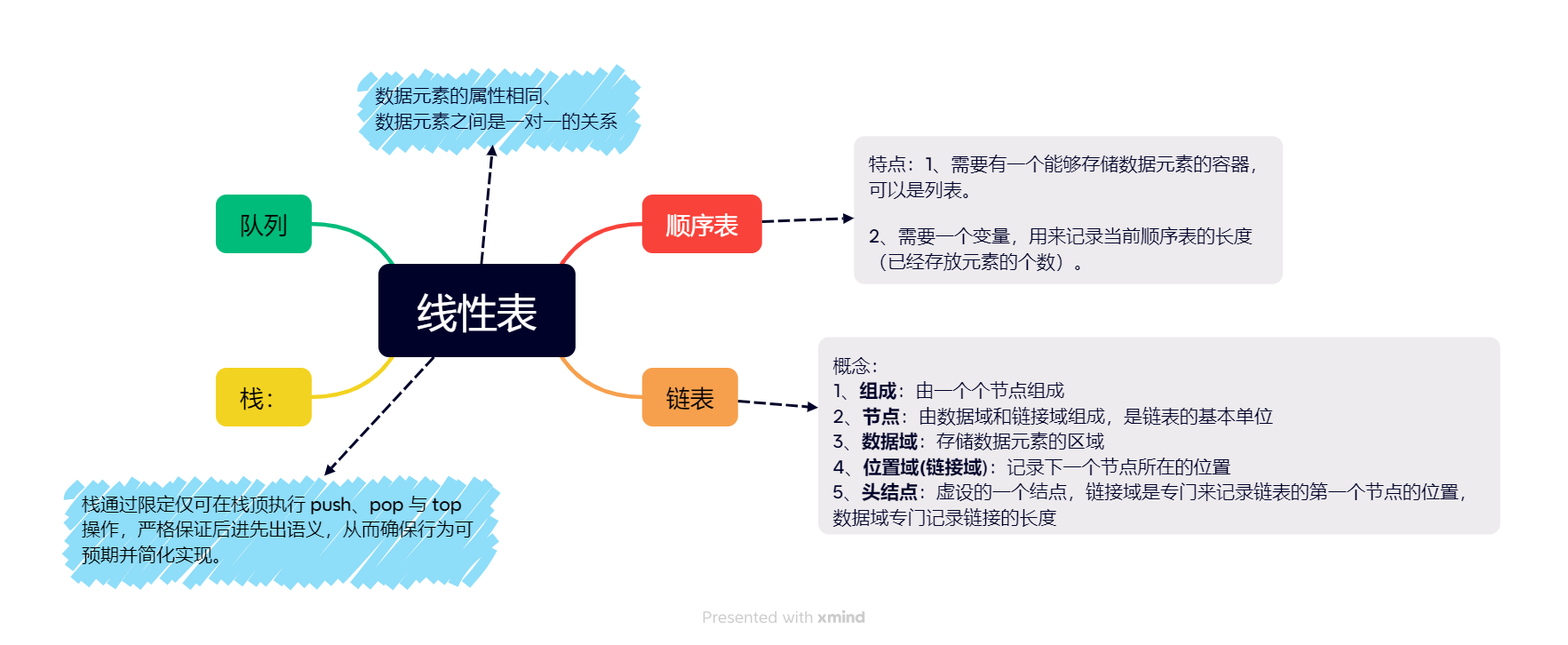
一、思维导图
二、链表的反转
def reverse(self):"""思路:1、设置previous_node、current、next_node三个变量,目标是将current和previous_node逐步向后循环并逐步进行反转,知道所有元素都被反转2、但唯一的问题是:一旦current.next反转为向前,current的后继元素就将不再被记录3、所以设置一个next_node用于在反转开始前,current将后继元素赋值给next_node。4、开始反转5、反转后将current和previous_node向后移动一次,然后重复以上3-5步骤:return:"""previous_node = Nonecurrent = self.headwhile current:next_node = current.next # 记录下一个节点,因为等会current的next要反转了,先保存以免丢失current.next = previous_node # 反转节点previous_node = current # 移动previouscurrent = next_node # 移动next_node,由于next_node已经被记录,所以即使current.next变成了前面的元素,但后面的元素也能找到。# print(current.data, end="--->")self.head = previous_node # 最后把self.head补上
三、合并两个有序链表
def merge_sorted_lists(self, other_list):"""思路:1、创建i、j用于确定次数(之所以函数中的ij就能确定次数,是因为合并两个有序列表实际上的目标是:将其中一个列表在与另一个列表的对比中,逐渐消耗到0,即排序完成),只要其中一个完成了不用管另一个完成了没有直接加到尾部就行了,而ij正是这种设计,知道i,j的某一个达到对应列表的最大值(排序完成)才跳出第一个循环2、创建p、q两个"指针"用于遍历各自的链表3、翻转两个链表方便对比,因为这是单项升序表4、删除链表1的原节点注意事项:1、当self链表为空时直接反转other链表并拷贝,other为空则不变2、判空"""# 任意链表为空则无操作if self.size == 0 and other_list.size == 0:returnelif self.size == 0:# 如果 self 是空的,就将 other_list 反转拷贝进来other_list.reverse()p = other_list.headwhile p:self.add_tail(p.data)p = p.nextself.reverse()self.size = other_list.sizereturnelif other_list.size == 0:return # self 不变# 记录 self 原有节点数量pre_size = self.size# 反转两个链表(升序→降序)self.reverse()other_list.reverse()# 准备两个指针,遍历 self 和 other_listq = self.headp = other_list.headi = j = 0while i < pre_size and j < other_list.size:if q.data >= p.data:self.add_tail(q.data)q = q.nexti += 1else:self.add_tail(p.data)p = p.nextj += 1# 4. 把剩下的节点继续添加到尾部while i < pre_size:self.add_tail(q.data)q = q.nexti += 1while j < other_list.size:self.add_tail(p.data)p = p.nextj += 1# 5. 删除 self 原来的 pre_size 个“旧节点”for _ in range(pre_size):self.delete_head()# 6. 恢复升序结构self.reverse()# 7. 更新 sizeself.size = pre_size + other_list.size
四、链表完整实现
"""
目的:解决顺序表存储空间有上限、删除和插入效率低等问题(因为是按照简单的列表索引储存的,每次插入删除需要腾位操作)。
链表:链式存储的线性表,使用随机的物理内存 存储逻辑上相连的数据。注意点:
1、 用q进行处理时q指向的就是实际链表的Node对象,因为q和node都是可变对象,这实际上是一种引用绑定,两者在赋值后指向同一个对象(Node)
2、 插入某个值时一定要先将下一个节点的位置给新节点保存,再将新节点的位置给前一个节点保存,顺序不可变。因为下一个节点的位置只有上一个节点知道,如果上一个节点先改为保存新的节点,下一个节点的位置就没有任何节点知道了。
"""class Node():"""1】 包含存储数据元素的数据域2】有一个存储下一个节点位置的位置域"""def __init__(self, data):self.data = data # 普通节点的数据域self.next = None # 普通节点的位置域class LinkedList():"""链表"""def __init__(self, node=None):self.size = 0 # 头节点的数据域self.head = node # 头节点的位置域,用于记录第一个节点的位置,可认为实际上就是下一个节点的整体(就通过next保存的位置来读取下一个Node整体),\# 不单单是位置,这个整体包含了下一个节点的下一个节点的位置和下一个节点的数据。def add_head(self, value):"""功能:将头插的方式插入到头节点的后面注意事项:1、插入成功链表长度自增。2、申请Node节点,封装:param:value:需要插入的节点的数据:return:"""node = Node(value) # 创建一个全新的节点node.next = self.head # 先将下一个节点的位置给新节点保存self.head = node # 再将节点作为第一个节点给seld.head保存self.size += 1def add_tail(self, value):"""功能:将一个新的节点插入到链表的尾部:param value::return:"""if self.is_empty():self.add_head(value) # 如果为空直接用add_headelse:q = self.head # 创建一个q用于寻找节点尾部的位置while q.next != None:q = q.nextq.next = Node(value) # 将找到的尾部None赋值为新的节点self.size += 1def add_index(self, index, value):"""通过q找到需要插入的位置冰进行处理,用q进行处理时q指向的就是实际链表的Node对象,因为q和node都是可变对象,这实际上是一种引用绑定,两者在赋值后指向同一个对象(Node):param value::param index::return:"""if index > self.size + 1 or index <= 0:returnelse:if index == 1:self.add_head(value)else:q = self.headi = 1while i < index - 1:q = q.nexti += 1node = Node(value)node.next = q.next # 先将新的next指向后面的node,否则后面的node的位置没有人记录链就断了(故此行代码不可与下行顺序调换)q.next = nodeself.size += 1def delete_head(self):"""删除第一个节点:return:"""if self.is_empty():returnelse:self.head = self.head.nextself.size -= 1def delete_tail(self):"""功能:尾删,删除最后一个节点:param value::return:"""# 判空if self.is_empty():print("删除失败")returnelif self.size == 1: # 当链表只有一个结点时self.head = Noneelse:# 找到最后一个结点的前一个节点q = self.headi = 1while i < self.size - 1:q = q.nexti += 1# 删除q.next = None # q.next = q.next.nextself.size -= 1def delete_index(self, index):"""通过q找到需要插入的位置冰进行处理,用q进行处理时q指向的就是实际链表的Node对象,因为q和node都是可变对象,这实际上是一种引用绑定,两者在赋值后指向同一个对象(Node):param value::param index::return:"""# 判空、判断位置是否合理if self.is_empty() or index > self.size or index <= 0:print("位置错误")returnelse:if index == 1: # 当索引为1时直接修改self.head.dataself.head = self.head.nextelse:q = self.head # 创建q用于寻找需要修改的节点i = 1while i < index - 1:q = q.nexti += 1q.next = q.next.nextself.size -= 1def change_index(self, index, value):"""按位置修改:param index::param value::return:"""if self.is_empty() or index > self.size or index <= 0:print("错误")returnelse:if index == 1: # 当索引为1时直接修改self.head.dataself.head.data = valueelse:q = self.head # 创建q用于寻找需要修改的节点i = 1 # i用于确定循环次数while i < index - 1:q = q.nexti += 1q.data = value # 对找到的节点进行赋值# 按值修改def change_value(self, o_value, n_value):""":param o_value::param n_value::return:"""if self.is_empty() or o_value == n_value:print("无需修改")returnelse:q = self.headwhile q:if q.data == o_value:q.data = n_valuereturnq = q.nextprint("查无此数据")def find_value(self, value):"""按值查找:param value::return:"""if self.is_empty():"链表为空空空空空空空空空"returnelse:q = self.headi = 1while i <= self.size:if q.data == value:return i + 1q = q.nexti += 1print("未找到数据") # 如果到最后还没有return说明没有该数据return Nonedef is_empty(self):return self.size == 0def show(self):"""从头到尾打印出节点的数据域中的数据,用q进行处理时q指向的就是实际链表的Node对象(但如果对q进行赋值则不是这样,那就是普通的赋值而已并不改变实际的Node),因为q和node都是可变对象,这实际上是一种引用绑定,两者在赋值后指向同一个对象(Node):return:"""if self.is_empty():returnelse:q = self.head # 此时self.head已经在add_head时指向了第一个Node,故可以进一步访问Node的data和下Node的next(即下一个Node)while q:print(q.data, end="->")q = q.nextprint() # 换行def reverse(self):"""思路:1、设置previous_node、current、next_node三个变量,目标是将current和previous_node逐步向后循环并逐步进行反转,知道所有元素都被反转2、但唯一的问题是:一旦current.next反转为向前,current的后继元素就将不再被记录3、所以设置一个next_node用于在反转开始前,current将后继元素赋值给next_node。4、开始反转5、反转后将current和previous_node向后移动一次,然后重复以上3-5步骤:return:"""previous_node = Nonecurrent = self.headwhile current:next_node = current.next # 记录下一个节点,因为等会current的next要反转了,先保存以免丢失current.next = previous_node # 反转节点previous_node = current # 移动previouscurrent = next_node # 移动next_node,由于next_node已经被记录,所以即使current.next变成了前面的元素,但后面的元素也能找到。# print(current.data, end="--->")self.head = previous_node # 最后把self.head补上def merge_sorted_lists(self, other_list):pre_size = self.size # 先记录一下排序之前的self.size,用于之后觉得执行头删操作的次数self.reverse()other_list.reverse()i = 0j = 0write = self.headq = self.head # 创建一个q用于寻找节点的位置p = other_list.head # 创建一个p用于寻找other节点的位置while write.next != None:write = write.nextwhile i < self.size and j < other_list.size:if q.data >= p.data:write.next = Node(q.data)write = write.nextq = q.nexti += 1else:write.next = Node(p.data)write = write.nextp = p.nextj += 1while j < other_list.size:write.next = Node(p.data)write = write.nextj += 1while i < self.size:write.next = Node(q.data)write = write.nexti += 1self.size=pre_size+other_list.sizefor i in range(pre_size):self.show()self.delete_head()self.reverse()if __name__ == '__main__':# 创建单向链表linkList = LinkedList()linkList.add_tail(10)linkList.add_tail(20)linkList.add_tail(30)linkList.add_tail(40)linkList.add_tail(50)linkList.add_tail(60)linkList_2 = LinkedList()linkList_2.add_tail(15)linkList_2.add_tail(25)linkList_2.add_tail(35)linkList_2.add_tail(45)linkList_2.add_tail(55)linkList_2.add_tail(65)linkList_2.add_tail(999)linkList_2.show()linkList.merge_sorted_lists(linkList_2)linkList.show()