[自用】JavaSE--集合框架(二)--Map集合体系
概述
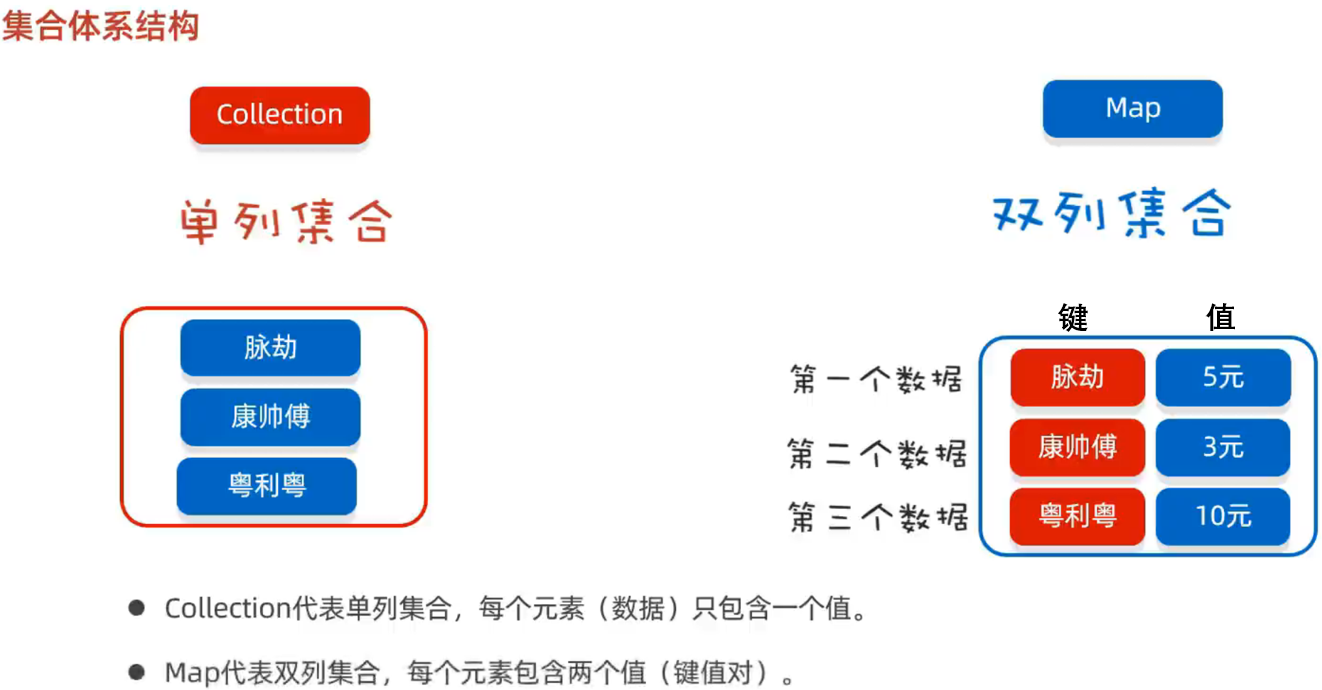

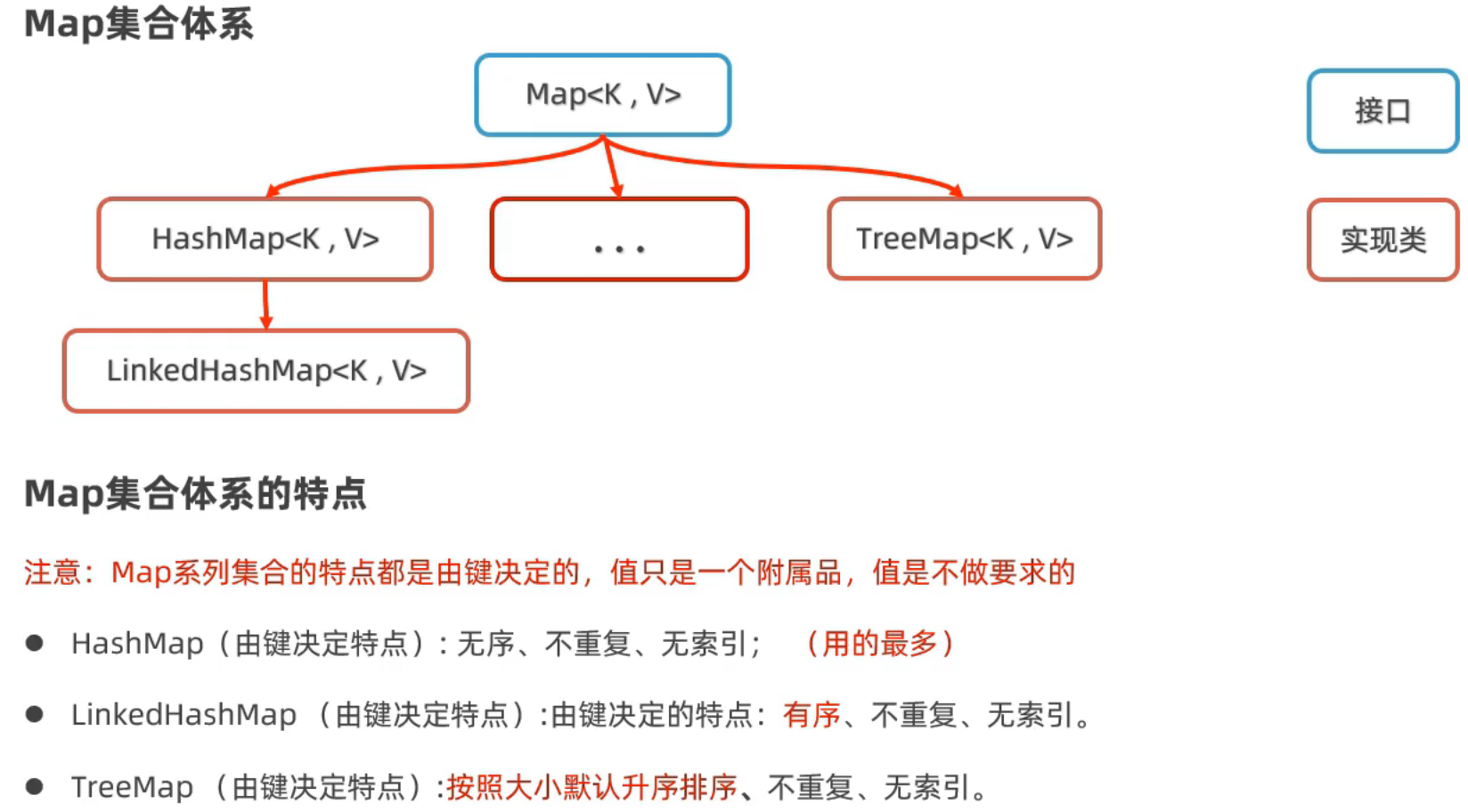
Map集合体系
HashMap:
LinkedHashMap:
就是在HashMap的基础上变得有序,代码同上,顺序会变成下图
![]()
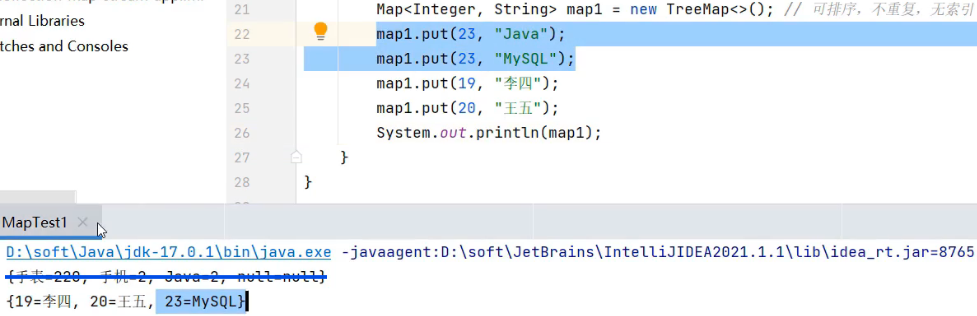
TreeMap:
可排序,默认升序,其他规则和HashMap一样,无索引、不重复,后面的出现的数据会覆盖前面出现的数据
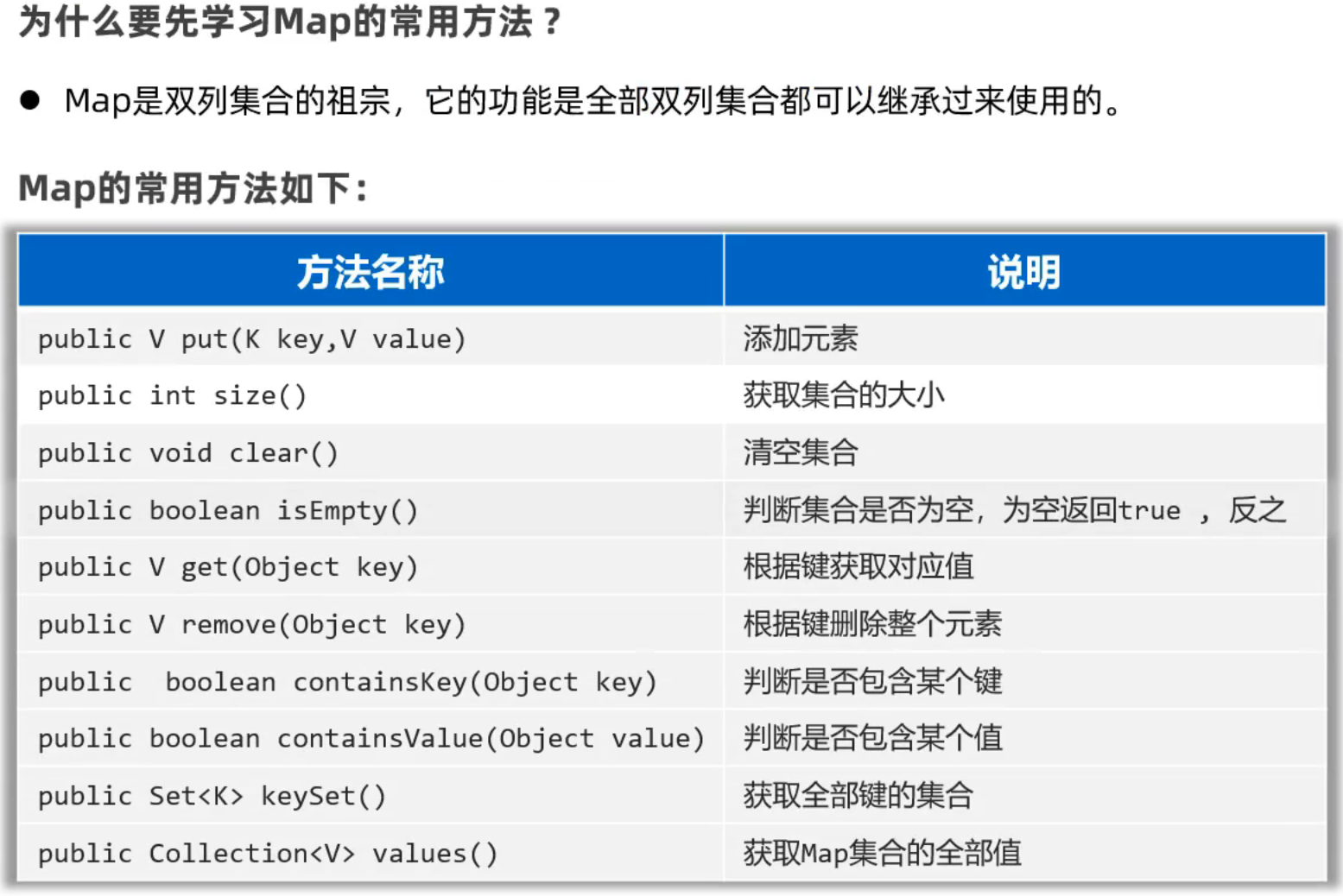
Map常用方法
同List集合,方法基本都是公共的
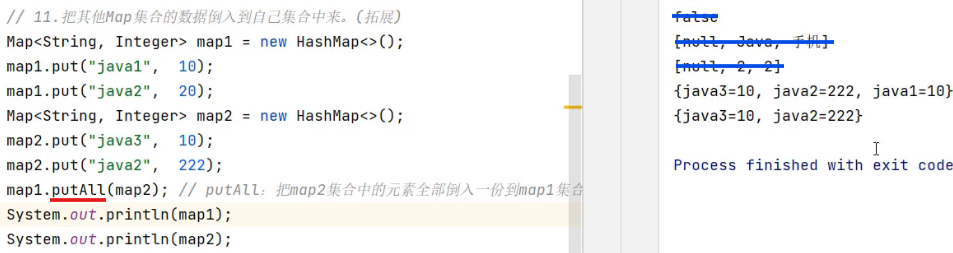
补充方法:putAll
如下图,可以将map2复制一份到map1中,且满足不重复的原则,map2中复制进去的相当于后来的数据,会覆盖原来在map1中相同的键(java2被覆盖)
Map遍历方式
第一种:键找值
将所以键放到一个set集合里,然后通过循环遍历set集合中的键找对应map的值

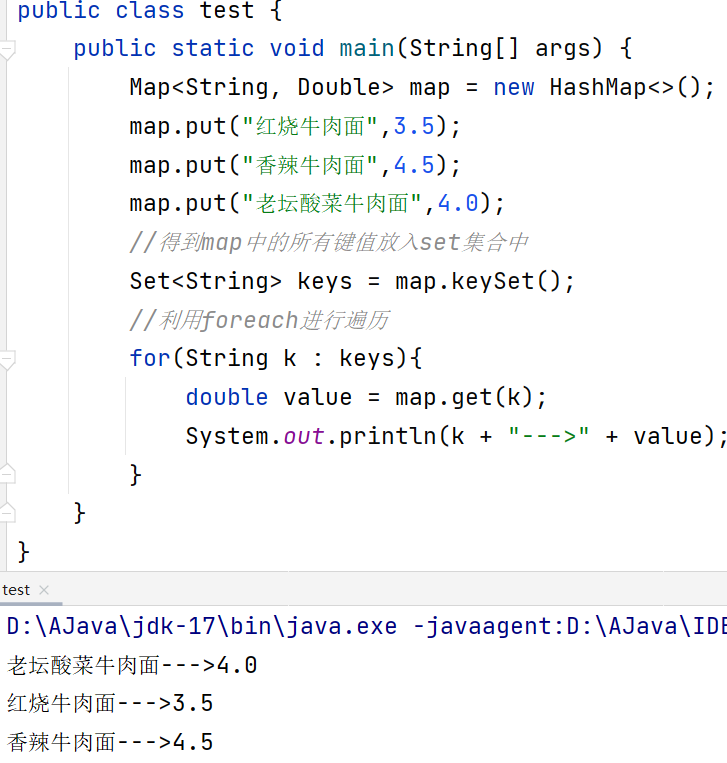
第二种:遍历键值对
与第一种思路接近,将键值对装进set集中中,再使用增强for循环进行遍历。
但是增强for循环的写法是 for( 类型 变量 : 集合) { }; 其中的类型难以确定,因为键值对有可能两个元素类型不一样,比如<String , Double>
因此需要通过 map.enterySet( ) 方法获取所有键值对封装成对象装入set集中去,写法: Set< Map.Entery<类型1, 类型2> > entries = map.entery( );
相当于键值对的类型就是 Map.Entery<类型1, 类型2> ,装入到entries集合中去,之后遍历entries即可
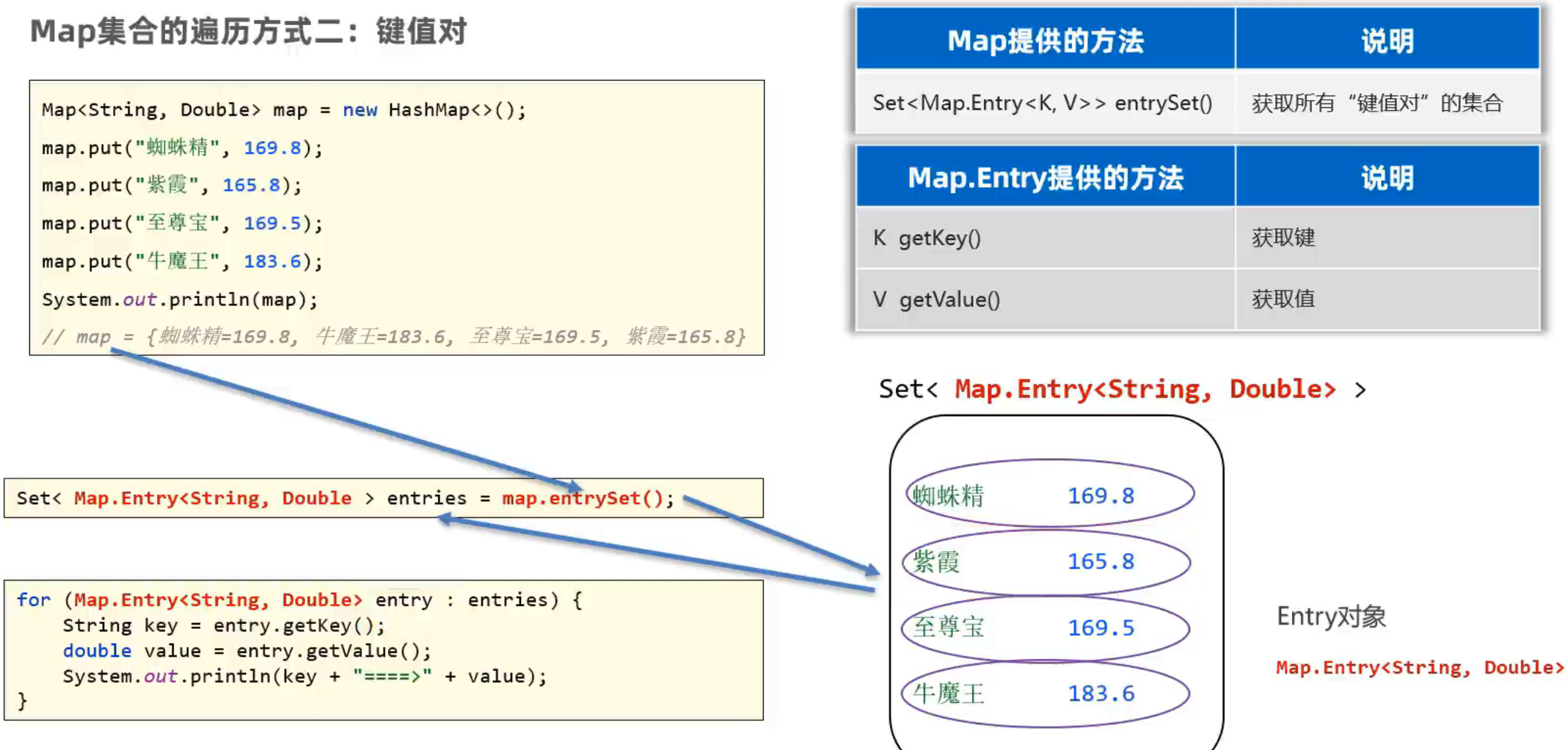
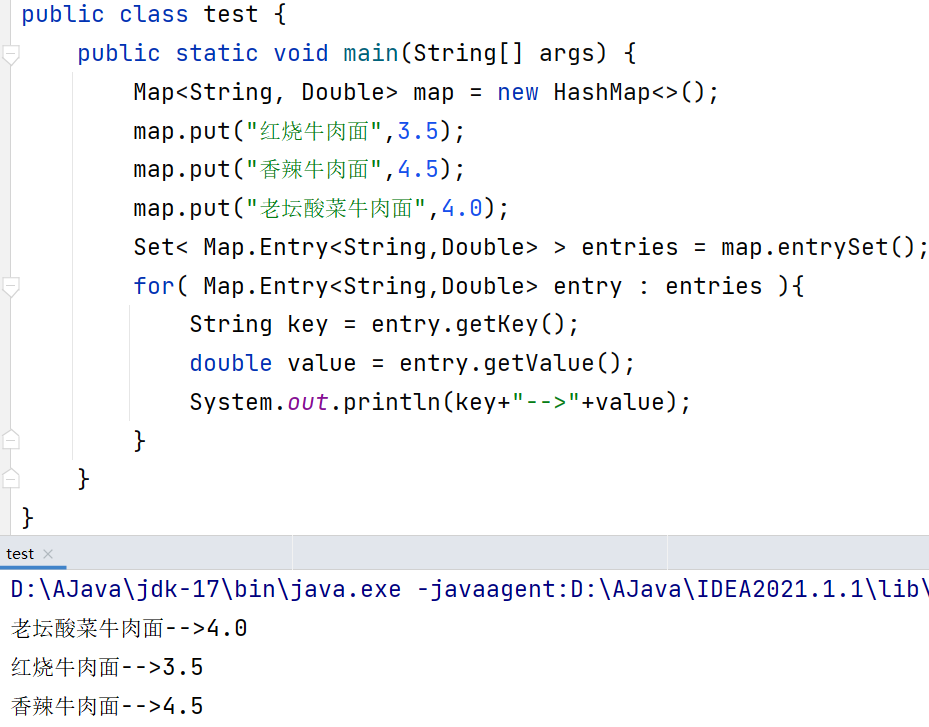
示例:
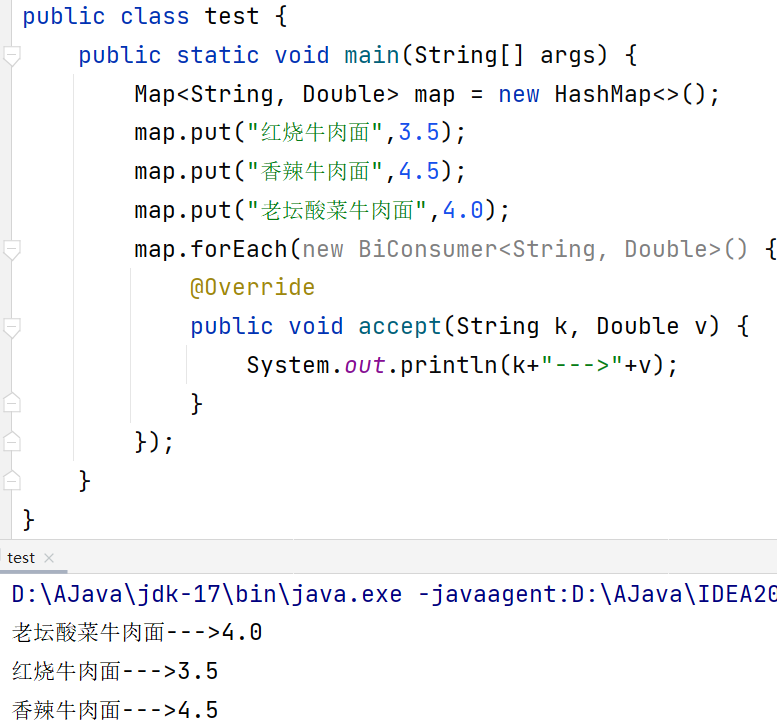
第三种:Lambda表达式
jdk1.8开始可以使用的,这个方法有点赖了,巨简洁,如下图
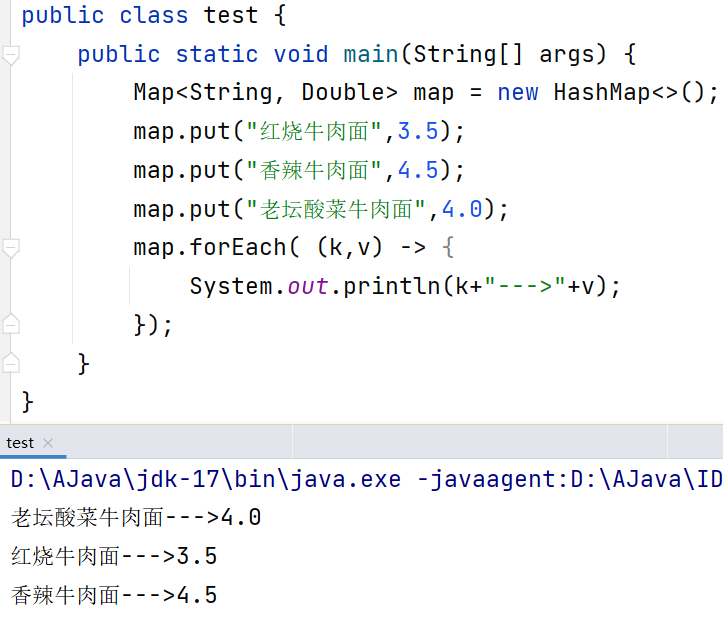 更有甚者-->
更有甚者-->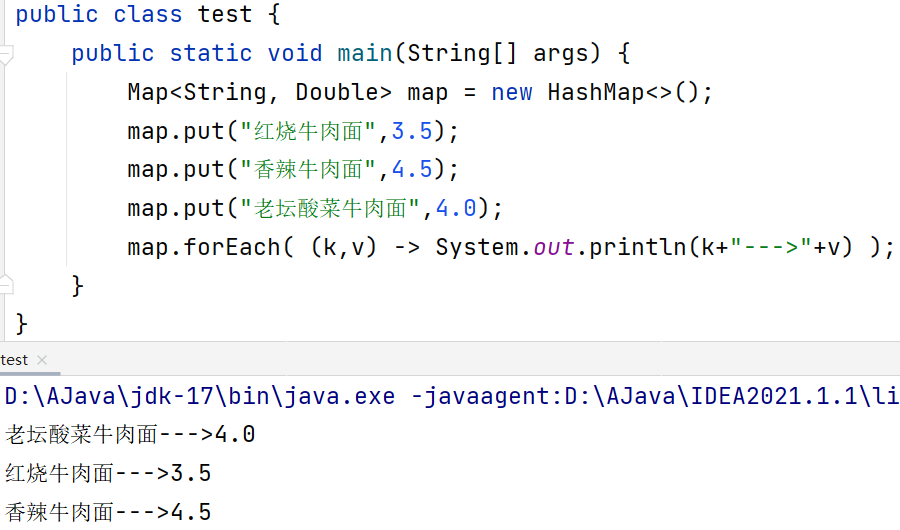
原版代码其实如下图,然后采用了lambda表达式对匿名内部类进行简化
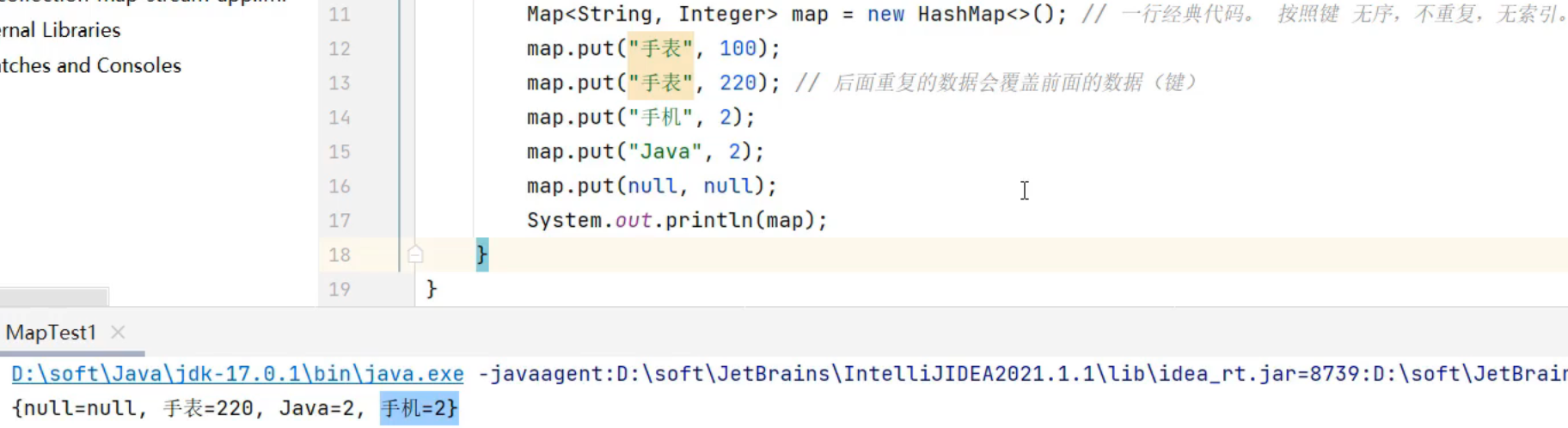
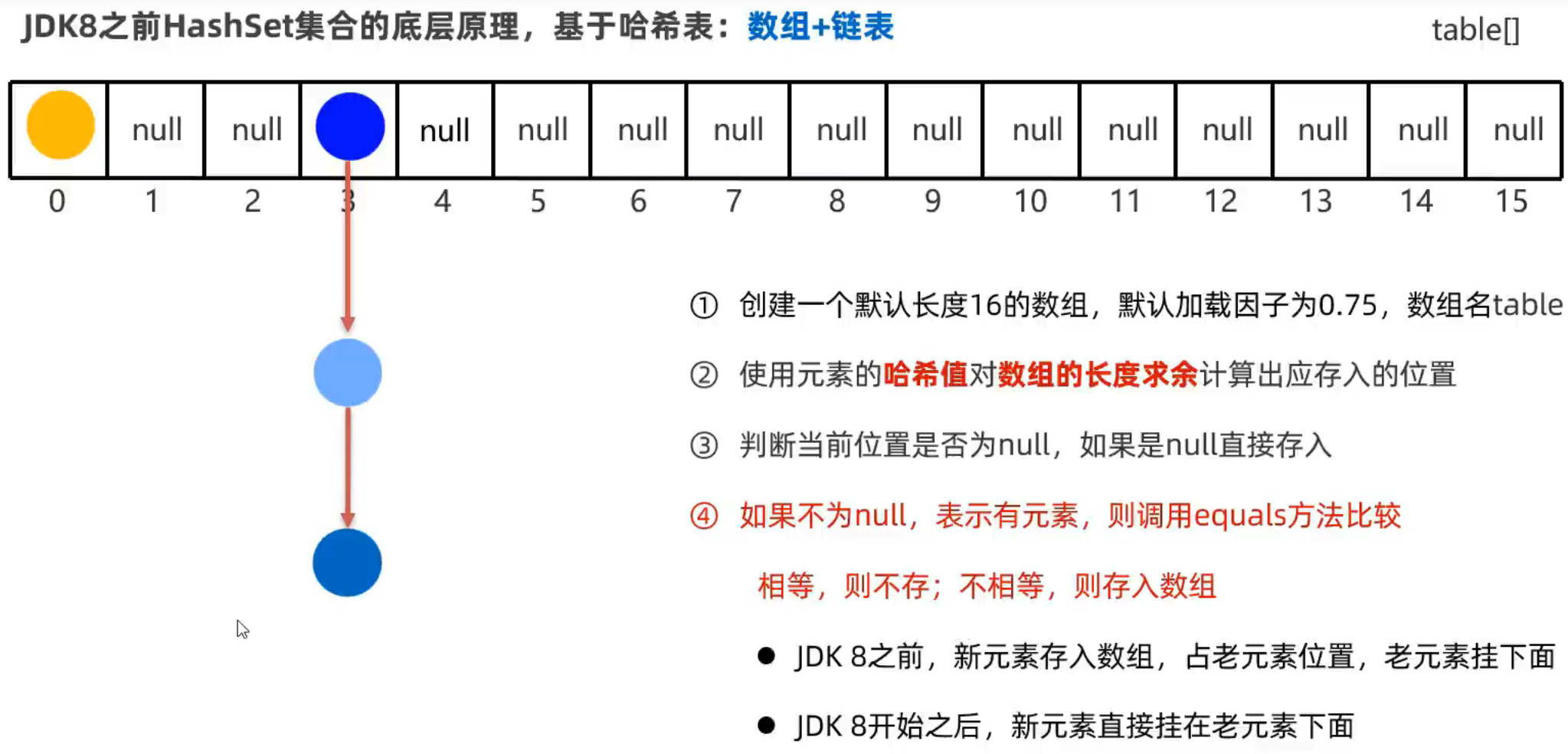
HashMap
无序、不重复、无索引
其实HashSet的本质就是没有值的HashMap,因此HashMap的原理与之前学习的HashSet一致,采用哈希表实现,如下图,HashMap用键来计算哈希值,且放入的数据是一个 键值对entry对象(下图的一个结点)

下面是从 【自用】JavaSE--集合框架(一)--Collection集合体系 中复制的:
HashMap同样也有对对象的去重原理,方法同HashSet,下面是从 【自用】JavaSE--集合框架(一)--Collection集合体系 中复制来的:
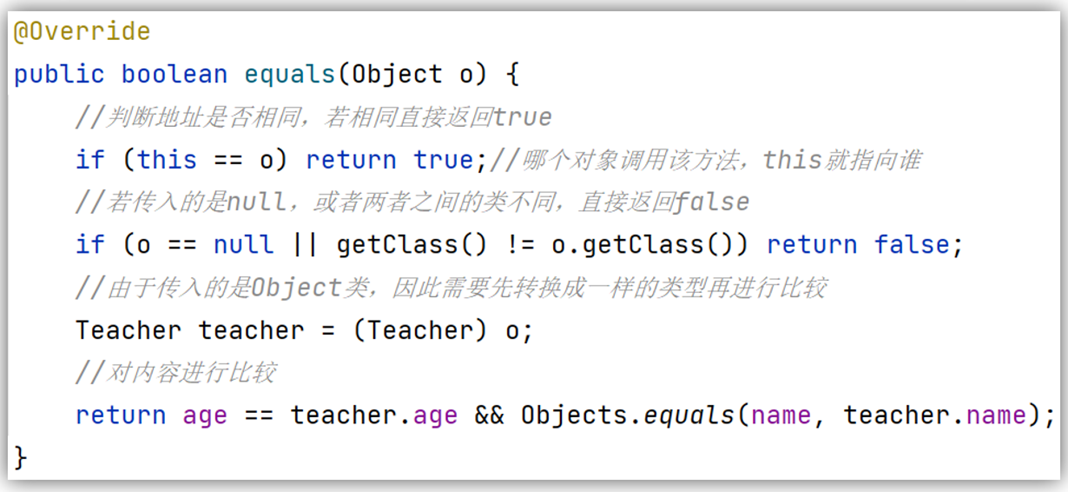
HashSet默认不能对内容一样的两个不同对象进行去重!因为虽然内容一样,但是地址是不同的,因此HashSet会认为两个对象并不是重复的
解决办法:在对象的类中重写 equals方法 与 HashCode方法 即可,直接右键generate可以生成,具体如下,简单的理解 ---> 重写后的equals方法:若对象相同会返回true,而重写后的hashcode方法:若两个对象的内容一样就返回相同的哈希值

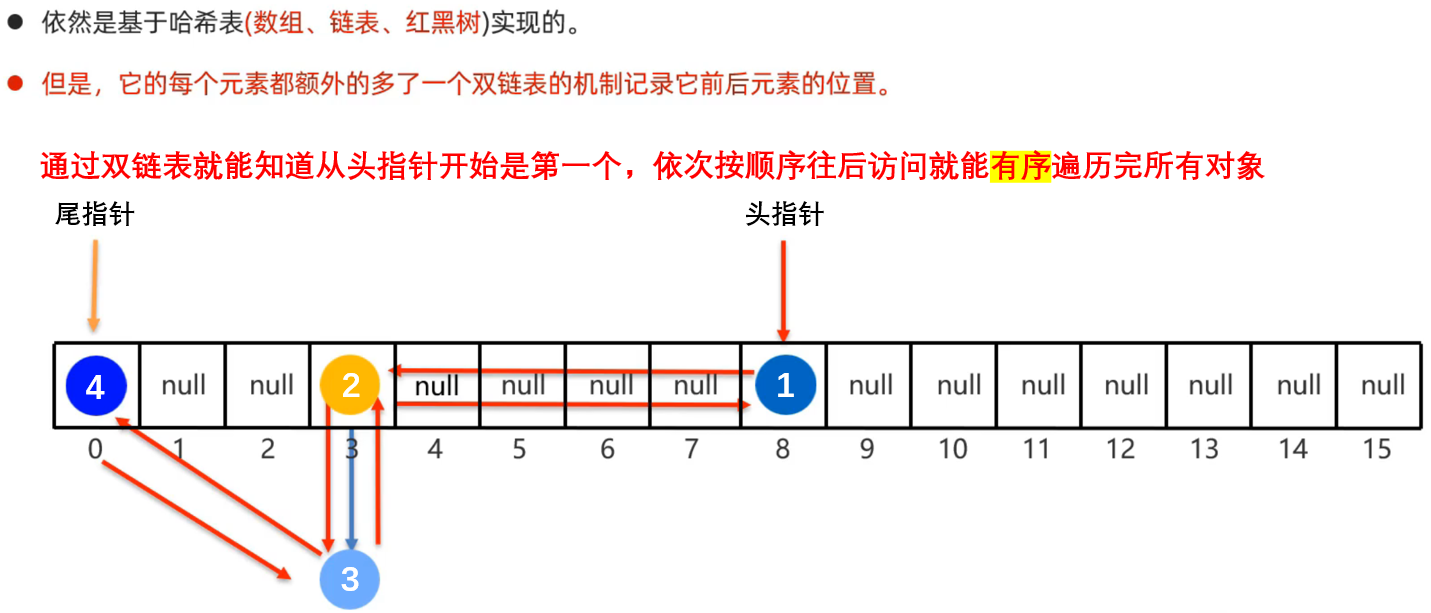
LinkedHashMap
有序、不重复、无索引
原理也与LikndHashSet一样,在哈希表的基础上增加了双链表,不同点就是存入的是 键值对 对象以及用键来计算哈希值
TreeMap
按照键的顺序默认升序排序(可自定义排序规则)、不重复、无索引


其实已经知道了,原理也是和TreeSet一样的!!!按照键默认升序排序,但是如果键是一个对象,就需要自定义排序,方法同TreeSet,具体如下(复制于【自用】JavaSE--集合框架(一)--Collection集合体系):
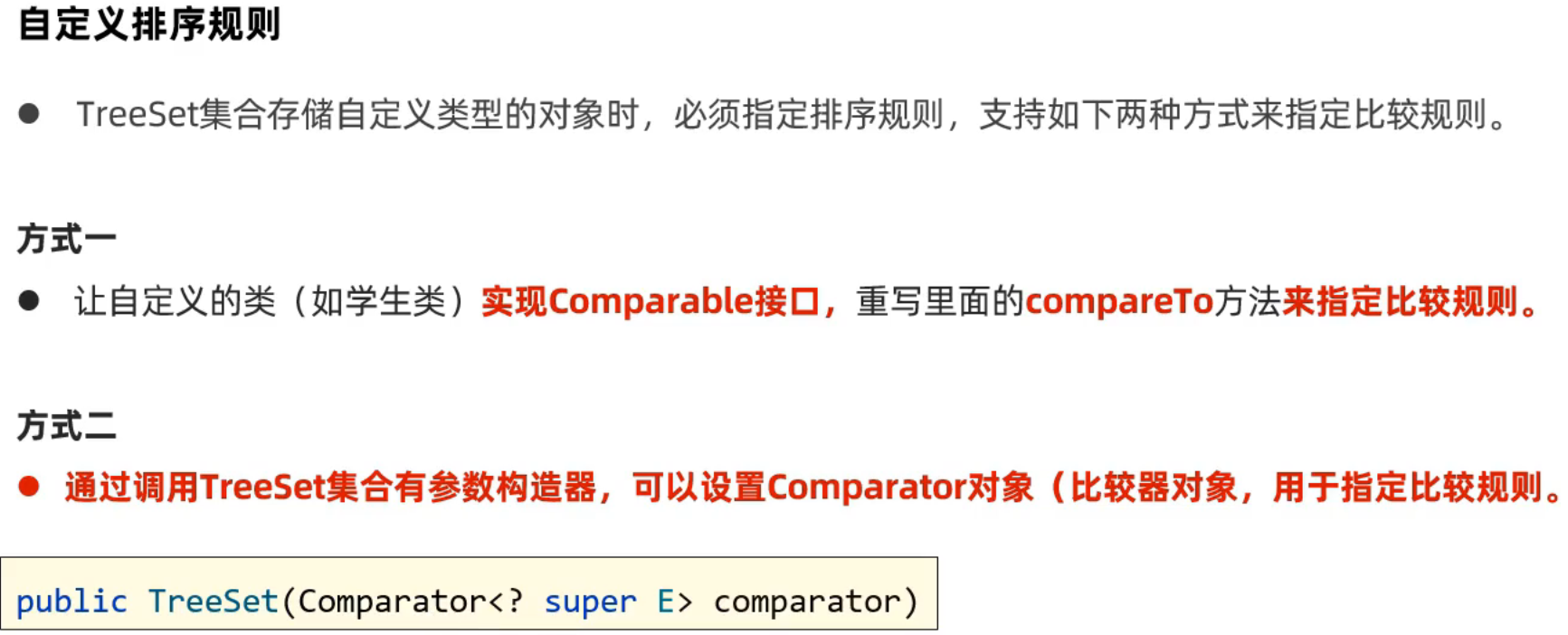
自定义排序规则
由于无法对对象进行直接排序,因此需要自己指定排序规则,如下图,之前在学习Arrays.sort时学过,这里方法一样
补充:
- 如果两种方法都是用了,TreeSet会采用就近原则使用外部重写的Comparator规则,而不使用对象类内部重新的
- 如果两个对象中出现的某一项相同,比如采用年龄排序,年龄都是16,则会丢失其中一个,因为Set的规则就是出现输入相同的数据时会保留先前输入的
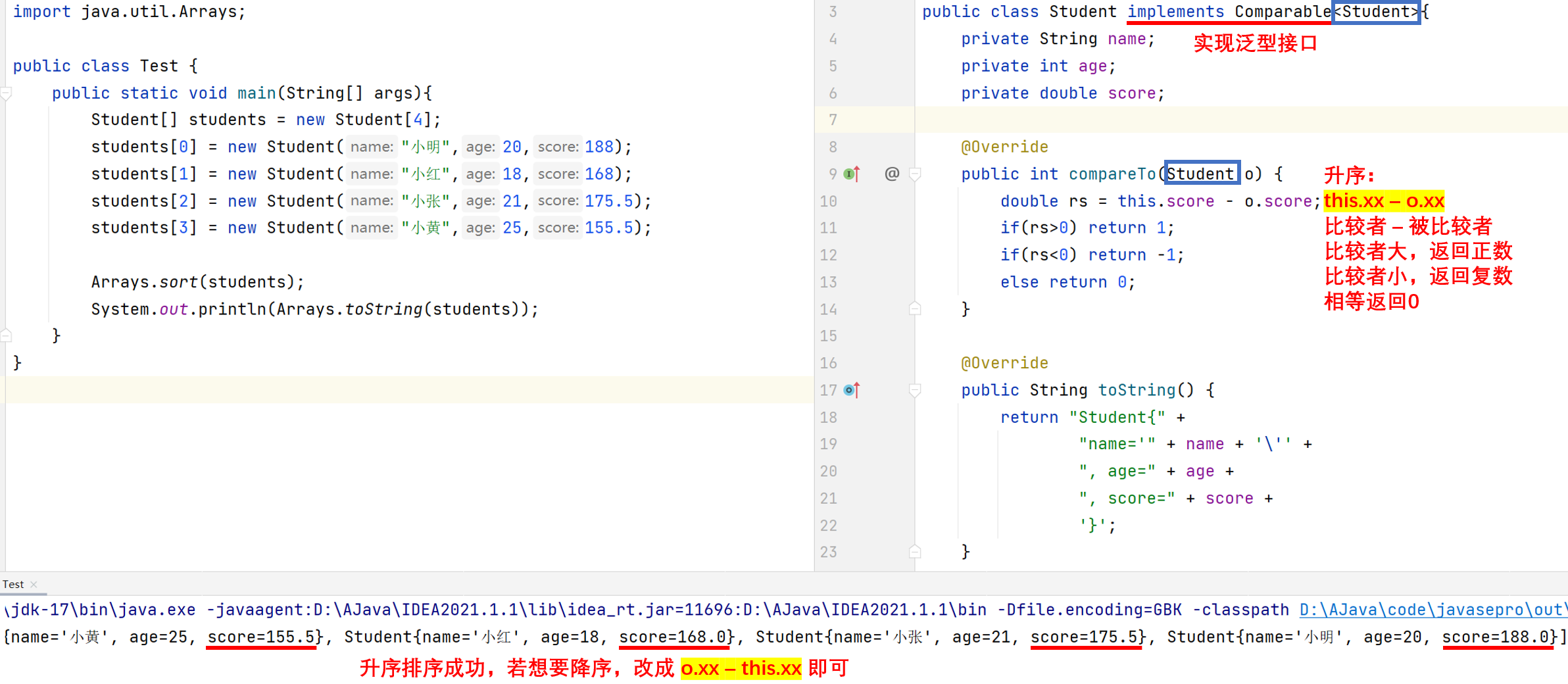
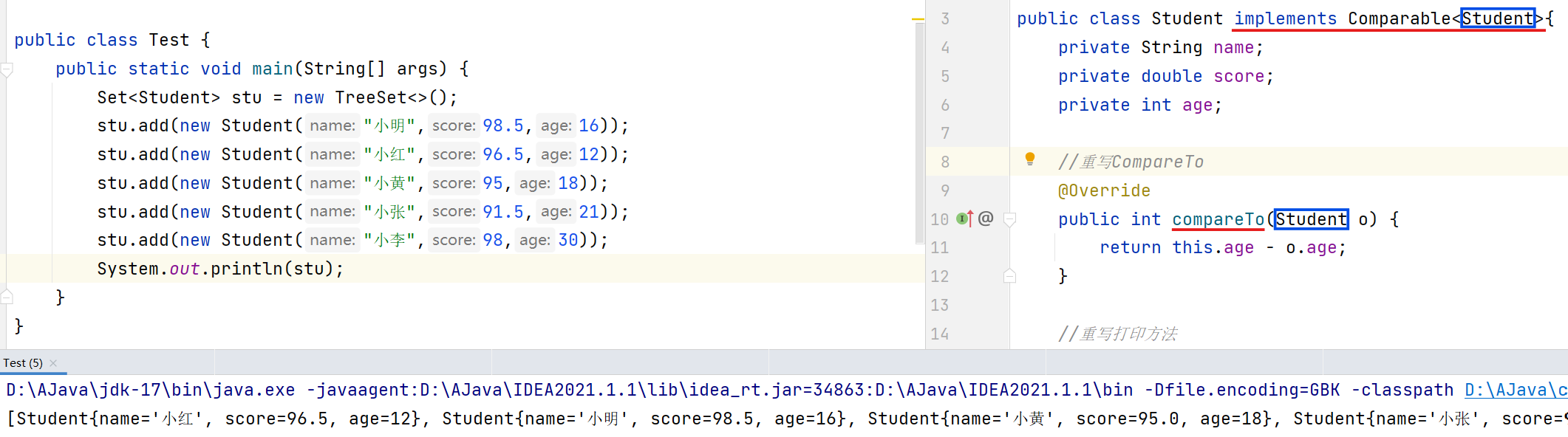
Comparable
让需要排序的对象类实现Comparable泛型接口,重写comparetor,自己指定规则,就能对对象进行排序了,示例如下:
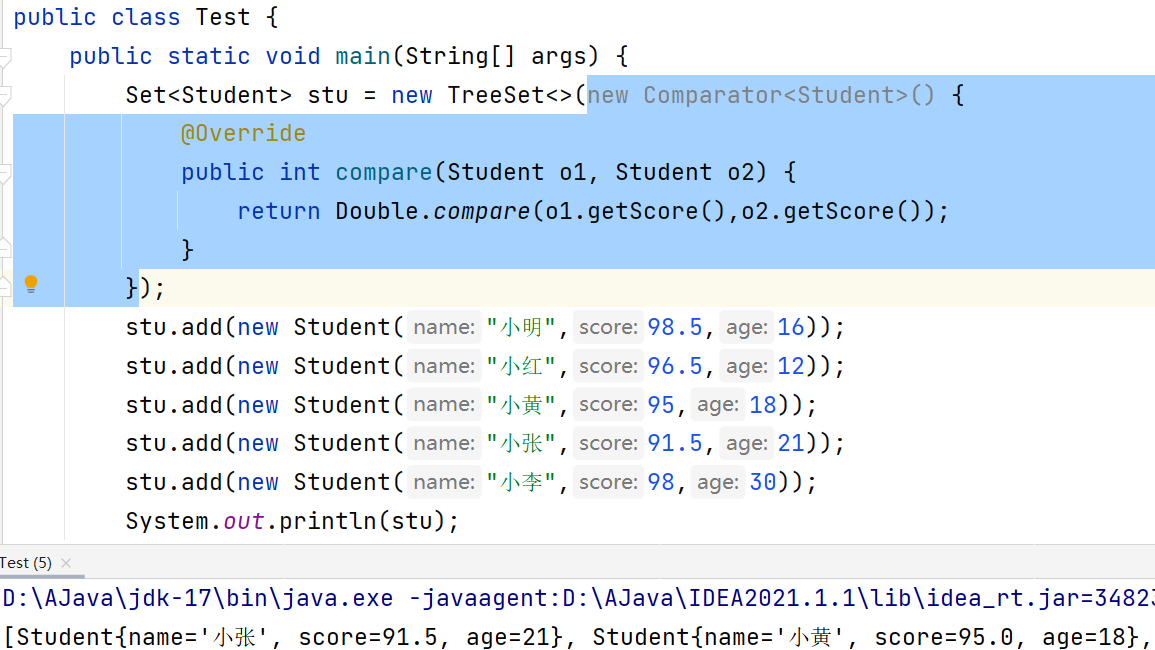
Comparator
Comparator是一个匿名内部类,在传入参数时直接重写,可以利用TreeSet的有参构造器直接设置Comparator对象
示例如下,其中调用的 Double.compare(double a,double b) 方法:a>b return 1 ; a<b return -1; a==b return0
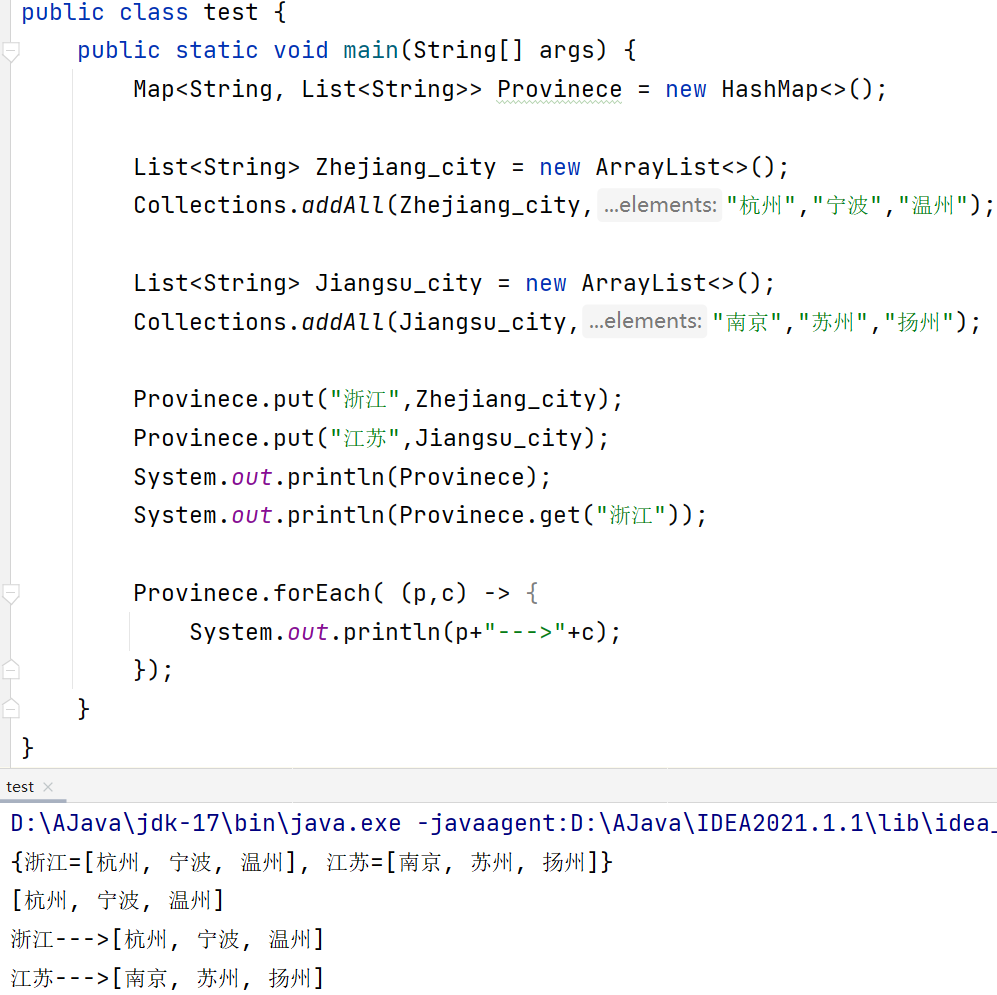
集合的嵌套
集合中还有集合,示例如下