IOPaint 图像修复工具,学习笔记
一、 项目背景与目标
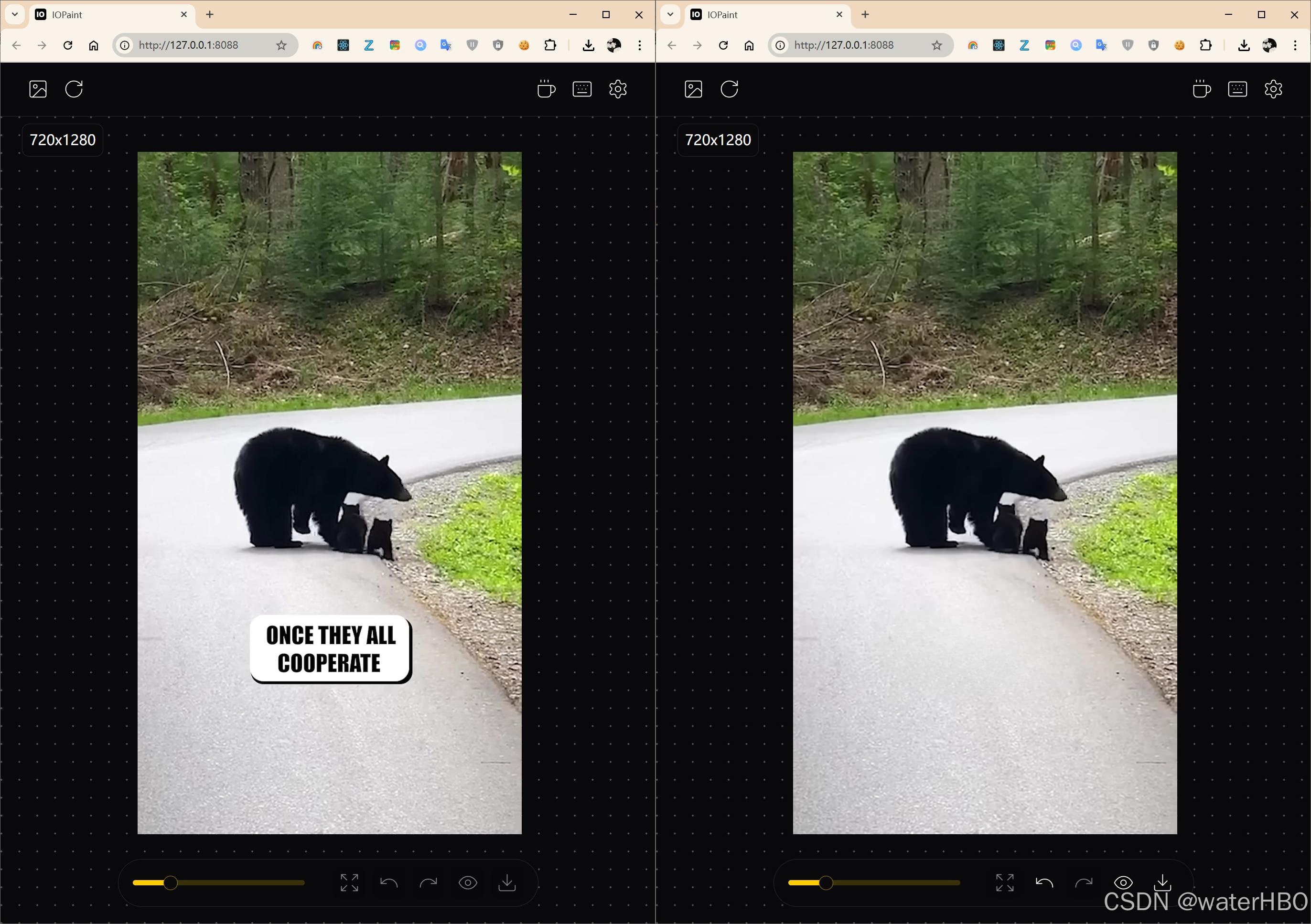
我的初始目标非常明确:我下载了一个带有“硬字幕”的视频(bear.mp4),我想找到一种方法,能有效地将这些已经“烤”在画面里的字幕去除掉。经过一番调研,我将目光锁定在了一个强大的开源图像修复工具上:IOPaint。
- 项目主页: https://github.com/Sanster/IOPaint
- 官方文档: https://www.iopaint.com/
这篇笔记记录了我使用 IOPaint 的完整学习路径,从最简单的想法,到克服各种预料之外的困难,最终实现了一个全自动的解决方案。
二、 基础入门:安装与模型管理
起步阶段相对直接,主要是熟悉工具的基本用法。
1. 安装 IOPaint
通过 pip 可以轻松安装:
pip install iopaint
2. 模型管理
IOPaint 支持多种修复模型,这些模型需要被下载并放置在正确的本地文件夹中。
- 模型下载地址: 官方文档提供了所有支持模型的下载链接。
- 本地存放位置:
C:\Users\YourUsername\.cache\torch\hub\checkpoints - 我的实践: 我提前下载了
lama,zits,ldm等几个常用模型,直接放到这个文件夹,可以避免运行时再去下载,节省了时间。
三、 核心功能探索:从交互式修复到批量处理
IOPaint 主要有两种工作模式:start 和 run。
1. 交互式模式 (iopaint start)
这是用于手动、精细化处理单张图片的模式。它会启动一个网页界面(WebUI),你可以在浏览器中上传图片、用画笔涂抹要修复的区域,然后实时看到结果。
- 启动命令:
# 启动一个使用 lama 模型,运行在 GPU 上的服务 iopaint start --model=lama --device=cuda --port=8080 - 我的感受:
lama模型(约200MB)速度快,效果已经非常出色,适合快速修复。ldm模型(约1.4GB)效果更好,但处理大面积区域时对显卡要求很高,可能会卡顿。
2. 批量处理模式 (iopaint run)
这才是实现自动化的关键!它允许我们通过命令行,对一整个文件夹的图片进行批量处理。
- 命令格式:
# 注意:这里的命令是 run,而不是 start iopaint run --model=[模型名] --image=[输入图片目录] --mask=[遮罩目录] --output=[输出目录]
四、 关键的进化之路:遮罩(Mask)的制作与迭代
这是我整个学习过程中最重要、也遇到问题最多的部分。修复效果的好坏,90% 取决于遮罩的质量。
第一阶段:天真的静态遮罩
- 我的想法: “对于我这个视频,字幕位置是固定的。那我只需要制作一个白色的矩形图片
one_mask.jpg,然后让iopaint对所有帧都使用这个遮罩不就行了吗?” - 尝试:
iopaint run --model=zits --image=bear_frames --mask=one_mask.jpg --output=bear_out2 - 遇到的问题与学习:
- 报错! 程序在处理几帧后就崩溃了。
- 重要的认知误区: 我最初以为是
zits模型不支持单一遮罩文件。但经过深入排查后发现,真正的原因是我安装的iopaint版本,其run命令还不支持“单一文件对多帧”的功能。而官方文档描述的是最新版的功能。这让我学到了开源工具实践中的一个重要教训:当功能与文档不符时,优先检查版本差异! - 正确的做法(兼容所有版本): 为每一帧都提供一个与之对应的遮罩文件。
第二阶段:AI 赋能的动态遮罩
既然手动遮罩不可扩展,我转向了 AI 自动化方案。目标是让程序自己判断哪里有字幕,并自动生成遮罩。
- 选用的工具: PaddleOCR,一个性能顶尖的开源 OCR 库。
- 核心逻辑:
- 遍历每一帧图片。
- 用 PaddleOCR 检测图片中是否存在文本。
- 如果存在,根据返回的坐标生成一个黑底白字的遮罩图片。
- 如果不存在,则跳过这一帧。
第三阶段:克服 AI 的“智能”陷阱
自动化并非一帆风顺,我遇到了两个经典的 AI 误判问题。
-
陷阱一:Mask 位置完全错误!
- 现象: 我发现生成的遮罩出现在了画面的顶部,而字幕明明在底部。
- 根本原因: PaddleOCR 内置了“文档方向分类”功能,它错误地认为我的视频帧是颠倒的,于是在内部将图片旋转了180度再进行检测。
- 解决方案: 在初始化 PaddleOCR 时,明确禁用这个功能:
ocr = PaddleOCR(use_doc_orientation_classify=False, ...)。
-
陷阱二:AI 把熊当成了字幕!
- 现象: 在某些帧里,模型将一只黑熊的轮廓识别为了一个巨大的文本块。如果直接使用这个遮罩,视频的主角就没了。
- 我的思考: “真正的字幕,形状上应该是细长的矩形。”
- 解决方案: 在生成遮罩后,增加一个基于形状的过滤步骤。一个轮廓必须同时满足以下条件才被认为是字幕:
- 面积(Area) 足够大(过滤掉小噪点)。
- 宽高比(Aspect Ratio) 足够高(确保是“细长”的)。
- 密实度(Solidity) 接近1.0(确保是“实心”的,而不是像熊一样不规则的形状)。
- 这套组合拳极大地提高了检测的准确率。
五、 重要的认知与总结
-
关于“Mask 面积”的误解:
- 我曾对 PaddleOCR 报告的几万像素的面积感到震惊,以为计算出了错。
- 事实是:
cv2.contourArea()计算的是像素点的总个数。对于一张 1080P 的高清图片(总像素超200万),一个看似不大的字幕框,其面积确实就在数万像素的量级。这个发现反而证明了用面积来过滤微小噪点是一个非常可靠的方法。
-
最终的全自动流程:
我的整个项目最终沉淀为一个优雅的自动化脚本,它完成了:- 智能筛选: 使用带有形状过滤的 PaddleOCR 脚本,精确找出需要修复的帧,并生成对应的遮罩。
- 隔离处理: 将需要修复的原始帧和遮罩文件,分别放入临时的输入文件夹。
- 调用修复: 在 Python 中通过
subprocess调用iopaint run命令,对临时文件夹进行处理。 - 结果整合: 将修复好的帧与原始的干净帧合并到最终的输出文件夹中,确保总帧数不变。
- 清理收尾: 删除所有临时文件。
这个过程让我深刻体会到,一个成功的项目不仅需要强大的工具,更需要清晰的逻辑、迭代的思维,以及解决各种意外问题的耐心。