mybatis拦截器实现唯一索引的动态配置
在我们日常的开发中,我们经常会遇到这种问题。有一张表,这张表中有一些字段在表中是唯一存在的,比如:我们的邮箱字段email、手机号字段phone又或者要求名称name不能够重复等等,这些字段要求在数据表中是唯一存在的。我们想到的方法是在数据表创建时给这些唯一性约束的条件加上唯一性索引。如:
ALTER TABLE users
ADD CONSTRAINT unique_email UNIQUE (email);这段语句就说明我们在给users表的email字段加上了唯一性索引,并且指定这个索引的名称为unique_email。
但是这样是很不友好的,我们出错之后是由数据库给我们兜底的,并且返回的错误信息很不友好。如:
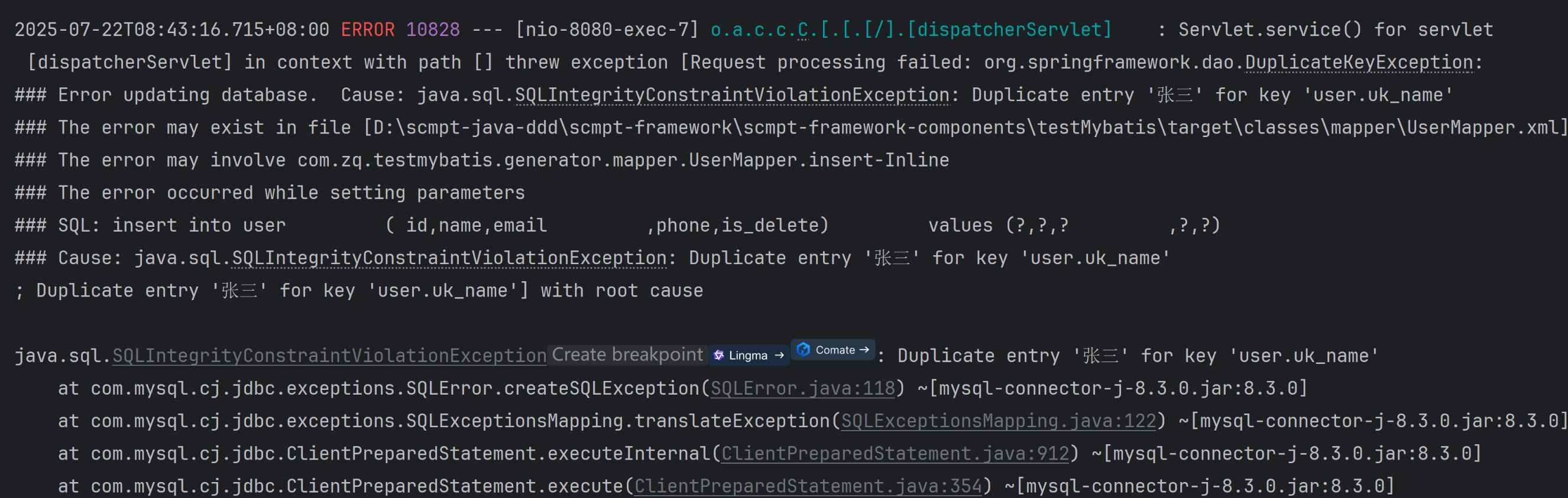
这段报错信息说明我们在插入数据库时,name名称字段违反了唯一性索引的约束,所以报错。当然,我们也能想到一些方法来进行修复,比如我创建一个全局的异常通知类,然后再这个类中统一拦截我们的异常并进行处理
@ExceptionHandler(DuplicateKeyException.class)public Result<Object> error(DuplicateKeyException e) {String message = Objects.requireNonNull(e.getRootCause()).getMessage(); // 获取底层 SQL 异常信息if (message != null && message.contains("Duplicate entry")) {// 例如:Duplicate entry '张三' for key 'user.uk_name'// 你可以用正则提取索引名Pattern pattern = Pattern.compile("for key '(.+?)'");Matcher matcher = pattern.matcher(message);if (matcher.find()) {String indexName = matcher.group(1);log.error("捕获到数据库唯一键冲突异常:{}", indexName);return Result.error(501,"唯一索引冲突:" + indexName);}}return Result.error(501, "该记录已存在,请勿重复操作");}现在,我们抛出异常的提示信息比之前清晰了一点。如:
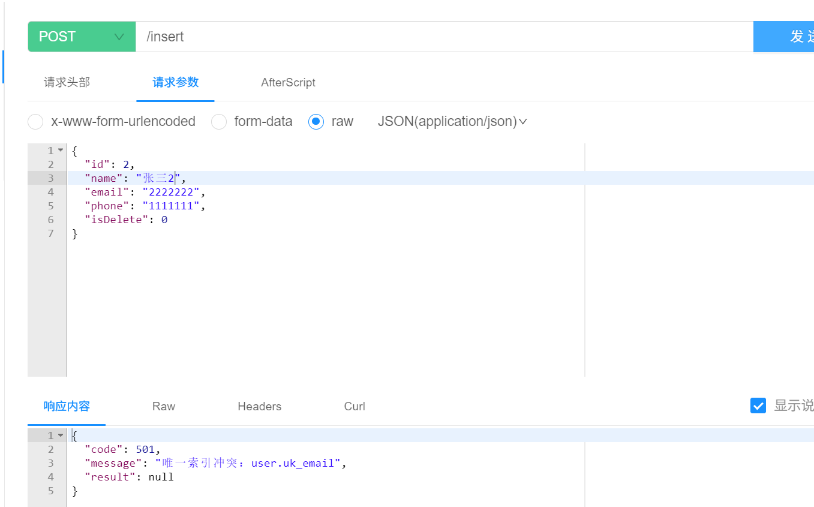
但是,这任然不是我们想要的结果,这样我们一次请求中只能知道一次唯一性索引的报错,如果有多个唯一性约束字段我们可能要等多次才能得到最终结果。并且,返回的报错信息也是我们唯一索引的约束名称。
说到底,我们不应该把数据库的兜底直接作为我们处理唯一性约束的方法。我们应该在插入或修改之前就直接判断出哪些字段违反了唯一性索引的约束。
这种也很好解决,我们在插入或修改之前先进行一次查询。看看要操作的参数有没有违反唯一性索引的约束。
如:对名称name这个字段做唯一性查询;
@PostMapping("/insert")public String insert(@RequestBody User user) {Integer count=userMapper.getExistsByName(user.getName(),null);if(count>0){throw new ResultException(501,"用户名已存在,请重新输入");}userMapper.insert(user);return "success";}@PostMapping("/updateById")public String updateById(@RequestBody User user) {Integer count=userMapper.getExistsByName(user.getName(),user.getId());if(count>0){throw new ResultException(501,"用户名已存在,请重新输入");}userMapper.updateByPrimaryKey(user);return "success";}在新增或者修改之前直接根据对应的字段来进行查询。
相应的mapper接口如下:
<select id="getExistsByName" resultType="java.lang.Integer">select count(*) from user whereis_delete=0 andname=#{name}<if test="id != null">and id=#{id}</if></select>现在,我们对于单个字段的唯一性索引也已经能够实现了。但是,这也只是对于单个字段的约束查询,如果,是多个字段呢?并且这多个唯一性约束的字段是可变的呢。我们可以想到的是,我们还是使用这种先查询在新增/修改的方法,只不过是我们要做的通用化。
我们可以先自定义两个注解,用来收集需要加唯一性约束的字段。
如下:
收集单个唯一性字段
@Repeatable(UniqueFields.class)
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface UniqueField {/*** Java实体属性名(必须)*/String property();/*** 数据库列名(可选)* - 为空时自动将属性名转换为下划线格式*/String column() default "";/*** 字段中文名称(用于错误消息)*/String name();}
收集一组唯一性字段
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface UniqueFields {UniqueField[] value();
}
我们收集了这些字段之后,可以进行一些处理了。我们最后还是要操作数据库表的,只不过我们把这些需要处理的唯一性字段都收集起来方便统一处理,在XML的SQL语句中,我们会使用foreach循环查询并且使用到了动态SQL的拼接。
定义一个工具类来实现我们收集到的唯一性索引的数据过滤
@Slf4j
@Component
public class UniqueValidator {/*** 字段配置信息*/private static class FieldConfig {final String propertyName; // Java属性名final String columnName; // 数据库列名final String chineseName; // 中文名称FieldConfig(String propertyName, String columnName, String chineseName) {this.propertyName = propertyName;// 智能列名处理:如果未指定列名,则自动转换驼峰为下划线if (StringUtils.hasText(columnName)) {this.columnName = columnName;} else {this.columnName = camelToSnake(propertyName);}this.chineseName = chineseName;}/*** 驼峰命名转下划线命名*/private String camelToSnake(String camelCase) {if (camelCase == null || camelCase.isEmpty()) {return camelCase;}StringBuilder result = new StringBuilder();char[] chars = camelCase.toCharArray();for (int i = 0; i < chars.length; i++) {char c = chars[i];if (Character.isUpperCase(c)) {// 在第一个字符前不加下划线if (i > 0) {result.append('_');}result.append(Character.toLowerCase(c));} else {result.append(c);}}return result.toString();}}/*** 执行唯一性校验并抛出字段异常** @param entity 需要校验的唯一性对象* @param excludeId 需要排除的唯一性ID。新增时设为null,更新时设为当前ID* @param checker 用于校验唯一性的函数,该函数接收一个属性-值映射和一个排除的唯一性ID,返回一个包含重复列名的列表* @throws DuplicateFieldException 如果存在重复的唯一性列,则抛出此异常,异常信息包含重复列名及其对应的字段配置信息*/public void validateAndThrowWithChinese(Object entity, Long excludeId,BiFunction<Map<String, Object>, Long, List<String>> checker) {// 1. 获取字段配置List<FieldConfig> fieldConfigs = getUniqueFieldConfigs(entity.getClass());if (fieldConfigs.isEmpty()) return;// 2. 收集Java属性值Map<String, Object> propertyValueMap = collectPropertyValues(entity, fieldConfigs);if (propertyValueMap.isEmpty()) return;// 3. 转换为数据库列名映射Map<String, Object> columnValueMap = convertToColumnMap(propertyValueMap, fieldConfigs);log.info("需要校验的数据: {}", columnValueMap);log.info("需要校验的ID: {}", excludeId);// 4. 执行校验List<String> duplicatedColumns = checker.apply(columnValueMap, excludeId);log.info("需要校验的 {}", duplicatedColumns);// 5. 处理校验结果if (!duplicatedColumns.isEmpty()) {throw new ResultException(501,generateErrorMessage(duplicatedColumns, fieldConfigs));}}/*** 获取唯一字段配置*/private List<FieldConfig> getUniqueFieldConfigs(Class<?> entityClass) {List<FieldConfig> configs = new ArrayList<>();// 检查容器注解UniqueFields container = entityClass.getAnnotation(UniqueFields.class);if (container != null) {for (UniqueField field : container.value()) {configs.add(new FieldConfig(field.property(), field.column(), field.name()));}}// 检查直接标注的注解UniqueField[] fields = entityClass.getAnnotationsByType(UniqueField.class);for (UniqueField field : fields) {configs.add(new FieldConfig(field.property(), field.column(), field.name()));}return configs;}/*** 收集Java属性值*/private Map<String, Object> collectPropertyValues(Object entity, List<FieldConfig> configs) {Map<String, Object> valueMap = new HashMap<>();BeanWrapper wrapper = new BeanWrapperImpl(entity);for (FieldConfig config : configs) {try {Object value = wrapper.getPropertyValue(config.propertyName);if (value != null) {valueMap.put(config.propertyName, value);}} catch (Exception e) {// 忽略无效属性}}return valueMap;}/*** 转换为列名映射*/private Map<String, Object> convertToColumnMap(Map<String, Object> propertyMap,List<FieldConfig> configs) {Map<String, Object> columnMap = new HashMap<>();for (FieldConfig config : configs) {if (propertyMap.containsKey(config.propertyName)) {columnMap.put(config.columnName, propertyMap.get(config.propertyName));}}return columnMap;}/*** 生成错误消息*/private String generateErrorMessage(List<String> duplicatedColumns,List<FieldConfig> configs) {// 创建列名到中文名的映射Map<String, String> columnToChinese = new HashMap<>();for (FieldConfig config : configs) {columnToChinese.put(config.columnName, config.chineseName);}// 转换为中文名列表List<String> chineseNames = duplicatedColumns.stream().map(column -> columnToChinese.getOrDefault(column, column)).collect(Collectors.toList());return String.format("%s 已经存在,请重新输入",String.join("、", chineseNames));}
}这是我们自定义的工具类,那么,接下来我们还需要写xml文件中的SQL语句。
List<String> findDuplicatedFields(@Param("columnMap") Map<String, Object> columnMap,@Param("excludeId") Long excludeId);对应的XML语句为:
<select id="findDuplicatedFields" resultType="string"><choose><when test="columnMap != null and !columnMap.isEmpty()"><trim suffixOverrides="UNION ALL"><foreach collection="columnMap" index="column" item="value"><if test="value != null">SELECT '${column}' AS duplicated_fieldWHERE EXISTS (SELECT 1FROM userWHERE is_delete = 0AND ${column} = #{value}<if test="excludeId != null">AND id != #{excludeId}</if>)UNION ALL</if></foreach></trim></when><otherwise>SELECT NULL AS duplicated_field WHERE FALSE</otherwise></choose></select>至此,我们就实行了一次处理多组唯一性索引的操作。相应的使用如下:
在数据实体类中指定需要做唯一性校验的字段,并手动指定报错的信息;
@Data
@UniqueFields(value = {@UniqueField(name = "邮箱", property = "email"),@UniqueField(name = "手机号", property = "phone"),@UniqueField(name = "名称", property = "name")
})
public class User {/*** 主键 ID*/private Integer id;/*** 用户昵称*/private String name;/*** 邮箱*/private String email;/*** 手机号*/private String phone;/*** 逻辑删除 0-正常 1-已删除*/private Integer isDelete;
}在新增/修改前手动校验一下唯一性索引;
@PostMapping("/insert")public String insert(@RequestBody User user) {
uniqueValidator.validateAndThrowWithChinese(user,null,userMapper::findDuplicatedFields);userMapper.insert(user);return "success";}@PostMapping("/updateById")public String updateById(@RequestBody User user) {uniqueValidator.validateAndThrowWithChinese(user, Long.valueOf(user.getId()),userMapper::findDuplicatedFields);userMapper.updateByPrimaryKey(user);return "success";}需要注意的是,修改比新增多了一个本身的id。因为它要排除本身的数据。
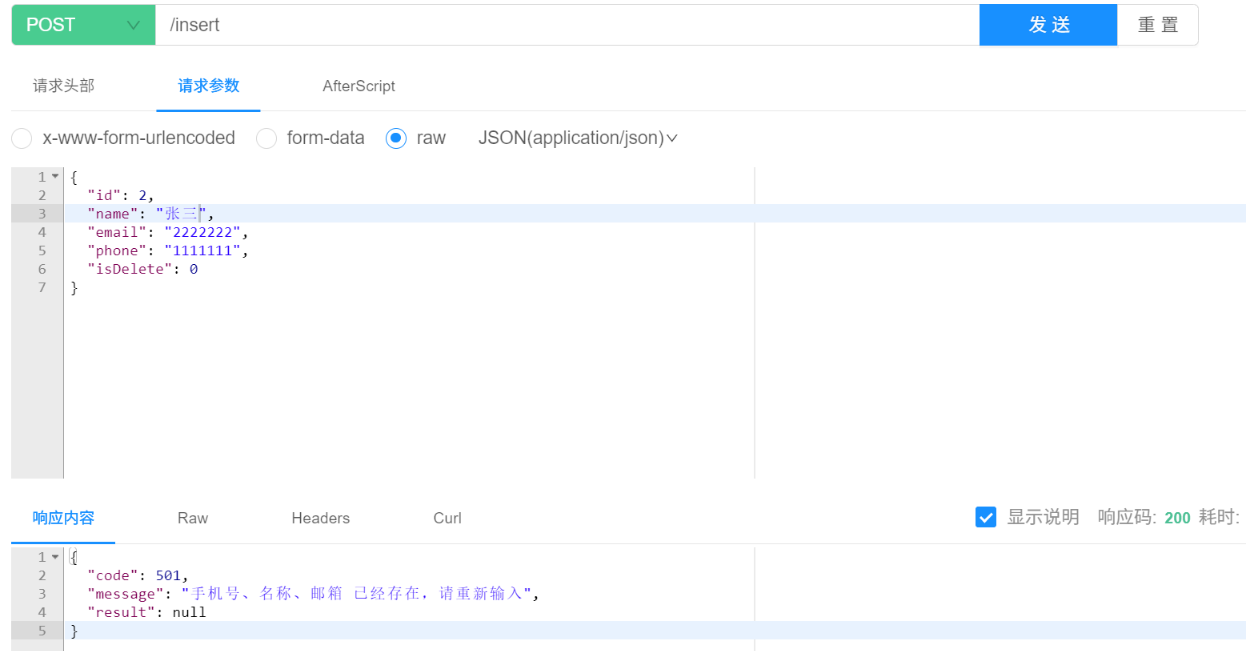
这是我们运行的结果:
我们可以看一下输出的查询语句:
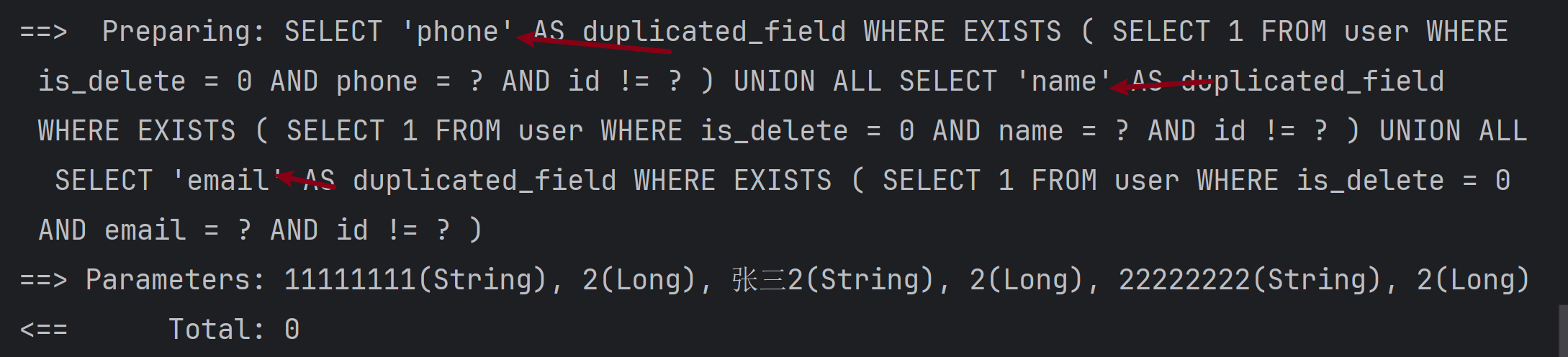
可以看到,我们在数据实体中指定的唯一索引字段都进行了查询。
以上这种方法当然可以实现我们的要求。但是我们还能进行一些优化。
我们发现这些相应的SQL语句是可以复用的,唯一不同的可能就是数据库的表明不同。那么,我们可以使用mybatis的拦截器在做一层封装,使得我们不需要写SQL语句,完全通过一个注解来控制相应的唯一性索引校验。
自定义控制注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface UniqueValidation {/*** 数据库表名(必填)*/String table();/*** 主键列名(默认为"id")*/String idColumn() default "id";/*** 逻辑删除列名(默认为"is_delete")*/String deleteFlagColumn() default "is_delete";/*** 逻辑删除标识值(默认为0)*/int deleteFlagValue() default 0;
}定义mybatis拦截器的实现:
@Setter
@Intercepts({@Signature(type = Executor.class,method = "update",args = {MappedStatement.class, Object.class})
})
@Slf4j
@Component
public class UniqueValidationInterceptor implements Interceptor {// 缓存类字段配置信息private static final Map<Class<?>, List<FieldConfig>> CONFIG_CACHE = new ConcurrentHashMap<>();// 字段配置类(与原始工具类保持一致)private record FieldConfig(String propertyName, String columnName, String chineseName) {private FieldConfig(String propertyName, String columnName, String chineseName) {this.propertyName = propertyName;this.columnName = StringUtils.hasText(columnName) ?columnName : camelToSnake(propertyName);this.chineseName = chineseName;}private String camelToSnake(String str) {return str.replaceAll("([a-z])([A-Z])", "$1_$2").toLowerCase();}}@Overridepublic Object intercept(Invocation invocation) throws Throwable {Object[] args = invocation.getArgs();MappedStatement ms = (MappedStatement) args[0];Object parameter = args[1];// 获取Mapper方法Method mapperMethod = getMapperMethod(ms);if (mapperMethod == null) return invocation.proceed();// 获取唯一性校验注解,如果不存在则返回执行结果UniqueValidation annotation = AnnotationUtils.findAnnotation(mapperMethod, UniqueValidation.class);if (annotation == null) return invocation.proceed();Executor executor = (Executor) invocation.getTarget();// 获取实体对象(支持Map和实体两种参数类型)Object entity = getEntityFromParameter(parameter, mapperMethod);if (entity == null) return invocation.proceed();// 执行唯一性校验validateUniqueness(entity, annotation, executor,ms);return invocation.proceed();}private void validateUniqueness(Object entity, UniqueValidation annotation,Executor executor,MappedStatement ms) {Class<?> entityClass = entity.getClass();// 获取字段配置List<FieldConfig> fieldConfigs = CONFIG_CACHE.computeIfAbsent(entityClass, this::getUniqueFieldConfigs);if (fieldConfigs.isEmpty()) return;// 收集属性值Map<String, Object> propertyValueMap = collectPropertyValues(entity, fieldConfigs);if (propertyValueMap.isEmpty()) return;// 转换为列名映射Map<String, Object> columnValueMap = convertToColumnMap(propertyValueMap, fieldConfigs);// 获取排除ID(更新操作时需要)Object excludeId = getExcludeId(entity, annotation.idColumn(),ms.getSqlCommandType());// 执行SQL校验List<String> duplicatedColumns = executeValidationSQL(annotation.table(),annotation.deleteFlagColumn(),annotation.deleteFlagValue(),columnValueMap,excludeId,executor);// 处理校验结果if ( duplicatedColumns!=null &&!duplicatedColumns.isEmpty()) {throw new ResultException(501,generateErrorMessage(duplicatedColumns, fieldConfigs));}}private List<String> executeValidationSQL(String tableName,String deleteFlagColumn,int deleteFlagValue,Map<String, Object> columnValueMap,Object excludeId,Executor executor) {StringBuilder sqlBuilder = new StringBuilder();List<Object> params = new ArrayList<>();// 构建动态SQLfor (Map.Entry<String, Object> entry : columnValueMap.entrySet()) {String column = entry.getKey();Object value = entry.getValue();if (value == null) continue;sqlBuilder.append("SELECT '").append(column).append("' AS duplicated_field ").append("WHERE EXISTS (").append("SELECT 1 FROM ").append(tableName).append(" WHERE ").append(deleteFlagColumn).append(" = ? ").append(" AND ").append(column).append(" = ? ");params.add(deleteFlagValue);params.add(value);if (excludeId != null) {sqlBuilder.append(" AND ").append("id").append(" != ? ");params.add(excludeId);}sqlBuilder.append(") UNION ALL ");}// 最终SQLString sql;if (!sqlBuilder.isEmpty()) {sql = sqlBuilder.substring(0, sqlBuilder.length() - "UNION ALL ".length());} else {sql = "SELECT NULL AS duplicated_field WHERE FALSE";}// 实际执行SQLreturn executeSQL(sql, params,executor);}private List<String> executeSQL(String sql, List<Object> params,Executor executor) {// 实际实现应使用SqlRunner或MyBatis的SQL执行能力// 这里简化实现,实际项目中需完整实现try {Transaction transaction = executor.getTransaction();Connection conn = transaction.getConnection();SqlRunner sqlRunner = new SqlRunner(conn);log.debug("sql执行参数----->: {}", params);log.debug("Sql执行语句---->: {}", sql);// 执行查询List<Map<String, Object>> results = sqlRunner.selectAll(sql, params.toArray());if(results == null || results.isEmpty()){return new ArrayList<>();}for (Map<String, Object> result : results) {log.debug("sql执行结果---->: {}", result.get("DUPLICATED_FIELD"));}// 提取结果return results.stream().map(map -> (String) map.get("DUPLICATED_FIELD")).filter(Objects::nonNull).collect(Collectors.toList());} catch (SQLException e) {throw new RuntimeException(e);}}/*** 获取唯一字段配置*/private List<FieldConfig> getUniqueFieldConfigs(Class<?> entityClass) {List<FieldConfig> configs = new ArrayList<>();// 检查容器注解UniqueFields container = entityClass.getAnnotation(UniqueFields.class);if (container != null) {for (UniqueField field : container.value()) {configs.add(new FieldConfig(field.property(), field.column(), field.name()));}}// 检查直接标注的注解UniqueField[] fields = entityClass.getAnnotationsByType(UniqueField.class);for (UniqueField field : fields) {configs.add(new FieldConfig(field.property(), field.column(), field.name()));}return configs;}/*** 收集Java属性值*/private Map<String, Object> collectPropertyValues(Object entity, List<FieldConfig> configs) {Map<String, Object> valueMap = new HashMap<>();BeanWrapper wrapper = new BeanWrapperImpl(entity);for (FieldConfig config : configs) {try {Object value = wrapper.getPropertyValue(config.propertyName);if (value != null) {valueMap.put(config.propertyName, value);}} catch (Exception e) {// 忽略无效属性}}return valueMap;}/*** 转换为列名映射*/private Map<String, Object> convertToColumnMap(Map<String, Object> propertyMap,List<FieldConfig> configs) {Map<String, Object> columnMap = new HashMap<>();for (FieldConfig config : configs) {if (propertyMap.containsKey(config.propertyName)) {columnMap.put(config.columnName, propertyMap.get(config.propertyName));}}return columnMap;}/*** 生成错误消息*/private String generateErrorMessage(List<String> duplicatedColumns,List<FieldConfig> configs) {// 创建列名到中文名的映射Map<String, String> columnToChinese = new HashMap<>();for (FieldConfig config : configs) {columnToChinese.put(config.columnName, config.chineseName);}// 转换为中文名列表List<String> chineseNames = duplicatedColumns.stream().map(column -> columnToChinese.getOrDefault(column, column)).collect(Collectors.toList());return String.format("%s 已经存在,请重新输入",String.join("、", chineseNames));}// 辅助方法private Method getMapperMethod(MappedStatement ms) {try {String mapperClassName = ms.getId().substring(0, ms.getId().lastIndexOf('.'));String methodName = ms.getId().substring(ms.getId().lastIndexOf('.') + 1);Class<?> mapperClass = Class.forName(mapperClassName);return Arrays.stream(mapperClass.getMethods()).filter(m -> m.getName().equals(methodName)).findFirst().orElse(null);} catch (Exception e) {return null;}}private Object getEntityFromParameter(Object parameter, Method method) {// 支持两种参数类型:// 1. 直接传递实体对象// 2. 通过@Param注解标记的Map参数(键为"et"或"entity")if (parameter instanceof Map<?, ?> paramMap) {return paramMap.getOrDefault("et",null) != null? paramMap.get("et") :paramMap.getOrDefault("entity", null);}return parameter;}private Object getExcludeId(Object entity, String idColumn, SqlCommandType commandType) {// 只有更新操作才需要排除自身IDif (commandType != SqlCommandType.UPDATE) {return null;}try {if (entity instanceof Map) {return ((Map<?, ?>) entity).get(idColumn);}BeanWrapper wrapper = new BeanWrapperImpl(entity);PropertyDescriptor pd = wrapper.getPropertyDescriptor(idColumn);if (pd.getReadMethod() != null) {return pd.getReadMethod().invoke(entity);}return null;} catch (Exception e) {log.warn("获取排除ID失败: {}", e.getMessage());return null;}}@Overridepublic Object plugin(Object target) {return Plugin.wrap(target, this);}@Overridepublic void setProperties(Properties properties) {}
}我们要拦截所有的新增/修改/删除操作。并且判断这些操作的方法上面有没有加上相应的启动注解,如果有加上我们就在之前拦截操作,并且执行一次查询操作。
使用:
我们现在使用起来就很简单了。我们只需要在相应的mapper接口上加上我们的注解,并且指定数据表明就可以了。说白了就是把原来在XML文件中的动态SQL语句,我们现在把它提出来了,在Java代码中进行拼接实行;
@PostMapping("/insert")public String insert(@RequestBody User user) {userMapper.insert(user);return "success";}@PostMapping("/updateById")public String updateById(@RequestBody User user) {userMapper.updateByPrimaryKey(user);return "success";}直接写新增/修改语句。在底层mapper接口上加上注解。
@UniqueValidation(table = "user")int insert(User record);@UniqueValidation(table = "user")int updateByPrimaryKey(User record);现在,再次启动我们的项目:
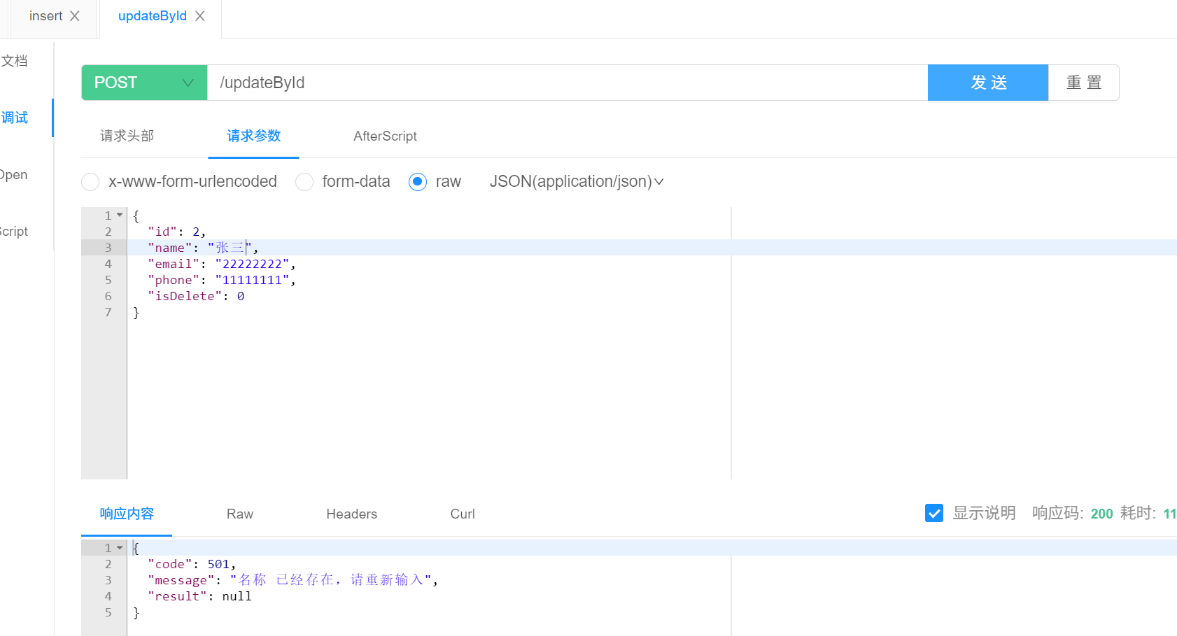
可以发现和之前手动写校验方法时完全一致,至此。我们就实现了一个通用的唯一性校验逻辑了,
我们只需要在数据实体类中加上相应的注解指定校验的字段编码和名称,并在mapper方法上使用注解指定数据表明,就可以实现数据在新增/修改时的统一校验逻辑了。