【Python】Pandas
要求:
Pandas是基于Numpy开发出的,专门用于数据分析的开源Python库
Series(一维数据)
DataFrame(多特征数据,既有行索引,又有列索引)
DataFrame的属性
Panda数据读取(以csv为例)
pandas.read_csv(filepath_or_buffer, sep=",", names=None, usecols = None)
filepath_or_buffer : 文件路径(本地路径或url路径) sep: 分隔符 names: 列索引的名字 usecols: 指定读取的列名 返回的类型: DataFrame
Dataframe通过布尔索引过滤数据

代码实现:
1、通过numpy数组创建
import pandas as pd
import numpy as np
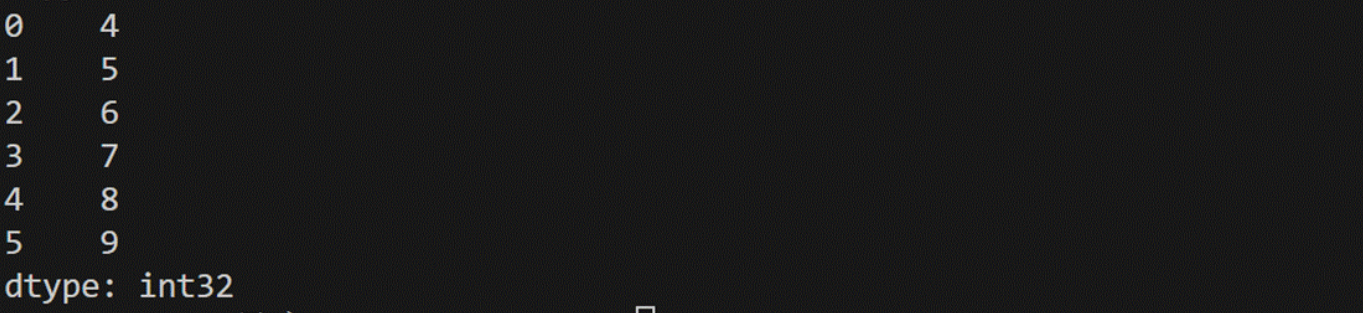
print(pd.Series(np.arange(4,10)))2、通过python数组创建
import pandas as pd
import numpy as npprint(pd.Series([11,12,14],index = ["北京","上海","深圳"]))3、通过python字典创建
import pandas as pd
import numpy as npprint(pd.Series({"北京":11,"上海":12,"深圳":14}))4、允许索引重复
import pandas as pd
import numpy as npa = pd.Series([11,12,14],index=["北京","上海","上海"])
a["上海"]
print(a)5、
DataFrame(多特征数据,既有行索引,又有列索引)
import pandas as pd
import numpy as npdata_3_4 = pd.DataFrame(np.arange(10,22).reshape(3,4))
print(data_3_4)
print(data_3_4[:1])
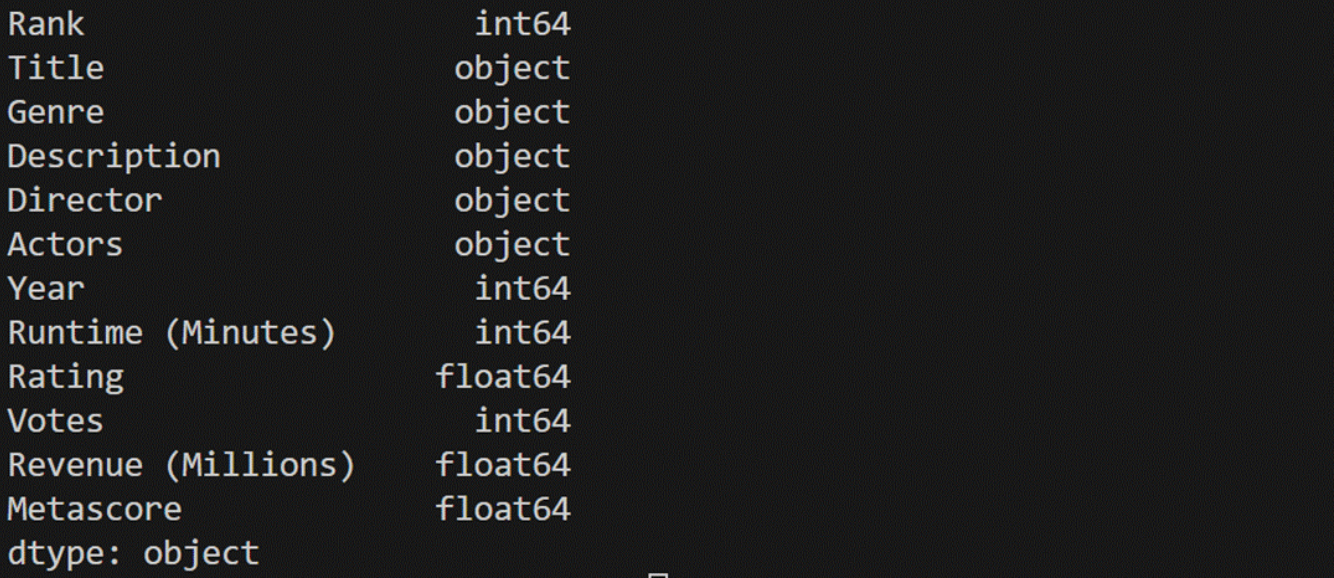
print(data_3_4[:][0])6、DataFrame的属性
import pandas as pd
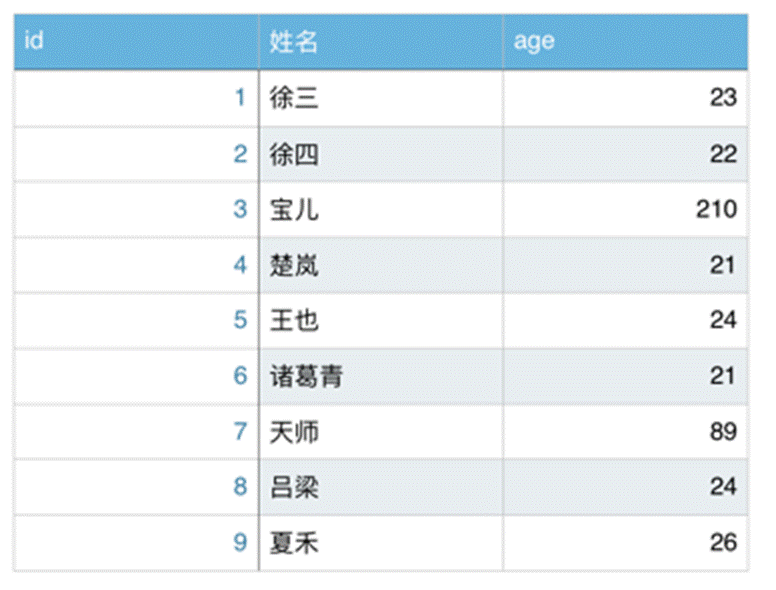
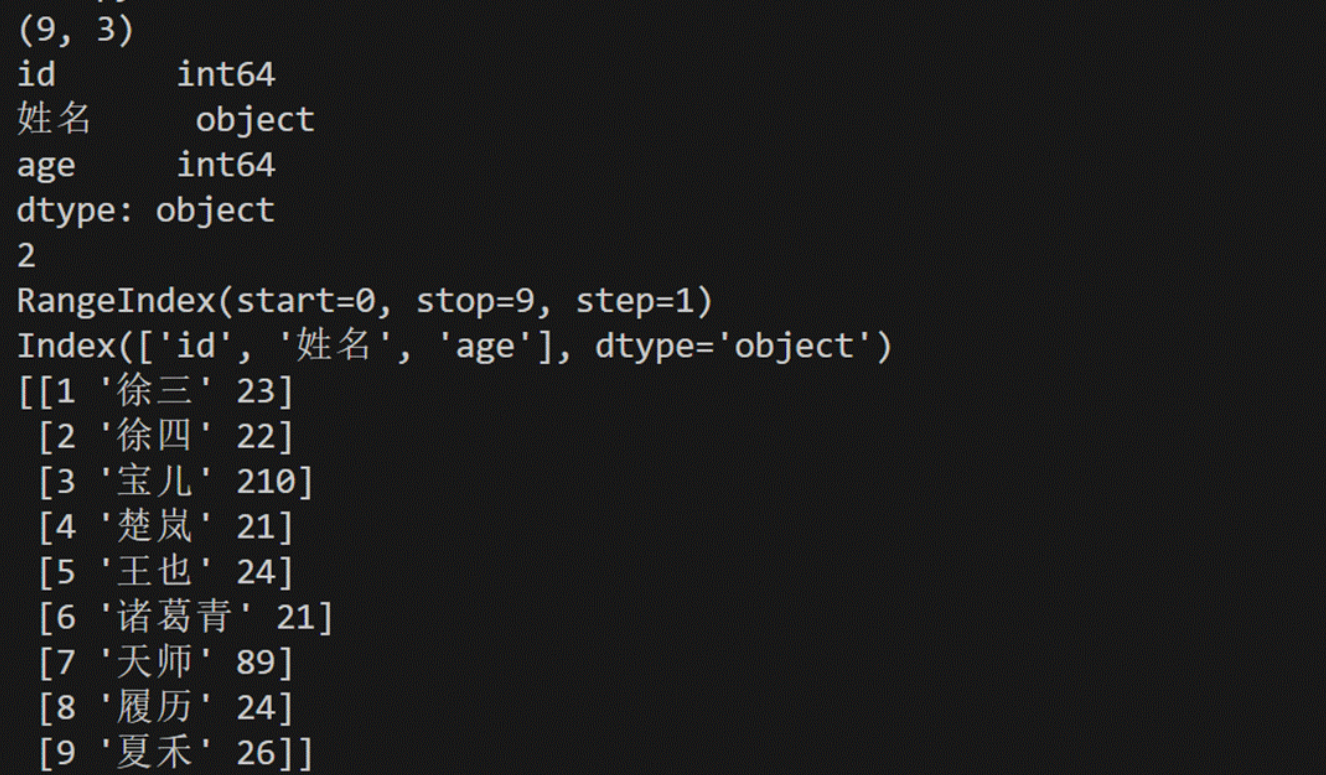
import numpy as npresult = pd.read_csv("C:/工作簿.csv",encoding='gbk')
print(result.shape)
print(result.dtypes)
print(result.ndim)
print(result.index)
print(result.columns)
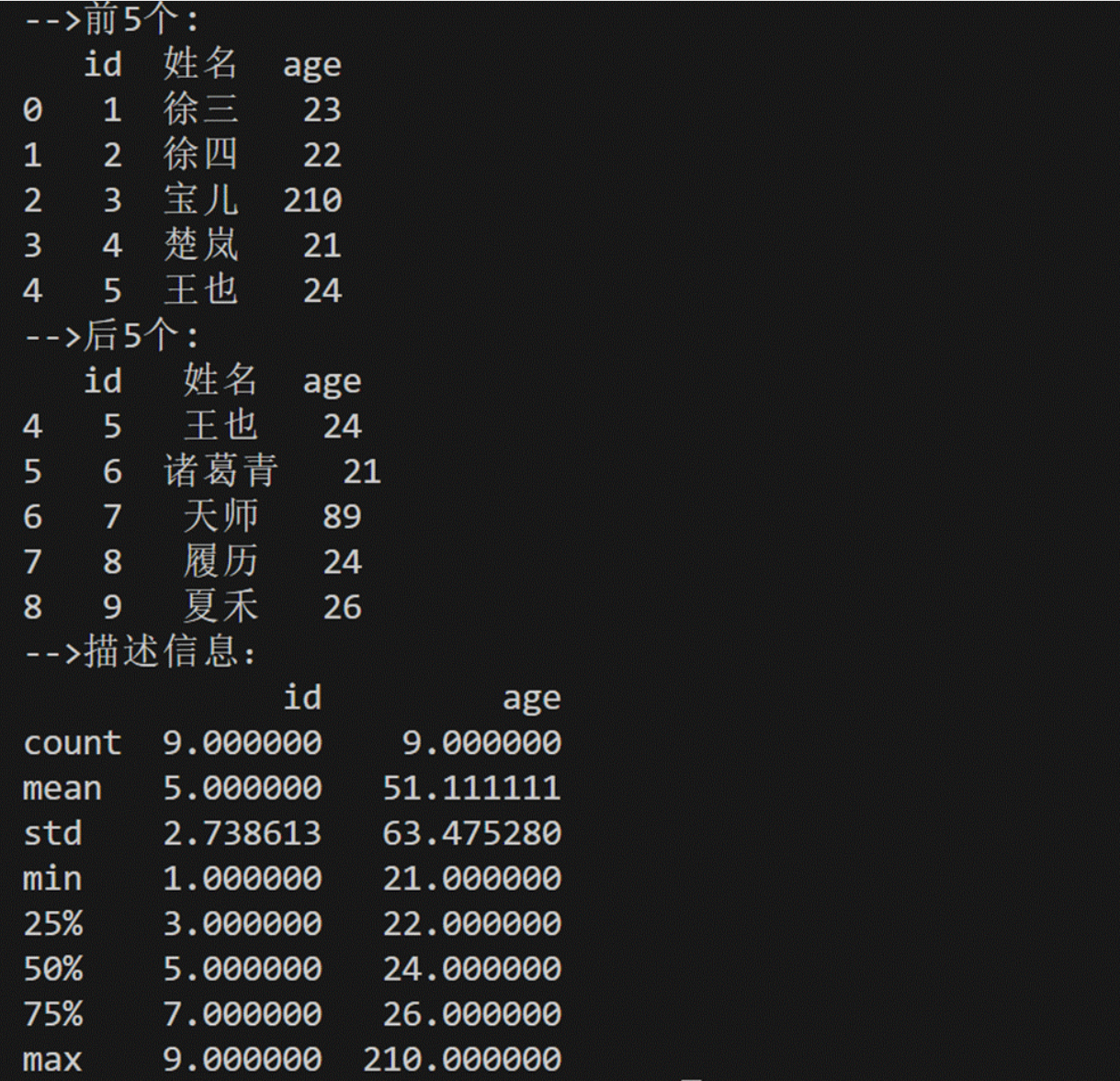
print(result.values)print("-->前5个:")
print(result.head(5))
print("-->后5个:")
print(result.tail(5))
print("-->描述信息:")
print(result.describe())7、Panda数据读取(以csv为例)
import pandas as pd
import numpy as npresult = pd.read_csv("C:/工作簿.csv",encoding='gbk')
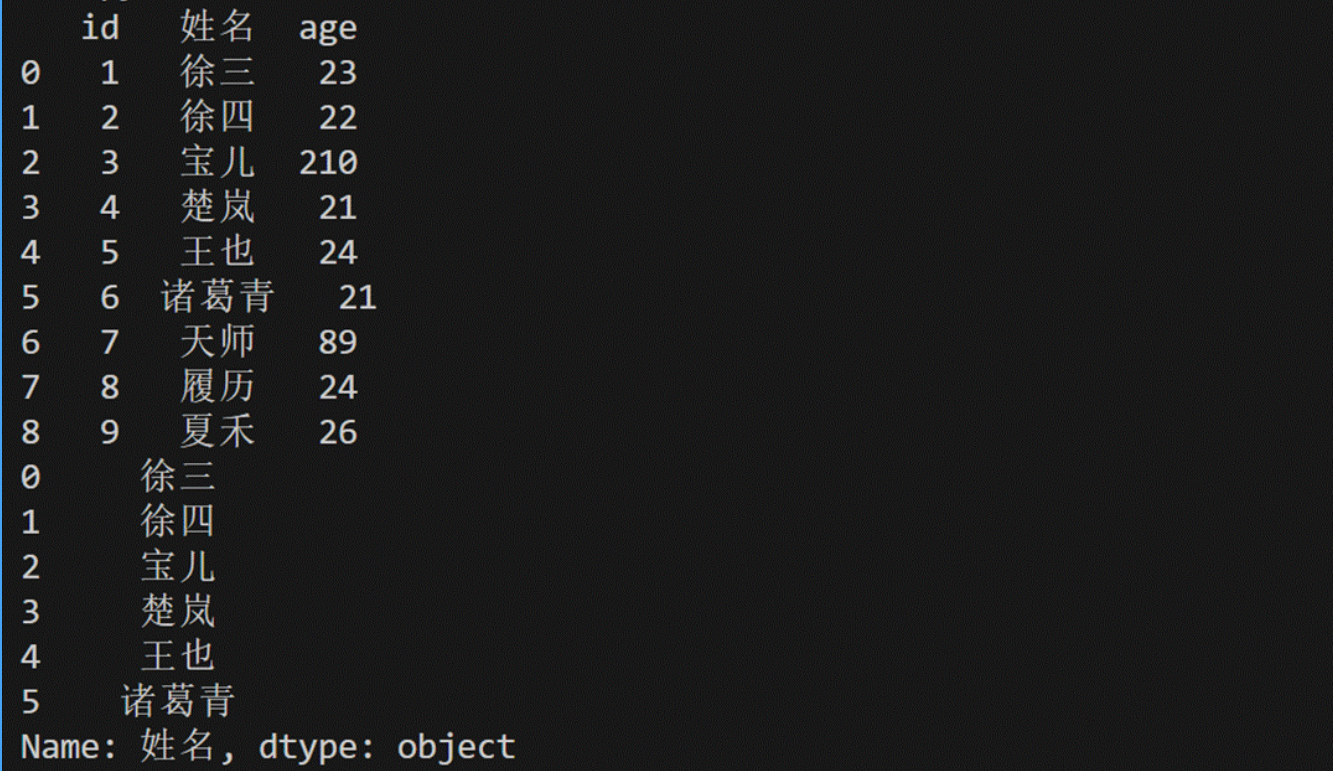
print(result)
print(result["姓名"][0:6])
print("读取后返回的类型为-->",type(result))8、Dataframe通过布尔索引过滤数据
import pandas as pd
import numpy as npresult = pd.read_csv("C:/工作簿.csv",encoding='gbk')
print(result[result["age"]>23])9、
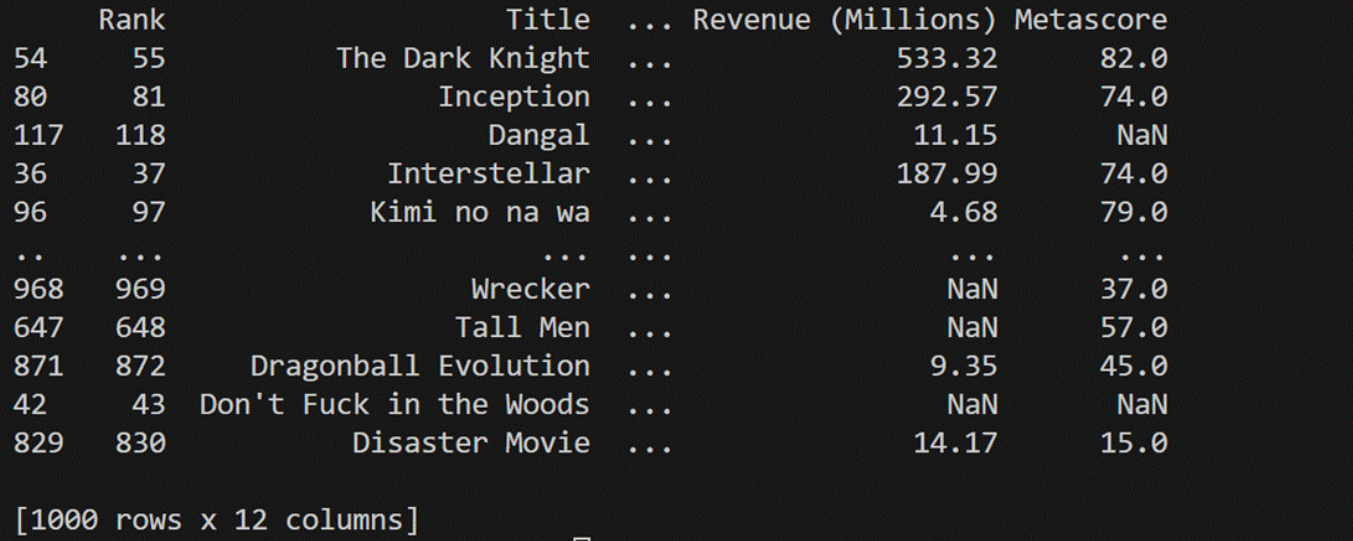
import pandas as pd
import numpy as npIMDB_1000 = pd.read_csv("C:/IMDB-Movie-Data.csv")
#print(IMDB_1000.dtypes)
#print(IMDB_1000.sort_values(by = "Rating",ascending=False))
#print(IMDB_1000[IMDB_1000["Runtime (Minutes)"]==IMDB_1000["Runtime (Minutes)"].max()])
#print(IMDB_1000[IMDB_1000["Runtime (Minutes)"]==IMDB_1000["Runtime (Minutes)"].min()])
#print(IMDB_1000["Runtime (Minutes)"].mean())
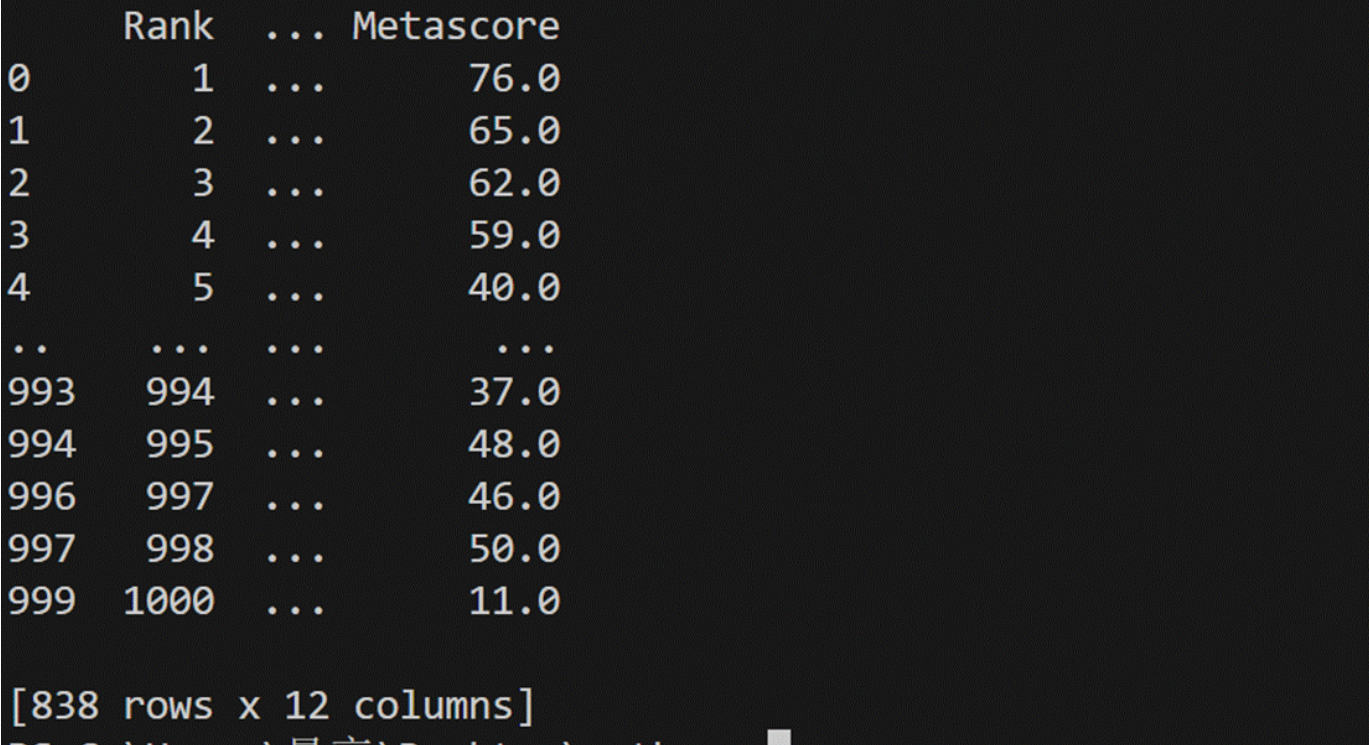
IMDB_1000.dropna()
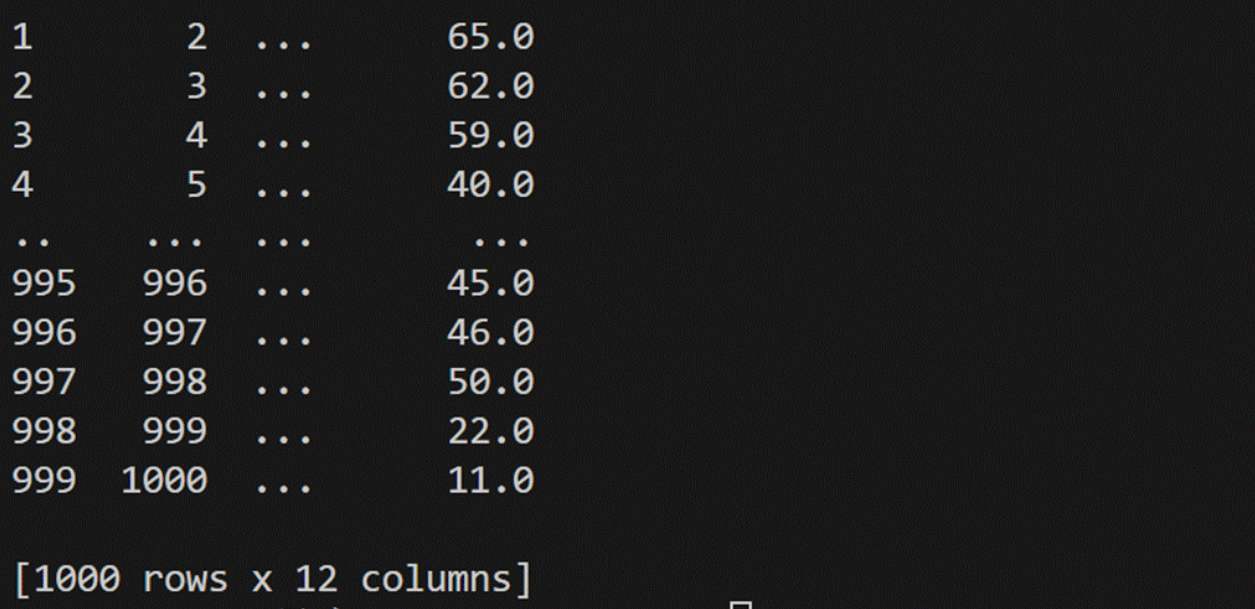
IMDB_1000.fillna("NaN")
IMDB_1000["Revenue (Millions)"].fillna(IMDB_1000["Revenue (Millions)"].mean(),inplace=True)
IMDB_1000运行结果:
1、通过numpy数组创建
2、通过python数组创建

3、通过python字典创建

4、允许索引重复

5、
DataFrame(多特征数据,既有行索引,又有列索引)

6、DataFrame的属性
7、Panda数据读取(以csv为例)
8、Dataframe通过布尔索引过滤数据

9、