【论文阅读 | PR 2024 |ITFuse:一种用于红外与可见光图像融合的交互式 Transformer】
论文阅读 | PR 2024 |ITFuse:一种用于红外与可见光图像融合的交互式 Transformer
- 1.摘要&&引言
- 2.方法
- 2.1 问题表述
- 2.2 框架概述
- 2.3 特征交互模块
- 2.4 特征重建模块
- 2.5 损失函数
- 3. 实验
- 3.1 数据集和实现细节
- 3.2 对比方法和评估指标
- 3.3 结果与讨论
- 3.3.1 在 TNO 数据集上的结果
- 3.3.2 在 RoadScene 数据集上的结果
- 3.4 消融研究
- 3.4.1 关于网络架构的消融研究
- 3.4.2 关于损失函数的消融研究
- 3.5 泛化实验
- 3.5.1 在 KAIST 数据集上的泛化实验
- 3.5.2 在 M3FD 数据集上的泛化实验
- 3.6 效率比较
- 4. 结论

题目:ITFuse: An interactive transformer for infrared and visible image fusion
会议:Pattern Recognition(PR)
论文:https://www.sciencedirect.com/science/article/pii/S0031320324005739?via%3Dihub
代码:https://github.com/tthinking/ITFuse
年份:2024
1.摘要&&引言
红外与可见光图像融合(IVIF)因其在下游应用中令人满意的结果而受到学术界越来越多的关注。
然而,大多数现有的深度融合模型要么是特征级融合,要么是图像级融合,导致信息丢失。
在本文中,我们提出了一种用于 IVIF 的交互式 Transformer,称为 ITFuse。
与以往算法不同,ITFuse 由特征交互模块(FIMs)和特征重建模块(FRM)组成,交替提取和整合重要特征。具体而言,为了充分利用不同源图像的共同属性,我们设计了残差注意力块(RAB)用于 mutual 特征表示。为了聚合相应输入图像中存在的独特特征,我们利用交互注意力(ITA)来整合互补信息,以实现全面的特征保留和交互。
此外,跨模态注意力(CMA)和 Transformer 块(TRB)用于充分融合所提取的特征并构建长距离关系。此外,我们设计了像素损失和结构损失,以无监督方式训练所提出的深度融合模型,从而进一步提升性能。
本文的主要贡献总结如下。
- 我们提出了一种用于 IVIF 的端到端交互式 Transformer(名为 ITFuse),其中设计了交互注意力(ITA)和残差注意力块(RAB),以选择性地提取个体特征并保留共同信息,从而实现充分的互补特征保留。
- 我们提出了跨模态注意力(CMA)和 Transformer 块(TRB),以充分整合所提取的特征并构建多模态长距离关系,从而获得良好的性能。
- 我们设计了像素损失和结构损失,以无监督方式训练 ITFuse,从而进一步提升性能。

2.方法
2.1 问题表述
考虑到 IVIF(红外-可见光融合)的基本目标,即提取互补信息以生成信息丰富的合成融合图像,我们的模型基于以交互方式保留来自各个模态的同质和异质特征,以实现充分的重要信息挖掘和交互。具体而言:
-
红外图像提供的信息表示为:
Fir=Firu+Fc\mathbb{F}_{ir}=\mathbb{F}_{ir}^{u}+\mathbb{F}_{c}Fir=Firu+Fc
其中 Firu\mathbb{F}_{ir}^{u}Firu 表示红外图像的独特特征(反映物体的热辐射信息),Fc\mathbb{F}_{c}Fc 表示红外与可见光图像共享的共同特征(如形状、边缘)。 -
可见光图像包含的信息表示为:
Fvi=Fviu+Fc\mathbb{F}_{vi}=\mathbb{F}_{vi}^{u}+\mathbb{F}_{c}Fvi=Fviu+Fc
其中 Fviu\mathbb{F}_{vi}^{u}Fviu 表示可见光图像的独特特征(如场景的纹理细节)。 -
红外与可见光图像融合得到的合成图像(同时具有清晰的物体和明确的场景)表示为:
Ff=Firu+Fviu+Fc\mathbb{F}_{f}=\mathbb{F}_{ir}^{u}+\mathbb{F}_{vi}^{u}+\mathbb{F}_{c}Ff=Firu+Fviu+Fc
因此,从不同模态中充分挖掘重要特征是关键。通过研究不同模态图像的内在特性,我们设计了交互式 Transformer 以解决这一挑战。
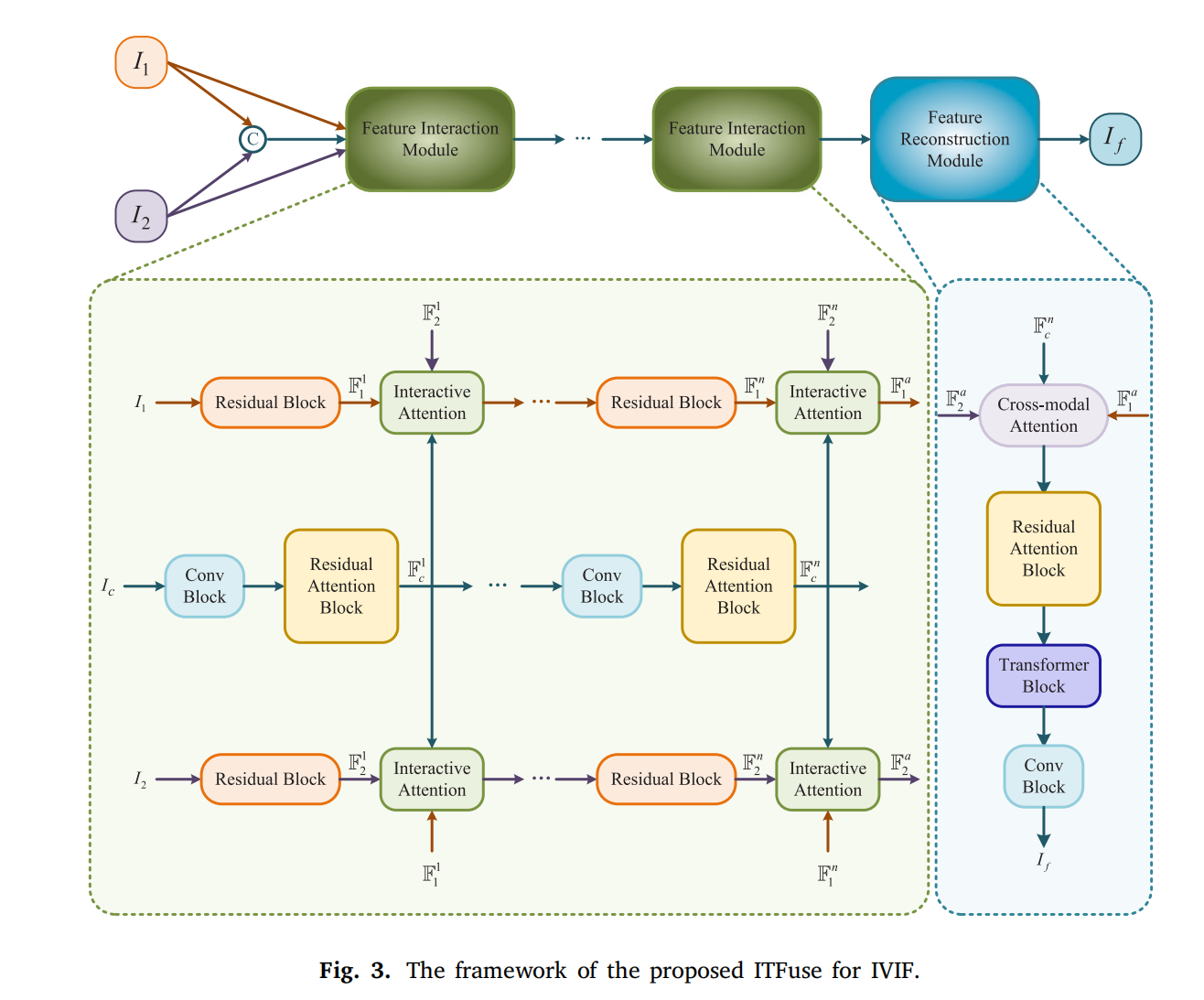
2.2 框架概述
所提出的 ITFuse 框架如图 3 所示。输入图像 I1I_{1}I1 和 I2I_{2}I2 被送入 NNN 个特征交互模块(FIMs)进行互补信息提取与整合,随后通过特征重建模块(FRM)生成融合结果 IfI_{f}If。具体流程如下:
- 特征提取:为捕获不同模态的独特特征,I1I_{1}I1 和 I2I_{2}I2 分别输入 FIM。FIM 可准确保留各模态的独特特征。
- 特征交互:对 I1I_{1}I1 和 I2I_{2}I2 进行通道拼接后输入 FIM,以挖掘输入图像的共同属性。共同特征与独特特征并非单独提取,而是通过交互注意力(ITA)动态交互,从而挖掘更多上下文信息(而非直接构建二维特征图的自注意力)。
2.3 特征交互模块
IVIF 的核心目标是聚合多模态重要特征,因此特征提取对融合结果至关重要。针对多模态特性,我们提出由 I1I_{1}I1 分支、IcI_{c}Ic 分支(共同特征提取)和 I2I_{2}I2 分支组成的特征交互模块,以交互方式挖掘共同特征与独特特征(而非单独或统一提取)。
2.3.1 共同特征提取分支(IcI_{c}Ic 分支)
为充分挖掘输入图像的同质属性,I1I_{1}I1 和 I2I_{2}I2 经通道拼接后输入 IcI_{c}Ic 分支(由卷积块 CB 和残差注意力块 RAB 组成):
- 卷积块(CB):用于浅层特征提取,包含两个连续卷积层,公式为:
Fcbo=R(B(C3C→C(R(B(C32→C(Fcbi))))))\mathbb{F}_{cb}^{o}=\mathcal{R}\left(\mathcal{B}\left(C_{3}^{C \to C}\left(\mathcal{R}\left(\mathcal{B}\left(C_{3}^{2 \to C}\left(\mathbb{F}_{cb}^{i}\right)\right)\right)\right)\right)\right)Fcbo=R(B(C3C→C(R(B(C32→C(Fcbi))))))
其中 Fcbi\mathbb{F}_{cb}^{i}Fcbi 和 Fcbo\mathbb{F}_{cb}^{o}Fcbo 分别为 CB 的输入和输出特征;Ckc1→c2(⋅)C_{k}^{c_{1} \to c_{2}}(\cdot)Ckc1→c2(⋅) 表示 k×kk \times kk×k 卷积(输入通道 c1c_{1}c1,输出通道 c2c_{2}c2);B(⋅)\mathcal{B}(\cdot)B(⋅) 为批归一化,R(⋅)\mathcal{R}(\cdot)R(⋅) 为整流线性单元(ReLU)。
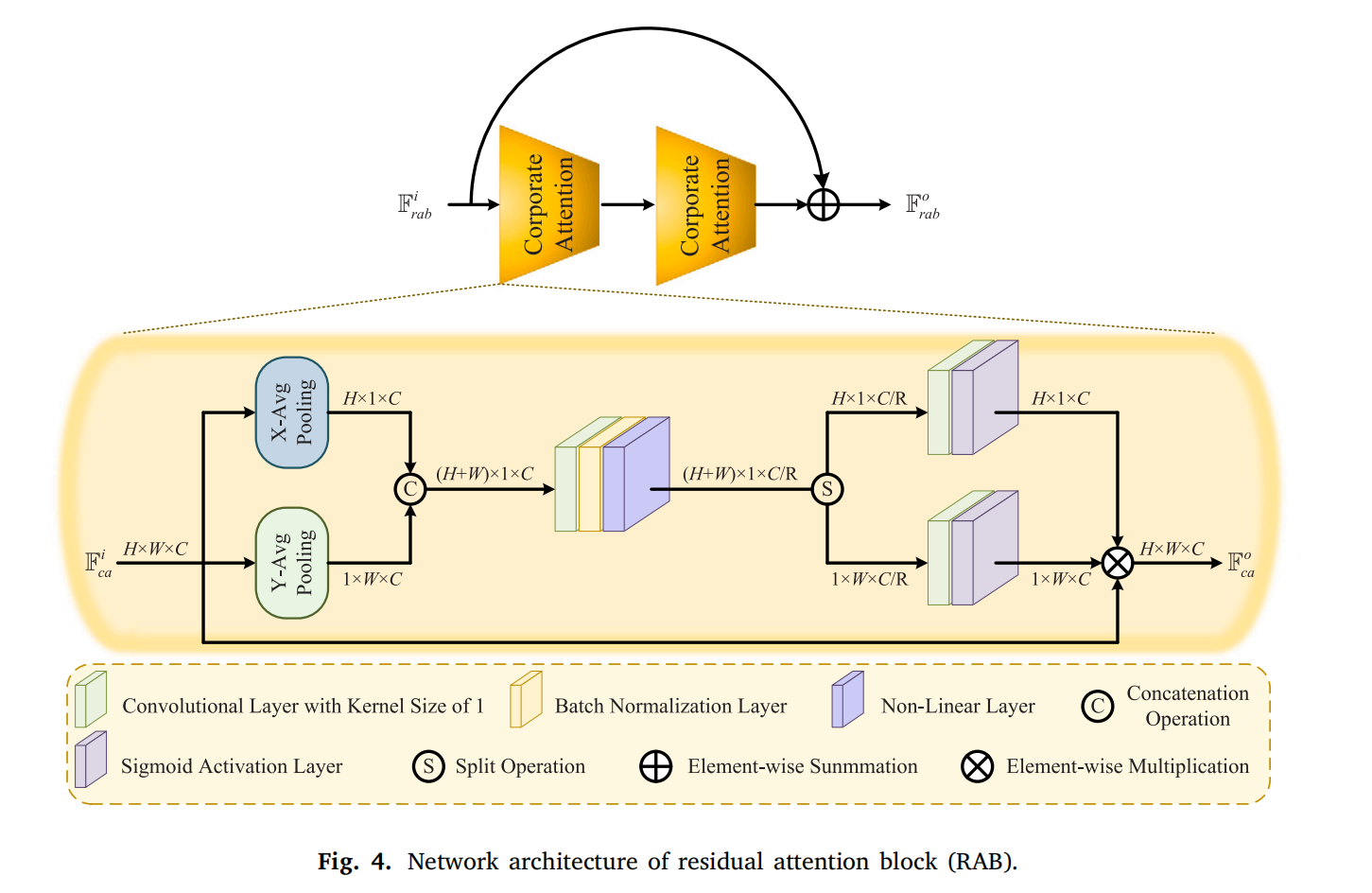
-
残差注意力块(RAB):用于强调红外与可见光共享的重要特征,包含两个协同注意力(CA)残差排列,以非平凡方式提取特征。受 [33] 启发,RAB 从水平和垂直方向构建注意力图:
- 对 CA 输入特征 Fcai∈RH×W×C\mathbb{F}_{ca}^{i} \in \mathbb{R}^{H \times W \times C}Fcai∈RH×W×C 同时进行 X 方向(池化核 (H,1)(H, 1)(H,1))和 Y 方向(池化核 (1,W)(1, W)(1,W))平均池化;
- 拼接双向池化特征后输入卷积层,输出为:
Fclo=N(B(C1C→C/R(Fcli)))\mathbb{F}_{cl}^{o}=\mathcal{N}\left(\mathcal{B}\left(C_{1}^{C \to C / R}\left(\mathbb{F}_{cl}^{i}\right)\right)\right)Fclo=N(B(C1C→C/R(Fcli)))
其中 Fcli∈R(H+W)×1×C\mathbb{F}_{cl}^{i} \in \mathbb{R}^{(H+W) \times 1 \times C}Fcli∈R(H+W)×1×C(输入),Fclo∈R(H+W)×1×C/R\mathbb{F}_{cl}^{o} \in \mathbb{R}^{(H+W) \times 1 \times C/R}Fclo∈R(H+W)×1×C/R(输出),RRR 为缩减比,N(⋅)\mathcal{N}(\cdot)N(⋅) 为非线性层(计算为 Fnlo=Fnli×S(Fnli)\mathbb{F}_{nl}^{o}=\mathbb{F}_{nl}^{i} \times S\left(\mathbb{F}_{nl}^{i}\right)Fnlo=Fnli×S(Fnli),S(⋅)S(\cdot)S(⋅) 为 sigmoid 激活函数)。
随后,Fnlo\mathbb{F}_{nl}^{o}Fnlo 分割为 Fx∈RH×1×C/R\mathbb{F}_{x} \in \mathbb{R}^{H \times 1 \times C/R}Fx∈RH×1×C/R 和 Fy∈R1×W×C/R\mathbb{F}_{y} \in \mathbb{R}^{1 \times W \times C/R}Fy∈R1×W×C/R,分别输入卷积层得到 Fxo=S(C1C/R→C(Fx))\mathbb{F}_{x}^{o}=S\left(C_{1}^{C/R \to C}\left(\mathbb{F}_{x}\right)\right)Fxo=S(C1C/R→C(Fx)) 和 Fyo=S(C1C/R→C(Fy))\mathbb{F}_{y}^{o}=S\left(C_{1}^{C/R \to C}\left(\mathbb{F}_{y}\right)\right)Fyo=S(C1C/R→C(Fy))(与 Fcai\mathbb{F}_{ca}^{i}Fcai 通道数一致)。最终,Fxo\mathbb{F}_{x}^{o}Fxo、Fyo\mathbb{F}_{y}^{o}Fyo 与 Fcai\mathbb{F}_{ca}^{i}Fcai 相乘得到 Fcao\mathbb{F}_{ca}^{o}Fcao。
2.3.2 独特特征提取分支(I1I_{1}I1、I2I_{2}I2 分支)
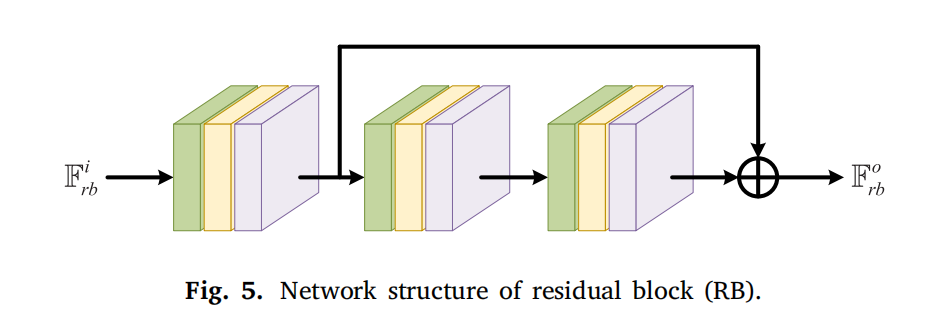
为挖掘各模态独特特征,I1I_{1}I1 和 I2I_{2}I2 分别输入独立分支(含残差块 RB 和交互注意力 ITA)。RB 用于挖掘浅层内在属性,如图 5 所示,由三个带跳跃连接的卷积层组成(每个层含 3×3 卷积、BN 和 ReLU)。源图像的典型特征通过 ITA 动态交互(而非单独利用),ITA 受 [34] 启发,设计为动态关注上下文信息(而非直接构建二维特征图的自注意力)。
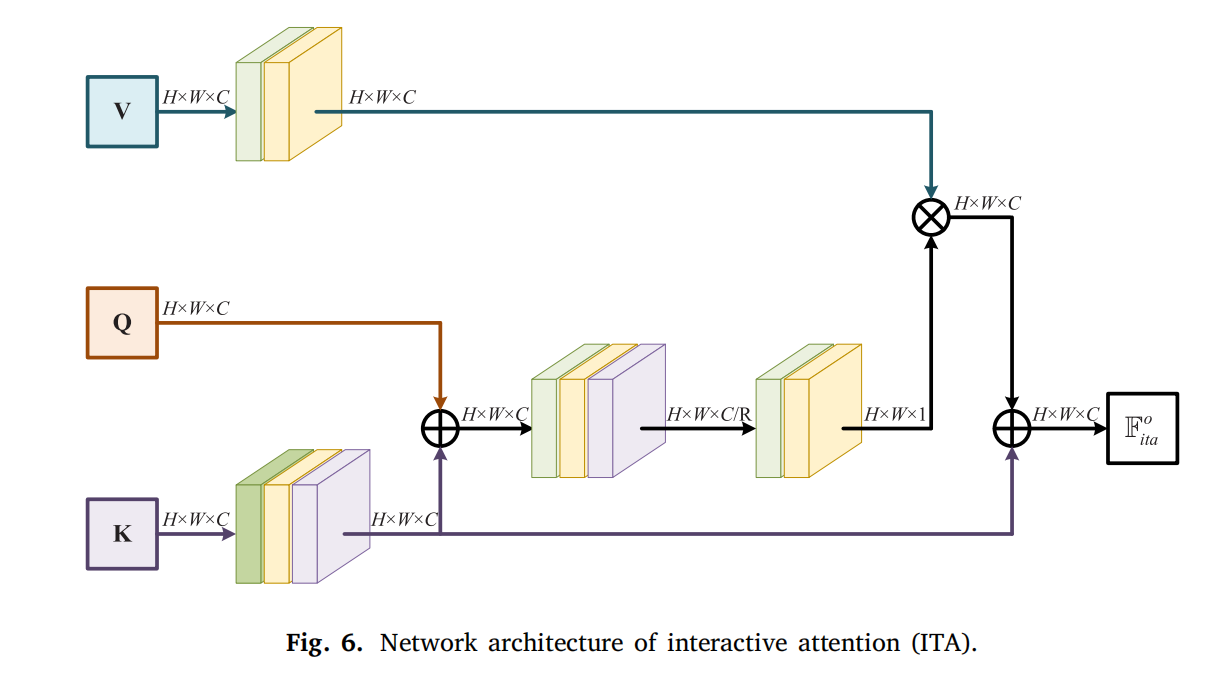
具体地,对 FK\mathbb{F}_{K}FK(对应 I1I_{1}I1 分支的 F1i\mathbb{F}_{1}^{i}F1i 和 I2I_{2}I2 分支的 F2i\mathbb{F}_{2}^{i}F2i)采用 3×3 卷积编码为单模态静态上下文信息;FV\mathbb{F}_{V}FV(表示 IcI_{c}Ic 分支的 Fci\mathbb{F}_{c}^{i}Fci)通过 1×1 卷积编码为共同特征。随后,FK\mathbb{F}_{K}FK 与 FCo\mathbb{F}_{Co}FCo(I1I_{1}I1 分支的 F2i\mathbb{F}_{2}^{i}F2i 和 I2I_{2}I2 分支的 F1i\mathbb{F}_{1}^{i}F1i)元素级求和,经两个 1×1 卷积构建动态注意力矩阵 FD\mathbb{F}_{D}FD。FV\mathbb{F}_{V}FV 与 FD\mathbb{F}_{D}FD 相乘实现多模态综合表示,最终 ITA 输出 Fita\mathbb{F}_{ita}Fita 通过 FK\mathbb{F}_{K}FK 与相乘特征的加和整合静态与动态信息:
Fitao=(FD×FV)+FK\mathbb{F}_{ita}^{o}=\left(\mathbb{F}_{D} × \mathbb{F}_{V}\right)+\mathbb{F}_{K}Fitao=(FD×FV)+FK
通过上述模块,可动态交互挖掘多模态的同质与异质属性。
2.4 特征重建模块
为将潜在空间的特征重建为融合结果,设计特征重建模块(FRM),包含跨模态注意力(CMA)、残差注意力块(RAB)、Transformer 块(TRB)和卷积块(CB)。
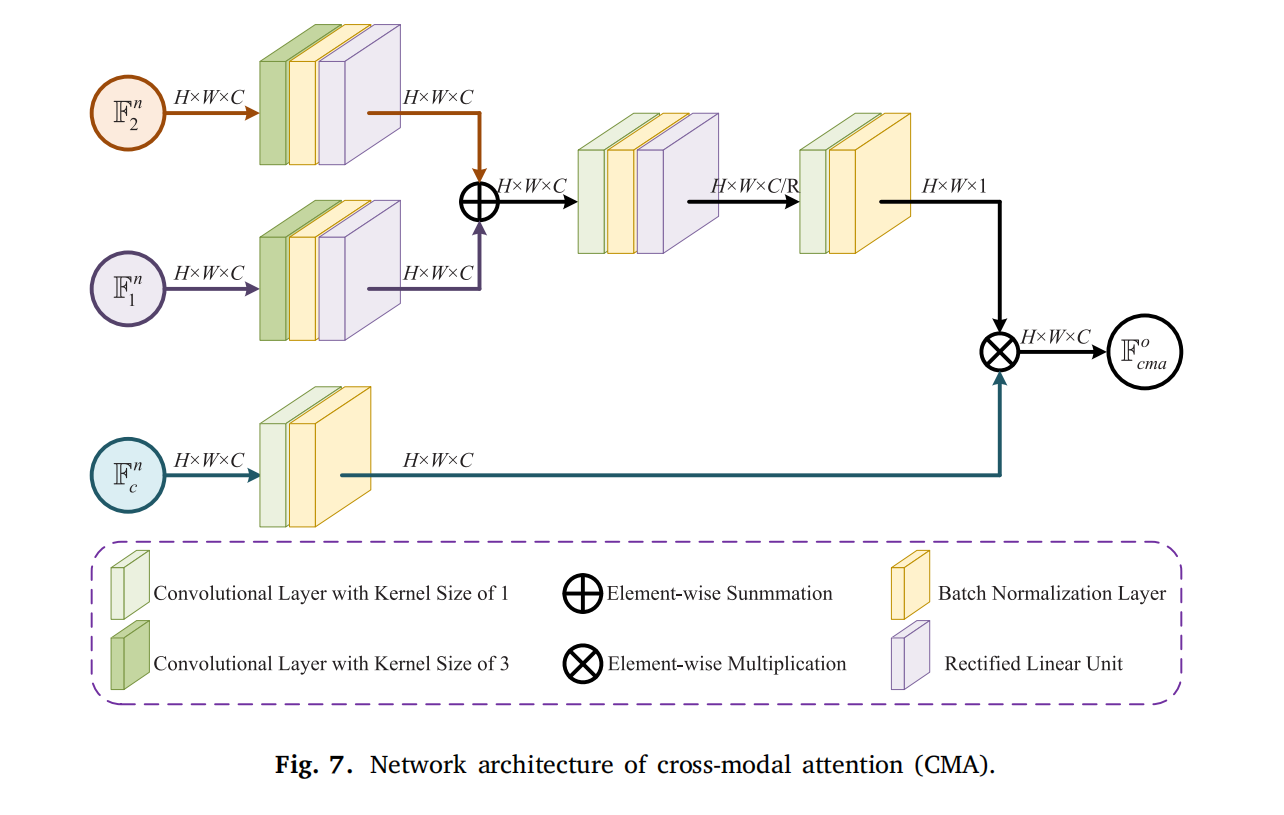
-
CMA:整合 I1I_{1}I1、IcI_{c}Ic、I2I_{2}I2 分支的挖掘特征(F1n\mathbb{F}_{1}^{n}F1n、Fcn\mathbb{F}_{c}^{n}Fcn、F2n\mathbb{F}_{2}^{n}F2n)。F1n\mathbb{F}_{1}^{n}F1n 和 F2n\mathbb{F}_{2}^{n}F2n 经 3×3 卷积编码为独特静态特征,相加后经两个卷积层生成独特动态属性;Fcn\mathbb{F}_{c}^{n}Fcn 经 1×1 卷积保留共同特征。最终,独特动态特征与共同特征相乘得到整合特征 Fcmao\mathbb{F}_{cma}^{o}Fcmao(保留重要特征,过滤冗余)。
-
RAB:对 CMA 整合的特征从水平和垂直方向重建表示。
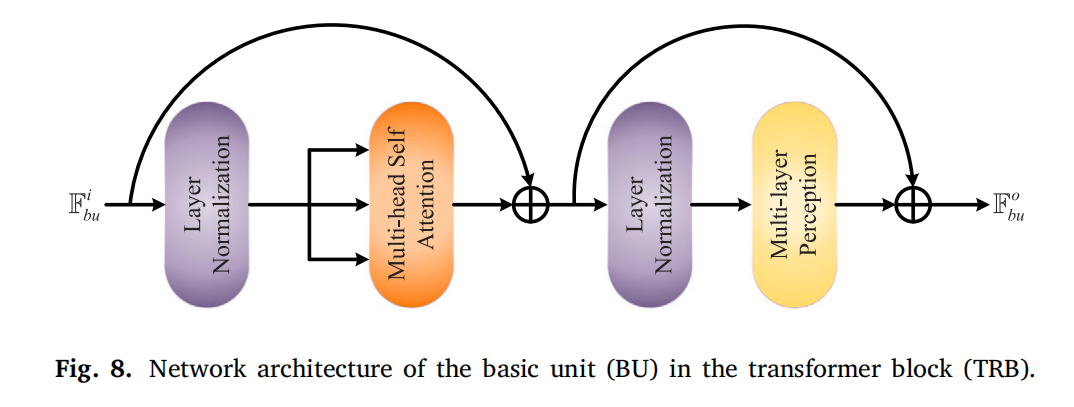
-
TRB:由 LLL 个基本单元(BUs)组成,每个 BU 包含两个加法操作:
- 第一个操作:FA=M(Y(Fbui))+Fbui\mathbb{F}_{A}=\mathcal{M}\left(\mathcal{Y}\left(\mathbb{F}_{bu}^{i}\right)\right)+\mathbb{F}_{bu}^{i}FA=M(Y(Fbui))+Fbui(M(⋅)\mathcal{M}(\cdot)M(⋅) 为多头自注意力,Y(⋅)\mathcal{Y}(\cdot)Y(⋅) 为层归一化);
- 第二个操作:Fbuo=P(Y(FA))+FA\mathbb{F}_{bu}^{o}=\mathcal{P}\left(\mathcal{Y}\left(\mathbb{F}_{A}\right)\right)+\mathbb{F}_{A}Fbuo=P(Y(FA))+FA(P(⋅)\mathcal{P}(\cdot)P(⋅) 为多层感知机)。
TRB 通过上述操作构建长距离依赖关系。
-
CB:对 TRB 输出特征经 3×3 卷积和 1×1 卷积生成最终融合图像 IfI_{f}If:
If=S(C1C→1(R(B(C3C→C(Ftrb)))))I_{f}=S\left(C_{1}^{C \to 1}\left(\mathcal{R}\left(\mathcal{B}\left(C_{3}^{C \to C}\left(\mathbb{F}_{trb}\right)\right)\right)\right)\right)If=S(C1C→1(R(B(C3C→C(Ftrb)))))
2.5 损失函数
由于 IVIF 无 ground truth,设计像素损失 LpL_{p}Lp 和结构损失 LsL_{s}Ls 以无监督方式训练模型,总损失为:
LITFuse=Lp+LsL_{ITFuse}=L_{p}+L_{s}LITFuse=Lp+Ls
-
像素损失 LpL_{p}Lp:确保融合结果与源图像像素属性相似,计算为:
Lp=Lcp1+Lcp2L_{p}=L_{cp}^{1}+L_{cp}^{2}Lp=Lcp1+Lcp2
其中 LcpzL_{cp}^{z}Lcpz 为 Charbonnier 惩罚函数:
Lcpz=(If−Iz)2+ε2L_{cp}^{z}=\sqrt{\left(I_{f}-I_{z}\right)^{2}+\varepsilon^{2}}Lcpz=(If−Iz)2+ε2(ε\varepsilonε 为惩罚系数)。 -
结构损失 LsL_{s}Ls:引导融合图像与输入图像结构分布相似,计算为:
Ls=Ls1+Ls2L_{s}=L_{s}^{1}+L_{s}^{2}Ls=Ls1+Ls2
其中 LszL_{s}^{z}Lsz 为结构相似性度量:
Lsz=1−(2μzμf+C1)(2σzf+C2)(μz2+μf2+C1)(σz2+σf2+C2)L_{s}^{z}=1-\frac{\left(2 \mu_{z} \mu_{f}+C_{1}\right)\left(2 \sigma_{z f}+C_{2}\right)}{\left(\mu_{z}^{2}+\mu_{f}^{2}+C_{1}\right)\left(\sigma_{z}^{2}+\sigma_{f}^{2}+C_{2}\right)}Lsz=1−(μz2+μf2+C1)(σz2+σf2+C2)(2μzμf+C1)(2σzf+C2)
(μz\mu_{z}μz、μf\mu_{f}μf 为平均强度;σzf\sigma_{zf}σzf 为协方差;σz2\sigma_{z}^{2}σz2、σf2\sigma_{f}^{2}σf2 为方差;C1C_{1}C1、C2C_{2}C2 为常数)。
总损失可重表示为:
LITFuse=α⋅Lcp1+β⋅Lcp2+γ⋅Ls1+λ⋅Ls2L_{ITFuse}=\alpha \cdot L_{cp}^{1}+\beta \cdot L_{cp}^{2}+\gamma \cdot L_{s}^{1}+\lambda \cdot L_{s}^{2}LITFuse=α⋅Lcp1+β⋅Lcp2+γ⋅Ls1+λ⋅Ls2
(α\alphaα、β\betaβ、γ\gammaγ、λ\lambdaλ 为权重参数,控制各项权衡)。
3. 实验
3.1 数据集和实现细节
在本文中,训练、测试和验证数据集基于 TNO [1] 和 RoadScene [11] 数据库构建。具体而言,下载了 348 对源图像,并随机分为包含 288 对图像的训练集、包含 40 对图像的测试集和包含 20 对图像的验证集。为获得足够的训练样本,将训练集中的图像裁剪为 120×120 像素(裁剪步长为 20),最终获得 58708 对图像块,并归一化到 [0,1]。所有实验均在配备 NVIDIA GeForce RTX 3090 GPU 的设备上使用 PyTorch 框架实现,采用 Adam 优化器 [37] 更新参数(学习率 0.0003,批处理大小 64,总 epoch 数 20)。超参数设置如下:N=3N=3N=3(特征交互模块数量)、C=16C=16C=16(卷积块通道数)、R=4R=4R=4(残差注意力块缩减比)、L=3L=3L=3(Transformer 块数量),ε=0.001\varepsilon=0.001ε=0.001(Charbonnier 惩罚系数)。对于 3×3 卷积,步长和填充均为 1,采用 “replicate” 边界模式。权重参数 α=1\alpha=1α=1、β=1\beta=1β=1、γ=4\gamma=4γ=4、λ=4\lambda=4λ=4(控制像素损失、结构损失的权衡)。
3.2 对比方法和评估指标
将提出的 ITFuse 与以下方法对比:
- 传统方法:GTF [5](基于多尺度变换);
- 深度学习方法:FusionGAN [6](生成对抗网络)、U2Fusion [11](多模态融合网络)、GANMcC [42](基于生成对抗网络的融合)、RFN-Nest [17](残差特征网络)、AUIF [43](自适应交互融合)、TarDAL [20](基于Transformer的跨模态对齐)、UNFusion [18](无监督融合);
- Transformer方法:SwinFuse [7](基于Swin Transformer)、CMTFusion [30](基于交叉注意力机制)。
所有对比算法的代码均为公开可用或由作者提供,参数设置遵循原始文献以保公平性。
定量评估采用五种指标:
- Tsallis 熵 QTEQ_{TE}QTE [38]:衡量源图像与融合结果的依赖程度,聚焦边缘信息保留,值越高表示融合结果边缘保留越好;
- Chen-Varshney 指标 QCVQ_{CV}QCV [39]:符合人类视觉系统,通过纹理和细节评估视觉自然度,值越低表示融合结果越自然;
- 峰值信噪比 PSNR [40]:衡量像素级失真,值越高表示图像质量越好;
- 多尺度结构相似性指数 MS-SSIM [41]:从亮度、对比度、结构三方面评估相似性(扩展自 SSIM),值越高表示结构保留越好;
- 均方误差 MSE [36]:反映融合结果与源图像的细节差异,值越低表示细节保留越完整。
指标特性总结:QTEQ_{TE}QTE、PSNR、MS-SSIM 越高越好;QCVQ_{CV}QCV、MSE 越低越好。
3.3 结果与讨论
3.3.1 在 TNO 数据集上的结果
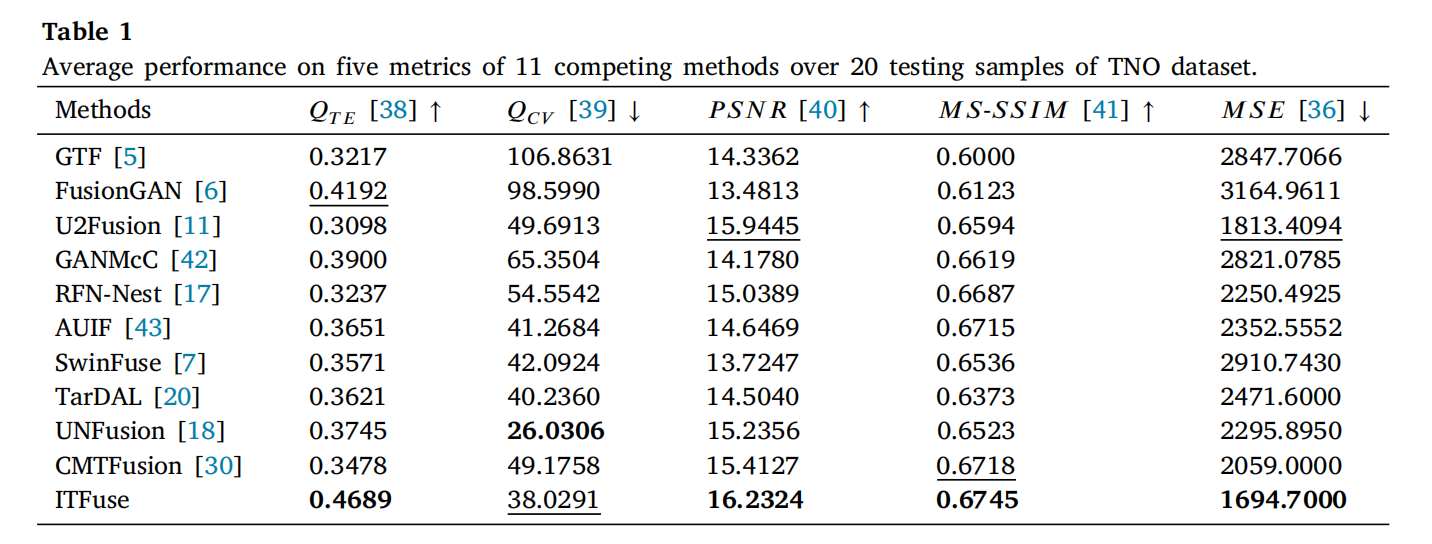
表 1 显示了 ITFuse 与其他十种算法的定量对比。ITFuse 在 QTEQ_{TE}QTE、PSNR、MS-SSIM 和 MSE 上均取得最佳性能(仅 QCVQ_{CV}QCV 第二)。图 9 和图 10 展示了 TNO 数据库的融合结果(源图像对及 11 种方法的融合图像):
- ITFuse 能有效保留源图像的互补信息(红外的热辐射与可见光的纹理细节),生成信息丰富的融合结果;
- GTF 融合结果模糊,丢失部分结构细节(图 9 第二个放大框);
- FusionGAN、GANMcC、RFN-Nest 场景细节提取较好但仍有模糊;
- AUIF、SwinFuse 存在过度强调柱子、背景过暗等不自然问题(图 9 放大框);
- U2Fusion 颜色失真(图 10 右侧特写);
- TarDAL、UNFusion、CMTFusion 生成过亮或不真实图像(图 10 右侧特写)。
主观与客观结果均表明,ITFuse 在视觉保真度和定量评估上优于现有方法。


3.3.2 在 RoadScene 数据集上的结果
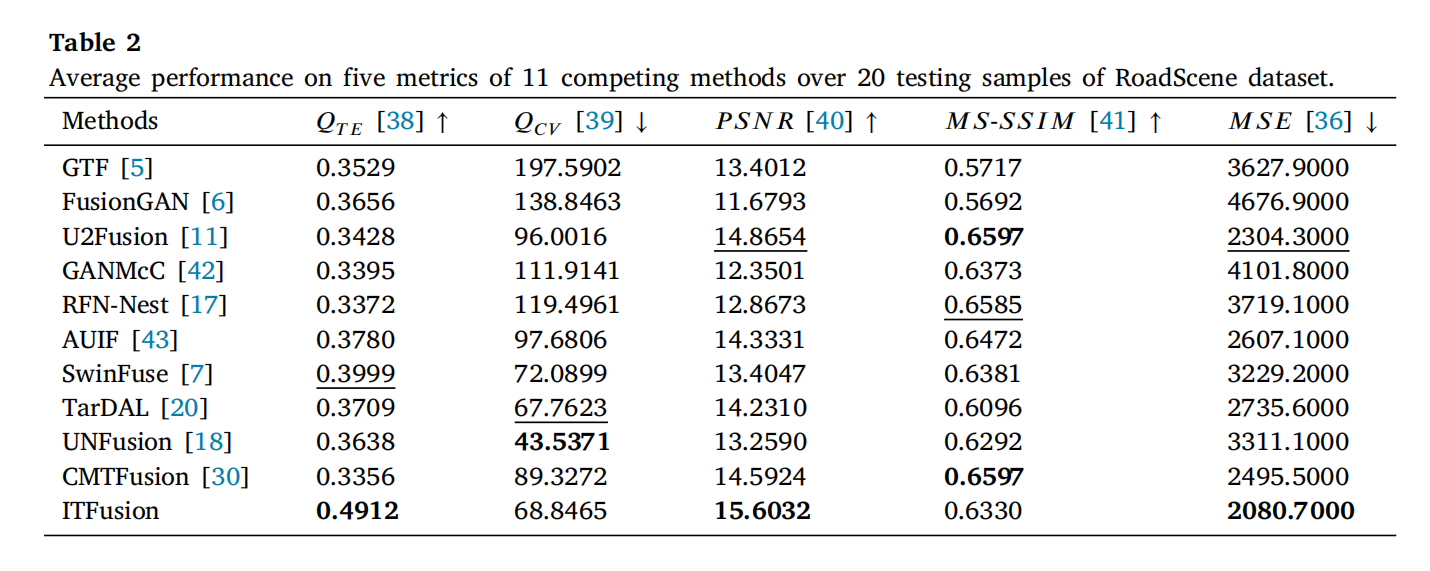
表 2 展示了 ITFuse 与其他方法的客观评估结果。ITFuse 在 QTEQ_{TE}QTE、PSNR、MSE 上优势显著,表明其能有效保留输入图像的重要特征(高散度、低失真)。图 11 和图 12 展示了 RoadScene 数据库的融合结果:
- 融合目标需同时揭示红外的热信息与可见光的场景细节,避免不真实特征;
- GTF、TarDAL 未能充分提取红外特征,目标不清晰(图 11 第一个特写);
- FusionGAN 图像过暗、对比度低(图 12 放大框);
- GANMcC、RFN-Nest、UNFusion、CMTFusion 可见光特征保留较好但对比度不足(图 12 第一个特写);
- U2Fusion、AUIF、SwinFuse 生成旗杆、道路标记过突出等不真实结果(图 11 放大框)。
ITFuse 在挖掘红外热辐射与可见光纹理细节、减少冗余属性上表现最佳。


3.4 消融研究
3.4.1 关于网络架构的消融研究
为验证交互式 Transformer 网络的有效性,在验证集上对 ITFuse 进行五种架构修改的消融实验:
- Uniformly Input:移除 I1I_{1}I1、I2I_{2}I2 分支,FIM 仅保留 IcI_{c}Ic 分支;
- Separately Input:删除 IcI_{c}Ic 分支,I1I_{1}I1、I2I_{2}I2 分别输入 FIM(不使用 ITA,因 ITA 需三输入);
- w/o RAB:用 CB 替换残差注意力块(RAB);
- w/o CMA:用 CB 替换跨模态注意力(CMA)(F1n\mathbb{F}_{1}^{n}F1n、Fcn\mathbb{F}_{c}^{n}Fcn、F2n\mathbb{F}_{2}^{n}F2n 相加后输入 CB);
- w/o TRB:用 CB 替换 Transformer 块(TRB)。
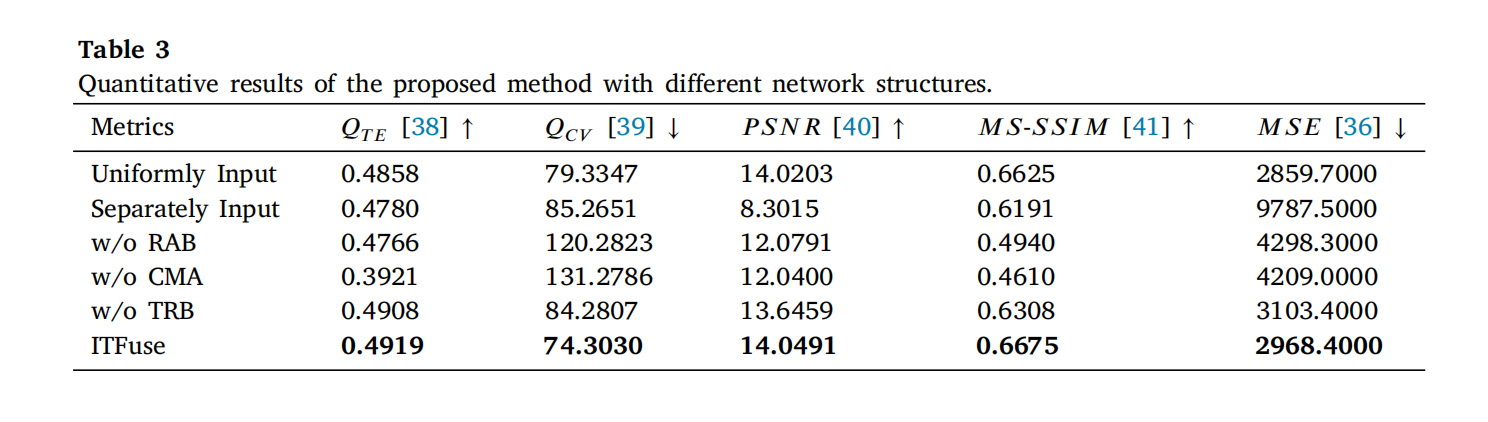
表 3 列出不同架构的定量结果:完整模型在所有指标上最优。图 13 展示主观融合性能:
- 退化模型(如 Uniformly Input、Separately Input、w/o TRB)丢失可见光纹理细节,融合结果模糊;
- w/o RAB、w/o CMA 存在严重伪影,生成不理想图像。
3.4.2 关于损失函数的消融研究
由于 IVIF 无 ground truth,损失函数对融合结果的生成至关重要。为验证所设计的像素损失 LpL_pLp 和结构损失 LsL_sLs 的重要性,在验证集上开展了消融实验:
- 移除像素损失:从总损失 LITFuseL_{ITFuse}LITFuse 中删除 LpL_pLp,新损失函数定义为 L1=LsL_1 = L_sL1=Ls(式19);
- 移除结构损失:从总损失中删除 LsL_sLs,重新定义为 L2=LpL_2 = L_pL2=Lp(式20)。

表 4 列出了 ITFuse 在不同损失函数下的定量比较结果。可见,完整损失函数 LITFuseL_{ITFuse}LITFuse 在 QTEQ_{TE}QTE、PSNR、MS-SSIM 和 MSE 所有指标上均取得最佳性能,验证了像素损失与结构损失协同优化对融合质量的关键作用。
3.5 泛化实验
为评估 ITFuse 的跨数据集泛化能力,将训练好的模型直接应用于未微调的其他红外-可见光融合数据集(KAIST [44] 和 M3FD [20]),验证其普适性。
3.5.1 在 KAIST 数据集上的泛化实验
KAIST 数据集包含红外与可见光图像对,用于验证模型对不同场景的适应性。表 5 展示了 11 种对比方法在 KAIST 数据集 200 个测试样本上的五个指标平均性能(最佳/次佳方法分别用粗体/下划线标记)。
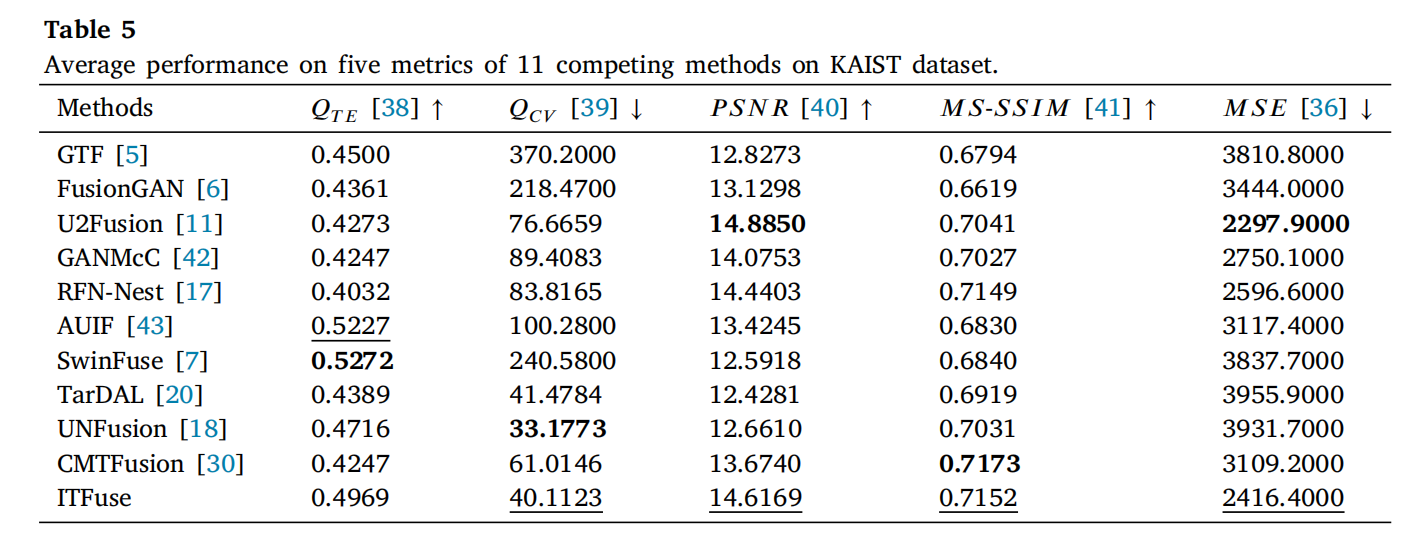
图 15 和图 16 展示了两组源图像对的融合结果(局部放大特写用于细节对比):


- ITFuse 能有效保留源图像的互补信息(红外的热辐射与可见光的纹理细节),融合结果信息丰富;
- 其他方法(如 FusionGAN、U2Fusion 等)存在低对比度、整体变暗问题,导致场景细节丢失。
3.5.2 在 M3FD 数据集上的泛化实验
M3FD 数据集包含灰度红外图像与 RGB 可见光图像,需解决通道不匹配问题。实验中采用 RGB-YUV-RGB 颜色变换 [4] 处理输入,表 6 列出了 11 种方法的平均性能(最佳/次佳方法标记同上)。
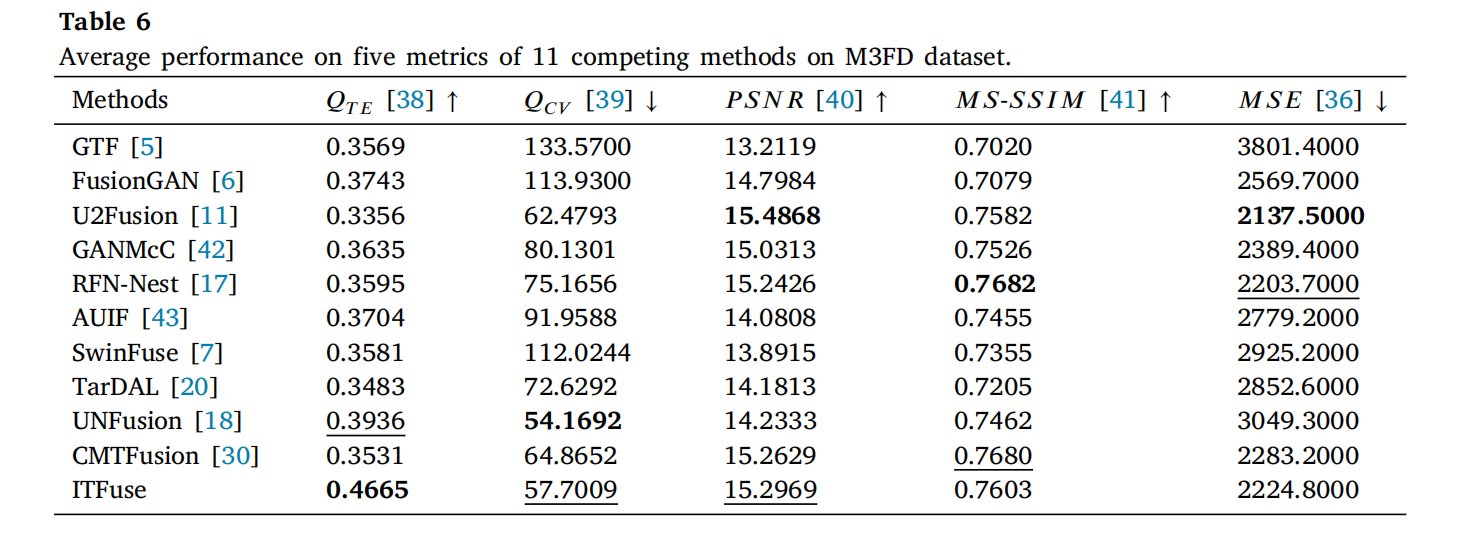


图 17 和图 18 展示了两组源图像对的融合结果:
- 所有方法均能生成合理融合结果,但 ITFuse 在细节保留与对比度上更优;
- FusionGAN 融合模糊,GTF、U2Fusion 等存在低对比度问题,UNFusion 热信息保留不足,而 ITFuse 综合表现最佳。
3.6 效率比较
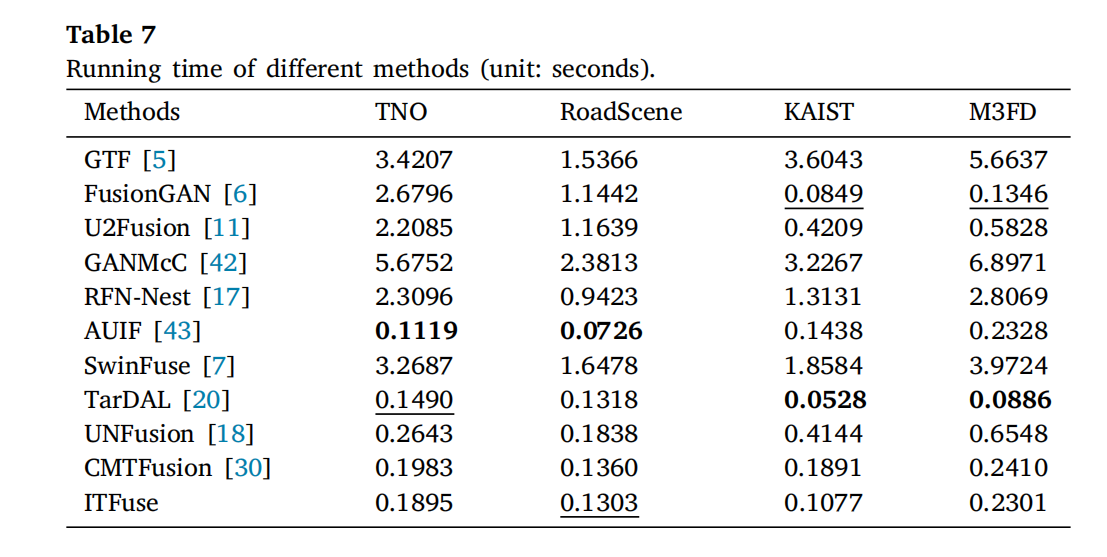
为全面对比方法性能,计算各方法在主流数据集上的平均运行时间(表7)。ITFuse 在 KAIST 数据集融合两幅图像仅需约 0.1 秒,M3FD 数据集约 0.2 秒,显著优于多数 SOTA 方法(如 GTF、U2Fusion 等),表现出实时融合能力。
4. 结论
本文提出了一种用于红外-可见光融合(IVIF)的交互式 Transformer 模型 ITFuse。与现有图像级或特征级融合模型不同,ITFuse 同时考虑多模态的内在与共同特征,通过以下创新实现高性能:
- 特征交互模块:设计特征交互模块(FIM),通过同质/异质属性统一提取与交互注意力(ITA)聚合,动态挖掘上下文信息;
- 特征重建模块:采用跨模态注意力(CMA)整合多分支特征,残差注意力块(RAB)保留重要特征,Transformer 块(TRB)构建长距离依赖;
- 无监督训练策略:结合像素损失 LpL_pLp(保留像素属性)与结构损失 LsL_sLs(约束结构分布),无需 ground truth 即可有效训练。
主流数据库(TNO、RoadScene)实验表明,ITFuse 在定量指标(QTEQ_{TE}QTE、PSNR、MS-SSIM、MSE)与定性评价(视觉保真度、细节保留)上均优于 GTF、FusionGAN 等 10 余种 SOTA 方法。泛化实验(KAIST、M3FD 数据集)验证了其跨场景适应性,效率实验(运行时间)证明其实时性优势。
未来工作将聚焦配准-融合集成模型,解决现实场景中图像未完全配准的问题,进一步推动 IVIF 在 3D 工程等领域的应用。