pandas库的数据导入导出,缺失值,重复值处理和数据筛选,matplotlib库 简单图绘制
目录
一.数据导入导出
1.CSV文件读取与参数说明
2.Excel与TST文件读取
3.数据导出操作
二.缺失值处理
1.填充缺失值
2.删除缺失值【删除整行数据】
三.重复值处理
四.数据筛选与条件查询
1.逻辑判断+取数
2.字符匹配
3.逻辑运算: &(和)、|(或)
五.matplotlib库 简单图绘制
1.绘制点线图:
2.直方图:
3.多子图绘制
一.数据导入导出
Pandas支持多种数据格式,包括CSV、Excel(XLSX/XLS)、TXT等
1.CSV文件读取与参数说明
- 使用
read_csv()方法读取CSV文件,自动识别逗号分隔符。 - 参数
header控制是否将第一行作为列名:header=None表示无列名,第一行视为数据。
- 默认将第一行作为列名(如
name, age, income)。import pandas as pddf_1 = pd.read_csv("data1.csv") print(df_1)name age income 0 lili 20 2000 1 peter 21 2300 2 jim 22 2200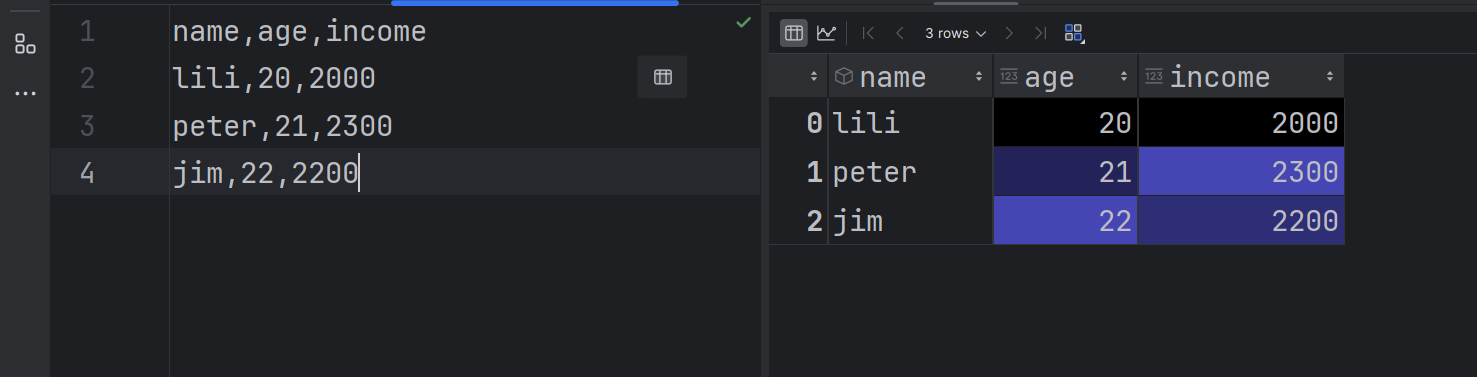
2.Excel与TXT文件读取
- Excel文件通过
read_excel()读取,同样支持header参数。 - TXT文件使用
read_table(),需指定分隔符(sep参数)和是否包含列名。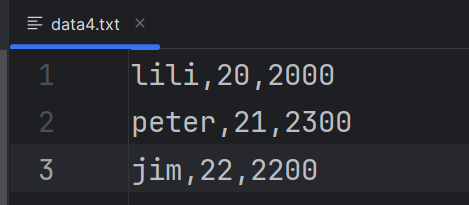
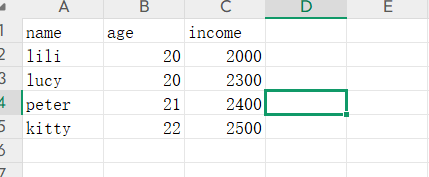
df_1 = pd.read_excel("data3.xlsx")name age income 0 lili 20 2000 1 lucy 20 2300 2 peter 21 2400 3 kitty 22 2500 df_2 = pd.read_table("data4.txt",sep=',',header=None)0 1 2 0 lili 20 2000 1 peter 21 2300 2 jim 22 22003.数据导出操作
导出CSV:to_csv()方法,参数包括:
header=True(导出列名)。
index=True(是否导出行索引)。
导出Excel:to_excel()参数与CSV类似,仅格式不同。
import pandas as pddf_1 = pd.read_csv("data1.csv")
df_1.to_csv(r"导出的地址",index=True, header=True)
df_2 = pd.read_excel("data3.xlsx")
df_2.to_excel(r"导出的地址",index=True, header=True)二.缺失值处理
缺失值处理方式:
1.数据补齐,填充缺失值 2.删除对应数据行 3.不处理
- 缺失数据在Pandas中显示为
NaN(如未填写的单元格)。 - 检测缺失值:
isnull()函数返回布尔类型DataFrame,标记空缺位置为True显示如下。import pandas as pd df = pd.read_csv(r"data.csv",encoding='gbk') na = df.isnull()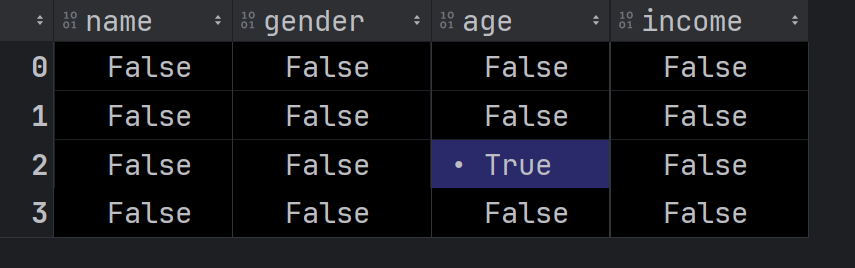
1.填充缺失值
使用 fillna()方法 填充缺失值
df1 = df.fillna('需要填充的值')
2.删除缺失值【删除整行数据】
df2 = df.dropna()
三.重复值处理
- 通过
duplicated()检测重复行,返回布尔值标识重复项(完全相同的行或指定列重复)。import pandas as pd df = pd.read_csv(r"data1.csv",encoding='gbk') result1 = df.duplicated()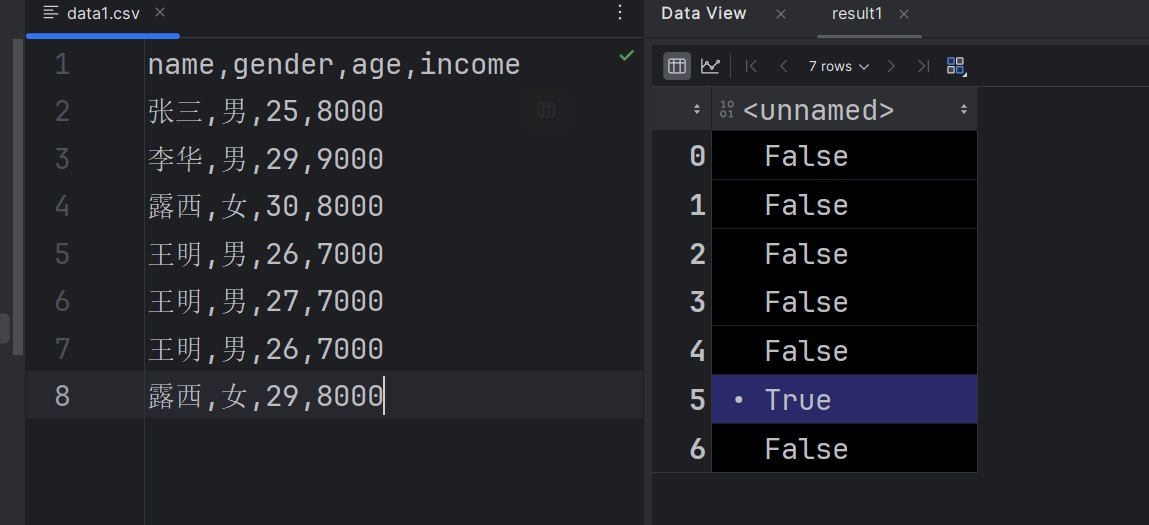
- 根据列名(如
name和gender)判断重复性,结合布尔索引提取重复行数据。result2 = df.duplicated('gender')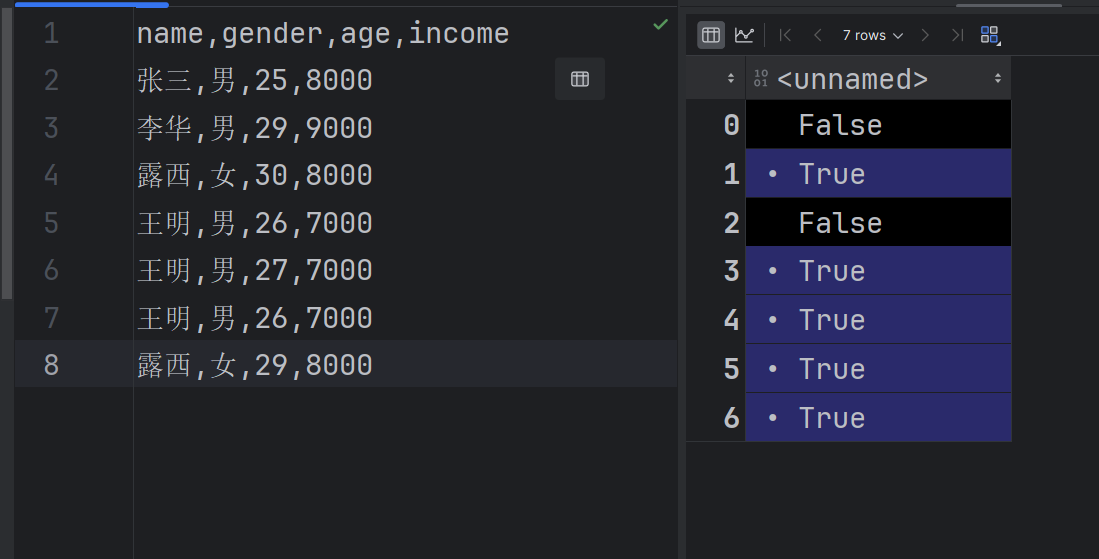
result3 = df.duplicated(['gender', 'name'])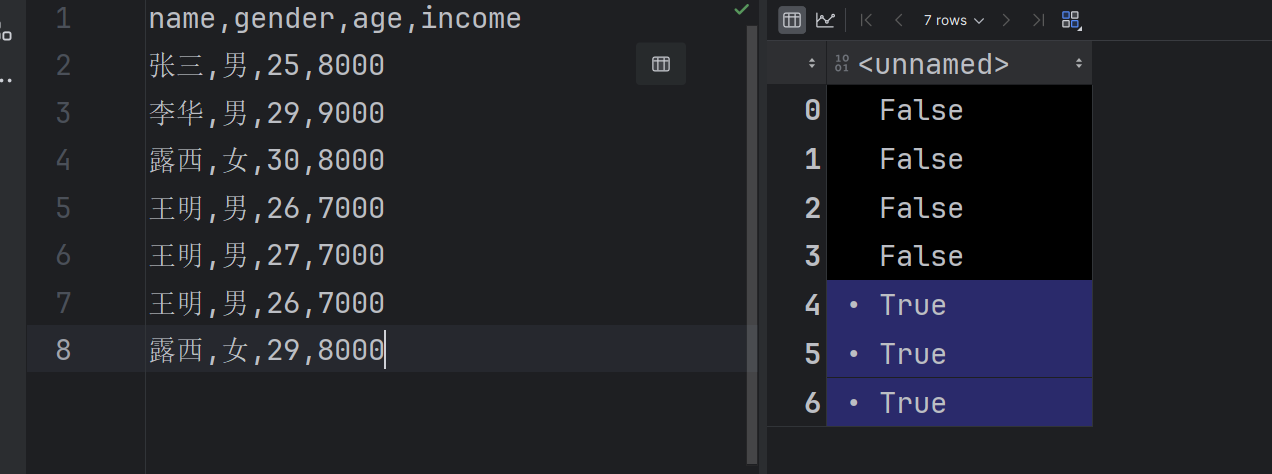
- 使用
drop_duplicates()删除重复行,需注意删除后索引可能不连续,需手动调整。#删除完全重复行 new_df1 = df.drop_duplicates()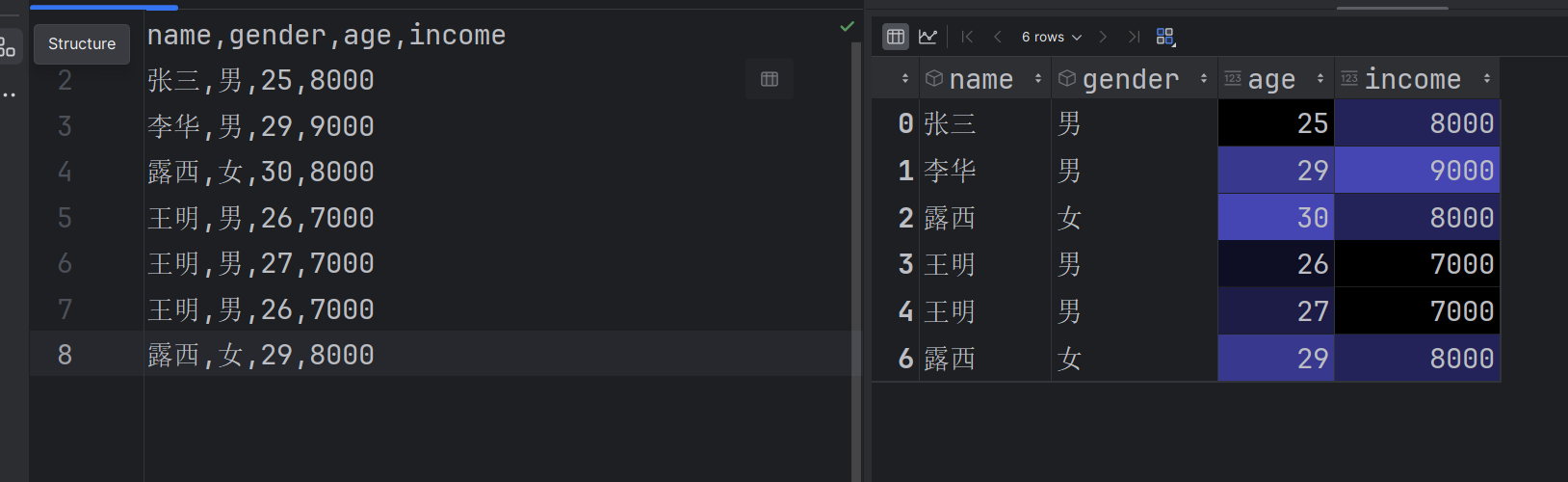
#删除部分重复【根据某列名来删除】 new_df2 = df.drop_duplicates(['name', 'gender'])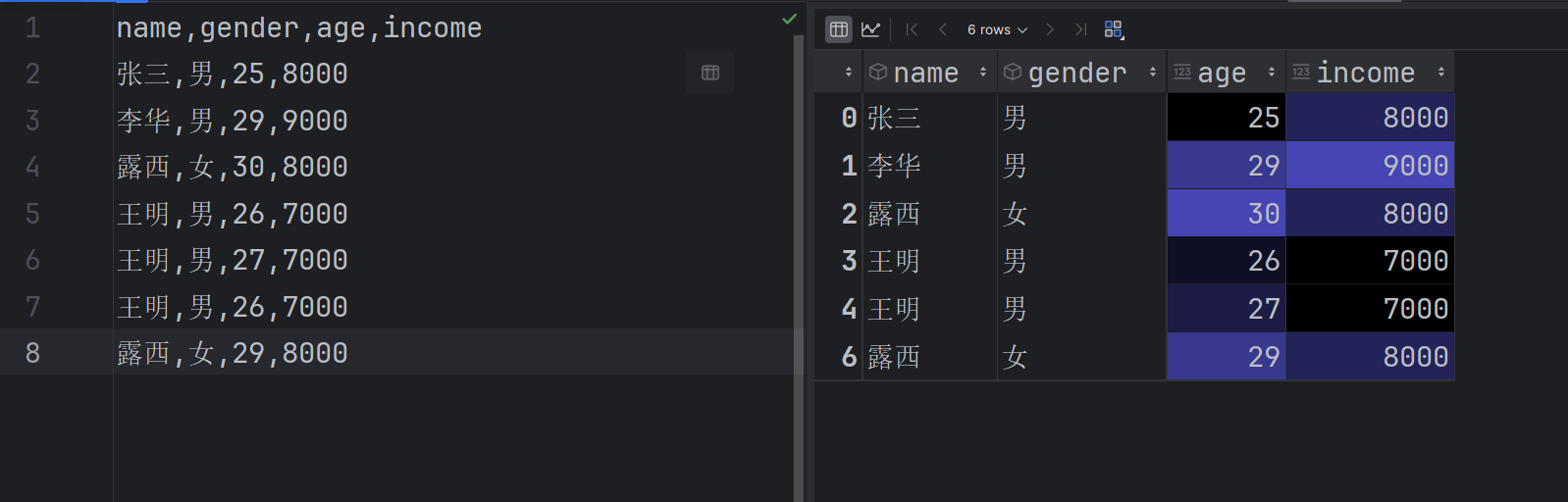
四.数据筛选与条件查询
1.逻辑判断+取数
通过布尔条件(如 好评数 > 17000)筛选数据,生成 True/False 序列后提取对应行。
使用 between() 方法筛选数值范围内的数据(如 好评数在15000到17000之间)。
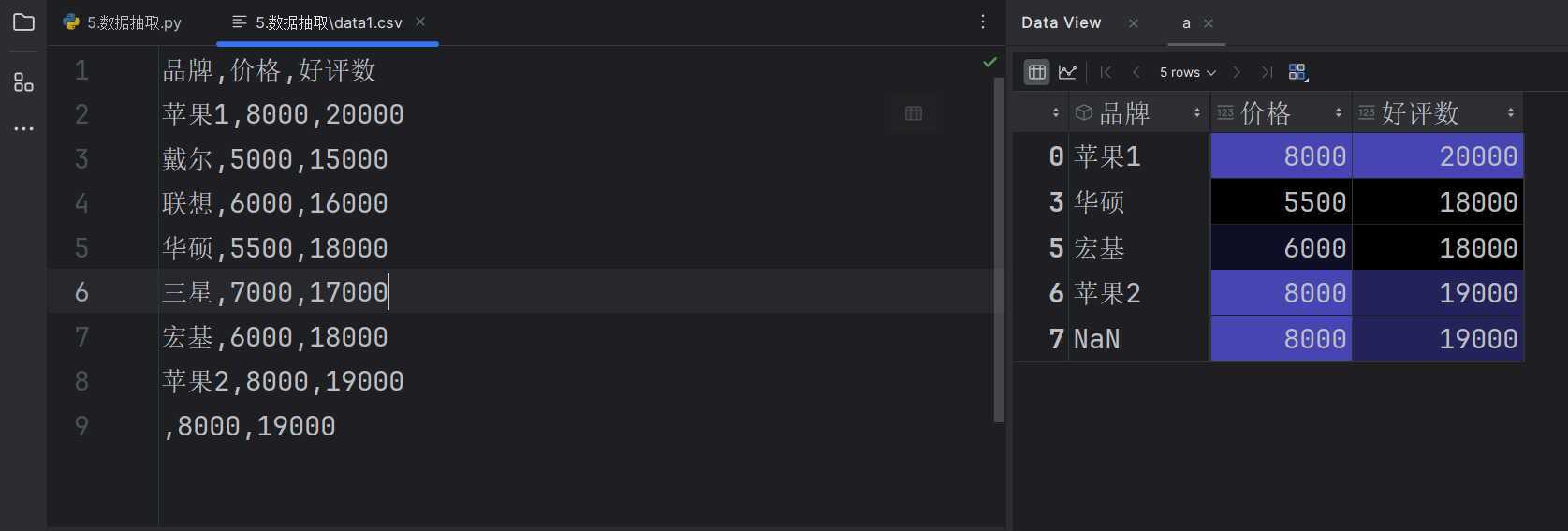
import pandas as pddf = pd.read_csv(
r"data1.csv",encoding='gbk')#抽取好评数大于17000的电脑
df[df['好评数'] > 17000]
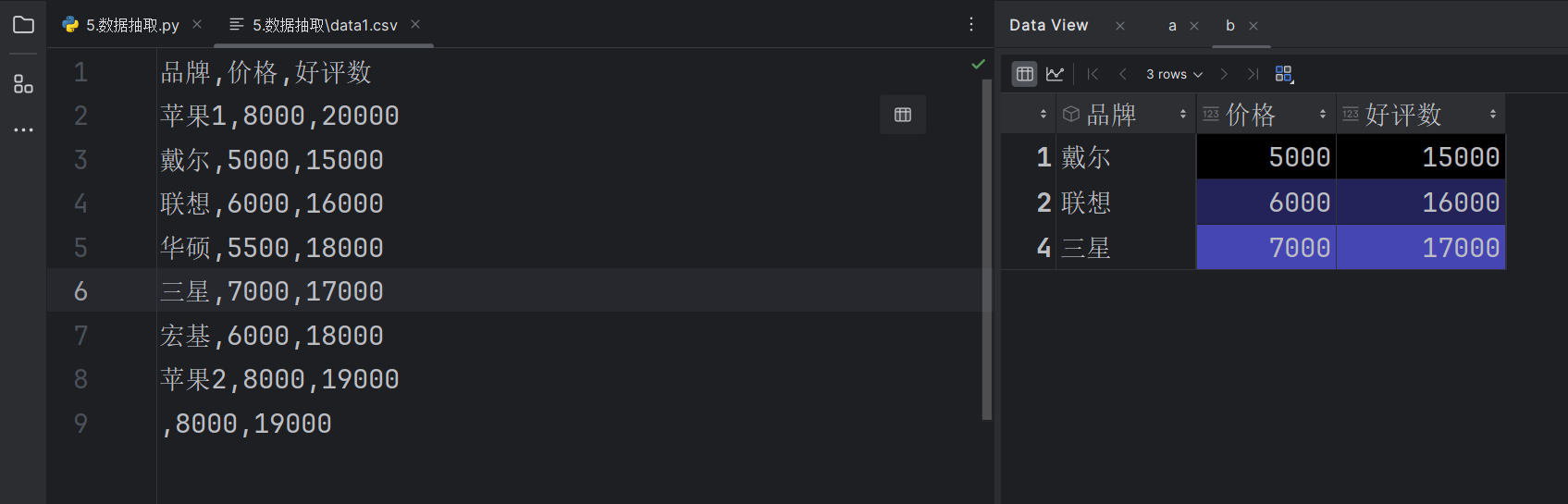
#抽取好评数在15000到17000之间的电脑
df[df['好评数'].between(15000, 17000)]
2.字符匹配
通过str.contains()方法筛选包含特定字符(如“苹果”)的内容
na=False参数的作用(忽略缺失值)与na=True的区别(将缺失值纳入匹配结果)。
df[df['品牌'].str.contains('苹果',na=False)]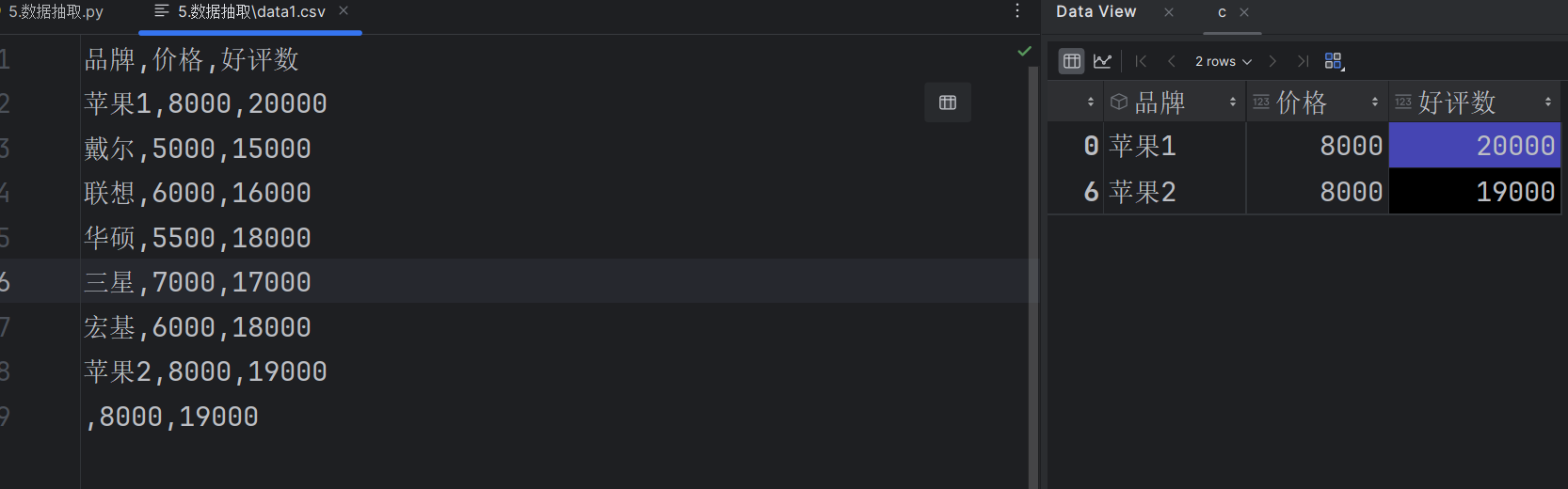
3.逻辑运算: &(和)、|(或)
&:所有条件都满足则返回True
| :满足一个条件就返回True
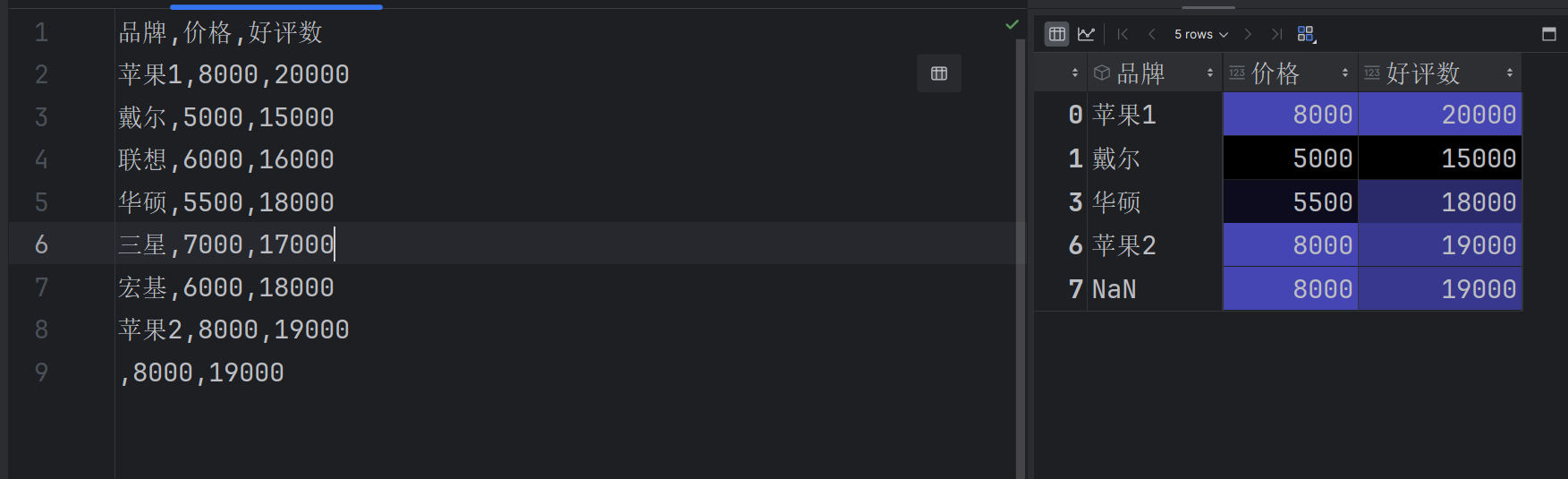
df[(df['价格']<7000) & (df['好评数'] > 16000)]
df[(df['价格']<6000) | (df['好评数']>18000)]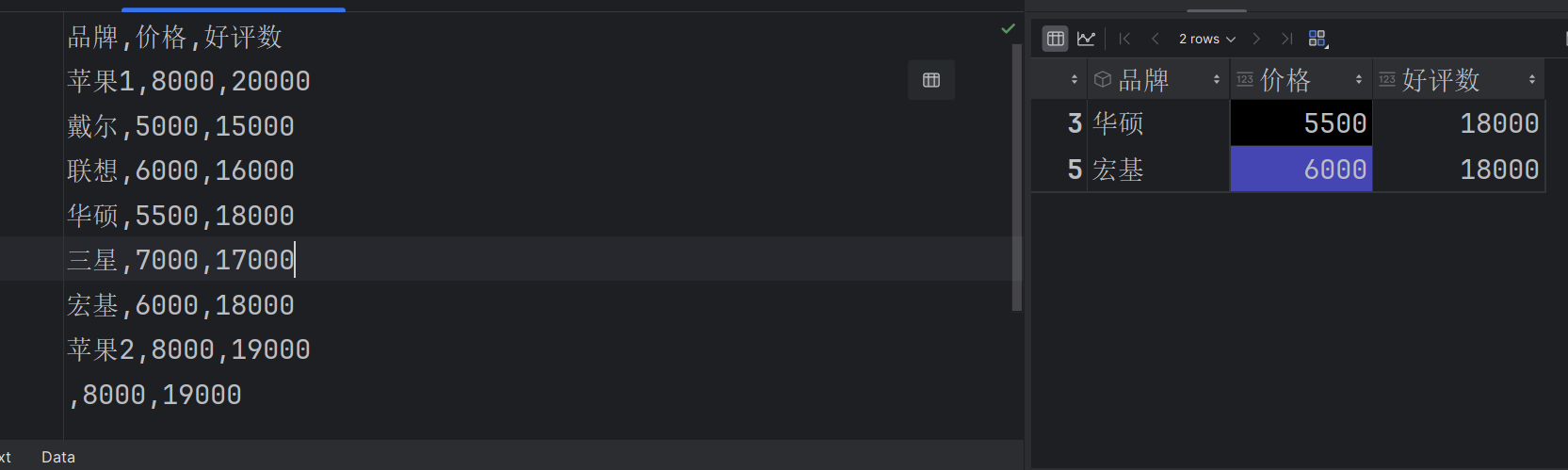
五.matplotlib库 简单图绘制
1.绘制点线图:
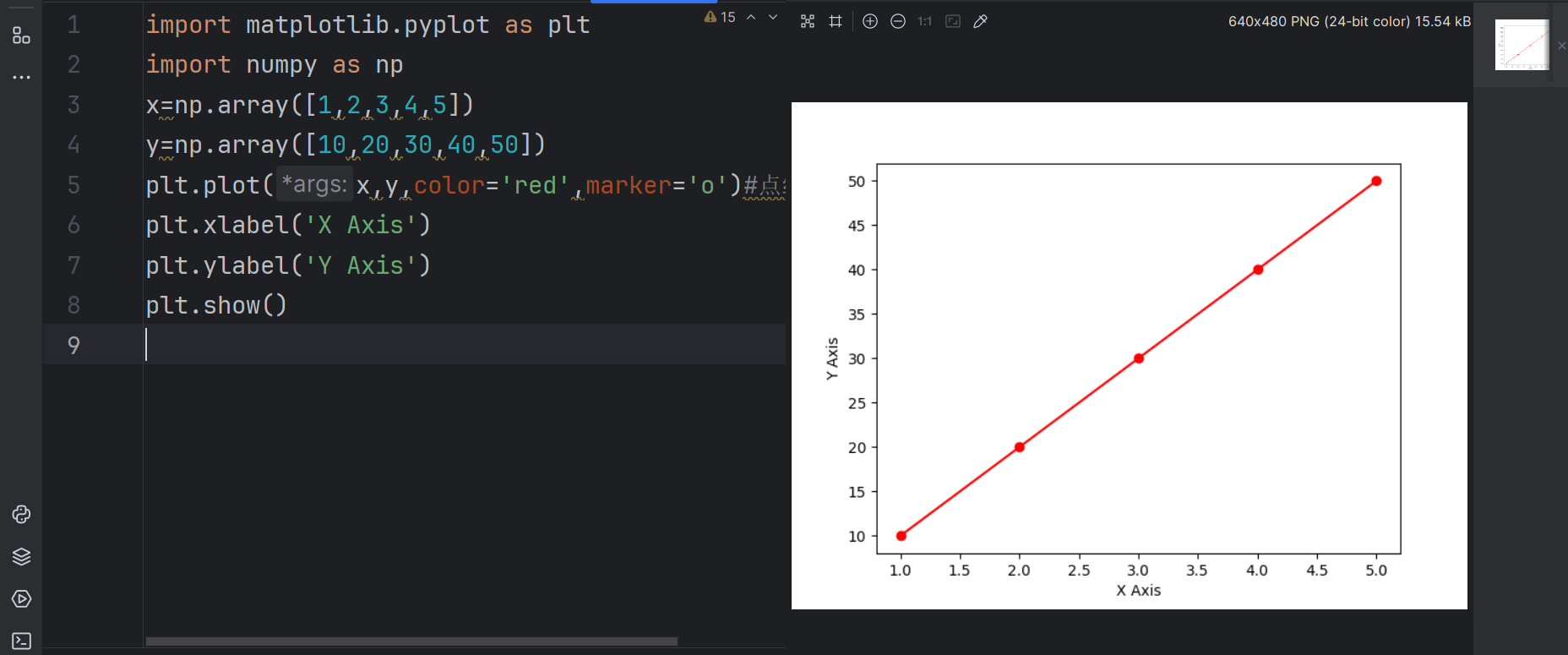
通过plt.plot(x, y)传入X/Y轴数据,设置颜色(color)和标记形状(marker),添加标题(title)和轴标签(xlabel/ylabel)。
import matplotlib.pyplot as plt
import numpy as np
x=np.array([1,2,3,4,5])
y=np.array([10,20,30,40,50])
plt.plot(x,y,color='red',marker='o')#点线图
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.show()
2.直方图:
使用plt.hist()绘制单值条形图
data = [1, 1, 1, 2, 2, 3, 3, 3, 3, 4, 4, 5, 5, 5, 5, 5]
plt.hist(data,color='red')
plt.show()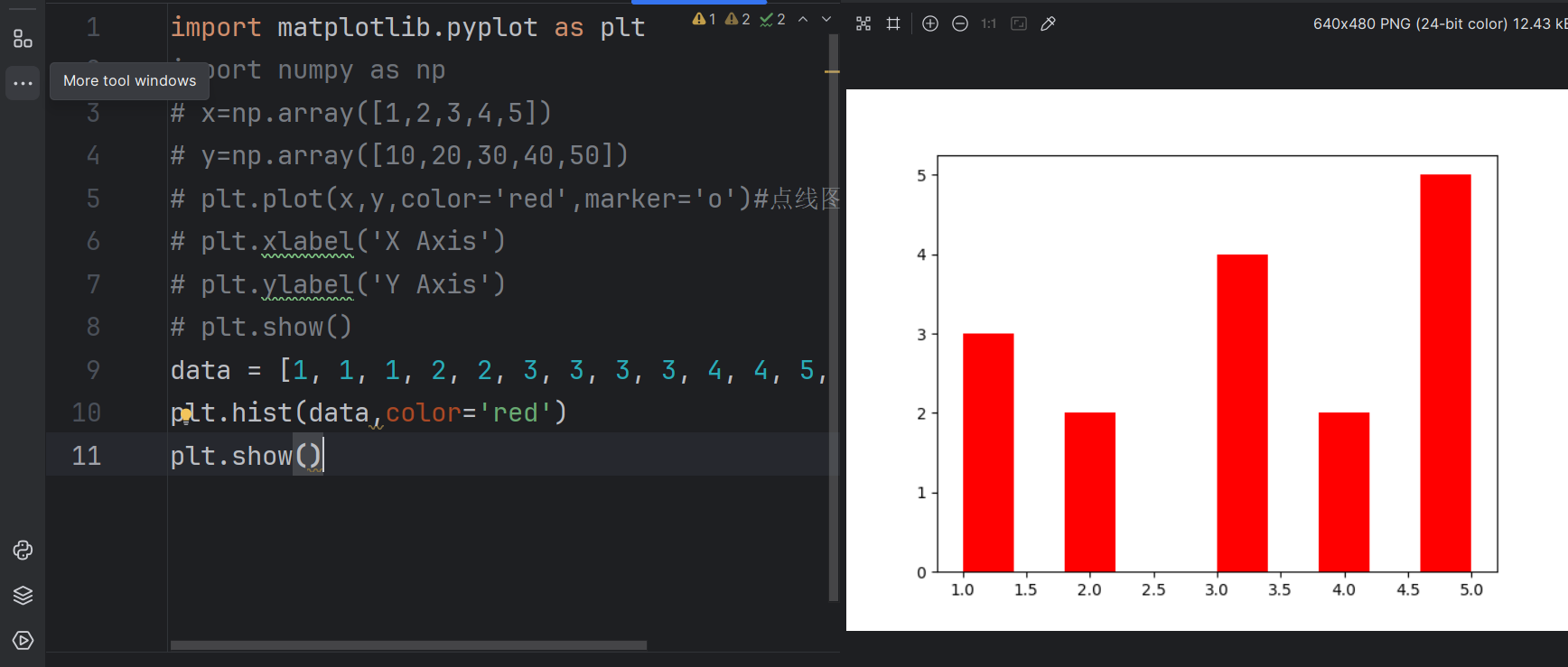
3.多子图绘制
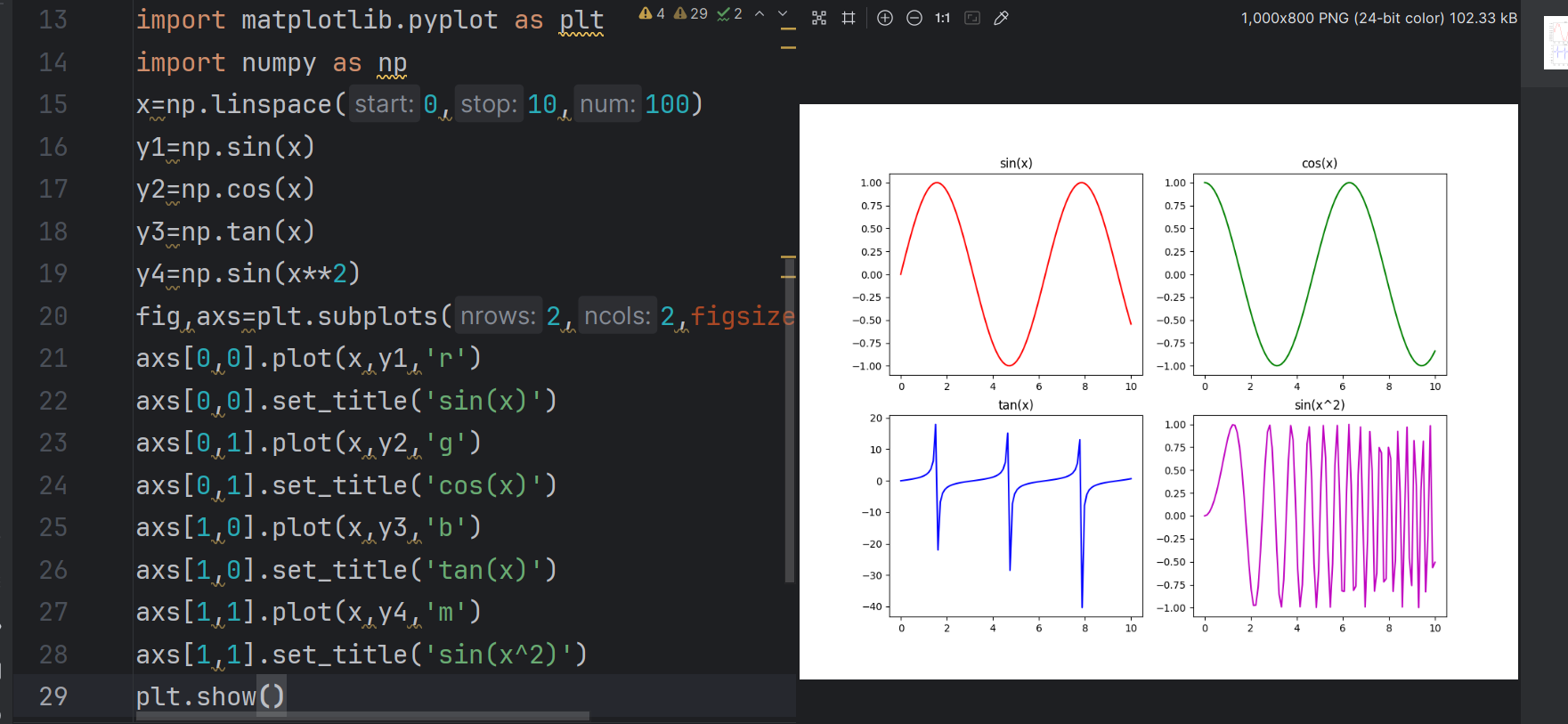
通过plt.subplot()在同一画布上分区域绘制多个图形(如正弦、余弦函数),结合np.linspace()生成等间隔数据点。
使用 plt.subplot 创建两行两列的子图(共4个),图像大小为10x8。
- 子图通过矩阵(
ndarray)管理,通过索引(如ax[0,0])在指定位置添加数据:- 第0行第0列:绘制
X和y1(红色),标题为sin(x)。 - 第0行第1列:绘制
X和y2(绿色),标题为cos(x)。 - 第1行第0列:绘制
X和y3(蓝色),标题为tan(x) - 第1行第1列:绘制
X和y4(粉色),标题为sin(x^2)
- 第0行第0列:绘制
import matplotlib.pyplot as plt
import numpy as np
x=np.linspace(0,10,100)
y1=np.sin(x)
y2=np.cos(x)
y3=np.tan(x)
y4=np.sin(x**2)
fig,axs=plt.subplots(2,2,figsize=(10,8))
axs[0,0].plot(x,y1,'r')
axs[0,0].set_title('sin(x)')
axs[0,1].plot(x,y2,'g')
axs[0,1].set_title('cos(x)')
axs[1,0].plot(x,y3,'b')
axs[1,0].set_title('tan(x)')
axs[1,1].plot(x,y4,'m')
axs[1,1].set_title('sin(x^2)')
plt.show()