Google DeepMind发布MoR架构:50%参数超越传统Transformer,推理速度提升2倍
自2017年Vaswani等人发表"Attention Is All You Need"以来,Transformer架构已成为现代自然语言处理和人工智能系统的核心基础,为GPT、BERT、PaLM和Gemini等大型语言模型提供了强有力的技术支撑。然而,随着模型规模的不断扩大和任务复杂性的持续增长,传统Transformer架构面临着日益严峻的计算资源消耗和内存占用挑战。
这是7月Google DeepMind与韩国科学技术院(KAIST)和蒙特利尔学习算法研究所(Mila)联合提出了一项重要的架构创新——递归混合(Mixture of Recursions, MoR)。这一新型架构通过引入自适应令牌级计算机制,在显著降低参数数量和计算开销的同时,实现了超越标准Transformer的性能表现。
本文深入分析MoR架构的核心技术创新,详细阐述其在令牌级推理、内存管理和训练效率方面相对于传统Transformer架构的显著优势。
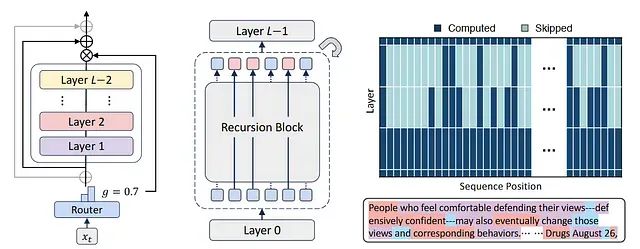
MoR架构核心原理
递归混合(MoR)架构本质上是一种递归Transformer设计,其核心创新在于引入了自适应令牌级计算机制。与传统Transformer在所有层中均匀处理所有令牌的固定计算模式不同,MoR能够根据每个令牌的复杂程度动态调整处理深度,对于语义相对简单的令牌实现早期退出机制,而对复杂令牌进行更深层次的递归处理。
MoR架构的关键技术特征包括:递归块设计替代了传统的多层堆叠结构,通过少量共享层的递归应用实现深度计算;轻量级路由机制负责智能决策每个令牌的最优递归步数;令牌级自适应计算确保计算资源的精确分配,避免在简单令牌上的资源浪费;选择性缓存策略仅对仍需进一步处理的活跃令牌进行缓存,有效节省内存开销。
性能对比分析:MoR与传统Transformer
参数效率优化
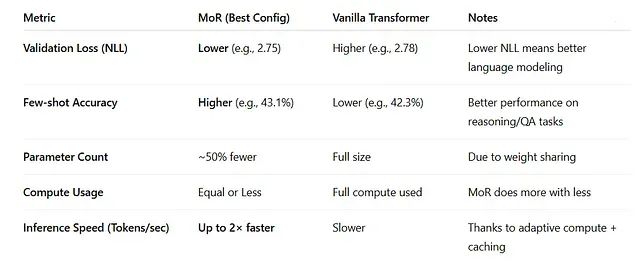
MoR架构通过递归机制实现了层间参数的高效复用。实验数据表明,118M参数的MoR模型能够超越315M参数的传统Transformer模型的性能表现。这种参数效率的提升意味着MoR能够以约50%的参数规模实现相当甚至更优的模型准确性,为大规模模型的部署提供了新的可能性。
自适应计算机制
传统Transformer架构采用固定计算模式,所有令牌必须顺序通过全部网络层进行处理。相比之下,MoR采用令牌特定的递归计算策略,简单令牌可以在较浅层实现早期退出,而复杂令牌则接受更深层次的递归处理。这种自适应机制使得MoR在训练阶段的计算开销降低多达50%。
推理性能提升
通过深度批处理技术和早期退出机制的协同作用,MoR实现了高达2倍的推理速度提升。这种性能改进主要源于对简单令牌计算资源浪费的有效避免,以及对复杂令牌的精准计算资源分配。
内存优化策略
MoR引入了递归级缓存和递归键值(KV)缓存机制,显著降低了模型的内存需求。在推理过程中,系统仅存储活跃令牌的键值对,在保持模型准确性的前提下大幅减少RAM使用量。
少样本学习能力
在标准自然语言处理基准测试中,包括ARC(AI2 Reasoning Challenge)和MMLU(Massive Multitask Language Understanding)等评估任务上,MoR展现出了优异的性能表现。118M参数的MoR模型在少样本学习任务中达到43.1%的准确率,超越了315M参数传统Transformer模型的42.3%准确率。在1.7B参数规模下,MoR模型在使用仅为传统模型三分之一参数量的情况下,仍能达到相当或更优的性能水平。
技术实现细节
递归架构设计
MoR摒弃了传统的N层独立网络结构,转而采用对相同共享块进行Nₐ次递归应用的设计范式。例如,3个共享层最多应用4次递归,其效果等价于12层深度网络模型,但参数复杂度显著降低。
路由策略机制
MoR实现了两种主要的路由策略:专家选择(Expert-choice)模式下,每个递归步骤主动选择需要进一步处理的令牌;令牌选择(Token-choice)模式下,令牌在处理初期预先确定所需的递归循环次数。实验结果显示,专家选择策略配合带辅助损失的线性路由器能够实现简单令牌与复杂令牌的精确分离,取得最优的性能表现。
智能缓存系统
MoR的缓存机制包含两个核心组件:递归级缓存仅为当前递归循环中的活跃令牌存储键值对;递归共享机制在所有后续递归过程中重用初始键值对,特别适合内存受限的部署环境。
架构局限性与优化方向
MoR架构在带来显著性能提升的同时,也存在一些技术挑战。训练复杂性方面,模型需要额外的路由模块支持,增加了系统的整体复杂度。在极小参数规模(如135M参数)下,MoR可能出现轻微的性能劣势。此外,令牌选择路由模式下的负载均衡问题相对复杂,尽管专家选择策略能够有效缓解这一问题。
这些技术挑战相对于MoR在计算效率和内存优化方面的显著优势而言,属于可接受的技术权衡。
结论与展望
递归混合架构代表了神经网络设计的重要范式转变,从传统的刚性、统一计算模式转向动态、令牌感知的智能计算策略。MoR不再强制所有令牌经过相同的网络层数处理,而是根据令牌的语义复杂度进行差异化计算。
这种架构创新带来了多重技术优势:潜在推理能力的增强使模型能够进行更深层次的语义理解;动态计算分配机制确保了资源的最优利用;内置的内存效率优化为大规模模型部署提供了可行方案;推理速度的显著提升满足了实际应用场景的性能需求。
MoR架构的提出为未来大型语言模型的发展指明了新的技术方向,其在效率和性能之间实现的平衡具有重要的理论价值和实践意义。
论文:https://avoid.overfit.cn/post/1703bc65882e4336ae3f5206daa61cfc