【python高阶】-1- python工程和线程并发
一、项目工程守则
1.pdm
新建一个项目
命令行终端:pip install pdm
pdm init
版本号:x.y.z
- x:兼容版本
- y:新增功能
- z:补丁版本
pdm add pytest requests (添加依赖)
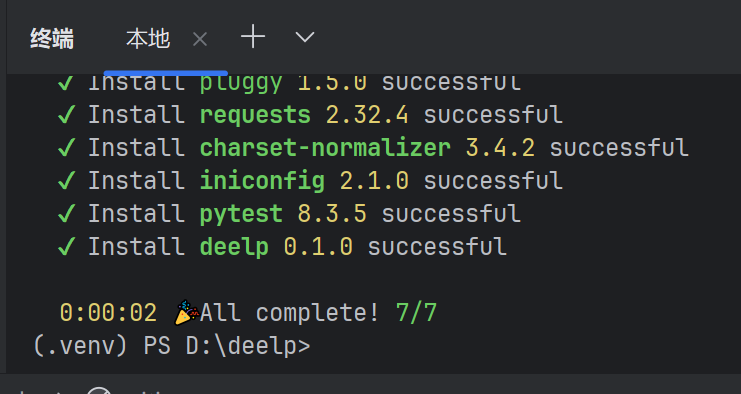
pdm是协助管理我们的项目
2. black
就是规范我们的代码风格的:
pdm add black
black
black test_api (./ 一次处理该目录下所有.py文件)
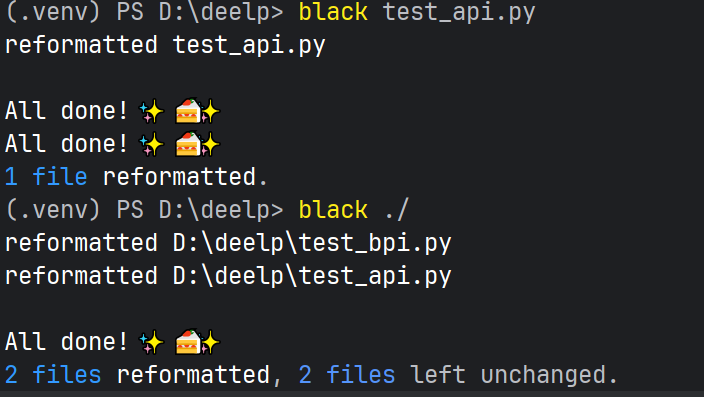
3.flake8
检查语法错误
pdm add flake8
新建配置文件 .flake8
里面写

这样就不会查所有的文件了
还要加上 extend-ignore = E501
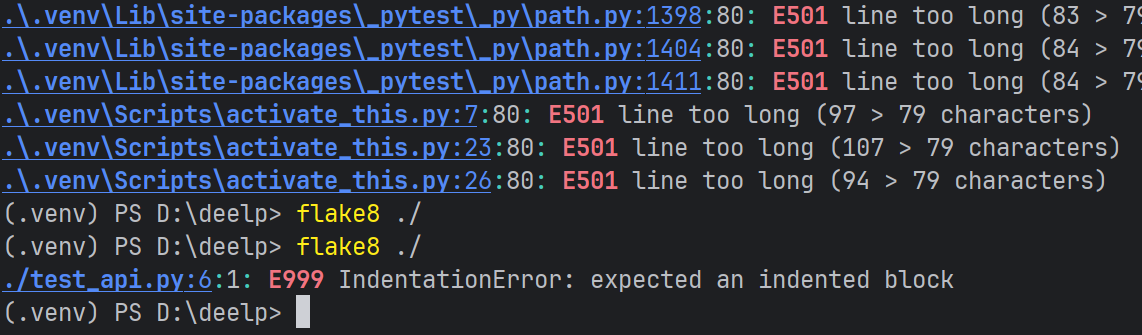
4.isort
排序import
5.pytest
管理和执行测试用例
6.自定义命令
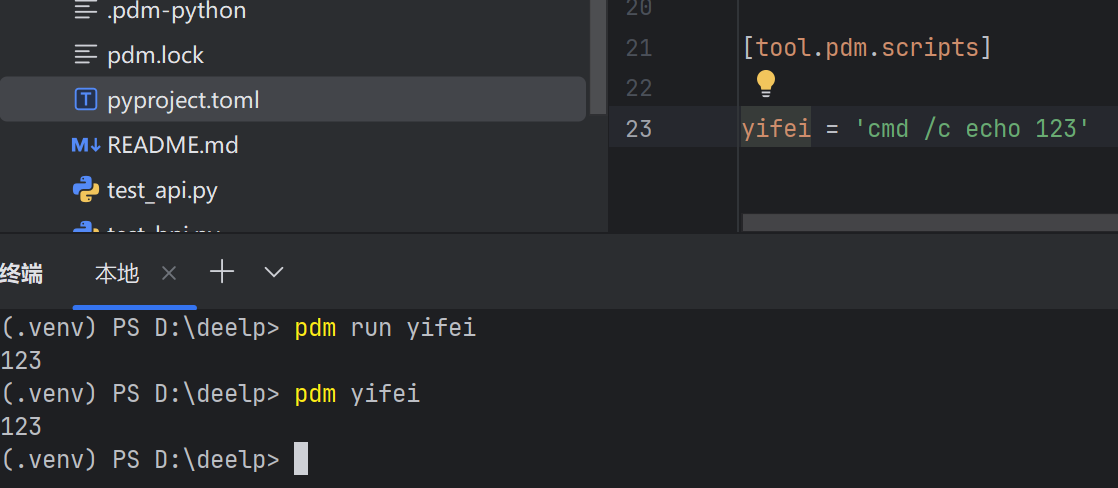 将四个命令合并在一起
将四个命令合并在一起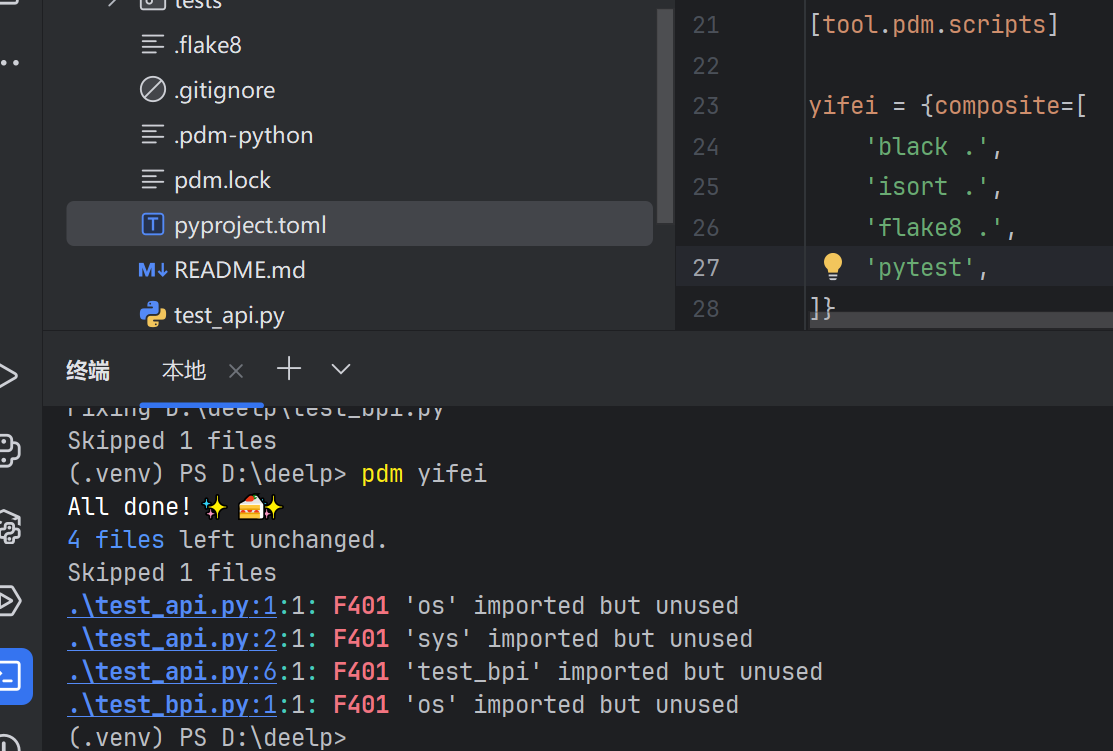
7.项目管理
src源代码 tests单元测试
二、错误和异常
python只有一种错误 语法错误 如果有语法错误的话整个文件都跑不起来 跑到半路停下来的都是异常
异常:执行前没有检查出错误,半路上遇到预期之外的情况
异常的引发方式:
python自动引发:
1 assert 1 == 2
2. 属性异常 print("beifan".beifan)
3. 导入异常 from sys import beifan
4. 索引异常 l = [ ] print(l[100])
5. 键值对异常 d = {} print(d["id"])
手动引发异常:
def add(a, b):if not isinstance(a, int):raise ValueError(f'{a=}, 不是整数,无法计算')if not isinstance(b, int):raise ValueError(f'{b=}, 不是整数,无法计算')return a + b异常引发之后发生了什么
异常引发之后,Python 会进行下面的操作:
- 停止执行
- 收集信息
- 向上传播
- 不仅 add 函数停止执行
- main 函数也停止执行
- python 也停止执行
如何想要改变这个默认的处理流程,需对异常进行捕捉(打断传播链条)
捕捉异常可以:
- 打断异常的传播
- 自动执行预定义的代码
注意:
- 尽量只捕捉能处理的异常
- 不能处理的异常,应该继续传播
- 如果没有代码可以处理,就应该让 Python 停止运行

Pycharm 提供的 Debug (更方便)
console:执行任意的 Python 代码
debugger:控制代码执行进度、显示变量内容
步过:执行到下一行
步入:执行到下一行代码的内部
步出:执行完函数
恢复运行:运行到下一个断点处
Python 提供的 Debug(更核心) pdb:python debug
python -m pdb main.py
命令:
- l: 查看代码
- n: 步过
- s: 步入
- c: 恢复执行
- b: 打断点
- ! : 执行任意代码
三、python多线程
(1)Python 多线程的两种实现方式
方式 1:继承 Thread 类
步骤:
- 继承父类:定义一个类(如
T1),继承threading.Thread; - 重写
run方法:在类里实现run方法,写线程要执行的任务(如调用task_1()); - 调用
start方法:创建线程对象后,用start()启动线程,自动执行run里的任务。
from threading import Thread # 需导入 Thread 类# 1. 继承 Thread 类
class T1(Thread): # 2. 重写 run 方法:定义线程任务def run(self): print("线程任务开始")task_1() # 假设 task_1 是要执行的函数print("线程任务结束")# 3. 实例化线程对象 + 启动线程
t_1 = T1()
t_1.start() # 启动线程,自动执行 run 方法# 可选:等待线程结束(避免主线程提前退出)
t_1.join()
方式 2:实例化 Thread 对象
步骤:
直接创建 Thread 对象,通过 target 参数指定线程要执行的任务(函数),再用 start() 启动。
from threading import Thread# 定义线程要执行的任务
def task_1(): print("线程任务开始")# 业务逻辑...print("线程任务结束")# 1. 实例化 Thread:用 target 指定任务函数
t_1 = Thread(target=task_1) # 2. 调用 start 方法:启动线程,执行 target 对应的任务
t_1.start() # 可选:等待线程结束
t_1.join()
(2)线程的执行流程
不管用哪种方式创建线程,执行流程 都是固定的:
- 实例化:创建
Thread对象(如t_1 = T1()或t_1 = Thread(target=task_1)); - 调用
start方法:触发线程创建,系统会分配新的线程资源; - 调用
run方法:新线程启动后,自动执行run里的逻辑(方式 1 是重写的run,方式 2 是Thread内置run会调用target函数 ); - 执行任务:最终执行
run里的代码(或target函数 )。
(3)关键方法解析
1. start():启动线程
- 作用:告诉系统 “创建新线程,执行任务”;
- 注意:不能重复调用,一个线程对象只能
start()一次。
2. run():线程的核心逻辑
- 作用:定义线程要做的事;
- 方式 1 中,需重写
run来定制任务; - 方式 2 中,
Thread内置的run会自动调用target指定的函数,无需手动重写。
3. join():等待线程结束
- 作用:主线程执行到
join()时,会暂停自己,等子线程执行完再继续; - 场景:如果主线程需要用到子线程的结果,或避免子线程还没跑完,主线程就退出,就需要
join()。
(4)两种方式的对比
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
继承 Thread 类 | 可以重写多个方法,定制性强 | 类继承会占用单继承名额 | 需要复杂线程逻辑(如自定义 run ) |
实例化 Thread | 简单直观,无需创建类 | 仅能通过 target 传任务 | 简单任务,快速创建线程 |
(5)实际应用建议
- 简单任务选方式 2:直接传
target,代码更简洁; - 复杂逻辑选方式 1:比如需要在
run里加前置 / 后置操作(如初始化资源、清理数据 ); - 必用
join():如果主线程依赖子线程结果(如统计多线程下载的文件总数 ),一定要用join()等待,否则可能出现 “子线程还没跑完,主线程已经退出” 的问题。
四、线程池
(1)为什么需要 “线程池”?
直接创建线程(如继承 Thread 类、实例化 Thread 对象 )有个问题:线程用完就销毁,频繁创建 / 销毁会浪费资源(比如测试 100 个任务,就要创建 100 个线程 )。
→ 线程池的作用:
- 预先创建一批线程(比如 3 个),放进 “池子” 里复用;
- 有任务时,从池子里拿线程执行;任务结束后,线程不销毁,放回池子等下次复用;
- 减少线程创建 / 销毁的开销,提升效率。
(2)线程池的核心逻辑
线程池的工作流程可以概括为 3 步:
- 创建线程池:根据需求设置最大线程数(
max_workers),比如同时最多跑 3 个线程; - 分配任务:有任务时,线程池自动选空闲线程执行任务;
- 复用线程:任务结束后,线程回到池子,等待下一个任务,不用销毁。
(3)线程池的使用步骤
步骤 1:导入模块
使用线程池需要导入 concurrent.futures 里的 ThreadPoolExecutor:
from concurrent.futures import ThreadPoolExecutor
import time # 用于统计耗时
步骤 2:定义任务(假设已有任务函数)
假设我们有 3 个任务函数,需要并行执行:
def task_1():time.sleep(1) # 模拟任务耗时return "任务1结果"def task_2():time.sleep(1)return "任务2结果"def task_3():time.sleep(1)return "任务3结果"
步骤 3:创建线程池 + 提交任务(两种方式)
方式 1:用 pool.map 批量提交任务
pool.map 会自动遍历任务列表,把每个任务分配给线程池执行,返回结果列表。
# 记录开始时间
start_time = time.time() # 1. 创建线程池:最多同时跑 3 个线程
pool = ThreadPoolExecutor(max_workers=3) # 2. 提交任务:用 map + lambda 执行任务列表
# lambda x: x() 表示“调用列表里的每个函数(task_1、task_2、task_3)”
res_list = pool.map(lambda x: x(), [task_1, task_2, task_3]) # 3. 关闭线程池:等待所有任务完成(也可以用 with 语法自动关闭)
pool.shutdown() # 记录结束时间
end_time = time.time() # 输出耗时
print(f'一共耗时:{end_time - start_time:.2f} 秒') # 遍历结果
for res in res_list:print(res)
执行流程:
- 线程池创建 3 个线程;
pool.map自动把task_1、task_2、task_3分配给线程执行;- 任务并行运行(因为
max_workers=3,3 个任务同时跑 ); - 所有任务结束后,
pool.shutdown()关闭线程池; - 遍历
res_list拿到每个任务的返回值。
方式 2:用 pool.submit 单个提交任务
Future 对象通常通过线程池 / 进程池的 submit() 方法创建
pool.submit 可以单个提交任务,返回 Future 对象,用于获取结果。
start_time = time.time() pool = ThreadPoolExecutor(max_workers=3) # 提交任务,返回 Future 对象
f_1 = pool.submit(task_1)
f_2 = pool.submit(task_2)
f_3 = pool.submit(task_3) pool.shutdown() # 等待任务完成end_time = time.time()
print(f'一共耗时:{end_time - start_time:.2f} 秒') # 通过 Future 对象的 result() 方法拿结果
print(f_1.result())
print(f_2.result())
print(f_3.result())
执行流程:
- 逐个提交任务,线程池自动分配线程执行;
pool.shutdown()等待所有任务完成;- 用
future.result()获取每个任务的返回值。
(4)两种提交任务方式的对比
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
pool.map | 自动遍历任务列表,代码简洁 | 必须等所有任务完成才返回结果 | 任务数量明确,需要批量执行 |
pool.submit | 灵活控制任务提交,可单独拿结果 | 代码稍繁琐 | 任务数量不确定,或需要实时拿结果 |
(5)线程池的关键细节
1. max_workers 的设置
max_workers是线程池里最多同时运行的线程数;- 设置太小(比如 1 ),任务会串行执行,失去并行优势;
- 设置太大(比如 100 ),会占用过多资源(CPU、内存 ),甚至拖慢程序;
- 建议:根据任务类型(CPU 密集型 / IO 密集型 )调整,IO 密集型(如网络请求 )可以设大些(比如 10-20 ),CPU 密集型(如大量计算 )设小些(比如 4-8,和 CPU 核心数匹配 )。
2. pool.shutdown() 的作用
- 关闭线程池,不再接受新任务;
- 但会等待已提交的任务全部完成后,才真正关闭;
- 也可以用
with语法自动关闭(推荐 ):with ThreadPoolExecutor(max_workers=3) as pool:res_list = pool.map(lambda x: x(), [task_1, task_2, task_3]) # 离开 with 块后,自动执行 pool.shutdown()
3. 异常处理
如果任务执行中抛出异常,pool.map 会在遍历 res_list 时抛出异常;pool.submit 则会在调用 future.result() 时抛出异常。需要用 try-except 捕获:
with ThreadPoolExecutor(max_workers=3) as pool:try:res_list = pool.map(lambda x: x(), [task_1, task_2, task_3])for res in res_list:print(res)except Exception as e:print(f"任务执行异常:{e}")
五、线程并发
一、变量通信 🌟
原理
多个线程可以共享同一个 “全局变量”,像小盒子一样📦 线程 A 往里塞数据,线程 B 能掏出数据~
但要注意!Python 里有个 GIL(全局解释器锁) 🚦 ,如果多个线程同时改变量,容易 “打架”(数据乱掉)!
代码示例(反面教材👉 线程打架现场)
import threading
import time# 共享小盒子📦
counter = 0 def increment():global counterfor _ in range(100000):# 非原子操作⚠️ 读→改→写,线程会打架!counter += 1 threads = []
for _ in range(5):t = threading.Thread(target=increment)threads.append(t)t.start()for t in threads:t.join()# 理想是 500000,实际可能乱套!因为线程打架啦🥊
print("最终 counter 值:", counter)
改进版(加锁保护🔒 让线程乖乖排队)
import threading
import timecounter = 0
# 可爱小锁🔒 同一时间只让一个线程动小盒子!
lock = threading.Lock() def increment():global counterfor _ in range(100000):# 拿锁!其他线程乖乖等~with lock: counter += 1 # 现在安全啦✨threads = []
for _ in range(5):t = threading.Thread(target=increment)threads.append(t)t.start()for t in threads:t.join()# 这次一定是 500000!完美~
print("最终 counter 值:", counter)
二、队列通信 📮
原理
队列是 线程安全的 “传送带” 🛳️ 一个线程当 “生产者”(往传送带上放东西),另一个当 “消费者”(从传送带上拿东西)~ 不用自己加锁,超省心!
代码示例(生产者 - 消费者 🍞→🥪 )
import threading
import queue
import time# 可爱传送带📦
q = queue.Queue() # 生产者:往传送带放面包🍞
def producer():for i in range(5):item = f"面包{i}"q.put(item) # 放传送带上~print(f"生产者放: {item} 👉 传送带")time.sleep(0.5)# 消费者:从传送带拿面包做三明治🥪
def consumer():while True:item = q.get() # 拿东西!没东西就等~print(f"消费者拿: {item} 👉 做三明治")q.task_done() # 告诉传送带:我处理完啦✅if q.empty(): # 传送带空了,下班!break# 启动线程~
producer_thread = threading.Thread(target=producer)
consumer_thread = threading.Thread(target=consumer)producer_thread.start()
consumer_thread.start()producer_thread.join()
q.join() # 等传送带所有任务完成~
效果:
生产者每隔 0.5 秒放面包,消费者马上拿走做三明治🥪 完美配合,不会乱~
三、锁通信 🔒
原理
锁是 “魔法小令牌” 🪄 线程拿到令牌才能动共享资源!其他线程只能乖乖等令牌~ 这样就不会打架啦!
代码示例(保护小盒子📦 )
import threading
import timecounter = 0
# 魔法令牌🔒
lock = threading.Lock() def increment():global counterfor _ in range(100000):# 拿令牌!其他线程等~lock.acquire() try:counter += 1 # 安全操作✨finally:lock.release() # 还令牌!其他线程可以拿啦~threads = []
for _ in range(5):t = threading.Thread(target=increment)threads.append(t)t.start()for t in threads:t.join()# 结果一定正确~因为令牌守护着!
print("最终 counter 值:", counter)
偷懒写法(with 自动管令牌🔄 )
import threading
import timecounter = 0
lock = threading.Lock() def increment():global counterfor _ in range(100000):# 进入 with 自动拿令牌,退出自动还~超方便!with lock: counter += 1 threads = []
for _ in range(5):t = threading.Thread(target=increment)threads.append(t)t.start()for t in threads:t.join()print("最终 counter 值:", counter)
四、总结(超可爱版对照表🐾 )
| 方式 | 可爱比喻 | 优点 | 缺点 |
|---|---|---|---|
| 变量 | 共享小盒子📦 | 简单直接 | 容易打架(需加锁) |
| 队列 | 传送带📮 | 线程安全、解耦省心 | 要维护队列结构 |
| 锁 | 魔法令牌🔒 | 精准保护共享资源 | 用不好会 “死锁”(慎用) |