11-day08文本匹配
文本匹配应用
- 问答对话
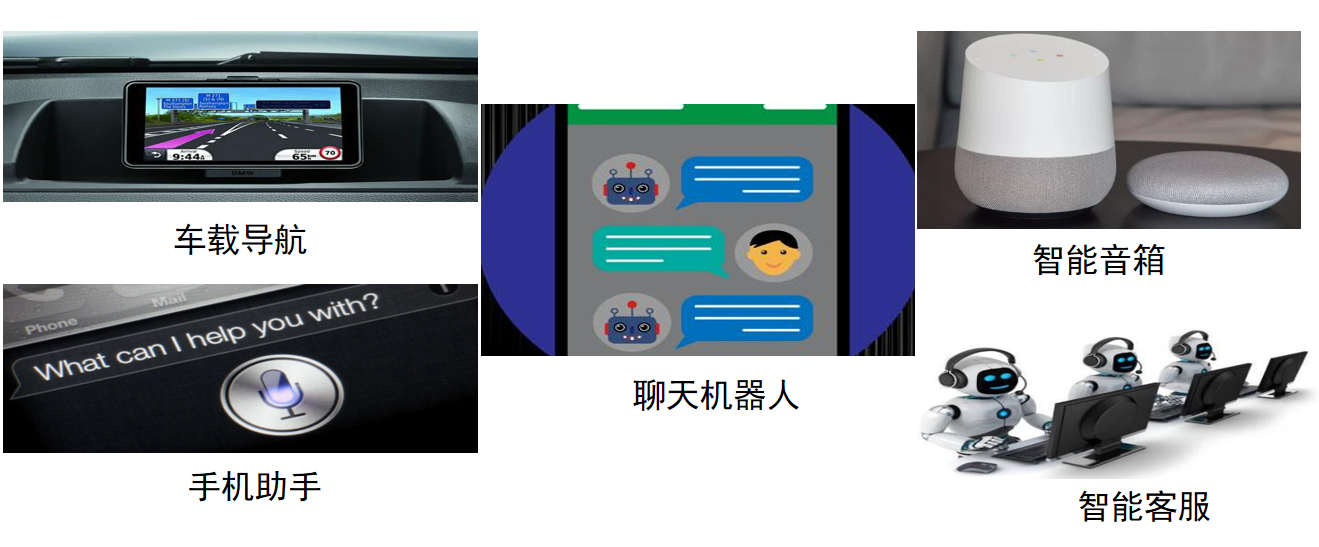
- 信息检索

- 短文本 vs 短文本
知识库问答 ,聊天机器人等 - 短文本 vs 长文本
文章检索,广告推荐等 - 长文本 vs 长文本
新闻、文章的关联推荐等
智能问答
-
基本思路
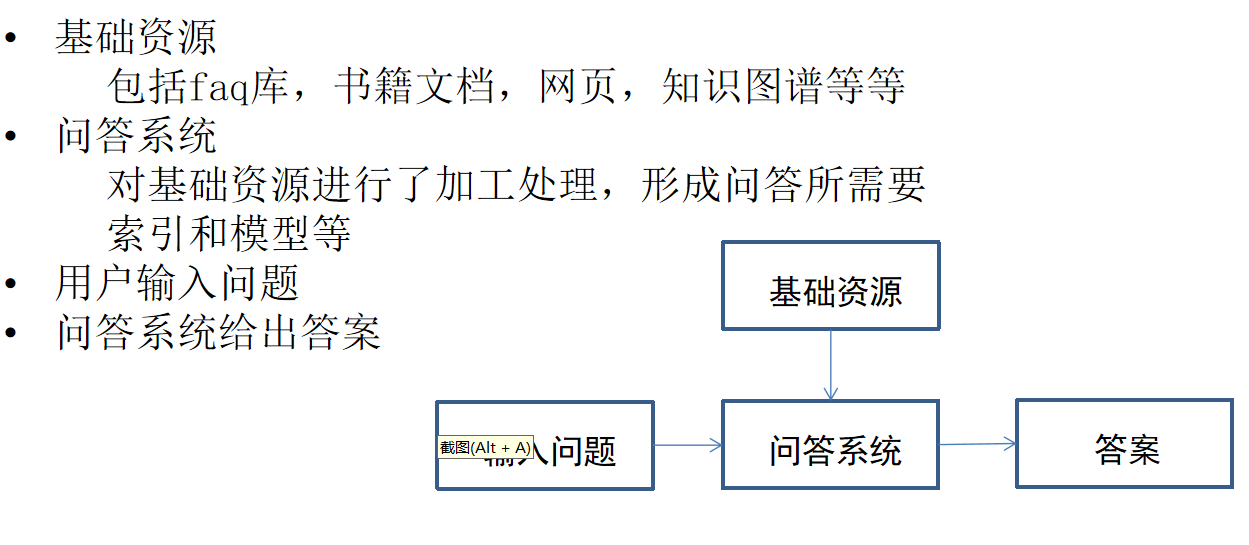
-
技术路线
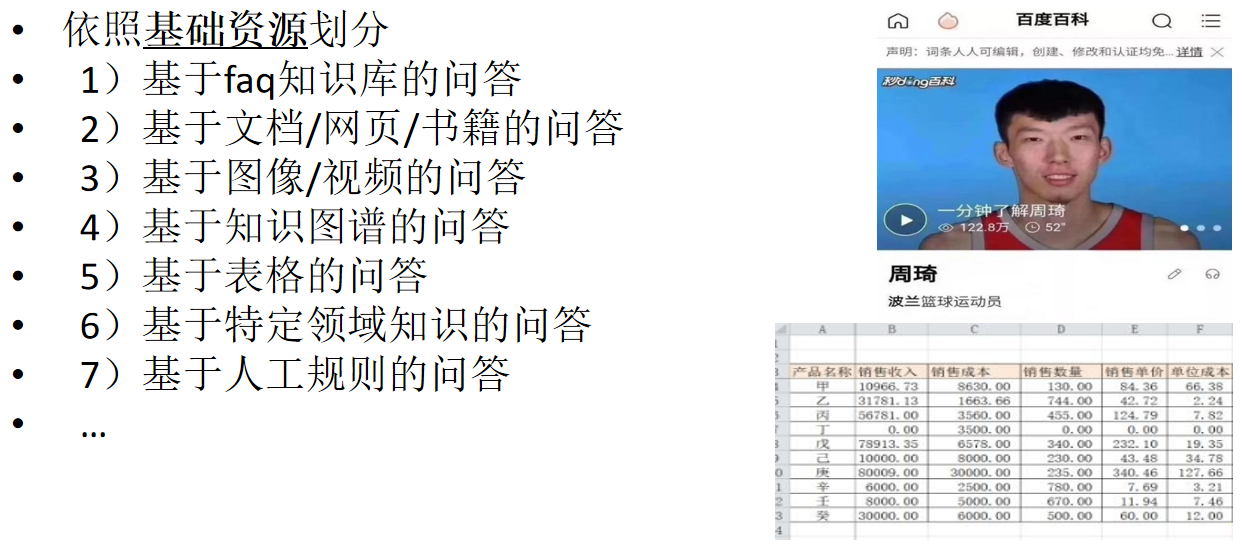
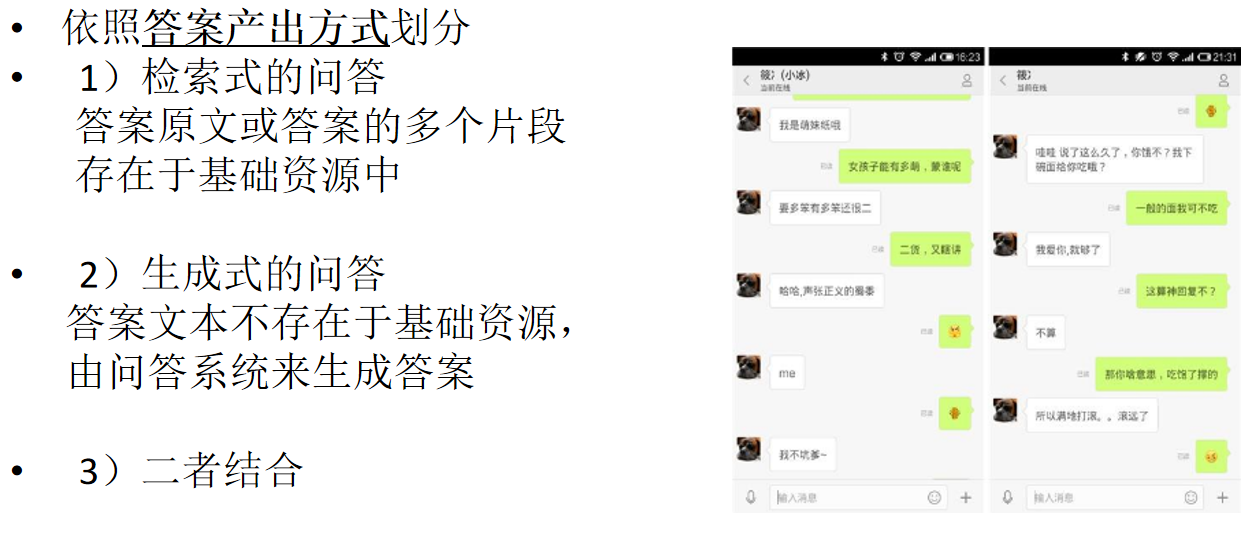

-
价值

-
FAQ知识库问答
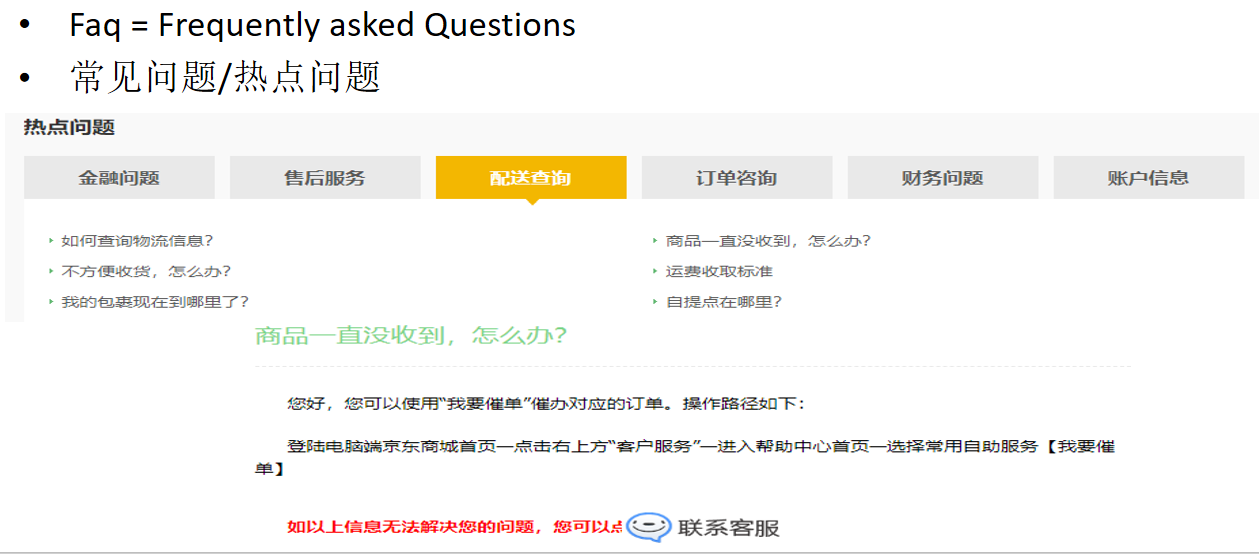


-
相关名词
1.问答对
一个(或多个相似的)问题与它对应的答案
2.faq库/知识库
很多问答对组成的集合
3.标准问
每组问答对中的问题,有多个时,为其中代表
4.相似问/扩展问
问答对中,标准问之外的其他问题
5.用户问
用户输入的问题
6.知识加工
人工编辑faq库的过程 -
运行逻辑
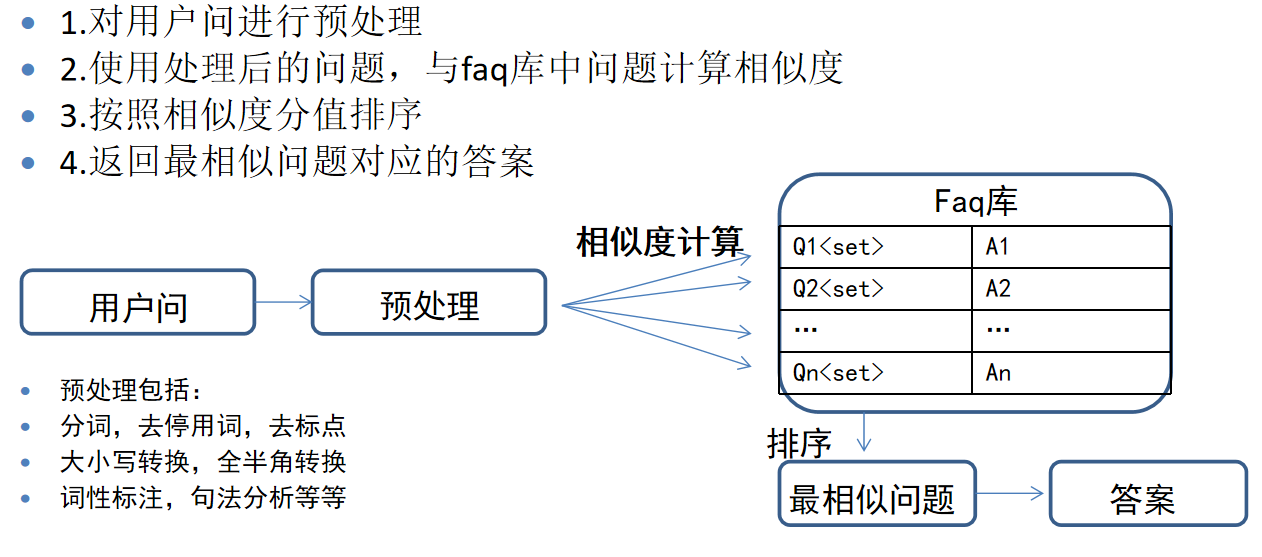
-
算法核心
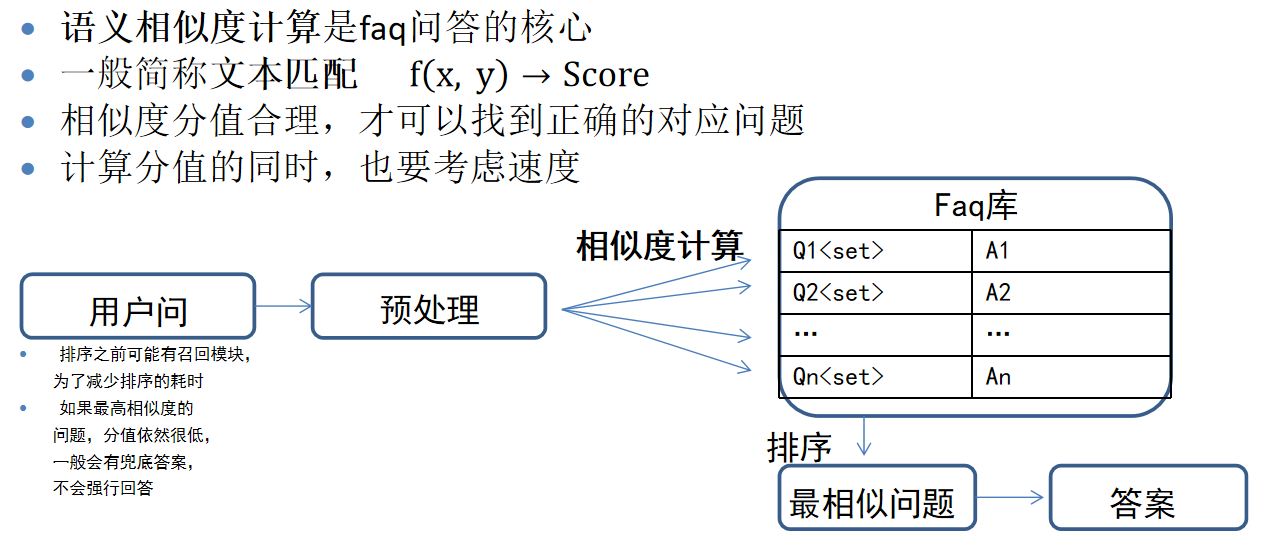
文本匹配算法-编辑距离



文本匹配算法-Jaccard相似度


文本匹配算法-BM25算法


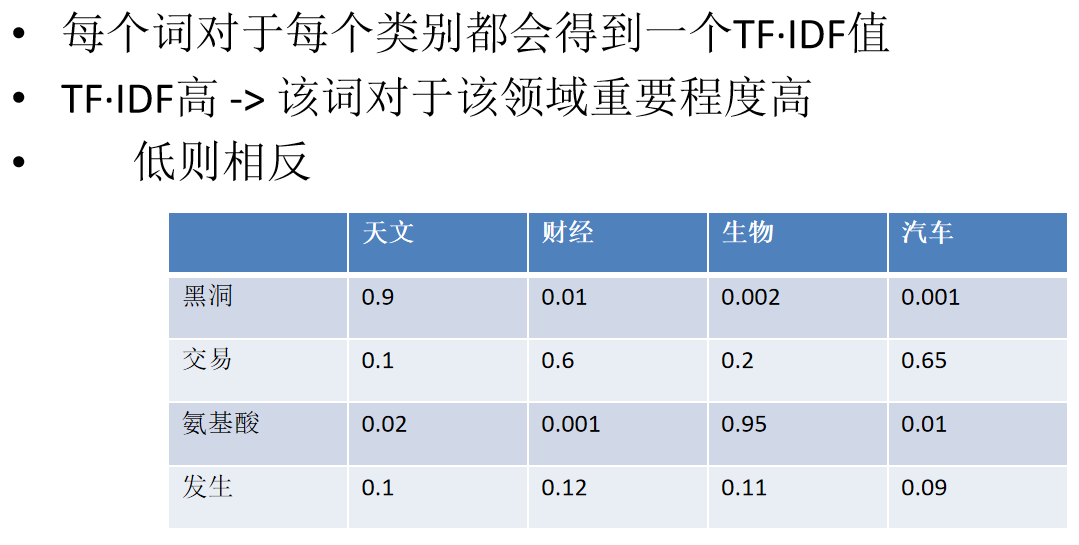

- 优点:
1.通过使用TF·IDF弱化了无关词的影响,强化了重要词的影响,使得效果大幅提升
2.统计模型计算快,不需要迭代
3.词袋模型*、跨语种等 - 缺点:
1.依然没有考虑词与词之间的相似性
2.需要一定量的训练(统计)样本(faq库本身)
3.对于新增类别,需要重新计算统计模型
4.分值未归一化
文本匹配算法-word2vec
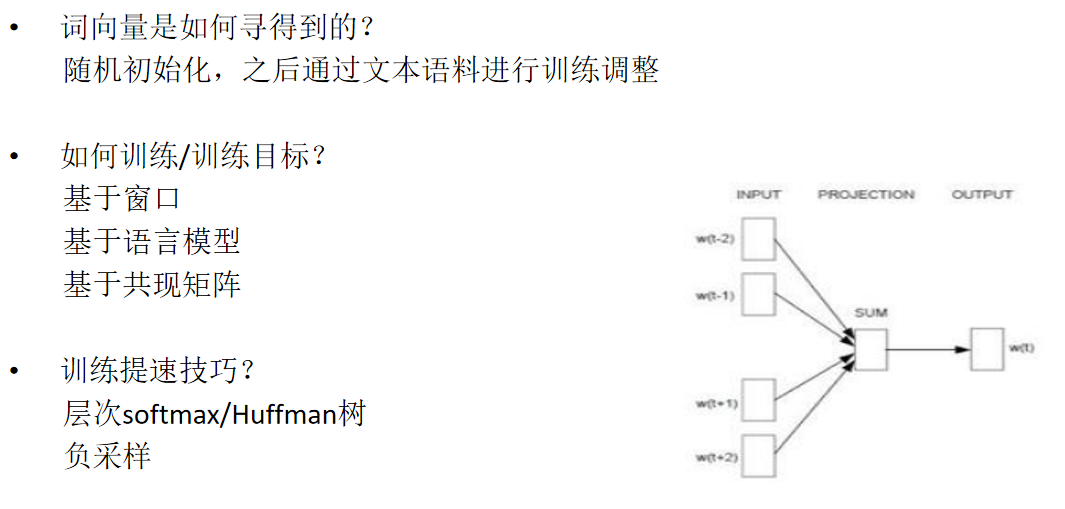
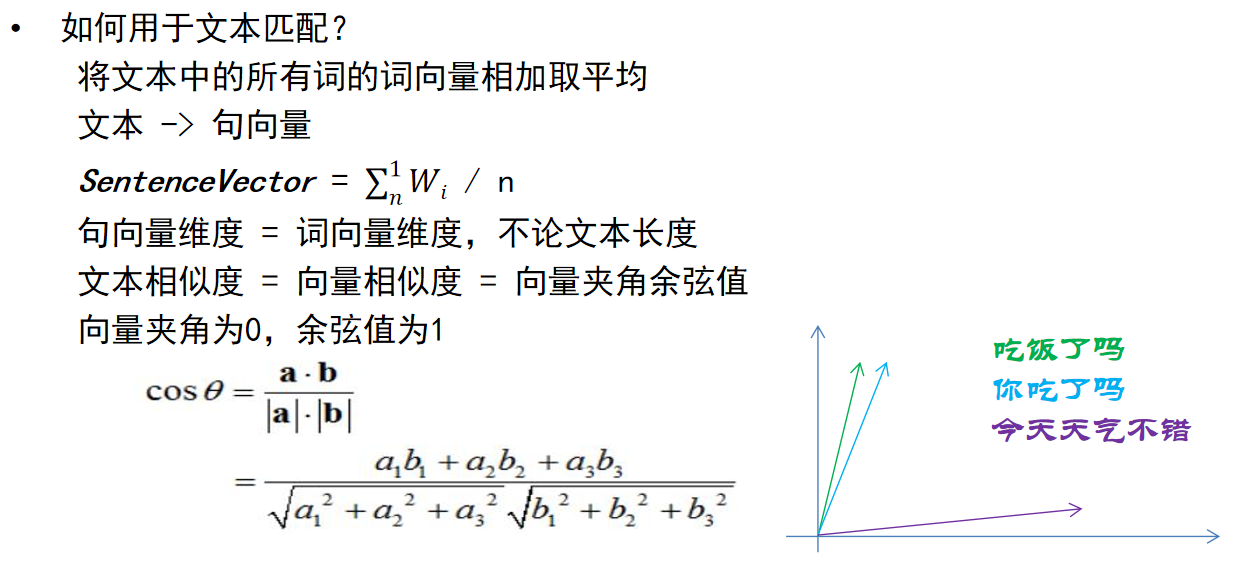
- 优点:
1.两个文本包含语义相似的词,会提高相似度
2.训练需要的数据简单(纯文本语料即可)
3.计算速度快,可以对知识库内问题预先计算向量
4.将文本转化为数字,使后续复杂模型成为可能 - 缺点:
1.词向量的效果决定句向量效果
2.一词多意的情况难以处理(梨-苹果-华为)
3.受停用词和文本长度影响很大(也是词袋模型)
4.更换语种,甚至更换领域,都需要重新训练
问答系统案例
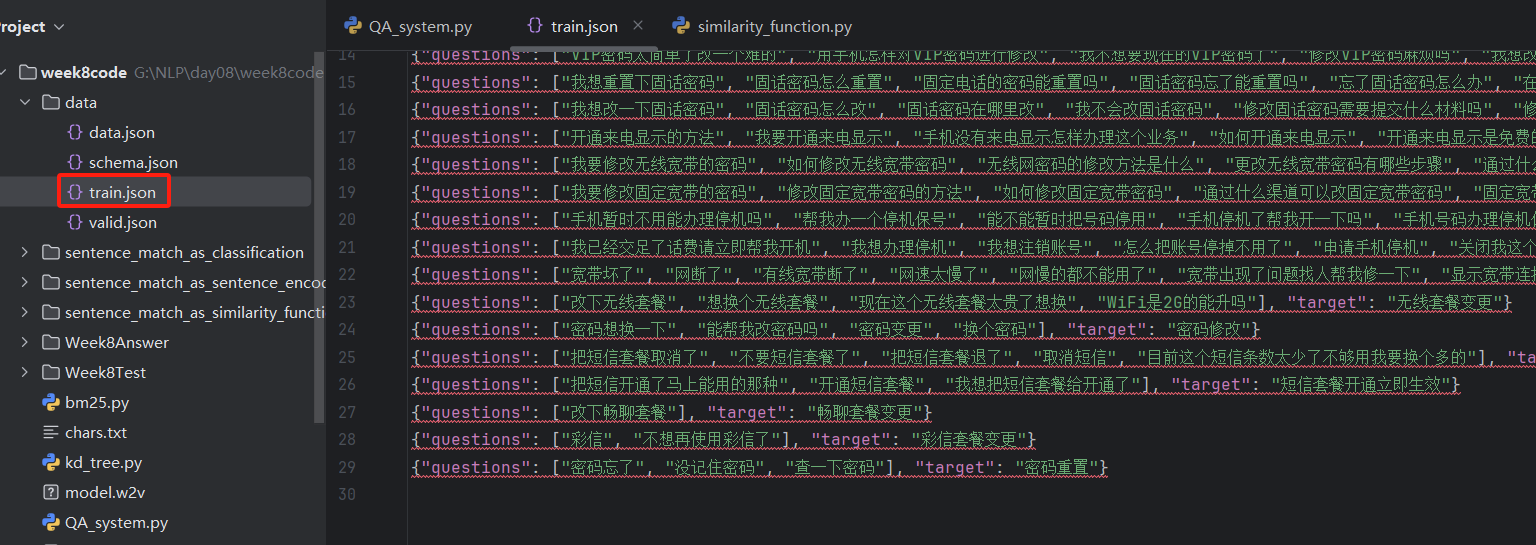
<similarity_function.py>
import numpy as np
'''
包含编辑距离和jaccard相似度的实现
'''
#编辑距离
def editing_distance(string1, string2):matrix = np.zeros((len(string1) + 1, len(string2) + 1))for i in range(len(string1) + 1):matrix[i][0] = ifor j in range(len(string2) + 1):matrix[0][j] = jfor i in range(1, len(string1) + 1):for j in range(1, len(string2) + 1):if string1[i - 1] == string2[j - 1]:d = 0else:d = 1matrix[i][j] = min(matrix[i - 1][j] + 1, matrix[i][j - 1] + 1, matrix[i - 1][j - 1] + d)return matrix[len(string1)][len(string2)]def editing_similarity(string1, string2):return 1 - editing_distance(string1, string2)/ max(len(string1), len(string2))#jaccard相似度
def jaccard_similarity(string1, string2):words1 = set(string1)words2 = set(string2)s = len(words1 & words2) / len(words1 | words2)return s
<QA_system.py>
import os
import json
import jieba
import numpy as np
from bm25 import BM25
from similarity_function import editing_similarity, jaccard_similarity
from gensim.models import Word2Vec
'''
基于faq知识库和文本匹配算法进行意图识别,完成单轮问答
'''
class QASystem:def __init__(self, know_base_path, algo):''':param know_base_path: 知识库文件路径:param algo: 选择不同的算法'''self.load_know_base(know_base_path)self.algo = algoif algo == "bm25":self.load_bm25()elif algo == "word2vec":self.load_word2vec()else:#其余的算法不需要做事先计算passdef load_bm25(self):self.corpus = {}for target, questions in self.target_to_questions.items():self.corpus[target] = []for question in questions:self.corpus[target] += jieba.lcut(question)self.bm25_model = BM25(self.corpus)#词向量的训练def load_word2vec(self):#词向量的训练需要一定时间,如果之前训练过,我们就直接读取训练好的模型#注意如果数据集更换了,应当重新训练#当然,也可以收集一份大量的通用的语料,训练一个通用词向量模型。一般少量数据来训练效果不会太理想if os.path.isfile("model.w2v"):self.w2v_model = Word2Vec.load("model.w2v")else:#训练语料的准备,把所有问题分词后连在一起corpus = []for questions in self.target_to_questions.values():for question in questions:corpus.append(jieba.lcut(question))#调用第三方库训练模型self.w2v_model = Word2Vec(corpus, vector_size=100, min_count=1)#保存模型self.w2v_model.save("model.w2v")#借助词向量模型,将知识库中的问题向量化self.target_to_vectors = {}for target, questions in self.target_to_questions.items():vectors = []for question in questions:vectors.append(self.sentence_to_vec(question))self.target_to_vectors[target] = np.array(vectors)# 将文本向量化def sentence_to_vec(self, sentence):vector = np.zeros(self.w2v_model.vector_size)words = jieba.lcut(sentence)# 所有词的向量相加求平均,作为句子向量count = 0for word in words:if word in self.w2v_model.wv:count += 1vector += self.w2v_model.wv[word]vector = np.array(vector) / count#文本向量做l2归一化,方便计算cos距离vector = vector / np.sqrt(np.sum(np.square(vector)))return vectordef load_know_base(self, know_base_path):self.target_to_questions = {}with open(know_base_path, encoding="utf8") as f:for index, line in enumerate(f):content = json.loads(line)questions = content["questions"]target = content["target"]self.target_to_questions[target] = questionsreturndef query(self, user_query):results = []if self.algo == "editing_similarity":for target, questions in self.target_to_questions.items():scores = [editing_similarity(question, user_query) for question in questions]score = max(scores)results.append([target, score])elif self.algo == "jaccard_similarity":for target, questions in self.target_to_questions.items():scores = [jaccard_similarity(question, user_query) for question in questions]score = max(scores)results.append([target, score])elif self.algo == "bm25":words = jieba.lcut(user_query)results = self.bm25_model.get_scores(words)elif self.algo == "word2vec":query_vector = self.sentence_to_vec(user_query)for target, vectors in self.target_to_vectors.items():cos = query_vector.dot(vectors.transpose())# print(cos)results.append([target, np.mean(cos)])else:assert "unknown algorithm!!"sort_results = sorted(results, key=lambda x:x[1], reverse=True)return sort_results[:3]if __name__ == '__main__':qas = QASystem("data/train.json", "word2vec")question = "话费是否包月超了"res = qas.query(question)print(question)print(res)## while True:# question = input("请输入问题:")# res = qas.query(question)# print("命中问题:", res)# print("-----------")