[2025CVPR-图象检索方向]CCIN:用于合成图像检索的合成冲突识别和中和模型
1. 任务背景和问题定义
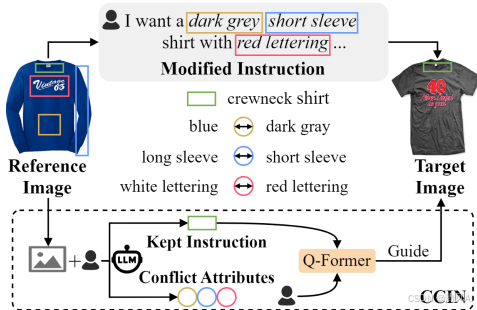
- Composed Image Retrieval (CIR)任务:CIR是一种多模态检索任务,旨在通过结合参考图像(reference image, Ir)和文本修改指令(modified instruction, Tmod)来检索目标图像(target image, It)。相比传统单模态检索(如图像或文本单独查询),CIR利用视觉和文本模态的互补性提升搜索灵活性。
- 核心挑战:组合冲突(Compositional Conflict):当参考图像的固有属性(如“蓝色长袖衬衫”)与修改指令(如“改为灰色短袖”)冲突时,会导致查询意图模糊,检索结果不准确。例如,冲突属性(如颜色、袖长)会使模型无法正确融合多模态特征,从而降低检索性能。
- 示例展示:Figure 1 展示了多模态查询中的冲突案例(如衬衫颜色、袖长等),这些冲突可能导致检索歧义。
- 现有方法的局限性:先前工作(如TG-CIR[45]和SSN[51])使用可学习掩码在特征层面抑制冲突,但特征空间的复杂性使冲突识别和中和难以精确控制,导致结果不可控。这凸显了需要更细粒度的冲突处理方法。
2. 提出的CCIN框架
CCIN框架通过序列化步骤识别和中和冲突,提升CIR性能。框架分为两个核心模块:
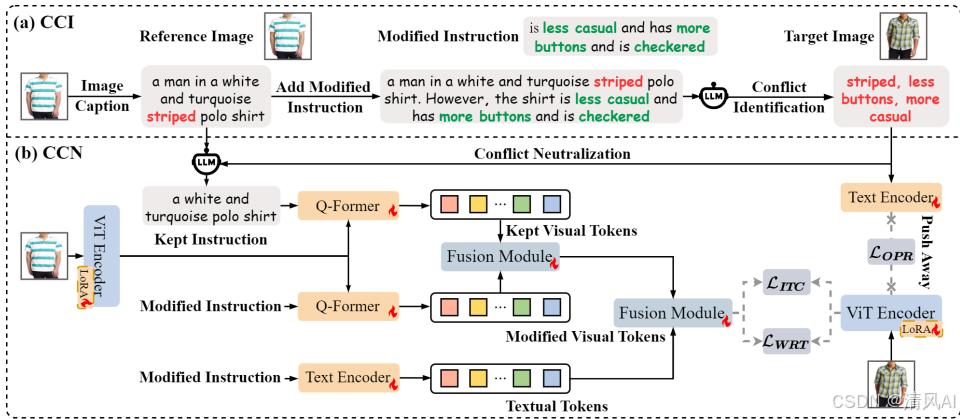
- Compositional Conflict Identification (CCI)模块:
- 功能:利用大型语言模型(LLM)精确识别冲突属性。首先,使用图像描述模型(如BLIP-2)生成参考图像的文本描述(Tref)。然后将Tref和Tmod结合(用“However”连接),输入LLM(如GPT-4)分析冲突属性(Tcon)。
- 公式表示:Tcon=Pcon→LLM(Tref+ However+Tmod),其中Pcon是自定义提示(见Figure 3)。
- 优势:显式识别具体冲突属性(如颜色或袖长),避免特征空间的模糊性。
- Compositional Conflict Neutralization (CCN)模块:
- 功能:使用双重指令(dual-instruction)机制中和冲突。首先,LLM基于Tref和Tcon生成保留指令(kept instruction, Tkep),仅保留非冲突属性。然后,结合Tkep和Tmod,通过Q-Former(基于InstructBLIP[11])提取指令感知的视觉特征:
- fkep=Tkep→FQ(Ir):保留参考图像的非冲突特征。
- fmod=Tmod→FQ(Ir):根据修改指令调整特征。
- 架构展示:Figure 2 展示了CCIN整体结构,包括CCI和CCN的协同工作。
- 功能:使用双重指令(dual-instruction)机制中和冲突。首先,LLM基于Tref和Tcon生成保留指令(kept instruction, Tkep),仅保留非冲突属性。然后,结合Tkep和Tmod,通过Q-Former(基于InstructBLIP[11])提取指令感知的视觉特征:
-
- 自适应融合模块:使用MLP和Sigmoid函数加权融合特征:
- θ1=Sigmoid(MLP(fkep,fmod))
- fneu=θ1⋅fkep+(1−θ1)⋅fmod
- 最终查询表示:fquery=θ2⋅fneu+(1−θ2)⋅ft(ft为文本特征)。
- 自适应融合模块:使用MLP和Sigmoid函数加权融合特征:
- 损失函数:总损失Ltotal=LITC+LOPR+λLWRT,包括:
- 图像-文本对比损失(\mathcal{L}_{\text{ITC}}})。
- 加权正则化三元组损失(\mathcal{L}_{\text{WRT}}}),基于相对距离区分正负样本。
- 正交投影正则化损失(\mathcal{L}_{\text{OPR}}}),扩大冲突信息与目标图像的差异。
3. 实验验证
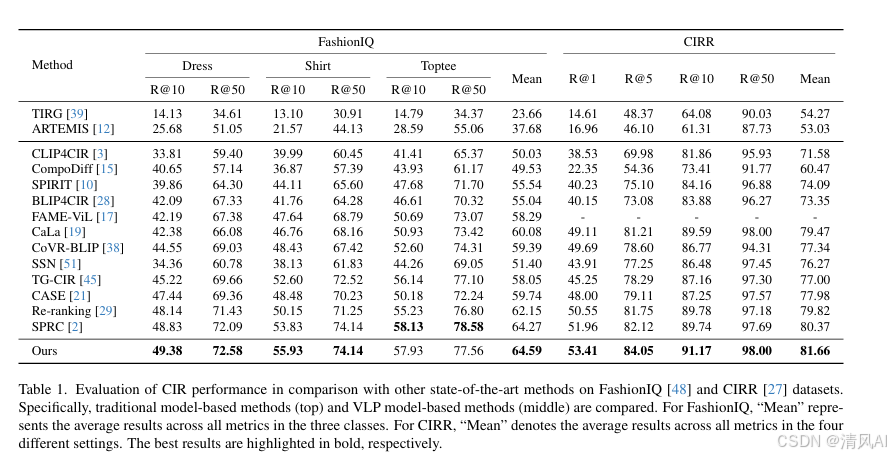
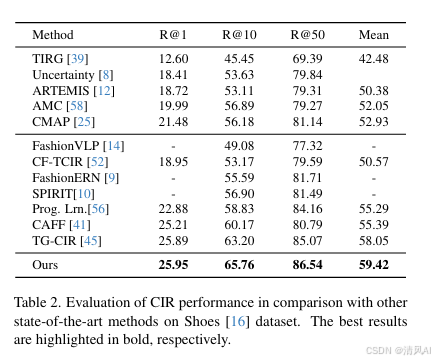
实验在三个标准数据集进行:FashionIQ[48]、CIRR[27]和Shoes[16]。使用Recall@K(R@K)作为主要指标。
- 数据集描述:
- FashionIQ:77,684张时尚图像,30,134个三元组(参考图像、目标图像、修改指令),类别包括Dress、Shirt和Toptee。
- CIRR:21,552张真实世界图像,36,554个三元组,减少假阴性问题。
- Shoes:14,600张鞋类图像,用于属性发现和CIR任务。
- 主要结果:
- 与SOTA方法比较:CCIN在FashionIQ、CIRR和Shoes上均超越现有方法(如SPRC[2]、TG-CIR[45])。例如:
- FashionIQ:R@10和R@50平均值达64.59%,优于SPRC的64.27%(Table 1)。
- CIRR:R@1达53.41%,优于Re-ranking[29]的50.55%(Table 1)。
- Shoes:平均R@K达59.42%,优于TG-CIR的58.05%(Table 2)。
- 定性分析:Figure 4 展示CCIN与SPRC的对比案例。CCIN能有效中和冲突(如袖长和图案),正确检索目标图像,而SPRC因冲突导致错误预测。
- 与SOTA方法比较:CCIN在FashionIQ、CIRR和Shoes上均超越现有方法(如SPRC[2]、TG-CIR[45])。例如:

消融研究:
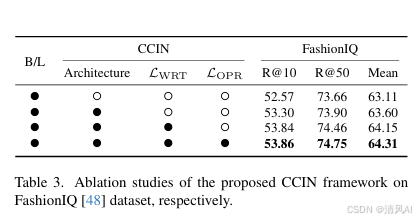
- 框架组件分析(Table 3):移除CCIN架构导致性能下降(平均R@50从74.75%降至73.66%)。损失函数LWRT和LOPR进一步提升性能。
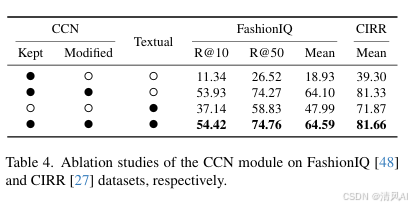
- CCN模块分析(Table 4):双重指令(Tkep和Tmod)比单一指令更有效(平均R@10 54.42% vs. 53.93%)。移除视觉特征严重降低性能。
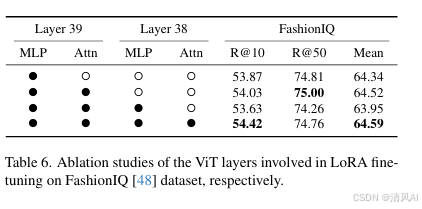
- LoRA微调分析(Table 6):在ViT骨干网的39层进行LoRA微调(MLP和Attention)优化性能,但过度微调可能导致过拟合。
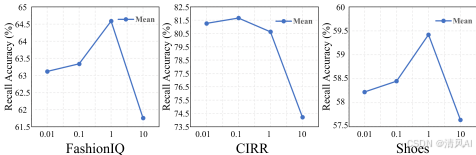
- 超参数分析:Figure 5 显示λ(控制损失权重)的影响。最优值因数据集而异(FashionIQ: λ=1, CIRR: λ=0.1, Shoes: λ=1)。
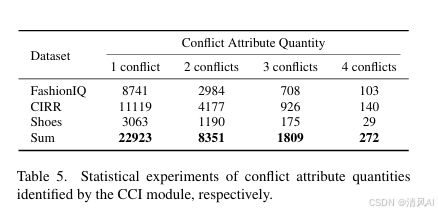
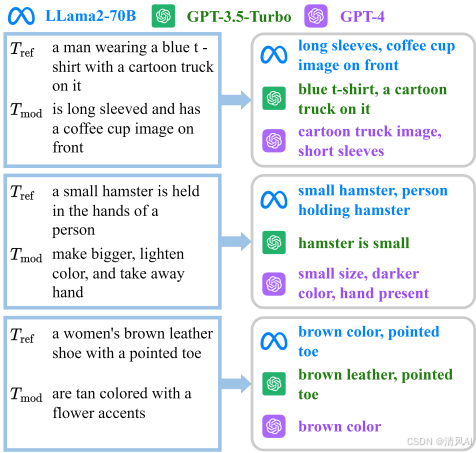
冲突识别分析:CCI模块有效识别冲突属性(Table 5)。例如,FashionIQ中29.1%查询有2个以上冲突。Figure 6 和7 展示LLM(如GPT-4)在冲突识别中的优越性(vs. LLama2-70B和GPT-3.5)。

4. 贡献和结论
- 主要贡献:
- 首次系统化解决了CIR中的组合冲突问题,提出可控制的识别和中和机制。
- 设计了CCIN框架,结合LLM的显式冲突分析和双重指令的特征提取,提升检索精度。
- 实验证明在多个数据集上显著优于SOTA方法,平均性能提升达2.44%(FashionIQ)。
- 结论:CCIN通过序列化冲突处理(识别→中和)解决了CIR的关键瓶颈。未来工作将探索多模态LLM(如GPT-4o)和更多输入模态(如草图)以扩展任务范围。
- 代码可用性:代码库公开于https://github.com/LikaiTian/CCIN。
论文: https://openaccess.thecvf.com/content/CVPR2025/papers/Tian_CCIN_Compositional_Conflict_Identification_and_Neutralization_for_Composed_Image_Retrieval_CVPR_2025_paper.pdf