GPU的barrier
目录
一、Barrier 的本质
二、GPU 架构中的 Barrier 实现
1. 硬件支持
2. Barrier 类型
三、Barrier 的工作原理(以 CUDA 为例)
四、Barrier 的资源开销:寄存器开销
五、Barrier 的关键应用场景
1. 共享内存同步
2. 数据归约
3. 生产者-消费者模式
六、Barrier 使用陷阱
1. 死锁(最常见错误)
2. 性能瓶颈
七、优化 Barrier 性能
1. 减少 Barrier 次数
2. 使用 Warp 级同步
3. 异步 Barrier(Hopper+)
八、总结
在 GPU 编程中,barrier(屏障) 是一种关键的线程同步机制,用于协调同一个线程组(如 CUDA 中的线程块、AMD 中的工作组)内多个线程的执行顺序。以下是 barrier 的全面解析:
一、Barrier 的本质
Barrier 是一个同步点,要求线程组内所有线程都到达此点后才能继续执行后续代码。其行为类似于现实中的集合点:
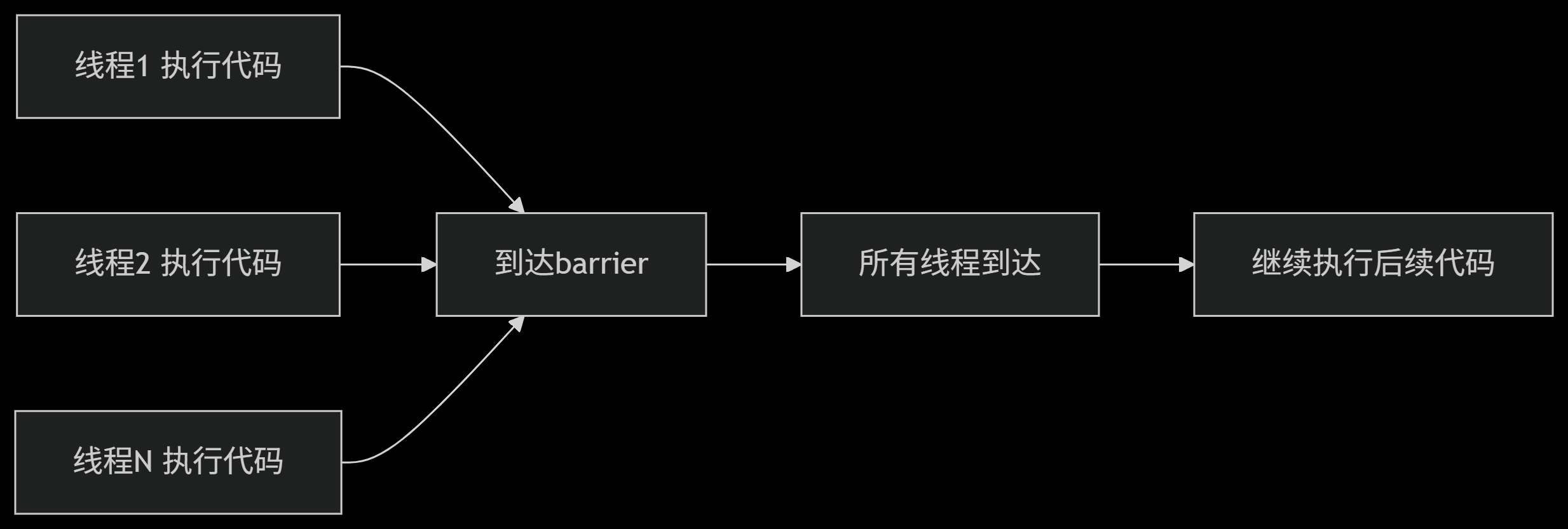
二、GPU 架构中的 Barrier 实现
1. 硬件支持
- 专用电路:现代 GPU 有专门的 barrier 执行单元
- 同步寄存器:每个线程使用 1-2 个寄存器存储 barrier 状态
- 信号网络:SM 内的线程通信网络(如 NVIDIA 的 Thread Block Comms Unit)
2. Barrier 类型
| 类型 | 范围 | 典型 API |
|---|---|---|
| Block-level | 线程块内 | CUDA: __syncthreads()HIP: __syncthreads() |
| Warp-level | Warp(32线程)内 | CUDA: __syncwarp()HIP: __builtin_amdgcn_wave_barrier() |
| Device-level | 全设备 | CUDA: Grid-wide sync (Hopper+) |
| System-level | 多 GPU | CUDA: cudaDeviceSynchronize() |
三、Barrier 的工作原理(以 CUDA 为例)
__global__ void kernel(int* data) {__shared__ int s_data[128];int tid = threadIdx.x;// 阶段1: 加载数据到共享内存s_data[tid] = data[tid];// Barrier 1: 确保所有线程完成加载__syncthreads(); // 所有线程停在这里等待// 阶段2: 跨线程处理int result = s_data[tid] + s_data[127-tid];// Barrier 2: 确保所有计算完成__syncthreads();data[tid] = result;
}# 硬件执行流程:
1. 线程到达 __syncthreads() 时:
- 设置状态寄存器(如 BAR.SYNC)
- 进入等待状态(停止取指令)
2. 当最后一个线程到达 barrier:
- 触发完成信号
- 清除所有线程的等待状态
3. 所有线程同时恢复执行
四、Barrier 的资源开销:寄存器开销
| 架构 | 每个 barrier 的寄存器开销 | 说明 |
|---|---|---|
| NVIDIA Pascal | 1 寄存器/线程 | 状态标志寄存器 |
| NVIDIA Volta+ | 2 寄存器/线程 | 状态寄存器 + 通信缓冲区 |
| AMD GCN/RDNA | 2 寄存器/线程 | 波前状态寄存器 |
| Intel Xe HPG | 1 寄存器/线程 | 子组同步寄存器 |
⚠️ 这就是为什么代码中需要扣除 HW_BARRIER_REGS_NEED:
五、Barrier 的关键应用场景
1. 共享内存同步
确保所有线程完成共享内存写入后再读取:
__shared__ float tile[256];tile[threadIdx.x] = input[globalIdx];__syncthreads(); // 必须同步!float neighbor = tile[threadIdx.x + 1];2. 数据归约
树状归约需多次同步:
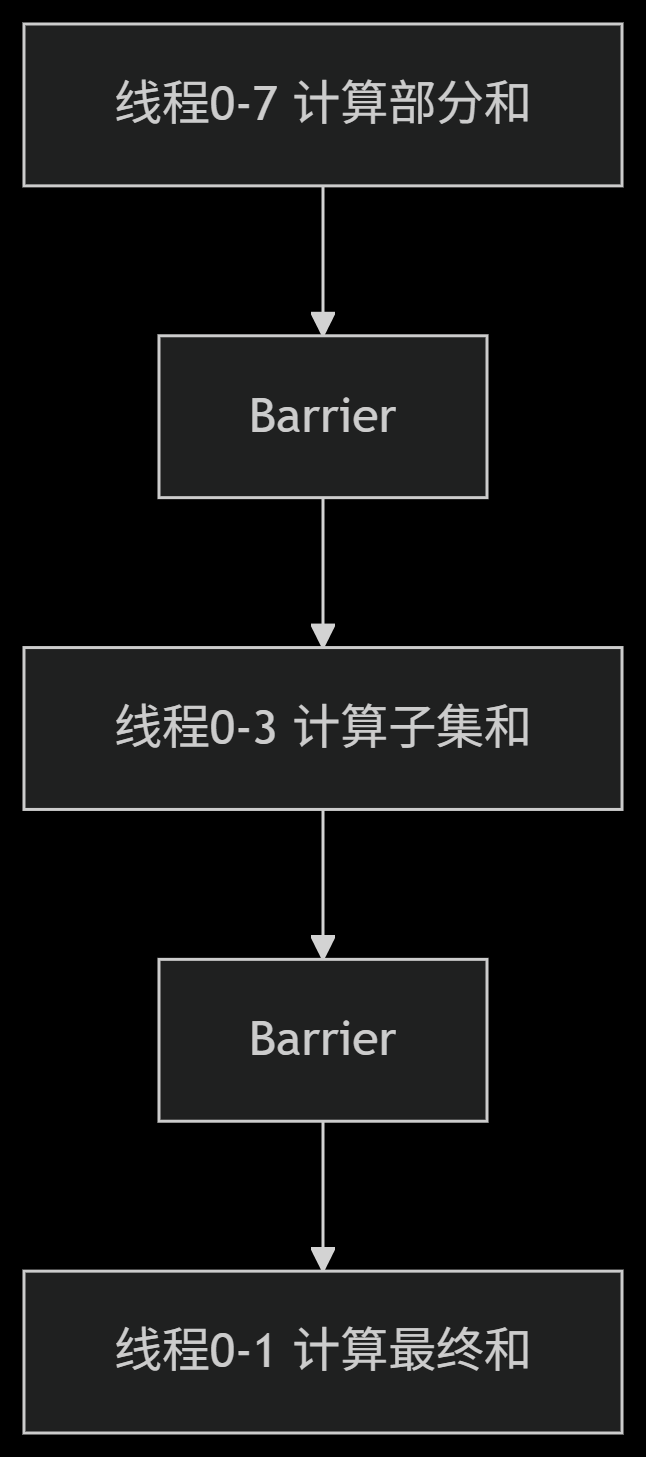
3. 生产者-消费者模式
协调不同线程的任务阶段:
if (threadIdx.x < 32) {// 生产者线程generate_data(shared_data);}__syncthreads(); // 生产完成if (threadIdx.x >= 32) {// 消费者线程consume_data(shared_data);}六、Barrier 使用陷阱
1. 死锁(最常见错误)
if (threadIdx.x < 128) {__syncthreads(); // 只有部分线程到达 → 死锁!}2. 性能瓶颈
不同执行路径导致线程等待时间不均:
if (threadIdx.x % 2 == 0) {heavy_computation(); // 慢路径} else {light_computation(); // 快路径}__syncthreads(); // 快线程在此空等3. 内存一致性
仅保证线程执行顺序,不保证内存可见性:
s_data[threadIdx.x] = value; // 写入共享内存__syncthreads();// 需要 __threadfence_block() 确保写入可见七、优化 Barrier 性能
1. 减少 Barrier 次数
合并相邻同步点:
- __syncthreads();// 少量计算- __syncthreads();+ // 合并计算+ __syncthreads();2. 使用 Warp 级同步
替代块级同步:
// 替代 __syncthreads()for (int offset = 16; offset > 0; offset /= 2) {if (lane_id < offset) {s_data[lane_id] += s_data[lane_id + offset];}__syncwarp(); // 仅同步 warp 内线程}3. 异步 Barrier(Hopper+)
重叠计算与同步:
__barrier_t bar;asm volatile ("bar.sync %0, 256;" : : "r"(bar));// 在等待期间执行独立计算八、总结
Barrier 是 GPU 并行的关键同步原语:
1. 硬件支持:专用电路实现高效同步
2. 资源开销:消耗额外寄存器(每线程 1-2 个)
3. 正确使用:避免死锁,确保内存一致性
4. 性能优化:减少次数、使用 warp 同步
5. 占用率影响:需在寄存器计算中考虑其开销
理解 barrier 的底层机制,对编写正确、高效的 GPU 代码至关重要。新一代 GPU(如 Hopper)通过异步 barrier 进一步提升了同步效率。