【AI论文】CLiFT:面向计算高效与自适应神经渲染的压缩光场标记
摘要:本文提出了一种神经渲染方法,该方法将场景表示为“压缩光场标记(CLiFTs)”,以保留场景丰富的外观和几何信息。CLiFT通过压缩标记实现计算高效的渲染,同时能够通过调整标记数量来表征场景,或利用单个训练好的网络渲染新视角。具体而言,给定一组图像,多视图编码器会根据相机位姿对图像进行标记化处理。潜在空间K均值聚类算法利用这些标记选取一组精简的光线作为聚类中心。随后,多视图“压缩器”将所有标记的信息压缩至这些中心标记中,从而构建出CLiFTs。在测试阶段,给定目标视角和计算预算(即CLiFTs的数量),系统会收集指定数量的邻近标记,并利用计算自适应渲染器合成新视角。在RealEstate10K和DL3DV数据集上开展的广泛实验,从定量和定性两方面验证了本文方法的有效性:该方法在实现显著数据缩减的同时,仍能保持相当的渲染质量,并获得最高的综合渲染评分,同时在数据规模、渲染质量与渲染速度之间提供了灵活的权衡方案。Huggingface链接:Paper page,论文链接:2507.08776
研究背景和目的
研究背景
随着视觉媒体消费量的爆炸性增长,尤其是在Instagram、YouTube和TikTok等平台的推动下,每天有数十亿张照片和视频被捕获、分享和流式传输,这对存储和带宽提出了巨大需求。尽管现代压缩算法在图像和高清视频传输方面取得了显著进展,但交互式新型视图合成(NVS)技术的发展进一步推动了实时、高效渲染的需求。传统的神经渲染技术,如神经辐射场(NeRF)和3D高斯溅射(3DGS),虽然在静态场景重建方面表现出色,但在处理动态场景和实时渲染时仍面临挑战。此外,这些方法通常需要针对每个场景进行优化,缺乏跨场景的泛化能力,并且假设输入覆盖密集。
研究目的
本文旨在提出一种新的神经渲染方法,通过引入“压缩光场标记(CLiFTs)”来解决上述挑战。CLiFT旨在保留场景丰富的外观和几何信息,同时实现计算高效的渲染。具体目标包括:
- 数据高效:通过压缩标记减少数据规模,同时保持高质量的渲染效果。
- 自适应渲染:根据计算预算动态调整渲染质量与速度之间的权衡。
- 泛化能力:构建一个能够处理不同场景的通用渲染框架,而无需针对每个场景进行单独优化。
研究方法
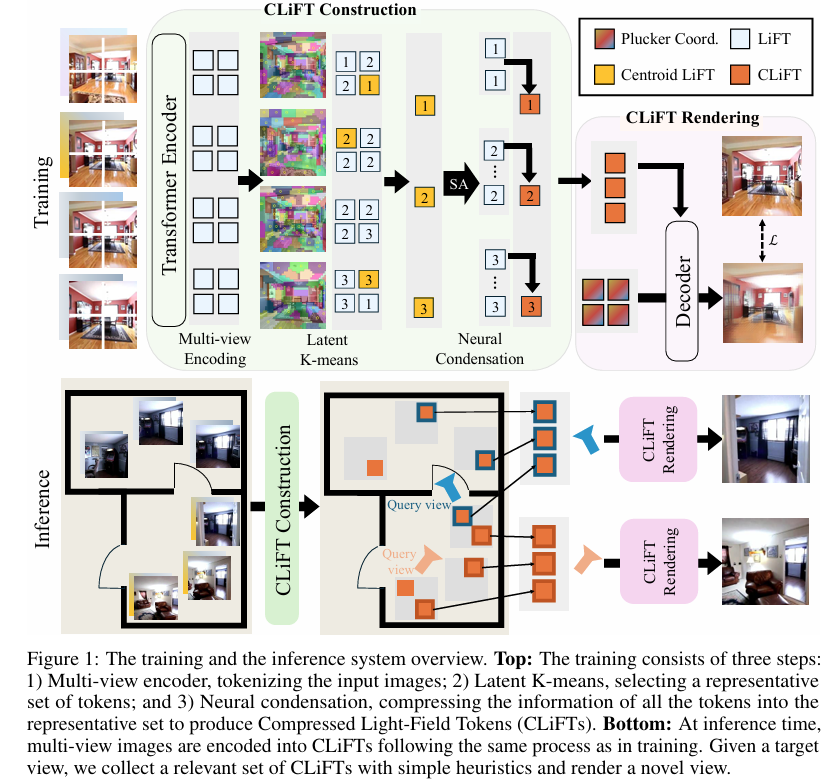
1. 压缩光场标记(CLiFTs)的构建
多视图编码:给定一组带有相机位姿的图像,使用Transformer编码器将每张图像及其相机位姿编码为光场标记(LiFTs)。每个LiFT包含对应光线的几何和外观信息,通过拼接光线的6D Plücker坐标和归一化3D颜色向量,并分块处理为768维的向量。
潜在空间K均值聚类:在潜在空间中使用K均值算法从所有LiFTs中选择一组精简的光线作为聚类中心(即CLiFTs)。这一步骤通过保留几何多样性覆盖同时增加纹理丰富区域的密度,确保选定的中心标记能够代表整个场景。
神经压缩:使用轻量级Transformer将所有LiFTs的信息压缩到中心标记中,形成最终的CLiFTs。这一过程通过自注意力和跨注意力机制实现信息在聚类内部的交换和整合。
2. 自适应渲染
动态令牌选择:在渲染新视角时,根据目标视角和计算预算(即使用的CLiFT数量),系统动态选择邻近的CLiFTs进行渲染。这一过程通过简单的启发式算法实现,确保所选标记在空间上的覆盖性和代表性。
计算自适应渲染器:使用Transformer解码器作为渲染器,以目标视角作为查询,选定的CLiFTs作为键和值,通过自注意力和跨注意力机制合成新视角。渲染器在训练过程中随机变化输入的CLiFT数量,以学习处理不同数量的标记,从而实现动态调整渲染质量和速度的能力。
研究结果
定量评估
在RealEstate10K和DL3DV数据集上的实验结果表明,CLiFT在数据规模、渲染质量和渲染速度之间实现了显著的权衡。具体而言:
- 数据缩减:与基线方法相比,CLiFT在保持相当渲染质量的同时,实现了约5-7倍的数据缩减(相对于MVSplat和DepthSplat),以及约1.8倍的数据缩减(相对于LVSM)。
- 渲染质量:在PSNR、LPIPS和SSIM等指标上,CLiFT达到了与基线方法相当甚至更高的渲染质量,尤其是在高压缩率下仍能保持较高的视觉保真度。
- 渲染速度:通过动态调整使用的CLiFT数量,CLiFT能够在保证渲染质量的同时,显著提高渲染速度(FPS),并降低计算量(FLOPs)。
定性评估
定性结果进一步验证了CLiFT的有效性。在RealEstate10K和DL3DV数据集上的渲染示例显示,CLiFT能够保留更多的细节和更高的视觉保真度,即使在强压缩下也仅轻微损失高频内容。
研究局限
尽管CLiFT在数据缩减、渲染质量和渲染速度方面表现出色,但仍存在一些局限性:
- 相机运动泛化性:当相机运动显著偏离训练分布时(如RealEstate10K数据集中主要是平滑平移和轻微旋转),模型的泛化能力受限。
- 动态场景处理:当前方法主要针对静态场景设计,对于动态场景的处理能力有限。
- 计算复杂度:尽管CLiFT通过压缩标记减少了数据规模,但在高分辨率场景下,计算复杂度仍然较高,尤其是在渲染过程中动态调整CLiFT数量时。
未来研究方向
针对上述局限,未来的研究可以从以下几个方面展开:
- 增强相机运动泛化性:通过引入更复杂的相机运动模型或数据增强技术,提高模型对复杂相机运动的适应能力。
- 动态场景渲染:探索将CLiFT框架扩展到动态场景的方法,如引入时间维度或动态光场表示。
- 优化计算效率:进一步研究计算高效的标记选择和渲染算法,如引入更高效的聚类方法或稀疏注意力机制,以降低计算复杂度。
- 多模态融合:结合其他模态的信息(如音频、文本),探索多模态神经渲染的可能性,以提供更丰富的交互体验。
通过不断优化和扩展CLiFT框架,有望推动神经渲染技术的发展,为虚拟现实、增强现实和在线购物等领域带来更高效、更真实的视觉体验。