第二章 分词和嵌入
目录
一、tokenization
1.1 语言模型的输入处理
1.2 运行LLM的tokenizer
1.3 tokenizer如何处理输入
1.4 Tokenizer层级的选择
1.4.1 Word Tokens
1.4.2 Subword Tokens
1.4.3 Character Tokens
1.4.4 Byte Tokens
1.5 Tokenizer处理方式的比较
1.6 决定tokenizer要素
1) 分词方法的选择
2) 分词器设计选择
词汇量大小
特殊标记
大写处理
3) 分词器的训练数据集
二、 Token Embedding
2.1 LLM中的Embedding
2.2 Contextualized Word Embeddings
三、Text Embeddings
3.1 生成Text Embeddings向量的方法
四、pre-LLM向量化技术: word2vec
4.1 使用预训练的Word Embeddings
4.2 Word2vec算法和对比训练
五、推荐系统中的嵌入
5.1 使用嵌入推荐歌曲
5.2 训练歌曲嵌入模型
六、总结
token和embedding是LLM原材料
一、tokenization
每一个大模型都有配套的tokenizer,其负责将输入文本分解成模型可以理解的格式,并将模型的输出转换回人类可读的文本。
1.1 语言模型的输入处理

prompt先通过tokenizer进行处理,将其分解成更小的片段。
(tokenizer模拟网页Tokenizer - OpenAI API)下图是gpt-4o的tokenizer
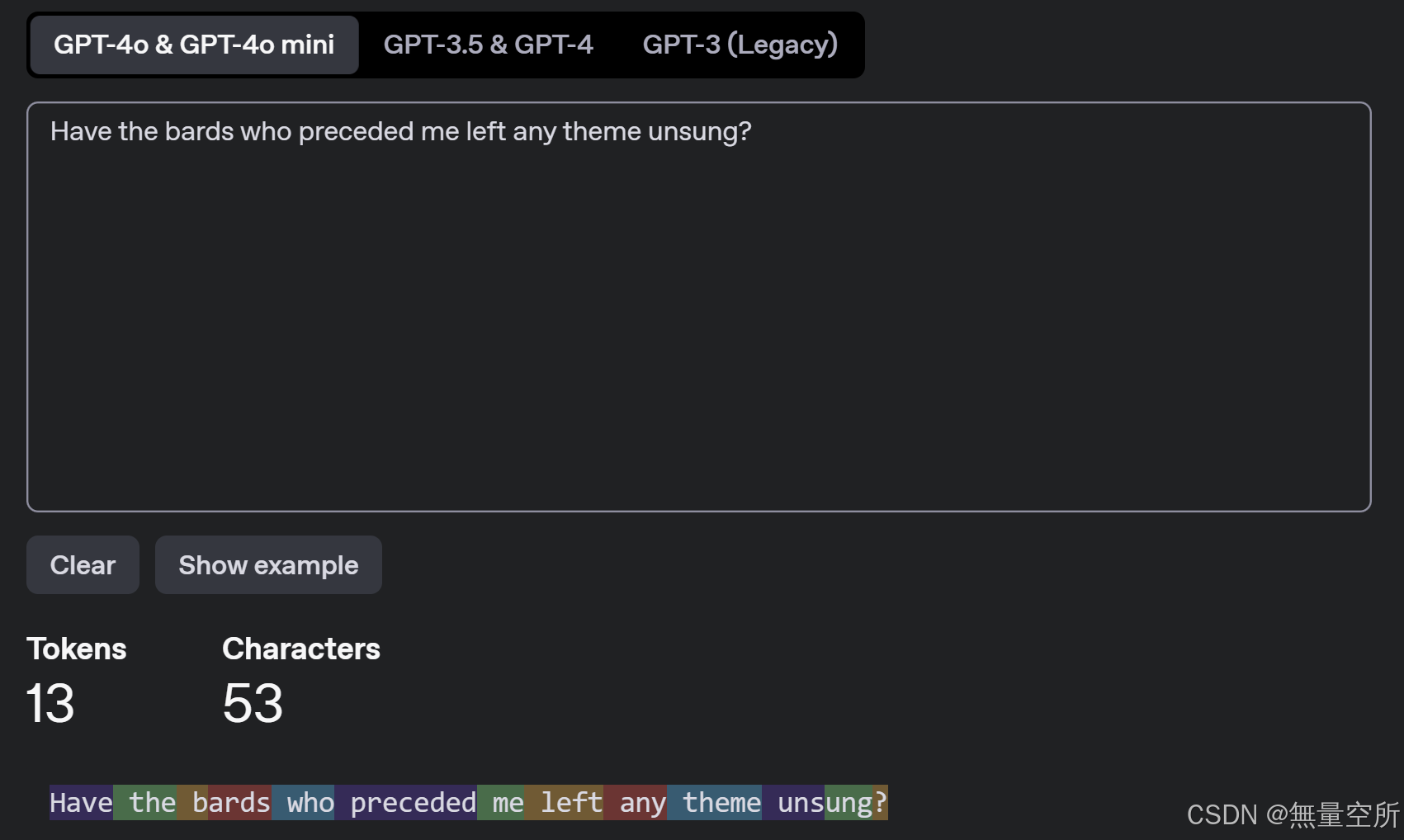
1.2 运行LLM的tokenizer
使用BERT-Base-Chinese的tokenizer
import torch
from transformers import BertTokenizer, BertModel
prompt = "这是一个测试文本,包含中文、English和特殊字符!@#$%^&*()。E=mc^2,x=(-b±sqrt(b?-4ac))/ 2a。def hello world(): print('Hello, world!');2024年,AI发展迅猛"
# 1. 加载分词器
# 这里使用的是BERT-Base-Chinese的分词器,它会自动下载并缓存到本地
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 2. 对文本进行分词处理并获取tokens序列
tokens = tokenizer.tokenize(prompt)
print("bert-base-chinese Tokens:", tokens)
print("-------------------------")
#获取tokensID
tokens_ids = tokenizer.convert_tokens_to_ids(tokens)
print("tokensID: ", tokens_ids)
print("-------------------------")1.3 tokenizer如何处理输入
tokenizer将输入文本转换成一系列的token ID(encode操作)。这些token ID是文本中特定token(字符、单词或单词的一部分)的唯一标识符,它们引用tokenizer内部维护的一个表,该表包含了tokenizer所知道的所有token。
下图展示了tokenizer如何处理输入prompt。除了用于处理输入prompt,tokenizer还用于处理语言模型的输出。将模型生成的标记ID转换为与之关联的输出单词或标记,这一过程是将模型的内部表示转换回人类可读的文本的关键步骤。
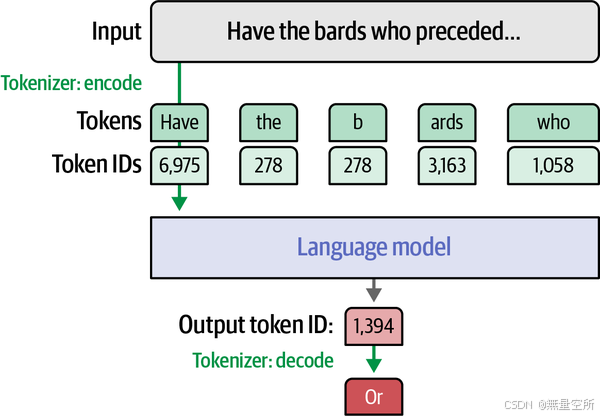
可以使用tokenizer中的decode方法将token ID转变成token
for id in tokens_ids:
print(tokenizer.decode(id))1.4 Tokenizer层级的选择
四种主要的分词方法
1.4.1 Word Tokens
早期的NLP方法(如word2vec)中很常见,但现在在NLP中使用得越来越少。但它仍然在NLP之外的领域(如推荐系统)中使用。
挑战:Tokenizer可能无法处理在Tokenizer训练后进入数据集的新词。这还导致词汇表中有很多标记之间只有微小差异(例如,apology, apologize, apologetic, apologist)。
解决方法:Subword Tokens通过拥有一个表示apolog的标记,然后是后缀标记(例如,-y, -ize, -etic, -ist),这些后缀与许多其他标记共有,从而解决了这一挑战,实现了更丰富的词汇表达。
1.4.2 Subword Tokens
包含完整的单词和部分单词。除了前面提到的词汇的词性外,这种方法的另一个好处是能够通过将新标记分解为较小的字符来表示新词,这些字符往往是词汇表的一部分。
Subword Tokens在适应Transformer模型有限的上下文长度方面具有优势。因此,对于具有1,024上下文长度的模型,使用子词分词可能比使用字符标记多容纳大约三倍的文本(子词标记通常平均每标记三个字符)。
1.4.3 Character Tokens
这是另一种可以成功处理新词的方法,因为它有原始字母作为后盾。虽然这使得表示更容易分词,但使得建模更加困难。使用子词分词的模型可以将“play”表示为一个标记,而使用字符级标记的模型需要建模拼写“p-l-a-y”的信息以及建模序列的其余部分。
1.4.4 Byte Tokens
一种额外的分词方法将token分解为用于表示Unicode字符的单个字节。这也被称为“无分词编码”。其他工作如“ByT5: Towards a token-free future with pre-trained byte-to-byte models”表明,这可以是一种竞争性方法,特别是在多语言场景中。
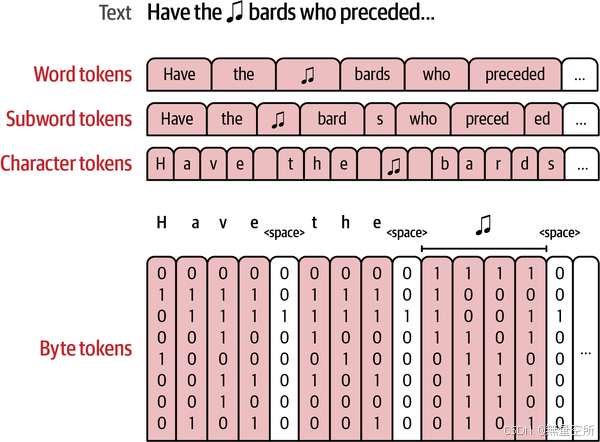
总结
- Word: word2vec, 新词不好处理,很多词变化只有小区别“apology, apologize, apologetic, apologist”
- Subword:既有全词也有子词,有些也使用byte fall back,如GPT-2 and RoBERTa
- Character:词元化容易,但训练模型困难,需要额外记 忆将字符拼成单词的信息, ⼤概数量是subword * 3
- Byte: 用字节来表示unicode⾳符
需要强调的一个区别:一些Subword Tokenizer也在其词汇表中包括字节作为标记,作为遇到无法以其他方式表示的字符时的最终后盾。例如,GPT-2和RoBERTa分词器就是这样。这并不意味着它们是无分词的字节级分词器,因为它们不使用这些字节来表示所有内容,只表示一部分。
1.5 Tokenizer处理方式的比较
关注:大写字⺟, 非英语, Emojis, Code, Number/digits,特殊字符
prompt:

处理结果:

1.6 决定tokenizer要素
1) 分词方法的选择
在模型设计阶段,模型的创建者会选择一种分词方法,每一种方法都概述了一种算法,用于选择适当的标记集来表示数据集。流行的分词方法包括字节对编码(BPE)和WordPiece。BPE被GPT模型广泛使用,而WordPiece则被BERT使用。
这些方法虽然目标相似——优化一组标记以有效表示文本数据集——但它们实现这一目标的方式不同。
在Hugging Face页面上可找到所有这些方法的概述,该页面总结了分词器的相关信息
2) 分词器设计选择
选择分词方法后,需要做出一些参数决策,如词汇表大小和使用哪些特殊标记。这些选择会影响分词器的性能和输出。
词汇量大小
分词器的词汇表中应保留多少标记?(30K和50K通常是词汇量大小的值,但我们越来越多地看到像100K这样的更大尺寸。)
特殊标记
我们希望模型跟踪哪些特殊标记?我们可以添加任意数量的这些标记,特别是如果我们想要构建一个用于特殊用例的LLM。常见的选择包括:
文本开始标记(例如,
<s>)文本结束标记
填充标记
未知标记
CLS标记
掩码标记
除此之外,LLM设计者还可以添加有助于更好地模拟他们试图关注的领域问题的标记,正如我们在Galactica中所看到的<work>和[START_REF]标记。
大写处理
在诸如英语之类的语言中,我们如何处理大写?我们应该将所有内容转换为小写吗?(名称大写通常携带有用信息,但我们是否希望在词汇表空间上浪费全大写版本的单词?)
3) 分词器的训练数据集
分词器还需要针对其处理的数据领域进行优化。例如,如果分词器主要用于代码生成,它可能需要能够识别和正确处理编程语言中的关键字和符号。同样,如果分词器用于多语言文本,它可能需要能够处理不同语言的字符和语法结构。
即使我们设置相同的方法和参数,训练在不同数据集上的分词器也会有所不同。例如,一个在英文文本数据集上训练的分词器将与在代码数据集或多语言文本数据集上训练的分词器不同。
总结
- 算法: BPE字节对编码GPT模型常用, WordPiece(BERT)。这些算法的⽬标都是优化⼀个数据集上的最优的tokens集合。
- 词汇表大小,特殊词元集(如开始、结束、填充、未知、 CLS、 MASK、对话分隔), 大写处理
- 专门的数据集: 用于训练最佳词汇表(用于什么领域)
二、 Token Embedding
Token Embedding是将文本数据转换为模型可以处理的数值形式的关键步骤。这些Embedding捕获了标记的语义信息,使得模型能够理解和生成文本。Embedding的质量和模型的性能密切相关,因为它们直接影响模型对文本模式的理解和生成能力。
挑战:1)如何确保Embedding能够准确地表示标记的含义。2)如何处理新出现的词汇或罕见的词汇。3)嵌入的维度和大小也会影响模型的效率和性能。
2.1 LLM中的Embedding
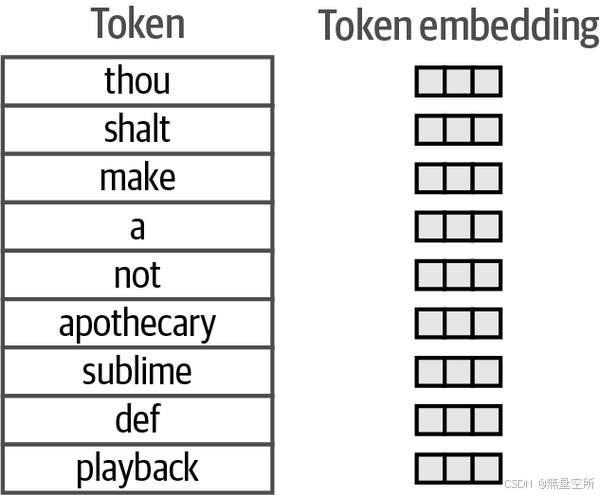
语言模型为其tokenizer词汇表中的每个token保存一个embedding向量,如下图。当我们下载一个预训练语言模型时,模型的一部分就是包含所有这些向量的嵌入矩阵。
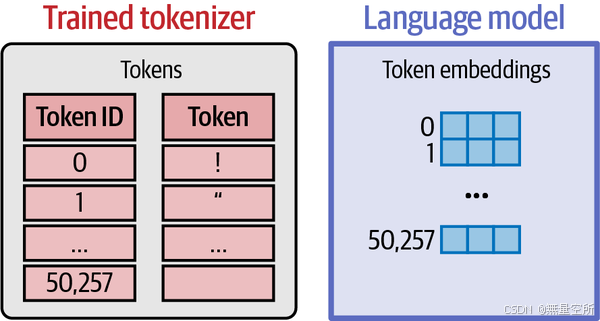
在训练过程中,嵌入向量会不断更新和优化,以更好地捕捉语言的复杂模式。这个过程包括:
-
随机初始化:在训练开始之前,嵌入向量随机初始化,为模型提供一个起点。
-
梯度下降:在训练过程中,模型通过梯度下降等优化算法不断调整嵌入向量,以最小化损失函数。
-
反向传播:模型使用反向传播算法来计算嵌入向量的梯度,并更新它们的值。
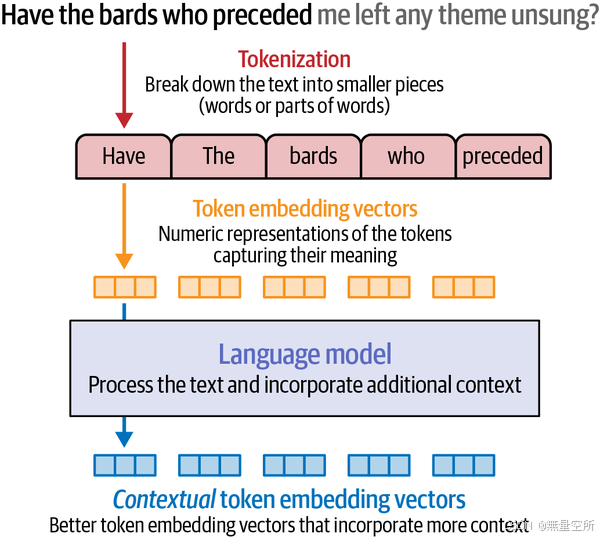
2.2 Contextualized Word Embeddings
与用静态向量表示每个标记或单词不同,语言模型创建上下文相关的词嵌入,根据单词的上下文用不同的token来表示它。然后,这些向量可以被其他系统用于各种任务。
下图表示语言模型以原始的静态嵌入作为输入,并生成上下文化的文本嵌入。
三、Text Embeddings
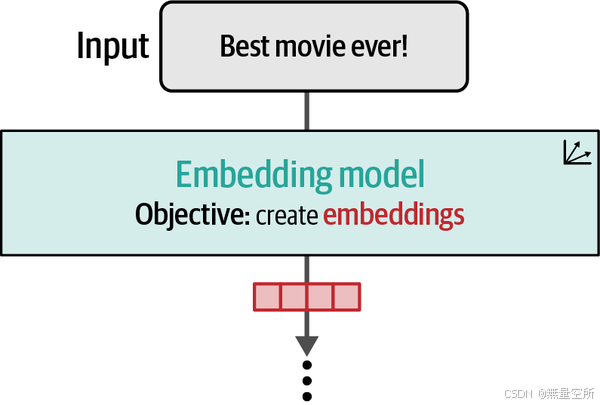
虽然Token Embedding是大型语言模型运作的关键,但许多LLM应用需要对整个句子、段落甚至文本文档进行操作。这导致了特殊语言模型的产生,这些模型能够生成Text Embedding——一个代表文本的单一向量,而不仅仅是一个token。
我们可以将Text Embeddings模型视为接受一段文本,并最终生成一个代表该文本并以其有用的形式捕捉其含义的单一向量。
3.1 生成Text Embeddings向量的方法
方法一:平均模型生成的所有Token Embeddings的值。然而,高质量的Text Embeddings模型往往是专门为Text Embeddings任务训练的。
方法二:使用sentence-transformers库生成文本嵌入,使用all-mpnet-base-v2模型。
from sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# 将文本转换为文本嵌入
vector = model.encode("Best movie ever!")嵌入向量的维度,取决于底层嵌入模型。 当前模型vector.shape = (768,),表明“Best movie ever”现在被编码在这个具有768个数值维度的单一向量中。
四、pre-LLM向量化技术: word2vec
4.1 使用预训练的Word Embeddings
使用Gensim库下载预训练的词嵌入(如word2vec或GloVe)
import gensim.downloader as api
# 下载嵌入(66MB,glove,训练于维基百科,向量大小:50)
# 其他选项包括 "word2vec-google-news-300"
# 更多选项在 https://github.com/RaRe-Technologies/gensim-data
model = api.load("glove-wiki-gigaword-50")我们已经下载了在维基百科上训练的大量单词的嵌入。然后我们可以通过查看特定单词“king”的最近邻来探索嵌入空间:
model.most_similar([model['king']], topn=11)
>> 输出
[('king', 1.0000001192092896),
('prince', 0.8236179351806641),
('queen', 0.7839043140411377),
('ii', 0.7746230363845825),
('emperor', 0.7736247777938843),
('son', 0.766719400882721),
('uncle', 0.7627150416374207),
('kingdom', 0.7542161345481873),
('throne', 0.7539914846420288),
('brother', 0.7492411136627197),
('ruler', 0.7434253692626953)]这显示了与“king”最相似的词,表明了嵌入空间中词与词之间的关系。
4.2 Word2vec算法和对比训练
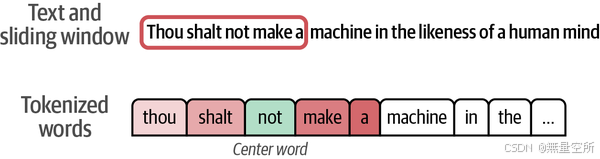
该算法使用滑动窗口生成训练示例。例如,我们可以有一个窗口大小为2,这意味着我们考虑中心词两侧的两个邻居。
Embedding是通过一个分类任务生成的。这个任务用于训练神经网络,以预测单词是否通常出现在相同的上下文中(这里的上下文意味着在训练数据集中的许多句子中)。我们可以将其视为一个神经网络,它接受两个单词并输出1(如果它们倾向于出现在相同的上下文中),如果它们不出现则输出0。
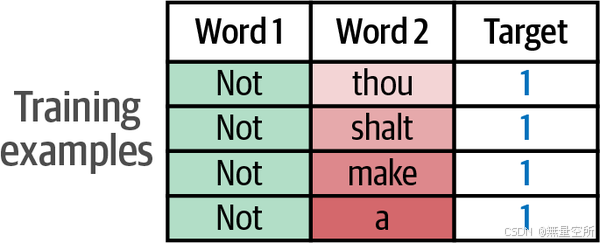
在滑动窗口的第一个位置,我们可以生成四个训练示例,以便word2vec算法稍后预测两个单词是否为邻居,如下图所示(此处not为中心词)。
在每个生成的训练示例中,中心词用作一个输入,每个邻居在每个训练示例中都是一个不同的第二个输入。我们期望最终训练好的模型能够分类这种邻居关系,并在接收到的两个输入单词确实是邻居时输出1。这些训练示例如图。
然而,如果我们的数据集只有一个目标值1,那么模型可以通过始终输出1来作弊并通过。为了解决这个问题,我们需要通过随机采样从数据集中添加非邻居的单词来丰富我们的训练数据集。这些被称为负例,如下图。
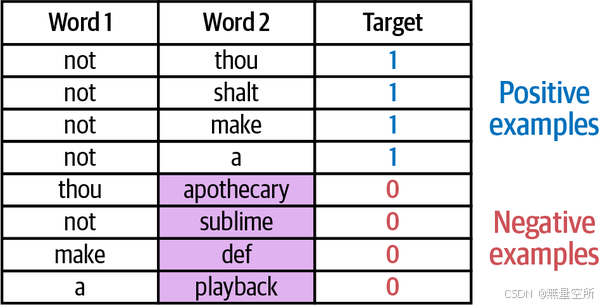
此处不必过于科学地选择负例。许多有用的模型都是通过简单地从随机生成的示例中检测正例而产生的(受到一个称为噪声对比估计的重要思想的启发,并在“Noise-contrastive estimation: A new estimation principle for unnormalized statistical models”中进行了描述)。因此,在这种情况下,我们获取随机单词并将它们添加到数据集中,并指出它们不是邻居(因此模型在看到它们时应该输出0)。
word2vec的两个主要概念:
- skip-gram,选择相邻单词的方法;
- 负采样,通过从数据集中随机采样添加负例。
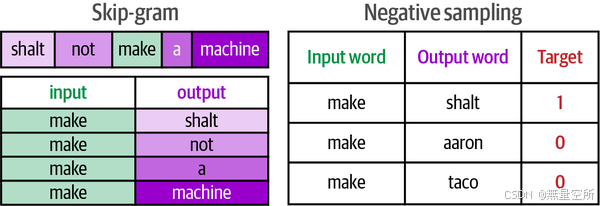
我们可以从运行文本中生成数百万甚至数十亿个这样的训练示例。
在继续在该数据集上训练神经网络之前,我们需要做出一些分词决策,就像我们之前看到的tokenizer一样,包括如何处理大小写和标点符号以及我们想要在词汇表中有多少个token。
然后我们为每个token创建一个Embedding向量,并随机初始化它们,如图2-15所示。在实践中,这是一个vocab_size x embedding_dimensions维度的矩阵。
然后模型在每个示例上进行训练,以接受两个嵌入向量并预测它们是否相关。如下图所示。

根据其预测是否正确,典型的机器学习训练步骤更新嵌入,以便下次模型呈现这两个向量时,它有更好的机会更正确。通过训练过程的结束,我们有了词汇表中所有标记的更好嵌入。
五、推荐系统中的嵌入
5.1 使用嵌入推荐歌曲
使用word2vec算法通过人工制作的音乐播放列表来嵌入歌曲。想象一下,如果我们将每首歌视为一个单词或标记,并将每个播放列表视为一个句子。然后,这些嵌入可以用来推荐经常一起出现在播放列表中的类似歌曲。
我们将使用由康奈尔大学的Shuo Chen收集的数据集。它包含来自美国数百个广播电台的播放列表。下图展示了这个数据集。

5.2 训练歌曲嵌入模型
1)加载包含歌曲播放列表以及每首歌的元数据(如其标题和艺术家)的数据集:
import pandas as pd
from urllib import request
# 获取播放列表数据集文件
data = request.urlopen('https://storage.googleapis.com/maps-premium/dataset/yes_complete/train.txt')
# 解析播放列表数据集文件。跳过前两行,因为它们只包含元数据
lines = data.read().decode("utf-8").split('\n')[2:]
# 移除只有一首歌的播放列表
playlists = [s.rstrip().split() for s in lines if len(s.split()) > 1]
# 加载歌曲元数据
songs_file = request.urlopen('https://storage.googleapis.com/maps-premium/dataset/yes_complete/song_hash.txt')
songs_file = songs_file.read().decode("utf-8").split('\n')
songs = [s.rstrip().split('\t') for s in songs_file]
songs_df = pd.DataFrame(data=songs, columns = ['id', 'title', 'artist'])
songs_df = songs_df.set_index('id')playlists列表中每个元素都是一个包含歌曲ID列表的播放列表:
print( 'Playlist #1:\n ', playlists[0], '\n')
print( 'Playlist #2:\n ', playlists[1])
>> 输出
Playlist #1: ['0', '1', '2', '3', '4', '5', ..., '43']
Playlist #2: ['78', '79', '80', '3', '62', ..., '210']2)训练模型
from gensim.models import Word2Vec
# 训练我们的Word2Vec模型
model = Word2Vec(
playlists, vector_size=32, window=20, negative=50, min_count=1, workers=4
)3)推荐相似歌曲
import numpy as np
def print_recommendations(song_id):
similar_songs = np.array(
model.wv.most_similar(positive=str(song_id),topn=5)
)[:,0]
return songs_df.iloc[similar_songs]
# 提取推荐,让模型找出与歌曲#2172相似的歌曲
print_recommendations(2172)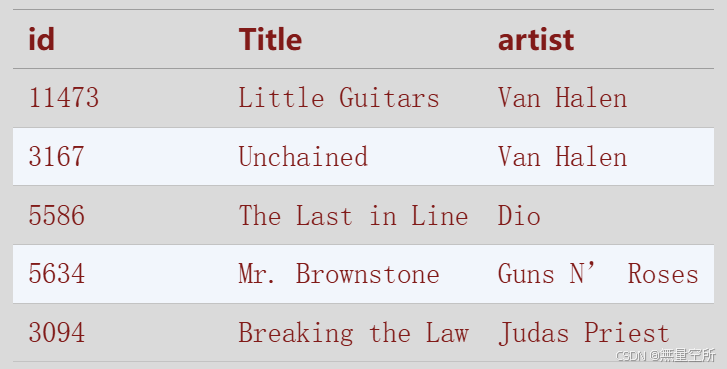
六、总结
分词器和标记嵌入基础
-
分词器将文本转换为模型可以理解的标记ID,是处理语言模型输入的第一步。
-
常见的分词方法包括按单词、子词、字符或字节来分解文本。
预训练分词器概览
-
不同的预训练分词器在处理特定信息(如大写、换行符、其他语言的标记)方面表现不同。
-
分词器之间的差异可能体现在它们如何分解特定的单词。
分词器设计决策
-
主要的设计决策包括选择分词算法(例如BPE、WordPiece)、设置分词参数(词汇量大小、特殊标记等)以及分词器训练的数据集。
语言模型与上下文相关的嵌入
-
语言模型能够产生上下文化标记嵌入,这些嵌入比原始静态嵌入更为高级。
-
这些上下文化嵌入对于执行命名实体识别、文本摘要和文本分类等任务至关重要。
-
语言模型还能生成代表整个句子或文档的文本嵌入,从而支持广泛的应用。
传统词嵌入方法与对比训练
-
在LLM出现之前,word2vec、GloVe和fastText等词嵌入方法很流行。
-
word2vec算法依赖于skip-gram和负采样两个核心概念,并使用对比训练。
嵌入在推荐系统中的应用
-
嵌入对于创建和改进推荐系统非常有用,例如基于策划的歌曲播放列表构建的音乐推荐系统。
下一步:深入LLM的处理过程
-
在下一章中,我们将深入了解分词之后的过程,即LLM如何处理标记并生成文本。
-
我们将探讨使用Transformer架构的LLM的工作原理和主要直觉。