【机器学习深度学习】LoRA 微调详解:大模型时代的高效适配利器
目录
前言
一、LoRA 的核心思想
二、LoRA 为什么高效?
✅ 1. 参数效率
✅ 2. 内存友好
✅ 3. 即插即用
三、LoRA 适用场景
四、LoRA 实践建议
五、LoRA 和全参数微调对比
六、 LoRA的具体定位
📌 总结
🔗 延伸阅读

前言
在大模型时代,微调(Fine-tuning)已成为模型落地的关键手段之一。但面对动辄几十亿甚至千亿参数的模型,全量微调往往意味着高昂的计算成本与资源消耗。这时,LoRA(Low-Rank Adaptation)应运而生,成为一种高效、轻量、即插即用的微调利器。
一、LoRA 的核心思想
LoRA 的设计哲学是:不要动大模型的原始参数,而是“加点小东西”来改变行为。
在传统微调中,我们需要对整个预训练模型中的权重进行更新,而 LoRA 提出了一个创新的思路:
只训练两个小矩阵 A 和 B,并将它们嵌入原有的线性层中。
其数学表达如下:
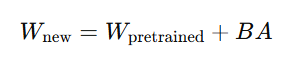
其中:
-
WpretrainedW_{\text{pretrained}}Wpretrained:冻结的大模型原始权重;
-
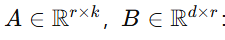 :新增的可训练参数;
:新增的可训练参数; -
r≪d,k:秩远小于原始维度(通常 r=8~64),这就是“Low-Rank”的由来。
这样做的核心优势是:不动原始模型,仅通过“添加低秩扰动”进行模型适配。
二、LoRA 为什么高效?
✅ 1. 参数效率
LoRA 只需训练少量参数(A 和 B)。比如一个 70B 的大模型,仅需训练约 0.1%~1% 的参数:
💡 举例:70B 模型约 7000M 参数,LoRA 仅需训练约 70M 参数。
这极大地减轻了训练负担。
✅ 2. 内存友好
由于只训练 A、B 小矩阵,前向传播时计算量大幅下降,反向传播时仅对小矩阵求梯度,因此显存消耗显著降低:
📉 通常显存降低 35 倍,适用于 12 张消费级显卡。
✅ 3. 即插即用
训练好的 A、B 矩阵可以单独保存为 adapter 权重(如 adapter_model.bin),后续加载时可按需组合:
-
原始模型保持不变;
-
多个 LoRA 模块可根据不同任务动态加载;
-
便于模型管理、部署与复用。
✅ LoRA 权重可以直接被本地预训练模型加载使用,只要你用的是支持 LoRA 的加载方式(如
peft),并确保模型架构一致。这也是 LoRA 的核心优势之一:即插即用、任务解耦、部署灵活。
三、LoRA 适用场景
LoRA 尤其适用于以下场景:
| 应用类型 | 描述说明 |
|---|---|
| 🎙️ 指令跟随 | 训练模型理解并响应自然语言指令,如 ChatGPT 样式交互 |
| 🧑💼 角色扮演 | 给模型注入特定角色或个性,如“AI 女友”、“法律顾问” |
| 📚 知识注入 | 为模型注入特定领域知识,如金融、医疗、工业文档 |
| 🗣️ 多语言适配 | 将英文基础模型迁移到小语种领域 |
| 📱 边缘部署 | 将微调后的小 LoRA 模块应用于低算力设备 |
四、LoRA 实践建议
-
推荐工具链:🤖 Hugging Face +
peft(Parameter-Efficient Fine-Tuning)库; -
推荐秩(rank)值:r=8 或 16 通常效果已足够;
-
保存方式:adapter 格式保存,原模型可复用,便于热加载;
-
部署模式:多个 LoRA 模型可组合,如“医生 + 指令精调”。
五、LoRA 和全参数微调对比
| 项目 | 全量微调 | LoRA 微调 |
|---|---|---|
| 参数量 | 100% | 0.1% ~ 1% |
| 显存占用 | 高 | 低 |
| 训练速度 | 慢 | 快 |
| 迁移性 | 差 | 高,可组合多个 LoRA |
| 原模型改动 | 修改原始权重 | 不修改原模型结构 |
六、 LoRA的具体定位
LoRA是**参数高效微调(PEFT)**的一个典型代表,属于局部微调的子类。它的核心特点是:
- 冻结原始模型:不修改 W,保证原始模型的完整性。
- 新增少量参数:通过 A 和 B 矩阵引入少量可训练参数。
- 任务特定适配:为特定任务(如指令跟随、领域知识注入)快速调整模型行为。
- 模块化设计:LoRA适配器独立于原始模型,易于保存、加载和切换。
这些特性使LoRA与局部微调的理念高度契合,而与增量微调的“持续更新全模型”目标有所不同。
LoRA被归为局部微调,因为它通过引入少量可训练参数(低秩矩阵 A 和 B )来实现任务适配,而不修改原始模型参数。尽管它冻结了全部原始参数,这与某些增量微调的场景有表面相似之处,但LoRA的模块化设计、参数效率和任务特定适配的特性使其更符合局部微调的定义。增量微调更侧重于通过持续训练更新模型的整体能力,通常涉及直接修改原始参数,这与LoRA的机制不同。
术语 狭义解释 广义解释(更通用) LoRA 属于哪类 局部微调 微调原模型部分参数 冻结原模型,仅训练少量参数(包括新增参数) ✅ 属于 增量微调 持续更新原模型参数 对原模型进行“数据/任务”驱动的全模型增强 ❌ 不属于
【举例说明】
- 局部微调(LoRA):假设你有一个70亿参数的模型,想让它适配客服对话任务。使用LoRA,你冻结原始模型,添加并训练低秩矩阵(约7000万参数),生成一个小型适配器文件。这个适配器可以快速加载到原始模型,用于客服任务,且不影响原始模型的其他能力。
- 增量微调:如果你想让同一个模型通过大量新数据(例如多语言语料)来提升其多语言能力,可能需要对全部或大部分参数进行持续训练。这会直接修改原始模型权重,属于增量微调。
📌 总结
LoRA 的提出,为我们提供了一种高效、灵活、可组合的大模型微调方式。它将复杂的全参微调问题简化为“小模块+大模型”的组合形式,大大降低了训练门槛,是当前最流行的参数高效微调方案之一。
在大模型应用爆发的当下,掌握 LoRA,不仅能节省资源,还能提升开发效率,是每一个 AI 开发者必备的技能!
🔗 延伸阅读
-
Hugging Face PEFT 官方文档
-
原始论文:LoRA: Low-Rank Adaptation of Large Language Models
-
实战推荐:在 llama2、Qwen、ChatGLM 等模型中使用 LoRA 微调