【Reasoning】LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning
LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning
arxiv: https://arxiv.org/abs/2410.02884
github: https://github.com/SimpleBerry/LLaMA-O1/tree/main、https://github.com/trotsky1997/MathBlackBox/tree/main
问题背景
复杂的数学推理,特别是奥林匹克级别的题对大语言模型来说仍然具有很大挑战。在现有的研究中:
- 推理方面:CoT可以增强推理能力,但是由于在生成过程缺乏全面的反馈,仍然性能有限。另一种前沿的研究是把整个解决方案当做一个独立状态,使用重写功能来改进解决方案,例如:Self-Refine、reflection等,但这些方法容易受到局部最优、错误的反馈等影响。
- 评估方面:ORM和PRM虽然能够让奖励模型分配一个标量分数,但由于数学任务中每个任务都有独特的特点,这种变化使奖励模型的尺度变得非常复杂,阻碍了它们捕获解决方案之间的局部偏好关系的能力。PRM的成功依赖于大量的人工标注数据,但是该方法耗时且仍面临绝对奖励分数波动性的挑战。
为了解决上述问题,本文提出了SR-MCTS和PPRM方式来进行推理: - SR-MCTS:一个新的马尔可夫决策过程框架。它将一个完整的解视为一个独立的状态,并应用Self-Refine对先前的解进行优化,以获得更优的解。同时,结合MCTS来增强对于解空间的搜索能力,避免陷入局部最优解。
- PPRM(成对偏好奖励函数):开发PPRM将绝对奖励计算转换为解决方案之间的偏好预测来计算,利用解决方案之间的偏好关系来评估它们的质量,这避免了绝对分数的波动。该方法减少了评分特征的可变性,从而导致对不同解决方案具有更好的鲁棒性和一致性的评估。同时,提供了更有指导性的最优路径探索。同时,采用EBC(增强波尔达技术)将局部偏好评估汇总为全局分位数得分,将局部偏好转化为全局评价。结合PPRM和EBC方法,不仅可以使奖励模型学习到更鲁棒的的奖励信号,还可以捕获解空间的全局特征,确保更可靠的比较。
本文LLaMA-Berry框架通过将Self-Refine应用于Monte Carlo Tree Search (SR-MCTS),显著提高了大型语言模型的解生成效率,然后以有向图的形式构建一个全局输赢矩阵来计算最终的分位数分数,结合PPRM将绝对评分转换为偏好预测任务,构建了解决方案之间的偏好,并且使用增强EBC方法计算得到最终的全局分位得分。
本文方法
(1)Self-Refine应用于MCTS
MCTS具有四个关键步骤:选择、扩展、评估、反向传播。在选择阶段,使用UCT(应用于树的上置信界限)来平衡探索和利用选择的节点:
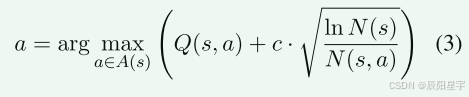
N(s):访问节点s的次数,N(s, a):动作的频率,c:控制探索的参数。评估阶段通常采用模拟或者启发式的方法来评估这些节点的Q。
- 选择阶段:
采用UCT算法选择最优节点,并采用动态剪枝避免局部最优。当节点si的子节点达到预定义的限制,且至少有一个子节点的Q值超过si的Q值时,则认为节点si被完全探索。 - 扩展阶段:
选择的答案si通过Self-Refine过程生成后续答案进行扩展,该过程包括『批判』和『重写』。针对当前选择的答案生成一个批判ci=C(si)来识别当前答案所具有的缺陷,然后再使用重写过程生成一个新的答案si+1=R(si, ci)。新生成的答案被作为新的状态s’被添加到搜索树T中。 - 评估阶段:
评估阶段使用PPRM计算新生成阶段的价值Q(s’),评估主要涉及两个阶段:- 全局评估:由输赢偏好矩阵M中的s’的分位数决定,反应了节点之间的输赢关系。
- 局部评估:通过与搜索树T中相邻节点比较得出。
最终汇总两者信息,得到总价值 Q ( s ′ ) = α Q g ( s ′ ) + ( 1 − α ) Q l ( s ′ ) Q(s')=\alpha Q_g(s') + (1 - \alpha)Q_l(s') Q(s′)=αQg(s′)+(1−α)Ql(s′),其中 α \alpha α被用来控制每个组件的相对影响。
- 反向传播阶段:
新节点的价值Q(s’)被反向传播到父节点s,更新Q(s’)值, Q ( s i ) = ( 1 − γ ) Q ( s i ) + γ Q ( s ′ ) Q(s_i)=(1-\gamma)Q(s_i)+\gamma Q(s') Q(si)=(1−γ)Q(si)+γQ(s′)。 γ \gamma γ用来控制考虑对未来奖励的重要性程度。这种迭代更新机制确保父节点的值逐步细化,增强了对未来选择的指导。
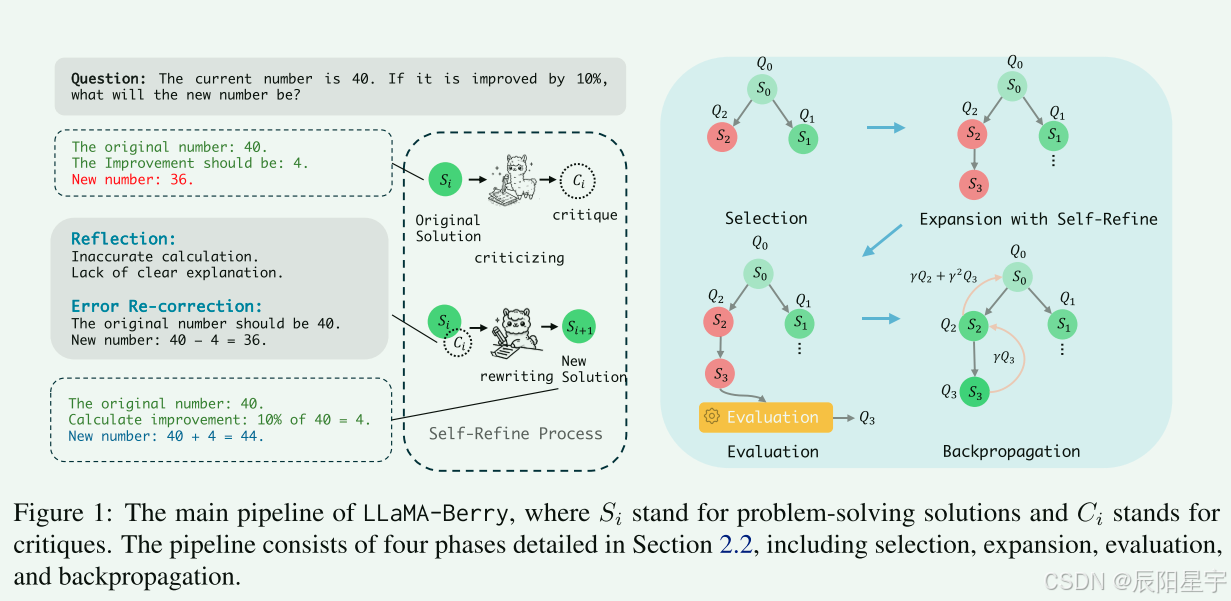
为了控制搜索树的增长,SR-MCTS方法限制了最大rollout次数Nmax。当达到限制条件时,搜索过程终止,这对树的无界扩展施加了限制。SR-MCTS的首要目标是最大化所有现有节点S的最高Q值,引导我们走向最理想的结果S *,确保搜索过程有效地收敛到高质量的解决方案。
(2)成对偏好奖励模型
现有的奖励模型通常通过给出绝对分数来评估解决方案,如过程奖励模型和结果奖励模型。然而,基于分数的奖励模型在利用大型语言模型的指令遵循能力或有效处理得分标准的变化方面可能会有所不足,特别是当解决方案之间的差异很细微时。为了解决这个问题,本文提出了成对偏好奖励模型,该模型利用了一个综合偏好数据集,其中包含来自PRM和ORM方法的大量样本学习数学解之间的偏好关系。
- 偏好定义
对于一个问题,给定的两个解决方案,PPRM使用两两偏序预测它们的相对质量:
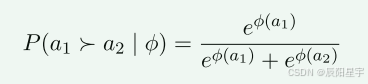
ϕ \phi ϕ表示奖励模型的参数。a1和a2是两个不同的解决方案。 a 1 > a 2 a_1>a_2 a1>a2使用LLM生成的token表示。
- 成对偏好模型训练
文中将PPRM的训练过程构建为问答任务,以利用大型语言模型的指令遵循能力。模型的任务是回答问题:
For Question Q, is solution a1 better than solution a2?
为了形成一个鲁棒的训练目标,使用指标函数I,使用真实值标签y对预测的标记y(“是”或“否”)进行评估:
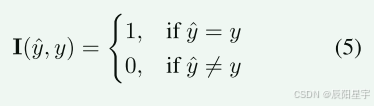
将包含数百万个数学问题解决方案对的配对偏好数据集D转换为适合问答任务的数据集D '。作者采用DPO方法对模型进行训练,以提高其在偏序预测问答任务中的性能。
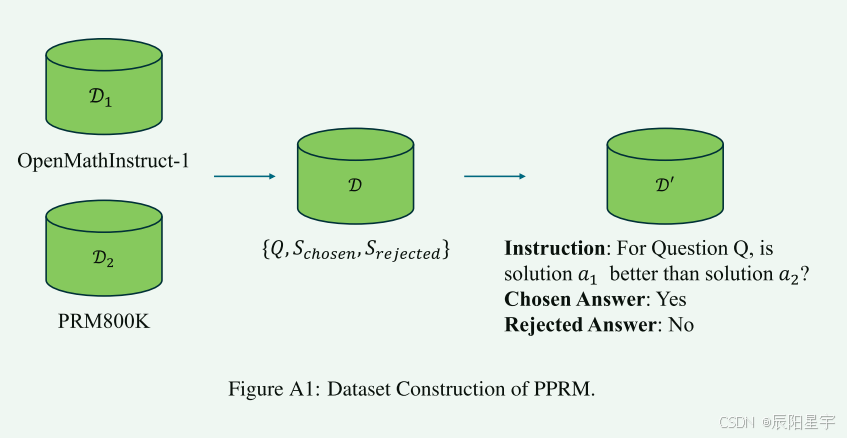
作者的合成数据来源于两个数据集:PRM800K 和OpenMathInstruct-1。从MATH数据集收集的PRM800K数据集包含大量分步解决问题的答案,每个步骤都有手动注释。主要利用该数据集生成基于逐步过程质量的比较分析的成对答案。OpenMathInstruct-1数据集合并了来自GSM8K和MATH数据集的数据,这些数据集已被手动注释以确保结果的正确性。我们使用该数据集合成基于结果质量的比较分析对。最终,文中形成了一个包含7,780,951个条目的数据集,采用DPO方式进行训练,用于训练PPRM模型。
(3)增强Borda计数方法
尽管PPRM允许直接比较两个解决方案的质量,但仍然需要将这些局部偏好转换为有凝聚力的全局排名,以获得对答案的全面评估。这种转换过程可以形式化为与学习排序(LtR)方法相关的全局最优排序聚合(GORA)问题。作者提出增强Borad技术(EBC)方法,该方法是将朴素Borda技术算法与与Floyd-Warshall算法进行结合得到全局评估结果。
- 局部偏好计算
首先,PPRM对所有n个问题的解生成一个偏好矩阵M∈Rn×n,其中Mi,j = 1表示解ai优于解aj,否则Mi,j = 0。
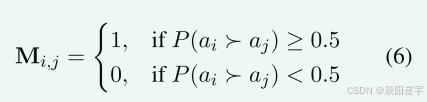
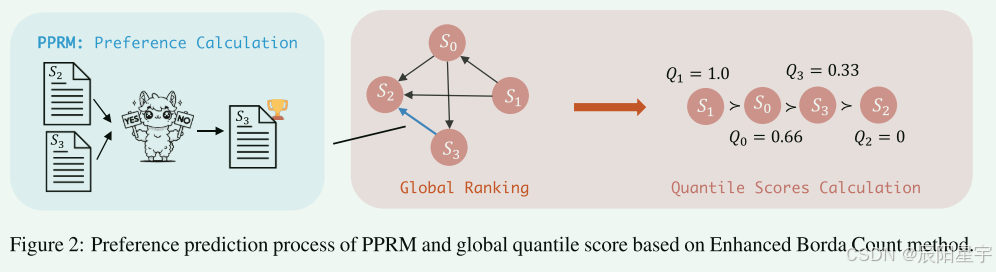
该矩阵可以被视为一个有向图G=(V, E)的邻接矩阵,其中每个解ai对应一个顶点vi,并且在mij=1时,存在一条边e=(vi, vj),表明解ai优于解aj。
-
传递闭包
为了简化问题,作者采用了数学解的传递性假设,即如果a大于b,b大于c,那么就认为a大于c。在此假设下,可以通过Floyd-Warshall算法计算优选矩阵的传递闭包C (例如,ai > aj, aj > al,那么通过Floyd算法后,可以得到ai > al这个闭包关系) ,如Mi,k = 1, Mk,j = 1,则Mi,j = 1。节点对比时,会分别对比父节点、兄弟节点和子节点,『外甥节点』不对比。 -
基于Borda计数的全局排名
在传递闭包矩阵C的基础上,采用增强的Borda计数方法进行全局排序。增强Borda计数通过计算每个节点的出度来确定每个节点的排名,出度对应于它失败的节点数量。对于每个节点vi,定义Borda(vi)为 ∑ j = 1 n = C i , j \sum_{j=1}^n=C_{i,j} ∑j=1n=Ci,j,如上图所示的排序节点。出度越小,排名越高。反之,排名越小。
在实践中,循环偏好可能会导致朴素Borda计数方法产生的效率问题。为了进一步优化排名,作者设计了一个重新排名阶段,其中PPRM生成的逻辑用于『具有相同Borda计数的节点之间的软比较』。具体来说,对于具有相等Borda计数的两个节点vi和vj,软比较规则可以表示为
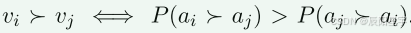
也就是说,当存在两种解决方案出度相同时,根据Floyd算法计算得到传递闭包关系,可得到方案之间的优劣关系。这个过程确保即使在存在循环或局部模糊的情况下,排名也保持一致和合理。也就是说,当出度相同时,比较两者中谁会更优的概率更大。 -
解的全局分位数得分
最后,将排名转换为全局分位数分数Qg,每个解决方案v为 Q g ( v ) = 1 − r a n k ( v ) − 1 ∣ V ∣ − 1 Q_g(v)=1-\frac{rank(v)-1}{|V|-1} Qg(v)=1−∣V∣−1rank(v)−1。
其中rank(v)为基于Borda计数的v在排名中的位置,| v |为节点总数。为了反映搜索树结构中的局部优势,在C中计算节点v及其子节点Children_v的局部胜率Ql(v)如下所示:
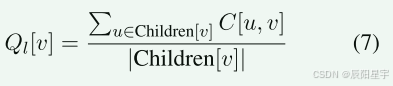
最后,一个解决方案的分数Q(v)是局部胜率Ql(v)和全局分位数分数Qg(v)的加权和。
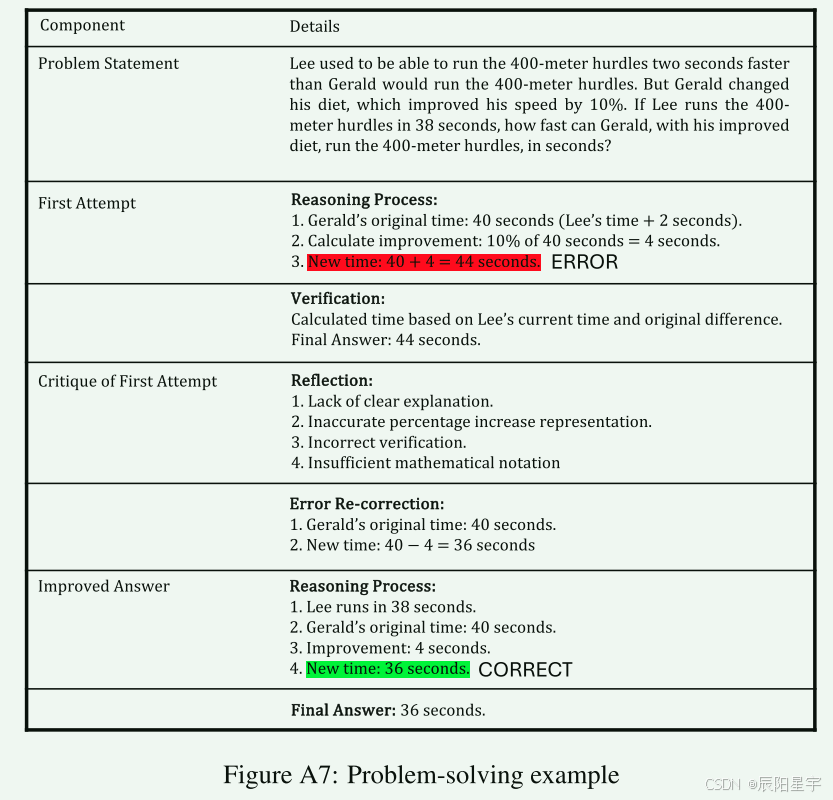
(4)Prompt设计和示例

实验设置
- 基座模型:LLaMA-3.1-8B-Instruct
- PPRM:Gemma2-2B-Instruct
- 评估指标:
- major@k:生成的前k个样本中的返回多数相同正确解的比例,这个指标主要关注多个生成答案之间的一致性。
- rm@k:奖励模型k个采样中最佳的N个响应
实验结果
(1)数据集上情况
- 通用数学任务
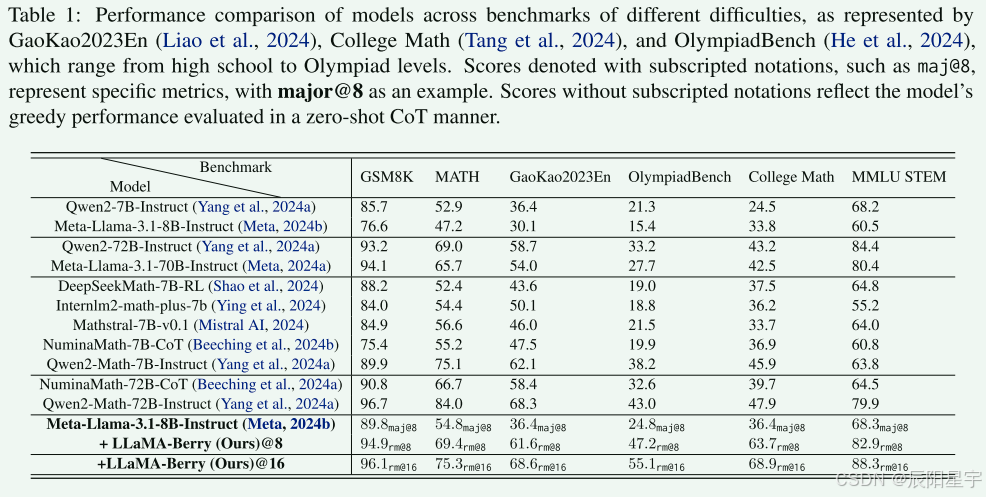
LlaMA-Berry方法对Llama-8B-Instruct在各项数据集上都有所提升,具体来说,在Llama-8B-Instruct的16次rollout中,在三个基准测试中,问题的解决率提高了35%以上。LlaMA-Berry@16在四个基准上的问题解题率都超过Qwen2-Math-72B-Instruct,在有挑战的OlympiadBench数据集上LLaMA-Berry在OlympiadBench和College Math上的得分分别达到55.1%和68.9%,分别高出11.9%和21%。
除了在数学推理方面表现出色,该方法在各种科学和工程领域也表现出色。例如,它在MMLU STEM和GPQA diamond等基准测试中取得了最佳性能。这证明了该方法的鲁棒性和通用性,使其能够解决广泛的技术挑战,并突出了其在研究和实际场景中更广泛应用的潜力。
- 前沿奥林匹克数据集
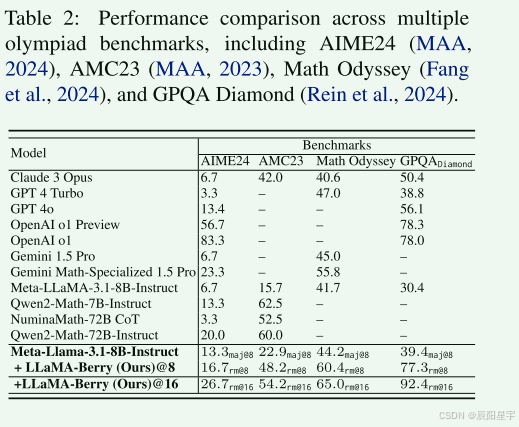
LLaMA-Berry在这些基准测试中具有很强的竞争力,证明了它在复杂推理方面的能力。值得注意的是,在最具挑战性的AIME2024基准上,该方法将基本模型的求解率从2/30提高到8/30,超过了除o1外的其他模型。
- 对比其他基于树的和COT的方法
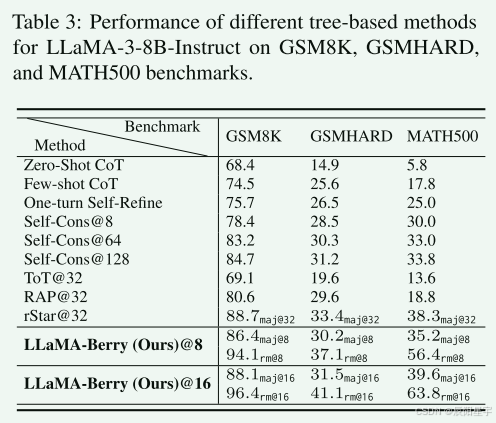
当难度从GSM8K增加到GSMHard时,RAP和ToT的性能相对于Few-shot CoT和One-turn Self-Refine等方法有更显著的下降的趋势。作者怀疑其原因可能是大型语言模型的自我评价能力较弱,这可能导致推理步骤效率低下。此外,基于树的方法可能比直接的方法产生更多的计算开销。相比之下,rStar和本文的方法保持了正向的输出性能趋势,突出了两种方法更高的搜索效率。
为了公平比较rStar 、自一致性和本文的算法对Llama-3-8B-Instruction的报告结果,作者还使用Llama-3-8B-Instruction作为基础模型,而不是3.1版本。作者观察到,文中的方法以更少的部署实现了同等甚至更好的性能。具体来说,文中的方法使用多数投票指标在GSM8K、GSMHARD和MATH500基准测试上分别实现了88.1%、31.5%和39.6%的准确率,这与其他方法的准确率水平相同,而只消耗了rStar的1/2和Self-consistency的1/8的推出时间。这为EBC方法的有效性和动态修剪策略所促进的积极探索提供了令人信服的验证。
(2)消融实验
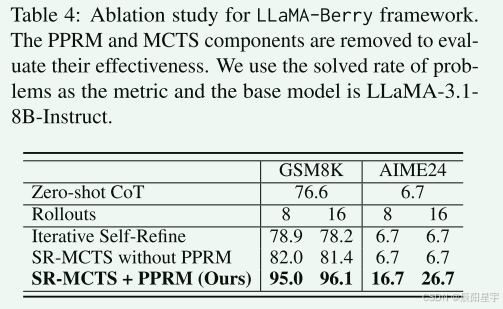
作者进行了消融验来评估LLaMA-Berry的关键组件,使用问题解决率对GSM8K和AIME2024进行度量。Zero-shot CoT表示基座模型推理能力。分别对迭代Self-Refine、只有SR-MCTS,有SR-MCTS和PPRM进行了测试。
实验结果表明,MCTS的引入有效地缓解了迭代Self-Refine方法中有缺陷的批评导致的解退化为次优结果的问题。GSM8K数据集上,在8和16rollout时,在只有SR-MCTS时,问题解决率分别提高了3.1%和3.2%。在又加入了PPRM组件后,问题解决率又分别提高了13%和14.7%。AIME2024数据集上,逐个包含这两个组建后,在8次和16次roloout的情况下,问题解决率从6.7%(2/30)提高到16.7%(5/30)和26.7%(8/30)。
结果强调了在解决复杂问题时将Self-Refine方法与PPRM相结合的有效性。self-reward和PPRM之间的对比强调了设计能够更有效地指导搜索过程奖励机制的重要性。PPRM为模型提供了更全面的激励,从而培养了更有效的解决问题的策略。
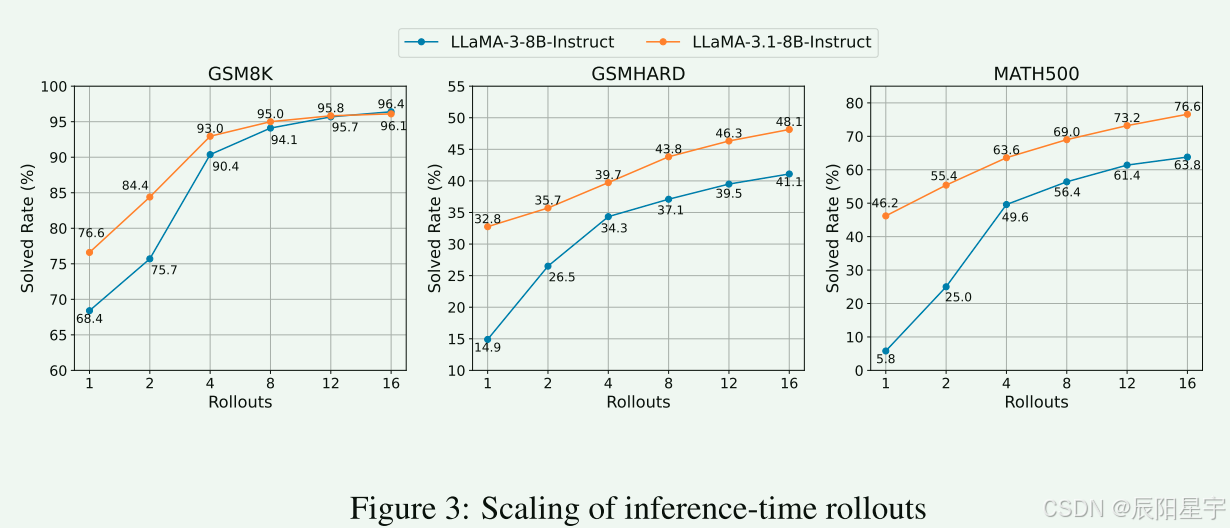
(3)缩放规律研究
为了探索在推理时间内扩展的潜力和趋势,作者在三个不同难度级别的基准中展示了rollout的问题的解决率。通过分析图中的性能,可以发现随着rollout数量不断增加,增强了不同基准测试的模型性能,这些改进的程度取决于基准测试的复杂性和基础模型的推理能力。这些曲线强调了LLaMA-Berry框架的性能受益于在推理期间扩大rollout,类似于OpenAI中的观察结果。然而,正如在GSM8K数据集中所看到的那样,存在上限限制,这表明基本模型在推理和『细化方面』的能力在决定整体性能方面起着至关重要的作用。
局限性
- LLaMA-Berry框架在推理任务中表现出了较强的性能,但在实际应用中仍存在一些挑战。首先,MCTS和Self-Refine等方法计算成本高。这些技术需要大量的计算资源,这可能会限制在计算能力有限的环境中部署的可行性。在解的总结器方面,基于规则的启发式方法(如自一致性、共同投票和相互推理)对MCTS的上限搜索性能产生了约束。因此,文中的目标是像OpenAI那样开发一个『基于学习的总结器』,以进一步提高搜索效率。
- 目前对LLaMA-Berry框架的评估主要集中在数学推理基准上,导致评估范围相对狭窄。因此,它在更广泛的领域的表现,如一般知识、符号逻辑任务和多模态应用,还没有得到充分的验证。
- 大多数实验都使用了相对较小的开源模型,在较大或闭源模型上进行了有限的测试。