LatentSync: 一键自动生成对嘴型的视频

LatentSync是什么
字节跳动与北京交通大学联合推出了全新的唇形同步框架 LatentSync,它基于音频驱动的潜在扩散模型,跳过了传统的3D建模或2D特征点提取,直接生成自然逼真的说话视频。
LatentSync借助Stable Diffusion强大的图像生成能力,精准捕捉声音与唇部动作之间的复杂关联。为了解决扩散模型在不同帧之间生成不一致的问题,团队提出了名为 TREPA(Temporal Representation Alignment) 的方法,引入大规模自监督视频模型提取时间特征,有效增强生成视频的时间连贯性,同时保持唇形同步的准确性。
在实验中,LatentSync成功解决了传统模型SyncNet的收敛难题,显著提升了唇形对齐的质量和稳定性。
LatentSync的主要功能
- 唇形同步生成:根据输入音频生成对应口型,让嘴唇与语音完美对齐。
- 高分辨率输出:突破传统扩散模型对显卡的高要求,轻松生成清晰流畅的视频画面。
- 动态真实表现:能捕捉情感语调中的细微变化,让说话表情更生动自然。
- 时间一致性优化:通过TREPA方法提升视频帧间连贯性,减少闪烁,让播放更平滑。
LatentSync的技术原理
- 音频驱动的潜在扩散模型:不同于传统在像素空间中进行扩散的方式,LatentSync在潜在空间中直接建模,以音频为条件生成唇形动作,避免两阶段生成过程,大幅提升质量与效率,同时精准捕捉视听之间的复杂关联。
- 端到端建模架构:整个流程从音频输入到唇部运动输出,全在一个统一模型中完成,省去了冗余的中间步骤,确保生成过程更加高效和一致。
- TREPA时间一致性优化:引入 VideoMAE-v2 自监督模型提取时间特征,通过衡量生成帧与真实帧的时间表示距离,作为训练中的额外损失,有效减少视频播放中的跳帧、闪烁问题,提升自然度。
- SyncNet监督机制:训练时结合预训练的 SyncNet,对生成的唇部动作进行精准监督,确保音视频高度对齐。在像素层面引入 SyncNet 损失,使模型更深入地理解音频与唇形之间的对应关系。
LatentSync的项目地址
- GitHub仓库:https://github.com/bytedance/LatentSync
- arXiv技术论文:https://arxiv.org/pdf/2412.09262
LatentSync的应用场景
-
🎬 影视后期制作:自动为配音生成匹配口型动画,提升效率,确保角色表演自然连贯。
-
📚 教育辅助教学:在在线英语课程中生成唇同步视频,帮助学生更准确地模仿发音,提升语言学习效果。
-
📢 广告视频创作:为虚拟代言人自动生成自然的口型表达,让广告词更具表现力和吸引力。
-
🧑💻 远程会议沟通:解决网络延迟带来的音画不同步问题,提升跨国视频会议的交流体验。
-
🎮 游戏角色互动:让NPC在游戏中实现语音与唇部动作同步,增强沉浸感与真实感。
先看效果
原视频
原视频
生成效果
生成结果
快速上手指南
AI工具已经被打包成一键启动的版本,只需轻轻点击即可使用,无需再为环境配置中的各种问题烦恼,一切变得更加便捷高效。
电脑配置要求
- 操作系统:Windows 10/11 64位
- 内存:16G以上
- 显卡:至少8G及以上显存的英伟达(NVIDIA)显卡
- CUDA:显卡驱动更新到最新,显卡支持的CUDA版本大于等于12.8版本
- 整个包解压完约21.3G,要留足硬盘空间
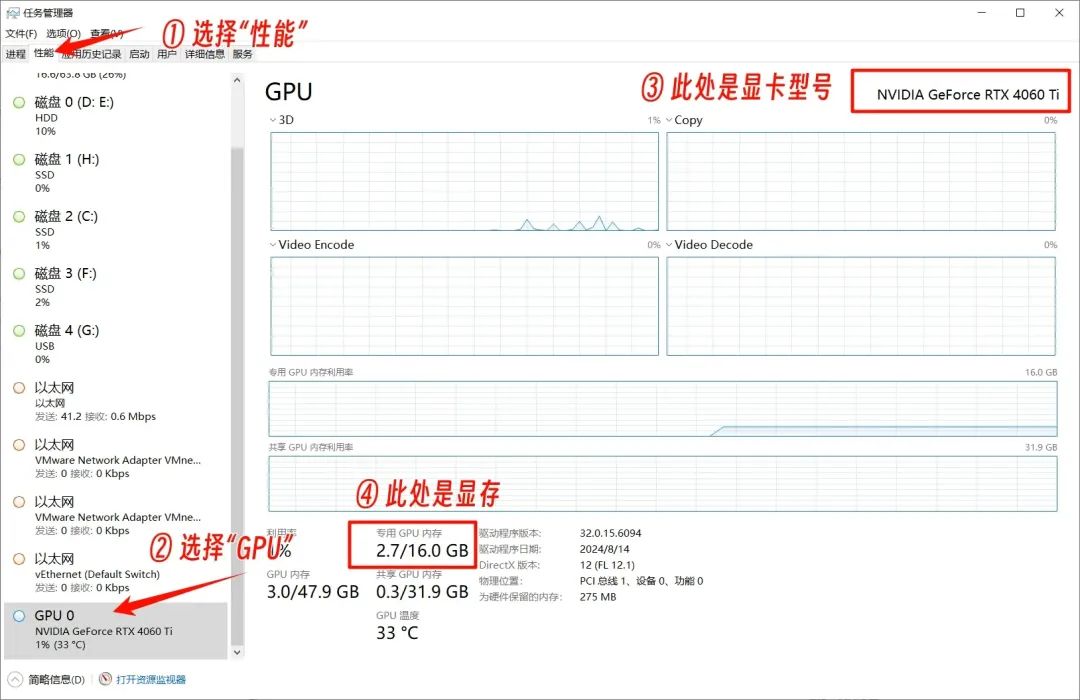
如何查看显卡品牌型号和显存:
- 打开任务管理器
- 点击“性能”
- 点击“GPU”
- 右上角可以看到显卡型号,下方可以看到显存大小
使用教程:
① 打开下载页面:
- (方式1)直达链接:https://www.xyanai.com/2036.html
- (方式2)进入官网www.xyanai.com,搜索”LatentSync”
进入后点击页面右侧下载按钮,下载整合包之后解压,建议使用winrar解压(解压软件在文件包中,或者可以自己下载安装,下载地址:https://www.winrar.com.cn/)
不要用Windows自带解压!!不要用360解压!!
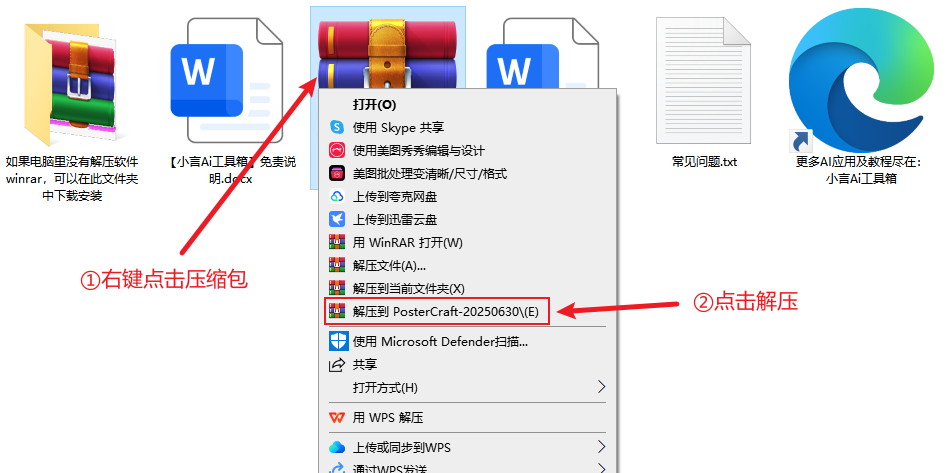
注意:文件夹路径和文件名称(包括音频、图片、视频等文件名称)不要出现中文字符,否则部分软件会因识别不出而报错
![]()
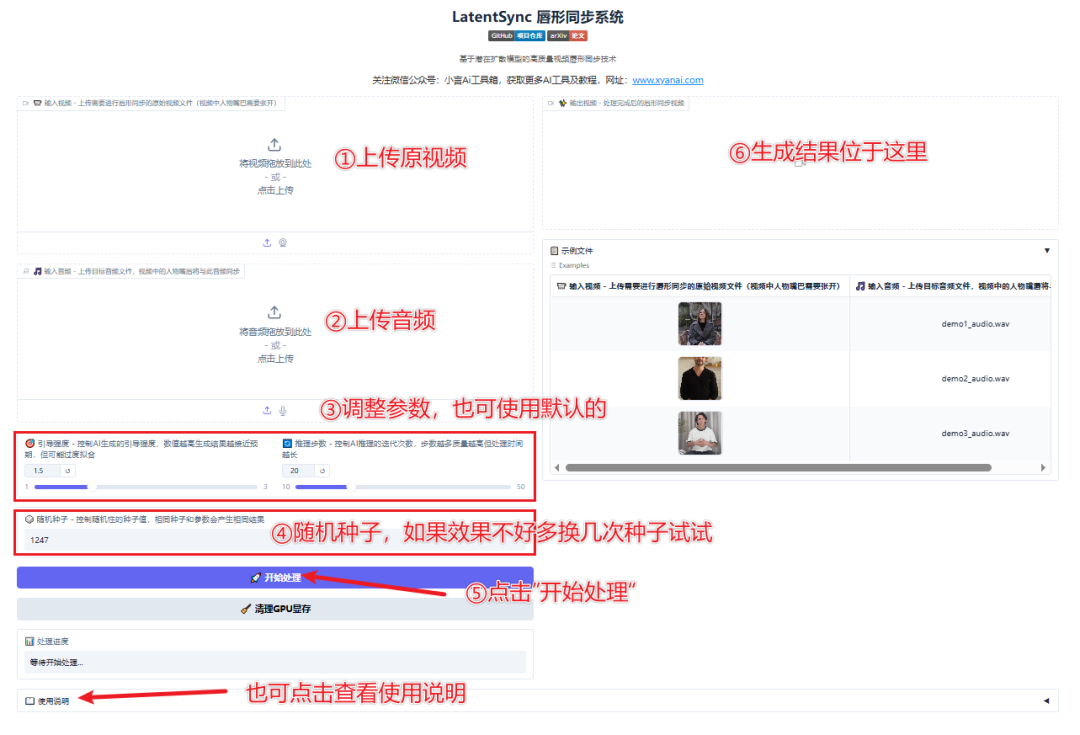
② 双击“启动程序.exe”,稍等片刻会在浏览器中自动打开操作界面

③只需上传一段人物视频(MP4格式,建议时长长于音频),再上传一段音频文件(支持常见格式如MP3、WAV等),系统便会自动生成与音频精准对口型的唇形同步视频。如果视频时长短于音频,系统会自动采用“正序→倒序”的循环方式,让画面更自然流畅。如需高清效果,可勾选“提升分辨率”选项,并选择GFPGAN版本和放大倍数。准备完成后,点击“生成”按钮即可开始处理,全流程无需手动干预,轻松生成自然真实的说话视频。
请确保上传的视频中人物面部清晰可见,且全过程中人物始终在画面内,避免出现离开画面或黑屏的情况,否则系统可能因无法检测到人脸而报错。处理时长将根据视频长度和设备性能有所不同,请耐心等待生成完成。
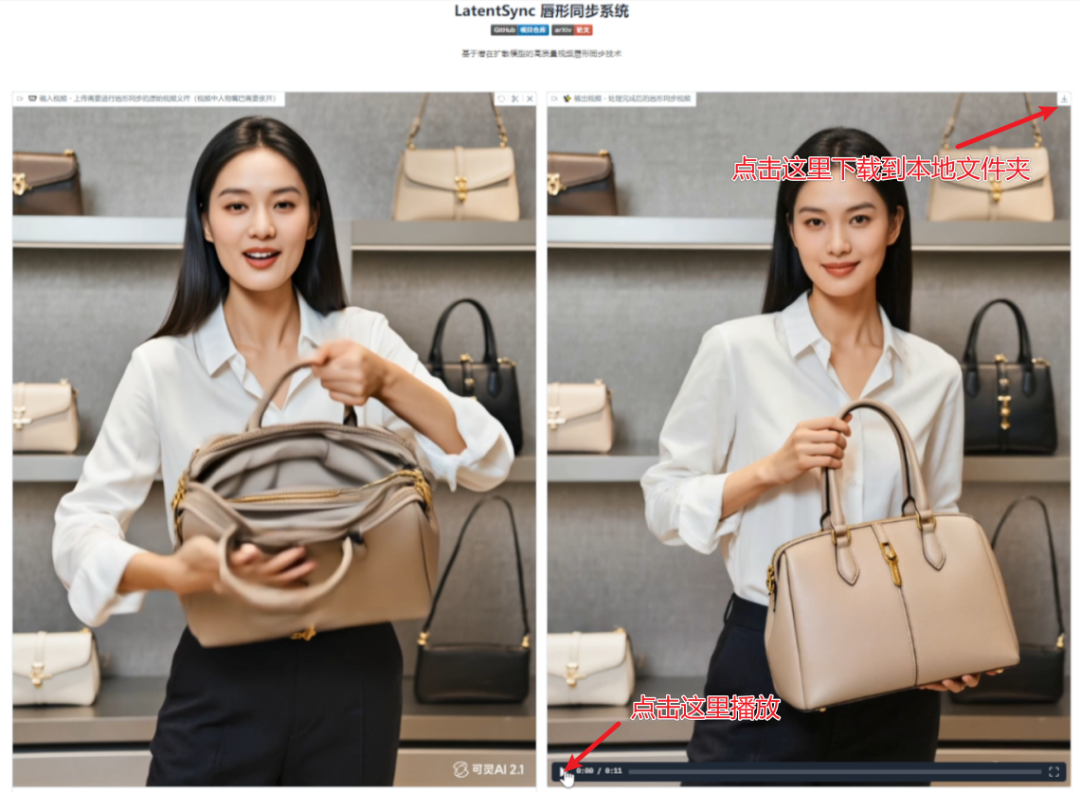
④等待处理完成后,右侧将显示生成的结果视频,可以播放查看,点击右上角下载按钮可以保存至指定文件夹
总结
LatentSync 是字节跳动与北京交通大学联合推出的一种音频驱动唇形同步视频生成框架。它基于潜在扩散模型,直接在潜在空间建模,无需3D建模或关键点提取,能高效生成高分辨率、时间一致性强、表情自然的说话视频。通过引入TREPA时间表示对齐机制和SyncNet监督,LatentSync实现了更真实流畅的音视频同步,广泛适用于影视、教育、广告、会议、游戏等场景。