pkl', 'rb') as f:word_idx = pickle.load(f)#加载模型与参数
vocab_size = len(word_idx)
embedding_dim = 128
hidden_dim = 128
output_size = 2 #二分类
num_layers = 2
model = LSTMmodel(vocab_size, output_size, embedding_dim, hidden_dim, num_layers)
model.load_state_dict(torch.load(model_path)) #加载权重参数device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
model.to(device)#清洗函数
def clean_text(text):#匹配所有不是中文、英文、空格的字符并替换为空字符串text = re.sub("[^\u4e00-\u9fa5A-Za-z ]+", "", text)return text#分词函数
def segment_text(text):words = jieba.cut(text)#先遍历分词得到的每一个词,再筛选中文长度大于2的词放入列表,所以这里用了列表推导式return [w for w in words if re.fullmatch(r'[\u4e00-\u9fa5]{2,}', w)]#编码函数
def code_text(words, word_idx):#批量处理之前生成的整个分词列表,将词转成编码return [word_idx[word] for word in words if word in word_idx]#固定长度,补齐或截断
def padding_codetext(codetext, max_len):if len(codetext) >= max_len:return codetext[:max_len]else:return codetext + [0]*(max_len - len(codetext))#最终将以上所有封装成一个函数
def text_process(text, word_idx, max_len=200):text = clean_text(text)words = segment_text(text)encode = code_text(words, word_idx)padded_text = padding_codetext(encode, max_len)return torch.tensor([padded_text])#预测函数
def pred_text(text, model, word_idx):x = text_process(text, word_idx, max_len=200)with torch.no_grad():output = model(x)pred = torch.argmax(output, dim=1)return "好评!" if pred == 1 else "差评!"if __name__ == '__main__':text_input = input("请输入一句评论:")result = pred_text(text_input, model, word_idx)print(f'模型预测为:{result}')这里我就不一步步介绍了,跟前面的是一样的,只是这里的数据处理我每一步都写成了功能函数,逻辑比训练时要连贯一点,运行结果:
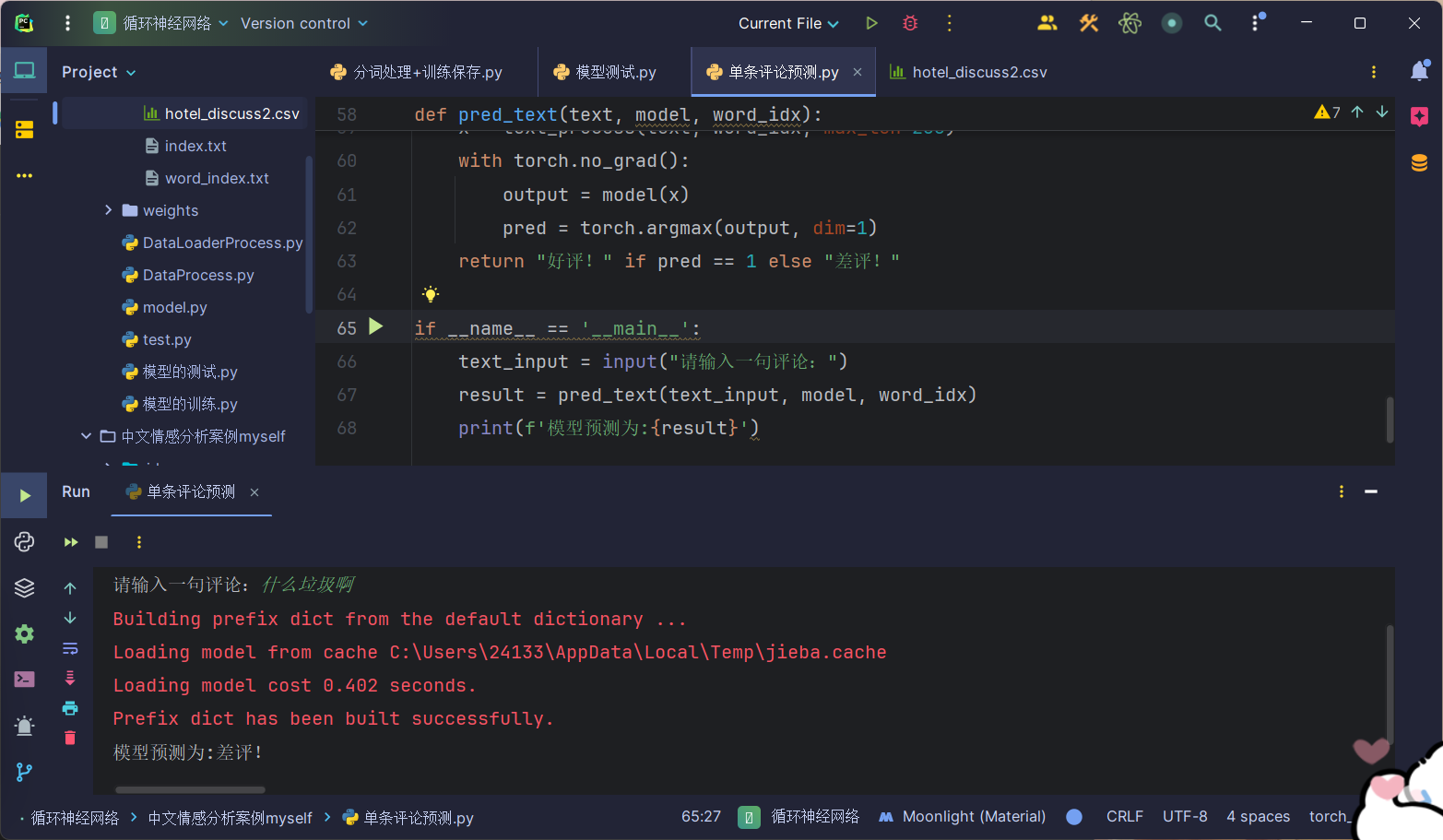
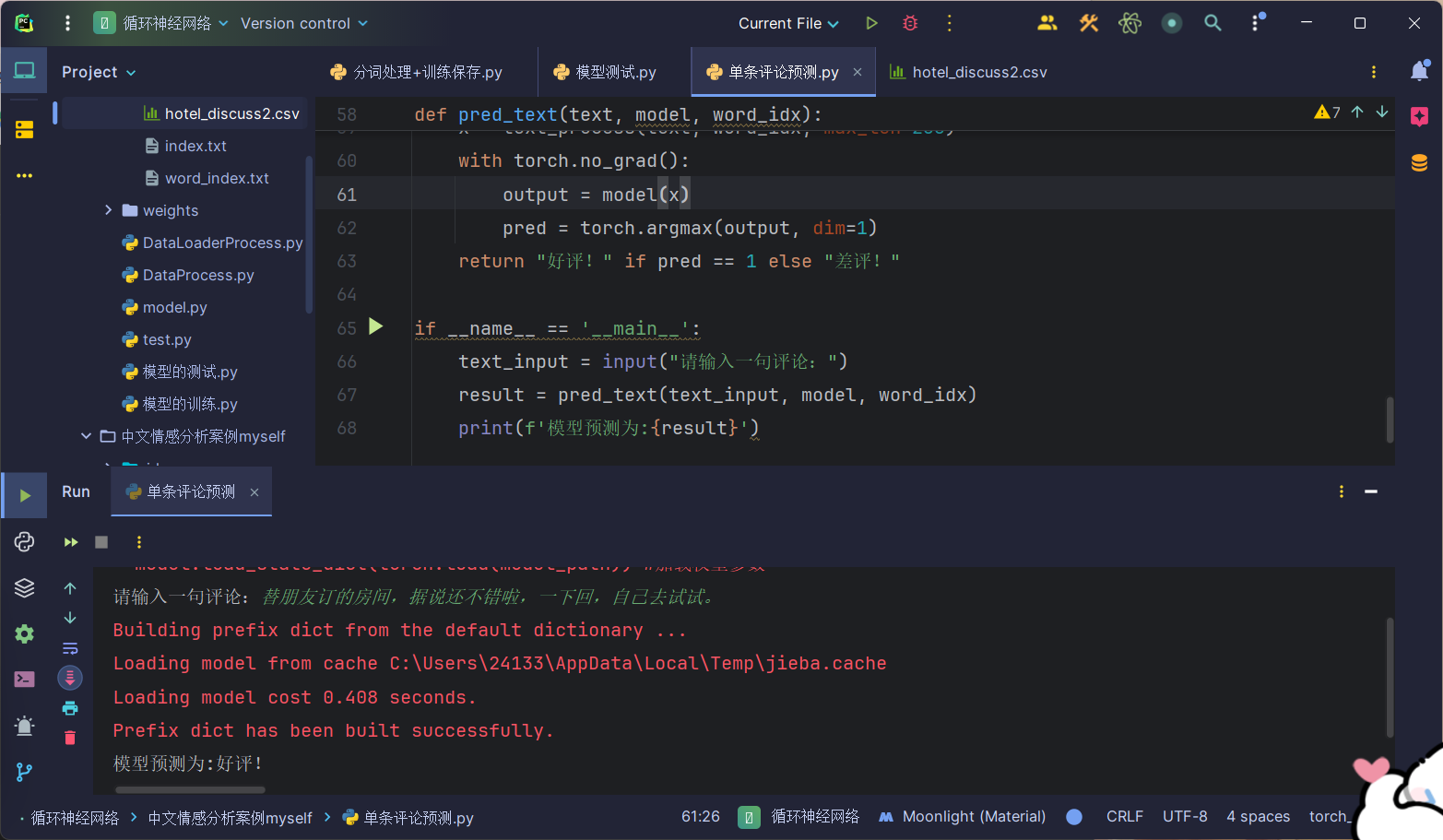
这一篇就到此结束,后面就开始学习YOLO算法了,下一篇同样没想好写什么 (๑•̀ㅂ•́)و✧
以上有问题可以指出。