深度学习水论文:特征提取
🧀深度学习什么方向最好发论文?我认为还是特征提取,尤其对于只想毕业or发低区期刊/会议的同学来说。
🧀作为深度学习的关键任务,特征提取既重要,又很灵活。一般我们在改进baseline的时候,最简单的就是对特征提取部分进行魔改,比如改自注意力、轻量化、缝合各种经典网络结构等,这些操作可以轻松从涨分、降参数量等多个方面提高整体网络性能,非常适合要求不高的同学“水”论文。
🧀但如果有区位要求,就不能这样简单地排列组合了,建议基于近年顶会论文的创新点提炼,再结合具体任务选择技术路径。这里为了方便大家找参考,我挑选了25篇特征提取前沿论文分享,包含顶会顶刊+开源代码~我给大家准备了10种创新思路和源码,一起来看有需要的搜索人人人人人人人工重号(AI科技探寻)免费领取
论文1
标题:
Adapter Learning in Pretrained Feature Extractor for Continual Learning of Diseases
预训练特征提取器中的适配器学习用于疾病的持续学习
方法:
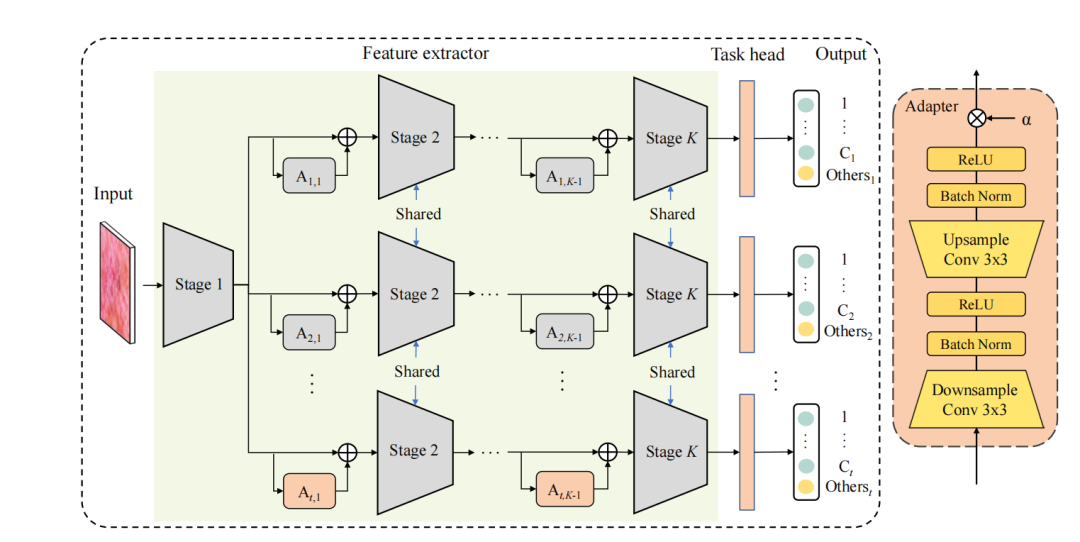
适配器学习框架(ACL):提出了一种基于适配器的持续学习框架,通过在预训练的固定特征提取器中添加轻量级的适配器模块,实现对新疾病的持续学习。
任务特定适配器:为每个学习轮次设计了轻量级的任务特定适配器,这些适配器被添加到预训练的卷积神经网络(CNN)的连续卷积阶段之间,以帮助提取新疾病的判别性特征。
任务特定分类器头:为每个新任务设计了一个任务特定的分类器头,其中将之前学习的所有旧类别视为“分布外”(OOD)类别,并在训练时将这些类别合并到一个额外的输出神经元中。
微调策略:应用了一种简单的微调策略,通过平衡训练数据对多个任务特定头进行联合微调,以确保不同头的输出具有可比性,并在模型推理时能够更准确地选择适当的分类器头。
创新点:
轻量级适配器模块:通过在预训练的固定特征提取器中添加轻量级的任务特定适配器,实现了对新疾病的持续学习,而无需改变共享的特征提取器,有效避免了灾难性遗忘。
任务特定分类器头:通过将之前学习的所有旧类别视为“分布外”类别,并在任务特定分类器头中增加一个额外的输出神经元,显著提高了特征的判别性,使得模型能够更好地区分不同任务的类别。
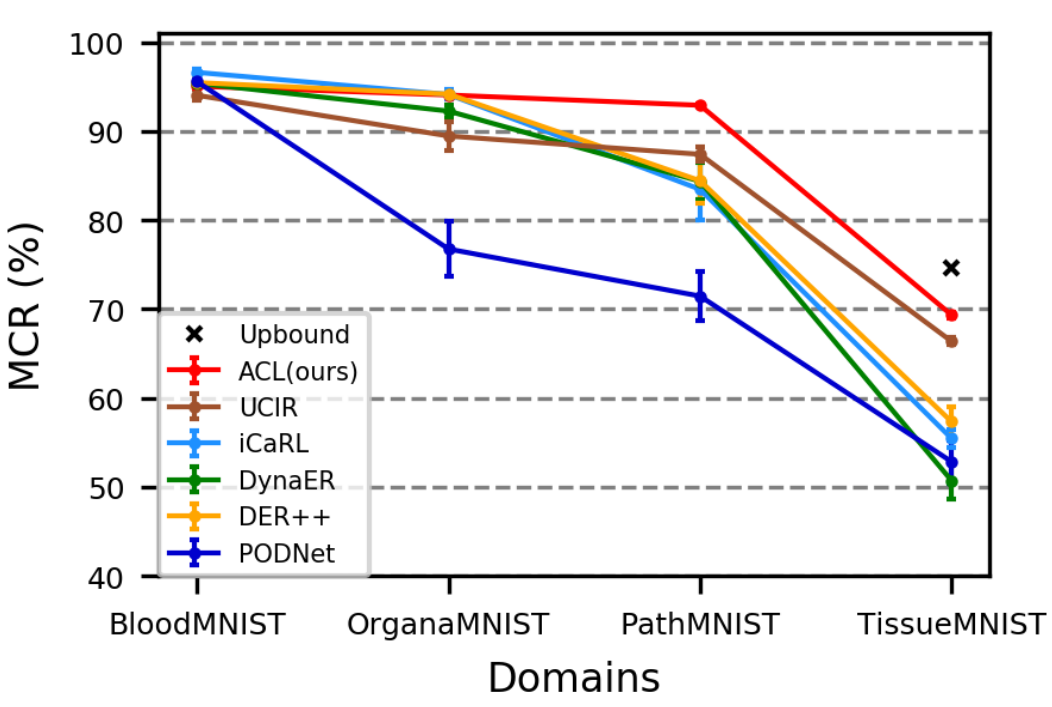
性能提升:在多个医学图像数据集(如Skin8、Path16、CIFAR100和MedMNIST)上进行了广泛的实验评估,ACL方法在持续学习新疾病方面显著优于现有的持续学习方法。例如,在Skin8数据集上,ACL的平均类别召回率(MCR)为66.44%,而其他强基线方法如iCaRL和DynaER的MCR分别为62.16%和60.24%。
论文2
标题:
DDPM-CD: Denoising Diffusion Probabilistic Models as Feature Extractors for Change Detection
DDPM-CD:将去噪扩散概率模型作为特征提取器用于变化检测
方法:
DDPM预训练:利用去噪扩散概率模型(DDPM)作为特征提取器,通过在大量未标记的遥感图像上进行自监督预训练,学习图像数据分布。
特征提取:从预训练的DDPM中提取多尺度、多时间步的特征表示,这些特征表示能够捕捉图像中的语义信息。
变化检测分类器:利用提取的特征表示训练一个轻量级的变化检测分类器,通过比较预变化和后变化图像的特征差异来预测变化概率图。
层次化变化解码器:设计了一个层次化变化解码器,通过在不同空间尺度上逐步计算特征差异,增强特征的判别能力。
创新点:
DDPM作为特征提取器:首次将DDPM用于变化检测任务,利用其强大的特征提取能力,显著提高了变化检测的性能。
多尺度、多时间步特征融合:通过结合不同尺度和时间步的特征表示,增强了特征的多样性和判别能力,从而提高了变化检测的准确性。
性能提升:在LEVIR-CD、WHU-CD、DSIFN-CD和CDD四个公开数据集上进行了广泛的实验,DDPM-CD方法在F1分数、IoU和总体准确率方面显著优于现有的变化检测方法。例如,在LEVIR-CD数据集上,DDPM-CD的F1分数为90.91%,IoU为83.35%,而其他强基线方法如FC-EF和FC-Siam-diff的F1分数分别为83.40%和86.31%。
论文3
标题:
Deconstructing Denoising Diffusion Models for Self-Supervised Learning
解构去噪扩散模型用于自监督学习
方法:
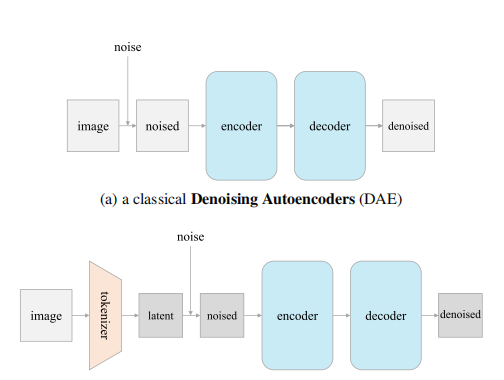
去噪扩散模型(DDM):研究了DDM在图像生成中的表示学习能力,通过逐步将DDM解构为经典的去噪自编码器(DAE),探索了现代DDM的各种组件对自监督表示学习的影响。
低维潜在空间:发现低维潜在空间是学习良好表示的关键组件,而与特定的编码器(如VAE、PCA)无关。
单噪声水平:研究表明,即使使用单一噪声水平(而不是DDM中的多噪声水平),也能获得相当好的结果。
逆PCA:通过逆PCA将特征从潜在空间映射回图像空间,使得模型可以直接在图像空间进行操作,而无需复杂的编码器
创新点:
简化模型结构:通过解构DDM,最终得到了一个高度简化的模型结构,类似于经典的DAE,但具有更好的自监督学习性能。
低维潜在空间的重要性:发现低维潜在空间是学习良好表示的关键,而与特定的编码器无关,这为设计更高效的自监督学习方法提供了新的思路。
性能提升:在ImageNet数据集上进行的实验表明,解构后的模型(l-DAE)在自监督学习任务中取得了65.1%的线性探测精度,与现有的自监督学习方法(如MAE)相当,但模型结构更简单。
单噪声水平的有效性:研究表明,即使不使用DDM中的多噪声水平,仅使用单一噪声水平也能获得较好的结果,这简化了模型的设计和训练过程。
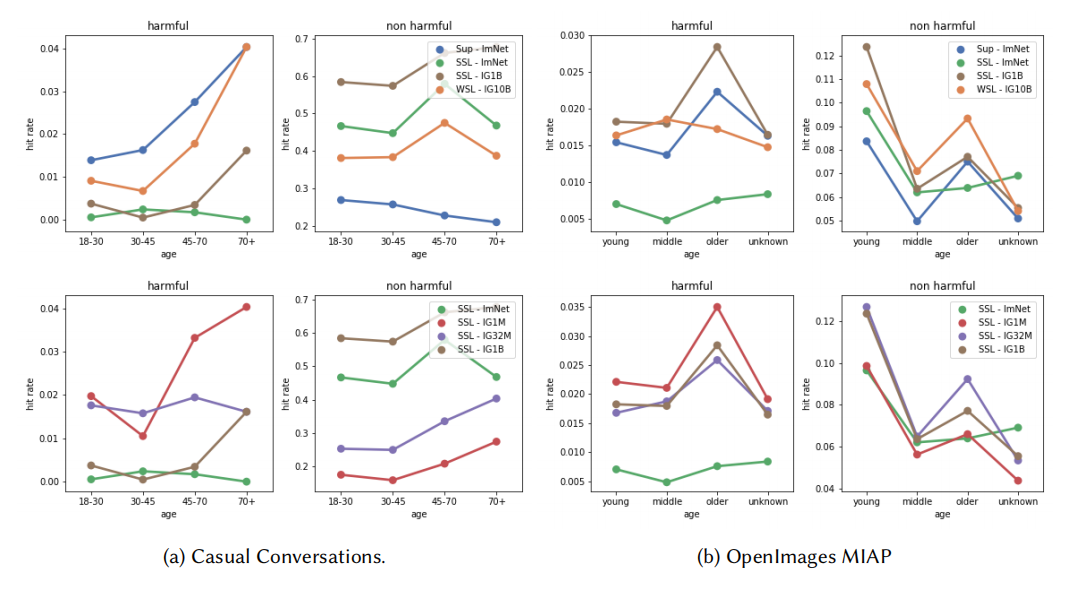
论文4
标题:
Fairness Indicators for Systematic Assessments of Visual Feature Extractors
用于系统评估视觉特征提取器的公平性指标
方法:
- 公平性指标:提出了三个公平性指标,用于量化视觉系统中的特定危害和偏见,包括有害标签关联、地理多样性以及社会和人口统计特征的表示差异。
实验协议:定义了适用于广泛计算机视觉模型的实验协议,使用公开可用的数据集来评估模型的公平性。
分类器基础指标:通过在特定数据集上微调特征提取器来构建分类器,评估模型在不同敏感群体上的表现差异。
相似性搜索指标:通过相似性搜索任务直接评估特征空间,测量不同敏感群体之间的表示差异。
创新点
系统化评估:提出了一个系统化的框架,用于评估视觉特征提取器的公平性,填补了当前研究中缺乏标准化公平性评估的空白。
多维度公平性评估:通过三个不同的指标,从有害标签关联、地理多样性和社会人口统计特征等多个维度评估模型的公平性,提供了更全面的评估视角。
性能提升:实验结果表明,自监督学习方法(如SEER)在大规模数据集上训练的模型在公平性指标上表现最佳,显著优于传统的监督学习方法。例如,在地理多样性指标上,SEER在低收入和非西方地区的相对改进达到了25%以上。
数据规模和领域的影响:研究表明,增加数据规模和使用多样化的数据领域可以显著提高模型的公平性,尤其是在地理多样性和社会人口统计特征的表示上